An Adaptive approach for Identifying Attribute value for
Annotated Document
Kondapalli Vani & T V Gopala Krishna
1M.Tech Student,Dept of CSE, Loyola Institute of Technology and Management, Dulipalla, AP, India 2Associate.Professor, Dept of CSE, Layola Institute of Technology and Mangement, Dulipalla, AP, India ABSTRACT: Many organizations generate and
use various similarly matching content document descriptions. Such large collections of related documents contain significant amounts of both structured and unstructured information buried in large texts. Previously various information extraction algorithms smoothens the extraction of the relevant relations, they often suffer with huge workloads and falls short of inaccuracies especially when processing a notational text that does not share any similarities with the targeted document contents. Previously proposed query value content value processing algorithms facilitate the annotation of the documents structured information by identifying and extracting the information of interests to aid in subsequent querying for information retrievals. But these approaches fall short of supporting auto suggestions and we propose to extend the querying engine and usage of document annotation strategies with respect to query value and content value for auto attribute suggestions. Our major contribution in this paper, involves in presenting a skyline sweeping algorithm which identifies related content that can be used for auto suggestions and are definite to appear within the document content, by utilizing Meta information and text of the document at reduced query workloads. Our experimental query engine demonstrates that our approach generates efficient results compared to prior approaches in processing attributes of interest.
KEY WORDS: Document Annotation, Adaptive Forms, Collaborative Platforms, Skyline Sweeping Algorithm.
I.INTRODUCTION
There are numerous application areas where clients make what's more, share data; for occasion, news web journals, logical systems, long range interpersonal communication gatherings, or calamity administration systems. Current data
sharing devices, like substance
Administration programming (e.g.,
Microsoft Share- Point), permit clients to
Share reports and expound (tag) them in a specially appointed way.
Additionally, Google Base permits clients to characterize qualities for their articles or look over predefined formats. This
annotation procedure can encourage
consequent data disclosure. Numerous annotation frameworks permit just "un-typed" pivotal word annotation: for example, a client may expound a climate report utilizing a tag, for example, "Storm Category 3."
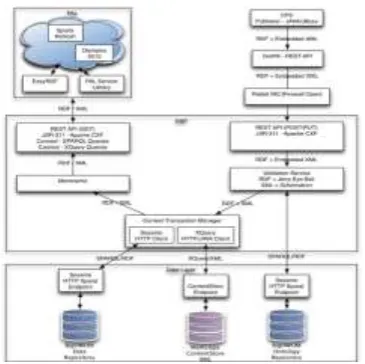
Annotation procedures that utilization trait quality sets are for the most part more expressive, as they can contain more data than un-typed methodologies. In such settings, the above data can be entered as (Storm Category, 3). A late profession toward utilizing more expressive questions that influence such annotations, is the "pay-as-you-go" questioning method in Data spacesNumerous frameworks, however, don't even have the fundamental "characteristic quality" annotation that would make a "pay-as you make a go at" questioning doable. Annotations that utilization "attribute value" sets oblige clients to be more principled in their annotation endeavors. Clients ought to know the fundamental pattern and field sorts to utilize; they ought to likewise know when to utilize each of these fields. With constructions that frequently have tens or even several accessible fields to fill, this assignment gets to be entangled and bulky. From figure (1) we can observe theDocument retrieval from data sets in uploaded datasets.
create" base that encourages handled
information annotation. A key
commitment of our framework is the immediate utilization of the question workload to coordinate the annotation process, also to inspecting the report's substance. The objective of CADS is to empower and bring down the expense of making pleasantly expounded records that can be promptly valuable for generally issued semi-organized questions.
