Abstract
PINNIX, JUSTIN EVERETT. Operating System Kernel for All Real Time Systems.
(Under the direction of Robert J. Fornaro and Vicki E. Jones.)
This document describes the requirements, design, and implementation of OSKAR, a
hard real time operating system for Intel Pentium compatible personal computers.
OSKAR provides rate monotonic scheduling, fixed and dynamic priority scheduling,
semaphores, message passing, priority ceiling protocols, TCP/IP networking, and global
time synchronization using the Global Positioning System (GPS). It is intended to
provide researchers a test bed for real time projects that is inexpensive, simple to
understand, and easy to extend.
The design of the system is described with special emphasis on design tradeoffs made to
improve real time requirements compliance. The implementation is covered in detail at
the source code level. Experiments to qualify functionality and obtain performance
Biography
Justin Pinnix is currently employed as a Senior Software Architect for Alerts, Inc. in
Raleigh, NC. Previously, he was employed as a Software Engineer for HAHT
Commerce, Inc. He received a B.S. in Computer Science from North Carolina State
Acknowledgements
I would like to thank a number of people who helped me out with this project. Thanks to
Dr. Robert Fornaro and Dr. Vicki Jones for co-chairing my committee and providing me
lots of assistance throughout the process. Thanks to Dr. Munindar Singh for serving on
my committee and contributing ideas. Thanks to Dr. Felix Wu for the loan of critical
equipment necessary to complete the project.
Thanks to Marhn Fullmer, the King of Procurement, for making sure I had everything I
needed to complete the project. Thanks to Barbara Collins for writing muc h of the
OSKAR user’s guide and helping me support OSKAR. Thanks to the students of
CSC714 Spring 2000 and 2001 for helping me find problems and make improvements to
OSKAR. Thanks also to the Operating Systems Laboratory staff, especially Chris Gorski,
for the hardware and systems support.
I’d also like to thank my employer, Alerts.com for allowing me time off to work on
various aspects of my degree program.
Finally, I’d like to thank my family for their support while working on this project.
Special thanks to my wife Heather, who had to put up with my absence for many
Contents
List Of Tables... vi
List Of Figures ... vii
1 Introduction... 1
1.1 Requirements for a Research Platform ... 1
1.1.1 Low Cost ... 1
1.1.2 Simplicity ... 2
1.1.3 Open Source ... 2
1.1.4 Code Legibility ... 2
1.2 Real Time Systems ... 2
1.3 Real Time Research Platforms ... 4
1.4 Existing Solutions ... 4
1.4.1 Commercial RTOS... 4
1.4.2 Open Source UNIX derivatives ... 5
1.4.3 RTLinux ... 6
1.5 OSKAR ... 7
1.5.1 Commodity Hardware... 7
1.5.2 Open Source ... 8
1.5.3 Small Code Base ... 8
1.6 OSKAR Features... 9
1.6.1 Hard Real Time ... 9
1.6.2 IP Networking ... 9
1.6.3 Software Clock... 10
1.6.4 Basic I/O Drivers ... 11
1.6.5 Timing... 12
1.6.6 Inter Process Communication... 12
2 Design of OSKAR ... 13
2.1 System Components ... 13
2.2 Phases of Operation ... 14
2.3 Kernel Architecture... 14
2.4 Memory Allocation ... 15
2.5 Semaphores ... 15
2.6 Message Passing ... 16
2.7 I/O Support... 16
2.8 Timing... 18
2.9 Networking... 18
2.10 What Makes OSKAR Measurable ... 21
3 Implementation ... 22
3.1 Execution Environment... 22
3.2 System Calls... 23
3.3 Scheduler... 24
3.4 Clock ... 26
3.5 Semaphores ... 34
3.6.2 Transmission ... 38
3.6.3 Receiving ... 40
3.7 I/O Drivers ... 41
3.7.1 Video Driver ... 41
3.7.2 Keyboard driver ... 43
3.7.3 Serial Driver... 46
3.7.4 Parallel Driver ... 50
4 Experimental Results ... 53
4.1 Functional Qualification ... 53
4.2 Maximum Number of Processes... 53
4.3 Performance Profile ... 57
4.3.1 Context Switch Time ... 57
4.3.2 Interrupt Latency... 61
4.4 Clock Synchronization... 63
4.4.1 Measuring Convergence Times ... 63
4.4.2 Long Term Stability Test... 69
4.5 Application: One-Way Delay Measurement ... 70
4.5.1 Test Conditions ... 71
4.5.2 Expected Results ... 71
4.5.3 Actual Results ... 71
5 Conclusion ... 73
Bibliography ... 74
Appendix A - Clock Synchronization Results ... 77
List Of Tables
Table 3-1 - Variable Name Translations ... 34
Table 4-1 - Maximum Number of Processes ... 56
Table 4-2 - Context Switch Results Summary. ... 61
List Of Figures
Figure 3-1 - Definition of a System Call... 24
