International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2017 IJSRCSEIT | Volume 2 | Issue 4 | ISSN : 2456-3307
Lightweight multilingual Named Entity Resource Extremely
Extraction and Linking Using Page Rank and Semantic Graphs
S N V A S R K Prasad1, K Gurnadha Gupta2, M Manasa3
1*CSE, Sri Indu College of Engineering and Technology, JNTU Hyderabad, Hyderabad, India 23CSE, Sri Indu College of Engineering and Technology, JNTU Hyderabad, Hyderabad, India
*Corresponding : [email protected]
ABSTRACT
Text analytic systems usually trust heavily on detecting and linking entity mentions in documents to data bases for downstream applications like sentiment analysis, question responsive and recommended systems. a major challenge for this task is to be able to accurately discover entities in new languages with restricted labeled resources. during this paper we present an accurate and lightweight1 multi-lingual named entity recognition (NER) and linking (NEL) system. The contributions of this paper are three-fold: 1) light-weight named entity recognition with competitive ac-curacy; 2) Candidate entity retrieval that uses search click-log data and entity embedding to attain high preciseness with an occasional memory footprint; and 3) e consumer entity disambiguation. Our system achieves progressive performance on TAC KBP 2013 trilingual data and on English aidaconll data. a multilingual named element recognizer and linker. Group depends on the connections in Wikipedia to determine mappings between the substances furthermore, their distinctive names, and Wikidata as a dialect skeptic reference of substance identifiers. Group separates the notices from content utilizing a string coordinating motor and connections them to elements with a mix of principles, PageRank, and highlight vectors based on the Wikipedia classes. We assessed Group with the assessment convention of ERD'14 (Carmel et al., 2014) and we come to the aggressive F1-score of 0.746 on the advancement set. Crowd is composed to be multilingual and has forms in English, French, and Swedish.
Keywords : KBP, ERD, Semantic Graphs, Wikipedia, NER, NEL, JAGADISH
I.
INTRODUCTION
Named entity recognition (NER) refers to the method of finding mentions of persons, locations, and organizations in text, whereas entity linking (or disambiguation) associates these mentions with unique identifiers. Figure one shows an example of entity linking with the mention Chandra Bose, an ambiguous name that will ask thousands of and wherever twenty one are famous enough to have a Wikipedia page (Wikipedia, 2016). In Fig. 1,the programmed chosen the foremost popular entity (top) and used the cue word biologist (bottom) to link the phrase JAGADISH
click information from seek logs, we can give focused execution to multi lingual applicant element recovery from archives, and through e customer strategies for substance disambiguation, we can get further changes in NEL exactness
Figure 1: Search results for the queries CHANDRA BOSE and jagadish CHANDRA BOSE. The engine returns the most popular entity (top) and uses the minimal context given in the query, fbiologist, to
propose a less popular entity (bottom)
Entity recognition and linking became a crucial part to several language process applications: Search engines (Singhal, 2012), question responsive (Ferrucci, 2012), or dialogue agents. This importance is reflected by a growing variety of obtainable systems; see TAC-KBP2015 (Jib et al., 2015), as an example, with ten collaborating teams.
Although several applications embrace entity linkers, the range of the input texts, which can embrace tweets, search queries, news wires, or encyclopedic articles, makes their analysis problematic. Whereas some evaluations consider entity linking in isolation and mark the mentions within the input, end-to-end pipelines, wherever the input consists of raw text, need to combine entity recognition and linking. The ERD’14 challenge (Carmel et al., 2014) is an example of the latter.
II.
METHODS AND MATERIAL
2. Previous Work
Substance connecting has impelled an extensive sum of work in the course of the most recent 10 years. Bunescu and Pasca (2006), Mihalcea and Csomai
(2007), and Cucerzan (2007) utilized Wikipedia as a learning source and its articles to characterize the substances; its hyperlinks to discover the notices, and semantic information from divert pages and classes, to convey out disambiguation. Milne and Witten (2008) utilized the probability of an element given a specify M, P(E|M), and a relatedness metric between two elements figured from the connections to their relating pages to enhance both review and exactness.
