ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
Semantic Web crawler on Hypertext records
E.Sandeep Krupakar 1, Dr.A.Govardhan2
M. Tech, Sap Basis Consultant Hyderabad, India1 Ph.D, Professor Dept. of CSE & Principal, JNTUH, India2
ABSTRACT: The primary indicate of the examination is to contemplate and comprehend the ideas of semantic web mining and web crawlers. Regular tens to a huge number of web data are caused and they answer a huge number of inquiries. Current web mining approaches utilize monstrous measures of ware equipment and preparing time to use investigation for the present web. For a consistent application collaboration, those methodologies need to use pre-totaled outcomes and files to go around the moderate preparing on their information stores e.g. social databases or report stores. Hypertext records contain content and for the most part insert hyperlinks to different archives dispersed over the Web. Today, the Web includes billions of records, wrote by a great many various individuals, altered by nobody specifically, conveyed more than a large number of PCs which are associated by phone lines, optical strands, and radio modems. The most central thing is web search tool to test the execution, nature of the outcomes and office to creep, and file the web effectively. The essential objective is to give top notch list items over a quickly developing World Wide Web in semantic web mining and to download the data from web creeping is required. This exploration work went for how the data's are removed from the web using crawler strategy and concentrate the examination territories of semantic web mining.
KEYWORDS: Semantic web, Web crawler, Hypertext records, Web mining
I. INTRODUCTION
The Ecumenical Web is the most hugely goliath and most unmistakable store of hypertext. Hypertext archives contain content and by and large implant hyperlinks to different records circulated over the Web. Today, the Web contains billions of records, wrote by a large number of different individuals, altered by nobody specifically, circulated more than a huge number of PCs which are associated by phone lines, optical strands, and radio modems. It is a ponder that the Web works by any stretch of the imagination. However it is quickly profiting and supplementing daily papers, radio, TV and phone, the postal framework, schools and universities, libraries, physical working environments, and even the destinations of business and administration.
A short history of hypertext and the Web: Citation, a type of hyperlinking, is as old as indited dialect itself. The Talmud, with its awkwardly weighty use of explanations and settled editorial, and the Ramayana and Mahabharata, with stretching, non-straight talk, are age-old cases of hypertext. The lexicon and the reference book can be seen as independent systems of printed hubs joined by referential connections. Words and ideas are portrayed by engaging different words and ideas. In current circumstances (1945), Vannevar Bush is credited with the main plan of a photoelectrical-mechanical capacity and processing contraption called a Memex (for "memory expansion") which could induce and benefit take after hyperlinks crosswise over records. Doug Engelbart and Ted Nelson were other early pioneers; Ted Nelson authored the term hypertext in 1965 [1] and induced the Xanadu hypertext framework with powerful two-way hyperlinks, variant administration, discussion administration, explanation and copyright administration.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
II. RELATED WORK 2.1 Crawling and ordering
We might visit a cosmically enormous assortment of projects which process printed and hyper textual data in various ways, yet the ability to quickly get a monstrously gigantic number of Web pages into a nearby storehouse and to list them predicated on catchphrases are required in numerous applications. Cosmically huge scale programs that bring a huge number of Web pages every second are called crawlers, arachnids, Web robots or bots. Slithering is generally performed to in this way file the archives got. Together, a crawler and a list shape key segments of a web index. Numerous others took after the internet searcher pioneers, and had sundry advancements to offer. HotBot and Inktomi highlight an appropriated design for creeping and putting away pages. Invigorate could dissect related characteristic amongst watchwords and match inquiries to archives having no syntactic match. Many web search tools started offering a "more like this" connection with every replication. Web crawlers stay probably the most went by locales today.
Numerous others took after the internet searcher pioneers, and had sundry developments to offer. HotBot and Inktomi highlight a conveyed engineering for creeping and putting away pages. Elate could break down related quality amongst watchwords and match questions to reports having no syntactic match. Many web crawlers initiated offering a "more like this" connection with every replication. Web crawlers stay probably the most went by locales today.
2.2 Clustering and assignment
Point registries worked with human exertion, (for example, Yahoo! or, on the other hand the Open Directory) quickly bring up the issue: would they be able to be developed naturally out of a formless corpus of Web pages, for example, amassed by a crawler? We contemplate this pickle, called grouping or unsupervised learning, in Chapter 4. Generally verbalizing, a bunching calculation finds bunches in the arrangement of archives to such an extent that reports inside a gathering are more homogeneous than records crosswise over gatherings. Bunching is a traditional region of machine learning and example apperception [2]. Be that as it may, a couple of difficulties emerge in the hypertext area. A fundamental predicament is that diverse individuals don't acquiesce about what they anticipate that a grouping calculation will yield for a given informational index. This is somewhat in light of the fact that they are verifiably using diverse related quality measures, and it is exhausting to guess what their homogeneous property measures are on the grounds that the quantity of characteristics is so cosmically huge. Hypertext is withal wealthy in highlights: printed tokens, markup labels, URLs, have names in URLs, substrings in the URLs which could be vital words, and host IP addresses, to assign a couple.
