2552
————————————————————
INTRODUCTION
As the usage of social media blogs for expressing opinions, recommendations, ratings and obtaining feedback is playing a major role in the decision making process. Reviews can source from different domains and it is difficult to prepare labeled training data for all of them. Also it is difficult to design a robust classifier to deal with different data distributions covering from different domains. The cost of labeling training data for a larger number of domains involves huge cost. Domain adaptation is a parameter in the cross domain sentiment classification in which the training and testing data are selected from different domains. The process of training and testing models on different domains are known as domain adaptive models. Two kinds of adaptations should be addressed, one is labeling adaptations and other is instance adaptation. Labeling adaptation goal is to learn a new labeling function or feature representation for the target domain. Instance adaptation tries to approximate the target domain data by assigning different weights to the source domain labeled data and conducting importance sampling as different domains have different term frequencies. Deep learning techniques can be used to extract high level features from online reviews in an unsupervised fashion. Large amounts of unlabeled data across all domains to learn the intermediate representations. Neural network based sentiment classification models are used to learn low-dimensional text features without any feature engineering. This model gives flexibility for sentiment classifiers in domain adaptation by training on labeled reviews from one source and deployed on another domain.
I.
RELATED
WORKS
A. Domain adaptation
Structural corresponding algorithm was proposed for domain adaptation and a measure of domain similarity was identified by selecting pivot features which links source and target domains based on their common frequency and mutual information by using source labels [1]. Spectral feature alignment algorithm was proposed with the help of bipartite graph by discovering the relationship between domain specific and independent words from different domains for learning meaningful text representations [2]. Deep learning approach was used for high level feature extraction by using a stack of denoising and auto encoders from the text reviews of all the available domains [3]. An approach for cross domain sentiment classification was proposed by creating a thesaurus
which is sensitive to the sentiment of words expressed in various domains [4]. A joint sentiment topic model was proposed for extracting polarity bearing topics and words from different domains can be grouped under the same polarity bearing topics [5]. Relative adaptive bootstrapping algorithm was proposed in a domain adaptation framework for sentiment and topic extraction in a target domain without any labeled data by expanding seeds in target domain [6]. Two individual classifiers with the labeled data from the source and target domains are selected with information samples using Query by Committee strategy approach [7]. A novel inter corpus statistical approach was proposed with the help of Domain Relevance measure and used for opinion feature extraction between different corpus [8]. A Joint approach was proposed for feature ensemble and sample selection by using Principal component analysis to handle label and instance adaptation [9].
B. Sentiment Classification
Neural networks performed well in cross domain sentiment classification area because of less feature engineering work. Document level sentiment classification model was proposed by using convolution kernels with the help of high impact substructures of sentences guided by a polarity lexicon [10]. Neural sentiment classification model was proposed by building a hierarchical long short-term memory (LSTM) using information of both global user and product to generate sentence and document level representation jointly [11]. Document level sentiment classification model was proposed with a recurrent neural based architecture by using cached LSTM neural networks for capturing the overall semantic information in long texts [12]. Deep unordered model for sentence and document level of classification was proposed on pretrained embeddings by using a deep averaging network [13]. Model was proposed with a combination of recursive neural tensor networks and the stanford sentiment tree bank which is a corpus for the sentiment analysis task. [14]. A hybrid model was proposed for character level sentiment classification based on neural network with combination of convolution and recurrent layer [15]. Aspect level classification attention model was proposed using deep memory network to compute the representation of a sentence with regard to an aspect [16]. Feature embedding model was proposed for domain adaptation by using representational learning which are dense representations of individual features [17]. For sentence level classification task, a convolutional neural network (CNN) which is trained on top of pre-trained word
Domain Adaptive Model For Sentiment
Classification Using Deep Learning Approach
Vamshi Krishna.B, Dr. Ajeet Kumar Pandey and Dr. Siva Kumar A.P
Abstract: This paper discusses a domain adaptive model for opinion mining and sentiment classification of unstructured text reviews posted in social media site or web forums. The amount of online textual reviews generated in social media websites and blogs is growing exponentially and can source from numerous domains and is difficult to maintain labeled training data for all of them. Model proposed in the paper utilizes deep learning techniques for feature extraction in an unsupervised manner and neural network for sentiment classification of textual reviews. The goal is to build a domain adaptive model which can automatically capture the shared sentiment features across domains.
vectors was used [18]. Neural network model was used for the target dependent sentiment classification by relating the content word with target word in Twitter data set [19]. Sentiment classification model was proposed for Arabic reviews by building CNN which is pretrained using word embeddings [20].
