1 | International Journal of Computer Systems, ISSN-(2394-1065), Vol. 03, Issue 07, July, 2016 International Journal of Computer Systems (ISSN: 2394-1065), Volume 03– Issue 07, July, 2016
Available at http://www.ijcsonline.com/
QUESTION ANSWERING SYSTEM USING SIMILARITY AND
CLASSIFICATION TECHNIQUES
Nabeel NeamahȦ, Saidah SaadḂ
Ȧ Faculty of Information Sciences and Technology, UKM, Bangi, Malaysia Ḃ School of IT, Faculty of Information Sciences and Technology, UKM, Bangi, Malaysia
Abstract
The main aim of question answering system is provide correct answers based on users’ queries. Question answering system developed to provide answers for various domains or restricted domain. There are main challenges face the question answering systems such as extract answers based on weak concepts of users’ queries and difficulty to retrieve accurate answers from large corpus of documents. These challenges increase the difficulty of questions analyzing and retrieve relevant and correct answers based on users’ queries. This research applies several NLP methods such as tokenization, stemming, and N-gram in order to analyze the users’ query effectively. Additionally, SVM method is deployed to classify the answers’ documents based on questions types in order to reduce the searching scope of proposed answers. The findings revealed that the average answers accuracy using CS technique is 67%, the average answers accuracy using LCS technique is 66%, the average answers accuracy using combination of CS and LCS techniques is 70%, and the average answers accuracy using CS, LCS, and SVM is 80%. Results accuracy involving SVM method is more accurate than other methods like CS and LCS. SVM enhance the system accuracy up to 10% more than using other methods without classification processes
Keywords: Question Answering System, NLP, SVM, Hadiths, Classification, Similarity
I. INTRODUCTION
Nowadays, there are large increasing of information sources such as online sources; these sources contain huge volume of information related to variant fields of topics i.e. economic, health, industry, and educational information [1, 2]. Traditional retrieving systems like google search engine retrieve information based on searching keywords of the users' queries rather than retrieve exact answers based on searching queries [3, 4]. For example, traditional search engine will retrieve documents that contain words similar to "Iraq" and "capital" based on the query "what is the capital of Iraq" rather than retrieve the accurate answer which is "Baghdad". Therefore, the users could expense efforts and time to find exact answers from large sources. There are two important processes to ensure the accuracy of QAS; (1) analyze the users' Query needs using various methods such as Natural Processing Language (NLP), and (2) classify and manage the documents that contain the candidates' answers accurately based on many methods such as machine learning. Therefore, the accurate matching between users' questions and the proposed answers will be founded effectively [5, 6]. The main aim of methods such as NLP is to update the concepts of users' queries based on formal representation of documents concepts which maximize the opportunities of found the similarities between users' quires and documents contents. On the other hand, the questions and documents classifications will support the matching between the users' types of questions and the proposed answers based on questions types [6, 7]. The user’s questions classify as many types such as "What" to inquire about facts and explanations, "Where" to ask
about places, and "Who" to ask about persons; the documents classified based on the purpose of information depend on questions types i.e. places information to match "Where" questions. The main problem of this research is the difficulty of retrieve accurate answers based on Hadiths documents due to two main reasons which are as the following:
i. Difficulty of provide formal concepts of Hadiths query: the Hadiths documents written based on Arabic languages using classical concepts. Currently, Arabic people are used the modern Arabic concepts. This would increase the difficulty of provide query concepts according to formal concepts of Hadiths. Also, non Arabic people face difficulty of provide the right concepts based on English language due to their weakness of Arabic language skills and knowledge weakness of Hadiths formal concepts using English.
ii. Large document of Hadiths that provided by various resources: Hadiths are spoken by Mohammad (Islam messenger) and after many decades these Hadiths were written as texts. Currently, there are large numbers of Hadiths published through various sources such as internet and books. This could increase the difficulty of extract right Hadiths that match with users needs.
