Research on the Website Keywords Seeding
System Based on SEO
LI Zhongjun
School of Economic Information Engineering,
Southwestern University of Finance and Economics, Chengdu, China Email: [email protected]
Abstract—Website Information Island leads to information partition between sites and customers, and holds back the improvement of website popularity. To solve this problem, the paper proposes website keywords seeding system based on internal and external SEO, and provides data structure, operation process and key algorithm inside model; According to external customers' high-frequency search terms and internal customers' demand, this model uses multi-dimensional vector overlay space to match and extract information required by customers, has internal website optimized automatically and issues keywords. Theoretical analysis and experimental results both show that, the model has a high feedback speed for demand, which can improve sites' customer satisfaction and search rankings effectively.
Index Terms—website, SEO, match, retrieval, overlay space, information
I. INTRODUCTION
Information Island (Automation Island, Resource Island) is that data units are stored separately and can’t share and exchange information automatically, which need to contact with outside world artificially[1]. Fundamentally speaking, Information Island is created by the extensive use of computer technology and different software products; For example, the current widely used website system mainly uses websites as information carriers, and its massive information is often stored in the database servers or file servers[2,3]; In order to use these information, customers usually make use of search engines to find relevant websites, then acquire relevant content through different ways such as manual search. Not only is it inconvenient to use, but also the limitation of website internal search results in lots of information shielded outside the customer perspective is wasted.
Generally, in order to achieve the purpose of resource sharing and collaboration , the fundamental approach to eliminate Information Island is to plan resources unitedly and develop integrated intelligent information processing platform. However, it’s difficult to realize this solution because of intellectual property of information resources, related technical standards and so on [4,5,6]. Therefore,
people use SEO in the process of the current site optimization and information promotion, publish key information, improve popularity of site and attract customers [7,8,9]. Among them, based on features of search engines with respect to web pages, SEO makes various basic properties in constructing website satisfy principles of search engines. Accordingly, the engines can search and collect as many websites as possible; Meanwhile, the obtained website can be ranked in a favorite position in the search result. The purpose of popularizing a website can be achieved. Thus, such an optimizing is applied widespread [10,11,12].
In response to these problems, based on SEO, the paper proposes the website keywords seeding system model on the strength of internal SEO. This article is structured as follows: First of all, it analyses network Information Island and proposes the crack program; Secondly, it provides architecture model, data structure, key algorithm and the running process of website keywords seeding system; Thirdly, it gives model’s performance analysis and compares it with other models; at last of the full text, it comes up with the technology foresight and future work
II. PROBLEMANALYSISANDSOLUTION
Website Information Island brings about many problems, the website keywords seeding model plans to use following approaches to solve them:
One important reason of Website Information Island formed is that: In terms of search engine, webpage’s quality degree is so low that search engine’s spider system programs “look down upon” that page: The search engine either includes pages to the bottom of index database, or gives up the pages included. This kind of situation is mostly due to webpage producers basically have no concept of search engine indexed, and just complete pages routinely but not make good adjustments for pages according to search engines. For example, in accordance with the rules of search engines, WebPages producers should have optimization on the pages title, keywords attributes and descriptions attributes of page Meta tags, rationalization layout of page Key Words and so on. If not, this page will be inconsiderable in the search engine's "eyes". To these Basic issues of web design, website keywords seeding model recommends
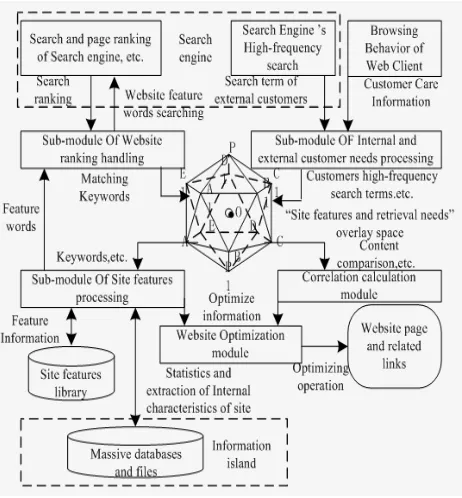
Figure 1. Infrastructure and processes of Internet keywords seeding system.
page creator must do good foundation for web design work honestly and seriously. Page creator should make search engine recognize that the page is useful for customer and worth to recruit for search engine from the point of SEO.