Our key objective is to empower the annotation of the reports at creation time, while the inventor is still in the "record era" stage, even despite the fact that the methods can likewise be utilized for post era report annotation. In our situation, the creator produces another record and transfers it to the store. After the transfer, CADS investigates the content and makes a versatile insertion structure. The structure contains the best quality names given the report content and the data need (inquiry workload), and the most likely quality qualities given the record content It is essential that clients have the capacity to flawlessly inquiry and scan data put away in these databases also. Looking databases on the web and intranet today is basically
empowered by modified web applications firmly fixing to the hid den’s composition databases, permitting clients to coordinate seek in an organized way. Cases of such pursuits inside of, say a book shop's database may be "Books → Travel → Lonely Planet → Asia", or "Books → Travel → Rough Guides → Europe". With the development of the Internet, there has been a quick increment in the quantity of clients who need to get to online databases without having a definite learning of pattern or question dialects; even
moderately straightforward question
dialects intended for non-specialists are excessively muddled for such clients.
Expanding measure of content information put away in social databases, there is an interest for RDBMS to bolster essential word questions over content information. As an item is frequently amassed from different social tables, customary IR-style
positioning and inquiry assessment
routines can't be connected specifically. This paper, Describes the adequacy and the proficiency issues of noting top-k magic word inquiry in social database frameworks. We propose another adapting so as to pose equation existing IR strategies in light of a characteristic idea of virtual documents.
II. RELATED WORK
The FFF seek system at the sites that gives statistical data points may be enlarged by DBXplorer innovation. Information Spot is a business framework that backings pivotal word based inquiries by extricating the database's substance into a hyper base. Accordingly, this methodology copies the
database's substance, which makes
information honesty and upkeep
troublesome. Microsoft's English Query gives a characteristic dialect interface to a SQL database. Find has proposed a Fig. 1. Document retrieval from data sets
broadness first CN specification calculation that is both sound and complete. The calculation is basically listing all sub diagrams of size k that does not damage any pruning principles. The calculation differs k from 1 to some hunt range limit M. Three pruning standards are utilized and they are recorded underneath. issue a SQL inquiry for each CN and union them to locate the top-k results by their significance scores.
DISCOVER2 present two option inquiry
assessment systems: meager and
worldwide pipeline calculations, both enhanced for ceasing the inquiry execution promptly after the genuine top-k-th result can be resolved. Consider a social mapping R as a set f relations {R1, R2, . . . , R|R|}. These relations are interconnected at the outline level by means of remote key to essential key references and indicate Ri → Rj if Ri has an arrangement of outside key attribute(s) referencing Rj's essential key attribute(s), taking after the tradition in drawing social blueprint charts. For straightforwardness, we accept all essential key and remote key qualities are made of single characteristic, and there is at most
one remote key to essential key
relationship between any two relations and don't force such restrictions in our execution.
A question Q comprises of (1) an arrangement of particular essential words, i.e., Q = {w1,w2, . . . ,w|Q|}; and (2) a parameter k demonstrating that a client is just keen on top-k results positioned by significance scores connected with every outcome. Ties can be broken subjectively. A client can likewise determine AND OR
semantics for the inquiry, which
commands that an outcome must or may not coordinate all the magic words, individually. The default mode is the OR semantics to permit more adaptable result positioning.
III. BACKGROUND APPROACH
In this area, we display the documentation that we use in whatever is left of the paper and depict the issue setting. As talked about in Section 1, we will likely recommend annotations for an archive. We characterize a report d as a couple ðdt; daþ, made out of the printed substance dt and the arrangement of existing client annotations da. We utilize dopt a to
indicate the complete and ideal
arrangement of annotations for d. The dopt a serves as a theoretical pattern, i.e., is made by a prophet with flawless information of the space of d (e.g., calamity administration) what's more, obviously, dopt an is obscure to the calculation that is attempting to gauge as precisely as would be prudent the dopt a Every annotation An in da has the structure ðAj; Viþ, where Aj is the quality name and Vi is the characteristic worth.
