Semi-supervised and Unsupervised Categorization of Posts in Web
Discussion Forums using Part-of-Speech Information and Minimal Features
Krish Perumal
Department of Computer Science University of Toronto Toronto, ON, M5S 3G4, Canada
Graeme Hirst
Department of Computer Science University of Toronto Toronto, ON, M5S 3G4, Canada
Abstract
Web discussion forums typically contain posts that fall into different categories such as ques-tion,solution,feedback,spam, etc. Automatic identification of these categories can aid in-formation retrieval that is tailored for specific user requirements. Previously, a number of su-pervised methods have attempted to solve this problem; however, these depend on the avail-ability of abundant training data. A few ex-isting unsupervised and semi-supervised ap-proaches are either focused on identifying only one or two categories, or do not dis-cuss category-specific performance. In con-trast, this work proposes methods for identify-ing multiple categories, and also analyzes the category-specific performance. These meth-ods are based on sequence models (specifi-cally, hidden Markov Models) that can model language for each category using both proba-bilistic word and part-of-speech information, and minimal manually specified features. The unsupervised version initializes the models us-ing clusterus-ing, whereas the semi-supervised version uses few manually labeled forum posts. Empirical evaluations demonstrate that these methods are more accurate than previous ones.
1 Introduction
Web discussion forums are platforms where peo-ple converse with one another to collaboratively solve problems and discuss issues. These are use-ful for existing users who participate in the discus-sion; however, new users need to read the entire fo-rum thread for obtaining a solution or a summary
of all opinions. This problem becomes much more pronounced in cases where threads contain tens or hundreds of posts, and reading the entire thread be-comes impractical1. In such cases, labeling the pur-pose of each post can guide the user towards useful posts (i.e., containing solutions) and away from triv-ial posts (i.e., containing feedback or off-topic dis-cussions). Moreover, current information retrieval techniques return entire threads as results to search queries. But by being sensitized to these anno-tations, they can return targeted results containing only the relevant posts. Further, user-contributed information contained in these forums can be bet-ter structured and can contribute towards the devel-opment of domain-specific knowledge bases. With these motivations in mind, this work aims to auto-matically annotate each post in a discussion forum with its purpose in the conversation thread. Our methods are not tailored for a specific domain or tagset. However, to demonstrate the objective of this work, Table 1 shows an example thread in which all posts are manually tagged with their purpose in the conversation.
2 Related Work
Categorizing forum posts is closely related to the task ofdialogue act tagging, which is defined as the identification of the meaning of an utterance at the level of illocutionary force (Stolcke et al., 2000); for example, an utterance could be identified as falling
1For example, the JeepForum thread http://www.
jeepforum.com/forum/f15/mud-tires-119948/ contains more than 500 posts discussing popular brands of tires.
Post Purpose User 15JKU: Hey Guys, Im looking to get 35s tires with either 18s or 20s as it will be more of
a daily driver and sometimes go mudding. My only concern is how they will perform in mud? Also, how loud would they for a daily driven jeep? Also, would A/T tires work for mudding?
Question
User mschi772: You need to more accurately convey what your true priorities are. You’re asking
for too much from one tire. Request forClarification
User 15JKU: Just asking if anyone knows how loud they are. My main concern is how they’ll
do on mud and if i should go with different tire. Clarification
User mschi772: Nitto Trail Grapplers are a ”classic” MT design. This is a very popular design
for people who frequently go offroading but want to maintain some street manners. Solution User JcArnold: I’ve got 37” trails and they are not noisy. I don’t know about mud but they are
great tires in the rocks and snow. Solution
User 15JKU: Thanks guys! Truly appreciate it. Feedback
Table 1: Example forum thread manually tagged with each post’s purpose in the conversation.
