Efficient Data Streams Processing in the Real Time
Data Warehouse
Fiaz Majeed
Computer Science DepartmentCOMSATS Institute of Information Technology Lahore, Pakistan
Muhammad Sohaib Mahmood
Computer Science Department COMSATS Institute of Information TechnologyLahore, Pakistan [email protected]
Mujahid Iqbal
Computer Science DepartmentCOMSATS Institute of Information Technology Lahore, Pakistan
Abstract—Today many business applications are generating
fast, multiple, continuous and time varying data streams [2] which are not manageable from available ETL (Extraction, Transformation and Loading) technology. This work gives architecture to extend the real time data warehouse for efficient handling of data streams while keeping traditional functionalities.
The paper focuses on the data stream processing part of the architecture. The data stream processor constructed with the combination of mature techniques performs data stream processing reliably. It ensures synchronization of the data streams processing with the pace of the incoming data streams from source applications.
Keywords-Data warehouse, Real-time, active databases, data streams
I. INTRODUCTION
The applications generating data streams include click stream based web applications, network monitoring, security, sensor, telecommunication and manufacturing applications [4] etc. In contrast to other transactional applications where limited numbers of transactions are carried out in un-continuous manner like order processing applications, data stream applications continuously generate data in non uniform way [2]. Sometimes data may produce in trickle feed [5]; it may come in the form of bursts in other time interval. So it is very difficult to handle this form of data with traditional methods.
Data stream applications are the source of most of the data warehouse systems. Data warehouse systems [14] are used in enterprises to take the dispersed data from heterogeneous source systems into a central container. It provides a single view of enterprise to the executives for strategic decision making. They can analyze current state of their business as well as predict for future with the use of historical data in the data warehouse.
Traditionally, data warehouses were updated with the source data weekly or daily in nightly batches. That time
those were built only for strategic analysis. For current analysis, operational systems were used. Now business is demanding for tactical analysis as well as strategic decision making from the data warehouse. For this purpose, data warehouse is required to be updated in real time when transaction is happened in any of the source systems. Therefore, real-time data warehouse fulfills this with close-loop functionality.
Enterprises are using real-time data warehouse with traditional functionalities. They can add new functionality in the existing system rather than deploy a whole new system. The data stream handling is presented in the proposed architecture as independent module which does not overloads the working of the ETL tool. Some proposed works on data streams [1]; design systems from scratch that divert from the traditional functionalities.
The rest of the paper is formatted as follows: Section II details the related work about real time data warehouse and data streams. In Section III, RTDW architecture with the inclusion of data streams is formulated. Data streams processing is discussed in Section IV. Finally, Section V concludes the work and provides future directions.
II. RELATED WORK
Data streams have been extensively studied in different domains. The potential issue in data stream handling is memory management. It is very difficult to store unlimited data streams in limited memory. Grid Technology [1] was used to cope over the storage requirement in the presence of data streams. In this solution, data streams are captured and stored in distributed grid nodes. These nodes contain high volume of storage capacity for huge quantity of data streams. Data stream processing systems normally hold fixed storage and computing power. In this case, the challenge is to get all the valuable contents from data streams in the presence of limited storage. Since, approximation techniques [2, 3, and 4] were produced to generate summary streams for handling the issue of small storage. Many techniques of summaries (or synopsis) creation have been proposed in the
literature. These contain sampling, histograms and wavelets [11] etc. provides approximate results closer to accurate input data. The congressional samples [6] calculate approximate results for group by queries. This proposed technique discusses the problem of uniform random sampling and gives a notion of bias sampling to get valuable contents from the data.
Architecture for continuous queries over data streams is presented in [4] which provide a way to contain the maximum data streams in short memory. It divides the storage in four containers named stream, store, scratch and throw. Stream holds the continuous processing elements, store saves those streams which are to be required after short period. Scratch contains streams for use in future analysis. The data no more beneficial is disposed through throw container. A data streams solution extract them using queue networks [8] in which streams are stored in queues before processing. ETL performance is then evaluated using queue theory.
III. ARCHITECTURE OF THE REAL TIME DATA WAREHOUSE
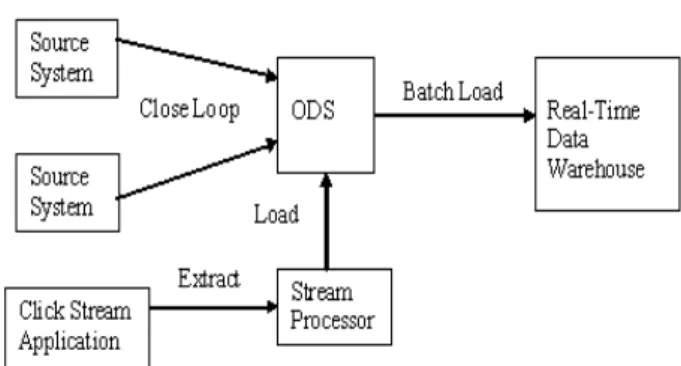
The focus of underlying research is to extract the data streams in efficient way, process them and load in a suitable format into the data warehouse. Data warehouse architecture with the extension of data streams handling is depicted in Fig.
