IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY622
Adder Enhancement Techniques
Shaik Sameera Bannu
1, S.Priyanka
2 1M.Tech. PG Scholar, Gouthami Institute of Technology & Management for Women, Proddatur
2
Assistant Professor, Gouthami Institute of Technology & Management for Women, Proddatur
Abstract- Adders are the basic building blocks of many computational circuits. As a result, it is imperative to design fast adders and simultaneously optimize the power in these adders to the maximum extent possible. Carry S elect Adder (CS A) is the most frequently used adder which works on the principle of pre computation of the sum and carry for each individual stage by assuming the carry in as ‘0’ and ‘1’. CSA employs additional Ripple Carry Adders (RCA) which induces an undesired increase in area as well as the delay as the carry is propagated through all stages. Thus the overall area and power consumption for CS A is also on the higher side. Hence, it is inevitable to opt for techniques to reduce the power consumption to achieve higher performance which is the eventual desired goal. This work involves Register Transfer Level design of 32-bit CS A with power and delay optimization techniques. The obtained results for the power consumed for each technique are hence analyzed and compared to obtain the best design which can be further implemented.
I. INTRODUCTION
Digital computer arithmetic is an aspect of logic design with the objective of developing appropriate algorithms in order to achieve an efficient utilization of the available hardware. The essential operations are expansion, subtraction, augmentation and division. In this, we will manage the operation of increases executed to the operation of duplication. The rehashed type of the expansion operations and moving outcomes in the augmentation operations given that the equipment can just play out a moderately straightforward and primitive arrangement of Boolean operations, number-crunching operations depend on a pecking order of operations that are based upon the basic ones. In VLSI plans, speed, power and chip territory are the frequently utilized measures for deciding the execution and effectiveness of the VLSI design. Duplications and increases are most generally and all the more frequently utilized number-crunching
calculations performed in all computerized flag preparing applications. Expansion is a major operation for any computerized duplication. A quick, region proficient and exact operation of an advanced framework is extraordinarily affected by the execution of the inhabitant adders. Adders are additionally critical segment in advanced frameworks on account of their broad use in these frameworks. A coordinated circuit or solid incorporated circuit (additionally alluded to as IC, chip, or miniaturized scale chip) is an electronic circuit produced by the designed dispersion of follow components into the surface of thin substrate of semiconductor material. Extra materials are saved and designed to shape interconnections between semiconductor gadgets. Incorporated circuits are utilized as a part of practically all electronic gear today and have upset the universe of gadgets. PCs, mobiles telephones, and other computerized machines are presently inseparable parts of the structure of current social orders, made conceivable by the minimal effort of generation of incorporated circuits.
ICs were made conceivable by trial revelations demonstrating that semiconductor gadgets could play out the elements of vacuum tubes and by mid -twentieth century innovation progressions in semiconductor gadget manufacture, the incorporation of huge quantities of little transistors into a little chip was a gigantic change over the manual get together of circuits utilizing discrete electronic parts. The coordinated circuit large scale manufacturing capacity, unwavering quality, and building -square way to deal with circuit configuration guaranteed the quick appropriation of institutionalized ICs set up of plans utilizing discrete transistors.
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY623
transistor immediately. Moreover, substantially less materials used to build a bundled IC kick the bucket than to develop a discrete circuit. Execution is high on the grounds that the parts switch rapidly and devour little power (contrasted with their discrete counter cards) because of the little size and nearness of the segments.
The vast majority of the understudies of Electronics Engineering are presented to Integrated Circuits (IC's) at an exceptionally fundamental level, including SSI (little scale reconciliation) circuits like rationale doors or MSI (medium scale coordination) circuits like multiplexers, equality encoders and so forth.In any cas e, there is a ton greater world out there including scaling down at levels so extraordinary, that a micrometer and a microsecond are truly viewed as enormous! This is the universe of VLSI - Very Large Scale Integration. The article goes for attempting to acquaint Electronics Engineering understudies with the potential outcomes and the work engaged with this field.