The other important reason of Website Information Island formed is that: There is a serious imbalance between the amount of information in websites and that contained in the databases; and search engine uses spider system program to collect all of the pages accessed in website automatically. The principle of technical search engine is that search engine’s spiders system program collects all pages crawled and extracts keywords into index database to prepare for customer retrieval; Therefore, it is difficult to obtain critical information inside island effectively and automatically for search engines, especially for a large number of information stored in the website database. In response to this problem, the website keywords seeding model must increase the "concentration" that features pheromone in the representative pages and raise the website's "representation ratio" so that the limited representative web pages can show site information as much as possible.
Another important reason of Website Information Island formed is that the references between WebPages and WebPages, especially the references between WebPages and non WebPages (such as PDF, WORD, Excel, PowerPoint, Video and so on) is so low that information resources in the same Web site is short of link reference sufficiently to each other. Although search engine applies indexing system program to analyze and extract key words for gathering web pages, and establishes web index databases for the related information according to the relevance (or importance) of key words in the web pages and hyperlinks , it is hard to achieve correlative information management within Information Island. Therefore, the website keywords seeding model should improve the correlation between web pages and non-pages information (such as the establishment of public keywords, the reference of similar contents, etc.) to achieve high visibility of non-web information.
The formation of Website Information Island is also closely related to the invisibility of website’s internal information. Familiarly, search engines find all relevant records of network resources in line with the keyword or phrase; Page Rank is according to relevance, the higher the correlation is , the better front page ranking is; At last, search engine’s page generation system returns the title of network resources, description(summary), link address and so on to clients. Website’s important information is usually sealed in site’s database. Customers are often allowed to search via various combinations of search criteria in site’s internal database, but they can’t access the site and have internal search due to the loss of relevant information and low page ranking. Above all, website optimization model will meet customer demand and improve pages’ rankings in search engine on the basis of customer search preferences, external search
rankings for the keyword "concentration", topic information display and so on.
III. WEBSITEOPTIMIZATIONMODEL
A. Theme and Model structure
Raised for the above problems, the theme of the website optimization model are matching internal and external information and ordering pages on demand.
Internally, the model will obtain keywords collection representing site’s theme and existing customers’ search terms set through statistics and analysis, build website feature space in accordance with search frequency of keywords.
Externally, the model will retrieve site’s feature words in the major search engine automatically and extract search ranking and other comprehensive information to determine site’s impact and popularity. Moreover, the model can define customers’ external demand based on the similar frequency key words in the search engine.
As a consequence of the above, the model will create a "site feature and search needs" match space; the space overlay keywords vector representing site feature and customer demand; with the addition of keywords / search terms, the space will produce clustering necessarily; By means of matching and retrieval space vector, the model can extract high-attention site feature, complete SEO and finally achieve the goal to optimize website advertising.
This website optimization model includes the following sub-modules; they’re shown in Figure 1:
keywords into search field of search engines regularly and automatically(Baidu, Google, Yahoo, MSN, etc.), as the basic information of website adaptive optimization. After results to be generated, the search results downloaded (the continuous Top10 search pages) will be used to analyze the ranking and influence of website outside the cyber world. Finally, it puts website’s advanced feature words into the "site features and retrieval needs" overlay space. Besides, the keywords which are similar to website feature words(For example, Baidu's "Search" and Google's "similar results") will be updated and saved in the website optimization databases.
(2) Sub-module OF Internal and external customer needs processing: The sub-module collects, analyzes and classifies customer demand from the website's own search tools and external search engines, then put two types of customer needs into the "site features and retrieval needs" overlay space: firstly, it gets customer’s search terms which are popular currently and relational to website feature words; secondly, it interviews this site’s feature words. Thirdly, it puts high frequency feature words obtained after analyzing into "site features and retrieval needs" overlay space to reserve.
