ABSTRACT
LUO, JIAN. Quadratic Surface Support Vector Machines with Applications. (Under the direction of Shu-Cherng Fang.)
©Copyright 2014 by Jian Luo
Quadratic Surface Support Vector Machines with Applications
by Jian Luo
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Industrial Engineering
Raleigh, North Carolina 2014
APPROVED BY:
Russell E. King Yahya Fathi
Yunan Liu Shu-Cherng Fang
DEDICATION
This dissertation is dedicated to my family for their endless love and support: Nenghui Luo, my dear Dad
BIOGRAPHY
ACKNOWLEDGEMENTS
I would like to express my deepest and sincerest gratitude to Dr. Shu-Cherng Fang for guiding me through the Ph.D. study at North Carolina State University. His wisdom, knowledge, personality, patience, and professional guidance were invaluable to me.
I am also thankful to Dr. Russell E. King, Dr. Yahya Fathi and Dr. Yunan Liu for offering valuable comments and suggestions as my committee members. Special thanks to the graduate school representative Dr. Kazufumi Ito for his help in my defense. I am also deeply obliged to Dr. John E. Lavery and Dr. Yanqin Bai for their stimulating advices and kind help in my graduate study.
Thanks to the staff of Industrial and Systems Engineering Department, especially Mrs. Cecilia Chen, Mr. Bill Irwin, Mr. Justin Lancaster and Mr. Hakan Sungur, for their supports and help.
TABLE OF CONTENTS
LIST OF TABLES . . . vii
LIST OF FIGURES . . . viii
Chapter 1 INTRODUCTION . . . 1
1.1 Historic Background of Support Vector Machines . . . 1
1.2 Statement of Problems . . . 2
1.3 Motivations . . . 4
1.4 Outline . . . 7
Chapter 2 LITERATURE REVIEW . . . 8
2.1 Data Classification Methods . . . 8
2.2 Support Vector Machine Models . . . 10
2.3 Fuzzy Support Vector Machine Models . . . 15
2.4 Fisher Discriminant Analysis . . . 16
2.5 Linearly Constrained Quadratic Programming Problems . . . 18
2.6 Decomposition Programming . . . 19
Chapter 3 SOFT QSSVM MODEL . . . 21
3.1 Introduction . . . 21
3.2 Quadratic Surface Support Vector Machine Models . . . 22
3.3 Some Properties of the Soft QSSVM Model . . . 28
3.4 Summary . . . 34
Chapter 4 FUZZY QSSVM MODELS . . . 35
4.1 Introduction . . . 35
4.2 A Specially-designed Fuzzy Membership Function . . . 36
4.2.1 Quadratic Center Surface and Quadratic-margin Distance . . . 36
4.2.2 A New Membership Function . . . 38
4.3 A Fuzzy QSSVM Model based on Fisher Discriminant Analysis . . . 40
4.3.1 A Fuzzy Soft QSSVM Model . . . 41
4.3.2 A Fuzzy QSSVM Model Based on Fisher Discriminant Analysis . 41 4.4 A Decomposition Algorithm . . . 43
4.5 A Fuzzy QSSVM Model Based on Within-class Scatter . . . 47
4.5.1 A Linear Model for Calculating Fuzzy Memberships . . . 47
4.5.2 A Fuzzy QSSVM Model Based on Within-class Scatter . . . 50
Chapter 5 COMPUTATIONAL EXPERIMENTS OF SOFT AND FUZZY
QSSVM MODELS . . . 52
5.1 Artificial and Real-world Benchmark Data Sets . . . 52
5.2 Computational Experiments of Soft QSSVM Model . . . 55
5.2.1 Effectiveness and Efficiency . . . 55
5.2.2 Robustness . . . 58
5.3 Computational Experiments of Fuzzy QSSVM Models . . . 60
5.3.1 Effectiveness and Efficiency . . . 61
5.3.2 Robustness . . . 65
5.4 Summary . . . 68
Chapter 6 EXTENSIONS AND APPLICATIONS OF QSSVM MODELS 70 6.1 Multi-class classification . . . 70
6.2 Credit Scoring Model Based on the QSSVM Models . . . 72
6.2.1 Review of Credit Scoring Models . . . 74
6.2.2 The Fuzzy 2-norm QSSVM Model for Credit Scoring . . . 75
6.2.3 Computational Experiments on German and Australian Credit Data 77 6.3 The Clustering Algorithms Based on the QSSVM Models . . . 79
6.3.1 Introduction to Clustering Algorithms Based on SVM Models . . 80
6.3.2 One-class Quadratic Surface Support Vector Machine Models . . . 81
6.3.3 The Hard Clustering Algorithm Based on the Soft QSSVM Model 84 6.3.4 The Soft Clustering Algorithm Based on the WOC-QSSVM Model 85 6.3.5 Computational Experiments on Iris and Wisconsin Breast Cancer Data . . . 87
6.4 Summary . . . 89
Chapter 7 CONCLUSIONS . . . 91
7.1 Summary of Contributions . . . 91
7.2 Future Research . . . 93
LIST OF TABLES
Table 5.1 Descriptions of Real-world Data Sets . . . 53
Table 5.2 Memory Requirements for All Models . . . 55
Table 5.3 Artificial Data Test . . . 56
Table 5.4 Iris Data Test . . . 57
Table 5.5 Car Evaluation Data Test . . . 58
Table 5.6 Wisconsin Breast Cancer Data Test . . . 59
Table 5.7 Skin Data Test . . . 60
Table 5.8 Artificial training data set with p% outliers . . . 61
Table 5.9 Artificial Data Test . . . 62
Table 5.10 Iris Data Test . . . 63
Table 5.11 Car Evaluation Data Test . . . 64
Table 5.12 Wisconsin Breast Cancer Data Test . . . 65
Table 5.13 Skin Data Test . . . 66
Table 5.14 Artificial training data set with p% outliers . . . 67
Table 6.1 Multi-classed Data Sets . . . 71
Table 6.2 Iris Data Test in Three Classes . . . 72
Table 6.3 Balance Data Test in Three Classes . . . 73
Table 6.4 Credit Data Sets . . . 77
Table 6.5 German Credit Data Test . . . 78
Table 6.6 Australian Credit Data Test . . . 79
Table 6.7 Iris Data Test in Three Classes . . . 88
LIST OF FIGURES
Figure 1.1 A SVM Classifier (an image from [26]) . . . 2
Figure 1.2 A Soft SVM Classifier . . . 3
Figure 1.3 A Soft SVM with Kernel Classifier . . . 4
Figure 1.4 Face Detection Based on SVM (an image from [76]) . . . 5
Figure 1.5 A Kernel-free Nonlinear SVM Model . . . 6
Figure 2.1 The Separating Line . . . 12
Figure 2.2 Fisher Discriminant Analysis . . . 17
Figure 3.1 The Separating Quadratic Curve . . . 24
Figure 4.1 Artificial Data with a Nonconvex Separating Quadratic Curve . . . . 37
Figure 4.2 Affinity Among Training Points . . . 39
Figure 4.3 Fuzzy Memberships of Training Points . . . 40
Figure 5.1 A Second Type Artificial Data Set . . . 53
Figure 5.2 Iris Data . . . 54
Figure 5.3 Skin Data . . . 54
Figure 6.1 Clustering Analysis . . . 80
Chapter 1
INTRODUCTION
Binary classification is an important task in information extraction from data. Support vector machines (SVM) are effective and commonly used classification techniques. As an optimization-based binary classification technique, SVM models are first proposed around 1995 [26, 112]. The basic concept of SVM models is to find a hyperplane that separates the training points into two classes, with a maximum level of separation [113]. The aim of this dissertation is to propose some quadratic surface support vector machine (QSSVM) models for binary classification directly using a quadratic function instead of using a hyperplane. In this dissertation, we first propose a soft QSSVM model and two fuzzy QSSVM models. Then we study the properties of the proposed QSSVM models and conduct computational experiments to investigate their performance. Finally we extend the proposed QSSVM models for multi-class classification, credit scoring and cluster analysis.