(Adapted from:http://www.jeepforum.com/forum/f15/tire-recommendations-3455674/) into one or more categories such asquestion,
solu-tion,clarification,feedback,command,request, etc. Most previous work has concentrated on super-vised machine learning methods (Catherine et al., 2012; Bhatia et al., 2012; Wang et al., 2010; Kim et al., 2010; Sondhi et al., 2010) using manually an-notated data in order to predict the annotations of unseen data. Apart from being constrained by the requirement of manually annotated data for train-ing, these methods are also limited in applicability to the domains they are trained on. In contrast, un-supervised methods overcome these drawbacks by identifying unlabeled clusters of data, each of which could potentially be mapped to a target category that one wants to identify. To the best of our knowl-edge, three unsupervised techniques have been pre-viously proposed for categorization of posts in Web forums. Out of these, Deepak and Visweswariah (2014) identified only answer posts, and Cong et al. (2008) additionally extractedquestionposts. The more difficult task of identifying multiple categories was tackled only by Joty et al. (2011). They used a combination of HMMs and Gaussian Mixture Mod-els (GMMs) in order to classify forum posts into 12 dialogue act categories. This model is similar to the content and conversation models used for other tasks by Ritter et al. (2010) and Barzilay and Lee (2004) respectively. In addition to the probability distribu-tion of wordn-grams, they use some structural fea-tures such as the chronological position of a post in the thread, the number of tokens in the post, and
au-thor identity. The motivation for this approach is that HMMs can model the sequential nature of dia-logue acts well. For example, the fact that asolution
is more likely to follow a question, as opposed to any other category, can be implicitly encoded in the HMMs. Our approach is inspired by the same idea.
One major drawback of unsupervised methods is that they often generate clusters unrelated to the tar-get categories. For example, clustering of forum posts on the travel domain might lead to a cluster containing posts pertaining to New York City sight-seeing alone. This cluster is irrelevant when the pur-pose is to find clusters of post categories such as
3 Proposed Methods
3.1 Conversation Model
As discussed previously, our models derive inspira-tion from the work of Joty et al. (2011). Our un-derlying model is the same but differs in several im-portant details. Our conversation model is a Hid-den Markov Model (HMM), in which hidHid-den (un-observed) states correspond to post categories, and emissions (observed) correspond to bags of post n -grams. Here, a threadTk consists of a sequence of category labels, and each category labelCi emits a bag of wordn-gramsNiof theithchronological post in the thread. The learning algorithm (Algorithm 1) of the conversation model uses iterative Expectation Maximization (EM) to maximize the expected prob-ability of a post given a state, repeating until con-vergence of the sum of all observation probabilities. During the expectation step (E-step), a wordn-gram language model is constructed for each state. Us-ing this state-specific language model, the emission probability of an observation (or post) can be cal-culated. During the maximization step (M-step), the most likely state sequence is calculated using Viterbi algorithm. The language model for each state is con-structed using smoothed n-gram frequency counts (using a smoothing parameter, δ1). The parameter,
lmType, determines the use of either unigrams or bi-grams. The initial state probabilities and state transi-tion probabilities are estimated using smoothed fre-quency counts of initial states and state transitions respectively (using a smoothing parameter of δ2). The calculation of these estimates is based on work by Barzilay and Lee (2004) (and are different from those of Joty et al. (2011)). A more detailed expla-nation of this model is made available by Perumal (2016).
In the HMM, the probability of a postPi, given a stateSk, is calculated as a categorical probability of its wordn-grams, as shown in Equation 1.
p(Pi|Sk) =
∏
j p(Wi,j|Lk) (1)
whereWi,j is the jth (in no particular order) word
n-gram in postPi, andLk is the language model for stateSk.
3.1.1 Unsupervised Version
In the unsupervised version, the prior probabili-ties of the model are derived from a two-step process (based on the work of Barzilay and Lee (2004)): (i) every post is represented as a vector of wordn-gram frequency counts, and (ii) the vectors are clustered using hierarchical clustering. The resultant cluster labels are used to calculate the frequency counts of initial HMM states and state transitions, and hence the corresponding probabilities. The priors are op-tionally calculated using an additional concept of in-sertion states. These are the states which contain a number of posts fewer than a fixed threshold, called
state size threshold. This concept is used to account for small noise states that pertain to no meaning-ful target category. If used, all insertion states are merged into a single state, representing a noise state.
3.1.2 Semi-Supervised Version
Instead of using unsupervised clustering, we pro-pose to derive the priors (i.e., the language model, the initial state probabilities and state transition probabilities) using smoothed frequency counts of post labels in few manually labeled threads. The ra-tionale of this process is to form a better real-world estimate of the model parameters in the first EM it-eration, and thereby reduce errors in the final predic-tions.