Figure 3-2 - Scheduler Code (cont’d) ... 26
Figure 3-3 - Clock Update Routine ... 28
Figure 3-4 - PPS Update Routine ... 31
Figure 3-5 - Semaphore Wait Routine ... 36
Figure 3-6 - Semaphore Signal Code ... 37
Figure 3-7 - Video Driver String Printing Function ... 42
Figure 3-8 - Scrolling Function... 43
Figure 3-9 - Keyboard Table and Handlers ... 44
Figure 3-10 - enqueue_key() Function... 45
Figure 3-11 - getch() System Call... 46
Figure 3-12 - Serial Port Driver Process... 48
Figure 3-13 - Serial Port Read API... 49
Figure 3-14 - Serial Port Write API ... 49
Figure 3-15 - Parallel Port Non-Kernel APIs... 50
Figure 3-16 - par_wait() System Call ... 51
Figure 3-17 - Parallel Port Interrupt Handler... 52
Figure 4-1 - Code Executed for Maximum Process Test. ... 54
Figure 4-2 - Maximum Number of Processes... 56
Figure 4-3 - Code to Measure Context Switch ... 59
Figure 4-4 - Interrupt Latency Measurement Code ... 62
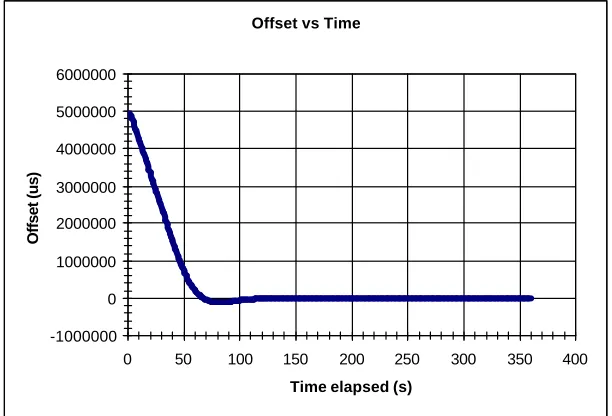
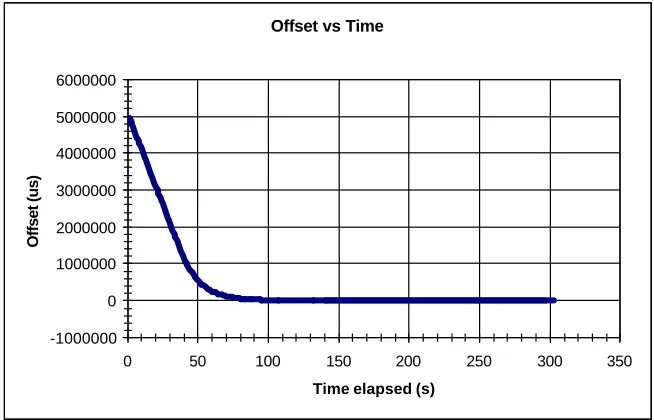
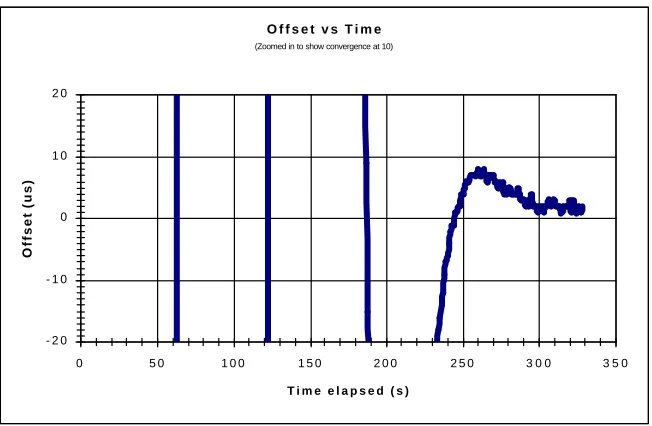
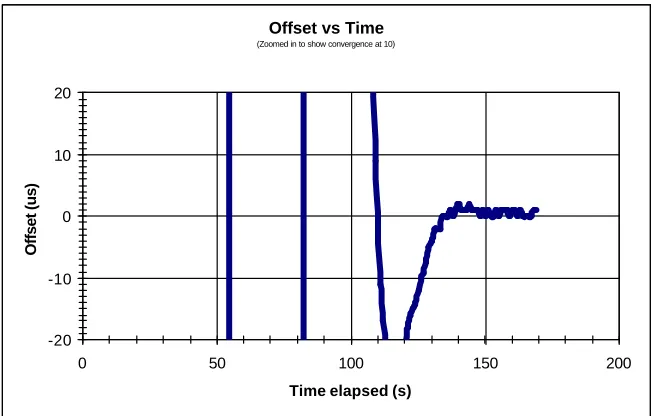
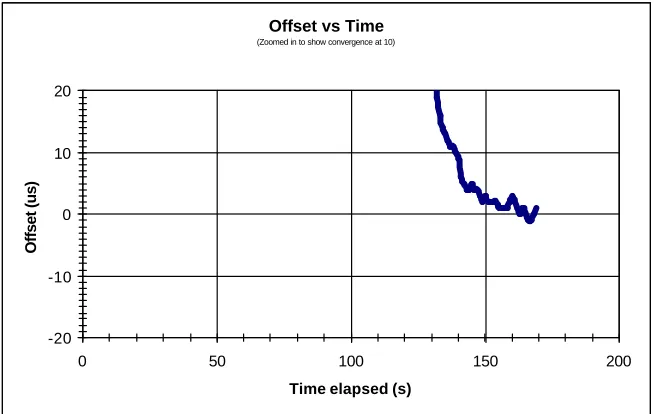
Figure 4-5 - Example of a Convergence Time Graph... 65
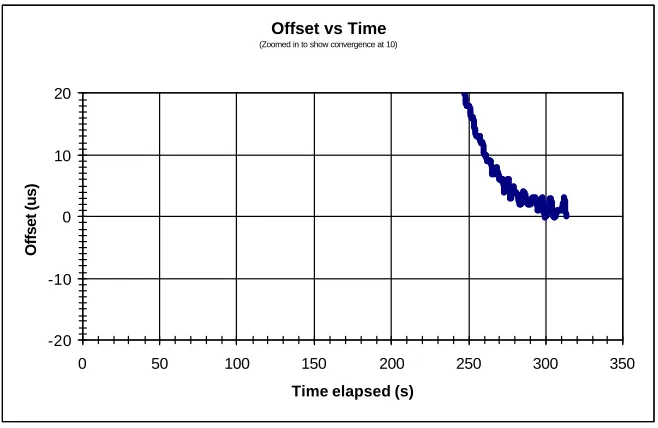
Figure 4-6 - Example of a Detailed Convergence Time Graph ... 66
Figure 4-7 - Clock Synchronization Convergence Times... 68
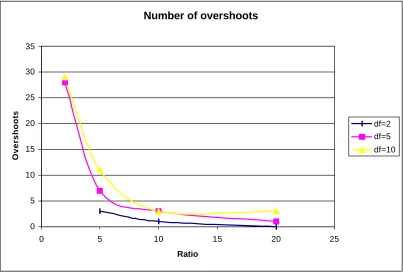
Figure 4-8 - Clock Synchronization Overshoots... 69
Figure 4-9 - OSKAR Output from Long-Term Stability Test ... 70
Figure 4-10 - Histogram of One-Way Delays... 72
Figure A-1 - Offset vs. Time for Test Run 1 ... 78
Figure A-2 - Overshoot Detail for Test Run 1 ... 78
Figure A-3 - Convergence Graph for Test Run 2 ... 79
Figure A-4 - Overshoot Detail for Test Run 2 ... 79
Figure A-5 - Convergence Graph for Test Run 3 ... 80
Figure A-6 - Overshoot Detail for Test Run 3 ... 80
Figure A-7 - Convergence Graph for Test Run 4 ... 81
Figure A-8 - Overshoot Detail for Test Run 4 ... 81
Figure A-9 - Convergence Graph for Test Run 5 ... 82
Figure A-10 - Overshoot Detail for Test Run 5 ... 82
Figure A-11 - Convergence Graph for Test Run 6 ... 83
Figure A-12 - Overshoot Detail for Test Run 6 ... 83
Figure A-13 - Convergence Graph for Test Run 7 ... 84
Figure A-14 - Overshoot Detail for Test Run 7 ... 84
Figure A-15 - Convergence Graph for Test Run 8 ... 85
Figure A-16 - Overshoot Detail for Test Run 8 ... 85
Figure A-18 - Overshoot Detail for Test Run 9 ... 86
Figure A-19 - Convergence Graph for Test Run 10 ... 87
Figure A-20 - Overshoot Detail for Test Run 10 ... 87
Figure A-21 - Convergence Graph for Test Run 11 ... 88
Figure A-22 - Overshoot Detail for Test Run 11 ... 88
Figure A-23 - Convergence Graph for Test Run 12 ... 89
Figure A-24 - Convergence Graph for Test Run 13 ... 90
Figure A-25 - Overshoot Detail for Test Run 13 ... 90
Figure A-26 - Convergence Graph for Test Run 14 ... 91
1 Introduction
This paper outlines the needs for a low cost, hard real time research platform. We examine
several possible existing alternatives and present OSKAR, a simple but capable real time
operating system.
1.1 Requirements for a Research Platform
A research platform is the hardware and software environment in which a researcher’s
experimental software or hardware will run. In effect, the research platform is the
“laboratory” in which computer science experiments are conducted.
1.1.1 Low Cost
Research institutions typically have limited financial resources. So, to have widespread
usefulness, a research platform must be inexpensive. One major area of cost is the licensing
fees for the operating system itself.
An equally important consideration is the cost of the hardware. Systems requiring obscure or
unusual hardware can be costly to obtain. An ideal research platform would be old personal
computers that have become obsolete for desktop tasks and have been replaced. Such
machines can be obtained for little or no monetary expenditure.
Off the shelf hardware is cheaper to maintain as well, for two reasons. First, there is a large
supply of compatible replacement parts. Since personal computers are modular in design,
failed components from older machines can usually be replaced with current production
components. Second, most hardware support personnel are familiar with the platform.
Institutions do not have to hire high priced experts to repair these systems.