VLSI remains for "Very Large Scale Integration". This is the field which includes pressing increasingly rationale gadgets into littler and littler territories. Because of VLSI, circuits that would have consumed boardfuls of room would now be able to be put into a little space couple of millimeters over! This has opened up a major chance to do things that were unrealistic some time recently. VLSI circuits are wherever ... your PC, your auto, your fresh out of the box new best in class advanced camera, the phones, and what have you. This includes a considerable measure of ability on many fronts inside a similar field, which we will take a gander at in later areas. VLSI has been around for quite a while, there is nothing surprising about it ... in any case, as a symptom of advances in the realm of PCs, there has been an emotional multiplication of instruments that can be utilized to outline VLSI circuits. Close by, complying with Moore's law, the ability of an IC has expanded exponentially finished the years, as far as calculation control, use of accessible region, yield. The consolidated impact of these two advances is that individuals would now be able to put assorted usefulness into the IC's, opening up new boondocks. Cases are inserted frameworks, where insightful gadgets are put inside ordinary items, and omnipresent processing where little registering gadgets multiply to such a degree, to the poin t that
even the shoes you wear may really accomplish something valuable like checking your heartbeats! These two fields are benevolent a related and getting into their portrayal can without much of a stretch prompt another article.
II. LITERATURE SURVEY
Seji Kahihara and Tsutomu Sasao, “On the adders with minimum tests”, IEEE Proceedings of the 5th Asian Test Symposium 1997.
This paper considers two kinds of n-bit adders, ripple deliver adders and cascaded bring appearance- exams in advance adders, with minimum for caught-at fault fashions. In the first part, we present two styles of complete adders consisting of five gates, and display their minimality. We additionally prove that one of the fill adders can be tested through only 3 test styles for single stuck-at faults. We additionally gift two styles of four-bit carry look-ahead adders and their minimal checks. In the second one part, we recall the tests for the cascaded adders, an n-bit ripple convey adder and a 4m-bit cascaded convey look in advance adders. These exams are extensively smaller than formerly published ones.
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY624
design range is defined from which a modeler can pick a viper with the coveted qualities.
Jucemar Monteiro, José Luís Güntzel Luciano Agostini, “A1CSA: Energy-Efficient Fast Adder design for Cell-Based VLSI Design” Electronics, Circuits And Systems. Energy-green fast adders are wanted within the layout of battery-powered portable gadgets. Although many speedy adder architectures exist, maximum of them require transistor-level optimizations that prevent their synthesis in a standard-mobile waft. This paper presents energy-efficient Add-One Carry-Select Adders (A1CSA and A1CSAH) desirable for fashionable-cells synthesis. Synthesis consequences demonstrated that the A1CSA is the littlest rapid viper requiring, by and large, 22.2% less area than the Carry-Select Adder. They also demonstrated that the A1CSAH is, on normal, 10.Eight% faster and three.Four% additional vitality productive than the Carry-Lookahead Adder, as a result comparing to the decent inclination for intemperate speed and high performance addition. James Levy and Jabulani Nyathi, “A High Performance, Low Area Overhead Carry Look-ahead Adder.
Adders are some of the maximum important records path circuits requiring massive design effort with a purpose to “squeeze” out as an awful lot performance advantage as feasible. Many adder designs control excessive overall performance via reducing the put off of the essential route, an effort that outcomes in high place overhead in most instances. In this paper we present a carry lookahead adder (CLA) with a prediction scheme that consequences in stepped forward performance and coffee location overhead. Carry prediction permits for the discount of the carry circuitry inside a block whilst reducing the postpone worried inside the era of the bring-out to the subsequent blocks. We have finished simulations of a 16-bit adder and recorded overall performance enhancements of 67% in propagating the deliver and producing the sum whilst in comparison with the conventional (fixed group- 4) CLA designed inside the equal generation D.C.Chen, L.M.Guerra, E. H.Ng, M. Potkonjak, D. P.Schultz and J. M. Rabaey, “An integrated device for fast prototyping of excessive overall performance algorithm Specific statistics paths,” in Proc. Application Specific Array Processors,Aug 1992, pp. 134-148.
