International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3300 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Abstract—Web usage mining is the process of extracting
useful usage patterns from the web data. Web personalization uses web usage mining technique for the process of knowledge acquisition done by analyzing the user navigational patterns interest. Nowadays, the Web is an important source of information retrieval, and the users accessing the Web are from different backgrounds. The usage information about users is recorded in web logs. Analyzing web log files to extract useful patterns is called Web Usage Mining. Web usage mining approaches include clustering, association rule mining, sequential pattern mining etc. The web usage mining approaches can be applied to predict next page access. As the size of cluster increases due to the increase in web users, it will become inevitable need to optimize the clusters. This paper proposes a cluster optimization methodology based on fuzzy logic and is used to reduce the redundancy. For clustering Fuzzy C-Means (FCM) algorithm is used. Fuzzy cluster chase algorithm for cluster optimization is used to personalize web page clusters of end users.
Keywords- Web Usage Mining, Web log files, Fuzzy C-Means algorithm, Fuzzy Cluster chase algorithm
INTRODUCTION
Data mining is the process of analyzing data from different angles and summarizing it into useful information. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational
databases.‖[1]. Web mining is the application of mining data techniques to discover patterns or trends followed by the user from the Web [2] .It is required as only small portion of information on web is relevant and giving user what he wants is important Web mining is required as information stored on worldwide web is growing rapidly and giving user what he wants is very important. There are three main thrust areas of web mining. Patterns followed by the users are evaluated by these three techniques of Web Mining and then these patterns are analyzed to get a user desired output. Desired output is then fed into the user understandable GUI [6].
World Wide Web is warehouse of information. It is used by the user to get required information requested through queries. Sometimes user might not be satisfied with response given. This might be as pages which are requested by the user have not been indexed since they are not indexed they are not returned in response to query submitted by the user. To increase user satisfaction for requests made on web we need a new technique that will enable user to get required information easily, efficiently and correctly, that easily mines the required information within fraction of seconds.‖This extraction of Information on Internet or World Wide Web is called Web Mining‖ [3].It is technique of mining data on World Wide Web. Web mining has three major thrust areas:
Web Usage mining Web Content mining Web Structure mining Web Usage Mining
Web usage mining is mining of web logs to discover access patterns of the pages accessed by the user. Analyzing
regularities in web log records can help us to identify potential customers for ecommerce, help in customization of web pages, improving server performance. Web server saves all entries of pages accessed in web logs. It includes URL requested, IP address, and timestamp. These log files can also be created at client and proxy. Web log databases provide rich information about web dynamics and that‘s why it is important to develop a technique that will help us to mine web log databases. This technique is web usage mining. Data stored in logs can be used to find most frequently accessed web pages, frequently accessed time periods. This data will help us in finding most potential customers to be targeted for marketing. It can also be done to find trends of web access. Web sites improve
themselves by learning from user access patterns. Web log analysis can also help to build customized web services for individual users.
There are four phases to perform web usage mining [4] Pre-processing - It is a process of preparing data so that it can be used for Pattern Discovery and analysis. It includes Cleaning of Server Log files accompanied by identification of user‘s sessions and user habits.
Seema Sheware
1, A.A. Nikose
*21
Department of Computer Sci & Engg , Priyadarshini Bhagwati College of Engg Nagpur,Maharashtra, India
2
Department of Computer Sci & Engg , Priyadarshini Bhagwati College of Engg Nagpur,Maharashtra, India
WEB USAGE MINING BASED ON SERVER LOG FILE USING
FUZZY C-MEANS CLUSTERING
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3301 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
It consists of
Data field extraction Data Cleaning User identification Session identification
Pattern Discovery - After the data is pre-processed, this data is utilized for discovering homogeneous patterns.[5]
Pattern Analysis - Once the patterns are discovered then these patterns is evaluated and analysis is performed on these patterns and result generated is given to neural network for further processing.
