Chapter 1: Introduction
Ajay Kshemkalyani and Mukesh Singhal
Distributed Computing: Principles, Algorithms, and Systems
Cambridge University Press
uting)
Distributed Computing: Principles, Algorithms, and Systems
Definition
Autonomous processors communicating over a communication network Some characteristics
)
No common physical clock
: it introduces the element of
“distribution” in the system and gives rise to the inherent
asynchrony amongst the processors.
)
No shared memory:
It requires message-passing for
communication. This feature implies the absence of the
common physical clock. It may be noted that a distributed
system may still provide the abstraction of a common
address space via the distributed shared memory
abstraction
)
uting)
Definition
• Geographical separation: A geographically wider apart that the
processors are, the more representative is the system of a distributed system
• Autonomy and Heterogeneity: The processors are “loosely coupled” in
Distributed Computing: Principles, Algorithms, and Systems
Distributed System
Model
P
P P P
P
M M M
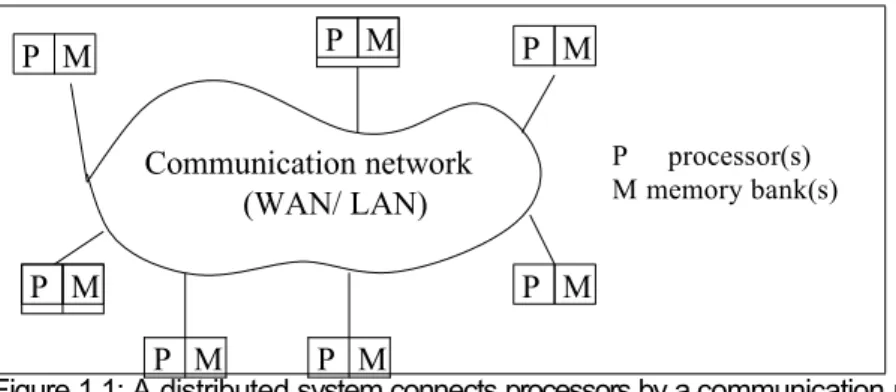
P M P M M M Communication network (WAN/ LAN) P processor(s) M memory bank(s)
Figure 1.1: A distributed system connects processors by a communication network.
uting)
Distributed Computing: Principles, Algorithms, and Systems
Relation between Software Components
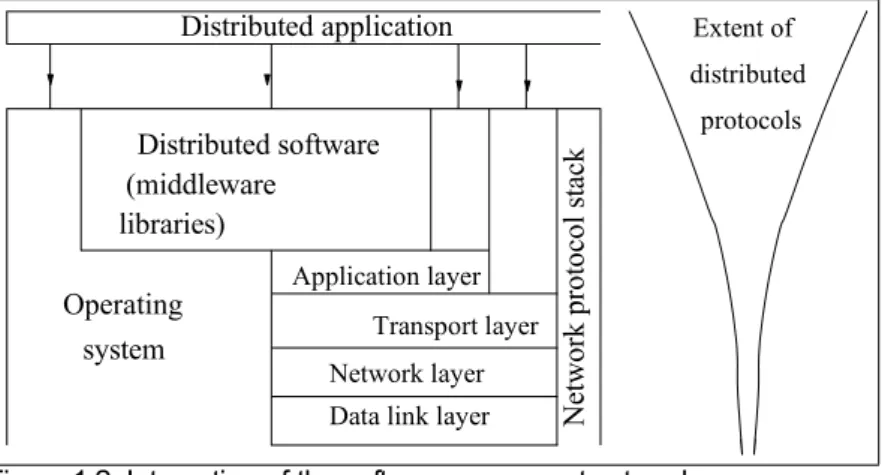
Extent of distributed protocols Distributed application Distributed software (middleware libraries) N et w or k pr ot oc ol s ta ck Operating system Application layer Transport layer Network layer Data link layer
Figure 1.2: Interaction of the software components at each process.
uting)
Relation between Software Components
• Figure 1.2 shows the relationships of the software components that
• run on each of the computers and use the local operating system and network protocol stack for functioning.