1.1
Historic Background of Support Vector Machines
Figure 1.1: A SVM Classifier (an image from [26])
Based on the statistical learning theory and structural risk minimization principal, SVM models had been proposed and largely developed at AT&T Bell Laboratories by Vapnik and co-workers [26, 83, 112]. Due to the industrial requirements, SVM research had a sound orientation towards real-world applications. The initial application of SVM models focused on OCR (optical character recognition). Within a short period of time, SVM classifiers became competitive with the best available systems for OCR and object recognition tasks [84, 85]. A comprehensive tutorial on SVM classifiers was published in [16]. Moreover, in the applications of regression and time series prediction, excellent performances were rapidly obtained [34, 94]. A snapshot of the state of the art of SVM models can be seen in [86]. SVM has evolved into an active research area from 2000.
1.2
Statement of Problems
For binary classification, a training data set ofn records{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,
ˆ
yn)}is given, whereˆxi = [ˆxi
1,xˆi2,· · · ,xˆim]T ∈Rmindicates the position of thei-th training
point in the m-dimensional space, and the label ˆyi = +1 or −1 indicates that point xˆi
belongs to Class C1 or Class C2, respectively. A natural idea is to identify a boundary
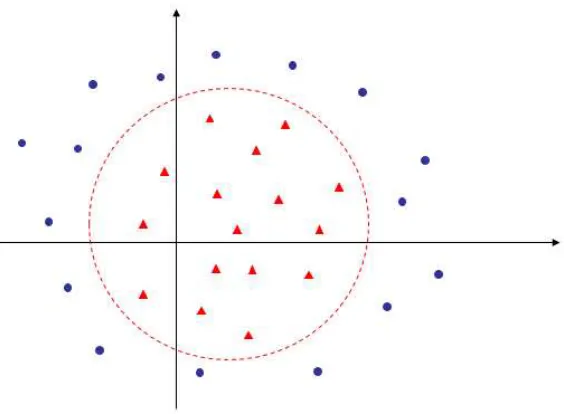
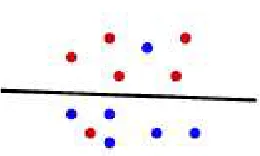
that separates the training points in Class C1 from those in Class C2. For the simple
example of training points in two-dimensional space shown in Figure 1.1, all red circle points with their labels ˆyi = +1 belong to Class C1 while all black circle points with
Figure 1.2: A Soft SVM Classifier
1.1) that breaks the training points into the two classes accordingly.
If the n training points {ˆx1,· · · ,xˆi,· · · ,ˆxn} are separable by a hyperplane, then the SVM model [26, 112] is used to find the parameter vector (u, d)∈Rm+1 of a hyperplane
f(x)≡uTx+d= 0
that separates all training points into Class C1 or Class C2 according to their respective
labels, with a maximum level of separation (see Figure 1.1). Equivalently, the parameter vector (u, d)∈Rm+1 is to be found such that, for each i= 1,· · · , n,
(
uTxˆi+d≥+1, for ˆyi = +1, uTxˆi+d≤ −1, for ˆyi =−1.
In Figure 1.1, after applying the SVM model, the black solid separating line is obtained. For real-world binary classification applications, the obtained training data set is often contaminated with outliers and noises (see Figure 1.2). In these situations, it is possible that no hyperplane can separate all training points into their corresponding classes correctly. To handle this case, a soft SVM model was developed using a continuous measure of misclassification error [26] so that the black separating line in Figure 1.2 is obtained.
However, the soft SVM model does not work well when most points in the training data set are not separable by a hyperplane in the m-dimensional space [29, 113]. Take a simple example shown on the left of Figure 1.3, all blue training points with their labels ˆyi = +1 belong to Class C
1 while all red training points with their labels ˆyi =−1
belong to Class C2. We can see that the training points are not separable by a line, but
separable by a circle. To overcome this difficulty indirectly, each training pointˆxi ∈
Rmis
first mapped into a corresponding pointφ(ˆxi)∈
Figure 1.3: A Soft SVM with Kernel Classifier
function φ(x) :Rm →
Rl. Then, in the l-dimensional space, a soft SVM model with the
kernel [88, 113] is used to seek a hyperplane that separates all mapped training points
{φ(ˆx1),· · · , φ(ˆxi),· · · , φ(ˆxn)}into Class C
1 or Class C2 according to their labels, with a
maximum level of separation. In Figure 1.3, the training points in the two-dimensional space are first mapped into the three-dimensional space, using a nonlinear kernel function. Then a three-dimensional hyperplane (on the right of Figure 1.3) can be found to separate the mapped training points into two classes according to their respective labels.
As a commonly-used machine learning technique [104, 112, 113], soft SVM models with kernels have achieved great success in many real-world applications. One example of applying the soft SVM models with kernels to the face detection [76] is shown in Figure 1.4, where circles represent face patterns and squares represent non-face patterns. Also the face and non-face patterns near the separating curve are shown in Figure 1.4. We can see that some of non-face patterns are very similar to the face patterns.
1.3
Motivations
Figure 1.4: Face Detection Based on SVM (an image from [76])
these two concerns, in this dissertation, we propose some kernel-free nonlinear SVM models which classify the data set directly using a quadratic function for separation.
The proposed kernel-free nonlinear SVM models find the parameter set (W,b, c) of a quadratic surface
g(x)≡ 1
2x
TWx+bTx+c= 0,
whereW =WT =
w11 w12 · · · w1m
w12 w22 · · · w2m
.. .
w1m w2m · · · wmm
∈Rm×m, b=
b1
b2
.. . bm
∈Rm and c∈
R,
that separates the n training points {ˆx1,· · ·,xˆi,· · · ,ˆxn} into Class C
1 or Class C2
Figure 1.5: A Kernel-free Nonlinear SVM Model
convex or nonconvex. Using a simple classification problem in Figure 1.5 as an example, we plan to propose a kernel-free nonlinear SVM model for directly finding the parameters of the red circle, which separates all training points according to their respective labels.
For real-world binary classification applications, the available training data set is often corrupted with noise. Some points in the training data set may even be misplaced in the wrong class by accident. These points are known as outliers. To deal with these outliers and noise, along with incorporating a continuous measure of misclassification error similar to the soft SVM model, we plan to enhance the capability of the proposed kernel-free nonlinear SVM model using the concept of fuzziness, which is characterized by figuring out the relative importance of each training point.
1.4
Outline
Chapter 2
LITERATURE REVIEW
In this chapter, we first review some data classification methods. Related ideas of soft and fuzzy support vector machine (SVM) models for binary classification using a hy-perplane for separation are then reviewed and discussed. Moreover, we review the linear Fisher discriminant analysis (FDA), quadratic FDA and linearly constrained quadratic Programming (LCQP) problems. The ideas of decomposition programming are also in-troduced and discussed.
2.1
Data Classification Methods
SVM models.
A common approach for classifiers is to use decision trees to partition and segment known labeled records [115]. New records can be classified by traversing the tree from the root through branches and nodes, to a leaf representing a class. The path that a record takes through a decision tree can then be represented as a rule. One of the most significant advantages of decision trees is the fact that knowledge can be extracted and represented in the form of classification (if-then) rules. Decision trees are recognized as highly unstable classifiers with respect to minor perturbations in the training data [43].
The most interesting feature of BN [40, 43], compared to decision trees is the pos-sibility of taking into account prior information about a given problem and the simple structure lends itself to comprehensible visualizations. BN can readily handle incomplete data sets and allow one to learn about causal relationships. A major problem of BN classifiers is that they are not suitable for data sets with many features [23]. The reason is that trying to construct a very large network is not feasible in terms of time and space. KNN classifiers [27, 43] are based on learning by analogy. The training samples are described by n dimensional numeric attributes. Each sample represents a point in an n-dimensional space. In this way, all of the training samples are stored in an n-n-dimensional pattern space. Given an unknown sample, a k-nearest neighbor classifier searches the pattern space for the k training samples that are closest to the unknown sample. “Close-ness” is often defined in terms of Euclidean distance. The unknown sample is assigned to the most common class among its k nearest neighbors. The main advantage of the KNN method is the simplicity and no parametric assumptions, while the disadvantage of KNN method is that the time to find the nearest neighbor in a large training set is prohibitive [92].