Fig.1: Web usage mining process
Problems faced while performing web usage mining Processing of logs that is cleaning of log files Cleaning of log files that are removing data that is not relevant.
Identification of user sessions Identification of user habits. Applications of Web Usage Mining
16. Personalization - Reconstruct the website based on user‘s profile and usage behaviour.
17. System Improvement - Provide help to understand web traffic behaviour. There are some benefits of it like web load balancing, data distribution or policies for web caching.
18. Adjustment of Website - Understanding visitor‘s behaviour in a web site provides hints for adequate design and update decision.
19. Business Intelligence - It occupies the application of intelligent techniques in order to help certain businesses, mainly in marketing.
20. Effective - Valuing the effectiveness of advertising by analyzing large number of access behaviour patterns.
21. Improving the design of e-commerce web site according to users browsing behaviour on site in order to better serve the needs of users.
Web usage mining uses data mining techniques to discover useful access patterns from web server logs. Web log data is a record of all URLs accessed by users on a Web site. Each log entry consists of access time, IP address, URL viewed, (the Web page visited just prior to the current one), etc. Web personalization uses web usage mining technique to customize the web pages for a particular user. This includes the extraction of user sessions from log files. Currently for web
personalization several clustering methods are available. But most of these techniques the data redundancy and scaling issues are high. In this paper an optimizing methodology is proposed for eliminating the data redundancies that may occur after the clustering done by web usage mining methods.
For the process of clustering basic concepts of Fuzzy C-Means (FCM) algorithm is used. FCM is an overlapping clustering approach so that a user can exist in more than one cluster with the algorithm assigns a feature vector to a cluster according to the maximum weight of the feature vector over all clusters. Each user cluster generalizes the URLs most
frequently accessed by all cluster members. In our proposed work Fuzzy Cluster-chase algorithm for cluster optimization which uses the fuzziness measure of the resulting cluster to calculate the similarity of the clusters. According to these similarity measures the most similar clusters are merged together. This merging helps to increase the precision without affecting the coverage. The proposed method adds an
optimization module to the clustering and provides a better clustering than normal fuzzy partitioning. Also if precise data is available than les memory will be utilized and runtime will be reduced.
RELATED WORK and LITERATURE SURVEY
Web Mining is the application of data mining techniques to extract knowledge from web data, including web documents, hyperlinks between documents, us-age logs of web sites, etc. There are three kinds of web mining process: Web Usage Mining-Web usage mining is the process of extracting useful information from server logs i.e. users history, Web Structure Mining structure mining is to extract previously unknown relationships between Web pages, Web Content Mining Web content mining is the mining, extraction and integration of useful data, information and knowledge from Web page contents [6].
Web Usage data are often used for Web site access statistics or for forecast of requested pages. In order to do this, the data are filtered and then organized and stored according to two essential ways: Graphs and trees are used when complex navigation models must be processed. For example WUM [8] (Web Utilization Miner) uses weighted aggregation trees to represent the navigation traffic along roads corresponding to the logical structure of the Web site. WUM proposes a language
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3302 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
named MINT with a syntax close to SQL in order to make requests about the routes in the navigation tree. N-dimensional vectors are also used when the space of navigation is well known. WEB Miner [9] represents a transaction as a vector in the space of the reachable pages. On the other hand, in this work, some other information about users and documents are used for the analysis. There is a general request language to access the data but then different structures are used according to the goal of the analysis.
Clustering analysis aims to group similar web usage sessions into identical clusters. The process cannot be
performed unless WUM data is passed through sophisticated preprocessing steps. They clustered the pre-processed WUM data using a swarm intelligence based optimization, PSO based clustering algorithm. In this paper, showed the performance of the Particle Swarm Optimization (PSO) algorithm is better than K-means clustering .The result of clustering of server log data based on these parameters: (a) time and request per 30 minutes distribution (b) page viewed and number of user distribution (c) session-number of request distribution (d) session-time distribution [7].