The main objective of this research is to develop question-answering systems using NLP and machine learning methods in order to retrieve accurate answers of Hadiths based on users' questions. The following section presents related works to this research. Section 3 explains the
research methodology. Section 4 presents the experimental data of the proposed QAS. Section 5 discusses the experimental results of this research. Lastly, section 6 presents the conclusion and future works.
II. RELATED WORKS
This presents literature of queries analysis, sentence similarity matching, WordNet Ontology, and documents classifications using machine learning.
A. Questions Analysis Using NLP
The queries analyzed and evaluated based on many factors such as question type and keywords. Reference [8] mentioned that, there are two parts for question analysis which are; (1) concepts analysis by extract the main or important concepts of users’ queries, and (2) concepts processing through update the analyzed concepts to be compatible with formal representations of QA domains concepts. According to [9], the main NLP methods for this stage are as the following:
1. Normalization: Text normalization is the process of transforming text into a single canonical form that it might not have before. Normalizing text before storing or processing it allows for separation of concerns, since input is guaranteed to be consistent before operations are performed on it. Text normalization requires being aware of what type of text is to be normalized and how it is to be processed afterwards; there is no all-purpose normalization procedure. Text normalization is frequently used when converting text to speech. Numbers, dates, acronyms, and abbreviations are non-standard "words" that need to be pronounced differently depending on context. For examples, "$200" would be pronounced as "two hundred dollars" in English, but as "lua selau tālā" in Samoan and "vi" could be pronounced as "vie," "vee," or "the sixth" depending on the surrounding words.
2. Remove stop words to remove the un-important keywords such as 'and', 'the', and 'has'. Stop words are words that are filtered out before or after processing of natural language data (text) [10]. There is no single universal list of stop words used by all processing of natural language tools, and indeed not all tools even use such a list. Some tools specifically avoid removing these stop words to support phrase search. Any group of words can be chosen as the stop words for a given purpose. For some search engines, these are some of the most common, short function words, such as the, is, at, which, and on. Other search engines remove some of the most common words—including lexical words, such as "want"—from a query in order to improve performance.
3. Tokenization which divides the text sequence into sentences and then the sentences into tokens. So, In the English language, words are bounded by whitespace and optionally preceded and followed by parentheses, quotes, or punctuation marks. Therefore, the tokenization divides the character sequence based on the whitespace positions or other punctuation marks between words in the sentence. In
addition, it cuts off the parentheses and punctuation marks to obtain the sequence of tokens.
4. N-gram which works on divides the sentences into words in query, where the N-gram algorithm focuses on calculating word by word, two words by two words and so on. Word gram is a contiguous sequence of 1-n items from a given sequence of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. The n-grams typically are collected from a text or speech corpus. An n-gram of size 1 is referred to as a "unigram"; size 2 is a "bigram" (or, less commonly, a "diagram"); size 3 is a "trigram". Larger sizes are sometimes referred to by the value of n, e.g., "four-gram", "five-gram", and so on [11, 12].
B. Similarity Measure
This section discusses the most common techniques of sentence similarity measuring which are; Cosine similarity (CS) and Longest Common Subsequences (LCS). In QAS, CS and LCS techniques are used widely to measure the similarity between users’ queries and system documents [13]. Based on CS and LCS techniques increase the opportunity of extract accurate answers depend on users’ questions.
i. Cosine Similarity (CS)
Cosine similarity (CS) is a well-known vector based similarity measure in the fields of text mining and information retrieval. Basically, this measure is extensively employed to estimate the relationship between words, the strength of association between elements in two sets is determined by considering the cosine of the angle between two feature vectors. When two vectors are exactly the same, the angle between them is 0, and the cosine of the angle between them is 1; when the vectors are orthogonal, the cosine value is 0. After obtaining the term weights (wij, wlj) of all words by, it's easy to apply cosine similarity to compute the similarity of two sentences. The cosine similarity between two sentences (si and sl) is defined as the following formula:
simcs( , ) = = , i, l=1,…,n. (1)
where is the number of similar words between both sentences, the is the total number of the weights of words in |si| and |sl| sentences.
