1120 All Rights Reserved © 2017 IJSETR
SHARING DATA EFFICIENTLY USING NAME
BASED ROUTING IN BIG DATA
Abstract: Big data unequivocally requests a system foundation having the capacity to productively gather, prepare, reserve, share, and convey the information, rather than straightforward transmissions. Such system outlines demonstrate the prerequisites of vitality proficiency, accessibility, superior, and information mindful knowledge. To meet these necessities, the information-centric networking (ICN) approach is received, where information are recovered through names and in-arrange storing is used. In any case, as the run of the mill existing ICN structures, content centric network (CCN) can't proficiently use the reserves for information sharing because of the on-path caching strategy and network of information (NetInf) exhibits the determination dormancy for information recoveries. To design an efficient and effective ICN architecture for big data sharing, combine the strong points of CCN and NetInf, where information islands (IOIs) and management plane are utilized for direct data retrieval and global data discovery, respectively. A reference engineering and an aggregatable name-based routing (ANBR), which can normally empower customers to recover the nearest duplicate of data.
Keywords: Information Centric Network , Content Centric Network , Energy efficiency, Information Islands
1. INTRODUCTION
As the quantity of clients and gadgets associated with the Internet is keep on expanding, in order to encourage content distribution numerous new assortment of internet applications are being presented. Finding efficient and versatile content distribution mechanisms is a fascinating research issue as the measure of content shared among the internet clients is regularly increasing. Billions of individuals with cell phones and small other devices such as sensors, actuators, and robots, are generating gigantic measures of information[1] .It is known as big data, described by five angles as volume, speed, esteem, multifaceted nature and assortment[2]. It is rapidly growing as one of the important section of the today's IT industry. Hug data of enormous information are created by and collected from geographically distributed devices, and passed it to data warehouses with the help of huge interrelated servers the data is processed in powerful data centers. The challenges faced by its applications are conquering, securing, preparing, distributing, transmitting,
breaking down and envisioning the data with extremely vast amount. For vitality proficient information sharing the system outlines must be effective in the huge information.
Huge information will overpower the current
communication systems, because that gigantic measures of information sharing applications create repetitive and copy traffic if networks basically act as transmission funnels. This tremendous amount of traffic impedes productive information streams[2] and gives the Internet the troubles in giving the very accessible services for these applications. In this way the time has come to re-consider the system foundation plan for information sharing applications in the period of enormous information. The four design necessities as follows,
Energy-efficiency :
To advance vitality utilization in information transmission the system ought to diminish the repetitive and copy traffic. It additionally ought to empower the information to be recovered from the nearest information duplicate holder.
Mr. SATHYANARAYAN S
Assistant Professor
Department of CS&E.,
J.N.N.C.E., Shivamogga
SUPRIYA S
M.Tech, 4
thSem ,
Department of CSE, J.N.N.C.E,
1121 All Rights Reserved © 2017 IJSETR
For the same data need to be delivered from data center the current implementation with data centers, which brings out expansive copy traffic overhead.
Availability:
To provide the services to users the network should be enabled over heterogeneous systems paying little mind to network scale or breakdowns.
High-Performance:
The system ought to furnish administrations with low dormancy and high-throughput, especially in the event of the postponement touchy applications.
Data aware intelligence:
The system ought to know about the qualities of the information in transmissions for the potential in-system preparing. In this manner, the system registering assets can adjust for system transmission assets to make the correspondence display more versatile and efficient [5].
To meet these requirements, the Information Centric Networking (ICN) approach is adopted to design a network architecture for content sharing in the era of big data .In ICN, routers are possibly equipped with cache memories to cache data. Because of in-network caching, the duplicate transmissions from the data centers to the users and further energy consumptions can be significantly reduced. The high availability can also be achieved, since the same data is not only stored in the data centers but cached in the networking nodes. In the ICN, data names, rather than server IP addresses, become the handles of the requests and replies for the routers. Hence, ICN approaches can achieve data-aware intelligence based on the data names.
2. RELATED WORK
The executions of enormous information applications are bypassing server farms, and systems go about as the transmission channels for information gathering, total, handling, sharing and conveyance. With the violently developing of the huge information, the systems turn into a bottleneck for the hazardous information sharing. Along
these lines, it is important to update the system capacities to assemble a system thruway for productive information sharing. ICN has been distinguished to can possibly make up for arrange assets to make the correspondence demonstrate more adaptable and proficient. NetInf for the most part outline an extra information name enrollment and determination framework to find and recover the nearest data duplicate. The fundamental thought of NetInf is to utilize ID/Locator part to alleviate data from have.
3. METHODOLOGY
Communication is defined in terms of requesting and publishing NDOs with integrated caches in the network infrastructure. An NDO can refer to audio, video, web page, image, email and many other data objects, each mapped to unique name identifiers. NDO retrieval in ICN can be done with two different methods. In the first method, which is known as Name Resolution Service (NRS), the NDO name is resolved in to NDO's network location. Once the network location is retrieved, a request for the NDO is sent to the identified network location and response with NDO is sent back to requester using legacy routing protocols. In the second method, which is known as Name Based Routing, NDO requests are routed to NDOs' locations based on NDO names in the network. Each router contains next hop mapping for each name. Since traditional routing mechanisms are not sufficient to handle requirements of future Internet, routing mechanisms that combine name resolution service and name based routing are being investigated.