Even if the research institution can afford specialized hardware and an expensive OS, such
financial requirements will inhibit the propagation of the work to other individuals or
1.1.2 Simplicity
A research platform should be simple. Researchers writing programs for it should not have
to contend with huge APIs filled with features they do not need. Rather, the system should
be simple and “to the point”.
1.1.3 Open Source
Inevitably, systems need to be expanded. Often times, research projects require the
integration of special hardware that the operating system does not directly support.
Open source systems allow the researcher, or in most cases a trusty assistant, to extend the
system to meet their needs. Not only can more hardware be supported, but defects in the
original implementation can be corrected without the participation of the original authors.
1.1.4 Code Legibility
If one is to take an open source system and extend it to meet one’s needs, the system must be
easily understood. Therefore, an open source research OS should be simple and coded
cleanly. If this is not the case, a programmer trying to extend the system will quickly get lost
and may not be able to perform the task.
1.2 Real Time Systems
A real time system is defined as a system which guarantees deadlines for the execution of
tasks. If a task does not meet its deadline, the system is considered in error.
Real time systems are further divided into hard real time and soft real time systems. In a
hard real time system, missing a deadline is considered a catastrophic system failure. Often,
this is the case with control systems where missing a deadline can cause equipment damage,
or in worst cases injury or loss of life. In a soft real time system, failure to meet a deadline is
considered undesirable, but does not carry the severity it does in a hard real time system.
For a system to be considered hard real time, timing constraints must be placed on the entire
system. The system does not necessarily have to be fast, but it must be predictable. If a
execute the highest priority ready process. Often, designers of general-purpose operating
systems will add mechanisms, such as process aging, to prevent higher priority processes
from “starving” lower priority processes. Rate monotonic scheduling requires such amenities
not be implemented, as they may cause a lower priority process to prevent a higher priority
process from meeting its deadline [LIU73].
The theory of rate monotonic scheduling holds only for independent processes. If two
processes interact using a semaphore, a priority inversion can occur when a low priority
process uses a semaphore that is also used by a higher priority process. If the lower priority
process obtains ownership of the semaphore and the higher priority process preempts it, the
higher priority process will be forced to block until the lower priority process releases the
semaphore. In the mean time, a medium priority process may be allowed to run, causing the
higher priority process to not complete on time.
Priority inheritance protocols are a way of eliminating this problem. There are two such
protocols, the Basic Inheritance Protocol (BIP), and the Priority Ceiling Protocol (PCP). In
the BIP, the lower priority job will have its priority temporarily boosted to that of the highest
priority job that is waiting on the semaphore owned by the lower priority job. When the
lower priority job releases the semaphore, its priority will be returned to normal.
However, the BIP does not prevent deadlocks. If a higher and lower priority job lock
semaphores A and B in a different order, the two can become deadlocked. Also, if a process
accesses semaphores used by a number of other processes, a chain of blocking can occur. A
higher priority process may have to wait for multiple lower priority processes to release locks
on semaphores, increasing the amount of time the higher priority process is blocked. The
PCP prevents both deadlocks and chains of blocking. It establishes a priority ceiling for each
semaphore, which is the priority of the highest priority process that will access the
semaphore. By using this ceiling value, the system will deny requests to lock semaphores
that may cause a chain of blocking or a deadlock [SHA90].
Most general-purpose operating systems are optimized for fast average case performance.
times at the expense of poor worst-case execution times. Real time systems are generally
deterministic, yielding consistent best and worst case execution times.
1.3 Real Time Research Platforms
A real time research platform is a system that meets the requirements for both a research
platform and a hard real time system. It must be low cost, simple, open source, and have a
deterministic kernel, a preemptive priority scheduler, and support priority inheritance
protocols.
1.4 Existing Solutions
1.4.1 Commercial RTOS
There are a number of commercially available real time operating systems. These operating
systems meet the requirements for a hard real time system. They are usually optimized for
embedded work. Some popular commercial real time operating systems are pSOSystem,
VxWorks, and QNX. All three of these systems have very similar feature sets.
All three systems feature a microkernel design. The kernel provides fast, deterministic
context switching. The I/O drivers and most advanced system services are implemented as
processes, rather than inside of the kernel. This allows them to be more modular and to
follow the same preemption rules as user code.
These systems provide priority based scheduling. The scheduler can be configured into first
in first out (FIFO) mode. In this mode, a process runs until a hi gher priority process
preempts it, or it blocks. This type of scheduler allows rate monotonic scheduling. The
presence of this type of scheduler, coupled with deterministic context switch times allows
these systems to be declared hard real time.
These systems also feature an array of synchronization features. All three feature binary
semaphores that use the BIP. pSOSystem also features the PCP for both semaphores and
condition variables. Each of these systems also implements message passing and shared
VxWorks, pSOSystem, and QNX offer complete TCP/IP implementations. The IP, UDP,
TCP, ICMP, IGMP, and ARP protocols are supported. Each system supports Ethernet and
PPP physical layers. The stacks are optimized to minimize the number of times a packet is
copied while the packet is being queued for transmission or received.
Each system also supports a number of commonly used file systems. The systems can use
MS-DOS, UNIX, and ISO 9660 file systems. NFS is also supported for accessing remote file
systems. QNX and VxWorks support specialized file systems for reading and writing files
from solid state flash memory.
POSIX compatibility is also an issue in commercial real time operating systems. POSIX
1000.4 describes a standard API for real time operating systems. Applications written to use
the POSIX APIs are much easier to port to other POSIX compatible systems [GAL94].
pSOSystem and VxWorks have their own proprietary APIs and offer a POSIX compatibility
layer to translate POSIX API calls into the native API. The QNX native API is itself POSIX
compliant.
The major drawback to these systems is that they are quite expensive to license. Being
commercial products they are also not open source. This limits the extensibility of the
system and forces the researcher to rely on the provider for all support and defect repair of
the product.
1.4.2 Open Source UNIX derivatives
In recent years, several open source operating systems, based heavily on UNIX have
achieved great popularity. The most famous of these is Linux. Another popular system is
FreeBSD.
Open source UNIX derivatives offer the researcher a number of advantages over commercial
real time operating systems. Foremost, they require no license fees to be paid. Of equal
importance is the fact that they run on Intel based personal computers which are ubiquitous.
Being open source, these systems are extensible. Additional features can be added and bugs
Unfortunately, these systems are uns uitable for real time work, because none of them are true
real time systems. To implement a real time operating system, real time requirements must
be considered in almost every line of kernel code. Code paths within the kernel must be
short and run in bounded time. None of the popular open source UNIX operating systems
make this guarantee.
A secondary concern is the complexity of the operating system itself. The kernel for Linux
2.2.14 contains over 1.5 million lines of C code. This provides a large array of features for
the end user, but can make modifying the operating system more difficult. Being open
source, the code was written by hundreds of different people, and coding conventions vary
from module to module.
1.4.3 RTLinux
RTLinux [YOD97] is an add-on package for Linux that makes it a hard real time system.
This is an interesting problem, since Linux itself is not hard real time. The kernel is large
and monolithic. Kernel switch times are not deterministic. The scheduler is not a
preemptive priority scheduler; it implements process aging and round robin scheduling,
which is typical of conventional operating system designs.
Rather than trying to modify the Linux kernel to meet hard real time requirements, RTLinux
implements its own kernel. This kernel has a priority preemptive scheduler and deterministic
context switch time. It meets the requirements for a hard real time system. This kernel has
total control of the CPU and hardware. The original Linux kernel runs on top of the
RTLinux kernel, as the bottom priority process.