ii. Longest Common Subsequence (LCS)
Nabeel Neamah et al Question Answering System Using Similarity and Classification Techniques
are closely related terminologies for multiple sequences, namely Longest Common Subsequence (LCS). Given sequences S= s1…sm and T = t1…tn, S is the subsequence of T if for each 1 ≤ j ≤ m, 1 ≤ i1 < i2< …< im ≤ n, sj = j i t. Given a set of sequences S+ = {S1, S2, …, Sk}, the LCS of S+ is the longest. Possible sequence T such that it is a subsequence of each and every sequence in S at the same time. Emphasizing the given set of sequences, their LCS and pattern are related; LCS represent different aspects of these sequences’ profile and it can all be used for sequence comparisons and analysis.
C. Classification Based Machine Learning
Since presenting all syntactic and semantic rules of a language to algorithm is a cumbersome task, for this reason different types of algorithms are made that can receive different examples and have the learning ability and can preview the user' expected response easily. Using machine learning, we can generate systems that includes thousands features of questions and do classification those questions automatically. This action increases the productivity rate of QAS [14]. Any text classification algorithm can be employed such SVM to classify the texts based on the purpose of information that included in this text [15, 16, 17]. For example, the text that talk about places is referring to where questions and the text that talk about date and time refer to when questions and so on.
i. Support Vector Machine (SVM)
SVM is a useful technique for data classification and it is easier to be implemented than other classification methods such as Neural Networks. A classification task usually involves separating data into training and testing sets. Each instance in the training set contains one “target value” (i.e. the class labels) and several “attributes” (i.e. the features or observed variables). The goal of SVM is to produce a model (based on the training data) which predicts the target values of the test data given only the test data attributes. Given a training set of instance-label pairs (xi, yi), i = 1, . . ., l where xi ∈ Rn and y ∈ {1, −1}, the support vector machines (SVM) [18] require the solution of the following optimization problem:
Here training vectors xi are mapped into a higher (maybe infinite) dimensional space by the function φ. SVM finds a linear separating hyperplane with the maximal margin in this higher dimensional space. C > 0 is the penalty parameter of the error term. Furthermore, K (xi, xj) ≡ φ(xi) T φ(xj ) is called the kernel function. Though new kernels are being proposed by researchers, beginners may find in SVM books the following four basic kernels:
• Linear: K (xi, xj) = x T i xj.
• Polynomial: K (xi, xj) = (γxi T xj + r) d , γ > 0.
• Radial basis function (RBF): K (xi, xj) = exp(−γkxi −xjk 2 ), γ > 0.
• Sigmoid: K (xi, xj) = tanh (γxi T xj + r). Here, γ, r, and d are kernel parameters.
III. RESEARCH DOMAIN
This research focuses on question answering system for Hadiths. The domain of this research is as the following:
i. Hadiths Sources: Albukary documents of Hadiths is the main documents source of this research due to many reasons such as Albukary documents of Hadith considered as the most trust sources of Hadiths. These documents are standard references in the Islam world, and Albukhary source contain large volume of Hadiths in various subjects. Thus, it is required to classify and analyze the documents based users’ query efficiently.
ii. Language of Hadiths documents: formal English translate of Hadiths is the language of Hadiths documents in this research. The non Arabic people face difficulty in provide effective concepts of Hadiths queries more than the Arabic people.
iii. Hadiths Subjects: pray and fasting are the main two Hadiths subjects in this research. These subjects involve the Muslim daily activities. The other subjects such as Hajj, Zakat, and Al-shahadateen are accomplished by Muslims for one time in the life or 1 time yearly.
iv. Questions Types: this research focuses on classify users’ queries and Hadiths documents depend on two types of questions; (1) ‘Where’, and (2) ‘When’. These types of questions are related to places and time classes. Pray and fasting questions and documents are mostly about places and time.
