International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
210
Effective Data Structure for Mining Frequent Itemset in Cloud
Databases
Anitha. R
1, Saswati Mukherjee
2
Department of Information Science and Technology, Anna University, Chennai-25, India.
Abstract — Due to increase of data in cloud computing environment over the past few years, retrieving required data from the huge database with lesser amount of time becomes tedious. Hence without having a proper cache management framework the retrieval of required data from the cloud data servers becomes difficult. This paper proposes a probabilistic framework for efficient retrieval of data from huge database using combined approach of caching and frequent transaction analysis. The use of novel data structure in the proposed model increases the performance of data retrieval in cloud. A novel method of cache management is used to serve the cloud user effectively. A Derived Cluster which is created in online mode, acts as cache which holds the frequent transactions for downloading required data quickly. Frequent transactions are identified based on the run time statistics of the transaction provided by the Bloomier Matrix Filter (BMF) analysis. Based on the run time statistics of the BMF the dynamic cluster is derived. We have implemented the model in a cloud environment and the experimental results show that our approach is more efficient than the existing search technology and increases throughput by handling more number of transactions efficiently with reduced latency.
Keywords—cloud storage, clustering, metadata, bloom filter, bloomier matrix.
I. INTRODUCTION
During the last one decade, tremendous development and growth have happened in the cloud computing system. As a key component, the large-scale cloud computing system has been attracting a great deal of attention from both industry and academia. Performance of a cloud is improved by an improved scalability, availability and security. In order to improve the scalability and availability of the cloud computing system, metadata management plays a vital role [1]. Setting up of an external metadata server (MDS) for metadata service speeds up the file retrieval by reducing latency. However, due to the rapid growth of data in cloud, the growth of metadata also increases and thus searching of metadata becomes complex.
Data mining techniques such as association rule mining, classification, clustering, web mining and correlations are popularly used in any large distributed database [10].
Although, research in this field of frequent pattern mining is not new, it is still emerging [7]. The reputation of the cloud and large volume of data have caused researchers to use such techniques for the exploration of unknown knowledge in data collections. This perhaps justifies the sudden increase of research in the general topic of mining the data in cloud computing environment. Among various data mining techniques employed, clustering is a popular technique.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
211
The rest of the paper is organized as follows: In Section 2 summarizes the related work. Section 3 discusses the detailed design of the system architecture. Section 4 describes the structure and creation of Bloomier Matrix Filter. Section 5 describes the creation and algorithm for the creation of proposed Derived Cluster. Section 6 discusses about MFT Algorithm in detail. Section 7 discusses the statistical measure of MFT Algorithm. The performance evaluation based on the prototype implementation is given in Section 8 and Section 9 concludes the paper.
II. RELATED WORK
Recently much of the work is being pursued in data analytics in cloud storage [1] [2]. Abhishek Verma et al. [4] have proposed metadata using Ring file system. In this scheme metadata for a file is stored based on hashing its parent location. Replicas are stored in its successor metadata server. Yu Hua et al. [3] have proposed a scalable and adaptive metadata management in ultra large scale file systems. Chaohui Liu et al. [8] has proposed a technique of mining frequent itemsets using Matrix reduces scanning cost and execution times, but the algorithm works only for few transactions. The partition algorithm proposed by Ashok Savasere et al. [9], aims to further improve the efficiency, by reducing the number of database scans, however, considerable time is still wasted in scanning infrequent candidate itemsets. Suh-Ying Wur et al. [10], has proposed Boolean algorithm mines association rules in two steps. In the first step logical OR and AND operations are used to compute frequent itemsets. In the second step, logical AND and XOR operations are applied to derive all interesting association rules based on the computed frequent itemsets. But the computational time is more as well as it occupies more memory. Wuling Ren et al.[11] has proposed a fast Mining maximum frequent item using Interest Frequent Pattern Matrix (IFPM), which is based on user’s interests, filters the transaction database according to the level of data item. The Bloom filter is a space-efficient probabilistic data structure that supports set membership queries. The data structure was conceived by Burton H. Bloom in 1970. The structure offers a compact probabilistic way to represent a set that can result in false positives (claiming an element to be part of the set when it was not inserted), but never in false negatives (reporting an inserted element to be absent from the set). This makes Bloom filters useful for many different kinds of tasks that involve lists and sets. In paper [12] the author has claimed that the data retrieval using metadata is less when compared to without using metadata due to reduction in latency.