PROPOSED METHODOLOGY
We are using data mining techniques such as
clustering in data mining and we are expecting the prediction of web usage mining. Web usage mining is the process of finding most important pages or sections from web which being highly visited by user or predicting the user‘s preference.
Fig.2: Proposed Architecture System
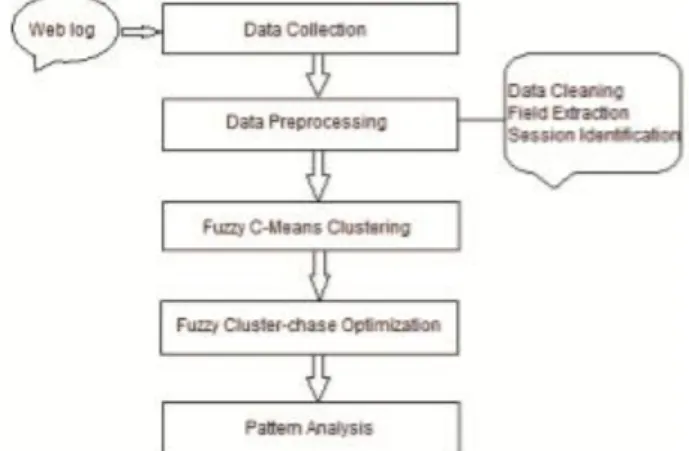
Web usage mining deals with the extraction of efficient usage patterns from web log data, in order to understand and provide the needs of web based applications. The web usage mining process includes the following steps: Data collection, Preprocessing of log file, Pattern discovery based on fuzzy clustering, Cluster optimization done by Fuzzy Cluster-chase algorithm, and the pattern analysis. Figure 1 describes the general frame work for the proposed model.
In the above figure, architecture of our proposed system is shown. The working of this model is discussed in detail where complete algorithm is explained based on Fuzzy C-means clustering.
Pre-processing Steps of Log Data
One objective of web usage mining is to extract sequential usage patterns from a large collection of web logs [9]. These patterns can be used to predict users' access patterns, to identify users' intention, and to provide timely help for using features available on a web site. Since web log records are usually designed for debugging purposes, they need to be preprocessed before applying data mining techniques [10]. Five
preprocessing steps have been identified [11]:
24. Data Cleaning: Irrelevant information which is useless for mining purposes can be removed from the HTTP server log files e.g. access performed by spiders, crawlers ,robots and files with extension name jpg, gif, css.
25.
26. User Identification: Address, User agents and referring URL fields of log file are used to identify user. There are some problems which can arise in user identification [4]. ISP‘s which uses DHCP technology, it is difficult to identify same user through different TCP/IP connections because IP address changes dynamically (single IP address/multiple server session). It is also possible that IP address of a user changes
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3303 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
user). Different IP address can be assigned for every single request performed by the user (Multiple IP address/single server session). Moreover, same user can access the Web by using different browsers from the same host (multiple agent/single users).
User Session Identification: Log entries of the same user are divided into sessions or visits. A time out of 30 minutes between sequential requests from the same user is taken in order to close a session.
Path Completion: To determine if there are important accesses which are not recorded in the access log due to caching on several levels.
27. Formatting: Format the data to be readable by data mining systems.
Once web logs are preprocessed, useful web usage patterns may be generated by applying data mining techniques such as mining association rules, mining clusters, and mining classification rules [12,13,14].
WORKING OF PROJECT
Here, we are going to explain how the system works by explaining complete architecture system in detail along with the algorithms used in this application. Web usage mining deals with the extraction of efficient usage patterns from web log data, in order to understand and provide the needs of web based applications. The web usage mining process includes the following steps: Data collection, Preprocessing of log file, Pattern discovery based on fuzzy clustering, Cluster optimization done by Fuzzy Cluster-chase algorithm, and the pattern analysis. Figure 3 describes the general frame work for the proposed model.