Ferragina and Scaiella (2010) tended to shorter bits of content with the thought to utilize a system understanding between every one of the elements. The Entity Recognition and Disambiguation Test (ERD'14) (Carmel et al., 2014) is a current assessment, where contenders were given a set of substances to perceive and connect in a corpus of unlabelled content. This setting is nearer to true application than TAC (Jib et al., 2015), where members need to connect as of now sectioned notices. The assessment included two tracks: one with long records of a normal size of 600 words and a short track comprising of the pursuit inquiry. At long last, the CoNLL-2003 shared assignment (Tjong Kim Sang and De Meulder, 2003) is a compelling assessment of dialect autonomous named element acknowledgment, with an attention on German and English. Hoffart et al. (2011) connected the names in the English corpus to Wikipedia pages making this dataset a valuable corpus for element connecting. In this paper, we utilized the ERD'14 improvement set and also the CoNLL-2003 informational index with Wikidata joins.
3. Building the Entity knowledge base
3.1 Mention-Entity Pairs
Following Mihalcea and Csomai (2007) and Bunescu and Pasca (2006), we collected the mention-entity pairs from the Wikipedia links (wiki links). we designed the entity base from the form three versions of Wikipedia: English, French, and Swedish, and therefore the frequency of the wiki links in each version. Figure try of} shows an example of a pair with the mention Swedish Parliament. This gives suggestions of however an entity is often referred
As terminology for the entities, we have a tendency to used Wikidata, the linked info of Wikimedia. Wikidata connects the various language versions of every an article in Wikipedia with a novel symbol known as the Q-number. Additionally to being a cross-lingual repository, Wikidata additionally links an oversized number of entities to structured info like the dates of birth and death for persons.
Figure 2: The structure of wikilinks in Wikipedia.
In order to use a language-agnostic symbol, we translated the wiki links into Q-numbers. We extracted the pairs of Q-numbers and article names from a Wikidata dump for every language. Since the dump doesn't contain any universal resource locator; the algorithmic should recreate the address from the titles. We could reach coverage of about 90th. The remaining 10% corresponds to redirect pages that act as different names or to hide common misspellings. We used the Wikipedia dump to identify these redirects and that we improved the coverage rate to 99.1%.to: i.e. its name or aliases.
3.3 Annotation the Mentions
We annotated the mention-entity pairs in our knowledge base with a collection of options that we used in the sequent processing:
1. The Frequency of the mention-entity pairs.
2. We used dictionaries of common nouns, verb, and adjectives for every language. If a mention only consists of words within the workbook, we mark it as only-dictionary. An example of this can be the artist Prince in English and French.
3. We have a tendency to compute an inventory of the foremost frequent words (stop words) from Wikipedia for every language. They embody the, in, and, and a, in English. If all the words in an exceeding mention are stop words, we have a tendency to mark it as only-stop-words.
4. The system marks the mentions with a high number of links as highly-ambiguous, such as John or details with virtually five,000 totally different entities joined to every.
5. Mentions while not upper case letters are marked as lower-case.
6. Family names and surnames. If the foremost common mention of someone has over two words, we mark every mention of 1 word as generic, like the mention Bush referring to the previous president St. George W. Bush.
7. We conjointly annotate the entities with their frequency (total-frequency). It corresponds to the total of all their mentions frequencies.
3.4 Pruning The Knowledge Domain
Although Wikipedia is reviewed by immeasurable volunteers, there are unit lots of dishonorable mentions in the collected knowledge domain. we removed a vicinity of them victimization the subsequent rules: 1. The mention is marked as lower-case and either only-dictionary or only-stop-words
2. The frequency of the entity-mention is strictly 1, whereas the total-frequency of that entity is higher than a threshold parameter that was empirically obtained. 3. The mention consists of 2 or additional words, and starts with a lower-case stop word, that
Is not an exact article. This may separate out anchors of the sort a town in the Kingdom of Sweden.
We conjointly clustered the mentions with a normalized Levenshtein distance (Levenshtein, 1966). If the distance was but zero.2 to any component, they were thought-about to be within the same cluster. We applied the clustering to all or any the surface forms and that we discarded the mentions while not a group.