• The distributed software is also termed as middleware.
Distributed Computing: Principles, Algorithms, and Systems
Motivation for Distributed System
• Inherently distributed computation: In many applications such as money transfer in banking, or reaching consensus among parties that are geographically distant, the computation is inherently distributed. • Resource sharing: Resources are typically distributed across the system.
For example, distributed databases such as DB2 partition the data sets across several servers, in addition to replicating them at a few sites for rapid access as well as reliability.
• Access to remote resources: It is therefore stored at a central server which can be queried by branch offices. Similarly, special resources such as supercomputers exist only in certain locations, and to access such supercomputers, users need to log in remotely.
uting)
Motivation for Distributed System
• Increased performance/cost ratio
• Reliability: Reliability entails several aspects:
i. availability: the resource should be accessible at all times; ii. integrity: the value/state of the resource should be correct, in the face of concurrent access from multiple processors, as per the semantics expected by the application;
fault-tolerance: the ability to recover from system failures, • Scalability
Distributed Computing: Principles, Algorithms, and Systems
Terminology
Coupling
) Interdependency/binding among modules, whether hardware or software (e.g.,
OS, middleware) Parallelism: T (1)/T (n).
) Function of program and system
Concurrency of a program
) Measures productive CPU time vs. waiting for synchronization operations
Granularity of a program
) Amt. of computation vs. amt. of communication ) Fine-grained program suited for tightly-coupled system
uting)
Coupling
The degree of coupling among a set of modules, whether hardware or software, is measured in terms of the interdependency and binding and/or homogeneity among the modules. When the degree of coupling is high (low), the modules are said to be tightly (loosely) coupled.
• Tightly coupled multiprocessors (with UMA shared memory). These may be either switch-based (e.g., NYU Ultracomputer, RP3) or bus-based (e.g., Sequent, Encore).
• Tightly coupled multiprocessors (with NUMA shared memory or that • communicate by message passing). Examples are the SGI Origin 2000 • and the Sun Ultra HPC servers (that communicate via NUMA shared • memory), and the hypercube and the torus (that communicate by message
passing).
Coupling
• These may be bus-based (e.g., NOW connected by a LAN or Myrinet card) or using a more general communication network, and the processors may be heterogenous. In such systems, processors neither share memory nor have a common clock, and hence may be classified as distributed systems
Parallelism or speedup of a program on a specific
system
•
This is a measure of the relative speedup of a specific program, on a
given machine.
•
The speedup depends on the number of processors and the mapping
of the code to the processors.
Parallelism within a parallel/distributed program
Granularity of a program
The ratio of the amount of computation to the amount of communication within the parallel/distributed program is termed as granularity.
• In fine-grained parallelism: a program is broken down to a large number of small tasks. These tasks are assigned individually to many processors. As each task processes less data, the number of processors required to perform the complete processing is high. This in turn, increases the communication and synchronization overhead.
Granularity of a program
• In coarse-grained parallelism, a program is split into large tasks. Due to this, a large amount of computation takes place in processors. The advantage of this type of parallelism is low communication and synchronization overhead.
• If the degree of parallelism is coarse-grained (fine-grained), there are relatively many more (fewer) productive CPU instruction executions, compared to the number of times the processors communicate either via shared memory or message passing and wait to get synchronized with the other processors.
Distributed Computing: Principles, Algorithms, and Systems
Message-passing vs. Shared Memory
) Partition shared address space
) Send/Receive emulated by writing/reading from special mailbox per pair of
processes Emulating SM over MP:
) Model each shared object as a process
) Write to shared object emulated by sending message to owner process for the
object
) Read from shared object emulated by sending query to owner of shared object
uting)
Emulating MP over SM:
• The shared address space can be partitioned into disjoint parts, one part being assigned to each processor.