The properties can have numerous
qualities (i.e., da may contain both ðAj; V1þ and ðAj; V2þ). We say that an archive d is commented with quality Aj if there is any worth v for which ðAj; vþ 2 da. We utilize the documentation DA and DV for the trait's spaces names and values, respectively,1 and D to signify the archive of all reports put away in the database. We concentrate on and propose answers for the "properties recommendation" issue. From the issue definition we recognize two, conceivably clashing, properties for
distinguishing and recommending
That is, they must show up in numerous inquiries in W, on the grounds that the regular properties in W have a more prominent potential to enhance the deceivability of d. Second, the traits must have high substance esteem (CV) as for dt. That is, they must be pertinent to dt. Something else, the client will most likely release the recommendations and d won't be legitimately.
IV. FRAME WORK
Horizon Sweeping calculation intended to minimize the quantity of join checking operations, which ordinarily overwhelms the calculation's expense. This instinct is that if there are two hopefuls x and y and the upper bound score of x is higher than that of y, y ought not be checked unless x has been checked. Subsequently, we ought to organize every one of the possibility to be checked by upper bound scores. An innocent technique is to figure the upper headed scores for every one of the hopefuls, sort them as indicated by the upper bound scores, and check them one by one as per this ideal request. This will causeintemperate measure of pointless work, subsequent to not every one of the hopefuls should be checked.
Algorithm: Skyline Sweeping Algorithm
1 .Q. Push ((1,1,..1), calc _ us core((1,1…,1)));
2. top-k∅;
3. While top-k[k].score<Q. head( ).us core Do
4 head Q. pop _max ( );
5 r execute sql (from Query (head));
6 if r≠nil then
7 Top-k. Push (r, score(r));
8 for i1 to m do
9 t head. dup ();
10 t.it.i+1;
11 Q. P ush(t, calc_ us core(t));
12 If head. I >1then
13 Break;
14 Return top-k;
An outcome list, top-k, contains close to k results requested by the plunging genuine scores. The fundamental information structure is a need line, Q, containing every one of the hopefuls (which are
mapped to multi-dimensional focuses) as per
precisely the upper bound score of all the natural applicants.
V. SYSTEM DESIGN
In proposed framework, observational execution assessment of social decisive word look frameworks. Our outcomes show that numerous current inquiry procedures don't give worthy execution to
sensible recovery undertakings.
Specifically, memory utilization blocks numerous pursuit systems from scaling past little datasets with a huge number of vertices. We additionally investigate the relationship between execution time and components changed in past assessments; our examination demonstrates that these components have moderately little effect on execution. In outline, our work affirms past cases with respect to the unsuitable execution of these frameworks and
underscores the requirement for
institutionalization as exemplified by the IR group when assessing these recovery frameworks. File length and Execution time can be seen. Easy to look after information Resolving the Security Issues by method for keep up their way of life and in addition crypto archive protection, Less Time Consuming Process, Low Cost is sufficient to control the information, on the grounds that the space needed for keeping up the information is less. Simple to separate from the server Maintenance of Data Owner and client gives more noteworthy advantage to break down them if any instance of abuse.
Our outcomes ought to serve as a test to this group in light of the fact that minimal past work has recognized these difficulties. Advancing, we must address a few issues. To start with, we must plan calculations, information structures, and usage that
perceive that principle memory is
restricted. Look systems must deal with their memory usage proficiently, swapping information to and from plate as
fundamental. Such usage are unrealistic to have execution qualities that are like existing methodologies yet must be utilized if social essential word look frameworks are proportional to expansive information sets (e.g., a huge number of tuples). Second, assessments ought to reuse information sets and question workloads to give more prominent consistency of results, for even our outcomes change broadly relying upon which information set is considered. Luckily, our assessment benchmark is starting to pick up footing around there as prove by others' reception of it for their needs.
VI. EXPERIMENTAL EVALUATION
To assess the algorithmic methodologies that we present in this paper, we contrast our calculations and a mixed bag of existing baselines. Data Freq. propose the most regular traits in the database of clarified records. The elements separated are settled to a specific blueprint that we guide to our own particular traits. We explain the archives and consider every one of the credits that compare to an element. We utilize the Calais significance score to rank the characteristics. On the off chance that the same property is expounded with different qualities, we utilize the most astounding significance score worth to score it. Items have particular qualities, and subsequently, we can't utilize this nonspecific extractor as a standard, so we just utilize this method as a pattern for the Emergency information set.