4. System Components and Pipeline
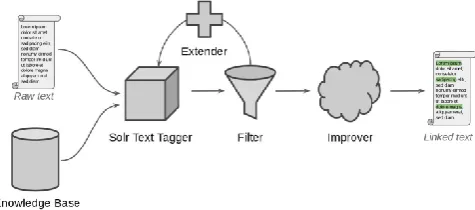
The framework comprises of three fundamental segments: a spotter that distinguishes the notices, an arrangement of guidelines that prunes the outcomes and an improved that employments logical signs for element acknowledgment (Fig. 3).
The spotter yields a match for each possible say of an element, abandoning us with a record where practically every word is labeled as an element. This yield has a high review, however a low exactness. The separating that comes after that tries to evacuate the most improbable of the options from the spotter and raises the exactness to a humble level while attempting to minimally affect the review.
In the event that the info information to the subsequent stage is totally unfiltered the Contextual Improver can't impact the outcomes emphatically. The Contextual Improver is the last stride and utilizes relevant pieces of information, for example, which classes the substances have a place with and which elements are generally seen together, to enhance the outcome.
4.1 Mention Spotting
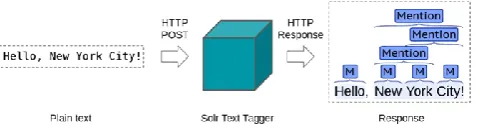
We utilize the say substance learning base to spot the notices in crude content and connect them with all their conceivable substances. Following Lipczak et al. (2014), we connected the Solr Text Tagger (Smiley, 2013) in view of limited state transducers and the Lucene indexer. Solr Text Tagger was picked as it is an exceptionally viable method for increasing conceivable matches of a database in content. It depends on the Lucene open-source programming and its usage of limited state transducers.
As a preprocessing step, Solr Text Tagger arranges every one of the notices in the learning base, where the info names are the letters and images of notices and the yield marks are the element identifiers. At that point, given an untagged content, the tagger denotes every one of the events, potentially covering, of the considerable number of names in the database. See Fig. 4.
4.2 Filtering and Expansion
The yield of the Spotter is typically extremely loud as most words can coordinate some say in the learning base. Illustrations incorporate it, a novel by Stephen King, or Is This It, a collection by The Strokes. The outcome is a high specify review, however a low exactness. We connected channels to expel a few coordinates and enhance the exactness while saving the review.
The framework utilizes an arrangement of physically composed tenets also, observationally acquired hyper parameters to make strides the exactness with a negligible impact on review. We portray them in the areas beneath. The total rundown of parameter esteems is given in the Crowd source code accessible from GitHub1.
4.2.1 Mention Probability
We processed the likelihood for a term or an expression to be a connection to the entire Wikipedia (Eckhardt et al., 2014) utilizing the recipe: Say likelihood = link (mention)/ freq (mention). This gives a indicate whether a word grouping is all the more generally utilized as a way of elements or similarly as words.
Restorative Center, for instance, is connected 1.0% of the circumstances utilized, while Medical Center of Central Georgia has a say likelihood of 73.7%. Any applicant that had under 0.5% say likelihood was instantly pruned.
4.2.2 Filters to Improve Precision
Channels are rules in light of linguistic pieces of information and the banners characterized in Sect. 3.3. Each coordinating principle returns a doubt score and we process the entirety of the scores. The most noteworthy principles are:
1. Capitalization: Add doubt to any specify that does not contain a capital letter. This loses some review however expands the accuracy significantly. We enhanced it with a capacity that mulls over the number of capital letters, regardless of whether the specify is the begin of another sentence and whether the specify has the main word reference tag. Features additionally utilize uppercase words. We perceive completely promoted sentences with consistent articulations. Says in features with the just lexicon, or just stop-words labels, produce doubt.
maintain a strategic distance from the labeling of the specify Bush with each substance having this name as a nonexclusive name.
3. Impacting names: If two labels are quick neighbors, except for a space, they produce doubt. The framework considers all the competitor substances for a surface shape and just triggers doubt if no less than one of the substances is a non specific name.