(3) Sub-module Of Site features processing: This module is primarily responsible to adjust the concentration of feature words in web pages (search engine’s crawl target) internally, and puts feature words analyzed and extracted in the website databases and file systems into "site features and retrieval needs" overlay space in order to use during site advertising externally. In addition, this module still provides the corresponding site features words for sub-module of website ranking handling as the functional basis in search engine ranking. Website optimization model has website optimized by rectifying the frequency of feature words or keywords; therefore, Key words’ frequency judgment plays an important role in SEO. According to SEO Theory, high (false propaganda) or low search engines that can not crawl will have an adverse effect on the site ranking, while 1% to 7% keyword density is right; During network keywords seeding, this sub-module abstracts keywords samples that needed by external customer and has high search ranking in "site features and retrieval needs" overlay space, and matches with relational site feature vector to make sure of the website keywords needed to promote, finally, it handles website optimization topic information to sub-module of website optimization to deal with. It takes optimized operation such as regulating related keywords and links and accomplishing keywords density adjustment. Correlation calculation module: It computes popular keywords(or links) in external search engines and internal websites and correlation with corresponding elements within this site, so that in the actual process it can judge the relevance and provide the basis for website keywords seeding system at last.
(4) Sub-module Of “Site features and retrieval needs” overlay space management: This module searches and finds website feature vector for website keywords seeding system by calculating internal / external customer needs’ high-frequency keywords (and links), search engine’s
high ranking search terms, and the correlation with the corresponding features words in websites. Meanwhile, it analyzes and calculates the correlation between external web pages /links and site features elements (content, links, etc.) to provide reference for website keywords seeding.
(5) Sub-module Of website keywords seeding: According to information provided by the first three modules, this module has some jobs like site keyword density adjustment, similar keywords replacement, relational links publication and so on.
B. Running process
This system’s workflow is divided into four steps: (1) Statistics and analysis of site's features: Sub-module of site features processing extracts the highest frequency, the latest keywords automatically from site’s public databases and file systems as search terms of sub-module of website ranking handling and demand information of website keywords seeding system; At the same time, it changes relevant information (key words, word frequency, address links, etc.) into website feature vectors and puts them into the "site features and retrieval needs" match space.
(2) Collection and analysis of external customer requirements: The system achieves high-frequency characteristics related to site features and high-ranking website information through sub-module of website ranking handling; Then, it obtains major search engines’ high-frequency words and analyzes them to know customers’ demand through sub-module of customer needs processing; Finally, it puts all information such as high-frequency keywords as customer’s external demand into "site features and retrieval needs" match space; Simultaneously, the similar or related words of site will be updated and stored in databases of website keywords seeding system as backup vocabulary.
(3) Collection and analysis of internal customer demand: This system records and gets the browsing tendency, the concern time to single page , common search words , web message and the expressed needs of online communication of customers accessing site directly by sub-module of internal customer needs processing, and they will be put into "site features and retrieval needs" match space as internal information needs.
(4) Matching and extracting of keywords seeding needs: Sub-module of “Site features and retrieval needs” overlay space management extracts identical or similar keywords and links according to website features and handles keywords seeding needs to sub-module of website keywords seeding to deal with by calculating to get the correlation between these elements and sites’.
Figure 2. Overlay space and Input-output information
search engine; the proactive approach has an active promotion by recommending information, for example, we can update website features in the ad column regularly.
C. Key Technologies
Website activity is usually dynamic, and its information content and customer demand are also changing. Thus, the search engine rankings collection, customer needs information gathering and site features statistics in the website keywords seeding model are all dynamics. Therefore, the suitable matching and retrieval operation should be provided to get high-speed and precise optimization objectives (key words, etc.).
To meet these needs, the system uses the "site features and retrieval needs" to match and search; the model structure and input/output contents are shown in Figure 2:
The system uses FCM (fuzzy clustering method based on the target) to provide stack space’s clustering and matching operation:
The paper supposes elements in the website features set have m attributes, that is, vector xi=(xi1,xi2,…,xim)
,X should be divided into c (2≤c≤n),then this site has c cluster centers V=(v1,v2,…,vc).
⎭
⎬
⎫
⎩
⎨
⎧
∈
∈
=
∈
∑
∑
− =X
x
R
a
a
x
a
v
v
v
i in i i n i i i
i
(
)
,
,
1 1 2 / 1 1 2
]
)
(
[
∑
=−
=
−
=
m j ij kjik
vk
vi
x
x
d
is the Euclidean distance for sample center and cluster center, then the goal is the classification of ideal sites’ related information.