IV. METHOD
The research method involves two important directions that effects on question answering system accuracy. Firstly, the users could not have the effective skills to provide their questions in right way. For example, the query typing of “what is Malaysia capital?” is better than typing “give me cities in Malaysia”. Therefore, the question answering system could address this challenge using NLP methods. Secondly, the document classifications according to queries types (i.e. When questions) using machine learning methods could improve the accuracy of provided answers. The NLP and machine learning methods selection of question answering system for Hadiths domain take into account many points based on question answering system aspects and research scope. These points are as the following:
focuses on many fields like weather and hotels bookings. However, the Hadith domain contains large information about various related fields e.g. Pray, Zakat, Fasting, Alshadteen, and Pilgrimage. Thus, this research focuses on two main fields which are Pray and fasting due to its relation with daily activities of people. The other fields like pilgrimage are done one time in the life.
Type of users query: there are two main types of questions which are open and restricted questions. In this research the restricted type is adopted in order to provide more accurate answers. The restricted type of questions help the users to manage their query using define keywords such as “what”, “when”, “where”, and “how” questions. On other hand, the documents or answers can be managed according question type which increases the opportunity to retrieve accurate answers from large documents. Specifically, this research focuses on “when” and “where” questions due to nature of selected Hadith fields. Usually, the fasting subject is related to time (i.e. “When”) and the Pray is related to time and places (i.e. “where” and “when”).
Architecture of question answering systems: the question answering systems involve two main directions in order to increase the opportunities of provide accurate answers; (1) query analysis, (2) and documents or answers management. The query analysis can accomplished effectively using many methods such as tokenization, stop-word removing, and N-gram. On the other side, one of most effective methods to classify the documents based on specific indicators’ (i.e. questions types) such SVM method.
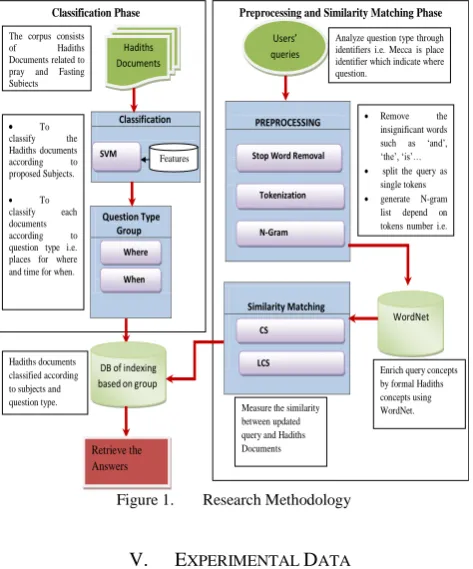
Another important process of question answering system is the concepts similarity which support the answers retrieving based on similarity measuring between query and system documents. Also, the similarity is important to enhance the users’ query supporting ontology that contains standard or right concepts of the related domain. The Cosine Similarity (CS) and Long Common Similarity (LCS) are the most common similarity measuring techniques in question answering systems and the WordNet is used widely for the purpose of extract and replace the weak concepts in queries by right concepts. Consequently, Fig. 1 illustrates the methodology of this research according to selected methods of question answering system. The methodology can be described as three main phases which are preprocessing phase, similarity measuring phase, and classification phase.
Preprocessing and Similarity Matching Phase Classification Phase
Figure 3.1: Research Methodology Similarity Matching
PREPROCESSING Classification
Question Type Group
Hadiths Documents
Users’ queries
CS
LCS Stop Word Removal
N-Gram Tokenization SVM
WordNet
DB of indexing based on group
Retrieve the Answers
The corpus consists
of Hadiths
Documents related to pray and Fasting Subjects
To
classify the Hadiths documents according to proposed Subjects.
To
classify each documents according to question type i.e. places for where and time for when.
Where
When
Hadiths documents classified according to subjects and question type.
Remove the
insignificant words such as ‘and’, ‘the’, ‘is’… split the query as
single tokens generate N-gram
list depend on tokens number i.e. 3-gram from 3 tokens.
Enrich query concepts by formal Hadiths concepts using WordNet. Analyze question type through identifiers i.e. Mecca is place identifier which indicate where question.
