Optimizing a MapReduce Module of Preprocessing High-Throughput DNA
Sequencing Data
Wei-Chun Chung
#,1,3, Yu-Jung Chang
#,2, Chien-Chih Chen
2, Der-Tsai Lee
2,3,4, Jan-Ming Ho
§,1,21 Research Center for Information Technology Innovation 2 Institute of Information Science
Academia Sinica Taipei, Taiwan, ROC
E-mail: {wcchung, yjchang, rocky, dtlee, hoho}@iis.sinica.edu.tw Abstract—The MapReduce framework has become the de facto
choice for big data analysis in a variety of applications. In MapReduce programming model, computation is distributed to a cluster of computing nodes that runs in parallel. The performance of a MapReduce application is thus affected by system and middleware, characteristics of data, and design and implementation of the algorithms. In this study, we focus on performance optimization of a MapReduce application, i.e., CloudRS, which tackles on the problem of detecting and removing errors in the next-generation sequencing de novo genomic data. We present three strategies, i.e., content-exchange, content-grouping, and index-only strategies, of communication between the Map() and Reduce() functions. The three strategies differ in the way messages are exchanged between the two functions. We also present experimental results to compare performance of the three strategies.
Keywords-error correction; genome assembly; mapreduce; next-generation sequencing; optimization;
I. INTRODUCTION
MapReduce [1] is a prominent distributed computational framework that possesses various key features for dealing with large-scale data processing on the cloud [2-4], including fault-tolerance, scheduling, data replication, load balance, and parallelization. By virtue of the scalability and simplicity on development, MapReduce and its implementations [5-7] have been widely-used in different applications, e.g., Web and social networks analysis, scientific emulation, financial and business data processing, and bioinformatics [8-12]. However, the performance and efficiency of MapReduce are affected by different factors, and thus, become challenging for optimization.
Optimizing MapReduce is essential as processing data in a timely and cost-efficient manner becomes critical [13-18]. Fortunately, various techniques have been introduced to improve the performance of MapReduce [19-25], including hardware, software, and framework level optimization. One of the optimization techniques is tuning parameters for
system, middleware, and MapReduce execution by utilizing expert systems [20-22] or the rule-of-thumb policies [26, 27]. Another type of optimization focuses on the design of algorithm or the characteristics of data of the application [28, 29].
In this study, we focus on CloudRS [9], a MapReduce application for correcting errors in the next-generation sequencing (NGS) data. As the cost of DNA sequencing rapidly reduces [12], the accompanying growth of genome data results in unpredictable execution time, even if the data is processed by MapReduce. Thus, to optimize the performance of CloudRS, we evaluate three kinds of message generation and transmission approaches to reduce the communication cost of MapReduce: content-exchange, content-grouping, and index-only strategies. We also present the experimental results, and discuss the observation and limitation of our proposed strategies.
II. BACKGROUND
A. The MapReduce programming model
The MapReduce programming model is composed of two primitive functions, Map and Reduce. The input data of a MapReduce program is a list of <key, value> pairs, and thus, the Map() function is applied to each pair and generate a set of intermediate pairs, e.g. <key, list(value)>. Then the Reduce() function is applied to each intermediate pair, process values of the list, and produce aggregated final results. Moreover, there are additional functions in the MapReduce execution model, e.g., shuffle and sort, to handle intermediate data. The shuffle function is applied on the Map
side, and performs data exchange by key after Map(). Thus, data with the same key will be transmitted to a single Reduce() function. The sort function is launched on the
Reduce side after data exchange. It sorts data by the key field to group all the pairs with the same key for further processing.
B. The CloudRS algorithm
The CloudRS algorithm [9] is implemented with multiple MapReduce rounds. It aims at conservatively correcting sequence errors to avoid yielding false decisions, and thus, improves the quality of de novo assembly. To correct a possible mismatch, CloudRS emulates read alignment and majority voting for each set of reads, denoted as a read stack, ───────────────────
# These authors contributed equally to this work (co-First authors). 3 Department of Computer Science and Information Engineering, National
Taiwan University, Taipei, Taiwan, ROC.
4 Department of Computer Science and Information Engineering, National Chung Hsing University, Taichung, Taiwan, ROC.
§ Corresponding author
with the same k-mer subsequence. Note that a k-mer
subsequence refers to a genomic subsequence of k base pairs of either guanine-cytosine or adenine-thymine. Once the reads are aligned and the read stack has been built, majority voting can be applied on each position of the read stack to summarize the quality value of each base. Then, a decision is made on each position to correct error if necessary.