Fig 3: A general framework for the proposed model
Data Collection
The input for the web usage mining process is collected from the web log file. Log file is available in two formats. The first is the common log format which records the host name and the version of the user‘s web browser. The second is the extended log format. Figure 4 shows the example log data.
user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/Canon_F-792SGA.html207.49.13.14 - - [21/Feb/2014:24:08:43 -0800] "GET/user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/Ca non_P220-DH.png HTTP/1.1" 401 12846 h24-71-249-14.ca.shawcable.net - - [21/Feb/2014:24:29:12 -0800] "GET/user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/BS -1200TS.png HTTP/1.1" 200 3382
Figure 4. Examples log file record Data Preprocessing
Preprocessing is the process of preparing log data for further analysis by removing irrelevant data items. The first step in preprocessing is data cleaning. Data cleaning can be done by checking the suffix of URL name and deleting the entries which are of no support to the analysis, such as gif, jpeg, JPG and GIF.
The next step in preprocessing is the field
extraction. The required fields are extracted from the cleaned log file and stored in the database for further processing. After data cleaning and field extraction the user sessions are identified. A request from a particular user within a
predefined time period is considered as a user session. Each user session has identified by the session ID. These user sessions are needed to be stored along with the log file fields for clustering.
Fuzzy C-means Clustering
Cluster is a collection of data objects that are similar to one another. In the case of web usage mining the data objects are user sessions generated by preprocessing step. By grouping the users having similar access patterns form the clusters. A good clustering method will produce high quality clusters in which intra-cluster similarity should be high and inter–cluster similarity should be less. The quality of cluster depends on the similarity measure. The data objects are represented by the feature vector.
The following steps explain the working of FCM: Input: The feature vector Xi that represents the navigational patterns of each user and the number of clusters.
Output: The clusters having users with similar access patterns.
Step 1: Start
Step 2: Initialize or update the fuzzy partition matrix U with equation (2)
Step 3: Calculate the center vectors using equation (3) Step 4: Repeat step (2) and (3) until the termination criterion is satisfied.
Step 5: Stop
The fuzzy c-means procedure continues until the termination criterion is satisfied. Termination criteria can be that the difference between updated and previous objective function value -, is less than a predefined minimum threshold. Additionally, the maximum number of iteration cycles can also be a termination criterion.
Our next step is to apply Cluster Chase optimization Algorithm which is our research oriented step and we will apply cluster chasing algorithm which will minimize the inter-cluster dependency.
Fuzzy Cluster-Chase Algorithm for Cluster Optimization The objective of cluster optimization is to reduce the inter cluster similarity and increase the intra cluster similarity
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3304 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
along with scalability. The clustering routine optimizes number of clusters as well as cluster assignment, and cluster prototypes. This paper proposes a Fuzzy Cluster-chase algorithm; a cluster optimization algorithm which takes the input from fuzzy clustering approaches FCM. The clusters obtained by FCM method is feed into fuzzy cluster-chase algorithm that check the similarity by analyzing the fuzziness measure.
The following steps explain the Fuzzy Cluster-chase algorithm:
Input: N clusters which gives the representation of the URLs most frequently accessed by all members of that clusters.
Output: M clusters which minimizes intra cluster distance and maximizes the inter cluster distance.
Web usage mining deals with the extraction of efficient usage patterns from web log data, in order to understand and provide the needs of web based applications. The web usage mining process includes the following steps: Data collection, Preprocessing of log file, Pattern discovery based on fuzzy clustering, Cluster optimization done by Fuzzy Cluster-chase algorithm, and the pattern analysis. Figure 3 describes the general frame work for the proposed model.