2.3 Hyperlink examination
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
connecting styles. Aside from algorithmic research, we might cover strategies for Web measurements and famous outcomes there from.
III. WEB CRAWLING
A Web crawler is a program that naturally crosses the Web's hyperlink structure and downloads each connected page to a nearby stockpiling. Creeping is regularly the initial step of Web mining or in building a Web internet searcher. But thoughtfully effortless, building a down to earth crawler is by no betokens basic. Because of proficiency and numerous different concerns, it includes a lot of designing. There are two sorts of crawlers: ecumenical crawlers and point crawlers [7]. An ecumenical crawler downloads all pages regardless of their substance, while a subject crawler downloads just pages of specific points. The exhaustingness in theme creeping is the means by which to agonize such pages. Web crawler is an Internet that methodically peruses the World Wide Web, ordinarily for the imply of Web ordering. It furthermore called as Web bug, a subterranean insect, a programmed indexer, Web Scatter.
Algorithm of a crawler
Begin with seed page {
Make a parse tree
Concentrate all URL's of the seed tree (front connections) Cause a line of removed URL's
{
Get the URL"s from the line and emphasize }
} }
Terminate with success
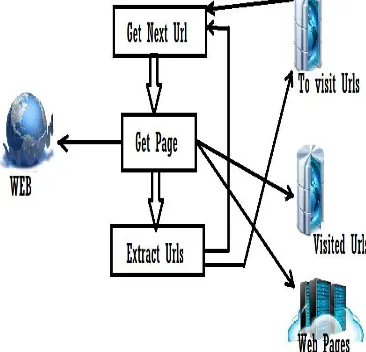
Web crawlers and some different locales utilize Web slithering or spidering programming to refresh their web substance or files of others destinations' web content. Web crawlers can repeat every one of the pages they visit for later preparing by an internet searcher that files the downloaded pages with the goal that clients can test them substantially more quickly [19]. The figure 1 demonstrates that the engineering of a web crawler.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
IV. WEB CRAWLING TECHNIQUES 4.1. Appropriated Crawling
Ordering the web is a test because of its developing and dynamic nature. As the extent of the Web is developing it has turned out to be basic to parallelize the slithering procedure with a specific end goal to come full circle downloading the pages in a conceivable term. A solitary creeping process is insufficient for sizably voluminous – scale motors that need to get sizably voluminous measures of information quickly. At the point when a solitary incorporated crawler is used all the brought information goes through a solitary physical connection. Conveying the creeping action through numerous procedures can profit fabricate an adaptable, easily configurable framework, which is blame tolerant framework. Part the heap diminishes equipment necessities and in the meantime builds the general download speed and unwavering quality. Each assignment is performed in a plenarily conveyed manner, that is, no focal facilitator subsists [1].
4.2 Focused Crawling
A general imply Web crawler gathers the greatest number of pages as it can from a specific arrangement of URL's, Where as an engaged crawler is intended to just store up reports on a solid point, in this manner lessening the measure of system movement and download. The objective of the engaged crawler is to specifically search out pages that relate to a pre-characterized set of themes. The points are assigned not using watchwords, but rather using model archives. Instead of amassing and ordering all available web archives to have the capacity to answer all conceivable specially appointed inquiries, an engaged crawler investigates its creep limit to discover the connections that are at risk to be most fitting for the slither, and dodges incidental locales of the web.
This prompts vital funds in equipment and system assets, and benefits keep the creep more up to date. The engaged crawler has three primary parts: a classifier, which makes relevance judgments on pages, slithered to settle on connect development, a distiller which decides a measurement of centrality of crept pages to decide visit needs, and a crawler with powerfully reconfigurable need controls which is represented by the classifier and distiller [6].
4.3 WEB CRAWLING CHALLENGES
The basic web slithering calculation is basic: Given an arrangement of seed Uniform Resource Locators (URLs), a crawler downloads all the site pages tended to by the URLs, separates the hyperlinks contained in the pages, and iteratively downloads the website pages tended to by these hyperlinks. Notwithstanding the apparent effortlessness of this crucial calculation, web creeping has numerous intrinsical difficulties [6]:
i). Scale. The World Wide Web is significantly and gigantically enormous and ceaselessly advancing. Crawlers that look for wide scope and great freshness must accomplish cosmically high throughput, which postures numerous laborious designing pickles.
ii). Content separate tradeoffs. Indeed, even the most noteworthy throughput crawlers don't indicate to creep the entire web, or stay aware of the considerable number of transmutations. Rather, slithering is performed specifically and in a carefully controlled request...
iii). Jovial commitments. Crawlers ought to be good citizens of the web, i.e., not force a luxurious measure of an encumbrance on the sites they slither.