Bin Lan et al. [13] has proposed a variant of the signature file, called Bit-Sliced Bloom-Filtered Signature File for mining frequent patterns. Many researchers have investigated possible ways to improve the performance of clustering based on the popular clustering algorithms like partition clustering, hierarchical clustering and frequent item based clustering. The concept of bloom filter in cloud computing is explained in depth in the paper [14]. The author has discussed about the independent lookup using CBF in cloud era. Here, we have proposed an effective statistical approach of clustering metadata based on frequent transaction-set using bloomier matrix filter.
III. SYSTEM MODEL
The architecture diagram of the proposed system model is shown in Figure 1. Each block in the architecture explains about the dynamic creation of derived cluster based on frequent transaction-set of metadata from user perspective and also from the temporal perspective.
Figure.1 Architecture Diagram
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
212
In order to make the retrieving process further efficient, a dynamic cluster is formed based on the history of transactions from the user perspective and time based transaction. The transactions are recorded and are used in the Bloom filter and analyzed. The Bloomier matrix filter is constructed based on the transactions recorded. The transactions with respect to time slot are recorded in Time Based Transactions BMF (TBT). The transactions with respect to user are recorded in User Based Transactions BMF (UBT) The analysis is done based on the similarity measure between the transactions and by using this run time statistical analysis a new cluster is formed. Thus knowledge has been extracted based on run time analysis which further improves the efficiency of the proposed model.
IV. BLOOMIER MATRIX FILTER
All paragraphs A special data structure called Bloomier Matrix Filter derived from a basic bloom filter, extracts the history of transaction based on temporal behavior and the user behavior. The structure of bloomier matrix filter is as shown in figure 2.
[image:3.612.326.575.313.499.2]
Figure.2 Structure of Bloomier Matrix Filter
Bloomier matrix filter represents and work on transaction set efficiently as it is a probabilistic data structure which has independent look up. The method works efficient for large databases and leverages statistical analysis on the recorded transactions and thus establishes accurate links between the records. Work is to develop matrix based manipulations in order to estimate similarity between user centric transactions and time-slot centric transactions. The structure takes up a matrix format where the column represents the files and row represents the time or user.
Initially all the values are set to zero and whenever transaction happens, the counter value of corresponding rows and columns gets incremented. The name bloomier matrix filter, because it filters out the unwanted files occupying the search space, thus reduces the database scanning in large databases. Inspite of scanning the database every time the usage of bloomier matrix minimizes the overhead by means of look up confidence values and compare them to the other set of recorded values based on transactions recorded with respect to a specific query. The Bloomier Matrix manipulations were originally developed to go for fast join operations in large distributed database. The similarity between the values are carried out and based on the similarity values, the files are stored in the derived cluster.
Figure 3. Structure of proposed Bloomier Matrix Filter
The Bloomier Matrix filter can be viewed as a matrix, which consists of parallel sub matrices in order to represent transactions with respect to files. A sub matrix is composed of parallel arrays and can be used to represent transactions. An array consists of counters and its related transaction frequency. The array values are processed parellely to calculate the frequent itemset. Assume that the query is with respect to ith file, the frequent transaction file with respect to the respective file is found. The process uses various time slots ranging from Ti, where i=1 to n. Thus, each sub matrix are used for processing frequent files. By using BMF the values are processed parellely and the results are used for further dependency tests. Figure 2 presents the algorithm of adding values in the proposed structure.
X1 0 0 0 0
f1
f2
f3
fn
X3
X2
Xn
0 0 0
0
9
0 0 0
0 0 0
0 0
....
[image:3.612.62.260.408.561.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
213
Algorithm for inserting an item into Bloomier Matrix Filter
Input: Item x
Output: Bloomier Matrix Filter with transactions recorded
Initialize Bm [ ][ ]= 0 for (i = 1; i ≤ Ti; i++) for (j = 1; j ≤ Fj; j++)
if(Transaction) /* Insert Value into Bm[ ][ ] */ {
Bm[Ti][Fj] = 1
Bm[Ti][Fj] = Bm[Ti][Fj]++; }
end end
A. False Positive Analysis of BMF
The False Positive analysis of the proposed BMF is as shown in Table.1.The Proposed BMF has lesser false positives compared to existing standard bloom filter.