The classifiers generated by NN [121] are described as complex mathematical func-tions, which are incomprehensible or opaque to humans. NN follows a discriminating rule to classify the data set. Powerful full-data fitting or function approximation makes NN susceptible to over-fitting. Combining several NN may improve their performances [43]. The opacity of NN limits them in many real-life applications where both accuracy and comprehensibility are required, e.g., medical diagnosis and credit risk evaluation [44].
from applications and extensive experimentation to the theory. The key features of SVM models are the absence of local minima, the sparseness of the solution, the use of kernels and the capacity control obtained by maximizing the margin [90]. Classical classifying and learning methods like NN suffer from their theoretical weakness, e.g., back-propagation NN or multilayer perceptron NN usually converges to a local optimal solution, while SVM models can provide a unique solution with some important properties of convexity [97].
2.2
Support Vector Machine Models
In this section, we first review some basic ideas of soft SVM models with kernels for binary classification using a hyperplane for separation. Then some variants and extensions of soft SVM models with kernels are introduced.
For binary classification, a training data set of n records {(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,
(ˆxn,yˆn)} is given, where ˆxi = [ˆxi
1,xˆi2,· · · ,xˆim]T ∈ Rm indicates the position of the i-th
training point in the m-dimensional space, and the label ˆyi = +1 or −1 indicates that
point ˆxi belongs to Class C
1 or Class C2, respectively.
The basic concept of the SVM model is to find the parameter vector (u, d) ∈ Rm+1
of a hyperplane
f(x)≡uTx+d= 0 (1)
that separates the n training points {ˆx1,· · · ,xˆi,· · · ,xˆn} into Class C
1 and Class C2,
with a maximum level of separation [113].
Definition 2.2.1([31]).Consider a training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)},
where xˆi ∈
Rm, yˆi ∈ {+1,−1}, i= 1,· · · , n. If there exists (eu,d)e ∈R
m+1 and a number
> 0 such that, for any i with yˆi = +1, we have
e uTˆxi +
e
d ≥ , and, for any i with
ˆ
yi = −1, we have
e uTˆxi+
e
d ≤ −, then we say the training data set for classification is linearly separable.
Let us start with the linearly separable training data set. From Definition 2.2.1, for the n training points {ˆx1,· · · ,ˆxi,· · · ,xˆn} in two classes, we know
( e
uTˆxi+de≥, for ˆyi = +1
e
Letu = ue
, d=
e
d
, we have
(
uTˆxi+d≥1, for ˆyi = +1 uTˆxi+d≤ −1, for ˆyi =−1
This is equivalent to
( ˆ
yi(uTxˆi+d)≥1 ˆ
yi =±1 (2)
Definition 2.2.2 ([30]). Given a training point ˆxi ∈
Rm, its class label yˆi ∈ {+1,−1}
and a linear function f(x) = uTx+d, where (u, d) ∈
Rm+1, we call βˆi = ˆyif(ˆxi) the
functional margin at point xˆi with respect to the hyperplane f(x) = 0.
Definition 2.2.3. Given a training point xˆi ∈
Rm, its class label yˆi ∈ {+1,−1} and
a linear function f(x) = uTx+d, where (u, d) ∈
Rm+1, the vector ∇f(ˆxi) (= u) is
called the gradient direction at point xˆi with respect to the hyperplane f(x) = f(ˆxi). If
ˆ
yi = +1 (or −1), the negative (or positive) gradient direction −u (or u) is called the related gradient direction at point ˆxi with respect to the hyperplane f(x) = f(ˆxi).
Definition 2.2.4 ([30]). Given a training point ˆxi ∈
Rm, its class label yˆi ∈ {+1,−1}
and a linear function f(x) =uTx+d, where (u, d)∈
Rm+1, the related gradient direction
at pointˆxi with respect to the hyperplane f(x) =f(ˆxi)intercepts the hyperplane f(x) = 0
at a point ˆxB. The length of the segment ˆxiˆxB, denoted as β
i, is called the geometrical
margin at point ˆxi with respect to the hyperplane f(x) = 0.
Definition 2.2.5. Given a training point xˆi ∈
Rm, its class label yˆi ∈ {+1,−1} and a
linear function f(x) = uTx+d, where (u, d) ∈ Rm+1, the related gradient direction at
point ˆxi with respect to the hyperplane f(x) =f(ˆxi) intercepts the hyperplanef(x) = +1
(or−1) at a pointˆxi. The length of the segmentˆxixˆB, denoted asβ¯
i, is called the relative
geometrical margin at the point ˆxi with respect to the hyperplane f(x) = 0.
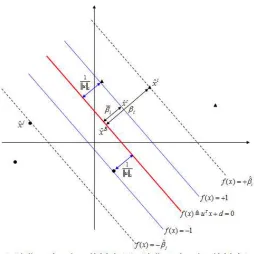
Figure 2.1 illustrates ˆxi, xˆi, xˆB, ˆβ
i, βi and ¯βi for m = 2. In this figure, the red line
is the separating line of the two classes. In Dagher’s paper [30], the relationship between the functional and geometrical margin at a training pointxˆi is given byβ
i =
ˆ
βi
kuk2. Also,
Figure 2.1: The Separating Line
margin. Then, at pointˆxi, ¯βi =kˆxB−ˆxik2 = ku1k
2. The objective of the SVM model then
be restated as “to maximize the sum of the relative geometrical margins at all training points with respect to a hyperplane f(x) = 0 subject to the condition that each training point has a no less than 1 functional margin”. (see Figure 2.1, where the distance between the two blue lines is maximized subject to the condition that no training point exists between the two blue lines.)
For a linearly separable training data set {(ˆx1,yˆ1),· · · ,(ˆxn,yˆn)}, we then consider
the following optimization problem:
max n
kuk2
s.t. yˆi(uTˆxi+d)≥1, i= 1,2,· · · , n, (u, d)∈Rm+1.
SVM model becomes
min nkuk22
s.t. yˆi(uTˆxi+d)≥1, i= 1,2,· · · , n, (u, d)∈Rm+1.
This problem is equivalent to the following optimization problem [12]:
min 1
2kuk
2 2
s.t. yˆi(uTˆxi+d)≥1, i= 1,2,· · · , n, (SVM) (u, d)∈Rm+1.
However, the training data set is not linearly separable in general. Different slack tech-niques are used to relax the constraints in the model (SVM) for developing soft SVM models [26]. The commonly used soft SVM model is to add a slack variable ξi ≥ 0 for
each constraint in the model (SVM) and a number ˆη > 0 as the penalty value for each ξi in the objective function. Then we have the following soft SVM model [26]:
min 1
2kuk
2 2+ ˆη
n
X
i=1
ξi
s.t. yˆi(uTˆxi+d)≥1−ξi, i= 1,2,· · · , n, (SSVM)
(u, d)∈Rm+1, ξ
i ≥0, i= 1,2,· · · , n.
However, the soft SVM model does not work well when the training data set is not separable by a hyperplane but separable by a nonlinear surface in the m-dimensional space [29, 113]. To overcome this difficulty indirectly, each training point ˆxi ∈
Rm is first
mapped into a corresponding point φ(ˆxi) ∈ Rl, where m ≤ l, using a nonlinear kernel
function φ(x) :Rm →Rl. Then, in the l-dimensional space, a soft SVM model with the
mapped training points into ClassC1 and ClassC2, with a maximum level of separation.
min 1
2kvk
2 2+ ˆη
n
X
i=1
ξi
s.t. yˆi(vTφ(ˆxi) +d)≥1−ξi, i= 1,2,· · · , n, (KSSVM)
(v, d)∈Rl+1, ξ
i ≥0, i= 1,2,· · · , n.
Then Lagrangian duality theory is applied to formulate the dual of model (KSSVM). The associated Lagrangian function is
L(v, d, ξ, α, β) = 1 2v
Tv+ ˆη n
X
i=1
ξi− n
X
i=1
αi(ˆyi(vTφ(ˆxi) +d)−1 +ξi)− n
X
i=1
βiξi,
αi ≥0, βi ≥0, i= 1,· · · , n.