This design allows any real time process to preempt the Linux process at any time. So, no
matter how slow or unpredictable Linux may be, we can build a hard real time system around
it, because the RTLinux processes are always given higher priority and can preempt Linux at
any time.
Real time processes are considerably different than Linux processes. Rather than the
calls. However, to create a real time process in RTLinux, one must use the
pthread_create() call.
This system’s greatest strength is its ability to fully leverage Linux. Linux has drivers for a
huge array of hardware devices, a world class networking subsystem, a file system, remote
access, a huge runtime library, and many other facilities. An array of resources of that size is
simply not available with real time and embedded operating systems, including OSKAR.
A major drawback is that access to Linux-controlled resources (such as the console, network,
disk drives, etc.) must be coordinated through a Linux process. Real time processes cannot
directly access these devices. Since Linux controls these devices and Linux is not a hard real
time system, no timing guarantees can be made with regards to accessing these devices.
RTLinux provides inter-process communication mechanisms (shared memory and a pseudo
I/O device) that allow real time processes to communicate with Linux processes. However,
the application programmer must coordinate work between the real time and Linux portions
of the system.
RTLinux does have drivers that allow RTLinux processes to access certain pieces of
hardware directly. RTLinux has drivers for the standard serial port, the Tulip PCI Ethernet
driver, and a few data acquisition boards.
1.5 OSKAR
OSKAR (Operating System Kernel for All Real time) is a small real time operating system
that fulfills all of the requirements for a hard real time research platform. It is a simple hard
real-time system that runs on a single, Intel Pentium compatible CPU.
1.5.1 Commodity Hardware
OSKAR runs on Intel based PCs. This is the same family of PCs that run the popular
Microsoft Windows™ operating systems and the venerable MS-DOS™. As an additional
cost savings, OSKAR can be run on systems that are too old to run current versions of
OSKAR requires a Pentium™ -compatible microprocessor. It requires at least four
megabytes of RAM and an NE2000 compatible network interface card (NIC). OSKAR does
not require a hard drive.
In contrast, Windows 2000 requires a Pentium 133 or later and 64 megabytes of RAM
[MS00]. The difference in system requirements between Windows and OSKAR means that
for the foreseeable future, there will be a huge supply of machines that are not able to keep
up with Windows, but can run OSKAR easily. Such hardware can be obtained cheaply, or in
many cases for free.
OSKAR does require a host system running Linux to host the editor, compiler, and remote
booting. However, this system need only meet the minimum requirements for Linux, which
are still considerably less than that of Windows. OSKAR was developed using a host
machine, which contained a 486, 8MB of RAM, and ran Linux. Therefore, there is a large
supply of suitable host machines as well.
1.5.2 Open Source
OSKAR is an open source system. All source code is freely available to the public to
compile, study, or even modify to fit one’s own needs. The kernel is written in C with a few
modules in assembler.
In addition to OSKAR being open source, it is also built on open source tools. The source
code can be compiled with the GNU C compiler (gcc) and GNU assembler (as). These tools
are widely used in the open source community. This means that they are robust, well
supported, and very familiar to most operating systems programmers. All of the tools
necessary to build, deploy, and extend OSKAR come standard as part of Red Hat Linux 6.2.
1.5.3 Small Code Base
The OSKAR system has approximately 5000 lines of C code. It was written by a single
author using a consistent coding standard. The code is well documented, both internally in
comments, and in the included external documentation. It is quite easy for a programmer to
1.6 OSKAR Features
1.6.1 Hard Real Time
OSKAR’s most important feature is the fact that it meets the requirements for a hard real
time operating system. All of the time critical kernel code paths are short and deterministic.
The system has been analyzed and guarantees can be made about its execution time.
OSKAR implements a preemptive priority scheduler, capable of handling both fixed and
dynamic priorities. This allows real time systems to be developed using rate monotonic
scheduling. In addition, priority inheritance protocols are implemented to allow systems with
dependent processes to meet real time requirements. Both the basic inheritance and priority
ceiling protocols are implemented for both fixed and dynamic priority scheduling.
1.6.2 IP Networking
OSKAR supports a subset of the TCP/IP suite of protocols. TCP/IP is the dominant protocol
suite for communication between computer systems. It is the foundation for the modern
Internet. This allows OSKAR to interact with more full featured, general-purpose operating
systems using an Ethernet connection.
OSKAR allows user programs to communicate to other systems using user datagram protocol
(UDP). This protocol is a member of the TCP/IP family of protocols and is understood by
virtually all modern operating systems, including Linux, FreeBSD, Solaris, and Windows.
An OSKAR program can use UDP to send data back to a data-logging program running on a
host computer that runs a more conventional operating system for easier analysis. OSKAR
programs can use UDP to communicate and coordinate activities with other OSKAR systems
as well. If connected to a router, an OSKAR program could send data to and receive data
from a remote host attached via the Internet.
OSKAR supports network booting using DHCP (dynamic host configuration protocol) and
TFTP (trivial file transfer protocol). The network boot loader may be burned into an
1.6.3 Software Clock
OSKAR provides a software clock with mi crosecond resolution. It combines inputs from
several hardware clocks with different characteristics to make a single virtual clock. This
clock is used for all OSKAR timing operations. The clock can be synchronized to a globally
distributed time source.
Many real time systems require the need for a globally distributed time source.
Telecommunications systems often use synchronized clocks to perform time division
multiplexing. Synchronizing clocks can be a difficult problem, especially if the two clocks
are in different geographical areas.
The Global Positioning System (GPS) is one of the most accurate ways to receive time
signals. Each GPS satellite has on board atomic clocks synchronized to the USNO master
clock. A GPS receiver uses the relative phase of a number of these time signals to determine
its position. Once it knows its position, it can adjust the time signals for propagation delay.
This allows a GPS receiver to provide a very accurate time signal.
OSKAR directly supports the connection of an external GPS receiver to a PC running
OSKAR. Not only can the current time be received from the GPS receiver, but also the GPS
measurements are used to discipline the computer’s internal clock to the correct frequency
and phase. Therefore, even if the GPS is disconnected, OSKAR applications have a free
running time base that is still more accurate than one which has never been disciplined.
When the GPS signal is reconnected, the clock will once again be disciplined to the GPS
signal. Any phase and frequency drifts that were encountered during the undisciplined
period will be gradually corrected.
GPS synchronization enhances a system’s hard real time properties. It does so by improving
the system’s ability to measure time. A hard real time system can only make timing
guarantees within the error bounds of its time base. For example, an undisciplined system
may guarantee a certain periodic process will run once per millisecond. However, if this
system measures a real millisecond as only 0.8 milliseconds, then the periodic process will be
1.6.4 Basic I/O Drivers
OSKAR provides I/O drivers for the system keyboard, video display, serial ports, and
parallel ports. The keyboard driver allows OSKAR programs to read ASCII characters from
the keyboard as they are typed by the user.
The video driver allows ASCII text to be displayed to the computer’s monitor. A printf()
function is included to allow easy text and numeric formatting, based on a C programming
language standard. The video driver also includes a text windowing library. This allows
user programs to divide up the available 80x25 character screen space into a number of
independently scrolling windows. A commo n use for this feature is to allow the user to see
messages from two running processes in two different areas of the screen, without their
messages becoming interleaved. Text windowing is also useful for creating control panel
type applications for monitoring multiple variables of a system.
OSKAR provides a serial port driver capable of blocking and buffering. Buffering allows an
OSKAR process to read and write data from the driver in units greater than one byte. This
cuts down on the number of context switches and improves performance of serial I/O. If an
OSKAR process attempts to read the serial port and no characters are available, the process
will become blocked, allowing lower priority ready processes to run. When the system
receives a character, the receiving process is unblocked and the lower priority processes are
preempted. Blocking also occurs if the transmit buffer is full.