TABLE.I
COMPARISON OF FALSE POSITIVE PROBABILITY OF PROPOSED BMF
AND EXISTING BF
V. CONSTRUCTION OF DERIVED CLUSTER USING BMF
The Derived cluster is generated using the following steps. When user searches the file using keyword or file name, filename will be stored in the User Based Transaction (UBT) and Timeslot Based Transaction (TBT). The Derived cluster uses the UBT and TBT. By applying the similarity measure between transactions recorded, a new cluster is formed in online mode which is called Derived cluster. In Time Based Transaction for every 30 minutes the transaction of the files are recorded and stored in separate table.
In UBT for every user the files transactions are recorded and is stored in separate table. The similarities measures of the BMF are calculated using the similarity measure, based on the measure the files which are frequently accessed are identified and clustered as derived cluster.
VI. MINING OF MAXIMUM FREQUENT TRANSACTION-SET
ALGORITHM USING BLOOM FILTER
The MFT algorithm is used to effectively discover the frequent transaction set based on the concept of support approximation. Two important measures, the chi-square measure and cramer’s V rule are adopted in MFT to approximate the support of itemsets. Chi-square analyses the support of the transactions which results in the dependency of the transactions. Cramer’s V Rule is used to determine the strength of association. The files with higher strength are physically copied at the derived cluster. The approximation quality, the quality of clustering obtained depends on the number of levels required to create the cluster. From this perspective it is required using a space-efficient algorithm in order to create a cluster with approximate quality. The space efficient data structure results in handling large number of transactions. In cloud scenario as the growth of file reaches exabyte’s, increases the count of transaction. Hence to handle this scenario perfectly the algorithm uses a space efficient data structure called bloomier matrix filter. The bloomier matrix has an advantage of independent look up hence reduces the time complexity for lookup. The advantage of the algorithm is that it maintains categorical data so that the space used is less. The algorithm uses two step processes to deduce the files, which fits into the derived cluster.
Algorithm: Creation of Derived Cluster using Maximum Frequent Transaction-set MFT algorithm.
Input: Record of time centric transactions, user centric transactions
Output: Building a derived cluster
Step.1 Create Bloomier Matrix1-TBM Scan the DB based on time slot
for (all transactions in time slot interval) { do{
if (FID exists in Transaction = 1) then
FID= FID++; /* Transaction taken place for same FID */ else
FIDth Column=1
} until transaction = END }
Number of Items
False Positive of
BMF
False Positive of Existing BF
0 0 0
500 0.002 0.95
1000 0.0059 0.997
1500 0.008 0.999
2000 0.011 0..999
2500 0.014 0..999
3000 0.017 0..999
3500 0.02 0..999
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
214
Step 2 : Create Bloomier Matrix 2-UBM Scan the DB based on User’s interest for (all transactions on users interest) do {
if (FID exists in Transaction = 1) then
FID= FID++; /* Transaction taken place for same FID */ else
FIDth Column=1
} Until transaction = END }
Step 3: Analysis of Dependence for TBM and UBM for (i=0 ; i< Tn; i++)
for ( j=0 ; j<Fj; j++) /* Apply chi-square Test */ for ( k=0 ; k<Fj+1; k++)
{
Chi-squared χ2 = ∑((observed-expected)2 / expected) /* determines whether there exists an association between two files*/
if (χ2 > α
(r-1)(c-1)) then {
Call Step 4 }
} End for End for
Step 4: Analysis for Strength Read the output from step 3
for ( j=0 ; j<Fj; j++) /* Apply Cramer’s V Rule */ for ( k=0 ; k<Fj+1; k++)
{
Cramer’s V Rule /* varies between 0 and 1*/ if (V > .4) then
{
Enter into Derived Cluster }
} } }
/*Close to 0 it shows little association between variables. Close to 1, it indicates a strong association.*/
Maximum value close to 1 and values greater than 0.4 enters derived cluster.