Data Collection
The input for the web usage mining process is collected from the web log file. Log file is available in two formats. The first is the common log format which records the host name and the version of the user‘s web browser. The second is the extended log format. Figure 4 shows the example log data.
user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/Canon_F-792SGA.html207.49.13.14 - - [21/Feb/2014:24:08:43 -0800] "GET/user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/Ca non_P220-DH.png HTTP/1.1" 401 12846 h24-71-249-14.ca.shawcable.net - - [21/Feb/2014:24:29:12 -0800] "GET/user/Gadgets_&_Other_Electronics/Calculators/Scientific/Canon/BS -1200TS.png HTTP/1.1" 200 3382
Figure 4. Examples log file record Data Preprocessing
Preprocessing is the process of preparing log data for further analysis by removing irrelevant data items. The first step in preprocessing is data cleaning. Data cleaning can be done by checking the suffix of URL name and deleting the entries which are of no support to the analysis, such as gif, jpeg, JPG and GIF.
The next step in preprocessing is the field
extraction. The required fields are extracted from the cleaned log file and stored in the database for further processing. After data cleaning and field extraction the user sessions are identified. A request from a particular user within a
predefined time period is considered as a user session. Each user session has identified by the session ID. These user sessions are needed to be stored along with the log file fields for clustering.
Fuzzy C-means Clustering
Cluster is a collection of data objects that are similar to one another. In the case of web usage mining the data objects are user sessions generated by preprocessing step. By grouping the users having similar access patterns form the clusters. A good clustering method will produce high quality clusters in which intra-cluster similarity should be high and inter–cluster similarity should be less. The quality of cluster depends on the similarity measure. The data objects are represented by the feature vector.
The following steps explain the working of FCM: Input: The feature vector Xi that represents the navigational patterns of each user and the number of clusters.
Output: The clusters having users with similar access patterns.
Step 1: Start
Step 2: Initialize or update the fuzzy partition matrix U with equation (2)
Step 3: Calculate the center vectors using equation (3) Step 4: Repeat step (2) and (3) until the termination criterion is satisfied.
Step 5: Stop
The fuzzy c-means procedure continues until the termination criterion is satisfied. Termination criteria can be that the difference between updated and previous objective function value -, is less than a predefined minimum threshold. Additionally, the maximum number of iteration cycles can also be a termination criterion.
Our next step is to apply Cluster Chase optimization Algorithm which is our research oriented step and we will apply cluster chasing algorithm which will minimize the inter-cluster dependency.
Fuzzy Cluster-Chase Algorithm for Cluster Optimization The objective of cluster optimization is to reduce the inter cluster similarity and increase the intra cluster similarity along with scalability. The clustering routine optimizes number of clusters as well as cluster assignment, and cluster prototypes. This paper proposes a Fuzzy Cluster-chase algorithm; a cluster optimization algorithm which takes the input from fuzzy clustering approaches FCM. The clusters obtained by FCM method is feed into fuzzy cluster-chase algorithm that check the similarity by analyzing the fuzziness measure.
The following steps explain the Fuzzy Cluster-chase algorithm:
Input: N clusters which gives the representation of the URLs most frequently accessed by all members of that clusters.
Output: M clusters which minimizes intra cluster distance and maximizes the inter cluster distance. Step 1: Start
Step 2: Initialize the value of i as 1
Step 3: Repeat the following steps until i is equal to N Step 4: For each cluster i to N
Step 5: Check the similarity between two clusters Pi and Pi+1 by the equation (6)
Step 6: If the similarity > ˜ then
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3305 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Step 8: If yes then check the membership value of the user in both clusters and delete the user form the cluster having low membership value and remains in the cluster having high membership value.
Step 9: Stop
Once all the iterations are finished we get M clusters which is less than the initial N clusters (M<N). Some clusters will have higher densities and some of them will be vanished. Pattern Analysis
In pattern analysis user profiles are created as a set of URLs from the clusters obtained and found the best web page accessed by most of the users.
Server Level Collection
Access log files at server side are the basic
information source for Web usage mining. These files record the browsing behavior of site visitors. Data can be collected from multiple users on a single site. Log files are stored in various formats such as Common log [6] or combined log formats. Following is an example line of access log in common log format.
