2017 2nd International Conference on Wireless Communication and Network Engineering (WCNE 2017) ISBN: 978-1-60595-531-5
Logging Reservoir Evaluation Based on Spark
Meng-xin SONG*, Hong-ping MIAO and Yao SUN
Computer Application Technology Research Department
Research Institute of Petroleum Exploration & Development Beijing, China
*Corresponding author
Keywords: Big data, IBM BigInsights, Spark, Decision tree, Reservoir evaluation.
Abstract. In the past, most traditional logging reservoir evaluation methods rely on expertise. However, as data size grow rapidly, the efficiency of manual analysis is low. With the big data technology becoming more and more mature, we can use big data platform to evaluate logging reservoir. In this paper, we proposed a Spark based logging reservoir evaluation method. By constructing a 3 nodes IBM BigInsights big data platform, using the decision tree algorithm of Spark, we accomplished the evaluation of logging reservoir. We tested our proposed algorithm on a dataset in an oil-field in Northwest China, the proposed algorithm can accomplish the evaluation of logging reservoir. This approach doesn't rely much on expertise and can achieve a better efficiency than traditional evaluation. The proposed method can provide a reference to using big data platform to evaluate the logging reservoir.
Introduction
The basic idea of reservoir evaluation is taking full advantage of various materials including well logging data to evaluate reservoir properties, such as oil bearing evaluation, layer classification, reservoir parameters prediction, capacity estimation etc. The traditional methods for logging reservoir evaluation rely on expertise [1,2]. However, with the steady accumulation of data, the datasets are too large, manual analysis is time-consuming.
Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them [3]. As for the oil exploration and development area, big data platform can help us to processing, analyzing large volume data. Spark is an important module of big data platform, is a fast and general engine for large-scale data processing.
In this paper, we proposed a Spark based logging reservoir evaluation method. By constructing a 3 nodes IBM BigInsights big data platform, using the decision tree algorithm of Spark, we accomplished the evaluation of logging reservoir, and tested the proposed on a dataset in an oil-field in Northwest China.
Big Data Related Technologies
In 2012, Gartner defines big data as follows: "Big Data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation." [3] Lately, the term "big data" tends to refer to the use of predictive analytics, user behavior analytics, or certain other advanced data analytics methods that extract value from data, and seldom to a particular size of data set.
Spark
1. Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS (Hadoop Distributed File System), Cassandra, HBase, and S3 [5].
Figure 1. Main modules of Spark.
IBM BigInsights Big Data Platform
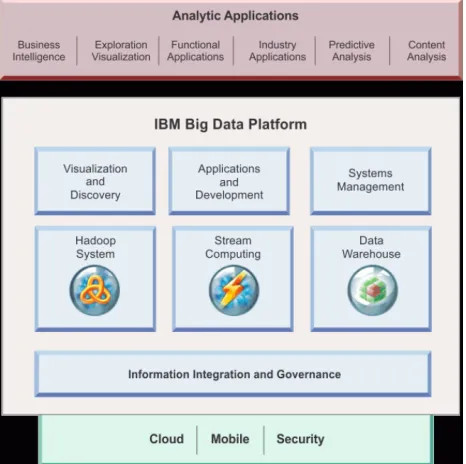
BigInsights is a collection of value-added services that can be installed on top of the IBM Open Platform with Apache Spark and Apache Hadoop, it provides a complete solution, including Spark, to scale analytics quickly and easily [6]. The architecture of BigInsights is shown in figure 2. BigInsights includes nearly 20 Apache projects critical to the Hadoop and Spark ecosystems, such as Hive, Sqoop, Hbase, etc, it uses Apache Ambari as the installer, which enables you to install only those components that you need. Figure 3 shows the homepage of Ambari.
[image:2.612.190.423.330.562.2]Figure 3. The homepage of Ambari.
Spark Based Logging Reservoir Evaluation
Decision Tree Algorithm
Decision tree builds classification or regression models in the form of a tree structure. It breaks down a dataset into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed [7]. The final result is a tree with decision nodes and leaf nodes. The core algorithm for building decision trees called ID3 by J. R. Quinlan which employs a top-down, greedy search through the space of possible branches with no backtracking. ID3 uses Entropy and Information Gain to construct a decision tree.