The serial driver supports up to four serial ports. The ports are independent; they do not
share any buffers or blocking data. Non-standard I/O addresses and interrupt request levels
(IRQs) can be used, as OSKAR is not limited by the COM1/COM2 standard adopted by
early PCs.
OSKAR’s parallel port driver allows the system to communicate with a printer. The PC
parallel port is really a 16 bit TTL I/O port. It has 4 input lines, 4 output lines, and 8
bi-directional lines. This makes is useful for connecting external hardware that OSKAR can
monitor or send signals to. The OSKAR parallel port driver has calls for accessing hardware
1.6.5 Timing
The OSKAR kernel provides a high-resolution clock based on an aggregate of several
hardware clocks and may optionally synchronize to an external time source. The OSKAR
clock’s resolution is one microsecond.
1.6.6 Inter Process Communication
OSKAR provides several features for inter process communication. Shared memory is
provided. Binary semaphores are implemented to serialize access to shared memory and
other shared resources. Also, a message passing library is implemented to allow serial
2 Design of OSKAR
2.1 System Components
The operating system code is divided into two categories: kernel and non-kernel. Kernel
code is not interruptible and not reentrant. In effect, it runs at maximum priority, above all
non-kernel code. Primarily, the kernel consists of the scheduler, which determines what
process should be running, the context switching code, which makes the chosen process run
after the kernel exits, and the interrupt handlers, which service requests from hardware
devices. Also, the code to initialize the system is contained in the kernel as well.
All non-kernel code must run in the context of an OSKAR process. These processes may be
preempted by a higher priority process, or the kernel itself.
OSKAR applications make use of system services by calling into OSKAR APIs (application
programming interfaces). Some APIs are implemented in the kernel, while others are
implemented in non-kernel code. For example, the semaphore wait operation (sem_wait())
is implemented in kernel code. When a user program calls this API, it generates a software
interrupt. This software interrupt causes a context switch into kernel code. A handler
function inside of the kernel processes the semaphore request. During the course of its
operation, it may change the state of the calling process and cause another process to be
scheduled.
Other APIs, such as the TCP/IP stack are implemented completely in non-kernel code. A
call to the udp_send() API simply calls into the networking library. A handler function in
the networking library encapsulates the data into a properly formed network packet and
places it into the network driver’s send queue. At any point during the execution of this API
(except for a small critical section in the message passing code), the process may be
preempted by a higher priority process.
Some portions of OSKAR are complete processes themselves. They are implemented in
non-kernel code. Containing these parts of the system in their own processes allows them to
run independently of user-supplied code, but still follow the same scheduling rules as all
2.2 Phases of Operation
The OSKAR system goes through three different phases. The first phase is the boot phase.
At this phase, the system is executing boot loader code to load the OSKAR image (including
the user program) into memory.
The second phase is the initialization phase. During the initialization phase, all of the
OSKAR subsystems are set up. All interrupts and I/O are disabled. Interrupt handlers are
put in place. Memory is allocated. Hardware devices are configured. The user’s init()
function is called to allow the user program to change the configuration of the system before
it begins running. The init() function will cause at least one process to be created. Once initialization is complete, the system enters the running phase. During this phase,
OSKAR processes are executed. Interrupts and I/O are enabled. The kernel regulates access
to system resources and schedules the appropriate processes to run according to the
scheduling rules. The system stays in the running phase until the computer is turned off,
rebooted, a halt() instruction is issued, or a fatal exception occurs.
2.3 Kernel Architecture
The OSKAR kernel is designed to be a simple “textbook” kernel. It coordinates execution of
a number of processes. All processes share a single processor. The kernel performs context
switches to change which process is currently executing.
All processes execute in the same address space. All processes have full access to every
other process’ memory. This allows for faster context switching, easier inter-process
communication, and a simpler kernel. It does require the programmer be more careful, as the
operating system cannot prevent memory overwrites from other processes.
Processes may only be created at boot time. Each process has a fixed priority, specified at
creation time. If the system is configured for dynamic priority scheduling, this fixed value is
ignored. The maximum number of processes defaults to 10. A user program may increase
this limit to any reasonable value at boot time, but it must do so before any processes are
Access to the CPU is governed by a scheduler. OSKAR’s scheduler allows for both fixed
and dynamic priority scheduling. The choice of which scheduling algorithm to use can be
specified by the user’s program at boot time.
2.4 Memory Allocation
OSKAR implements a trivial memory allocation scheme. Blocks of memory are allocated
using the allocate() call. This call simply increments a pointer. This allows memory to be
allocated in constant time. However, memory allocated with this call may never be freed.
The allocate() call is used to allocate objects at initialization time (processes, semaphores,
buffers, etc.). Such objects are not allocated after the initialization phase and have no need to
be freed. User programs can also use the allocate() call for memory requests with the
same constraints.
A general-purpose dynamic memory manager, capable of freeing and reusing memory, is not
supplied, because such memory managers are generally not able to run in constant time.
Constant time operations are easily bounded. Any algorithm used in a hard real time system
must be bounded, otherwise it is impossible to guarantee its completion time.
Applications that require the ability to free and reuse memory must implement their own
dynamic memory schemes. Often, it is possible to create a dynamic memory scheme that
does run in constant or bounded time within the context of a specific application. If it is
know that an application only requests certain sized blocks, or only requests a limited
number of them, it is easy to create a specialized algorithm, or bound a generic one. The
message-passing library (see Section 2.6) is an example of a specialized memory manager
that runs in bounded time.
2.5 Semaphores
The kernel provides basic counting semaphores. These semaphores provide wait and signal
operations. In addition, semaphores interact with the scheduler to provide priority ceiling
protocols. Both the BIP and PCP protocols are supported. Like processes, semaphores must
be created at boot time. The maximum number of semaphores defaults to 10, but like the
2.6 Message Passing
OSKAR provides a message-passing library. The message-passing library allows a process
to asynchronously send a block of data to another process. Since the message passing
operations are asynchronous, the sending process need not wait for the receiver to handle the
message before continuing execution.
The message-passing library implements several fundamental objects. A message is simply a
pre-allocated block of memory of a set size. Each message has a “length” field to record the
number of bytes actually used in the message. Messages are created by creating a message
pool. The number and size of messages must be specified at creation time. Once the pool
has been created, messages can be allocated and have appropriate data copied into them.
Messages are passed between processes using message queues. A queue is simply a
collection of semaphores and a linked list of waiting messages. The semaphores are
necessary to ensure serial access to the linked list, allowing the list to be safely accessed by
multiple processes. A sending process sends a message by enqueuing it onto a queue. The
receiving process dequeues it. There are both blocking and non blocking options for the
dequeue operation. The non-blocking version returns immediately if there are no messages in
the queue. The blocking version blocks the receiving process until a message is enqueued.
Once a message is no longer used, it can be freed, allowing it to be used again. Each
message pool maintains queue of free messages. The message allocate operation is actually a
dequeue of the pool’s free queue. Likewise, the free operation is an enqueue to the pool’s
free queue.
Message pools are a limited form of dynamic memory. Since all memory objects are of
equal size, both the allocate and free operations can run in constant time. This allows
their runtime to be predictable, which is a requirement for a hard real time system.
2.7 I/O Support
In a “textbook” conventional OS, all device I/O is done within kernel space. Since the I/O
I/O access to kernel space guarantees serial access to the hardware itself and allows the OS to
prevent user code from having direct hardware access.