III. METHODS
The basic idea of error detection and correction is to align reads having the same specific subsequence of length k and sort them according to the relative position of the subsequence in the read. A voting algorithm is then used to examine the symbols and quality values at each position of the stack of reads to detect and correct sequencing errors if the reads and their quality values show high level of consistency at each position. Interested readers may refer to [9] and [30] for details. In this section, we are going to present three strategies, i.e., content-exchange strategy, content-grouping strategy, and index-only strategy, to collect reads with the same specific subsequence of length k in the error correction algorithm based on the MapReduce framework. Note that each strategy consists of a pair of Map() and Reduce() functions. The Map() function scans through a read for the k-mer subsequences it contains and emits the <k-mer, read> pairs. The shuffle stage of MapReduce then aggregates reads with the same k-mer
subsequence for further processing by a Reduce() function later. The Reduce() function thus performs the align/sort/voting algorithm to identify and recommend sequencing errors containing in the reads it receives. Details of these strategies are presented as follows.
A. Content-exchange strategy
For each read r of length l, the Map() function of the content-exchange strategy generates a message of the form <k-meri, (identifier, sequence, quality value)> at each
position i of r, where 1 ≤ i ≤ l-k+1, sequence and quality value are vectors of length l representing the DNA sequence and quality value of r given by the sequencer, and k-meri is
the subsequence of r of length k starting at position i.
B. Content-grouping strategy
In this subsection, we present a content-grouping strategy in which the Map() function groups messages destined for the same Reduce() function and thus reduces the total size of messages transmitted during the shuffle stage. That is, the key-value pair is defined as <group key, (list(identity key), identifier, sequence, quality value)>. In other words, we divide the original key into two parts, the group key and the
identity key. Messages with the same group key are sent to the same instance of Reduce() function which first sorts the reads it receives according to their identity keys, then performs align/sort/voting algorithm to detect and recommend sequencing errors in the subset of reads with the same identity key.
C. Index-only strategy
In the third strategy, we aim at reducing communication overhead further by using the distributed cache mechanism of Hadoop. The input data file containing sequence data and quality value of each read is replicated to each computing node of the cluster before executing the Map() function. So that the Map() function does not have to duplicate read data including sequence data and quality value for each message generated with each k-mer subsequence. Instead, it generates messages in key-value pairs containing only the k-mer
subsequence and the read identifier which will be used later by the Reduce() function to retrieve read data from its local file cache. Each message generated by the Map() function is formatted as <group key, (list(identity key), identifier)>. Thus, the communication cost in terms of total message size is reduced at the cost of I/O overhead of retrieving read data from the local file cache.
D. Qualitative comparison of the three strategies
To evaluate the effectiveness of proposed methods, we estimate the intermediate data size and its reducing rate by calculation. The input dataset consists of a set of reads; each read is composed of read id, DNA sequence, and a quality-value character for each DNA. For a dataset with r reads and each read’s sequence composed of l characters, the quality values of a read is also length l. Let the size of a sliding window on reads’ sequences be k, there will be r*(l-k+1) k-mer substrings, abbreviated as k-mers in the following, to be processed (denoted as t) as the input of mappers.
We also define the grouping rate of the k-mers (denoted as n) to evaluate the performance of grouping mechanism. Hence, we can approximately estimate the amount of key groups and the number of k-mers in each group. For convenience, we give related notations as that (a) the length of read id is a fixed size i, (b) the length of group key is p
and identity key is k-p, where 1 ≤p≤k (see content-grouping strategy in Methods for definitions), (c) the grouping rate is a normal distribution, thus0 < n ≤ 1, and there are n*t k-mer
groups and 1/nk-mers in each group.
The estimated sizes of intermediate data for the three strategies are as follows. For the content-exchanging strategy, the intermediate data size is at least t*(k+i+2l)
bytes, since a key-value pair of a k-mer passing to reducers has to carry itself and the id, sequence and quality values of its read with size k+i+2l. The content-grouping strategy produce (nt)*(p+1/n*(k-p)+i+2l) bytes intermediate data, because a message contains a grouping key, a list of identity keys, the id, sequence and quality values of its read. The size of identity key list is 1/n*(k-p), since there are 1/nk-mers in each group and the length of each identity key is k-p. The index-only strategy generates (nt)*(p+1/n*(k-p)+i) bytes, since the key-value pair contains only the id. Table I summarizes the intermediate data size and the complexity of storage space of our proposed strategies.