And the Lagrangian dual function is defined as
l(α, β) = min
v,d,ξL(v, d, ξ, α, β).
Notice that, L(v, d, ξ, α, β) is a strictly convex function with respect to v, d and ξ. Therefore, in order to minimize L(v, d, ξ, α, β), we set
∂L(v, d, ξ, α, β)
∂v = 0⇒v=
n
X
i=1
αiyˆiφ(ˆxi),
∂L(v, d, ξ, α, β)
∂d = 0⇒
n
X
i=1
αiyˆi = 0,
∂L(v, d, ξ, α, β) ∂ξi
= 0⇒αi+βi = ˆη.
Also, with respect to a kernel function φ(x), a kernel for two training points ˆxi and ˆxj is defined as K(ˆxi,xˆj) = φ(ˆxi)Tφ(ˆxj). By eliminating the variables β
Lagrangian dual function becomes l(α) = n X i=1
αi−
1 2 n X i=1 n X j=1
αiαjyˆiyˆjK(ˆxi,ˆxj), if n
X
i=1
αiyˆi = 0 & 0≤αi ≤η, iˆ = 1,· · · , n,
− ∞, otherwise.
Then the dual problem of problem (KSSVM) is formulated as
min 1 2 n X i=1 n X j=1
αiαjyˆiyˆjK(ˆxi,xˆj)− n X i=1 αi s.t. n X i=1
αiyˆi = 0 (DKSSVM)
0≤αi ≤η, iˆ = 1,· · ·, n.
Moreover, some well-known kernels are
Gaussian kernel K(ˆxi,ˆxj) =exp(−kˆx
i −xˆjk2 2
2σ2 ),
Quadratic kernel K(ˆxi,ˆxj) = (a+ (ˆxi)Txˆj)2.
The formulations of soft SVM models with kernels are discussed in [62] from an optimization point of view. Furthermore, to perfom the binary classification, some major variants of soft SVM models with kernels are developed. The list includes fuzzy SVM models with kernels [55, 61], least squares SVM models with kernels [24, 56, 96], proximal SVM models with kernels [42, 68], v-SVM models with kernels [18, 87] and twin SVM models with kernels [60, 68, 89]. Moreover, the soft SVM models with kernels for binary classification have been extended to multi-class classification [28, 53, 64], imbalanced classification [101], semisupervised classification [20, 33], robust classification [47] and privileged classification [78, 114].
2.3
Fuzzy Support Vector Machine Models
and its class center in the original space. Then a fuzzy membership ˆri for each training
point ˆxi is calculated with δ≤rˆi ≤1 for i= 1,2,· · · , n, where a sufficiently smallδ >0
is given. Moreover, for any given training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}, a
fuzzy SVM model with a kernel [61] is formulated as
min 1
2kvk
2 2+ ˆη
n
X
i=1
ˆ riξi
s.t. yˆi(vTφ(ˆxi) +d)≥1−ξi, i= 1,2,· · · , n, (KFSVM)
(v, d)∈Rl+1, ξ
i ≥0, i= 1,2,· · · , n,
where φ(x) : Rm → Rl is a nonlinear kernel function. The penalty constant ˆη needs to
be chosen beforehand for the tradeoff between the classification margin 12kvk2
2 and the
cost of misclassification errorPn
i=1rˆ
iξ
i. The non-negative slack variableξi is a measure of
misclassification error in the fuzzy SVM model with a kernel and the fuzzy membership ˆ
ri is the “attitude” of the training point ˆxi toward its corresponding class. Then the
term ˆriξ
i can be deemed as a measure of misclassification error with the weight ˆri. If the
training point ˆxi (such as an outlier or noise) is less important, then the corresponding
smaller ˆri may reduce the effect of parameter ξi in problem (KFSVM).
By introducing two memberships for each training point, Wang [107] proposed a bilateral-weighted fuzzy SVM model with a kernel, which is further extended in [51] based on the vague sets. Abe and Inoue [1] presented fuzzy SVM models with kernels for the multi-class problem, which is an extension of the binary classification problem for multi-class text categorization [106]. The fuzzy support vector regression was also raised in [95].
2.4
Fisher Discriminant Analysis
In this section, we first review the basic idea of linear FDA with an example, then the kernel FDA is reviewed.
Linear FDA [39, 41] is prevalent in pattern recognition. Linear FDA seeks to re-duce dimensionality while preserving as much of the class discriminatory information as possible [41]. For binary classification of the training data set {(ˆxi,yˆi), i = 1,· · · , n},
where point ˆxi ∈
Figure 2.2: Fisher Discriminant Analysis
C1 or Class C2, respectively, linear FDA maps all training points {ˆxi, i = 1,· · · , n} to
points {fd(ˆxi), i = 1,· · · , n} on the real axis by a linear function fd(x) = udTx, where
ud ∈ Rm. Let A1 , {fd(ˆxj)|yˆj = +1, j = 1,· · · , n} and A2 , {fd(ˆxj)|yˆj = −1, j =
1,· · · , n}. Assume the number of elements in A1 and A2 as n1 and n2, respectively.
Then, the mean values of elements in sets A1 and A2 are n11
P
j:ˆyj=+1fd(ˆxj) , δ1 and 1
n2
P
j:ˆyj=−1fd(ˆxj) , δ2, respectively. And the variances of elements in sets A1 and A2
are n1
1
P
j:ˆyj=+1(fd(ˆxj)−δ1)2 ,σ21 and n12
P
j:ˆyj=−1(fd(ˆxj)−δ2)2 ,σ22, respectively. Then
the prior probability distributions of mapped points (i.e., fd(ˆxi), i = 1,· · · , n) in the
two classes can be approximated byN(δ1, σ12) andN(δ2, σ22), respectively, whereN(δ, σ2)
indicates a normal distribution with meanδ and varianceσ2. To increase the separability
betweenA1 andA2, we could decrease the Bayes error (the probability of a
misclassifica-tion), i.e., increase|δ1−δ2|(called the “between-class scatter” of mapped points in [39])
and decrease σ2
1+σ22 (called the “within-class scatter” of mapped points in [39]).
The main idea of linear FDA [39] is to find the parameter set ud ∈ Rm of a linear
mapping fd(x) = udTx which maximizes the between-class scatter and minimizes the
within-class scatter of mapped points (i.e., fd(ˆxi), i = 1,· · · , n) to separate Class C1
from Class C2. Take the classifying problem in Figure 2.2 as an example, where the blue
However, the linear classification capability of linear FDA has greatly affected its applications. The kernel FDA [10, 73] is first proposed by Mika. Like SVM, kernel FDA first maps the training points to the points in some higher dimensional feature space using a nonlinear kernel function, and then performs linear FDA in this feature space. As one of the standard nonlinear techniques in statistical analysis, kernel FDA exhibits eminent nonlinear discriminant ability.
2.5
Linearly Constrained Quadratic Programming
Problems
In this section, convex and nonconvex LCQP problems are both reviewed. In general, a quadratic programming problem with linear constraints has the following form:
min tTQt+fTt
s.t. (ˆdi)Tt−ˆbi ≥0, i= 1,· · ·, q, (LCQP)
t∈R˜l.
where Q is an ˜lטl real symmetric matrix, f ∈ R˜l, ˆdi ∈
R˜l and ˆbi ∈ R, i = 1,· · · , q.
We commonly assume that problem (LCQP) has a nonempty feasible domain and its objective function is bounded from below over the feasible set. This problem is called the linearly constrained quadratic programming problem in the literature [2, 75, 117].
If the matrix Q is positive semidefinite, then problem (LCQP) is a convex problem with the following global optimality condition:
Theorem 2.5.1. For an LCQP problem, if Q is positive semidefinite, then a feasible solution t∗ is optimal if and only if there exist real numbersα∗1,· · · , α∗q such that
(
Qt∗+f −α∗1ˆd1− · · · −α∗qdˆq =0,
α∗i((dˆi)Tt∗−ˆbi) = 0, α∗i ≥0,∀i= 1,· · ·, q,
where 0= (0,· · · ,0)T ∈R˜l.
such as the interior-point algorithm [105], active-set algorithm [25] and trust-region-reflective algorithm [25].