∑
∑
==
=
ni ik ik n k
d
u
V
U
J
1 21
)
(
)
,
(
,function is theminimum value U. And u is the membership of sample x to distance center. To make different data with different dimensions in practical problems can be compared; data usually has two kinds of transformation as follows, and it is compressed to [0, 1]. Standard deviation is changed:
k k ik ik
s
x
x
x
*=
−
. 2 1
)
(
1
∑
=−
=
n i k ikk
x
x
n
s
,∑
==
n i ik kx
n
x
11
.Thus, it can standardize all input vectors (site characteristics and retrieval requirements, etc.), and put them into the same overlay space to choose. To improve matching and retrieval speed, the system uses vector cosine method as vector measure and selection algorithm, establishes fuzzy similar matrix according to the similarity rij of xi and xj, and establish corresponding algorithm of similarity coefficient:
∑
∑
∑
= = =−
=
m k jk m k ik m k jk ik ijx
x
x
x
r
1 2 1 2 1*
)
(
To fuzzy similar matrix in FCM, there is a smallest natural number k≤n make all natural numbers q >k have Rq=Rk ;that is, it can construct an equivalent matrix through the transitive closure of similarity matrix R to R and it will be skillful after finite computations; With this matrix structure, it can classify vectors based on website features in overlay space, get similarity evaluation results on output information, and apply them into site keywords seeding system.
The content above only focuses on single vector’s matching and retrieval; however, Network Information System usually takes various factors into account to achieve system optimization. The Bayesian network used by this system is a special kind of causal reasoning network, as is a directed acyclic graph consisted of nodes and directed lines, each node represents a random variable, the probability distribution shows that the probability of each state in variable states set, every directed line is on behalf of the dependency between two nodes, which is described quantitatively by conditional probability matrix associated with the connection.
The reasoning model based on Bayesian network is shown in Figure 3. Inference network nodes are divided into two categories: hypothesis (Hypothesis) nodes (H nodes) and event (Event) nodes (E nodes). Imaginary nodes indicate customers’ subjective views and demands for information; Event nodes express the objective facts occurred within certain space, they stand for databases and page data in this system. Events can be divided into two categories, one is directly observed, as event cues or events sign, like numerical data in the table, picture information and so on; The other is not directly observable, such as the relationship between the data, etc.
Links between nodes show the causality between scenarios, scenarios and events, as well as between events, it describes the relationship between them with
Figure 3. The reasoning model based on Bayesian
link X → Y, we can define the conditional probability matrix:
( ) (
y
x
p
Y
y
X
x
)
p
M
∆ ∆
x
y
=
=
=
=
The
p
( )
y
x
in matrix shows that:IF
p
(
X
=
x
)
=
p
x THENp
(
Y
=
y
)
=
p
y.The reasoning model uses the network to describe the relationship between events and customer’s scenario, and it describes the relationship between nodes with conditional probability matrix. According to the model, we can deduce and get the hypothetical status from the observed events. In reasoning process, state probability that all nodes are obtained using Bayesian integrated prior probability and conditional probability, model can save the updated results of nodes. Clearly, the hypothetical final state is not only about the latest incident information, but also has some connection with cumulative events before. Therefore, the reasoning model based on Bayesian network has cumulative function of time on information; this memory function cannot be realized by the traditional reasoning mechanism on account of production rules.
Reasoning model is built according to the prior information, when the state probability distribution of the leaf nodes cannot change, the network will maintain a balance; once the state of leaf nodes alters under observation information, the nodes of entire network will update their state probability distribution according to algorithm Peal[1]
The paper adopts Tree Bayesian network as a reasoning model whose structural features are that each node has one parent node at most. Considering a typical tree Bayesian network, node X has m child node
m 2
1
,
Y
,
,
Y
Y
…
and one parent node U, structures andalgorithm variables are defined as follows: Bel: State probability distribution of node.
λ: Diagnostic information obtained from child nodes.
π: Causal information obtained from parent nodes. Algorithm centers on single nodes, gets λ from child nodes and obtains π from parent nodes, then calculate the node’s Bel, λ and π, and triggers adjacent nodes to update, repeat cycling, when all nodes’ posterior probability equals prior probability, the network reaches a
new equilibrium. The specific calculation is divided into the following three steps.
The first step: updating their confidence.
( )
x
αλ
( ) ( )
x
π
x
Bel
=
( )
=
∏
( )
jj
x
Y
x
λ
( ) ( )
x
π
u
M
Xuπ
=
×
The second step: updating bottom-up.
( ) ( )
XU Xu
λ
x
M
λ
=
×
The third step: updating top-down.