IV. EXPERIMENTAL RESULTS
A. Environment setup and datasets
Our experiments are evaluated in a Hadoop cluster with 10 dedicated computing nodes and an isolated internal network. Each node has 2 quad-core Intel Xeon E5410 CPUs, 16 GB memory, 1 TB local storage, and 1 Gb network connection. We use Ubuntu Linux 8.04 and Hadoop version 0.20.203 for our experimental environment. We also set up at most 7 map tasks and 7 reduce tasks execute concurrently for each node. Thus, there are at most 70 map tasks and 70 reduce tasks in a MapReduce wave. The detail configuration of job parameters lists in Appendix Table A1. In addition, to separate the control flow and computation flow of the Hadoop framework, we add an additional control node into our cluster. We also define roles for the 11 nodes: one control node roles as Name Node and Job Tracker, while 10 computing nodes act as Data Nodes and Task Trackers.
We use three real datasets to evaluate the performance of CloudRS. Information of datasets is listed in Table II. The dataset D1 is a set of short read data from an Escherichia coli
(E. coli) library (SRX000429), which consists of 20.8M 36-bp reads. The dataset D2 is released by Illumina, which includes 12M paired-end 150-bp reads. This dataset contains sequences from a well-characterized E. coli strain K-12 MG1655 library sequenced on the Illumina MiSeq platform. The dataset D3 is Illumina reads from an African Male
(NA18507).
Note that we set up the size of k-mer as 24 characters in our experiments. Parameter settings of evaluations are bundled within the physical computation limitations, i.e., 8 cores and 16 GB memory of each computing node.
B. Evaluation Results
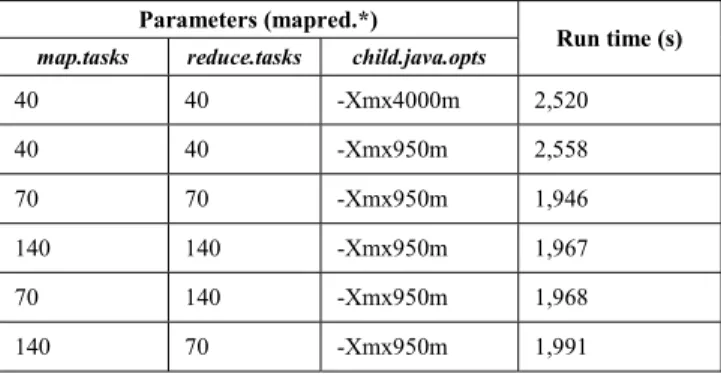
We use dataset D1 to demonstrate the effect of parameters affect to a MapReduce program by evaluating the content-exchange strategy. As shown in Table III, the execution time is reduced near 23%, comparing to the first and the third row. We observed that the execution time in the second row is longer than the first row. We also observed that multiple mapper/reducer waves also increases total execution time, as shown in the last 3 rows. The parameter settings of 70 mappers, 70 reducers and 950 MB memory achieves the shortest execution time in our experiment. Thus, we use the setting and the parameters list in Appendix Table A1 for the rest of the evaluations.
To demonstrate the efficiency of the content-grouping strategy, we evaluate the strategy with dataset D2 and various partitions of keys. As shown in Table IV, the intermediate data size and execution time decrease with the grouping mechanism. We also evaluate the performance comparing to the content-exchange strategy by setting up the key partition as 24:0. However, we encounter an error during execution since we set the key partition is 6:18 and below.
For index-only strategy, we use dataset D2 and D3, and use 12:12 as the key partition. The result lists in Table V. In dataset D2, the execution time has a reduction about 37% with index-only strategy, comparing to the content-grouping one. However, we encounter an unexpected longer execution with dataset D3.
V. DISCUSSIONS
A. A brief summary on the three strategies
The three versions of error correction algorithms basically consider a read as an object and consider each k-mer subsequence of the read as a feature of the read. In the content-exchange strategy, the Map() functions generate a message, for each feature of each object, containing the feature as well as the object. The shuffle stage then collects objects with the same feature for further processing by an instance of Reduce() function. The content-grouping strategy defines features with the same prefix as belonging to the same feature group. The Map() functions generates a message for each feature group of each object. The shuffle
stage thus collects objects belonging to the same feature group to an instance of Reduce() function for further processing. Note that total size of messages generated by the content-grouping strategy is smaller than that generated by the content-exchange strategy. However, the Reduce() function of the content-grouping strategy may suffer an exception of JAVA due to insufficient amount of physical memory, and thus, terminate the execution. The index-only strategy incorporates the grouping mechanism, and thus, to reduce the message size. The index-only strategy is thus the least time-consuming among the three. Unfortunately, though the strategy works well with small dataset, it failed when the input data is large.