―64.242.88.15 - - [20/Feb/2014:16:36:22 -0800] "GET
/user/Cellphone_&_Accessories/LG/Main/WebIndex?rev1=1.2&rev2=1.1 HTTP/1.1" 200 46373‖
Fig: 5 Example of web log
Figure 6. Sample of Web Log Data
Above figure shows the sample data from our project. This data consists of the following fields:
29. Client IP address
30. User id (‗-‗if anonymous) 31. Access time
32. HTTP request method
33. Path of the resource on the Web server 34. Protocol used for the transmission 35. Status code returned by the server 36. Number of bytes transmitted
V. EXPERIMENTAL EVALUATION AND RESULT ANALYSIS
To open the project in NetBeans IDE 8.0.2, I have to first open NetBeans IDE 8.0.2. Click on ―Open Project‖ and select path where our database ―Matrimonial‖ is stored. Click ―Open‖ and the project is opened in NetBeans IDE 8.0.2. And ―Run‖ this application as shown below in figure 7.
Fig 7: Project Run in NetBeans IDE 8.0.2
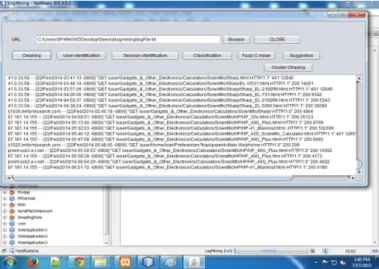
Now user has to select a file named as ―logfile.txt‖ which contains complete log data including unwanted data like images, etc. Before moving on cleaning of this logfile is needed which later on is updated in database for further processes. Convert this file data into sessions for getting required information.
Figure 8: Select “logfile.txt” file
In this phase, pre-processing of data will be started that is ―Cleaning‖. Irrelevant information which is useless for mining purposes can be removed from the HTTP server log files like files with extension name jpg, gif, css, etc. The screen shot is shown below:
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3306 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Figure 9: Cleaning of unwanted data
Figure 10: User Identification
Address, User agents and referring URL fields of log file are used to identify user. There are some problems which can arise in user identification. We have already discussed those problems in proposed methodology section.
Figure 11: Session Identification
Above screen shows the session tracking Log entries of the same user are divided into sessions or visits. A time out of 30 minutes between sequential requests from the same user is taken in order to close a session. This is done to track a record of each and every user, on which product user is giving more time and what kind of purchases he is doing. Each and every second‘s detail of user‘s can be tracked.
Classification is the task of mapping a data item into one of several predefined classes. In the Web domain, one is interested in developing a profile of users belonging to a particular class or category. This requires extraction and selection of features that best describe the properties of a given class or category. In our project we classified the sessions as S1, S2, and so on. URLs are defined as short, medium, long as shown in figure 12.
Unique users are identified after applying the algorithm and sessions whose paths are completed to form transactions are found out. Completed transactions are represented in a user transactions-URLs matrix format. It is a process of grouping data objects into disjoint clusters so that the data in each cluster are similar, yet different to the other clusters.