( )
( )
∏
( )
≠
=
j k
y Yj
x
απ
x
λ
kx
π
Bayesian network updating is triggered by the event, so Bayesian network is a reasoning process based on diagnostic, which has the same way of thinking with customers situation assessment, from the perspective of cognitive, the reasoning result of Bayesian network has high credibility.
IV. EXPERIMENTALRESULTSANDANALYSIS
The application effect of system had been confirmed in the online website forum, the test data and that did not use this system before were compared at the same period.
Experimental design and results are as follows:
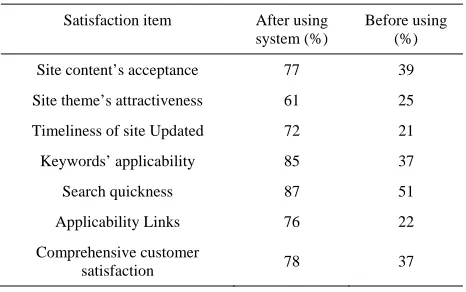
Effect of eliminating Information Island: This experiment researches how the model to eliminate website information island on the standpoint of customers; If this system can find out information itself timely in accordance with customer demand, the customer satisfaction will be greatly enhanced, Table 1 shows the online survey of client satisfaction.
Customer satisfies the following result.
(1) Customers’ average browsing time: The experiment records all kinds of information excavated in the database and matching degree with customers’ central issue through the operation of 10 cycles (72 hours as one
TABLE I. THE OVERALL SATISFACTION OF FORUM CUSTOMER
Satisfaction item After using system (%)
Before using (%)
Site content’s acceptance 77 39
Site theme’s attractiveness 61 25
Timeliness of site Updated 72 21
Keywords’ applicability 85 37
Search quickness 87 51
Applicability Links 76 22
Comprehensive customer
Figure 4. Comparison of Average visit time of Forum customer
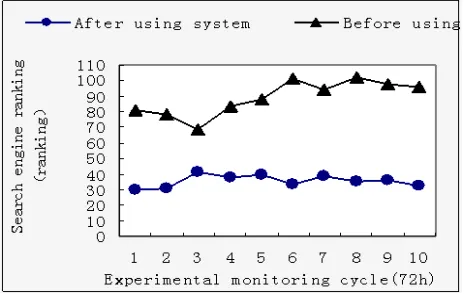
Figure 5. Comparison of the average rankings of forums in search engine
cycle); Among them, the most intuitive test data is customers’ average browsing time, the higher customer satisfaction to forum is, the longer browse time is ,or customer will quit soon; Figure 4 shows that this forum received a longer customers’ scanning time and smaller page bounce rate owing to applying this system.
(2) Search engine ranking, if forum contents meet current customer demand, and forum updates website features in good time, the average rankings of website’s characteristic words in search engine will increase; Figure 5 shows the ranking of site’s TOP10 feature words (the ranking period of internal feature words is 24 hours) in search engines of Baidu; This forum gets higher feature words average ranking thanks to website keywords seeding system.
V. CONCLUSION
To network Information Island, this paper proposes website keywords seeding system model; According to external customers’ high-frequency search terms and internal customers demand, this model uses multi-dimensional vector overlay space to match and extract information required by customers and has internal website optimized automatically. Experimental results
show that the model has better customer satisfaction(referring to the average customer visiting time on the site) and well search engine ranking, which is valuable in applications.
The paper’s logic is wonderful but it is weak in experiment because limit websites and validation assessment indicators will have effect on model confidence. The next study will do more job in experiment and include the construction of new "demand VS features" vector stacking space and so on.
APPENDIX A APPENDIX TITLE
A. Website. Also spelled Web site[1]; officially styled website by the AP Stylebook) is a collection of related web pages, images, videos or other digital assets that are addressed relative to a common Uniform Resource Locator (URL), often consisting of only the domain name, or the IP address, and the root path ('/') in an Internet Protocol-based network. A web site is hosted on at least one web server, accessible via a network such as the Internet or a private local area network.
B. SEO. Search engine optimization (SEO) is the process of improving the volume or quality of traffic to a web site or a web page (such as a blog) from search engines via "natural" or un-paid ("organic" or "algorithmic") search results as opposed to other forms of search engine marketing ("SEM") which may deal with paid inclusion. The theory is that the earlier (or higher) a site appears in the search results list, the more visitors it will receive from the search engine. SEO may target different kinds of search, including image search, local search, video search and industry-specific vertical search engines. This gives a web site web presence.