VII. STATISTICALMEASURESOFBMFUSING MAXIMUMFREQUENTTRANSACTIONSET
ALGORITHM (MFT)
The proposed model uses three different statistical measures in order to create and prove the efficiency of the derived cluster viz. 1.
Dependency Measure using Chi-Square analysis 2. Measure of strength using Cramer’s V Rule 3. Quality Measure using F-Measure. Dependency measure is the measure of finding out the transactions which are dependent to each other. The Dependency measure is calculated from the bloomier matrix. Dependency measure is a similarity measure calculated based on the categorical data, called observed frequencies, which shows the transaction of files from the sample and represented in each cell of the matrix.
TABLE.II
STATISTICAL ANALYSIS OF RECORDED TRANSACTIONS FROM TBT
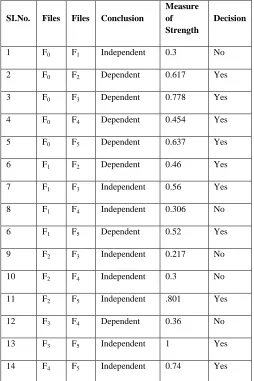
This means that using statistical tests, if we accept the null hypothesis then the files are independent, which implies that there is no association between the two random files. However, the computation of how strongly the files are connected is not defined. A solution to this problem is to use correlation techniques to find the strength of association. The proposed model uses Cramer’s V Rule for finding the strength of Association. The files with higher strength are clustered into derived cluster. The results from the Table. 2 and Table. 3 are observed. Based on the decision from the result the files which have higher strength whose probability is greater than 0.4 entered into derived cluster.
SI.
No Files Files
Test
Value Conclusion
Measur e of Strengt
h
Decis ion
1 F0 F2 12.12
Dependen
t 0.625 Yes
2 F0 F3 9.173
Dependen
t 0.562 Yes
3 F0 F4 6.601
Dependen
t 0.485 Yes
4 F1 F2 8.42
Dependen
t 0.464 Yes
5 F1 F3 7.44
Dependen
t 0.448 Yes
6 F1 F4 5.3
Dependen
t 0.383 No
7 F2 F3 3.09
Independe
nt 0.32 No
8 F2 F4 4.78
Independe
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
215
TABLE.III
STATISTICAL ANALYSIS OF RECORDED TRANSACTIONS FROM UBT
The Evaluation of derived cluster is carried out using F-Measure. For evaluation, we need to compare the generated clusters with the key clusters. To do that, we used F-Measure scoring method. This scoring algorithm models the accuracy of the system on a per-document basis and then builds a more global score. For a document i, the precision and recall with respect to that document are calculated as follows,
VIII. DESIGN AND IMPLEMENTATION DETAILS
[image:6.612.42.296.166.547.2]The Experiments have been carried out in a cloud setup using Eucalyptus, which contains a cloud controller and walrus as storage controller. KDD Cup dataset has been used for these experiments. In our experiment, files are uploaded into the storage and then downloaded. When a user uploads a file, the model first generates the metadata and based on tfidf algorithm keywords are extracted. We have uploaded around 1000 files for experimentation. From the experimental results, it is observed that the time taken to create Derived cluster is less. We further note that the quality of the Derived cluster is high. We have used the following metrics namely, Precision, Recall and F-measure for evaluating the performance of the proposed approach. The evaluation metrics used in the proposed approach is given below, where precision is the fraction of retrieved files that are relevant to the search and recall is the fraction of the files that are relevant to the query that are successfully retrieved. The F-score is the single measure of performance of the test.
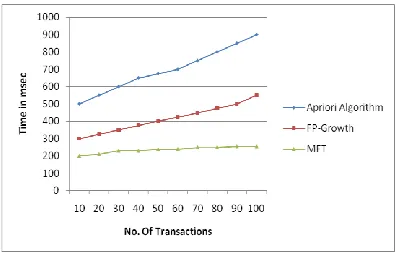
Figure 4. Comparison of Running time of proposed and existing algorithms.
From the Figure 4 it is observed that the running time of the proposed algorithm is less when to compared to the exixting algorithms. Apriori algorithm is costly to handle a huge number of candidate sets.