3.2 Conversation Model with Part-of-Speech Tags
Since the conversation models of Ritter et al. (2010) take only word n-gram language models into ac-count, it is likely that they output clusters of posts that are topically related, without reflecting the posts’ purpose or intention. To overcome this lim-itation, we enhance the plain conversation model by modeling HMM emissions partially from part-of-speech (POS) tags of words. This idea is based on the assumption that posts belonging to the same category are likely to be syntactically similar. For example, question posts are very likely to contain POS tags such asWDT,WP,WP$, andWRB2. Our model uses POS n-gram language models in addi-tion to wordn-gram language models, and calculates the HMM emission probability of a post given its
2These tags can be seen in the Penn Treebank project
state using a linear combination of both. Here, the probability of a postPi, given a stateSk, is calculated as shown in Equation 2.
p(Pi|Sk) =∏j
λ×p(Wi,j|Lk) + (1−λ)×p(POSi,j|PLk)
Z
0≤λ≤1
Z=∑
i,k
" ∏
j
λ×p(Wi,j|Lk) + (1−λ)×p(POSi,j|PLk)
# (2)
wherePOSi,j is the jth(in no particular order) POS
n-gram in postPi,PLk is the POSn-gram language model for state Sk, λ is the parameter that controls the proportion of probability arising from the word and POS language models (usingλ=1 is equivalent to the conversation model), andZis the normalizing constant.
3.3 Conversation Model with Features
As a further enhancement to the conversation mod-els, we incorporate discriminative features that might be useful for generating clusters that better represent the desired categories. For example, the chronological position of a post in a thread might be a useful feature, because a post is more likely to be aquestionif it is the first post in a thread as opposed to any other position. The following features are used: post position, post length, presence of ques-tion mark(s) (?,???, etc.) in current and preceding post, presence ofthankorthanks, presence ofsame
orsimilar, presence ofdid, presence of exclamation mark(s) (!, !!!, etc.), average cosine similarity with other posts in thread, cosine similarity with initial post, current post’s author identity, whether previ-ous post is by same author, number of previprevi-ous posts by current author, and total number of posts by cur-rent author. All feature values are discretized. Joty et al. (2011) also use a few specific features in their model, but our approach is more general and can ac-commodate a variable number of features. The prob-ability of a postPi, given a stateSk, is calculated as shown in equation 3.
p(Pi|Sk) =
∏
j p(Wi,j|Lk)
∏
f p(Fi,f|FLk) (3)whereFi,f is the fth(in no particular order) discrete-valued feature in post Pi, and FLk is the feature model for stateSk.
Ubuntu(Bhatia et al., 2012) Domain: Computer technical Tagset:Question,Repeat Question,
Clarification,Solution,Further Details,
Positive Feedback,Negative Feedback,Spam
Number of threads: 100
TripAdvisor-NYC(Bhatia et al., 2012) Domain: Travel
Tagset: Same asUbuntu Number of threads: 100 Apple(Catherine et al., 2012)
Domain: Computer technical Tagset:Answer
[image:4.612.314.540.58.277.2]Number of threads: 300 labeled and 140,000 unlabeled
Table 2: Discussion forum datasets used in the current work’s experiments.
3.4 Mapping of Clusters to Categories in Unsupervised Methods
Unsupervised methods output cluster labels for each post, not a specific category label. In order to pair them with an observed category label, a one-to-one mapping is obtained using the Kuhn-Munkres algo-rithm for maximal weighting in a bipartite graph (Kuhn, 1955; Munkres, 1957). The nodes of the graph correspond to the predicted cluster labels and gold labels, and the weights correspond to the num-ber of overlapping posts between them. In this pro-cedure, one set of disjoint nodes of the bipartite graph corresponds to the set of predicted cluster la-bels, and the other set corresponds to the set of man-ually obtained gold labels. The weight of an edge from cluster labelc to gold labelg is calculated as the number of posts which are predicted as c and also have a gold labelg. Joty et al. (2011) follow the same procedure.