1.
Figure 1. RTDW architecture extended with Data Streams processing Real-time data is extracted from the source applications based on event driven approach and loaded into the Operational Data Store (ODS). When transaction is occurred in any of the source systems, it is detected and sent to the ODS.
The novel part of the architecture is data stream handling which is the main focus of this research work. It is classified into three areas that are data stream extraction, processing and loading. According to the architecture, the data streams and other source systems are integrated in the ODS. Then real-time analysis and reports are generated from the ODS by
conducted on WAN application performance [13], the web traffic is more than 25% of the overall WAN traffic. It is increasing rapidly with the increasing number of users all over the world.
Following sections discuss in depth the data streams processing of real-time data warehouse.
IV. DATA STREAM PROCESSING
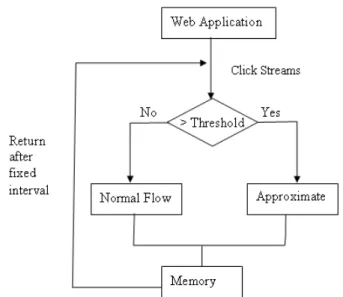
The click streams are pushed [10] from the web application to the stream processor to load them into the data warehouse. As depicted in Fig. 2, stream processor takes stream items as input, process and converts them into the format suitable for the ODS.
Figure 2. Data Streams processing before Data Warehouse insertion The stream processing part of the architecture ensures memory management, synchronization and accurate processing. The challenge is to manage the fixed memory in the presence of heavy, burst and time varying data streams.
A. Continuous Queries
As we have already discussed that data streams arrive in unbounded size. The handling of these heavy data streams requires huge storage and computing technology which is unaffordable. The size of the data streams can be reduced by filtering the irrelevant data streams. The data streams processor filters them by using continuous query [4]. Data streams that pass the filtration criteria are allowed to enter in the stream processor. Remaining streams that do not follow the criteria are discarded.
The queries are registered to the system before the execution. Continuous queries run continuously and evaluate the arriving data streams. The predicates defined in the query are used as filtering criteria. The memory in this way is now capable to carry maximum number of data streams and increase the efficiency of the system. The filtration through continuous query is shown in Fig. 3.
B. Data Streams Approximation
The approximation techniques are broadly explored in query processing context. As the databases are mostly huge reservoirs of data in the enterprises. If a query is evaluated on the whole database, it takes long time for achieving results. The user composing the query expects faster response from the database management system (DBMS). The DBMS evaluates the query on stored datasets and return results within nanoseconds to the user. In fact, the query processor of DBMS makes it possible with the use of summarization techniques. It uses algorithms that compute summary of the detailed data in one pass and provide approximate results on the basis of those summaries. The results are not completely accurate but close to the accurate answers.
Especially, data warehouse environment which stores historical data of decades. The query processing in that environment is highly complicated. If query is evaluated on detailed data in data warehouse, it takes days to compute the results which are unaffordable by the users.
In this work, sampling [6] is used to produce approximate results. In sampling technique, the dataset is divided into equal parts and small samples are picked where each sample represents the essential characteristics of a part of data. The approximations are started when the size of data streams increase from a specified threshold level set on memory. This process is continued until the size of data streams reach below the threshold.
There are two cases when data streams cross the threshold level of memory. First, when data streams arrive from the application. Due to their unpredictable nature, these might not be adjusted in memory. Second, if the rate of processing to data streams is not equal to their arrival rate then all data streams might not be processed due to lack of synchronization. In that case, extra data streams are discarded. The data streams processor generates summaries in both situations.
1) Approximations Production Alert
The data streams are transformed in detail while memory is available to keep them for processing. As mentioned earlier, all valuable data can only be loaded into ODS and then to Real Time Data Warehouse (RTDW) if the quantity of data streams remains below the threshold. Otherwise extra data would be discarded due to lack of memory.
To eliminate this risk, data should be summarized instantly when this condition occur. There should be applied some alert to monitor the data rate flow which informs the data streams processor to start the process of summarizations in case of imbalance in flow. Such alert in the data streams processor is implemented in the form of continuous query. Fig. 4 depicts the process of data streams processing that run normally until threshold level exceed.
Figure 4. Data Stream approximations production alert The alert system generates exception when threshold level is exceeded from the specified limit with respect to memory.
C. Regulate Flow of Data Streams
The data streams processor is not able to process the data streams more than a fixed quantity in a unit time. The irregular and rush of data streams create disorder in their processing. They demand for high computing power of the data streams processor. The underlying real-time data warehouse architecture uses token bucket technique [12] to regulate the data streams arrive into the data streams processor.
1) Token Bucket Technique
The token bucket holds tokens which are generated at every clock tick. The fixed number of streams can be transmitted on getting a token. It allows sending some burstness in the output with increasing rate of input streams. It discards tokens when fills up and saves the streams.
By using this technique, data streams processor receive streams in a regular flow. It is capable to process data streams in a constant rate, thus increase the efficiency of the system. The valuable contents in the data streams are guaranteed to be stored in the real-time data warehouse reliably. Another advantage of this technique is the maintenance of synchronization between arrival and processing of data streams.