A framework has been created which focus es on the rapid prototyping of unreasonable execution insights calculation units that are common to constant advanced flag preparing applications. The equipment stage of the contraption is a possess group of multiprocessor incorporated circuits. The prototype chip of this family consists of eight processors connected thru a dynamically managed crossbar transfer. With a most clock charge of 25 MHz, ii can help a computation fee of 200 MIPS and might maintain a facts I/O bandwidth of four hundred MByte/sec. An assembler and simulator provide low-degree programmability of the hardware. A compiler which takes enter defined in the high-level facts go with the flow language Silage, and plays estimation, adjustments, partitioning, mission, and scheduling earlier than producing assembly code, presents an automatic software program compilation M.D. Ercegovac and T. Lang, “Digital Arithmetic.” San Francisco: Morgan Daufmann.
Digital arithmetic performs an crucial role inside the layout of trendy-purpose digital processors and of embedded systems for signal processing, pics, and communications. Regardless of a develop group of records in virtual science, each new age of processors or virtual frameworks makes new number juggling format inconveniences. Planners, analysts, and graduate understudies will discover solid responses to those issues in this complete, modern day exposition of virtual arithmetic.Ercegovac and Lang, of the field's main specialists, supply a unified treatment of digital mathematics, tying underlying theory to layout exercise in a generation-unbiased way. They consistently use an algorithmic approach in defining mathematics operations, illustrate ideas with examples of designs at the common sense degree, and discuss fee/performance traits throughout. Students and working towards designers alike will find Digital Arithmetic a definitive reference and a steady teaching device for developing a deep knowledge... T. Y. Ceiang and M. J. Hsiao, “Carry-select adder using single ripple Carry adder,” Electron. Letts, vol. 34, no. 22, pp. 2101–2103, Oct. 1998
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY625
CSLA structure has advanced using Binary to Excess-1 converter (BEC). This paper proposes an green approach which replaces the BEC the use of D latch. Experimental analysis indicates that the proposed structure achieves the 3 folded advantages in phrases of location, delay and energy.
May PhyoThwal, KhinHtay Kyi, and Swar Soe,” Implementation of Adder-subtracterDesign with Verilog HDL” World Academy of Science, Engineering and generation.
According to the density of the chips, designers are looking to positioned so any facilities of computational and storage on unmarried chips. Along with the complexity of computational and storage circuits, the designing, trying out and debugging grow to be an increasing number of complicated and luxurious. So, hardware layout might be built by way of the usage of very excessive velocity hardware description language, that's greater efficient and cost powerful. This paper will focus on the implementation of 32-bit ALU layout based totally on Verilog hardware description language. Adder and subtracter function efficaciously on both unsigned and superb numbers. In ALU, addition takes most of the time if it makes use of the ripple-convey adder. The general method for designing rapid adders is to reduce the time required to shape bring alerts. Adders that use this principle are known as bring look- in advance adder. The bring appearance-ahead adder is to be designed with combination of 4-bit adders. The syntax of Verilog HDL is just like the C programming language. This paper proposes a unified approach to ALU layout in which each simulation and formal verification can co-exist.
III. ADDER ENHANCEM ENT TECHNIQUES
The RCA has a finite postpone in obtaining the end result, due to the fact the convey needs to be transmitted from one degree to some other level. Hence, to increase the speed of the adder, faster bring generation techniques must be used.
These Techniques improves the s peed of the adder, but however it increases the region. Some of the techniques are:
• Carry Skip Adder • Carry Select Adder • Carry Look-ahead adder
A Carry Skip Adder (otherwise called a bring -sidestep adder) is a adder execution that enhances the put off of a swell convey adder with little exertion in contrast with different adders. The improvement of the worst-case put off is executed with the aid of the usage of several bring-skip adders to form a block-deliver-skip adder.
The worst case for a simple one stage carry-ripple-adder happens, whilst the propagate-condition is real for every digit pair (Ai, Bi). Then the deliver-in ripples through the n-bit adder and appears as the deliver-out after.
TCRA (n) ≈n*TVA
Figure 3.1: 16-Bit Carry Skip Adder
The carry skip adder uses some setup to block the carry propagation. In a setup if the bits of the operands A, B are different in all the positions with respect to each other, then the carry need not be generated. A special setup is defined as block propagation of carry BP = pi
If BP =1 then Cin need not be propagated through the adder block. Instead it can be directly transmitted through a MUX to the next block. However if BPi =0 then the cin needs to be propagated through the adder block.