C. Research motivation
As the supervised learning classifier trained on a domain must be retrained if the domain shifts. From the literature it is found neural models for sentiment analysis are used to learn low-dimensional text features without any feature engineering. This paper integrates deep learning techniques with neural network to capture and share sentiment features across domains.
II.
RESEARCH
BACKGROUND
A. Deep LearningDeep learning algorithms have the ability to represent features in most intermediate form in a hierarchical level. Unsupervised learning can be used in each level of hierarchy, for representing features which are based on the features discovered at the previous level. This ability will help to perform transfer features across domains. Neural networks with the ability of text representation learning which can discover a good combination of features continuously without feature engineering and human intervention. Sequences of each word is converted into vector and after multiplying with weight matrix results into a dense and real valued vector. Deep neural networks process this sequence in multiple layers resulting in a prediction probability.
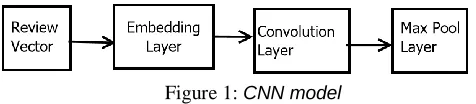
Figure 1: CNN model
B. Convolutional Neural Network (CNN)
CNN is built for the feature extractor with several layers as shown in figure 1, which is used for sentiment classification purpose:
i. Each review is represented as a sequence of vector T (x1, x2, …., xT).
ii. In Embedding layer, continuous vector space Rd with d-dimensional is formed by multiplying each review vector with weight matrix:
W R dV , where V is the unique number of symbols in a vocabulary: et = W Xt. After this input sequence becomes a dense and real valued vectors (e1,e2,…, eT).
iii. In Convolution layer, d’ filters of respective size r , FRd’xr, are applied to the input sequence:
ft = (F[et-(r/2)+1;… ;et;…,et+(r/2]), where is a rectifier and resulting in a sequence
F= (f1,f2, … , fT).
iv. By using max pool of size r’, f’t= max(f(t-1)xr’+1, …,ftxr’) ,
and transformed to F’ = (f’1 ,f’2, … , f’T/r’).
v. Classification layer takes fixed dimensional vector from the lower layers and after transforms using
activation function for computing predictive probabilities.
C. Recurrent Neural Network (RNN)
RNN extracts features by propagating the activation outputs in both direction and have memory to remember patterns. RNN considers the current input and also the previously received inputs for prediction. RNN has one variant Long Short Term Memory (LSTM) which are designed to remember things in the long term. RNN with a separate memory cell and LSTM encoder is used to encode all the information of text. RNN has another variant with gated recurrent unit (GRU) which can learn long term dependencies by using gates. Bidirectional RNN is another variant which connects two hidden layers in opposite direction to the same output. Train two LSTMs, one for the input sequence and another for reverse copy of the input sequence.
Figure 2: RNN model
III.
PROPOSED
WORK
The model architecture is shown in the Figure 2, which uses deep learning techniques for feature extraction in an unsupervised manner and convolution neural network for sentiment classification purpose which is implemented by using Python deep learning libraries Keras and Tensorflow. Few variants of CNN and RNNs are used in building the neural models.
Figure 3: Proposed model architecture
A. Data-set Used
Twitter streaming text data set is used in which recent reviews used for opinion exchange related to various domains are collected. Data set is split into training, testing and validation.
TABLE I. REVIEWS
Total Review
Training
Set Test Set
2554
5000 3000 1000 1000
B. Data Preprocessing
Twitter reviews after filtering retweets are preprocessed by removing stop words, punctations, digits and other special symbols. These cleaned text reviews are split into tokens and converted into integer sequences as neural networks does not recognize text data.
C. Feature Extraction
Text reviews after converting into sequences, very low dimensional features are extracted in a continuous vector space embeddings and multiplied with weight matrix which results into a dense and real valued vector. These features can be reused in other domains as well without feature engineering.
D. Sentiment classification and prediction
Convolutional neural network with several layers and filters are used for classifying the sentiment in the text reviews. Sentiment distribution is predicted by softmax classifier.
E. Model parameter and settings
Below are the model parameters used in building all variants of neural network models for training the feature vectors and predicting sentiment for the validation dataset. Models are trained with Adam optimizer and binary Cross-Entropy loss function using a batch size of size 128, epoch 12. Table 2 shows the model parameters and settings used in CNN model. Five convolutional layers with rectified linear units as an activation function, 128 filters and max pooling size is set to 2. Tables 3, 4 and 5 shows the model parameters and settings used in RNN with LSTM/GRU and bidirectional models. 100 LSTM encoders or gated units with dropout rate and recurrent dropout as 0.2 with tanh activation function are used.