• “Send” and “receive” operations can be implemented by writing to and reading from the destination/sender processor’s address space, respectively.
• A separate location can be reserved as the mailbox for each ordered pair of processes.
• A Pi–Pj message-passing can be emulated by a write by Pi to the mailbox and then a read by Pj from the mailbox.
• In the simplest case, these mailboxes can be assumed to have unbounded size. • The write and read operations need to be controlled using synchronization
Emulating SM over MP:
This involves the use of “send” and “receive” operations for “write” and “read” operations. Each shared location can be modeled as a separate process;
“write” to a shared location is emulated by sending an update message to the corresponding owner process;
a “read” to a shared location is emulated by sending a query message to the owner process.
As accessing another processor’s memory requires send and receive operations, this emulation is expensive.
Primitives
There are two ways of sending data
Buffered option: copies the data from the user buffer to the kernel buffer. The data later gets copied from the kernel buffer onto the network.
Unbuffered option: the data gets copied directly from the user buffer onto the network.
For Send primitive– the buffered option and the unbuffered option.
Synchronous primitives
• A Send or a Receive primitive is synchronous if both the Send() and
Receive() handshake with each other.
• The processing for the Send primitive completes only after the invoking processor learns that the other corresponding Receive primitive has also been invoked and that the receive operation has been completed.
Asynchronous primitives
• A Send primitive is said to be asynchronous if control returns back to the invoking process after the data item to be sent has been copied out of the user-specified buffer.
Distributed Computing: Principles, Algorithms, and Systems
Classification of Primitives (1)
Synchronous (send/receive)
) Handshake between sender and receiver ) Send completes when Receive completes ) Receive completes when data copied into buffer
Asynchronous (send)
) Control returns to process when data copied out of user-specified buffer
uting)
Blocking primitives
Non-blocking primitives
• A primitive is non-blocking if control returns back to the invoking process immediately after invocation, even though the operation has not completed.
• For a non-blocking Send, control returns to the process even before the data is copied out of the user buffer.
• For a non-blocking Receive, control returns to the process even before the data may have arrived from the sender
Distributed Computing: Principles, Algorithms, and Systems
Classification of Primitives (2)
Blocking (send/receive)
) Control returns to invoking process after processing of primitive (whether sync
or async) completes Nonblocking (send/receive)
) Control returns to process immediately after invocation ) Send: even before data copied out of user buffer ) Receive: even before data may have arrived from sender
uting)
Distributed Computing: Principles, Algorithms, and Systems
Non-blocking Primitive
//handlek is a return parameter Send(X, destination, handlek )
... ...
Wait(handle1, handle2, . . . , handlek , . . . , handlem ) //Wait always blocks
Figure 1.7: A nonblocking send primitive. When the Wait call returns, at least one of its parameters is posted.
Return parameter returns a system-generated handle
) Use later to check for status of completion of call ) Keep checking (loop or periodically) if handle has been
posted
) Issue Wait(handle1, handle2, . . .) call with list of
handles
) Wait call blocks until one of the stipulated handles is
posted
uting)
Wait Call
• The completion of the processing of the primitive is detectable by checking the value of handlek. If the processing of the primitive has not completed, the Wait blocks and waits for a signal to wake it up.
• When the processing for the primitive completes, the communication subsystem software sets the value of handlek and wakes up (signals) any process with a Wait call blocked on this handlek. This is called posting
There are four versions of the Send primitive – i. synchronous blocking,
ii. synchronous non-blocking, iii. asynchronous blocking, and iv. asynchronous non-blocking.
Non- Blocking Calls
• For non-blocking calls, the burden on the programmer increases because he or she has to keep track of the completion of such operations in order to meaningfully reuse (write to or read from) the user buffers.