4 Experiments
4.1 Datasets
Algorithm 1Conversation model
Input: A list of threadsT, each containing a list of postsP(in chronological order)
Parameters:initialNumClusters,mergeInsertionStates,stateSizeThreshold,maxNumIterations,lmType,δ1,δ2
Output: A list of cluster labelsCLfor each post in each thread (in the order of the input) 1: for allthreadTxdo
2: for allpostPx,y∈Txdo
3: Vx,y:=vectorize(Px,y) //Vx,yis the vector of postPx,y 4: end for
5: end for
6: ICL:=cluster(V,initialNumClusters) //ICLis the list of initial cluster labels for each post (ICLx,y is the initial cluster label for postPx,yin threadTx)
7: S:=ICL //Sis the list of states for all posts; at this step, it is the same as the initial cluster labels 8: forn=1→maxNumIterationsdo
9: ifmergeInsertionStatesistruethen
10: [S,numStates]:=merge small states(S,stateSizeThreshold) 11: end if
12: fori=1→numStatesdo 13: SPi=/0
14: for allstateSx,ydo 15: ifSx,y=ithen
16: SPi:=SPi∪Px,y //SPiis the set of all posts that belong to statei 17: end if
18: end for
19: Li:=language model(SPi,lmType,δ1) 20: end for
21: fori=1→numStatesdo
22: init countsi:=ΣTx1Sx,1=i //Sx,1is the state of the first post in threadTx
23: end for
24: fori=1→numStatesdo
25: πi:= (init countsi+δ2)/(Σk(init countsk) +δ2×numStates) //πiis the probability that initial state isi 26: end for
27: fori=1→numStatesdo 28: for j=1→numStatesdo 29: trans countsi,j:=∑Tx
|Tx|−1
∑
a=1 1Sx,a=i,Sx,a+1=j 30: end for
31: end for
32: fori=1→numStatesdo 33: for j=1→numStatesdo
34: φi,j:= (trans countsi,j+δ2)/(Σk,l(trans countsk,l)+δ2×numStates2) //φi,jis the probability of tran-sitioning from stateito state j
35: end for 36: end for
37: S:=Viterbi algorithm(π,φ,L)
38: ifsum of observation probabilities convergedthen 39: break
4.2 Preprocessing and Configuration Parameters
Initially, all forum posts were tokenized by sentence and word, followed by POS tagging and stemming — all using Stanford CoreNLP Toolkit (Manning et al., 2014). Stopword removal was found to degrade performance; hence, it was not used. Forum conver-sations often consist of informal English language text, along with the use of domain-specific abbrevia-tions and non-standard special characters such as el-lipses and emoticons. Hence, some errors are intro-duced in all the previous steps. However, no effort was made to overcome them, and this is accepted as a limitation of the current work.
All methods require the conversion of posts to vectors of n-grams. For this purpose, we experi-mented with both unigrams and bigrams, and the former was found to produce better performance. The maximum number of iterations of Expecta-tion MaximizaExpecta-tion was set to 100, which was suffi-cient because all experimental runs were completed in fewer than 100 iterations. The values of both smoothing parameters (i.e., δ1 andδ2) were varied in the range of 10−1 to 10−9. Subsequently, 10−2 and 10−9 were found to be the best values for δ1 andδ2 respectively. The value of the POS model’s
λ was varied between 10−6 and 1−10−6, and the value of 0.999 was found to be the best. Since the unigram/bigram vocabulary size is much larger than the POS tag vocabulary size, the former prob-ability distribution is much more fine-grained. For example, each word unigram’s probability value in the NYC dataset is of the order of 10−4 (since the unigram vocabulary size is 5000), whereas each POS unigram’s probability value is of the order of 10−2 (since the POS vocabulary size is 42). So, the value of 0.999 for word unigrams and 0.001 for POS unigrams can be viewed as a scaling factor to ensure that both contribute almost equally towards discriminating between post categories. The param-eters, initialNumClusters and stateSizeThreshold, directly affect the resulting number of clusters. In all experimental runs, both these parameters were var-ied in the range of 1 to 100, and those which did not output the desired number of clusters (i.e., number of distinct gold labels) were ignored. In each case,
different parameter values were best suited; how-ever, only the best performing results are reported.
For semi-supervised methods, experiments were carried out in a randomizedn-fold cross-validation setup. The dataset was randomly divided (by sam-pling from the uniform distribution) into n equal-sized folds, and the experiment was runntimes. In each run, one fold was used for initializing the priors of the models, and the remainingn−1 folds were used for evaluation. In the case of language mod-els, different datasets benefited from using one of word/POS unigram or bigram models. Hence, ex-periments were run using both, and results are re-ported for the better performing alternative.