TABLE II. CNN MODEL
Model Parameters Settings
Embedding Size 10000 Convolution Filters 128
Epochs 12 Batch Size 128 Optimization adam
TABLE III. RNN-LSTM MODEL
Model Parameters Settings
Embedding Size 10000 LSTM 100 dropout 0.2 Epochs 12 Batch Size 128 Optimization adam
TABLE IV. RNN-GRU MODEL
Model Parameters Settings
Embedding Size 10000
GRU 100 dropout 0.2 Epochs 12 Batch Size 128 Optimization adam
TABLE V. RNN-BDIR MODEL
Model Parameters Settings
Embedding Size 10000 BDIR LSTM 100
dropout 0.2 Epochs 12 Batch Size 128 Optimization adam
IV.
RESULTS
AND
DISCUSSION
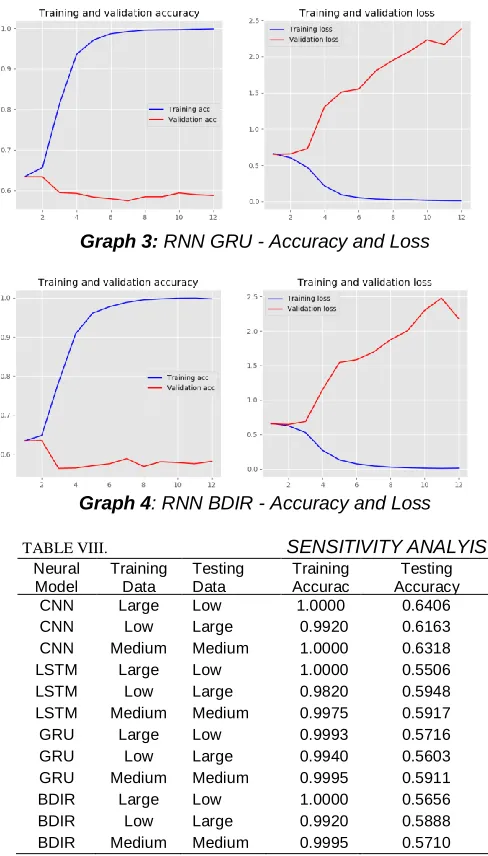
Table 6 shows the results of prediction accuracies from four different trained models and among all of them CNN model has high testing accuracy. Graphs 1, 2, 3 and 4 respectively shows the training and validation accuracies and loss values for all the four neural network models. Table 7 shows the results of sensitivity analysis of data when training, validation and testing data sets are considered as large, medium and low volumes of data respectively.
TABLE VI.
TABLE VII. ACCURACY
Neural Model Training Accuracy
Testing Accuracy
CNN 1.0 0.6406
RNN LSTM 0.9403 0.6206 RNN GRU 0.8007 0.6326 RNN BDIR 1.0 0.5766
Graph 1: CNN - Accuracy and Loss
Graph 2: RNN LSTM - Accuracy and Loss
Graph 3: RNN GRU - Accuracy and Loss
Graph 4: RNN BDIR - Accuracy and Loss
TABLE VIII. SENSITIVITY ANALYIS
Neural Model
Training Data
Testing Data
Training Accurac
y
Testing Accuracy
CNN Large Low 1.0000 0.6406
CNN Low Large 0.9920 0.6163 CNN Medium Medium 1.0000 0.6318 LSTM Large Low 1.0000 0.5506 LSTM Low Large 0.9820 0.5948 LSTM Medium Medium 0.9975 0.5917 GRU Large Low 0.9993 0.5716 GRU Low Large 0.9940 0.5603 GRU Medium Medium 0.9995 0.5911 BDIR Large Low 1.0000 0.5656 BDIR Low Large 0.9920 0.5888 BDIR Medium Medium 0.9995 0.5710
V.
CONCLUSION
A neural model is proposed by extracting general textual features in an unsupervised way using deep learning techniques for sentiment classification of various domain reviews. Also, model is useful to analyze textual reviews which are unstructured and ungrammatical in nature and enhances hidden sentiment prediction. Future work may include pre-trained word embedding model to apply transfer learning.