Give K1 a chance to be the time required by the help flag to engender through the viper circuit and K2 be the proliferation deferral of the MUX. At that point the calculation time is given by
T=2(P-1) K1+ (M-2) K2
Where P= Number of adder elements in each block M= Number of blocks
N= Number of bits
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY626
The Carry Select Adder typically includes ripple deliver adders and a multiplexer. Adding two n -bit numbers with a carry-pick out adder is finished with two adders (therefore ripple bring adders) in an effort to carry out the calculation twice, one time with the belief of the deliver-in being zero and the other assuming it'll be one. After the two effects are calculated, the perfect sum, in addition to the appropriate bring-out, is then selected with the multiplexer as soon as the proper bring-in is understood.
The variety of bits in each carry select block can be uniform, or variable. In the uniform case, the surest put off happens for a block size of √n. Whenever variable, the square size need a deferral, from expansion inputs An and B to the do, indistinguishable to that of the multiplexer chain fundamental into it, all together that the perform is computed no ifs ands or buts in time. The deferral is gotten from uniform measuring, wherein the best number of finish snake factors as per piece is same to the rectangular foundation of the scope of bits being included, considering that with an end goal to yield a same amount of MUX delays.
Figure 3.3: 16-bit Carry Select Adder A sixteen-bit Carry Select Adder with a uniform block size of 4 may be created with 3 of these blocks and a four-bit ripple carry adder. Since convey-in is known at the beginning of computation, a bring choose block isn't always wanted for the primary four bits. The put off of this adder might be 4 complete adder delays, plus 3 MUX delays.
When the overall-adder postpone is identical to the MUX postpone, which is not going. The total delay is two full adder delays, and four MUX delays. We try
to make the delay thru the 2 deliver chains and the delay of the previous stage bring identical.
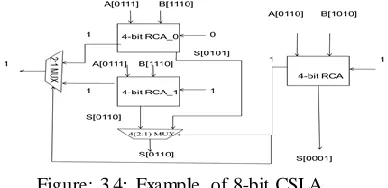
Considering an Example of 8-bit CSLA by using binary bits.
Figure: 3.4: Example of 8-bit CSLA
A Carry Look-beforehand Adder (CLA) or speedy adder is a kind of adder utilized as a part of computerized precise judgment. A supply-appearance Ahead adder enhances speed through method for diminishing the measure of time required to choose bring bits. It might be appeared differently in relation to the less perplexing, however ordinarily slower, swell pass on adder for which the pass on bit is computed nearby the whole piece, and each piece need to hold up till the past convey has been figured to start ascertaining its own end final product and bring bits (see adder for component on swell pass on adders). The convey look Ahead adder figures one or more prominent bring bits before the aggregate, which diminishes the hold up time to ascertain the surrender final product of the bigger charge bits. The under figure suggests the primary constructing block of CLA for four-bit with technology & propagation functions.
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY627
the possibility of getting to feature an additional 1, from a convey that has are available from the subsequent position to the right.
This method that no digit role will have an definitely final cost until it's been mounted regardless of whether a convey is rolling in from the correct. In addition, if the total without a convey is 9 (in pencil-and-paper methodologies) or 1 (in double science), it isn't even feasible to advise regardless of whether or no longer a given digit position goes to pass on a convey to the situation to its left side. Even under the least favorable conditions, when an entire arrangement of totals comes to ...99999999... (In decimal) or ...11111111... (in parallel), nothing might be found at all until the point when the expense of the convey rolling in from the correct is comprehended, and that pass on is at that point engendered to one side, with extra special care, as every digit position assessed "9+1=0, bring 1" or "1+1=zero, pass on 1". It is the "undulating" of the convey from appropriate to left that gives a swell convey snake its name, and its gradualness. While including 32-bit whole numbers, for instance, recompense wants to be made for the open door that a pass on might need to need to swell by means of every last one of the 32 one-piece adders.
Convey look prior relies upon subjects:
1. Calculating, for each digit position, regardless of whether that position will proliferate a convey in the event that one roll in from the best possible.
2. Combining these ascertained esteems that enables you to conclude speedy whether, for every association of digits, that foundation will proliferate a convey that is accessible in from the correct.
Assuming that association of four digits are Chosen. At that point the succession of exercises is going something like this:
1. All 1-bit adders ascertain their belongings. At the same time, the appearance ahead contraptions play out their estimations.