Figure 12: Classification
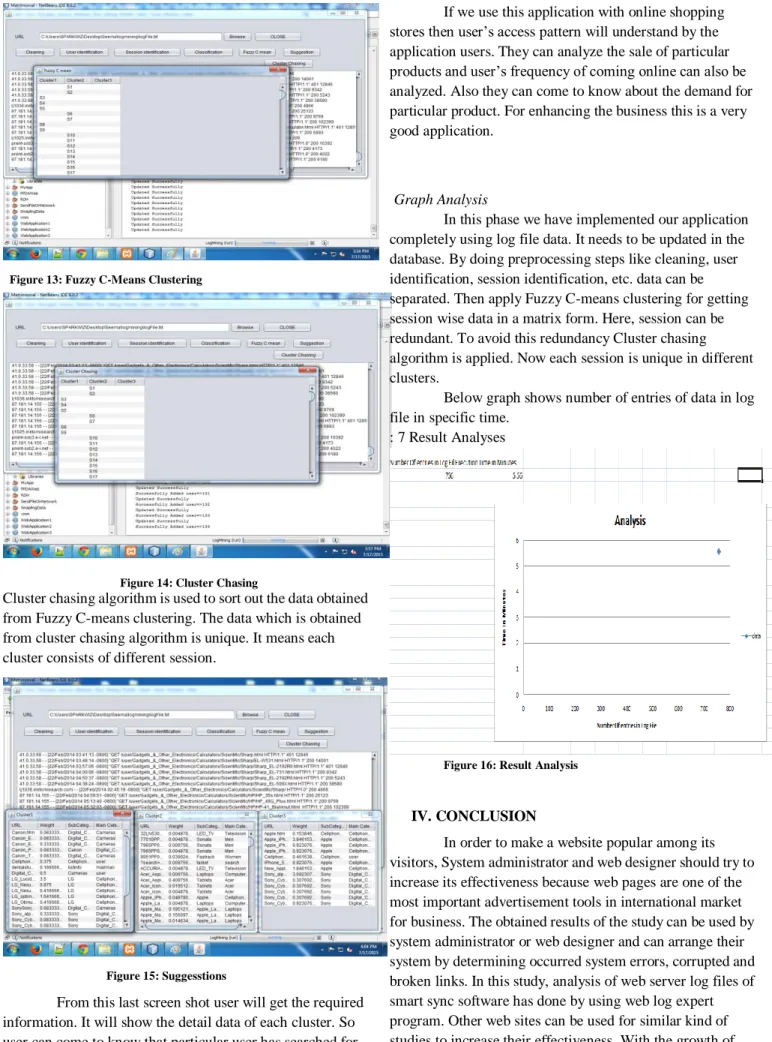
In next screen shot we have shown the screen after applying Fuzzy C-means Clustering. In this clustering it may happen that sessions are repeated in more than one cluster as it is a loose kind of clustering.
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3307 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Figure 13: Fuzzy C-Means Clustering
Figure 14: Cluster Chasing
Cluster chasing algorithm is used to sort out the data obtained from Fuzzy C-means clustering. The data which is obtained from cluster chasing algorithm is unique. It means each cluster consists of different session.
Figure 15: Suggesstions
From this last screen shot user will get the required information. It will show the detail data of each cluster. So user can come to know that particular user has searched for which products.
If we use this application with online shopping stores then user‘s access pattern will understand by the application users. They can analyze the sale of particular products and user‘s frequency of coming online can also be analyzed. Also they can come to know about the demand for particular product. For enhancing the business this is a very good application.
Graph Analysis
In this phase we have implemented our application completely using log file data. It needs to be updated in the database. By doing preprocessing steps like cleaning, user identification, session identification, etc. data can be separated. Then apply Fuzzy C-means clustering for getting session wise data in a matrix form. Here, session can be redundant. To avoid this redundancy Cluster chasing algorithm is applied. Now each session is unique in different clusters.
Below graph shows number of entries of data in log file in specific time.
: 7 Result Analyses
Figure 16: Result Analysis
IV. CONCLUSION
In order to make a website popular among its visitors, System administrator and web designer should try to increase its effectiveness because web pages are one of the most important advertisement tools in international market for business. The obtained results of the study can be used by system administrator or web designer and can arrange their system by determining occurred system errors, corrupted and broken links. In this study, analysis of web server log files of smart sync software has done by using web log expert program. Other web sites can be used for similar kind of studies to increase their effectiveness. With the growth of web-based applications web usage and data mining to find access patterns is a growing area of research. Data mining techniques like association rules, sequential patterns,
International Journal of Science, Engineering and Technology Research (IJSETR), Volume 4, Issue 10, October 2015
3308 ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
clustering and classification can be used to discover frequent patterns.