C. Information retrieval. Information retrieval (IR) is the science of searching for documents, for information within documents, and for metadata about documents, as well as that of searching relational databases and the World Wide Web. There is overlap in the usage of the terms data retrieval, document retrieval, information retrieval, and text retrieval, but each also has its own body of literature, theory, praxis, and technologies. IR is interdisciplinary, based on computer science, mathematics, library science, information science, information architecture, cognitive psychology, linguistics, and statistics.
Automated information retrieval systems are used to reduce what has been called "information overload". Many universities and public libraries use IR systems to provide access to books, journals and other documents. Web search engines are the most visible IR applications.
D. Information. Information, in its most restricted technical sense, is an ordered sequence of symbols. As a concept, however, information has many meanings.
The concept of information is closely related to notions of constraint, communication, control, data, form, instruction, knowledge, meaning, mental stimulus, pattern, perception, and representation.
are commonly called hits. The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. Unlike Web directories, which are maintained by human editors, search engines operate algorithmically or are a mixture of algorithmic and human input.
F. Computing platform. In computing, a platform describes some sort of hardware architecture and software framework (including application frameworks), that allows software to run. Typical platforms include a computer's architecture, operating system, programming languages and related user interface (runtime libraries or graphical user interface).
G. Algorithm. I n mathematics, computer science, and related subjects, an 'algorithm' is an effective method for solving a problem expressed as a finite sequence of instructions. Algorithms are used for calculation, data processing, and many other fields. (In more advanced or abstract settings, the instructions do not necessarily constitute a finite sequence, and even not necessarily a sequence; see, e.g., "nondeterministic algorithm".)
Each algorithm is a list of well-defined instructions for completing a task. Starting from an initial state, the instructions describe a computation that proceeds through a well-defined series of successive states, eventually terminating in a final ending state. The transition from one state to the next is not necessarily deterministic; some algorithms, known as randomized algorithms, incorporate randomness.
H. Meta element. Meta elements are HTML or XHTML elements used to provide structured metadata about a Web page. Such elements must be placed as tags in the head section of an HTML or XHTML document. Meta elements can be used to specify page description, keywords and any other metadata not provided through the other head elements and attributes.
The meta element has four valid attributes: content, http-equiv, name, and scheme. Of these, only content is a required attribute.
I. HTML element. An HTML element is an individual component of an HTML document. HTML documents are composed of a tree of HTML elements and other nodes, such as text nodes. Each element can have attributes specified. Elements can also have content, including other elements and text. HTML elements represent semantics, or meaning. For example, the title element, which is represented by the p element represents the title of the document.
ACKNOWLEDGMENT
I wish to thank Prof. Zhou Qihai who is my Ph.D. advisor. Prof Zhou gave my many useful suggestions to finish this paper. And I also want to thank my graduate, Zhuanzhuan Li, who helped me to translate this paper into English which is a heavy work.
REFERENCES
[1] Yimu Ji, Lili Lu. Research on the Integrated Model of
Campus Legacy System on SOA[J].Computer Science.2009.36(9):131-134.
[2] Luo Zhao, Xiaohui Chen. Design and Implementation of
Web Automation Building System on Content Management [J].Computer Science. 2005.32(2):105-108.
[3] Gang Li,Lizhu Zhou. Website Crawling for Specific
Topics [J]. Computer Science.2007.34(2):137-141.
[4] Yongqi Ren,Yi Tang. Research on Search Engine
Optimization Oriented User-Centered [J].Researches in Library Science.2009(1):44-45.
[5] Yongqiang Du. Sort Algorithm of Search Engine on
Behaviour Statistic YongQiang,Du(beihang university) [J].Computer & Digital Engineering.2006.34(10):46-48.
[6] Shaohua Li,Wenyu Gao. Survey of Page-ranking
Algorithms [J]. Application Research of Computers.2007.24(6):4-7.
[7] Ligang Wang,Zhengwen Zhao,Xinxin Zhao. Anti-cheating
on search engine optimization [J].Application Research of Computers.2009.26(6):2035-2037.
[8] Junwei Zhang, Ling Zhang,Fansou Ma. An Algorithm for
Ranking Pages of a Search Engine Providing Personality Service [J].Computer Engineering.2003.29(19):58-60.