This type of I/O creates a priority inversion that is problematic for real time systems. Kernel
code effectively executes at top priority, above the highest priority process. A low priority
process can request a lengthy I/O operation that will prevent higher priority user processes
from running. Even worse, an external device can cause an I/O handler to execute, creating a
priority inversion that was not even triggered by user code. In such a system, rate monotonic
scheduling is not possible.
These types of priority inversions are unacceptable even in conventional operating systems.
These operating systems have ways of attempting to overcome this problem. Linux queues
lengthy requests into a task queue to be handled by a piece of code called the “bottom half”.
[RUB98] The bottom half is basically a second scheduler. It schedules pieces of work that
are done on behalf of the interrupt handler, but run with interrupts enabled. Such a system
gives acceptable performance for a conventional OS, but is very difficult to model for rate
monotonic scheduling, since there are two schedulers instead of one.
OSKAR adapts a microkernel-like approach [SIL94]. I/O drivers still have interrupt
handlers, but they are kept extremely simple and execute quickly. A driver process performs
the bulk of the work. In most cases, the interrupt handler simply acknowledges the interrupt
and unblocks the driver process.
The driver process is an OSKAR process. The process is automatically created by the driver
when the driver’s initialize routine is called by the user’s application. It is usually necessary
for the user’s application to specify a priority for the driver process as an argument to the
initialize routine. This priority is used as a fixed priority to schedule the driver process when
the system is configured for fixed priority scheduling. This means it is entirely possible (and
many times desirable) for user code to preempt the device driver. This can happen whenever
a user process has a higher priority than the priority assigned to the device driver.
OSKAR processes have full access to the hardware, so the driver process can do all of its
using the scheduler. The driver process delivers data to and from user processes using one of
OSKAR’s inter-process communication mechanisms.
2.8 Timing
OSKAR’s time sources are the Pentium cycle counter, the 8254 timer chip, and the CMOS
real time clock. The cycle counter provides a high-resolution, undisciplined time source.
The 8254 is a lower resolution time source, but it is capable of producing interrupts. The
CMOS clock is non-volatile, so it keeps running even when the machine is powered off.
The OSKAR clock combines all of these time sources to make a virtual clock that has high
resolution, is disciplined, can generate interrupts, and is non-volatile.
External synchronization is done via a pulse per second (PPS) signal from external hardware.
OSKAR slews the frequency of its internal clock so that the frequency and phase differences
between the PPS signal and OSKAR’s internal clock approach zero.
2.9 Networking
OSKAR provides two distinct areas of network functionality. The first is network booting.
This is accomplished using a third party open source tool called etherboot. Etherboot is a
bootstrap loader that is loaded from a boot floppy or a ROM. It makes a DHCP request to
obtain an IP address for itself. Then, it contacts a TFTP server and downloads the OSKAR
system image into memory and executes it.
The rest of the network functionality is implemented in OSKAR’s networking subsystem.
This consists of an Ethernet driver and a protocol stack. The Ethernet driver currently
supports only NE2000 compatible network cards. These are far from being the fastest cards
ever manufactured, but they are widely available and inexpensive ($14 each). OSKAR’s
driver and driver interface are adapted from the etherboot source, so it is not difficult to add
support for any card etherboot supports.
OSKAR’s protocol stack supports a subset of the TCP/IP protocol suite. User programs may
send and receive UDP datagrams. This allows an OSKAR system to communicate with
Address Resolution Protocol (ARP) protocol is implemented. OSKAR also supports sending
and receiving broadcast packets.
Traditional operating systems usually implement the IP stack inside of the kernel. This type
of implementation is problematic in a real time system. The problem is best demonstrated
using an example. Suppose that a real time system has two processes. Process A operates a
dangerous pneumatic drill, while process B answers IP requests for current weather
conditions. Using rate monotonic scheduling, we determine that process A needs to have a
higher priority than B, since it needs to check the position of the drill bit 20 times a second,
while the response time of weather requests need not be guaranteed. Since the receipt and
transmission of IP packets is implemented in the kernel, which preempts all user processes, it
is possible for those network operations to preempt process A, possibly causing it to miss a
deadline.
OSKAR’s IP stack is implemented completely in non-kernel code. Most of the work of
preparing IP packets to be transmitted and unpacking received packets runs in the context of
the calling process. The physical transmission and receipt of packets is handled in the
Ethernet adapter’s driver process. Shuttling of the packets to and from the Ethernet driver’s
process is handled using the message passing library.
Since the IP stack is implemented in non-kernel code, all network operations are subject to
preemption by the scheduler. As long as process A had a higher priority than the Ethernet
driver process (whose priority is set by the user’s application), network requests would
never preempt process A. Instead, those requests would be handled by process B and the
Ethernet driver process when the scheduler allowed them to execute.
It is important to note that the IP protocol itself was not designed to meet hard real time
requirements. It does not make any guarantees about the timeliness of message receipt or
delivery.
One barrier to real time IP is the Ethernet medium itself. If two hosts attempt to transmit at
the same time, each host will wait a random period of time and retry [STE94]. A random
guarantee the retry will not produce another collision. So, we must settle for a “soft” real
time requirement. A lightly loaded Ethernet segment will have few collisions.
Another real time culprit is the ARP. This is a protocol used to translate IP addresses into
Ethernet addresses. When a packet is transmitted, the following steps are taken [STE94]:
1. Look up the IP address in an in-memory table (the ARP cache). If found, use the
Ethernet address in the table.
2. If not found, broadcast an ARP request packet to all hosts on the local Ethernet
segment. (Who has IP address aaa.bbb.ccc.ddd?)
3. Wait for an ARP reply packet from the owner of the IP address. If received, add the
ARP entry to the cache and use its Ethernet address (I have IP address
aaa.bbb.ccc.ddd my Ethernet address is xx:xx:xx:xx:xx:xx).
4. If no reply is received within a given period of time, drop the transmitted packet.
This algorithm has several real-time unfriendly aspects. First of all, any time a cache is
involved, the algorithm becomes stochastic rather than deterministic. The first time a packet
is sent to a host, it will take a long time. Each successive send will be quick, as long as the
cache entry is kept current. In order to bound it, you must find the worst case time. But, this
can not be computed either, because a foreign host (possibly running a non real-time
operating system) must produce the reply. Also, there is the possibility of collisions on both
the ARP request and ARP reply. So, it is difficult to come up with an upper bound less than
the ARP timeout value.
OSKAR has a solution to this problem. The IP layer can be configured to not use ARP. In
this mode, if the IP address is not found in the ARP table, the packet will be sent to the
Ethernet broadcast address. Also, the user can force static entries into the ARP table, which
2.10 What Makes OSKAR Measurable
Much of OSKAR’s performance profile can be determined by executing test routines in user
space against the OSKAR kernel. Such a measurement is performed in Section 4.3.1 to
determine the context switch time. Some performance measurements are made by the system
and can be read using a system call. An example of this type of measurement is performed in
Section 4.3.2 to determine the interrupt latency.
Most operations can be timed using OSKAR’s internal clock. OSKAR’s clock provides
microsecond accuracy. Since the OSKAR clock can be calibrated to a GPS, performance
3 Implementation
3.1 Execution Environment
OSKAR executes on Intel based personal computers. It requires a Pentium compatible
processor. The processor runs in Protected mode. It uses the Intel “flat” memory model. All
physical memory is mapped into one 4GB address space, which is shared by all processes. In
this regard, processes are more like threads, whereas conventional operating system
processes have their own address spaces. The processor’s segment registers are locked to
fixed values and not switched as part of a context switch.
For performance and simplicity, most of the processor’s security mechanisms are disabled.
Any process may access any other process’ memory, or the system memory. This eliminates
the need to do expensive context switches to access data common to the system and
application processes.