Building an NRS system for a global ICN network is challenging due to enormous amount of NDOs. Though there are some proposals to provide NRS on a global level, NDO requests are still forwarded using legacy routing protocols. Hence it will be difficult to apply ICN functions on forwarded path. For instance, NDO requests are routed in a cache unaware manner i.e., router caches are not looked up for the requested NDO. This brings us to Name Based Routing that performs cache aware routing i.e., NDO is served from a router if it is available in the router's cache. For the ICN architecture designs, the core challenge is the
1122 All Rights Reserved © 2017 IJSETR
design of Name-Based Resolution/Routing (NBRR) accompanied with the caching strategy to discover and retrieve the closest cached copy by data name. The proposed reference architecture composed of Information Island (IOI) for local caching and Management Plane (MP) for global discovery and management. Then propose an Aggregatable Name-Based Routing scheme called ANBR as NBRR, where overlay technology is utilized in the MP to globally discover and manage cached data at IOI granularity and name-based registration/retrieval is employed in local IOI. NBRR is the core function of ICN to enable a data consumer to fast discover and retrieve the close copy of the desired data under the situation where there are several copies of the same data in the network.
The system is separated into numerous appropriate size Information Island (IOI) for information storing and quick recovery. A Management Plane (MP) is used for worldwide reachability and administration. Around are two sorts of elements, forwarding cacheable node (FCN) and aggregate management node (AMN). FCN has elements of sending also in-system storing. AMN has elements of sending.
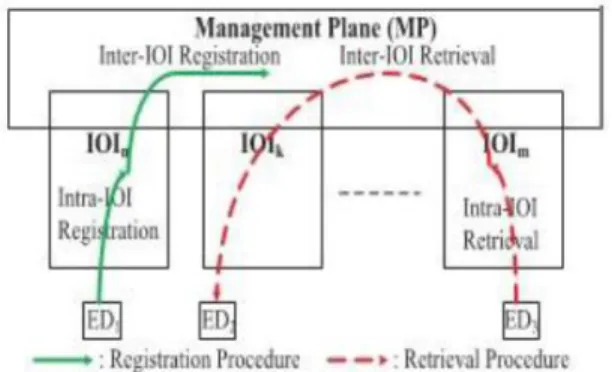
Figure 1: ANBR system overview
The simplified arrangement of NBR stays represented in Fig.1, which comprises of the IOIs and a MP. End devices (EDs) are data distributers and shoppers. The IOI goes about as control system stage to give data admission to EDs. NBR involves two equal enrollment and recovery,
intra-IOI enlistment/recovery and between IOI
enrollment/recovery, to find and recover the nearest
duplicate. Data is managed with data name (InfN), For intra-IOI enrollment, InfN or prefixf InfN container stay enlisted in FCNs/neighborhood AMNs to empower nearby disclosure. In between IOI level, NBR utilizes AMN overlay system to enlist IOI data of stored information to empower traffic to be aggregatable at IOI unit and nearest duplicate to be discoverable. In the interim, AMN overlay gives fundamental administration of all duplicates for effectively performing activities of expeland overhaul. As in Fig.1, at the point when data is created and after that reserved by ED1, its presence will be reported through enrollment system. The FCNs getting the enlistment parcel make another section for achieving this data in intra-IOI enrollment. In the interim, when the enlistment bundle touches base at the AMN, the data will be enrolled comprehensively through between IOI enrollment. In information recovery methodology, information demand bundle is first sent to the duplicate holder in neighborhood IOI however much as could reasonably be expected. That is, the point at which one FCN in IOI gets a solicitation parcel, it authorizations whether this information happens in its memory.
If no matching cached data in memory, it computes which prefix in its routing table has the longest match compared with InfN in the request. Here longest prefix matching is used. After the selection of longest matching entry, the packet will be forwarded to the next hop specified in it.
If there is no matching data and entry in FCN/server, this data request packet is forwarded to the AMN for global DHT query to find the closest IOI holding the copy and finally reach the closest FCN/server holding a copy in that IOI. Then SAMN performs longest matching in all the entries with the same prefix and compare with location information to send to the closest copy holder. This lookup procedure is called mixed prefix match lookup. In Fig.1, once ED3 needs to recover the data, it firstly performs intra-IOI.. recovery now neighborhood IOI. The
1123 All Rights Reserved © 2017 IJSETR
FCNs onward the solicitation parcel to the FCN/server holding a duplicate in the same IOI through longest prefix competition l00kup. On the off chance that such FCN/server happens in nearby IOI, it answers by an information recovery parcel. Something else, between IOI recovery is activated.. This data request packet will be forwarded to the SAMN for global query[3]. Then SAMN forwards the message to the closest IOI holding the copy and finally reach the closest FCN/server, ED2, which replies with data[4] .