SI.No. Files Files Conclusion
Measure of Strength
Decision
1 F0 F1 Independent 0.3 No
2 F0 F2 Dependent 0.617 Yes
3 F0 F3 Dependent 0.778 Yes
4 F0 F4 Dependent 0.454 Yes
5 F0 F5 Dependent 0.637 Yes
6 F1 F2 Dependent 0.46 Yes
7 F1 F3 Independent 0.56 Yes
8 F1 F4 Independent 0.306 No
6 F1 F5 Dependent 0.52 Yes
9 F2 F3 Independent 0.217 No
10 F2 F4 Independent 0.3 No
11 F2 F5 Independent .801 Yes
12 F3 F4 Dependent 0.36 No
13 F3 F5 Independent 1 Yes
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
216
[image:7.612.330.555.171.348.2]For example, in order to discover a frequent pattern of size 200, it needs to generate a candidate set of 2200. Hence the running time is high when compared to MFT algorithm. In FP-growth algorithm the drawback is that the pruning can be done only on single itemset. For every itemsets the noed has to be revisted hence time taken is higher for higher support. Revisting the node is the inherent cost of FP-growth generation. On comparing MFT with exixting algorithms it is much more scalable the time taken is less due to its independent look up and statistical analysis. As the number of transactions grows the difference between the existing and propsed grows larger. Overall, MFT is about an order of magnitude faster than Apriori in large databases, and this gap grows wider when the minimum support threshold reduces.
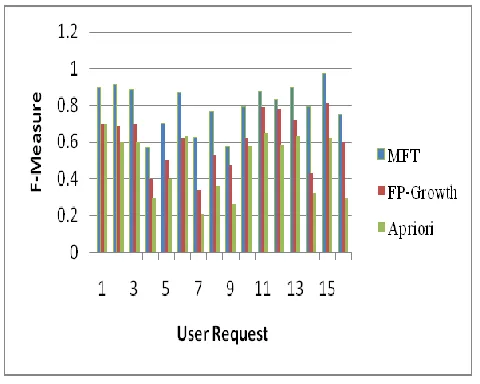
Figure 5. F-Measure of the of proposed algorithm
Figure 5 shows the F-measure for a given query based on the recall, precision. Precision is the number of correct results divided by the number of all returned results and recall is the number of correct results divided by the number of results that should have been returned. The F-measure can be interpreted as a weighted average of the precision and recall, where an F-measure reaches its best value at 1 and worst score at 0 for the same set recall. The F-measure of the proposed algorithm claims to be high compared to existing algorithms.
From the above results it can be concluded that users’ request can be responded appropriately. The time taken for such response would define the latency of the performance. In turn, the latency is defined by the time taken by the algorithm to run and create Derived cluster.
Since, this time is less for MFT in comparison to both FP Growth and Apriori algorithms, we can conclude that the latency is less for MFT.
Figure 6. Comparison of response time for file retrieving using metadata with and without using MFT algorithm.
From Figure.6 it is observed that the time taken to the retrieve the file from the data server using metadata after analysis using MFT is less when compared to metadata without analysis as mapping of user query to the data server is efficiently handled by derived cluster where the search space is less.
From the result is observed that the latency reduction due to metadata becomes more significant with the increase in workload. Under the heaviest work-load studied in our experiments, a configuration of metadata servers reduces the response time of file retrieval in cloud scenario approximately by a factor of 40%.
Figure 7. shows the memory usage of the proposed algorithm and compared with the existing algorithm.
[image:7.612.49.289.312.504.2] [image:7.612.327.560.543.695.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 2, February 2014)
217
[image:8.612.69.271.323.452.2]Form the Figure.7 it is observed that the Memory usage is less in proposed MFT when caompared with the existing frquent pattern algorithms. When the case arise where transactions are in millions, the existing algorithms the main memory may not be sufficeint and hence starts using secondary storage in order to save the translated computation due to the initial computations like creation of prefix-trees. So there comes a drastic change in the usage of memory. The performances of the existing algorithms of Apriori and FP-growth degrades severely when the amount of transactions goes in the multiplication factor of million. But this is not the case of proposed MFT algorithm. When the existing algorithms are compared with the proposed MFT algorithm, the memory usage is drastically less due to involvement of both, a novel bloomier matrix datastructure and the computation based on the statistical analysis.