In this analysis, we measure the nature of the proposed characteristics for a report, contrasted with its ground-truth properties. Note that this test disregards the question workload, and henceforth does not quantify the methods' accomplishment in taking care of the Attribute Suggestion issue, which is the key commitment of this paper, and is assessed. For every execution, we pick a record d for assessment (testing) and utilize the rest as preparing set, that is, as the commented reports database. We figure the accuracy for the test archive d as the proportion of the proposed properties da that are in the ground-truth qualities d pick an of d.
We utilize the full workload to gauge the questioning quality. We report the exactness and review found the middle value of overall archives d in D. In this investigation, we check the size's impact of the database on the exactness of quality proposals and the quantity of inquiry matches. Review that the substance worth is processed utilizing the database of clarified records. We consider subsets of the database of records of distinctive sizes. As the quantity of records of the Emergency information set is little, we just report the outcomes got in the CNET and Amazon information set.
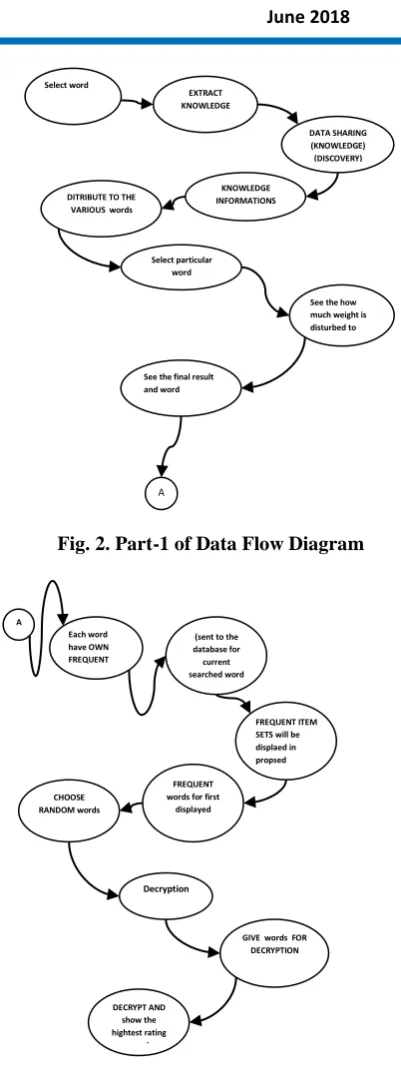
VII. DATA FLOW DIAGRAMS
VIII. CONCLUSION
This paper, considered supporting
successful and effective top-k pivotal word inquiries over social information bases. What's more, proposed another positioning system that adjusts the cutting edge IR enchanment
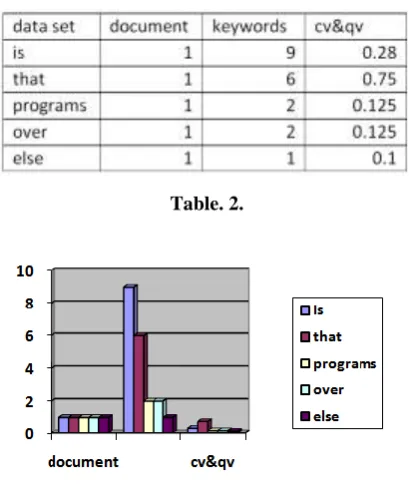
data set document keywords cv&qv
Is 1 9 0.0025
That 1 6 0.0078
programs 1 2 0.002
over 1 2 0.0090
Else 1 1 0.0060
Each word have OWN FREQUENT ITEM SETS
(sent to the database for current searched word
ITS OWN FREQUENT ITEM
SETS FREQUENT ITEM SETS will be displaed in propsed FREQUENT
words for first displayed CHOOSE
RANDOM words
Decryption A
GIVE words FOR DECRYPTION
DECRYPT AND show the hightest rating
word
EXTRACT KNOWLEDGE Select word
DATA SHARING (KNOWLEDGE) (DISCOVERY) KNOWLEDGE
INFORMATIONS DITRIBUTE TO THE
VARIOUS words
Select particular word
VARIOUS SITES See the how much weight is disturbed to selected word
PROTECTED See the final result
and word
A
Fig. 2. Part-1 of Data Flow Diagram
positioning capacity and standards into positioning trees of joined database tuples. Positioning technique additionally has a few remarkable elements over existing ones. We moreover examined inquiry handling system customized for our non-monotonic positioning capacities. Two
calculations were recommended that
forcefully minimize database tests. We have led broad tests on extensive scalegenuine databases. The test results affirmed that our positioning strategy could accomplish high exactness with high proficiency to scale to databases with a huge number of tulles.