[9] Jinlong Hao,Chengliang Wang. Ranking Algorithms of
Originals Promotion for Search Engine [J].Computer Engineering.2008.34(18):85-86.
[10]Xiaohai Chen,Ya Zhou. A Crawling Algorithm Based on
Topical Similarity for Guiding the Web Crawler Though Tunnels [J].Computer Engineering & Science.2009.31(10):126-128.
[11]Wei Zhang,Zhishu Li. Optimizing strategies for search
engines based on PageRank algorithm [J].Computer Applications.2005.25(7):1711-1713.
[12]Bo Zhang,Wandong Cai. The Research and
Implementation of Topic Spider Technique [J].Microelectronics & Computer.2009.26(5):52-55.
[13]Sung-Shun Weng, Binshan Lin, Wen-Tien Chen. Using
contextual information and multidimensional approach for recommendation[J]. Expert Systems with Applications, 2009, 36(2):1268-1279.
[14]Kwiseok Kwon, Jinhyung Cho, Yongtae Park. Influences
of customer preference development on the effectiveness of recommendation strategies[J]. Electronic Commerce Research and Applications, 2009, 8(5):263-275.
[15]You-Jin Park, Kun-Nyeong Chang. Individual and group
behavior-based customer profile model for personalized product recommendation[J]. Expert Systems with Applications, 2009.36(2): Pages 1932-1939.
[16]Daniel Baier, Eva Stüber. Acceptance of recommendations
to buy in online retailing [J]. Journal of Retailing and Consumer Services, 2010.17(3):173-180.
[17]Ting-Peng Liang, Yung-Fang Yang, Deng-Neng Chen,
Yi-Cheng Ku. A semantic-expansion approach to personalized knowledge recommendation
[18]Decision Support Systems, 2008.45(3):401-412.
[19]Kun Chang Lee, Soonjae Kwon. Online shopping
recommendation mechanism and its influence on consumer decisions and behaviors: A causal map approach [J]. Expert Systems with Applications, 2008.35(4):1567-1574.
[20]Yuxia Huang, Ling Bian. A Bayesian network and analytic
hierarchy process based personalized recommendations for tourist attractions over the Internet[J]. Expert Systems with Applications, 2009.36(1):933-943.
[21]Yuanchun Jiang, Jennifer Shang, Yezheng Liu.
model [J]. Decision Support Systems, 2010.48(3): 470-479.
[22]Yoon Ho Cho, Jae Kyeong Kim. Application of Web usage
mining and product taxonomy to collaborative recommendations in e-commerce [J]. Expert Systems with Applications, 2004.26(2):233-246.
[23]Duen-Ren Liu, Chin-Hui Lai, Wang-Jung Lee. A hybrid of
sequential rules and collaborative filtering for product recommendation [J]. Information Sciences, 2009.179(20):3505-3519.
[24]Tae Hyup Roh, Kyong Joo Oh, Ingoo Han. The
collaborative filtering recommendation based on SOM cluster-indexing CBR [J]. Expert Systems with Applications, 2003.35(3):413-423.
[25]Feng-Hsu Wang, Hsiu-Mei Shao. A personalized
recommendation system based on product taxonomy for one-to-one marketing online [J]. Expert Systems with Applications, 2005.29(2):383-392.
[26]Lun-ping Hung. Effective personalized recommendation
based on time-framed navigation clustering and association mining [J]. Expert Systems with Applications, 2004.27(3):365-377.
[27]Sang Hyun Choi, Sungmin Kang, Young Jun Jeon.
Personalized recommendation system based on product specification values [J]. Expert Systems with Applications, 2006.31(3):607-616.
[28]Sung-Shun Weng, Mei-Ju Liu. Feature-based
recommendations for one-to-one marketing[J]. Expert Systems with Applications, 2004.26(4):493-508.
[29]Chunyan Miao, Qiang Yang, Haijing Fang, Angela Goh. A
cognitive approach for agent-based personalized recommendation [J]. Knowledge-Based Systems, 2007.20(4):397-405.
[30]Amir Albadvi, Mohammad Shahbazi. A hybrid
recommendation technique based on product category attributes [J]. Expert Systems with Applications, 2009.36(9):11480-11488.