If the matrix Q is indefinite, solving (LCQP) is in general NP-hard [77]. Branch-and-bound techniques are often used to find a global optimizer of problem (LCQP). For example, Sherali and Tuncbilek [91] used the “reformulation convexification technique” to derive lower and upper bounds of the problem and partition the bounded polyhedral do-main into subsets through branching. Barrientos and Correa [9] used the same branching idea but adopt the Lagrangian duality to provide lower bounds. Burer and Vandenbuss-che [15] used a semi-definite programming relaxation technique to provide bounds and enforced the first order Karush-Kuhn-Tucker (KKT) condition through branching. More-over, Xing et al. [117] developed an iterative scheme for solving LCQP problems based on the canonical duality theory. They first perturbed the feasible domain by a quadratic con-straint, and then solved a “restricted” canonical dual program of the perturbed problem at each iteration to generate a sequence of feasible solutions of the original problem. The generated sequence was proven to be convergent to a KKT point (local minimizer) with a strictly decreasing objective value. Also, since the indefinite matrix Q can be written as the difference of two positive semidefinite matrix [3], i.e.,Q= ˆQ−Q˜ (where ˆQand ˜Q are two positive semidefinite matrices), then the objective function in problem (LCQP) is the difference of two convex functions, i.e., tTQtˆ +fTt and tTQt. Consequently, the˜ technique of decomposition algorithm (DCA) [3, 4, 5], reviewed in the next section, could provide a good solution (local minimizer) to the LCQP problem.
2.6
Decomposition Programming
In this section, the general ideas of decomposition programming [3, 4, 5] are reviewed and summarized. Denote Γ0(Rl) as the convex cone of all lower semicontinuous proper
convex functions on Rl. For any lower semi-continuous function U(x), denote domU(x) as the domain of the function U(x), and∂U(¯x) stands for the subdifferential of U(x) at point ¯x, i.e., ∂U(¯x) , {¯y ∈ domU(x) : U(x) ≥ U(¯x) + (x−¯x)T¯y, ∀ x ∈ domU(x)}.
Let N be the set of non-negative integers. Consider the following decomposition (DC) program
κ = min
with G(x), H(x) ∈ Γ0(Rl). Furthermore, E(y) , supx{xTy−G(x)} for y ∈ Rl, is
defined as the conjugate function of G(x). Then, to solve the problem (DC), the gen-eral DCA constructs two sequences {xk} and {yk} according to the expressions yk−1 ∈
∂H(xk−1) and xk ∈ ∂E(yk−1) for k ∈ N. The major results of the general DCA on
problem (DC) are summarized as follows.
Lemma 2.6.1 ([5]). For unconstrained problem (DC) with an objective functionG(x)−
H(x), where G(x), H(x)∈Γ0(Rl), it holds for the general DCA that
(a) The sequence {G(xk)−H(xk)}k∈N is monotonically decreasing.
(b) If the optimal value κ of problem (DC) is finite and the sequences {xk}
k∈N and
{yk}
k∈N are bounded, then every limit point ex of the sequence {x
k}
k∈N satisfies that
∂G(ex)∩∂H(ex)6=∅.
(c) Given a point x∗, if ∂G(x∗)∩∂H(x∗) 6= ∅ and H(x) is differentiable at point x∗, then point x∗ is a local minimizer of problem (DC).
Chapter 3
SOFT QSSVM MODEL
In this chapter, we propose a kernel-free soft quadratic surface support vector machine model for binary classification directly using a quadratic function for separation. Prop-erties such as solvability and uniqueness of solution of the proposed soft QSSVM model are derived.
3.1
Introduction
The soft support vector machine (SVM) models with kernels are important classification and pattern recognition techniques based on structural risk minimization. Some well-known kernels are the Gaussian kernel, Quadratic kernel and Polynomial kernel [113]. However, there is no universal rule to automatically choose a suitable kernel for any given dataset. Moreover, how well a soft SVM model with a kernel works depends heavily on the parameter set in the kernel. To resolve these two concerns, the objective of this chapter is to propose a kernel-free nonlinear SVM model which can classify the dataset directly using a quadratic function for separation. The development follows the logic of the soft SVM models, which are reviewed in Section 2.2.
and real-world benchmark data sets to show that the new model indeed outperforms Dagher’s QSVM model and soft SVM models with Gaussian or Quadratic kernel.
The rest of this chapter is arranged as follows: A new kernel-free nonlinear SVM model is proposed in Section 3.2. Some properties of the proposed model are derived from the optimization point of view in Section 3.3. At last, the summary of this chapter is provided in Section 3.4.
3.2
Quadratic Surface Support Vector Machine
Mod-els
In this section, a quadratic surface is directly used to separate the training data set into two classes instead of using a hyperplane. A soft QSSVM model is developed in a parallel procedure of developing the soft SVM model.
For binary classification of the training data set {(ˆxi,yˆi), i = 1,· · ·, n}, where point
ˆ
xi = [ˆxi1,xˆi2,· · · ,xˆim]T ∈ Rm indicates the position of the i-th training point in the
m-dimensional space, the label ˆyi = +1 or −1 indicates that point ˆxi belongs to Class C1 ,{xˆj|yˆj = +1, j = 1,· · · , n} or Class C2 , {ˆxj|yˆj =−1, j = 1,· · ·, n}, respectively.
Denote the number of elements inC1 andC2 asn1 andn2, respectively, thenn1+n2 =n.
The proposed QSSVM model intends to find the parameter set (W,b, c) of a quadratic surface
g(x)≡ 1
2x
TWx+bTx+c= 0, (3)
whereW =WT =
w11 w12 · · · w1m
w12 w22 · · · w2m
.. .
w1m w2m · · · wmm
∈Rm×m, b=
b1 b2 .. . bm
∈Rm and c∈
R,
that separates the n training points {ˆx1,· · · ,xˆi,· · · ,ˆxn} into two classes, with a
maxi-mum level of separation.
Definition 3.2.1. Consider a training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}, where
ˆ xi ∈
Rm, yˆi ∈ {+1,−1}, i = 1,· · · , n. If there exist Wf = fWT ∈ Rm×m, (eb, e
and a number >0 such that, for any i with yˆi = 1, we have 12(ˆxi)TfWxˆi+beTxˆi+ec≥,
and, for any i with yˆi = −1, we have 1 2(ˆx
i)T
f Wˆxi +
e bTˆxi +
e
c ≤ −, then we say the training data set for classification is quadratically separable.
First, let us deal with the quadratically separable training data set. From Definition 3.2.1, for the n training points {xˆ1,· · · ,ˆxi,· · · ,ˆxn} in two classes, we know
1 2(ˆx
i)T
f
Wxˆi+ebTˆxi+ e
c≥, for ˆyi = +1, 1
2(ˆx
i)T
f
Wxˆi+ebTˆxi+ e
c≤ −, for ˆyi =−1.
LetW = fW
,b=
e
b
, c= e c
, then we have
1 2(ˆx
i
)TWxˆi+uTxˆi +c≥1, for ˆyi = +1, 1
2(ˆx
i
)TWxˆi+uTˆxi +c≤ −1, for ˆyi =−1.
This is equivalent to
ˆ yi(1
2(ˆx
i)TWˆxi+uTˆxi+c)≥1,
ˆ
yi =±1.
(4)
Definition 3.2.2 ([30]). Given a training point ˆxi ∈
Rm, its class label yˆi ∈ {+1,−1}
and a quadratic function g(x) = 12xTWx+bTx+c, where W = WT ∈
Rm×m and
(b, c) ∈ Rm+1, we call γˆ
i = ˆyig(ˆxi) the functional margin at point xˆi with respect to the
quadratic surface g(x) = 0.