The floating-point features of the processor are supported. A context switch between two
processes will save the floating-point registers of the old process and load the values last
saved with the new process.
Context switch functionality is spread over a number of functions. All context switches
initiate with an interrupt. Interrupts are generated either by hardware when it needs the OS to
perform an action, or by user code when it needs to make a system call. The processor
handles the interrupt by pushing the EIP and EFLAGS registers to the stack, disabling further
interrupts, and calling an interrupt handler. All OSKAR interrupt handlers share almost
identical entry and exit code. This is assembly code is defined in system.S. The interrupt handler will push the remaining registers onto the stack in a set order using the PUSHA
instruction. Then, the stack pointer is stored in the current running process’ PCB. Next, the
stack register is set to point to a system stack. Since all interrupts are handled serially, one
common system stack will suffice. Next, the entry code makes a call into a C function that
does the “real work” of handling the interrupt. Most C interrupt handlers make a call to the
schedule() function. This function determines which process should be running and sets
When the C interrupt handler returns, the exit code reads the stack pointer value from the
current process’ PCB. The current process is determined by reading the value of pid, which
may have been changed by the handler. Once the stack pointer is reset, a POPA instr uction
is executed. This retrieves the correct register values for the process that should be running
from that process’ stack. Lastly, the IRET instruction is executed, which restores the EIP and
EFLAGS registers. This causes the processor to resume execution at the point where the new
current process was last interrupted. The processor’s interrupt mask is stored in the EFLAGS
register, so the IRET call will also re-enable interrupts.
3.2 System Calls
As described in Section 2.1, some OSKAR APIs are implemented in kernel code. To call
these functions from a user process requires a special mechanism to switch the system into
kernel mode.
The kernel call is implemented as a C function in the OSKAR kernel source. The function
definition is preceded by a K_CALL() macro, which takes the name of the system call as a
parameter. Next, the function is declared. The function implementing the system call must
begin with the letter k, followed by an underscore, followed by the name of the system call.
Prepending k_ to the name is necessary because user code must not call this function directly.
When OSKAR is compiled, the script gen_kcalls.pl searches all source files and finds all instances of the K_CALL() macro. In turn, this script generates a stub function, whose name
is the same as the system call name. The stub function switches the system to kernel mode
and then calls the implementation (k_) function. After the implementation function returns,
the stub function switches the system back to user mode.
Figure 3-1 is an example of the sleep_until system call. User code will call into the sleep_until() function, which is generated as a result of the K_CALL(sleep_until)
macro. After switching the system to kernel mode, sleep_until() calls the implementation
K_CALL(sleep_until)
void k_sleep_until(timestamp_t wakeup) {
pcb[pid].wakeup = wakeup; pcb[pid].state = state_sleep; schedule();
}
Figure 3-1 - Definition of a System Call
3.3 Scheduler
The scheduler code is listed in Figure 3-2. Every interrupt handler makes a call to the
scheduler, normally near the end of the interrupt handler’s execution. First, it records the
elapsed time since the last time it was called and adds this value into the PCB’s cpu_time
field. Next, it iterates through all available processes. Each running or ready process is
considered. If the system is configured for fixed priority scheduling, the process with the
lowest value of eff_pri in its PCB is selected. If dynamic scheduling is used, the process
with the soonest timestamp value for the deadline field in the PCB is selected. In the event
of a tie, the process with the highest PID is chosen. This corresponds to the process created
last.
All processes are visited in this loop. It never terminates before visiting all processes. This
helps give it a more constant run time and makes it easier to predict.
Once the new running process is selected, the global variable pid is set to the id of the
selected process. If the new process is not the same as the old process, the floating point
void schedule() {
static timestamp_t last_call = 0; timestamp_t now = get_time_exact();
int new_pid = n_processes - 1; // Which pid to activate next // Default to "idle" process
int i;
static int n = 0; n++;
// Record statistics if (pid != pid_none) {
pcb[pid].cpu_time += now - last_call; }
last_call = now;
// Choose a new process
for (i = 0; i < n_processes - 1; i++) {
switch (pcb[i].state) {
case state_running: case state_ready:
if (scheduler_type == scheduler_fixed) {
if (pcb[i].eff_pri < pcb[new_pid].eff_pri) {
new_pid = i; }
} else {
if (pcb[i].deadline < pcb[new_pid].deadline) {
new_pid = i; }
} break; default:
/* Ignore */ }
}
// Switch new pid into context if (pid != new_pid)
{
assert(new_pid >= 0 && pid < n_processes); if (pid != pid_none)
{
// Switch out old process pcb[pid].sp = user_sp;
if (pcb[pid].state == state_running) pcb[pid].state = state_ready; save_fpregs(&pcb[pid].fpregs); }
// Switch in new process pid = new_pid;
user_sp = pcb[pid].sp;
pcb[pid].state = state_running; restore_fpregs(&pcb[pid].fpregs); }
last_call = now; }
Figure 3-2 - Scheduler Code (cont’d)
3.4 Clock
OSKAR keeps time using a number of time sources. The primary source of time is the
Pentium processor’s cycle counter. This is a 64-bit counter that accumulates the number of
clock cycles since the system was booted. It is extremely useful for a number of reasons.
First of all, it is very precise. On a 100 Mhz computer, the cycle counter will have a 10 ns
resolution. Second, it never overflows. On a 100Mhz computer, it would take 5,845 years
for the clock to overflow. Third, it can be read with a single CPU instruction. Hardware
timers often require the processor to wait a number of cycles before the result can be read.
The cycle counter alone cannot be used as the time source. Its value cannot be set. At
minimum, a timestamp of the system’s boot time needs to be added to it for it to return “real”
time. Its frequency cannot be directly adjusted. Its frequency varies from system to system,
as different model PCs have different clock speeds. It cannot generate interrupts, which
All PCs contain another hardware timer called the 8254 [IBM85]. This timer runs at a much
lower frequency, roughly 1Mhz. This frequency is the same for all PCs (within a tolerance).
This timer has a decrementing counter attached, which can be configured to generate an
interrupt when it reaches 0. The OS can set its initial value, and it can be configured to
automatically re-trigger itself when it reaches 0. So, this chip divides the frequency of the
1Mhz oscillator and generates processor interrupts at that frequency.
Neither of these timers are synchronized to an external time source. Both use extremely
cheap oscillators, whose frequency tolerances can cause drift of several seconds per day.
One way to solve this problem would be to connect an atomic clock to the PC and use it as an
additional time source. However, this is an extremely expensive proposition.
GPS receivers, however, do provide a globally distributed time source based on a collection
of atomic clocks. The output of a GPS receiver is within 50µs of UTC. OSKAR can use a
GPS receiver as an additional time source, providing OSKAR applications with a clock of
similar tolerances.
OSKAR combines these three time sources to make a software virtual clock that has the
benefits of all three. OSKAR’s software clock uses the convenient base unit of
microseconds. Absolute times are reported as the number of microseconds since the epoch.
OSKAR uses the UNIX epoch of January 1, 1970.
The 8254 interrupt frequency can be set at boot time by calling the system call
set_pd_clk().