4.3 Baselines
Therandom baselinerandomly assigns category la-bels to every post (by sampling from the uniform distribution). Themajority baselineassigns the most commonly occurring gold category label to every post, which is solution for all the datasets used in this work. Two other baselines are heuristic in na-ture, and are both based on the assumption that the first post in the thread is very likely to be a ques-tion. The first of these, called question-solution heuristic 1, assignsquestion to the first post in the thread, spam/otherto the last post, and solutionto the rest. It assumes that the last post in the thread is very likely to be unrelated to the main thread topic and that many of the preceding posts are likely to be solution. The second heuristic baseline, called
question-solution heuristic 2, assignsquestionto the first post in the thread, solutionto the second post, andspam/otherto the rest. It assumes that the sec-ond post is very likely to be asolutionin direct re-sponse to the first question post, and many of the following posts are likely to bespam/other.
4.4 Main Results
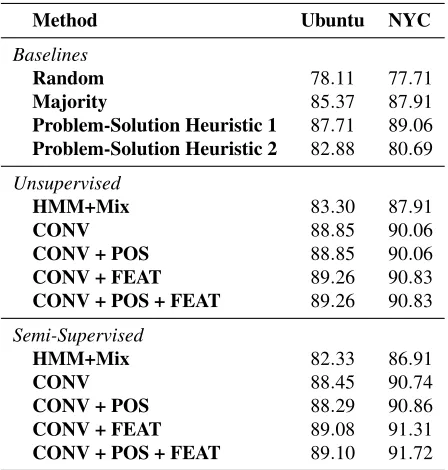
Accuracy (%)
Method Ubuntu NYC
Baselines
Random 78.11 77.71
Majority 85.37 87.91 Problem-Solution Heuristic 1 87.71 89.06 Problem-Solution Heuristic 2 82.88 80.69 Unsupervised
HMM+Mix 83.30 87.91
CONV 88.85 90.06
CONV + POS 88.85 90.06 CONV + FEAT 89.26 90.83 CONV + POS + FEAT 89.26 90.83 Semi-Supervised
HMM+Mix 82.33 86.91
CONV 88.45 90.74
CONV + POS 88.29 90.86 CONV + FEAT 89.08 91.31 CONV + POS + FEAT 89.10 91.72 Table 3: Experimental results for the Ubuntu and NYC datasets using all the possible combinations of models in both unsupervised and semi-supervised settings (CONV: Conversation model; POS: Part-of-speech tags; FEAT: Features).
Joty et al. (2011) reported results of their best per-forming HMM+Mix model for dialogue act classifi-cation on email and forum thread datasets. The code and datasets are not available to other researchers; hence, we implemented the HMM+Mix, while also accommodating the additional features that we used for our methods.
Our unsupervised methods beat all the baselines, in contrast to Joty et al. (2011)’s HMM+Mix, which beats only the random baseline. The use of both POS tags and features results in the best overall perfor-mance, whereas the use of POS tags does not make any difference in performance. The semi-supervised adaptation of the existing HMM+Mix model outper-forms only the random baseline. However, all of our semi-supervised methods beat all the baselines. In this case, the sole use of POS tags or features results in improved performance. But the use of both in combination leads to the best performance overall. Specifically, for the Ubuntu dataset, the best aver-age accuracy value is 89.10%. In case of the NYC dataset, the corresponding best value is 91.72%. The corresponding absolute accuracy values are 56.40%
Method P R F1
[image:7.612.315.537.60.111.2]Catherine et al. (2013) 0.57 0.84 0.68 CONV + POS + FEAT 0.66 0.73 0.69 Table 4: Experimental results comparing the perfor-mance of an existing semi-supervised answer extraction method with our best semi-supervised method (i.e., con-versation model with POS tags and features).
Category P R F1
Question 83.81 73.95 78.57
Repeat Question 0.00 0.00 0.00
Clarification 78.57 22.45 34.92
Further Details 40.00 8.51 14.04
Solution 66.05 96.56 78.44
+ve Feedback 0.00 0.00 0.00
-ve Feedback 60.78 30.10 40.26
[image:7.612.74.298.70.305.2]Junk 33.33 4.00 7.14
Table 5: Experimental results of semi-supervised con-versation model with POS tags and features for one of the folds in a 10-fold cross-validation setup using the NYC dataset.
and 66.86% respectively. The reported results using semi-supervised methods are averages over 10 runs of a randomized 10-fold cross-validation setup.