B. Overhead of index-only strategy
The index-only strategy utilizes the grouping mechanism and distributed cache to successfully reduce the size of data transmitted by the Map() function, and thus, also reduce communication cost in the shuffle stage. However, since the data, i.e., sequence and quality value, is read from the local cache, performance bottleneck shifts to disk I/O among the Reduce() function. The overhead increases rapidly as the size of input data becomes large. This is mainly due to the fact that reads with the same key, the k-mer, usually scatters in the local cache. Furthermore, there are multiple tasks running concurrently on a single computing node. The lack of cache hit results in a high page-fault rate, especially when physical memory is exhausted by the running tasks. This phenomenon is known as thrashing. When it occurs, the execution time of the application may run indefinitely. TABLE I. APPROXIMATED INTERMEDIATE DATA SIZE PRODUCED BY
PROPOSED STRATEGIES.
Proposed strategies
Approximated intermediate data size (bytes)
Complexity of storage spaces
Content-exchange t*(k+i+2l) O(rl2)
Content-grouping (nt)*(p+1/n*(k-p)+i+2l) O(nrl2)
VI. CONCLUSION
In this era of big data, it is critical to process a large amount of data timely and efficiently. MapReduce is one of the prominent solutions to this end. It provides scalability and fault-tolerance for big data applications. However, the share-nothing nature of MapReduce also elicits researches that study applications with high degree of data dependency. An error detection and correction algorithm based on processing reads with the same k-mer subsequence is an application with high degree of data dependency, especially when it is applied to a large genome.
In this paper, we present three strategies to handle data communication between the Map() and Reduce() functions of the MapReduce framework in a bioinformatics application that detects and corrects sequencing errors in the NGS data. Note that the NGS data consists of fixed-length reads, each being associated with sequence and quality value. The first strategy replicates the read data of each k-mer subsequence, and transmits the entire set of data from Map() to Reduce(). The second strategy groups the k-mer subsequences of a read by their prefix, and thus, transmits fewer amounts of data through the network. The third strategy, i.e., index-only strategy, pre-caches the read data directly on each node, and transmits only the indices of reads as messages. The index-only strategy has been shown to be most efficient for small genomes. However, for large genomes, our current implementation may suffer the thrashing problem.
Our future research will focus on improving the performance of the index-only strategy. We will also look into other problems with similar nature, e.g., de novo
assembly, and develop applications based on the MapReduce framework.
ACKNOWLEDGMENT
The authors wish to thank anonymous reviewers for their helpful suggestions, and thank Dr. Wen-Liang Hsu and Dr. Chung-Yen Lin for their valuable discussions and comments. They also wish to thank Chunghwa Telecom Co. and National Communication Project of Taiwan for providing the cloud computing resources. The research is partially supported by Digital Culture Center, Academia Sinica, and National Science Council under grant NSC 102-2221-E-001-013-MY3.
TABLE II. LIST OF DATASETS OF EVALUATING OUR PORPOSED STRATEGIES.
Dataset SRA accession number Reference genome
NCBI reference sequence accession number Genome length (MB) Read length Number of reads (M) Genome coverage Data size (GB) D1 SRX000429 E. coli NC_000913 ~4.64 36 bp ~20.8 161x ~1.59 D2 - E. coli NC_000913 ~4.64 150 bp ~12.1 388x ~3.50
D3 SRA000271 African Male (NA18507) - ~3000 36 bp ~218.0 2.6x ~17.3
TABLE III. RESULTS OF DIFFERENT PARAMETER SETTINGS WITH CONTENT-EXCHANGE STRATEGY ON DATASET D1.
Parameters (mapred.*)
Run time (s) map.tasks reduce.tasks child.java.opts
40 40 -Xmx4000m 2,520 40 40 -Xmx950m 2,558 70 70 -Xmx950m 1,946 140 140 -Xmx950m 1,967 70 140 -Xmx950m 1,968 140 70 -Xmx950m 1,991
TABLE IV. RESULTS OF CONTENT-GROUPING STRATEGY ON DATASET
D2.