Experiment Environment Configuration
Using VMware virtualization platform, we build a 3 nodes IBM BigInsights big data platform, the configuration of the virtual machines is 16GB memory, 8vCPUs, 100GB disk, the operating system of the virtual machines is RedHat 6.6. We used Apache Ambari [6] as the installer, which enables you to install only those components that you want or need, the version of Ambari is 2.2.0. 1 virtual machine is used for Ambari server, and the other 2 virtual machines are used for Ambari agent, the architecture of the experiment environment is shown in figure 4, Scala version is 2.10.5, Intellij IDEA version is 2016.2.
[image:3.612.212.394.537.682.2]Experiment and Analysis
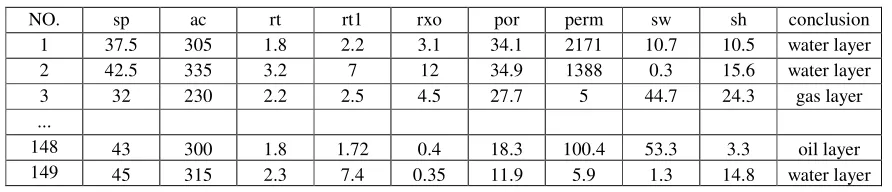
[image:4.612.84.530.200.296.2]The main task of reservoir evaluation is using original data collected by well logging to evaluate its properties, such as porosity, oil saturability, lithological characters etc. and finally give a comprehensive evaluation [8]. We tested our proposed algorithm on a dataset in an oil-field in Northwest China, original data collected by well logging mainly includes well logging curves, such as potential curve (SP), gamma ray curve (GR), resistivity curve (RT, RI, RXO), density log (DEN), acoustic logging (AC), compensated neutron log (CNL) etc., there are 7 classes in our experiment data, such as oil layer, water layer, dry layer, etc. The experimental data is shown in table 1.
Table 1. Experimental data demonstration.
NO. sp ac rt rt1 rxo por perm sw sh conclusion
1 37.5 305 1.8 2.2 3.1 34.1 2171 10.7 10.5 water layer
2 42.5 335 3.2 7 12 34.9 1388 0.3 15.6 water layer
3 32 230 2.2 2.5 4.5 27.7 5 44.7 24.3 gas layer
...
148 43 300 1.8 1.72 0.4 18.3 100.4 53.3 3.3 oil layer
149 45 315 2.3 7.4 0.35 11.9 5.9 1.3 14.8 water layer
MLlib is Apache Spark's scalable machine learning library. In our experiment, we use the decision tree algorithm of MLlib. The workflow of our proposed method is shown below, firstly, upload our data to HDFS; secondly, build a decision tree; thirdly, optimize the parameters of the decision tree. The Scala code to build the decision tree is shown below.
The results of our experiment are shown below. (1) Confusion Matrix
Confusion matrix is a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one. Each row of the matrix represents the instances in a predicted class while each column represents the instances in an actual class.
(2)Precision and Recall
Precision is the fraction of relevant instances among the retrieved instances, while recall is the fraction of relevant instances that have been retrieved over the total amount of relevant instances.
The experiment results shows that the proposed method can accomplish the evaluation of logging reservoir, compared with traditional methods, it doesn't rely much on expertise and can achieve a better efficiency than traditional evaluation.
Conclusion
In this paper, we proposed a Spark based logging reservoir evaluation method, by constructing a 3 nodes IBM BigInsights big data platform, using the decision tree algorithm of Spark, we accomplished the evaluation of logging reservoir. Compared with traditional methods, the proposed method doesn't rely much on expertise and can achieve a better efficiency. The proposed method provides a reference for petroleum companies using the big data technology to solve their production problems.
References
[1] S. D. Mohaghegh, A new methodology for the identification of best practices in the oil and gas industry, using intelligent systems, Journal of Petroleum Science and Engineering, 49(2005), 239-260.
[2] Y. L. Ren and Y. T. Ren, A framework of data mining for logging reservoir evaluation. International Conference on Service Systems & Service management, 2016, 1-6.
[3] https://en.wikipedia.org/wiki/Big_data
[4] http://spark.apache.org/
[5] https://en.wikipedia.org/wiki/Apache_Spark
[6] https://www.ibm.com/us-en/marketplace/biginsights-on-cloud
[7] J. Han, M. Kamber, J. Pei, Data Mining: Concepts and Techniques, Morgan Kaufmann Publishers 2011.