Measure the similarity between updated query and Hadiths Documents Features
Figure 1. Research Methodology
V. EXPERIMENTAL DATA
The dataset of the proposed system consists of 132 Hadiths documents about pray and fasting subjects. These documents were selected from Al-bukhari reference of true Hadiths. Al-bukhari considered as one of most trusted references of Hadiths documents due to strong procedures that followed by writer to assure the truth of spoken Hadiths by prophet Mohammad. Prof. Dr. Ahamad Shaker Mahmmod validated the selected 132 Hadiths as proposed dataset as pray and fasting documents who work in Islamic college in Baghdad University, and he considered as expert in Hadiths due to his large experience years (more than 20 years) in the domain of sacred Hadiths. Table 1 illustrates the selected Hadiths numbers according to subject.
TABLE 1 PROPOSED DATASET Subject Number of Hadiths
Pray 82
Fasting 50
Total 132
Nabeel Neamah et al Question Answering System Using Similarity and Classification Techniques
TABLE 2 SUMMARY OF HADITHS CORPUS
Type of Question Pray Fasting
When 17 14
Where 11 0
Not related to when or where 54 36
Total 82 50
The proposed system test was conducted based on 12 queries that were selected based on proposed questions about pray and fasting subjects that provided by 15 students from UKM universities according to discussion of proposed system objectives. Table 3 presents the proposed queries according to question and subject classifications.
TABLE 3 DIRECTION OF TESTED QUIRES
Query Subject Question Type
Proposed Query Q1 Pray When When is the five time
of pray for Muslims? Q2 Pray Where Where was the first
Friday prayers? Q3 Fasting When When is the fasting
month of Muslims
Q4 Pray When When does the
Muslims can pray for eid?
Q5 Pray When When do you pray Maghrib?
Q6 Pray Where Where was the first qibla of Muslims? Q7 Fasting When When does fasting
begin?
Q8 Pray Where When can be Muslims taraweeh prayers?
Q9 Pray When When Should the
Traveler Shorten the Prayer?
Q10 Fasting When When does fasting end?
Q11 Pray When When does the
Muslim pray for God? Q12 Pray When When is time of al-fajr
prayer?
VI. EXPERIMENTAL DATA Test #1: Cosine Similarity
This test is conducted through using only the cosine similarity technique to measure the similarity between user query and answers documents. The accuracy results of proposed question answering system based on CS technique. The accuracy scores computed depend on the queries precision and recalls where recall = T/(T+(Hadith-T )), Precision= T/(T+(Hadith-T/(T/(T+(Hadith-T+(N.H-T/(T+(Hadith-T)) and F_Score= 2(recall * precision)/ (recall + precision). The most accurate F_score (0.74) is belonging to third query (When is the fasting
month of Muslims?) while the lowest F_score (0.55) is belong to 8th query (when can be Muslims Taraweeh prayers?). The accuracy results for the queries based on cosine similarity technique are; 0.71 for Q1, 0.70 for Q2, 0.74 for Q3, 0.62 for Q4, 0.73 for Q5, 0.61 for Q6, 0.56 for Q7, 0.55 for Q8, 0.60 for Q9, 0.72 for Q10, 0.71 for Q11, and 0.73 for Q12. The average of answers accuracy of all tested queries record 67%. Thus, the accuracy results of cosine similarity technique considered acceptable, but it could be enhanced supporting other methods to provide answers that are more accurate.
Test #2: Longest Common Subsequence
This test is conducted through using only the long common similarity technique to measure the similarity between user query and answers documents. The accuracy results of proposed question answering system based on LCS technique. The accuracy scores computed depend on the queries precision and recalls where recall = T/(T+(Hadith-T)), Precision= T/(T+(N.H-T)) and F_Score= 2(recall * precision)/ (recall + precision). The most accurate F_score (0.76) is belonging to 2nd query (where was the first Friday prayers?) while the lowest F_score (0.55) is belonging to 6th query (When where was the first Qibla of Muslims?), and 9th query (When Should the Traveler Shorten the Prayer?). The accuracy results for the queries based on long common similarity technique are; 0.67 for Q1, 0.76 for Q2, 0.69 for Q3, 0.57 for Q4, 0.67 for Q5, 0.55 for Q6, 0.72 for Q7, 0.71 for Q8, 0.55 for Q9, 0.72 for Q10, 0.75 for Q11, and 0.57 for Q12. The average of answers accuracy of all tested queries record 66%. It can be noticed that the average of accuracy results of CS and LCS are approximately same. Thus, these results could be enhanced supporting other methods to provide answers that are more accurate.