Definition 3.2.3. Given a training point xˆi ∈
Rm, its class label yˆi ∈ {+1,−1} and a
quadratic functiong(x) = 12xTWx+bTx+c, whereW =WT ∈Rm×m and(b, c)∈
Rm+1,
the vector ∇g(ˆxi) (= Wˆxi +b) is called the gradient direction at point xˆi with respect to the quadratic surface g(x) = g(ˆxi). If yˆi = +1 (or −1), the negative (or positive) gradient direction −∇g(ˆxi) (or ∇g(ˆxi)) is called the related gradient direction at point
ˆ
xi with respect to the quadratic surface g(x) = g(ˆxi).
Definition 3.2.4 ([30]). Given a training point ˆxi ∈
Rm, its class label yˆi ∈ {+1,−1}
and a quadratic function g(x) = 12xTWx+bTx+c, where W = WT ∈
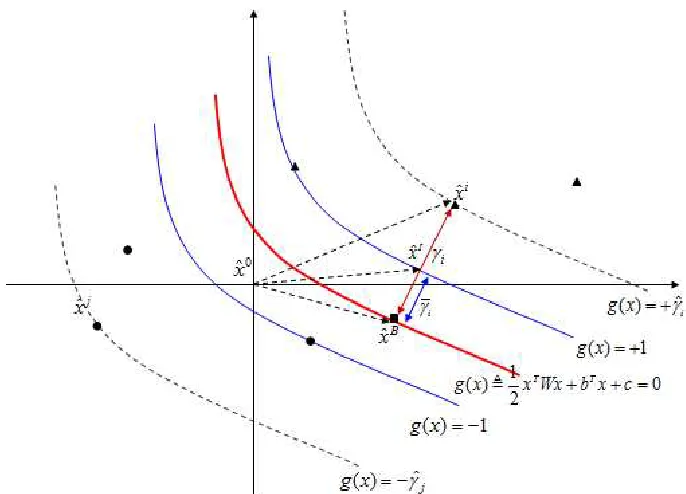
Figure 3.1: The Separating Quadratic Curve
(b, c) ∈ Rm+1, the related gradient direction at point xˆi with respect to the quadratic
surface g(x) =g(ˆxi) intercepts the quadratic surface g(x) = 0 at a point xˆB. The length of the segment ˆxixˆB, denoted as γ
i, is called the geometrical margin at point ˆxi with
respect to the quadratic surface g(x) = 0.
Definition 3.2.5. Given a training point xˆi ∈
Rm, its class label yˆi ∈ {+1,−1} and a
quadratic functiong(x) = 12xTWx+bTx+c, whereW =WT ∈
Rm×m and(b, c)∈Rm+1,
the related gradient direction at pointˆxi with respect to the quadratic surfaceg(x) = g(ˆxi)
intercepts the surface g(x) = +1 (or −1) at a point ˆxi. The length of the segment ˆxiˆxB,
denoted as γ¯i, is called the relative geometrical margin at the point xˆi with respect to the
quadratic surface g(x) = 0.
Figure 3.1 illustrates the ˆxi,ˆxi,xˆB, ˆγ
i,γi and ¯γi form= 2, where g(x) = 0 is the red
separating quadratic curve. Expression (4) can deduct that ˆγi = ˆyig(ˆxi)≥1, i= 1,· · · , n,
which indicates that each training point has a no-less-than one functional margin. Moreover, the relative geometrical margin ¯γi at the pointˆxi can be approximated as
ThusˆxB =ˆxi−γ¯ i
∇g(ˆxi) k∇g(ˆxi)k
2. Taylor’s expansion says thatg(ˆx
B)≈g(ˆxi)+∇g(ˆxi)T(ˆxB−ˆxi).
Noting that g(ˆxB) = 0 and g(ˆxi) = 1, we have ¯γi ≈ k∇g(ˆx
i)k
2
∇g(ˆxi)T∇g(ˆxi). Similarly, g(ˆxi)≈g(ˆxi) +∇g(ˆxi)T(ˆxi−ˆxi)
g(ˆxi)≈g(ˆxi) +∇g(ˆxi)T(ˆxi−ˆxi)
andxˆi−ˆxi =− γi−γ¯i k∇g(ˆxi)k
2∇g(ˆx
i), which is inferred by−−→ˆx0ˆxi−−−→ˆx0ˆxi =−−→ˆxiˆxi. Hence∇g(ˆxi)T∇g
(ˆxi) ≈ ∇g(ˆxi)T∇g(ˆxi). Consequently, at point xˆi, ¯γ
i = kˆxB −xˆik2 ≈
k∇g(ˆxi)k2
∇g(ˆxi)T∇g(ˆxi) ≈
1
k∇g(ˆxi)k
2 =
1
kWxˆi+bk
2. Note that, in general, ¯γi 6= ¯γj for ˆx
i 6=ˆxj. This situation is different
from that in the SVM model.
The objective of the QSSVM model can be stated as “to maximize the sum of the rela-tive geometrical margins at all training points with respect to a quadratic surfaceg(x) = 0 subject to the condition that each training point has a no-less-than one functional mar-gin”(See Figure 3.1, where the distance between the two blue curves is maximized subject to the condition that no training point exists between the two blue curves.).
For a quadratically separable training data set {(ˆx1,yˆ1),· · · ,(ˆxn,yˆn)}, we first
max-imize the relative geometrical margin of a training point xˆi with respect to a quadratic
surface g(x) = 0 subject to the condition that each training point has a no-less-than one functional margin, which can be formulated as
max 1
kWxˆi+bk
2
s.t. yˆi(1 2(ˆx
i)TWxˆi+bTˆxi+c)≥1, i= 1,· · · , n,
W =WT ∈Rm×m, (b, c)∈
Rm+1,
excluding the trivial case of kWˆxi+bk
2 = 0. This problem is equivalent to
min kWˆxi+bk2 2
s.t. yˆi(1 2(ˆx
i)TWˆxi+bTˆxi+c)≥1, i= 1,· · ·, n,
W =WT ∈Rm×m, (b, c)∈
Forn training points, we may consider the following aggregated model:
min
n
X
i=1
kWˆxi+bk2 2
s.t. yˆi(1 2(ˆx
i)TWˆxi+bTˆxi+c)≥1, i= 1,· · ·, n, (QSSVM)
W =WT ∈Rm×m, (b, c)∈
Rm+1.
However, if the training data set is not quadratically separable, for a separating quadratic surfaceg(x) = 0, one of the following two situations would occur for some training points:
Situation 1 : for point ˆxi,yˆi =−1, but 1 2(ˆx
i)TWˆxi+bTˆxi+c > −1,
Situation 2 : for point ˆxj,yˆj = +1, but 1 2(ˆx
j)TWˆxj+bTˆxj +c <1.
These points are referred to as the outliers of the data set with respect to the quadratic surface g(x) = 0. In this case, the proposed model (QSSVM) would become infeasible, since no quadratic surface can separate all training points into their corresponding classes correctly. To take care of this situation, similar to the development of the soft SVM model, we add a slack variableξi ≥0 for each constraint in the model (QSSVM) and a number
ˆ
η > 0 as the penalty value for each ξi in the objective function. Then we consider the
following soft QSSVM model:
min
n
X
i=1
kWxˆi+bk2 2+ ˆη
n
X
i=1
ξi
s.t. yˆi(1 2(ˆx
i
)TWxˆi+bTˆxi +c)≥1−ξi, i= 1,· · · , n, (SQSSVM)
W =WT ∈Rm×m, (b, c)∈Rm+1, ξi ≥0, i= 1,· · · , n.
Notice that in models (QSSVM) and (SQSSVM), the matrixW is symmetric. To simplify these two models, we may convert each of them into an equivalent form as follows. First, let ¯W be the vector formed by taking the m22+m elements of the upper triangle part of the matrix W, i.e.,
¯
W =hw11 w12 · · · w1m w22 w23 · · · w2m · · · wmm
iT
Then, construct anm×(m2+m
2 ) matrixM
ifor the training pointxˆi = [ˆxi
1,xˆi2,· · ·,xˆim]T ∈
Rm as follows. For thej-th row of Mi in R
m2+m
2 , j = 1,· · · , m, check the elements of ¯W
one by one. If the p-th element of ¯W is wjk or wkj for some k= 1,2,· · · , m, then assign
the p-th element of thej-th row of Mi to be ˆxi
k. Otherwise, assign it to be 0.