Fig. 5 shows the use of token bucket technique in the data streams processing part of the proposed real-time data warehouse architecture.
Figure 5. Regulate Streams using Token Bucket
D. Format Conversion
The click stream producing application generates items in web oriented formats. Currently, ODS structure is implemented in relational databases. Relational structures store data in two-dimensional format. Table 1 shows the relational structure.
TABLE I. RELATIONAL FORMAT Source of Request (Host) Bytes Referring Page Date and Time of Request Browser Page Requested (HTTP protocol) Platform
PID OID CID
Pm471-46.dialip .mich.ne t 1449 "http://www.g ately.com/" "Mozilla/4.51 [en] (Win98; I)" [24/May/2009 :19:13:44 -0400] "GET /images/tagline.gi f HTTP/1.0" P131 C101 Pm471-46.dialip .mich.ne t 10659 "http://www.g ately.com/" "Mozilla/4.51 [en] (Win98; I)" [24/May/2009 :19:13:44 -0400] "GET /images/bkgrnd.jp g HTTP/1.0" P131 O142 C101
In current advanced technological environment, web applications use relational databases for data storage. If this is the case with source web applications, it is easy to transfer data streams to ODS with initial conversions. Most web applications running on legacy platforms store data in files. It is necessary to restructure the data streams into relational format before forwarding them to the ODS. Fig. 6 shows the mapping among streams and relations.
restructure relations into streams reversely. In addition, processor creates initial extract files to integrate them with other source system’s data into ODS.
E. Time Stamping
Time dimension in the data warehouse has great importance for strategic analysis. The analyses in the data warehouse are performed against time dimension for forecasting and comparisons etc. Therefore, it is necessary to store each tuple with a time stamp. Especially, time stamp is required for each incoming stream item to store within arrival order. Two types of time stamps are defined [2] that are implicit and explicit. Implicit time stamps are appended by the system as a field. This type is used when streams do not already have time element. Explicit time stamps add an attribute for exact time information.
A data model to deal with time delays in data warehouse is presented in [9]. It defines a time dimension includes three time stamps i.e. valid time, revelation time, and load time stamp. In our stream processing architecture, time stamps are assigned to the streams by the data streams processor.
V. CONCLUSIONS
Currently, a new class of applications are introduced which generate fast, multiple, continuous and time varying data streams [2, 3]. Most of the time, these applications generate data streams in the form of heavy bursts [4] which cannot be handled by existing ETL technology. The real time ETL and EAI (Enterprise Application Integration) tools built for the source systems generate data in non continuous form and little number of transactions is generated in a unit time, incapable to handle data streams. The existing solutions [1, 7] divert from the traditional functionality of the data warehouse which is the requirement of the enterprises.
The real time data warehouse architecture with the inclusion of data stream management is presented in this work. Data stream management is divided into three parts that are extraction, processing and loading. This paper discusses in detail the data streams processing part. In each step, worthwhile techniques are used to make the data stream management efficient. The data streams processor takes valuable data contents from the data stream elements for achieving maximum accuracy.
It is necessary to work on data streams extraction and loading according to the requirements of the data streams processor in the future work and required a solution of the integration of the data from both operational data sources and data streams applications.
REFERENCES
[1] N. M. Tho, A. M. Tjoa, “Zero-latency Data Warehousing (ZLDWH): the state-of-the-art and experimental implementation approaches,” In proceedings of 4th IEEE Intl. conference on computer science research, 2003.
[4] S. Babu, J. Widom, “Continuous queries over data streams,” SIGMOD Record, 30(3): 109-120, sep. 2001.
[5] R. Basu, “Challenges of Real-time Data Warehousing,” DMReview article, 1999.
[6] S. Acharya, B. Gibbons, V. Poosala, “Congressional samples for approximate answering of group by queries,” In proceedings of the special interest group on management of data, pages 487-498, 1999. [7] N. M. Tho, A.M. Tjoa, “Zero latency data warehousing for
heterogeneous data sources and continuous data streams,” In proceedings of the 5th intl. conference on information integration, web
applications and services, Jakarta, Indonesia, 2004.
[8] P. Karakasidis, Vassiliadis, E. Pitoura, “ETL queues for active data warehousing, In proceedings of IQIS,” Pages 28-39, 2005.
[9] R. Bruckner, A. M. Tjoa, “Managing time consistency for active data warehouse environments,” In proceedings of the intl. conference on data warehousing and knowledge discovery, 2004.
[10] E. J. Kendall, E. K. Kendall, “Information delivery systems: An exploration of web pull and push technologies,” Tutorial, Volume1, Paper 14, April 1999.
[11] S. Guha, N. Koudas, “Approximating a data stream for querying and estimation: Algorithms and performance evaluation,” In proceedings of the data engineering, 2002.
[12] J. S. Turner, “New directions in communications (or which way to the information age),” IEEE Commun. Magazine, vol. 24, pp. 8-15, Oct. 1986.
[13] Blue Coat, “WAN Application Performance,” White Paper, 2007. [14] W.H. Inmon, “Building the data warehouse,” New York: Wiley, 1996.