Test #3: Combination of CS and LCS
The combination between CS and LCS techniques was conducted through testing each proposed query using these two techniques and selects the better F-score of CS and LCS. For example, if F_score of first query using CS technique is higher than F_score of first query using LCS then the system will select F-Score of CS. The measurement of F-score and results selection was accomplished using proposed QA system. Thus, the combination results represent the best possible answers using similarities techniques. The accuracy results of proposed question answering system based on the combination of CS and LCS techniques. The most accurate F_score (0.76) is belonging to 2nd query (where
answers more than separate CS technique and LCS technique.
Test #4: Combination of CS , LCS, and SVM
This test is conducted based on two main steps; (1) classify the Hadiths documents using SVM method based on the questions types, and (2) measure the similarity through CS and LCS combination. SVM is used to classify Hadiths documents according to Hadiths subjects (Pray and Fasting), and proposed answers of questions types (Where and When). Then, the similarity between queries and documents was measured using the combination of CS and LCS techniques before calculate F-score of final extracted answers. Table 4 summarizes the accuracy results of proposed question answering system based on the combination of CS and LCS, in addition to classification based SVM. The accuracy scores computed depend on the queries precision and recalls where recall = T/(T+(Hadith-T )), Precision= T/(T+(N.H-T)) and F_Score= 2(recall * precision)/ (recall + precision). As noticed from Table 4, the average of F_score using combination of CS, LCS, and SVM was recorded 80%. The most accurate F_score (0.86) is belonging to 2nd query (where was the first friday prayers?) while the lowest F_score (0.73) is belonging to 8th and 12th queries.
TABLE 4 ACCURACY MEASUREMENTS BASED ON CS, LCS, AND SVM
F_ Sco re R ec all Pre cisi o n Output system Had ith Qu er y F T N.H 0.84 0.76 0.93 1 13 14 17 Q1 0.86 0.82 0.90 1 9 10 11 Q2 0.77 0.71 0.83 2 10 12 14 Q3 0.81 0.76 0.87 2 13 15 17 Q4 0.84 0.76 0.93 1 13 14 17 Q5 0.83 0.77 0.91 1 10 11 11 Q6 0.77 0.71 0.83 2 10 12 14 Q7 0.73 0.65 0.85 2 11 13 17 Q8 0.77 0.71 0.86 2 12 14 17 Q9 0.80 0.71 0.91 1 10 11 14 Q10 0.84 0.76 0.93 1 13 14 17 Q11 0.73 0.65 0.85 2 11 13 17 Q12 0.80 Av
VII. DISCUSSION ON THE FINDINGS
According to findings of experimental results, the combination of CS, LCS, and SVM techniques record the highest accurate records of answers (80%) followed by the combination of CS and LCS techniques (70%), then CS technique (67%), and finally LCS technique (66%). SVM technique is plays important role to improve the accuracy results of proposed question answering system. The average accuracy results of all queries was improved by 10% when apply SVM with other techniques. On the other hand, most individual results of queries record accurate answers based on SVM with other techniques. SVM reduce the searching space of Hadiths documents through classify the Hadiths depend on proposed question types and documents subjects. The reducing of searching space increases the opportunities of retrieving true answers that match with users queries. This finding can be justified clearly through compare the results of SVM of pray and fasting subjects. the pray subject can classified as when and where question types documents but the fasting subject can be classified as when question type documents. the results of pray queries based on SVM is more accurate than Fasting queries due to possibility of minimize the searching space of pray subject more than the fasting subject.