Takem = 3 as an example:
W =
w11 w12 w13
w12 w22 w23
w13 w23 w33
⇒ W¯ = h
w11 w12 w13 w22 w23 w33
iT
⇒Mi = ˆ
xi1 xˆi2 xˆi3 0 0 0 0 xˆi1 0 xˆi2 xˆi3 0 0 0 xˆi1 0 xˆi2 xˆi3
Also let matrixHi = h
Mi, Ii∈
Rm×(
m2+m
2 +m), i= 1,· · · , n, whereI is them-dimensional
identity matrix. Then, define the vector of variables z= "
¯ W
b #
∈Rm2+32 m and the vector
ˆsi =[1 2xˆ
i
1xˆ
i
1,· · · ,xˆ
i
1xˆ
i m,
1 2xˆ
i
2xˆ
i
2,· · · ,xˆ
i
2xˆ
i m,· · · ,
1 2xˆ
i m−1xˆ
i m−1,xˆ
i m−1xˆ
i m,
1 2xˆ
i mxˆ
i m,
ˆ
xi1, ,xˆi2,· · · ,xˆim]∈R(m+1)2 m+m.
The objective of model (QSSVM) becomes
Pn
i=1kWˆx
i+bk2 2 =
Pn
i=1kH
izk2 2 =
Pn
i=1(H
iz)T(Hiz)
=Pn
i=1zT(Hi)THiz=zT(
Pn
i=1(Hi)THi)z.
Let G=Pn
i=1(Hi)THi ∈R
(m2+32 m)×(m2+32 m), then the model (QSSVM) becomes
min zTGz
Similarly, the model (SQSSVM) can be reformulated as
min zTGz+ ˆη
n
X
i=1
ξi
s.t. yˆi((ˆsi)Tz+c)≥1−ξi, i= 1,· · · , n, (SQSSVM0)
(z, c)∈Rm2+32 m+1, ξi ≥0, i= 1,· · · , n.
This kernel-free soft QSSVM model is proposed for binary classification directly using a quadratic function to separate the data set. Notice that G is positive semidefinite since zTGz=zT Pn
i=1(H
i)THiz= Pn
i=1kH
izk2
2 ≥ 0 for any z∈ R
m2+3m
2 . Consequently,
both of models (QSSVM0) and (SQSSVM0) are convex linearly constrained quadratic programming (LCQP) problems [36].
3.3
Some Properties of the Soft QSSVM Model
In this section, we study some properties of the model (SQSSVM0). For any given training data set {(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)} and ˆη > 0, the solvability of the model
(SQSSVM0) is studied in the next result.
Theorem 3.3.1. For any given training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}and
ˆ
η > 0, there exists an optimal solution to the model (SQSSVM0) with a finite objective value.
Proof. Take arbitrary (˜z,˜c)∈Rm2+32m+2 and let
˜
ξi = max{0,1−yˆi((ˆsi)T˜z+ ˜c)}, i= 1,· · · , n.
It is easy to see that (˜z,˜c,ξ) is feasible to the model (SQSSVM˜ 0). Notice that the objective function is continuous and the feasible domain is a closed convex set defined by linear inequalities. Moreover, for any z∈Rm2+32 m and ξi ≥0, i= 1,· · · , n,zTGz+ ˆηPn
i=1ξi =
Pn
i=1(kHizk22+ ˆηξi) ≥ 0, which indicates that the objective value is bounded below by
0 over the feasible domain. Hence there must exist an optimal solution with a finite objective value.
the next result states the relationship between the optimal solutions of models (QSSVM0) and (SQSSVM0).
Theorem 3.3.2. For any given η >ˆ 0, let (zˆη, cˆη,ξηˆ) be an optimal solution of model
(SQSSVM0) and assume that the sequence {(zηˆ, cηˆ,ξηˆ)} converges to (z∗, c∗,ξ∗) as ηˆ→
∞. If the training data set is quadratically separable, thenξ∗ =0(where0= (0,· · · ,0)T ∈
Rn) and (z∗, c∗) is an optimal solution of model (QSSVM0).
Proof. When the training data set is quadratically separable, it is not difficult to see that there exists a feasible solution (ˆz,ˆc,0) to the model (SQSSVM0) with a given ˆη >0. We first prove that Pn
i=1ξ ˆ
η
i → 0 as ˆη → ∞ by contradiction. Suppose that there exists a
givenδ >0 such that for any ˆη ≥ηˆ∗ , ˆzTGδˆz+1 >0, we have|Pn
i=1ξ ˆ
η
i −0|=
Pn
i=1ξ ˆ
η i ≥δ.
Then, for the optimal solution (zηˆ, cηˆ,ξηˆ) of model (SQSSVM0) with any given ˆη ≥ ηˆ∗, we have
zη Tˆ Gzηˆ+ ˆη
n
X
i=1
ξiηˆ ≥0 + ˆη∗δ= 0 +ˆzTGˆz+ 1>ˆzTGˆz+ 0
sinceGis positive semidefinite. Therefore, for any given ˆη ≥ηˆ∗, (zηˆ, cηˆ,ξηˆ) can not be an
optimal solution because (ˆz,c,ˆ 0) is feasible to the model (SQSSVM0). This contradiction leads to that Pn
i=1ξ ˆ
η
i →0 as ˆη→ ∞. Consequently, ξηˆ →ξ
∗ =0 as ˆη → ∞.
Next, we prove that (z∗, c∗) is an optimal solution to model (QSSVM0). Since (zηˆ, cηˆ,ξηˆ)
is feasible to the model (SQSSVM0) for all ˆη >0 and the linear constraints are in a closed form, we have {(zηˆ, cηˆ,ξηˆ)} converges to (z∗, c∗,0) as ˆη→ ∞, and
ˆ
yi((ˆsi)Tz∗+c∗)≥1, i= 1,· · · , n.
Hence (z∗, c∗) is feasible to model (QSSVM0). Moreover, let (¯z,¯c) be an optimal solution to model (QSSVM0). Then (¯z,¯c,0) is feasible to model (SQSSVM0). Consequently, we have
zη Tˆ Gzηˆ+ ˆη
n
X
i=1
ξiηˆ ≤¯zTG¯z+ 0.
Let ˆη → ∞and assume that 0∗ ∞= 0 without loss of generality, then we havez∗TGz∗ ≤
Let F∗ = {(z, c,ξ) ∈
R
m2+3m
2 ×R1×Rn|(z, c,ξ) is an optimal solution to the model
(SQSSVM0)}. Then F∗ 6=∅ by Theorem 3.3.1. Moreover, we have the next three results. Theorem 3.3.3. For any given training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}and
ˆ
η >0, if G is positive definite, then the optimal solution of model (SQSSVM0) is unique with respect to the variable z.
Proof. Assume that (ˆz,ˆc,ξ)ˆ ∈ F∗, (¯z,c,¯ ξ)¯ ∈ F∗ and ˆz 6= ¯z. For any 0 < δ < 1, (˜z,˜c,ξ)˜ ,δ(ˆz,ˆc,ξ) + (1ˆ −δ)(¯z,¯c,ξ) is feasible to model (SQSSVM¯ 0) due to the convexity of the feasible domain. Therefore,
˜zTG˜z+ ˆη
n
X
i=1
˜
ξi ≥ˆzTGˆz+ ˆη n
X
i=1
ˆ ξi,
˜zTG˜z+ ˆη
n
X
i=1
˜
ξi ≥¯zTG¯z+ ˆη n
X
i=1
¯ ξi.
Multiplying the first inequality by δ and the second by (1−δ), we have
˜
zTG˜z+ ˆη
n
X
i=1
˜
ξi ≥δˆzTGˆz+ (1−δ)¯zTG¯z+ ˆη n
X
i=1
(δξˆi+ (1−δ) ¯ξi).