Figure 7. Running Time of algorithm
From Figure.8 we evaluate how well the various schemes scale with respect to the database size. The number of transactions vary from 10K to 100K. The results of this study is shown in Figure 8. As shown,all the schemes show linear scalability with respect to the number of transactions. However, MFT are the least affected because of the independent lookups. The performance of the MFT schemes remains the same as it can handle any number of transaction with same time factor.
IX. CONCLUSIONS
Due to the exponential increase in the volume of data stored at cloud data servers, the need for analyzing the metadata created is required. This paper has proposed an effective approach for clustering metadata in accordance with the frequent itemsets that provides significant search space reduction. We have obtained a set of Base clusters using the attribute keyword which is extracted using TF-IDF algorithm.
The Derived cluster is a dynamic cluster which is generated at the time of information retrieval using frequent itemsets based on User Transaction and Time based Transaction. Our MFT method allows the user to retrieve the data with less latency and increase the throughput.
REFERENCES
[1] Michael Cammert, Jurgen Kramer, and Bernhard Seeger, "Dynamic
Metadata Management for Scalable Stream Processing Systems", Proc. of IEEE International Conference on Data Engineering Workshop, pp.644-653, 2007.
[2] Jan-Jan Wu, Pangfeng Liu, and Yi-Chien Chung, "Metadata
Partitioning for Large-scale Distributed Storage Systems", Proc of IEEE International Conference on Cloud Computing, 2010. [3] Yu Hua, Yifeng, Hong Jiang, Dan Feng, and Lei Tian,"Supporting
Scalable and Metadata Management in Ultra Large Scale File Systems", IEEE Transactions on Parellel and Distributed Systems, Vol.22, No.4, 2011.
[4] Abhishek Verma, Shivaram Venkataraman, Matthew Caesar, and
Roy Campbell, "Efficient Metadata Management for Cloud Computing Applications", Proc of International Conference on Communication Software and Networks, 2010.
[5] Tan Zhipeng, Zhou Wei, Sun Jianliang, Zhan Tian, and Cui Jie, ―An
Improvement of Static Subtree Partitioning in Metadata Server Cluster,‖ International Journal of Distributed Sensor Networks, pp. 1-10, 2012.
[6] Benjamin C.M. Fung, Ke Wang, Martin Ester, ‖Hierarchical
Document Clustering Using Frequent Itemset‖ in proc. Siam international conference on data mining 2003.
[7] NVB Gangadhara Rao, Sirisha Aguru, ‖A Hash based Mining
Algorithm for Maximal Frequent Item Sets using Double Hashing‖ Journal of Advances in Computational Research, Vol. 1 No.1-2, 2012, pp.1-6.
[8] Chaohui Liu, Jiancheng an, The Software Engineering School, China
―Fast Mining and Updating Frequent Itemsets‖, 2008 ISECS International Colloquium on Computing, Communication, Control and Management, Vol.1, pp. 365-368.
[9] Ashok Savasere, Edward Omiecinski, and Shamkanth Navathe, ―An
Efficient Algorithm for Mining Association Rules in Large Databases‖ In VLDB 1994, Zurich, Switzerland, pp.432-443.
[10] Suh-Ying Wur and Yungho Leu, ―An Efficient Boolean Algorithm
for Mining Association Rules in Large Databases‖. 6th International Conference on Database Systems for Advanced Applications, 1999, pp: 179.-186.
[11] Wuling Ren, Guoxin Jiang, ― A Fast Algorithm for Maximum
Frequent Itemsets Based on the User’ Interest,‖ International Colloquium on Computing, Communication, Control, and Management, 2009.
[12] R. Anitha, Saswati Mukherjee, "A Dynamic Metadata Model in
Cloud Computing", Proc. of Springer CCIS, Vol.2, pp.13–21, 2012.
[13] Bin lan. Beng chin ooi, kian-lee tan,―Efficient Indexing structure for
mining frequent patterns, in proc. International conference on Data Engineering, 2002, pp. 453-462.
[14] R.Anitha, SaswatiMukherjee. "CBF: Metadata Management in
Cloud Computing" in Proc. of international conference