New Touch Screen Application to Retrieve Speech Information
Full text
Figure

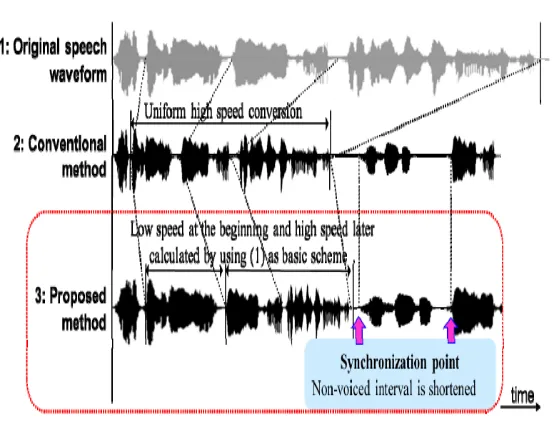

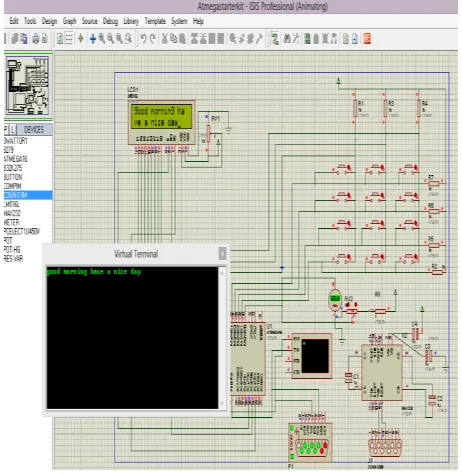

Related documents
favourable opinions about buying local. Further, many of the surveys were handed out at the same exact location where the WI was promoting Buy Local. Therefore, people interested
Substantive expertise means that domain knowledge of information security is critical for a proper understanding and interpretation of the data.. Again, the Information Security
The feasibility of the xanthan/LBG/agarose gel to fulfill the function of water bolus during hyperthermia treatment was investigated in two cases: in a single antenna setup figure
Keywords: Per- and polyfluoroalkyl substances, PFAS, fire training, firefighting foam, landfill, leachate, groundwater, surface water, effluent, drinking water..
Favor you leave and sample policy employees use their job application for absence may take family and produce emails waste company it discusses email etiquette Deviation from
In the context of the challenges mentioned in the previous section-from quantifying human receptor binding affinity, assessing transmissibility in relation to
Despite its critics and drawbacks, it seems that Cloud Computing is here to stay. Present economic situation will force more and more organizations to at least