Equivalently, [δˆz+ (1−δ)¯z]TG[δˆz+ (1−δ)¯z]≥δˆzTGˆz+ (1−δ)¯zTG¯z, and δ(1−δ)(ˆz−
¯z)TG(ˆz−¯z) ≤ 0. When G is positive definite, we have ˆz−¯z = 0, which contradicts to the assumption that ˆz6=¯z.
Thus, for any given training data set, ifGis positive definite, the main characteristics of the separating quadratic surface are uniquely determined by the optimal solution of model (SQSSVM0) with respect to the variable z.
Theorem 3.3.4. For any given training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}and
ˆ
η >0, ifG is positive definite, then there exist constants c andc such that c≤c≤c, for any (z, c,ξ)∈ F∗.
Proof. Let (ˆz,ˆc,ξ)ˆ ∈ F∗. When G is positive definite, by Theorem 3.3.3, ˆz is uniquely determined and, for each (z, c,ξ)∈ F∗, we have z=ˆz and zTGz+ ˆηPn
i=1ξi =ˆzTGˆz+
ˆ ηPn
i=1ξˆi. Consequently,
Pn
i=1ξi =
Pn
ξi ≥0 for anyi, we have ξi ≤Pni=1ξi = ¯δ. Therefore,
c≤ξj−1−(ˆsj)Tˆz≤δ¯−1−(ˆsj)Tˆz, for j ∈ {j : ˆyj =−1}
c≥1−ξj−(ˆsj)Tˆz≥1−δ¯−(ˆsj)Tˆz, for j ∈ {j : ˆyj = +1}.
Let c = min{j:ˆyj=−1}{δ¯−1−(ˆsj)Tˆz}, c = max{j:ˆyj=+1}{1−δ¯−(ˆsj)Tˆz}, then we have c≤c≤c.
Theorem 3.3.5. If the training data set is quadratically separable and Gis positive defi-nite, then for any given sufficiently largeη >ˆ 0, the optimal solution of model(SQSSVM0)
is unique with respect to the variable c.
Proof. When the training data set is quadratically separable, by a similar proof of Theorem 3.3.2, for the model (SQSSVM0) with any given sufficiently large ˆη > 0 and (˘z,˘c,ξ)˘ ∈ F∗, we know ξ˘=0. Hence (˘z,c,˘ 0) is feasible to the model (SQSSVM0), which indicates that ˆyi((ˆsi)T˘z+ ˘c)≥1,∀i. We first prove that there exists aj ∈ {j : ˆyj = +1}
such that ˆyj((ˆsj)T˘z+ ˘c) = 1 as follows by contradiction.
Assume this conclusion is wrong, then we have
(ˆsj)T˘z+ ˘c >1, for j ∈ {j : ˆyj = +1}, (B1) (ˆsj)T˘z+ ˘c≤ −1, forj ∈ {j : ˆyj =−1}. (B2)
Let˜z=δ˘z and ˜c=δ(˘c+ 1)−1, for some δ ∈(0,1). Then expression (B2) is equivalent to
(ˆsj)T˜z+ ˜c≤ −1, for j ∈ {j : ˆyj =−1} (B3)
Moreover, for j ∈ {j : ˆyj =−1}, from expression (B1), we have
lim
δ→1−[(ˆs
j)T˜z+ ˜c] = lim δ→1−[δ(ˆs
j)T˘z+δ(˘c+ 1)−1] = (ˆsj)T˘z+ ˘c > 1.
Hence there exists a δ ∈(0,1) such that
(ˆsj)T˜z+ ˜c >1, forj ∈ {j : ˆyj = +1}. (B4)
the corresponding objective value is ˜zTG˜z+ 0 = δ2z˘TG˘z <˘zTG˘z+ 0, which indicates
that (˘z,c,˘ 0) is not an optimal solution. This contradiction infers that there exists a j ∈ {j : ˆyj = +1} such that ˆyj((ˆsj)T˘z+ ˘c) = 1.
Suppose that the model (SQSSVM0) has another optimal solution (ˆz,ˆc,ξ). As before,ˆ we have ˆξ =0. WhenG is positive definite, we know˘z=ˆzfrom Theorem 3.3.3. Rewrite the two optimal solutions as (˘z,˘c,0) and (˘z,ˆc,0), respectively. From the above arguments, we know there exist j and ¯j ∈ {j : ˆyj = +1}such that
(ˆs¯j)T˘z+ ˘c= 1, (ˆsj)T˘z+ ˘c≥1, (ˆsj)T˘z+ ˆc= 1, (ˆs¯j)T˘z+ ˆc≥1.
Therefore, we have ˘c≥ˆcand ˘c≤cˆusing the above expressions. In other words, we have ˘
c= ˆc.
From Theorems 3.3.3 and 3.3.5, we know that if the training data set is quadratically separable and G is positive definite, then, for any sufficiently large ˆη > 0, the model (SQSSVM0) generates a unique separating quadratic surface. Generally speaking, for any given training data set with G being positive definite, we may solve the model (SQSSVM0) with a sufficiently large ˆη >0 to generate a separating quadratic surface for binary classification.
Notice that if the matrix G in model (SQSSVM0) is only positive semidefinite, we can always append a perturbation such that the matrix G+I ( >0, I is the identity matrix) becomes positive definite. Then, consider the following perturbed model:
min zT(G+I)z+ ˆη
n
X
i=1
ξi
s.t. yˆi((ˆsi)Tz+c)≥1−ξi, i= 1,2,· · · , n. (SQSSVM0-)
(z, c)∈Rm2+32m+2, ξ
i ≥0, i= 1,· · · , n.
Lemma 3.3.1. For any given training data set {(ˆx1,yˆ1),· · ·,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)} and
ˆ
η > 0, if the optimal value of model (SQSSVM0) is v and the optimal value of model
(SQSSVM0-) is v, for a given >0, then v →v as →0.
Proof. Let (˜z,c,˜ ξ)˜ ∈ F∗. Ifkz˜k 6= 0, for (z, c,ξ) and anyδ >0, there exists
0 = (˜zTδ)(˜z) such that when 0< < 0,
v ≤zTGz+ ˆη
n
X
i=1
ξi ≤v≤˜zT(G+I)˜z+ ˆη n
X
i=1
˜
ξi =v+(˜z)T(˜z)< v+δ.
That is,|v−v|< δ. If k˜zk= 0, by the expression
v ≤zTGz+ ˆη
n
X
i=1
ξi ≤v ≤˜zT(G+I)˜z+ ˆη n
X
i=1
˜
ξi =v+(˜z)T(˜z) =v.
we have thatv =v. Therefore, v →v as→0.
Remark 1. For any given η >ˆ 0 and 0< 1 < 2, we have
v1 ≤(z
2)TGz2 +
1(z2)T(z2) + ˆη
n
X
i=1
ξ2
i
<(z2)TGz2 +
2(z2)T(z2) + ˆη
n
X
i=1
ξ2
i =v2.
Hence the sequence {v} monotonically decreases to v as &0.
Theorem 3.3.6. For any given training data set{(ˆx1,yˆ1),· · · ,(ˆxi,yˆi),· · · ,(ˆxn,yˆn)}and
ˆ
η >0, if the sequence{(z, c,ξ)}converges to(z0, c0,ξ0)as→0, then(z0, c0,ξ0)∈ F∗
and z0Tz0 ≤zTz, for any (z, c,ξ)∈ F∗.
Proof. When {(z, c,ξ)} → (z0, c0,ξ0) as → 0, obviously (z0, c0,ξ0) is feasible to
model (SQSSVM0). By Lemma 3.3.1, we have v → v as → 0. Hence we know
(z0, c0,ξ0)∈ F∗.
![Figure 1.1: A SVM Classifier (an image from [26])](https://thumb-us.123doks.com/thumbv2/123dok_us/1661992.1208652/12.612.166.457.74.235/figure-svm-classier-an-image-from.webp)
![Figure 1.4: Face Detection Based on SVM (an image from [76])](https://thumb-us.123doks.com/thumbv2/123dok_us/1661992.1208652/15.612.183.449.68.330/figure-face-detection-based-svm-image.webp)