REFERENCES
[1] John Blitzer , Mark Dredze and Fernando Pereira, ―Biographies, Bollywood, Boom-boxes and Blenders:,‖ in Association of Computational Linguistics, pages 440–447, June 2007.
[2] Sinno Jialin Pan, Xiaochuan Ni, Jian-Tao Sun, Qiang Yang and Zheng Chen, ―Cross-Domain Sentiment Classification via Spectral Feature Alignment,‖ in ACM 2010, pages 751–760.
[3] Xavier Glorot, Antoine Bordes and Yoshua Bengio, ―Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach,‖ in
Proceedings of the 28 th International Conference on Machine Learning, 2011, pages 513–520.
[4] Danushka Bollegala, David Weir and John Carroll, ―Using Multiple Sources to Construct a Sentiment Sensitive Thesaurus for Cross-Domain Sentiment Classification,‖ in Association of Computational Linguistics, pages 132–141, June 2011.
[5] Yulan He ,Chenghua Liny and Harith Alani, ―Automatically Extracting Polarity-Bearing Topics for Cross-Domain Sentiment Classification‖, in Association of Computational Linguistics, pages 123–131, June 2011.
[6] Fangtao Li, Sinno Jialin Pan, Ou Jin, Qiang Yang and Xiaoyan Zhu, ―Cross-Domain Co-Extraction of Sentiment and Topic Lexicons,‖ in Association of Computational Linguistics, pages 410–419, July 2012.
[7] Shoushan Li, Yunxia Xue, Zhongqing Wang and Guodong Zhou, ―Active Learning for Cross-Domain Sentiment Classification,‖ Proceedings of the Twenty-Third international joint conference on Artificial Intelligence Pages 2127-2133, August 2013.
[8] Zhen Hai, Kuiyu Chang, Jung-Jae Kim, and Christopher C. Yang, ―Identifying Features in Opinion Mining via Intrinsic and Extrinsic Domain Relevance‖, IEEE
TRANSACTIONS ON KNOWLEDGE AND DATA
ENGINEERING, VOL. 26, NO. 3, Pages 623-634, MARCH 2014.
[9] Rui Xia , Chengqing Zong, Xuelei Hu and Erik Cambria, ―Feature Ensemble Plus Sample Selection: Domain Adaptation for Sentiment Classification,‖ Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Pages 4229-4233. [10]Zhaopeng Tu, Yifan He, Jennifer Foster, Josef van
Genabith, Qun Liu and Shouxun Lin, ―Identifying High-Impact Sub-Structures for Convolution Kernels in Document-level Sentiment Classification,‖ in Association of Computational Linguistics, pages 338–343, July 2012. [11]Huimin Chen, Maosong Sun, Cunchao Tu, Yankai Lin and
Zhiyuan Liu, ―Neural Sentiment Classification with User and Product Attention,‖ in Association of Computational Linguistics, pages 1650–1659, Nov 2016
[12]Jiacheng Xu, Danlu Chen, Xipeng Qiu and Xuanjing Huang, ―Cached Long Short-Term Memory Neural Networks for Document-Level Sentiment Classification,‖ in Association of Computational Linguistics, pages 1660– 1669, Nov 2016.
[13]Mohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber and Hal Daum, ―Deep Unordered Composition Rivals Syntactic Methods for Text Classification,‖ in Association of Computational Linguistics, pages 1681–1691, July 2015.
[14]Richard Socher, Alex Perelygin, Jean Y. Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng and Christopher Potts, ―Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank‖, in Association of Computational Linguistics, pages 1631– 1642, Oct 2013.
[15]Yijun Xiao and Kyunghyun Cho, ―Efficient Character-level Document Classification by Combining Convolution and Recurrent Layers,‖ in Conf. Rec. 1995 IEEE Int. Conf. Communications, pp. 3–8.
2556
[17]Yi Yang and Jacob Eisenstein, ―Unsupervised Multi-Domain Adaptation with Feature Embeddings,‖ in Association of Computational Linguistics, pages 672–682, June 2015.
[18]Yoon Kim, ―Convolutional Neural Networks for Sentence Classification,‖ in Association of Computational Linguistics, pages 1746–1751, Oct 2014.
[19]Duyu Tang, Bing Qin, Xiaocheng Feng and Ting Liu, ―Effective LSTMs for Target-Dependent Sentiment Classification,‖ in COLING 2016, the 26th International Conference on Computational Linguistics pages 3298– 3307, Dec 2016.