This is a technique to distinguish and abstain from labeling a multi-word name which does not exist in our insight base with various different hopefuls.
4.2.3 Extender To Improve Recall
We expanded the identified notices following the work of Eckhardt et al. (2014). When we perceive a specify comprising of two words or more that passed the channel, we make new specifies with acronyms and non specific adaptation of the thing by part it into different parts.
Given the content a division of First Citizens Bank Offers Inc. of Raleigh, N.C., where the framework perceives the say First Citizens BancShares Inc, and the extender makes conceivable acronyms, such as FCBI and F.C.B.I. It additionally searches for brackets, instantly following a specify, giving a proposal of how it is intended to be abridged.
The extender additionally parts the specify into parts of 1, 2, and 3 words. The say above produces In the first place, Citizens, BankShares and Inc., and additionally In the first place Citizens, Citizens BankShares, BankShares Inc, et cetera. We relate the produced notices with the arrangement of elements of the first specify. The labeled expansions are sifted in the same way as the various labels.
4.3 Contextual Improver
For each record, the Improver utilizes PageRank to figure out which applicants usually happen together, and prunes the concealed blends. This creates an outcome with a high accuracy.
We utilize this high accuracy yield as the displayed setting of the archive. A weighted classification diagram is ascertained for this demonstrated setting. The named substance acknowledgment is then extended by considering the comparability of the
considerable number of contender to the demonstrated setting. Once the improver has been connected, we convey out a last tidy up step, where we wipe out all the cover and rank the rest of the contender for each say.
4.3.1 PageRank
We apply an altered rendition of PageRank (Brin what's more, Page, 1998) to the labeled notices. Following Eckhardt et al. (2014), we make a hub for each say element combine that is identified in the content, also, run three emphases of PageRank. We break down the inner connections of Wikipedia to figure out which elements show up in a similar setting. Two substances are viewed as connected if the article of Entity A connections to the article of Entity B or a connection to both the article of Entity An and the article of Entity B happens in the same section.
The connections computed on Wikipedia are exchanged to the labeled archive and create a diagram of connected elements. Not at all like the work of Eckhardt et al. (2014), we introduce every hub with the standard esteem 1/N, and the proportion between the underlying esteem and the last esteem is utilized to adjust the doubt for a competitor. Subsequent to applying PageRank, a few substances will be higher positioned than others which we take as info to another round of sifting. The competitors with high doubt are evacuated. This produces a high accuracy yield, with a slight drop of the review.
Figure 4: The Solr Text Tagger processing scheme, where the operations are carried out through POST
requests.
4.3.2 Weighted Category Graph
We utilize a weighted class diagram (WCG)
determined from the client commented on
one of the dialects in which the article is accessible. In the event that an article has the same class in every one of the dialects, this classification is allocated the greatest weight of 1.0. The weight is at that point diminished as a direct capacity of the number of dialects. The classifications should be weighted to stay away from uncommon or off base classifications doled out to articles. Wikipedia classifications are themselves arranged into parent classifications. The classification of Sweden has a parent classification of Countries in Europe for instance. A tree of classifications is gotten from each article by getting the best k classifications of an article, furthermore, growing those classifications with the best k guardians for every classification. This procedure is rehashed d times. This sums up the classifications of the article, which makes them less demanding to contrast with contiguous articles. The esteem k is set to 5, and the esteem d is set to 3, as proposed by Lipczak et al. (2014).
Table 1 demonstrates a case of the classifications we acquire from the article about Sweden.
The weighted classification diagram is utilized as a part of the accompanying way:
1. We input an arrangement of center substances with high accuracy. The improver figures a weighted class vector for every element and makes a subject centroid as the straight blend of these vectors. This is intended to work as the general subject of the dissected report. 2. We enhance the exactness of the center elements by looking at each of the high-exactness substances to the subject centroid with a cosine likeness. In the event that the score of an element is under a limit estimation of 0.6, it is expelled. At long last, the subject centroid is recalculated.