Catherine et al. (2013) reported the performance of their semi-supervisedanswerextraction approach on 300 labeled threads of the Apple discussion fo-rums dataset. They trained using only three training threads; however, the identities of these three are not known. The code is also unavailable. Hence, the methods can only be compared indirectly. For the methods of Catherine et al. (2013), precision, recall andF1-measure values are obtained from their paper. The same values are reported for our best method (i.e., the semi-supervised conversation models with POS tags and features), using a 100-fold cross-validation setup; i.e., out of 300 labeled threads, 3 were used for training, and 297 were used for test-ing in each fold. Table 4 shows that our method per-forms better in terms ofF1-measure and precision.
4.5 Category-wise Performance and Error Analysis
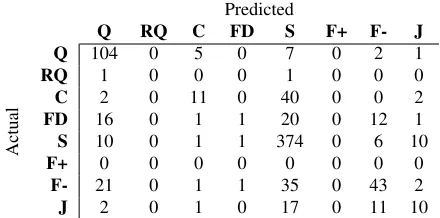
[image:7.612.314.538.171.299.2]Predicted
Q RQ C FD S F+ F- J
Actual
Q 104 0 5 0 7 0 2 1
RQ 1 0 0 0 1 0 0 0
C 2 0 11 0 40 0 0 2
FD 16 0 1 1 20 0 12 1
S 10 0 1 1 374 0 6 10
F+ 0 0 0 0 0 0 0 0
F- 21 0 1 1 35 0 43 2
[image:8.612.77.297.58.167.2]J 2 0 1 0 17 0 11 10
Table 6: Confusion matrix of the semi-supervised con-versation model with POS tags and features, for one of the folds in a 10-fold cross-validation setup using the NYC dataset (Q: Question; RQ: Repeat Question; C: Clarification; FD: Further Details; S: Solution; F+: Posi-tive Feedback; F-: NegaPosi-tive Feedback; J: Junk).
model with POS tags and features. Table 6 shows the confusion matrix of the same experiment. The confusion matrix for the Ubuntu dataset is similar. Predictions of question, solution, clarification and
negative feedbackare the best in terms of precision values; however, the recall values of the two latter categories are not practically useful. The most com-mon error is the prediction of a non-solution cate-gory as solution, indicating a bias towards predict-ing the majority category. Overall, the predictions of minority categories are not practically useful, be-cause they were less accurate than the predictions using the random baseline. Specifically, there are no predictions ofrepeat questionandpositive feed-back, owing to the minuscule number of posts with these labels. Since previous literature ignores the analysis of category-wise performance altogether, a direct comparison is not possible. But this confusion matrix indicates a major weakness of current semi-supervised and unsemi-supervised approaches in classify-ing minority categories.
5 Conclusions and Future Work
Our experimental results indicate that our unsuper-vised methods are not adequate for tackling a task as complex as forum post categorization. However, they are able to capture some useful sequential de-pendencies, as observed from the fact that they out-performed the random and majority baselines. Also, knowledge of POS tags and simple textual features provided more context for classification, and thus enabled the technique to classify more accurately. The novel proposal of incorporating a few labeled
examples for initializing the model priors led to bet-ter performance than thequestion-solution heuristic
baselines in most cases. Our experiments demon-strate that these methods perform better than pre-vious methods. Prediction of question and solu-tioncategories were the most accurate, followed by
clarificationandnegative feedback. However, pre-dictions of the minority categories are not accurate enough to be practically useful.
Discussion forum posts often contain multiple dialogue categories, i.e., a post could start with some sentence(s) mentioning asolutionto a previ-ousquestion, and end with some sentence(s) posing a newquestion. Such cases can be tackled by em-ploying a 2-tier hierarchical HMM which models the transition between sentence categories within a sin-gle post (in addition to the higher-level post category transitions). However, this proposal is dependent on the availability of datasets that are annotated by cat-egory at the sentence level. The lack of knowledge of long-range dependencies between different cate-gories is another drawback of current methods. Con-sequently, they are unable to learn that a post cannot be classified assolution, without any question post before it. This problem can be addressed by using higher-order Markov chains, but this would lead to much greater run-time and space complexity as well as specially tailored algorithms for inference. In-stead, the use of heuristics to flag certain categories, based on prior post categories in the thread, could resolve this problem more efficiently. Moreover, ef-fort should be made to balance the distribution of categories that are used for initializing and training the methods. We leave these ideas for exploration in future work.