2. Suppose that a convey emerges in a specific association. Inside at most 5 door postpones that convey will develop at the left-hand surrender of the foundation and start spreading through the gathering to one side.
3. If that convey goes to propagate all of the way via the next organization, the look in advance unit will have already got deduced this. Accordingly, earlier than the deliver emerges from the subsequent
organization, the appearance beforehand unit is immediately (inside one gate postpone) able to tell the next group to the left that it's miles going to get hold of a deliver and, at the equal time, to inform the subsequent appearance in advance unit to the left that a bring is on its manner.
For very massive numbers (hundreds or even lots of bits), look beforehand deliver logic does not become any greater complex, due to the fact more layers of terrific businesses and brilliant businesses can be brought as important. The growth inside the quantity of gates is also slight: if all the group sizes are four, one could end up with one 0.33 as many appearance ahead bring devices as there are adders. However, the "slow roads" on the way to the quicker stages begin to impose a drag at the complete gadget (for instance, a 256-bit adder may want to have as much as 24 gate delays in its carry processing), and the mere bodily transmission of indicators from one give up of a long variety to the opposite begins to be a trouble. At these sizes, convey-keep adders are optimum, due to the fact they spend no time on deliver propagation in any respect.
The following is the sixteen-bit CLA Block by using Propagate & generate capabilities, P & G respectively.
Figure:3.6:16-bit Carry Look-ahead Adder
IV. RESULTS
32-bit RCA
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY628
32-bit CSKA
Figure: 4.2: Simulation result of 32-bit CSKA with Cin=0 & 1
32-bit CSLA
Figure. 4.3: Simulation result of 32-bit CSLA With Cin=0 & 1
32-bit CLA
Figure 4.4: Simulation result of 32-bit CLA With Cin=0 & 1
VI. CONCLUSION
A design and implementation of Verilog HDL based 32-bit addition with different adders was presented. Verilog HDL, a Verified Logic Hardware Description Language, was used to model and simulate. In future, this particular work can be extended from 32-bit to 64-bit. It is a skillful challenge for us to perform addition by using the proposed system .i.e., COMBINATION OF CSA & CSLA.
REFERENCE
[1] P.Prashanti and B.Rajendra Naik, “Design and Implementation of High Speed Carry Select Adder”, International Journal of Engineering Trends and Technology (IJETT), Vol. 4, Issue 9, pp. 3985-3990, Sept. 2013.
[2] N. Banerjee, A. Raychowdhury, K. Roy, S. Bhunia, and H. Mahmoodi “Novel Low-Overhead Operand Isolation Techniques for Low-Power Datapath Synthesis”, IEEE transactions on very large scale integration (VLSI) systems, Vol. 14, No. 9, Sept. 2006. [3] L. Benini, P. Siegel, and G. De Micheli,
“Automatic Synthesis of Gated Clocks for Power Reduction in Sequential Circuits,” IEEE Design Test Computer Magazine, Vol. 11, No. 4, pp. 32–40, 1994.
[4] M. Alidina, J. Monteiro, S. Devadas, A. Ghosh, and M. Papaefthymiou, “Precomputation based Sequential Logic Optimization for Low Power,” IEEE Trans. VLSI Systems, Vol. 2, No. 4, pp. 426–436, 1994.
[5] Yunlong Zhang, et. al., “Automatic Register Transfer level CAD tool Design for Advanced Clock Gating and Low Power Schemes” International SoC Design Conference (ISOCC), pp. 21-24, 2012.
[6] Anantha P. Chandrakasan, Robert W. Brodersen, “Minimizing Power Consumption in Digital CMOS Circuits”, proceedings of the IEEE, Vol. 83, No. 4, April 1995.
IJIRT 145199
INTERNATIONAL JO URNAL OF INNOVATIVE RESEARCH IN TECHNOLOGY629
[8] Y. He, C. H. Chang, and J. Gu, “An Area Efficient 64-bit square root Carry-Select Adder for Low Power Applications,” in Proc. IEEE Int. Symp. Circuits Syst., Vol. 4, pp. 4082-4085, 2005.
[9] E. Abu-Shama and M. Bayoumi, “A New cell for Low Power Adders,” in Proc. Int. Midwest Symp. Circuits and Systems, pp. 1014–1017, 1995.