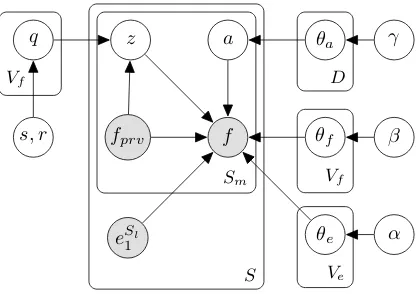
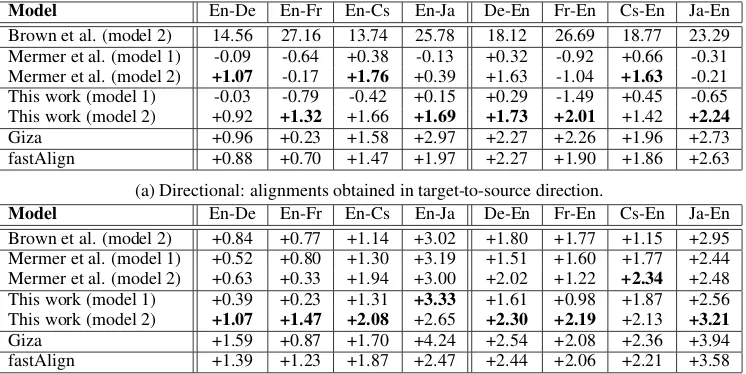
Word Alignment without NULL Words
6
0
0
Full text
Figure
Related documents