4. BASIC DESIGN
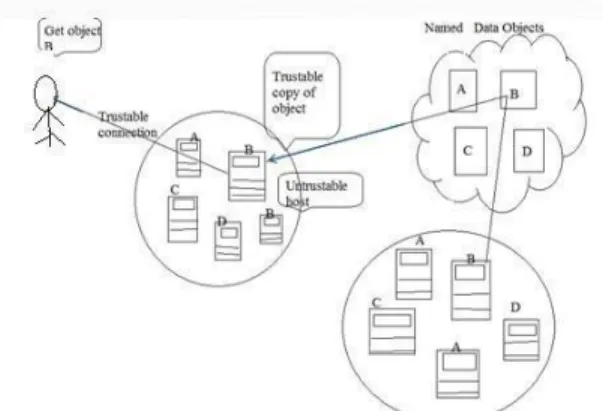
The system design considerations divide the system into many subsystems depending on the requirements of the system. System design states relationships between components and also the software structure. It maintains a design decisions record and provides a plan for the implementation phase. In Fig.2 the Information Centric Architecture (ICN) it has Named Data Objects (NDO) is nothing but web pages, documents, movies and any interactive media. The NDO name and identity does not change regardless of its location, storage media, application program and transportation methods that implies that any two copies of an NDO are equivalent such that any mode or system holding a same copy can supply it to a requests.
Figure 2: Information Centric Network Architecture
Named data objects: NDO is nothing but web pages, documents, movies and any interactive media. The NDO name and identity does not change regardless of its location, storage media, application program and
transportation methods that implies that any two copies of an NDO1 are equal such that any mode or system allotment a same copy can supply it to a requests.
Naming and Security: ICN requires a different name for each NDO those names have t0 be unique since they are used for detecting objects regardless of their position or containers.
Application Programming Interface (API): The API consists of Requesting and delivering NDO’s .which enables the Information provides to post the availability of their content and subscribe the requested data.
Caching: An essential part of the ICN services is the storage for caching NDO’s in an ICN have caches so that request for an NDO can be accomplished by any node storing a copy in its store.
Level 1
In the ICN network, each bit of data can be stored at one IOI at maximum after, which advances the effectiveness of the cache procedure.
Level 2
Name Based Routing (NBR) comprises of the IOIs and an administration plan(MP). End devices (EDs) are data distributers and customers. The IOI goes about as edge system stage to give data access to EDs.NBR involves two levels enrollment and recovery, intra-IOI. registration/recovery and between IOI. enlistment/recovery, to find and recover the nearest duplicate. Data is managed with data name (InfN).
5. RESULTS
The NDO is named data objects it can find out the required objects by using its name hence it decreases the traffic and increases the efficiency because instead of searching all data without knowing their name it can helps to find out the data .When the number of users want to store the same data which is containing the same text files like text1.txt, text2.txt, text3.txt as well the number of users are nothing but the instances whose storing their data in the storage area The text.txt files containing the number of blocks it is nothing but blks each block contains 32 bytes. Hence by
1124 All Rights Reserved © 2017 IJSETR
using the Hash key it helps to find the same data present in the two blocks from the different text.txt files stored by the different instances. Hash key generator is not a human readable. Here it has to increase the efficiency by decrease the traffic by the number of users caching the data from the storage area is recovered by using the number of data centers.
Figure 3 : Hash key details
6. CONCLUSION
Enormous information requests a system design that can accomplish accessibility, elite, and information mindful knowledge. It is watched that data driven methodology can assume a vital part to give the systems administration in the period of enormous information. Here to propose the naming technique, parcel configuration, and element capacities for this design. At that point give the essential outlines on information enrollment and information recovery methodology. To empower the vitality efficiency, models the system and look at the effect on the vitality utilizations for the proposed design from the key factor. Therefore, we avoid the disadvantages and absorb the merits of the typical existing ICN architecture, CCN and NetInf, and design a reference network architecture. The tremendous volume of traffic frustrates efficient information flows and gives the Internet the difficulties in giving the exceedingly accessible administrations to these applications. In this manner, it is time to reconsider the system foundation plan for information sharing applications in the period of huge information.
7. REFERENCES
[1] D. Che, M. Safran, and Z. Peng, ``From big data to big data mining: Challenges, issues, and opportunities,'' in Database Systems for Advanced Applications. Berlin, Germany: Springer-Verlag, 2013,
[2] S. Kaisler, F. Armour, J. A. Espinosa, andW. Money, ``Big data: Issues and challenges moving forward,'' in Proc. IEEE 46th Annu. Hawaii Int. Conf. Syst. Sci. (HCISS), Jan. 2013,
[3] E. K. Lua, J. Crowcroft, M. Pias, R. Sharma, and S. Lim, ``A survey and comparison of peer-to-peer overlay network schemes,'' IEEE Commun. Surveys Tuts., Mar. 2005.
[4] I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, and H. Balakrishnan, ``Chord: A scalable peer-to-peer lookup service for Internet applications,'' in Proc. ACM SIGCOMM, 2001,
[5] H. Yin, Y. Jiang, C. Lin, Y. Luo, and Y. Liu, ``Big data: Transforming the design philosophy of future Internet,'' IEEE Netw., vol. 28, no. 4, pp. 14_19, Jul./Aug. 2014.