Partition of keys (group:identity)
Intermediate data
size (bytes) b Run time (s)
24:0 a 393,610,577,668 22,738 20:4 393,596,531,558 22,454 12:12 393,439,082,022 21,949 8:16 391,616,362,031 21,396 6:18 379,682,068,879 GC overhead exceeded 3:21 160,805,782,820 GC overhead exceeded
a Content-grouping method with key partition of 24:0 is same as content-exchange method. b The input data size is 3,062,609,572 bytes.
TABLE V. RESULTS OF INDEX-ONLY METHOD ON DATASET D2 AND
D3.
Dataset Method a Run time (s)
D2 Content-grouping 21,728
Index-only 13,691
D3 Content-grouping 16,345
Index-only > 8 hr
REFERENCES
[1] J. Dean and S. Ghemawat, "MapReduce: simplified data processing on large clusters," Commun. ACM, vol. 51, pp. 107-113, 2008. [2] Amazon. Amazon Elastic Compute Cloud (Amazon EC2). Available:
http://aws.amazon.com/ec2/
[3] Amazon. Amazon Simple Storage Service (Amazon S3). Available:
http://aws.amazon.com/s3/
[4] Amazon. Amazon Elastic MapReduce (Amazon EMR). Available:
http://aws.amazon.com/elasticmapreduce/
[5] Apache. Welcome to ApacheΤΜ Hadoop®! Available:
http://hadoop.apache.org/
[6] Nokia. Disco MapReduce. Available: http://discoproject.org/
[7] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly, "Dryad: distributed data-parallel programs from sequential building blocks," presented at the Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, Lisbon, Portugal, 2007.
[8] Y.-J. Chang, C.-C. Chen, C.-L. Chen, and J.-M. Ho, "A de novo next generation genomic sequence assembler based on string graph and MapReduce cloud computing framework," BMC Genomics, vol. 13, pp. 1-17, 2012.
[9] C.-C. Chen, Y.-J. Chang, W.-C. Chung, D.-T. Lee, and J.-M. Ho, "CloudRS: An Error Correction Algorithm of High-Throughput Sequencing Data based on Scalable Framework," in IEEE International Conference on Big Data, In press.
[10] B. Langmead, K. D. Hansen, and J. T. Leek, "Cloud-scale RNA-sequencing differential expression analysis with Myrna," Genome Biol, vol. 11, p. R83, 2010.
[11] M. C. Schatz, "CloudBurst: highly sensitive read mapping with MapReduce," Bioinformatics, vol. 25, pp. 1363-9, Jun 1 2009. [12] L. D. Stein, "The case for cloud computing in genome informatics,"
Genome Biol, vol. 11, p. 207, 2010.
[13] E. Anderson and J. Tucek, "Efficiency matters!," SIGOPS Oper. Syst. Rev., vol. 44, pp. 40-45, 2010.
[14] J. Cohen, B. Dolan, M. Dunlap, J. M. Hellerstein, and C. Welton, "MAD skills: new analysis practices for big data," Proc. VLDB Endow., vol. 2, pp. 1481-1492, 2009.
[15] D. J. DeWitt and M. Stonebraker. (2008). MapReduce: A major step backwards. Available: http://databasecolumn.vertica.com/database-innovation/mapreduce-a-major-step-backwards/
[16] B. Irving. Big data and the power of hadoop.
[17] A. Pavlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, S. Madden, et al., "A comparison of approaches to large-scale data analysis," presented at the Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, Providence, Rhode Island, USA, 2009.
[18] M. Schroepfer. Inside large-scale analytics at facebook.
[19] J. Ekanayake, H. Li, B. Zhang, T. Gunarathne, S.-H. Bae, J. Qiu, et al., "Twister: a runtime for iterative MapReduce," presented at the Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, Illinois, 2010. [20] W. Guanying, A. R. Butt, P. Pandey, and K. Gupta, "A simulation
approach to evaluating design decisions in MapReduce setups," in Modeling, Analysis & Simulation of Computer and Telecommunication Systems, 2009. MASCOTS '09. IEEE International Symposium on, 2009, pp. 1-11.
[21] H. Herodotou, H. Lim, G. Luo, N. Borisov, L. Dong, F. B. Cetin, et al., "Starfish: A Self-tuning System for Big Data Analytics," In
Proceedings of the 5th Conference on Innovative Data Systems Research, 2011.
[22] E. Jahani, M. J. Cafarella, C. R, and #233, "Automatic optimization for MapReduce programs," Proc. VLDB Endow., vol. 4, pp. 385-396, 2011.