V. WORKING OF CRAWLER
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
Fig 2. Searching by crawler
Once a page is fetched it is then kept into a local repository and its URL is normalized. This avoids revisiting to the same page. Normalization of URL’s is done in many ways like the URL is converted to lower case or the initials of the URL’s are in upper case. The crawler has to crawl many local servers with the same algorithm hence it is really difficult as it has to deal with many problems. URL Normalization is important step in Optimization so as web search engines only pick the meaningful page. Normalization or Canonicalization is also a major issue as search as many website points to same link, so to select the best among them is required to be done. This is done according to the bro There are many normalization that preserves the semantics of the web page and some normalization disturbs the semantics of web, it is important to select the best normalization technique.
5.1 Page Rank and returning to
An internet searcher looks through a page by its page rank. i.e. by its incentive in the WWW. Page rank assigns "how much justified regardless of a website page is". It uses some page rank calculation for it other than just content coordinating the inquiry. Page rank might be doled out by the recurrence of time the hunt term shows up on the site page or the no. of locales that connect to the site page. The more streamlined a site page is the better is its page rank. Page rank of a page is ascertained as
Where d is damping factor whose esteem is taken between 0-1. t1… .tn are the no of connections to our page and C(tn) is the no. of connections leaving the page. So a page having better page rank is brought by the crawler and showed. Moreover another factor called P esteem decides the significance of the page it is computed as
= . − . k
Where PV is the page Value and F joins are the Forward connections and B joins are the rearward connections. The most elevated PV is given the need , a page can even have 0 PV. i.e. minimum need.
Again a few indicates that the crawler has manage is as the web is exceptionally powerful in nature so it is required to return to the page and check for refreshing. So a portion of the crawlers cost is incorporated to return to the page. This include the age of the page and the freshness of the page. The page ought not be antiquated and ought to have greatest freshness .This return to strategy is used in incremental crawler. There can be two sorts of changes: "change in the structure" of the page or "change in the substance" or "Change Image"
Change in structure: alludes to how the HTML report is organized i.e. how messages and pictures are arranged on a website page. This is finished with the profit of HTML labels. A calculation would run that would store the places of the labels and the characters related with it. So crawlers would look at the foremost labels area and if the page is refreshed it will refreshed the list page at the season of return to
Change in content As the crawlers filters the archive surprisingly it allots a code to the content substance of the site page so at the season of return to it looks at the content code of the record. It finds the ASCII tally of the page and the aggregate character check.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor & UGC Approved Journal) Website: www.ijirset.com
Vol. 6, Issue 8, August 2017
VI. EXPERIMENTAL RESULT
The proposed Web Crawler'was tried and keep running on the standard condition and assess its execution with broadly acknowledged connection and substance predicated web crawler
VII. CONCLUSION
Web crawlers are a significant part of all the web search tools. They are the fundamental part of all the web facilities so they require to give superior. Information control by the web crawlers covers a wide range. Building a solid web crawler to comprehend distinctive intentions is not an exhausting undertaking, but rather separating the correct procedures and building an adequate design will prompt execution of profoundly clever web crawler application. Various creeping calculations are used by the web indexes. A decent slithering calculation ought to be executed for better outcomes and superior.
REFERENCES
[1] T. Nelson. A file structure for the complex, the changing, and the indeterminate. In Proceedings of the ACM National Conference, pages 84–100, 1965
[2] R. Duda and P. Hart.Pattern Classification and Scene Analysis.Wiley, New York, 1973.
[3] Chakrabarti, Soumen., Mining the Web: Analysis of Hypertext and Semi Structured Data, Morgan Kaufmann Publications, Elsevier, 2003 [4] Chakrabarti S., Data mining for hypertext: A tutorial survey, SIGKDD Explorations, 1:1–11, 2000.
[5] Christopher Olston and Marc Najork., Web Crawling, Foundations and Trends in Information Retrieval Vol. 4, No. 3 (2010) 175–246 [6] Maedche and Staab S., Ontology learning for the semantic web. IEEE Intelligent Systems, 16(2):72 –79, 2001.
[7] DhirajKhurana, SatishKumar., Web Crawler: A Review IJCSMS International Journal of Computer Science & Management Studies, Vol. 12, Issue 01, January 2012 ISSN (Online): 2231 –5268.