Processor synchrony
• All the processors execute in lock-step with their clocks synchronized. As this synchrony is not attainable in a distributed system,
• This abstraction is implemented using some form of barrier synchronization
Asynchronous Executions; Mesage-passing System
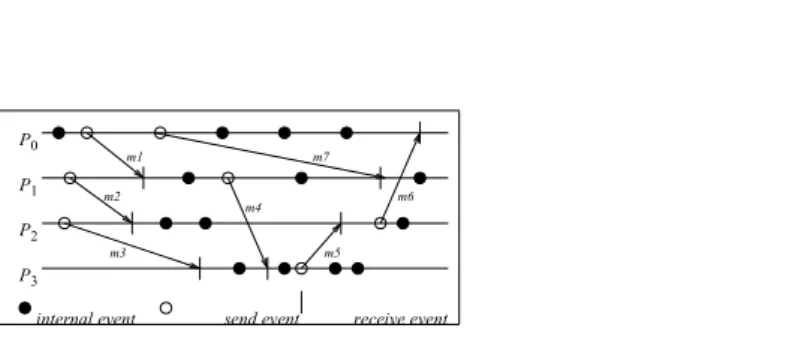
An asynchronous execution is an execution in which
(i) there is no processor synchrony and there is no bound on the drift rate of processor clocks,
(ii) message delays (transmission + propagation times) are finite but unbounded, and
Distributed Computing: Principles, Algorithms, and Systems
Asynchronous Executions; Mesage-passing System
P0
P1
P2
m4
m1 m7
m3 m5
m6 m2
P3
internal event send event receive event
Figure 1.9: Asynchronous execution in a message-passing system
uting)
synchronous execution
A synchronous execution is an execution in which
(i) processors are synchronized and the clock drift rate between any two processors is bounded,
(ii) message delivery (transmission + delivery) times are such that they occur in one logical step or round, and
Distributed Computing: Principles, Algorithms, and Systems
Synchronous Executions: Message-passing System
P P P P 3 2 0 1
round 1 round 2 round 3
Figure 1.10: Synchronous execution in a message-passing system In any round/step/phase: (send | internal )∗(receive | internal )∗
(1) Sync Execution(int k, n) / /k rounds, n processes.
each proc i receives msg from (i + 1) mod n and (i − 1) mod n;
(2)for r = 1 to k do
(3)proc i sends msg to (i + 1) mod n and (i − 1) mod n; (4) (5)
compute app-specific function on received values.
uting)
Distributed Computing: Principles, Algorithms, and Systems
Challenges: System Perspective (1)
The following functions must be addressed when designing and building a distributed system:
• Communication mechanisms: This task involves designing appropriate mechanisms for communication among the processes in the network. E.g., Remote Procedure Call (RPC), remote object invocation (ROI), message-oriented vs. stream-message-oriented communication
• Processes: process/thread management at clients and servers, Code migration,
Naming: Easy to use and robust schemes for names, identifiers,
and addresses is essential for locating resources and processes in a transparent and scalable manner.
• Synchronization: Mechanisms for synchronization or coordination among the processes are essential. Mutual exclusion is the classical example of synchronization
uting)
Challenges: System Perspective (2)
• Data storage and access
o Schemes for data storage, search, and lookup should be fast and scalable across network
o Revisit file system design
• Consistency and replication
o Replication for fast access, scalability, avoid bottlenecks o Require consistency management among replicas
• Fault-tolerance: correct and efficient operation despite link, node, process failures • Distributed systems security
o cryptography, Secure channels, access control, key management (key generation and key distribution), authorization, secure group management
Distributed Computing: Principles, Algorithms, and Systems
Challenges: System Perspective (3)
API for communications, services: ease of use
Transparency: hiding implementation policies from user
) Access: hide differences in data representation across systems, provide uniform
operations to access resources
) Location: makes the locations of resources transparent to the users ) Migration: allows relocating resources without renaming
) Relocation: relocate resources as they are being accessed ) Replication: hide replication from the users
) Concurrency: mask the use of shared resources ) Failure: reliable and fault-tolerant operation
Some experimental systems: Globe, Globus, Grid
uting)