VIII. CONCLUSION
There are many methods were applied to analyze the query needs of answers and update the query to be more effective based on the formal concepts of Hadiths. Preprocessing methods such as normalization, tokenization, stop-word removal, and N-gram were applied to analyze the concepts of users’ quires. the WordNet tool was applied to replace the weak concepts of queries by effective Hadiths concepts or synonyms. SVM technique was applied to reduce the searching space of answers and improve the possibility of retrieving accurate answers. SVM classify Hadiths documents as four main cluster which are; Pray documents for when question type, pray documents for where question type, fasting documents for when question type, and fasting documents for where question type. The results of experimental tests show that the proposed methods are effective to improve the accuracy of question answering system for Hadith domain. Significantly, SVM technique reduces the searching space of answers which improve the accuracy of provided answers.
REFERENCES
[1] Xu-Dong Lin, Hong Peng, Bo Liu, “Support Vector Machines for Text Categorization in Chinese Question Classification,” College of Computer Science and Engineering, South China University of Technology, International Conference on Web Intelligence (WI 2006 Main Conference Proceedings), IEEE, 2006.
Nabeel Neamah et al Question Answering System Using Similarity and Classification Techniques
[3] Hakan Sundblad, Question Classification in Question Answering Systems, Thesis No. 1320 ISSN 0280-7971, Department of Computer and Information Science Linkopings University, Linkoping, 2007.
[4] Dell Zhang, Wee Sun Lee, Question Classification using Support Vector Machines, National University of Singapore, Singapore-MIT Alliance, Toronto, Canada, 28-August 1, 2003.
[5] Harb.A, Michel Beigbeder, Jean-Jacques, Evaluation of Question Classification Systems Using Differing Features, Institute of Electrical and Electronics Engineers, 2009.
[6] Tan.W, Jianrong Cao, Hongyan Li, “Algorithm of Shot Detection based on SVM with Modified Kernel Function,” Shan Dong Jianzhu University, Jinan 250101, China, International Conference on Artificial Intelligence and Computational Intelligence, IEEE, 2009.
[7] Gharehchopogh, Farhad Soleimanian, and Yaghoub Lotfi. "Machine Learning based Question Classification Methods in the Question Answering Systems."International Journal of Innovation and Applied Studies 4.2 (2013): 264-273.
[8] Srihari, R. & Li,W. (2000). Information extraction supported question answering, In Proceedings 8th Text Retrieval Conference (TREC-8), NIST Special Publication 500-246.
[9] Bhaskar.P, Pakray.P, Banerjee.S and Banerjee.S, 2012, “Question Answering System for QA4MRE”, Department of Computer Science and Engineering, Jadavpur University, Kolkata, 700032, India.
[10] Ullman, Jeffrey D., Jure Leskovec, and Anand Rajaraman. "Mining of Massive Datasets." (2011): 305-338.
[11] Brants, T., Franz, A. 2006." Web IT 5-gram Version 1". (www.ldc.) upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC2006T13). [12] Jian-fang, S., Zong-tian, L., & Jian-feng, F. 2010. Event-network
clustering using similarity. In Natural Computation (ICNC), 2010 Sixth International Conference on (Vol. 8, pp. 3970-3973). IEEE. [13] Madylova, A. & Oguducu, S. 2009. A Taxonomy Based
Semantic Similarity of Documents Using the Cosine Measure. Computer and Information Sciences, 2009. ISCIS 2009. 24th International Symposium on, hlm. 129-134.
[14] Day.M, Chorng-Shyong Ong, Question Classification in English-Chinese Cross-Language Question Answering: An Integrated Genetic Algorithm and Machine Learning Approach, Institute of Information Science, Academia Sinica, Taiwan, Department of Information Management, National Taiwan University, Taiwan, IEEE, 2007.
[15] Molina-González, M. D., Martínez-Cámara, E., Martín-Valdivia, M.-T., & Perea-Ortega, J. M. (2013). Semantic orientation for polarity classification in Spanish reviews. Expert Systems with Applications, 40(18), 7250-7257.
[16] Turney, P. D. (2002). Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews. Paper presented at the Proceedings of the 40th annual meeting on association for computational linguistics.
[17] Xu, T., Peng, Q., & Cheng, Y. (2012). Identifying the semantic orientation of terms using S-HAL for sentiment analysis. Knowledge-Based Systems, 35, 279-289.