In this paper we proposed preprocessing of web log data, applying clustering and optimization methods to get similar interest particular user and finally to provide user related suggestion using suffix tree concept. Here web log data is given as input and perform data cleaning to eliminate the irrelevant data items. The cleaned web log is used to pattern discovery and clustering technique is used for discovering useful patterns which will be beneficial for the commercial site owner to improve services and products.
REFERENCES
http://www.anderson.ucla.edu/faculty/jason.frand/teacher/technologie s/palace/ datamining.htm
http://en.wikipedia.org/wiki/Web_mining
Mrs.Bhanu Bhardwaj, ―Extracting Data Through Web mining‖, International Journal of Engineering Research & Technology (IJERT),Vol. 1 Issue 3,2012.
Sonali Muddalwar Shashank Kawar ,―Applying artificial neural network in web usage mining‖, Vol 1 Issue 4, International Journal of Computer Science and Management , 2012.
Anshuman Sharma, ―Web usage mining using neural network‖ International Journal of Reviews in Computing, 2012.
International Journal of Advanced Research in Computer Science and Software Engineering Z, Volume 3, Issue 3, March 2013.
Anna Alphy, S.Prabakaran, ―Cluster Optimization for Improved web Usage Mining ‖ using Ant Nestmate Approach‖,
IEEE-InternationalConference on Recent Trends in Information Technology, June 3-5, 2011.
M. Spiliopoulou, L. C. Faulstich, and K. Winkler. A data miner analyzing the navigational behaviour of web users. In Proc. of the Workshop on Machine Learning in User Modeling of the ACAI'99 Int. Conf., Creta, Greece, July 1999.
M. Perkowitz and O. Etzioni. Adaptive web sites: Automatically synthesizing web pages. In AAAI/IAAI, pages 727{732, 1998.
F. Bonchi, F. Giannotti, C. Gozzi, G. Manco, M. Nanni, D. Pedreschi, C. Renso, and S. Ruggieri. Web log data warehousing and mining for intelligent web caching. Data Knowledge Engineering, 39(2):165-189, 2001.
Osmar R. Zaiane, Man Xin, and Jiawei Han. Discovering web access patterns and trends by applying OLAP and data mining technology on web logs. In Advances in Digital Libraries, pages 19-29, 1998.
Park, Sungjune, Nallan C. Suresh, and Bong-KeunJeong. "Sequence- based clustering for Web usage mining: A new experimental framework and ANN-enhanced K-means algorithm." Data & Knowledge Engineering 65.3 (2008)pp, 512-543.
Zhang, Xuejun, John Edwards, and Jenny Harding. "Personalised online sales using web usage data mining." Computers in Industry 58.8 (2007)pp, 772-782.
Li, Ziang, et al. "An ontology-based Web mining method for unemployment rate prediction." Decision Support Systems 66 (2014) pp,114-122.
Dr.V.Prasanna Venkatesan, ―An Analysis on Performance of Decision Tree Algorithms using Student‘s Qualitative Data‖, I.J.Modern Education and Computer Science, 2013, 5, 18-27 Published Online June 2013 in MECS
D.Lavanya Dr. K.Usha Rani ―Performance Evaluation of Decision Tree Classifiers on Medical Datasets‖, International Journal of Computer Applications (0975 – 8887)Volume 26– No.4, July 2011. Devi Prasad bhukya and S. Ramachandram , ― Decision tree induction- An Approach for data classification using AVL –Tree‖, International journal of computer and electrical engineering, Vol. 2, no. 4, August 2010.
Tarun Verma, Sweety raj,Mohammad Asif khan, Palak modi, ―Literacy Rate Analysis‖, International journal of science & engineering research volume 3, issue 7, ISSN 2229- 5518. 2012. S.Anupama Kumar and Dr. Vijayalakshmi M.N. , ―Efficiency of decision trees in predicting student‟s academic performance‖, D.C. Wyld, et al. (Eds): CCSEA 2011, CS & IT 02, pp. 335-33, 2011.