[31]Duen-Ren Liu, Ya-Yueh Shih. Integrating AHP and data
mining for product recommendation based on customer lifetime value [J]. Information & Management, 2005.42(3):387-400.
[32]Kwiseok Kwon, Jinhyung Cho, Yongtae Park.
Multidimensional credibility model for neighbor selection in collaborative recommendation [J]. Expert Systems with Applications, 2009.36(3):7114-7122.
[33]Duen-Ren Liu, Chin-Hui Lai, Chiu-Wen Huang.
Document recommendation for knowledge sharing in personal folder environments [J]. Journal of Systems and Software,2008.81(8): 1377-1388.
[34]Yukun Cao, Yunfeng Li. An intelligent fuzzy-based
recommendation system for consumer electronic products [J]. Expert Systems with Applications, 2007.33(1):230-240.
[35]Patrick Valente, Gautam Mitra. The evolution of
web-based optimisation: From ASP to e-Services [J]. Decision Support Systems, 2007.43(4):1096-1116.
[36]Rong-Hong Jan, Ching-Peng Lin, Maw-Sheng Chern. An
optimization model for Web content adaptation [J]. Computer Networks, 2006.50(7):953-965.
[37]Kerry Dye. Website abuse for search engine optimisation
[J]. Network Security,2008.3:4-6.
[38]Nadine Hchsttter, Dirk Lewandowski. What users see –
Structures in search engine results pages [J]. Information Sciences,2009.179(12):1796-1812.
[39]Judit Bar-Ilan, Mazlita Mat-Hassan, Mark Levene.
Methods for comparing rankings of search engine results[J]. Computer Networks,2006.50(10):1448-1463.
[40]Bernard J. Jansen, Paulo R. Molina. The effectiveness of
Web search engines for retrieving relevant ecommerce links [J]. Information Processing & Management, 2006.42(4):1075-1098.
[41]Bernard J. Jansen, Amanda Spink. How are we searching
the World Wide Web? A comparison of nine search engine transaction logs [J]. Information Processing & Management, 2006.42(1):248-263.
[42]Seda Ozmutlu, Huseyin C. Ozmutlu, Buket Buyuk. A
Monte-Carlo simulation application for automatic new topic identification of search engine transaction logs [J]. Simulation Modelling Practice and Theory, 2008.16(5):519-538.
[43]B. Barla Cambazoglu, Evren Karaca, Tayfun
Kucukyilmaz, Ata Turk, Cevdet Aykanat. Architecture of a grid-enabled Web search engine [J]. Information Processing & Management, 2007.43(3):609-623.
[44]Daniele Braga, Alessandro Campi, Stefano Ceri,
Alessandro Raffio. Joining the results of heterogeneous search engines [J]. Information Systems, 2008.33(7):658-680.
LI Zhongjun, born in 1974, Sichuan. He studied Information Management at Shaanxi Finance and Economics School located in Xi'an in 1994, and got computer bachelor in Jul 1998; Then he had researched data mining of EC in his postgraduate study in School of Economics and Finance of Xi'an Jiaotong University in 2001, and got Master of Economics; Since 2007, he has been a PHD in Economic Information Technology and Application in the school of Economic Information Engineering of Southwestern University of Finance and Economics, his research direction is intelligent computing and network recommendation system, he will graduate in 2011.
He worked as a software developer in a corporation in Guangzhou from Jul 1998 to Dec 1999 and did the same job in a company of Xi’an from Jan 2000 to Sep 2001. He has been a teacher in Southwestern University of Finance and Economics since Jul 2004. He was a teaching assistant from Jul 2004 to Dec 2006 and has been a lecturer since Jan 2007.Book: Song Kuang, Zhongjun Li. WEB Programming[M],Hangzhou: Zhejiang University Press, in 2009.Paper 1: Zhongjun Li,Qihai Zhou, Qinghong Shuai. Recommender System Model Based on Isomorphic Integrated to Content-based and Collaborative Filtering[J]. Computer Science,2009.12(36) :142-145.Paper 2: Li Zhongjun, He Lijuan, Zhou Qihai. The Reconstruction, Exploration and Innovation of Logos of E-commerce[A]. International Symposium on Electronic Commerce and Security, in 2008. From undergraduate to postgraduate, his research interests included information systems development and e-commerce web site development and application; his research interests has been mainly in artificial intelligence and conduct research on e-commerce site since he graduated in 2004.