3. We at that point analyze every element in the unfiltered yield of Solr Text Tagger to the subject centroid with cosine comparability. We keep the elements that are over a limit estimation of 0.2.
This method extends the extent of the element choice and enhances the review in a specific situation mindful way. Since the yield of the weighted class charts is like the information requirements of PageRank, and the yield of PageRank is comparable to the information necessities of the weighted class chart, we have set them into an emphasis cycle with a specific end goal to accomplish higher outcomes.
4.3.3 Clean-Up
As a last stride, we dispose of covering notices:
At the point when two notices cover, we keep the longest. On the off chance that the notices are of equivalent length, we keep the furthest right. The rest of the possibility for each specify are at that point positioned by their wiki interface recurrence and the most continuous applicant is chosen as the right disambiguation.
III. RESULTS AND DISCUSSION
EXPERIMENTAL SETUP AND RESULTS
We evaluated the system with 2 totally different knowledge sets for English: ERD-51 and AIDA/YAGO and we used the analysis metrics of ERD’14 Carmelet al. (2014). we have a tendency to do have access to analysis sets for the opposite languages.
ending with an iteration cycle between a personalized version of PageRank and the usage of weighted class graphs. The system reached a weighted F1-score of zero.746 on theERD-51 dataset.
IV. CONCLUSION
The paper takes an uncommon approach to named entity recognition and elucidation because it will not separate the tasks, however treats each candidate to every mention as a separate chance. The iteration between 2 context-aware algorithms with totally different precision/recall characteristics improved the results dramatically and is, to the simplest of our data, a novel, language-independent approach to entity recognition and elucidation. We conjointly exposed the simplest way of pruning disappointing links in a very collected knowledge base by clustering.
V.
REFERENCES
[1]. Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: A collaboratively created graph database for structur-ing human knowledge. In Proceedings of the 2008 ACM SIGMOD International
Conference on Man-agement of Data,
SIGMOD ’08, pages 1247–1250, New York, NY, USA. ACM.
[2]. Sergey Brin and Lawrence Page. 1998. The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30(1-7):107–117, April.Razvan C Bunescu and Marius Pasca. 2006. Using en-cyclopedic knowledge for named entity disambigua-tion. In European Chapter of the Association for Computational Linguistics, volume 6, pages 9–16.
[3]. David Carmel, Ming-Wei Chang, Evgeniy
Gabrilovich, Bo-June Paul Hsu, and Kuansan Wang. 2014. ERD’14: Entity recognition and disambiguation challenge. In ACM SIGIR Forum, volume 48, pages 63–77. ACM.
[4]. Silviu Cucerzan. 2014. Name Entities Made Obvi-ous: The Participation in the ERD 2014 Evaluation. In Proceedings of the First International Workshop on Entity Recognition & Disambiguation, ERD ’14, pages 95–100, New York, NY, USA. ACM.
[5]. Alan Eckhardt, Juraj Hresko,ˇ Jan Prochazka,´ and Otakar Smri;. 2014. Entity linking based on
the co-occurrence graph and entity probability. In Pro-ceedings of the First International Workshop on En-tity Recognition & Disambiguation, ERD ’14, pages 37–44, New York, NY, USA. ACM.
[6]. Paolo Ferragina and Ugo Scaiella. 2010. Tagme: On-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, CIKM ’10, pages 1625– 1628, New York, NY, USA. ACM. [7]. Johannes Hoffart, Mohamed Amir Yosef, Ilaria
Bor-dino, Hagen Furstenau,¨ Manfred Pinkal, Marc Span-iol, Bilyana Taneva, Stefan Thater,
and Gerhard Weikum. 2011. Robust
disambiguation of named entities in text. In Proceedings of the 2011 Con-ference on Empirical Methods in Natural Language Processing, pages 782–792, Edinburgh.
[8]. Marek Lipczak, Arash Koushkestani, and
Evangelos Milios. 2014. Tulip: Lightweight entity recog-nition and disambiguation using wikipedia-based topic centroids. In Proceedings of the First Inter-national Workshop on Entity Recognition & Disam-biguation, ERD ’14, pages 31–36, New York, NY, USA. ACM.