Acknowledgments
This research was supported by the Natural Sciences and Engineering Research Council of Canada un-der the Engage grant (no. EGP 477227-14). We thank Afsaneh Fazly and Mohamed Abdalla for their valuable contributions, and thank the anonymous re-viewers for their constructive feedback.
References
to generation and summarization. InProceedings of the 2nd Human Language Technology Conference and Annual Meeting of the North American Chapter of the Association for Computational Linguistics, pages 113–120.
Sumit Bhatia, Prakhar Biyani, and Prasenjit Mitra. 2012. Classifying user messages for managing Web forum data. InProceedings of the 15th International Work-shop on the Web and Databases (WebDB’12), pages 13–18.
Rose Catherine, Amit Singh, Rashmi Gangadharaiah, Di-nesh Raghu, and Karthik Visweswariah. 2012. Does similarity matter? The case of answer extraction from technical discussion forums. In Proceedings of the 24th International Conference on Computational Lin-guistics (COLING), pages 175–184.
Rose Catherine, Rashmi Gangadharaiah, Karthik Visweswariah, and Dinesh Raghu. 2013. Semi-supervised answer extraction from discussion forums. In Proceedings of the 6th International Joint Con-ference on Natural Language Processing (IJCNLP), pages 1–9.
Gao Cong, Long Wang, Chin-Yew Lin, Young-In Song, and Yueheng Sun. 2008. Finding question-answer pairs from online forums. InProceedings of the 31st Annual International ACM SIGIR Conference, pages 467–474.
P Deepak and Karthik Visweswariah. 2014. Unsuper-vised solution post identification from discussion fo-rums. InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, pages 155–164.
Minwoo Jeong, CY Lin, and GG Lee. 2009. Semi-supervised speech act recognition in emails and fo-rums. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1250–1259.
Shafiq Joty, Giuseppe Carenini, and Chin Yew Lin. 2011. Unsupervised modeling of dialog acts in asynchronous conversations. In Proceedings of the 22nd Interna-tional Joint Conference on Artificial Intelligence (IJ-CAI), pages 1807–1813.
Su Nam Kim, Li Wang, and Timothy Baldwin. 2010. Tagging and linking web forum posts. InProceedings of the 14th Conference on Computational Natural Lan-guage Learning (CoNLL), pages 192–202.
Harold W Kuhn. 1955. The Hungarian method for the assignment problem. Naval Research Logistics Quar-terly, 2(1-2):83–97.
Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language pro-cessing toolkit. In Proceedings of the 52nd Annual
Meeting of the Association for Computational Linguis-tics: System Demonstrations, pages 55–60.
Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beat-rice Santorini. 1993. Building a large annotated cor-pus of English: The Penn Treebank. Computational linguistics, 19(2):313–330.
James Munkres. 1957. Algorithms for the assignment and transportation problems. Journal of the Society for Industrial and Applied Mathematics, 5(1):32–38. Krish Perumal. 2016. Semi-supervised and
un-supervised methods for categorizing posts in web discussion forums. Master’s thesis, University of Toronto. http://ftp.cs.toronto.edu/ pub/gh/Perumal-MSc-2016.pdf.
Alan Ritter, Colin Cherry, and Bill Dolan. 2010. Unsu-pervised modeling of Twitter conversations. In Pro-ceedings of the 2010 Annual Conference of the North American Chapter of the Association for Computa-tional Linguistics, pages 172–180.
Parikshit Sondhi, Manish Gupta, ChengXiang Zhai, and Julia Hockenmaier. 2010. Shallow information ex-traction from medical forum data. InProceedings of the 23rd International Conference on Computational Linguistics (COLING), pages 1158–1166.
Andreas Stolcke, Klaus Ries, Noah Coccaro, Eliza-beth Shriberg, Rebecca Bates, Daniel Jurafsky, Paul Taylor, Rachel Martin, Carol Van Ess-Dykema, and Marie Meteer. 2000. Dialogue act modeling for automatic tagging and recognition of conversational speech. Computational Linguistics, 26(3):339–373. Li Wang, Su Nam Kim, and Timothy Baldwin. 2010.