[23] S. Lattanzi, B. Moseley, S. Suri, and S. Vassilvitskii, "Filtering: a method for solving graph problems in MapReduce," presented at the Proceedings of the 23rd ACM symposium on Parallelism in algorithms and architectures, San Jose, California, USA, 2011. [24] K.-H. Lee, Y.-J. Lee, H. Choi, Y. D. Chung, and B. Moon, "Parallel
data processing with MapReduce: a survey," SIGMOD Rec., vol. 40, pp. 11-20, 2012.
[25] C. Ranger, R. Raghuraman, A. Penmetsa, G. Bradski, and C. Kozyrakis, "Evaluating MapReduce for Multi-core and Multiprocessor Systems," presented at the Proceedings of the 2007 IEEE 13th International Symposium on High Performance Computer Architecture, 2007.
[26] Cloudera. Optimizing MapReduce Job Performance. Available:
http://www.slideshare.net/cloudera/mr-perf
[27] T. White, Hadoop: The Definitive Guide: O'Reilly Media, 2009. [28] J. Lin and C. Dyer, Data-Intensive Text Processing with MapReduce:
Morgan and Claypool Publishers, 2010.
[29] J. D. Ullman, "Designing good MapReduce algorithms," XRDS, vol. 19, pp. 30-34, 2012.
[30] S. Gnerre, I. MacCallum, D. Przybylski, F. J. Ribeiro, J. N. Burton, B. J. Walker, et al., "High-quality draft assemblies of mammalian genomes from massively parallel sequence data," Proceedings of the National Academy of Sciences, 2010.
APPENDIX
A. Rules-of-thumb policy for configurations
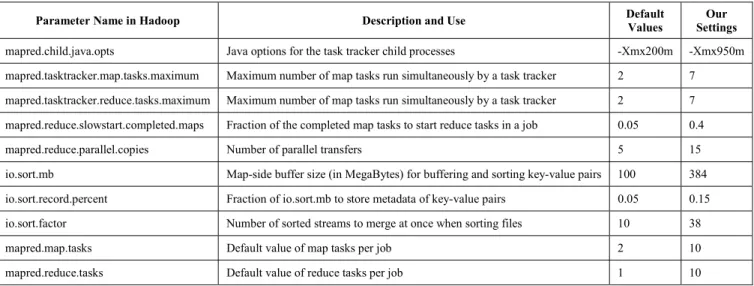
Table A1 lists our Hadoop configuration parameters depends on the rules-of-thumb policy that aims at ensuring the values are not exceed the physical limitation of each computing node. Assume that we have 10 computing nodes and each node has 8 CPU cores, 16 GB memory, and acts as Data Node and Task Tracker. We demonstrate the calculation of the first three parameter values of Hadoop framework in Table A1. To achieve the best-effort of CPU utilization, there would be assign 2 processes to utilize for each CPU core, in general. Thus, there are 16 processes execute simultaneously in a node. However, to obtain the functionality of underlying operating system, we prepare one CPU core for system routine process and I/O operations. Thus, there are at most 7 CPU cores for Hadoop framework, and we decide to set up at most 7 map tasks and 7 reduce tasks concurrently. Since in-memory processing is faster than performing operation with swap space or content switching, we optimism the memory usage of each node is within its physical boundary. Furthermore, we preserved around 500 MB for processes of operating system, 1 GB for operations of Data Node, and 1 GB for Task Tracker. To utilize the rest 13 GB memory with at most 14 tasks concurrently, we can assign 950 MB memory for each task.
TABLEA1. A SUBSET OF JOB CONFIGURATION PARAMETERS OF HADOOP THAT AFFECT JOB PERFORMANCE SIGNIFICANTLY.
Parameter Name in Hadoop Description and Use Default Values Settings Our
mapred.child.java.opts Java options for the task tracker child processes -Xmx200m -Xmx950m mapred.tasktracker.map.tasks.maximum Maximum number of map tasks run simultaneously by a task tracker 2 7 mapred.tasktracker.reduce.tasks.maximum Maximum number of map tasks run simultaneously by a task tracker 2 7 mapred.reduce.slowstart.completed.maps Fraction of the completed map tasks to start reduce tasks in a job 0.05 0.4
mapred.reduce.parallel.copies Number of parallel transfers 5 15
io.sort.mb Map-side buffer size (in MegaBytes) for buffering and sorting key-value pairs 100 384 io.sort.record.percent Fraction of io.sort.mb to store metadata of key-value pairs 0.05 0.15 io.sort.factor Number of sorted streams to merge at once when sorting files 10 38
mapred.map.tasks Default value of map tasks per job 2 10