OSKAR’s clock works by periodically updating a global variable called cur_time. This update is performed as a result of the 8254 timer generating an interrupt. This interrupt is
handled by the timer_intr() function in timer.c (see Figure 3-3). cur_time contains the number of microseconds since the epoch. Each time an 8254 interrupt occurs, a number of
void timer_intr(int intno, struct regs *regs) {
timestamp_t cycle; int i;
/* Record interrupt latency */
latency_buffer[latency_buffer_pos] = pd_clk + get_cal_time() - 65536; latency_buffer_pos = (latency_buffer_pos + 1) % LATENCY_BUFFER_SIZE; /* Read the cycle counter */
cycle = get_cycle_count();
/* Wiggle interrupt controller bits */ outb(0x20, 0x20);
/* Update cur_time */
remainder += nanos_elapsed(cycle - last_cycle); cur_time += remainder / 1000;
remainder = remainder % 1000;
/* Allow "new" phase_adjust value to take effect */ last_freq = eff_freq;
last_cycle = cycle;
// Resume any processes waiting on their // deadlines
for (i = 0; i < n_processes; i++) {
if (pcb[i].state == state_wait_period && pcb[i].deadline < cur_time)
{
pcb[i].deadline = pcb[i].next_deadline; pcb[i].state = state_ready;
}
else if (pcb[i].state == state_sleep && pcb[i].wakeup < cur_time) {
pcb[i].state = state_ready; }
}
schedule(); }
Figure 3-3 - Clock Update Routine
Each time a timer interrupt is received, the Pentium cycle counter is read into the variable
elapsed since the last timer interrupt. This value is multiplied by one billion and divided by
last_freq, to compute the number of nanoseconds elapsed since the last interrupt.
This value cannot be directly added to cur_time, because cur_time is specified in
microseconds. The global variable remainder is used to extend the precision of cur_time to
the nanosecond level. This helps prevent the accumulation of round off errors. The number
of nanoseconds elapsed is added to remainder. remainder is divided by 1000. The
quotient is added to cur_time, and the variable remainder becomes the remainder of that division.
At system boot time, the frequency of the cycle counter is measured against the 8254 clock.
This value is stored in the variable freq, which is never modified. It is also used as the
initial value for last_freq. However, if OSKAR is synchronizing to an external source, last_freq will be adjusted to make phase and frequency corrections in the clock.
The system call get_time() is used to report the current time (in µs past the epoch) to user programs. This call returns the value of cur_time. While cheap to execute, this version’s
precision is limited by the frequency of the 8254 timer. For more demanding applications,
get_time_exact() must be called. It returns a more accurate version by reading the cycle
counter and performing the same calculations as the interrupt handler to compute a new value
of cur_time. It is important to note that get_time_exact() does not actually modify any of
the variables, rather it returns what cur_time’s value would be if an interrupt occurred at that instant.
A potential problem emerges here. last_freq is being constantly changed. What if a process called get_time_exact() two times consecutively, returning t1 and t2? What if
between the first and second calls, the system made a frequency adjustment, slowing down
the clock frequency? Since the second call is using a lower divisor than the first call, t2
could have a lower (earlier) value than t1. This would make the clock non-monotonic, as
This does not happen in OSKAR, because the clock adjustment code is not allowed to
directly modify last_freq. Instead, it must modify the variable eff_freq. At the end of
each timer interrupt, the value of eff_freq is copied to last_freq.
OSKAR’s external clock synchronization algorithm is based loosely on the NTP (network
time protocol) algorithm described by Mills [MIL94]. Like the NTP algorithm, it uses a
modified phase locked loop (PLL) to adjust the phase and frequency of the internal clock to
match the external source. Unlike NTP, the OSKAR algorithm only deals with pulse per
second (PPS) signals. NTP is optimized to work accurately with sporadic updates whose
periods range from 1 second to 2 seconds. NTP also uses integer math for all calculations, 16
while OSKAR uses floating point. This was done to allow the algorithm to be easier to
program and more accurate. Since the synchronization code only runs once per second, a
few floating point operations is an acceptable overhead.
The GPS receiver interfaces with the OSKAR clock in two places. Once a second two events
occur. First, the GPS receiver sends a pulse through its PPS output, which should be
connected to the computer’s parallel port. Second, it outputs the current UTC time (as of the
last pulse) to the serial port, which should be connected to a serial port on the computer.
When the system is booted, the system time must be stepped to a value that is approximately
UTC, by calling the set_time() function. The function gps_get_time() will return the UTC time last transmitted by the GPS. Passing the value from gps_get_time() into set_time() will cause the clock to be set to a value that is at most one second behind UTC. An OSKAR process must monitor the PPS signal using the par_wait() system call. When
the GPS signals the computer’s parallel port, the interrupt handler will immediately call
get_time_exact() and store its value. This is the observed time of the PPS event. Next, it
will cause the par_wait() call to unblock. The monitor process calls the pps() function (see Figure 3-4). The pps() function requires two parameters, the observed time of the PPS
event, according to the computer, and the real time the PPS event occurred, according to the
void pps(timestamp_t observed_time, timestamp_t real_time) {
int64 new_freq = 0;
// Compute periods of real and observed timestamps observed_period = observed_time - last_observed_time; real_period = real_time - last_real_time;
// Make sure pulse falls within acceptable boundaries
if (observed_period > 800000 && observed_period < 1200000 && real_period > 800000 && real_period < 1200000)
{
last_pps_status = PPS_GOOD;
// Compute offset and adjustment values offset = observed_time - real_time;
phase_adj = ((double) offset) / ((double) real_period); phase_adj /= pps_params.phase_divisor;
freq_adj =
(((int) observed_period) -
((int) real_period)) / ((double) real_period); freq_adj /= pps_params.freq_divisor;
// Compute new frequency using adjustments new_freq = eff_freq;
new_freq += (freq_adj * (double) eff_freq); new_freq += (phase_adj * (double) eff_freq); // Apply clamping and set eff_freq
if (new_freq < min_freq) eff_freq = min_freq; else if (new_freq > max_freq) eff_freq = max_freq; else
eff_freq = new_freq; }
else {
// Last pulse was bad. Ignore it last_pps_status = PPS_BAD;
}
// Remember timestamps for next iteration last_observed_time = observed_time;
last_real_time = real_time; }
Figure 3-4 - PPS Update Routine
The pps() function makes a number of calculations. First, it computes a real and observed
period, by subtracting the current and previous values of real and observed time respectively.
real_period will not equal 1 second. If the observed period is less than 800ms or greater than 1200ms, the pulse is thrown out as well. This type of problem can result from line noise
or a faulty GPS receiver.
Next, the offset is computed. The offset is the difference between the observed and real
times of the PPS event.
Two measurements of the “correctness” of the observed signal are made: a phase
measurement (aφ) and a frequency measurement (af ). These measurements are computed
as follows:
(
r r)
r o t t t t a − ′ ′ − ′ = φ
(
)
(
)
(
r r)
r r o o f t t t t t t a − ′ − ′ − − ′ =
To demonstrate the necessity of two measurements, let us look at each measurement
independently. If only the frequency differences of the two signals were used to adjust the
frequency of the OSKAR clock, then we would have a frequency locked loop (FLL). This
would guarantee the two clocks were ticking at the same rate, but their relative times would
continue to be off. Thus, the clocks would never converge.
If only the phase difference were used (as was done in an earlier attempt at this algorithm), a
subtle problem emerges. Consider the case where both clocks are running at exactly the
same frequency, but the OSKAR’s clock is one second ahead of the GPS. OSKAR would
detect a phase difference of 1,000,000 ìs and begin slowing the clock down. Closing the gap
between the two takes a number of seconds. With each PPS pulse, the phase difference is
measured again. In each case, the OSKAR clock is still ahead, so OSKAR will continue to
reduce the frequency of its internal clock. Finally, the two clocks will converge and their
phase difference will be zero. However, at this instant, their frequencies are considerably
different. One second later, OSKAR will be behind the GPS clock. It would begin speeding
up and the phases would converge, only to overshoot again. With the right damping factors,
this system would eventually converge, but it will take much too long. As the phase offset