IX. GRAPHS
X. REFERENCES
[1] “Facilitating Document Annotation Using Content and Querying Value” by Eduardo J. Ruiz, Vagelis Hristidis, and Panagiotis G. Ipeirotis proceedings in
IEEE TRANSACTIONS ON
KNOWLEDGE AND DATA
ENGINEERING, VOL. 26, NO. 2, FEBRUARY 2014.
[2] S.R. Jeffery, M.J. Franklin, and A.Y. Halevy, “Pay-as-You-Go User Feedback for Dataspace Systems,” Proc. ACM SIGMOD Int’l Conf. Management Data, 2008.
[3] K. Saleem, S. Luis,Y. Deng, S.-C. Chen, V. Hristidis, and T. Li,“Towards a Business Continuity Information Network for Rapid Disaster Recovery,” Proc. Int’l Conf Digital Govt. Research (dg.o ’08), 2008.
[4] A. Jain and P.G. Ipeirotis,“A
Quality-Aware Optimizer for Information
Extraction,” ACM Trans. Database Systems, vol. 34, article 5, 2009.
[5] J.M. Ponte and W.B. Croft,“A
Language Modeling Approach to
Information Retrieval,” Proc. 21st Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval
(SIGIR ’98), pp.275-281,
http://doi.acm.org/10.1145/290941.291008 , 1998.
[6] R.T. Clemen and R.L.
Winkler“Unanimity and Compromise
among Probability Forecasters,”
Management Science, vol. 36, pp. 767-779,
http://portal.acm.org/citation.cfm?id=8161 0.81609, July 1990.
[7] C.D. Manning, P. Raghavan, and H. Schu¨ tze, Introduction to Information Retrieval, first ed. Cambridge Univ. Press, http://www.amazon.com/exec/obidos/redir ect?tag=citeulike07-
20&path=ASIN/0521865719, July 2008. [8] P.G. Ipeirotis, F. Provost, and J. Wang, “Quality Management on Amazon Mechanical Turk,” Proc. ACM SIGKDD Workshop Human Computation (HCOMP
’10), pp. 64-67,
http://doi.acm.org/10.1145/1837885.18379 06, 2010.
[10] R. Fagin, A. Lotem, and M. Naor.
Optimal aggregation algorithms for
middleware. In PODS, 2001.
[11] R. Goldman, N.Shivakumar, S. Venkatasubramanian, and H. Garcia-Table. 1.
Molina. Proximity search in databases. In VLDB, 1998.
[12] T. Grabs, K. B¨ohm, and H.-J. Schek. Powerdb-ir – information retrieval on top of a database cluster. In CIKM, pages 411–418, 2001.
[13] P. J. Haas and J. M. Hellerstein. Ripple joins for online aggregation. In SIGMOD 1999, pages 287–298, 1999. [14] V. Hristidis,L.Gravano, and Y. Papakonstantinou. Efficient IR-Style
Keyword Search over Relational
Databases. In VLDB, 2003.
[15] V. Hristidis and
Y.Papakonstantinou. DISCOVER: