Hardware Acceleration of Network
Intrusion Detection and Prevention
by
Brendan Cronin, B.E., M.Eng.
A thesis submitted in partial fulfilment of the requirements for the Degree of Doctor of Philosophy
(Electronic Engineering)
Supervised by Dr. Xiaojun Wang
Dublin City University School of Electronic Engineering
Declaration
I hereby certify that this material, which I now submit for assessment on the programme of study leading to the award of Doctor of Philosophy is entirely my own work, that I have exercised reasonable care to ensure that the work is original, and does not to the best of my knowledge breach any law of copyright, and has not been taken from the work of others save and to the extent that such work has been cited and acknowledged within the text of my work.
Signed:
ID number:
Acknowledgements
I would like to thank my supervisor Dr. Xiaojun Wang for his excellent guidance, advice and encouragement throughout my time in Dublin City University. I am also grateful to all my colleagues in the Network Processing Group for their support and help, in particular Yachao and Xiaofei. Thanks also to Dr. Olga Ormond, Research Officer with the Network Innovations Centre, for her assistance with my work.
I delivered the taught postgraduate module HDL and High Level Logic Synthesis in 2010 and 2011 under the supervision of the module coordinator, Dr. Wang. I would like to thank Dr. Wang, and Dr. Noel Murphy, head of the School of Electronic Engineering at the time, for giving me this opportunity. Teaching this module gave me a more in depth knowledge of VHDL, Verilog and FPGA design which helped me greatly in the development of prototype designs for evaluation of my research.
I would like to dedicate this thesis to my late parents, Teresa and Patrick, who actively encouraged my learning and education from an early age. I must include special mention for my godfather and uncle, Denis, who has always been a great support throughout my time in school and university.
Finally, these last four years of study would have been very difficult without the love, patience and support of Ilaria.
Table of Contents
Declaration ... i
Acknowledgements ... ii
Table of Contents ... iii
List of Figures ... ix
List of Tables ... xii
List of Acronyms and Abbreviations ... xiv
Abstract ... xix
List of Publications ... xx
Chapter 1 - Introduction ... 1
1.1. Background ... 1
1.1.1. Growth of the Internet ... 1
1.1.2. Energy Consumption ... 1
1.1.3. Internet Security ... 1
1.2. Motivation ... 3
1.3. Intrusion Detection and Prevention ... 3
1.3.1. Classification ... 3
1.3.2. Detection Methods ... 4
1.3.3. Modes ... 4
1.3.4. NIDS Sensor Location ... 5
1.3.5. NIPS Sensor Location ... 6
1.4. Research Goals ... 7
1.5. Contributions ... 9
Chapter 2 - Background ... 12
2.1. Automata Theory ... 12
2.1.1. Formal Languages ... 12
2.1.2. Regular Languages ... 14
2.1.3. Perl Compatible Regular Expressions ... 18
2.1.4. Construction of NFA from regex ... 21
2.1.5. NFA to DFA conversion ... 24
2.1.6. Trie ... 25
2.2. Network Intrusion Detection and Prevention Systems ... 26
2.2.1. Snort ... 26 2.2.2. Snort Rules ... 26 2.2.3. Suricata ... 28 2.2.4. Bro ... 28 2.2.5. Market Trends ... 29 2.3. Platforms ... 30 2.3.1. Commodity Hardware ... 30 2.3.2. Custom Hardware... 30 2.4. Summary ... 32
Chapter 3 - TCP/IP Reassembly ... 34
3.1. Theory of IP Fragmentation and TCP Segmentation ... 35
3.1.1. TCP Connections ... 35
3.1.2. The need for IP fragmentation ... 38
3.1.3. Path MTU Discovery ... 39
3.1.4. IP Reassembly ... 40
3.2. Handling of Reassembly in different Operating Systems ... 41
3.2.1. Simple Insertion and Evasion Attacks ... 41
3.2.2. Creation of connection session... 43
3.2.3. TCP Stream Reassembly – Connection Window... 43
3.2.4. Overlapping Fragments or Segments ... 44
3.2.5. TCP Stream – RST Validity Check ... 45
3.2.6. TCP Stream – Timestamp Validity Check ... 46
3.2.7. TCP Stream – Handling of repeated SYN segment ... 46
3.3. Target-based Reassembly and Normalisation ... 47
3.4. TCP/IP Reassembly in Software ... 48
3.4.1. Snort ... 48
3.4.2. OISF Suricata ... 51
3.5. TCP/IP Reassembly in Hardware... 53
3.5.1. TCP Processing Engine ... 55
3.5.2. Non-TCP Processing Engine... 62
3.5.3. Software on CPU ... 63
3.5.6. Evaluation and comparison with related work ... 64
3.6. Conclusion and Future Work ... 66
Chapter 4 - Multi-match Header Classification ... 68
4.1. Characteristics of NIDS Rule Sets ... 68
4.2. Proposed Architecture ... 70
4.2.1. Pre-processing ... 70
4.2.2. Top-level Architecture ... 71
4.3. Algorithms ... 71
4.3.2. Hypercuts ... 72
4.3.3. EGT-PC ... 72
4.3.4. ART (Allotment Routing Table) ... 81
4.4. Related Work ... 84
4.4.1. Bit Vector – TCAM architecture... 84
4.4.2. Field-Split parallel Bit Vector architecture ... 87
4.5. Comparison ... 89
4.6. Conclusion ... 90
Chapter 5 - Pattern Matching Methods ... 91
5.1. Fixed String Matching ... 91
5.1.1. Precise Matching ... 91
5.1.2. Imprecise Matching (with false positives) ... 94
5.2. Regular Expression Matching ... 95
5.2.1. DFA-based solutions ... 95
5.2.2. NFA-based solutions ... 98
5.2.3. Imprecise Matching Finite Automata ... 101
5.2.4. Alphabet Reduction ... 103
5.2.5. Multi-stride Automata ... 104
5.2.6. Commodity versus Speciality Hardware ... 104
5.3. Conclusion ... 105
Chapter 6 - Constrained Repetitions in Regular Expressions ... 107
6.1. Constrained Repetitions in Snort Rule Set ... 107
6.2. Bit-Parallel (BP) Architectures ... 108
6.3. Glushkov NFA ... 109
6.5. Bit Parallelism ... 115
6.5.1. Standard G-NFA ... 115
6.5.2. Counting G-NFA ... 122
6.5.3. Counting G-NFA for single symbol elements ... 125
6.6. Implementation ... 125
6.6.1. Hardware Architecture ... 125
6.6.2. Bitmask Generation Software ... 132
6.7. Performance Results... 135
6.7.1. Synthesis and simulation ... 135
6.7.2. Memory requirements ... 137
6.7.3. Memory and power savings ... 137
6.7.4. Extending to multiple counting blocks ... 138
6.8. Related Work ... 138
6.9. Conclusion ... 144
Chapter 7 - Pattern Overlap in case of Constrained Repetitions ... 146
7.1. Counting Overlap Issue ... 146
7.2. Counting GlushKov NFA with Overlap Handling... 149
7.3. Implementation ... 154 7.3.1. Hardware Architecture ... 154 7.3.2. Software ... 157 7.4. Performance Results... 157 7.5. Related Work ... 159 7.6. Conclusion ... 160
Chapter 8 - Conclusions and Further Work ... 161
8.1.2. Multi-match Packet Header Classification ... 162
8.1.3. Regular Expression DPI ... 162
8.2. Future Directions ... 163
8.2.1. Improving Performance ... 163
8.2.2. Fixed String Pre-Filter ... 164
8.2.3. Improving Power Efficiency ... 164
8.2.4. Mobile Internet DPI ... 165
List of Figures
Figure 1. Possible locations for NIDS in enterprise network ... 5
Figure 2. Example of NIPS placement in enterprise network ... 7
Figure 3. Example NIDPS Architecture... 8
Figure 4. NFA equivalent to example regular grammar ... 16
Figure 5. Example of right-linear grammar and corresponding automaton ... 18
Figure 6. Equivalent left-linear grammar and corresponding automaton ... 18
Figure 7. Thompson Construction – glueing together automata ... 22
Figure 8. Thompson NFA for regex (a|b)*ca ... 22
Figure 9. Marked Glushkov NFA for RE=(a1|b2)*c3a4 ... 24
Figure 10. NFA to DFA conversion of (a|b)*ca using Subset Construction ... 25
Figure 11. Trie for set of strings P={bale, ball, bark} ... 26
Figure 12. Snort rule syntax (only some rule options are shown) ... 27
Figure 13. Hybrid software-hardware processing ... 35
Figure 14. TCP Header ... 35
Figure 15. TCP 3-way handshake ... 36
Figure 16. TCP data segment transmission ... 37
Figure 17: Example of IP packet fragmentation ... 39
Figure 18: Example of insertion attack ... 42
Figure 19. TCP Segment overlap ... 45
Figure 20: SNORT Architecture ... 48
Figure 21: Snort TCP reassembly flowchart ... 50
Figure 22: Suricata TCP reassembly flowchart (non-inline mode) ... 52
Figure 23. TCP/IP reassembly and DPI architecture on Xilinx FPGA ... 54
Figure 24. TCP Processing Engine ... 56
Figure 25. External memory packet buffers ... 56
Figure 26. TCP Connection Record ... 57
Figure 28. Reassembly flow chart ... 61
Figure 29. Non-TCP Fragment Tracker Record ... 63
Figure 30: Overall proposed NIDS Scheme... 70
Figure 31. Example basic Grid-of-Tries ... 74
Figure 32. Example basic Grid-of-Tries with backtracking... 75
Figure 33. Example basic Grid-of-Tries with Switch pointers ... 76
Figure 34. Example EGT using jump pointers... 77
Figure 35: Example EGT with path compression ... 78
Figure 36. Alternative EGT-PC implementation ... 79
Figure 37: EGT-PC Multi-match Architecture ... 79
Figure 38. Source IP address & port number trie for example rule set ... 81
Figure 39. All 3-bit prefixes mapped into complete binary tree ... 82
Figure 40. Multi-level ART for example rule set ... 83
Figure 41. Multi-match architecture using ART ... 84
Figure 42. Overall BV-TCAM architecture ... 85
Figure 43. Tree bitmap for example rule set ... 87
Figure 44. Multi-match using FSBV algorithm ... 87
Figure 45. FSBV scheme for example rule set ... 88
Figure 46. Aho-Corasick – automaton for set of patterns P={lrle, le, rk} ... 92
Figure 47. Example boolean function and corresponding OBDD ... 99
Figure 48. Example StriDFA for patterns “reference” & “replacement” with tag ‘e’102 Figure 49. Example of construction of abstracted DFA by state removal ... 103
Figure 50: The G-NFA for RE = ((ABA|C)B*)A ... 109
Figure 51: G-NFA for marked sub-pattern ... 110
Figure 52. FirstBlk states for example Counting G-NFA ... 112
Figure 53. FinalBlk and IncrementBlk states in example Counting G-NFA ... 113
Figure 54. Counting G-NFA for regex /((ABA|CB)B*){min,max}A/ ... 114
Figure 56. High level view of BP G-NFA algorithm ... 121
Figure 57. High level view of BP Counting G-NFA algorithm ... 124
Figure 58. High level view of Counting G-NFA for single symbol repetition ... 125
Figure 59: Proposed overall IDS architecture on NetFPGA platform ... 127
Figure 60: Regex DPI Handling Module hardware architecture ... 128
Figure 61: Payload Buffer scheme used in evaluation ... 129
Figure 62: Outline of Regex Processing Engine (PE) ... 131
Figure 63: Counting Block Mechanism for regex with up to n-1 symbols ... 132
Figure 64: Power Consumption as a function of throughput ... 137
Figure 65. Distribution of Snort regexes based on no. of constrained repetitions ... 138
Figure 66. CES tile mesh for example regex ... 140
Figure 67. CCR Interconnections ... 140
Figure 68. DPICO block diagram ... 142
Figure 69. Counting G-NFA for single symbol repetition elements ... 152
Figure 70: Regex Engine Architecture ... 155
List of Tables
Table 1. Chomsky Hierarchy ... 14
Table 2. State Transition Table for example regular grammar ... 16
Table 3. Regex operator precedence ... 17
Table 4. Important PCRE Syntax and Semantics... 20
Table 5. Snort regex anchors ... 21
Table 6. Reassembly Policies – segment data favoured when overlap occurs ... 44
Table 7: Target-based checking of RST segment ... 46
Table 8: Example Snort rule ... 68
Table 9: Statistical information for Snort 2.8 rule set (January 2010) ... 69
Table 10: Example Rule Set ... 73
Table 11. Example rule set with port ranges ... 80
Table 12. Example rule set with port prefixes ... 80
Table 13. Simple example rule list ... 83
Table 14. Example rule set ... 85
Table 15. Example rule set for 4-bit field ... 88
Table 16: Comparison of Algorithms ... 89
Table 17: Snort Rule Set Statistics ... 108
Table 18: Constrained repetition quantifier syntax ... 108
Table 19: Snort Constrained Repetition Statistics (v2.9.3.1, 18.09.2012 snapshot) .. 108
Table 20. Values of Follow' for each state x of example Counting G-NFA ... 112
Table 21. Mapping between DFA state bitmask and equivalent NFA states... 116
Table 22. Follow Table indexed by NFA state index for RE= ((A1B2A3|C4)B5*)A6 116 Table 23. FOLLOW_ACTIVE indexed by Active bitmask ... 118
Table 24. Horz. partitioning by 2 of FOLLOW_ACTIVE ... 118
Table 26. Input string ABABBA with RE=((ABA|C)B*)A (no anchor) ... 122
Table 27. Rewriting of constrained quantifiers ... 132
Table 28. ENTER and FOLLOW tables as generated by modified CCP software ... 134
Table 29. FOLLOW_ACTIVE tables ... 134
Table 30: Virtex5 TX240T Device Utilisation ... 136
Table 31: Virtex7 1140T Device Utilisation ... 136
Table 32: Comparison of dynamic memory-based hardware architectures ... 144
Table 33: Counter Overlap in case of regex /ab[abc]{3}d/ ... 147
Table 34. Handling counter overlap with multiple counter instances ... 147
Table 35. Handling counter overlap with differential counters ... 148
Table 36: Bit serial FIFO to track overlap in case of regex /ab[abc]{3}d/ ... 150
Table 37: Virtex5 TX240T Device Utilisation ... 158
List of Acronyms and Abbreviations
AMBA ─ Advanced Microcontroller Bus ArchitectureAPI ─ Application Programming Interface ART ─ Allotment Routing Table
ASIC ─ Application Specific Integrated Circuit AXI ─ Advanced eXtensible Interface
BDD ─ Binary Decision Diagram
BP ─ Bit Parallel
BRAM ─ Block RAM
BSD ─ Berkeley Software Distribution
BV ─ Bit Vector
CAM ─ Content Addressable Memory
CCP ─ Champarnaud - Coulon – Paranthoën CCR ─ Character class with Constraint Repetition CD2FA ─ Content Addressed Delayed Input DFA
CES ─ CCR regExp Scanner
CPU ─ Central Processing Unit
CX-NFA ─ CAM-based eXtended NFA
DCE/RPC ─ Distributed Computing Environment / Remote Procedure Calls
DDR ─ Double Data Rate
DF ─ Don’t Fragment
DFA ─ Deterministic Finite Automaton
DoS ─ Denial of Service DPI ─ Deep Packet Inspection
DPICO ─ DPI COmpact
DRAM ─ Dynamic Random Access Memory
D2FA ─ Delayed Input DFA
EGT-PC ─ Extended Grid-of-Tries with Path Compression
ET ─ Emerging Threats
FA ─ Finite Automaton
FIFO ─ First In First Out
FPGA ─ Field Programmable Gate Array FSBV ─ Field-Split parallel Bit Vector FSM ─ Finite State Machine
Gb/s ─ Gigabits per second GB/s ─ Gigabytes per second GPU ─ Graphics Processing Unit
GW ─ Gigawatt
G-NFA ─ Glushkov NFA
HIDS ─ Host-based Intrusion Detection System HIPS ─ Host-based Intrusion Prevention System HTTP ─ HyperText Transfer Protocol
H-FA ─ History-based FA
ICMP ─ Internet Control Message Protocol IDS ─ Intrusion Detection System
IDPS ─ Intrusion Detection and Prevention System IET ─ Institution of Engineering and Technology
ioctl ─ input/output control
IP ─ Internet Protocol, or, Intellectual Property IPS ─ Intrusion Prevention System
ISN ─ Initial Sequence Number
ITU ─ International Telecommunication Union IXP ─ Internet eXchange Processor
I/O ─ Input/Output
KMP ─ Knuth-Morris-Pratt (algorithm)
LAN ─ Local Area Network
LSB ─ Least Significant Bit
MAC ─ Media Access Control
Mb/s ─ Megabits per second
MF ─ More Fragments
MSB ─ Most Significant Bit
MSS ─ Maximum Segment Size
MTU ─ Maximum Transmission Unit
NAT ─ Network Address Translation NBA ─ Network Behavioural Analysis NGFW ─ Next Generation FireWall
NGIPS ─ Next Generation Intrusion Prevention System NIC ─ Network Interface Card
NIDS ─ Network Intrusion Detection System NIPS ─ Network Intrusion Prevention System NFA ─ Nondeterministic Finite Automaton NFP ─ Network Flow Processor
NPU ─ Network Processing Unit (Network Processor) OBDD ─ Ordered Binary Decision Diagrams
OISF ─ Open Information Security Foundation
OS ─ Operating System
PAF ─ Protocol Aware Flushing
PAWS ─ Protection Against Wrapped Sequence numbers PCI ─ Peripheral Component Interconnect
PCRE ─ Perl Compatible Regular Expression PDN ─ Packet Data Network
PDU ─ Protocol Data Unit
PE ─ Processing Engine
PHP ─ PHP: Hypertext Preprocessor
PL ─ Programmable Logic
PLPMTUD ─ Packetization Layer Path MTU Discovery
PMTUD ─ Path MTU Discovery
P2P ─ Peer to Peer
RAM ─ Random Access Memory
RE ─ Regular Expression
regex ─ Regular Expression
RFC ─ Request For Comments
RX ─ Receive
SDRAM ─ Synchronous Dynamic Random-Access Memory
SMB ─ Server Message Block
SPAN ─ Switched Port ANalyzer
TCAM ─ Ternary CAM
TCP ─ Transmission Control Protocol
TCP/IP ─ Transmission Control Protocol/Internet Protocol
TFO ─ TCP Fast Open
TOE ─ TCP/IP Offload Engine
TW ─ Terawatt
TX ─ Transmit
UDP ─ User Datagram Protocol
VHDL ─ VHSIC Hardware Description Language VHSIC ─ Very High Speed Integrated Circuit VLAN ─ Virtual Local Area Network
VRT ─ Vulnerability Research TeamTM (Sourefire)
XFA ─ Extended FA
Abstract
Network Intrusion Detection and Prevention Systems (NIDPS) are important elements of network security. Their role is to monitor internet traffic for malicious content and, on detection, generate an alert message and/or block the offending traffic. Potential attacks are described in a database of rules known as the rule set, where each rule consists of an IP header part and a payload signature part. The payload signature can be in the form of a fixed string and/or regular expression. This thesis studies the three main stages of these systems, namely TCP/IP reassembly, multi-match header matching and Deep Packet Inspection (DPI).
TCP/IP reassembly is a necessary prerequisite to DPI as attack patterns may span more than one IP fragment or TCP segment. Either target-based reassembly or traffic normalisation is required in order to overcome insertion/evasion attacks. This thesis builds upon existing research by outlining an FPGA-based architecture that handles the common case of reassembling in-sequence data streams in hardware and the much rarer out-of-sequence data streams in software.
Multi-match header matching involves the matching of each packet header against the header section of all rules. This differs from the single-match classification used in routers where there is a single highest priority match per packet. The strategy adopted in this thesis was to adapt a number of single match algorithms to perform multi-matching and to compare their performance with existing solutions. Existing solutions typically involve the use of Ternary Content Addressable Memory (TCAM) and therefore suffer from disadvantages such as high cost, high energy consumption, and low storage efficiency. Algorithmic solutions, which use SRAM instead of TCAM, can therefore have an advantage. The adapted algorithms were implemented in C code and evaluated in terms of speed and energy efficiency on an ARM processor.
DPI is particularly challenging due to the number and complexity of regular expressions. This thesis builds on existing research into Bit-Parallel hardware architectures. The main contribution is an extension for the efficient handling of the constrained {min,max} repetition syntax, including a solution to the issue of counter overlap. This allows for the handling of many additional regular expressions that would otherwise be unsuitable. The design was implemented in VHDL and evaluated using the Xilinx tool set. A comprehensive review of the most significant research works in the DPI field is also provided.
List of Publications
Journal PapersCronin, B. and Wang, X. Hardware Acceleration of Regular Expression Repetitions in Deep Packet Inspection, IET Information Security, Vol.7, No.4, 2013, pp.327-335, doi:10.1049/iet-ifs.2012.0340.
Cronin, B. and Wang, X. Pattern Overlap in Bit-Parallel Implementation of Regular Expression Repetition Quantifiers, Inderscience International Journal of Security and Networks, Vol. 8, No. 4, 2013, pp.231-238, doi:10.1504/IJSN.2013.058154.
Conference Paper
Cronin, B. and Wang, X. Algorithmic Multi-match Packet Classification in Network Intrusion Detection Systems, Proceedings of 2010 China-Ireland International Conference on Information and Communications Technologies (CIICT2010), Wuhan, China, 10-11 Oct., 2010.pp.150-156.
Chapter 1 -
Introduction
1.1.
Background
1.1.1. Growth of the Internet
Recent years have witnessed rapid growth in both internet penetration and bandwidth due to huge improvements in telecommunication infrastructure, the proliferation of competitively priced computers and internet-capable mobile devices, and the reduced cost of internet access resulting from increased competition. The number of individuals using the internet has increased from 1 billion in 2005 to over 2.7 billion in 2013 (ITU, 2013). Cisco (2013) estimates that global internet traffic has increased from 2,000 GB/s in 2007 to 12,000 GB/s in 2012 and forecasts that this will increase to 35,000 GB/s by 2017, equivalent to 1 zettabyte per year, mainly driven by increased video traffic. Business IP traffic is expected to triple between 2012 and 2017, mainly due to the increased use of high quality video communications.
1.1.2. Energy Consumption
The increase in energy consumption associated with expanding internet use has become a concern because of the associated economic and environmental costs. Raghavan and Ma (2011) estimated that the power consumed globally by the internet in 2011 was between 170 and 307 GW, in other words between 1.1 and 1.9% of the total 16TW used by the world population. Although this may seem like a small fraction, it is equivalent to the power output of over 350 typical nuclear reactors. Raghavan and Ma argue that we should apply the internet to reducing other forms of energy consumption (e.g. video conferencing versus travel) in addition to making the internet itself more efficient. According to Lanzisera et al. (2012), network equipment consumed about 1% of buildings electricity in the USA in 2008 and was increasing at a rate of approximately 6% per annum, with most of this consumption occurring in offices and residences rather than data centres. They found that office building networking equipment is one of the largest energy consumers, accounting for 40% of the total in 2008.
1.1.3. Internet Security
Approximately 7.6 million new unique pieces of malware were detected by the AV-Test Institute (2013) for the month of June 2013. In other words, a new malware was
created every 0.35 seconds. The ever increasing penetration and speed of the internet means that these viruses can spread even faster. The MyDoom worm was one of the fastest spreading email worms ever. Within a few hours of its first appearance in January 2004, it had slowed the internet by 10% and average web page load times by 50% (Jones 2006). The worm spread as an email attachment, and spammed itself to addresses listed in computer’s address books when the attachment was clicked on. It’s estimated that 10% of email messages, sent in the hours immediately after its first appearance, contained the worm. Consultancy firm mi2g (2004) estimated the economic losses caused by MyDoom at $38.5 billion, although this figure has been disputed by others. Another famous worm, Sasser, appeared in April 2004. Unlike MyDoom, it was not transmitted via email. It instead exploited a buffer-overrun flaw in unpatched versions of Microsoft Windows 2000 and XP which allowed it to take control of the infected computer (Vamosi 2004). It then scanned local networks and the internet for other computers to infect. It caused French satellite communications to be shut down, the cancellation of several Delta flights and the shutdown of many computer systems worldwide. The economic damage is estimated at between $14.8 and $18.1 billion (ThinkQuest 2004). The virus was created by a German student who released it on his 18th birthday.
Mobile internet traffic is currently growing rapidly due to the recent surge in smartphone take-up and the rollout of 4G networks. Smartphones are particularly attractive to cyber criminals as owners regularly use them for personal tasks such as online purchases, email and social media – all involving the use of sensitive personal information such as usernames, passwords and credit card details (Ruggiero and Foote 2011). They also pose an easier target than PCs as many users do not recognise the need to install or enable security software on their smartphones. Many naively believe that surfing the internet on their phone is safer than on their PC. NQ Mobile (2013) found that mobile malware attacks increased 163% in 2012, with 95% of all attacks targeting the Android OS.
The conventional way of defending against malware attacks is to use end-host based solutions such as patches to vulnerable operating systems and applications, anti-virus software and firewalls. The main issue with these approaches is that there is a time lag between the appearance of a virus, the availability of a software patch and virus database update, and finally the actual update of the end-hosts. Given the speed with
which some viruses can spread, this time lag can be more than sufficient for many systems to be infected. Moreover, the repeated updating of end-host software is an added maintenance cost for businesses, which also disrupts the normal work of computer users.
1.2.
Motivation
Given the issues with end-host security software, a more attractive approach is to block the malware in the network before it arrives at the end-hosts. This is known as intrusion prevention. In the case of office networks, this is typically performed at the edge of the network, just inside the firewall. It can also be performed internally to protect a particularly important segment of the network. In the case of the mobile internet, next generation security gateways would block attacks at the Gi/SGi interface between the 3G/4G network and the external PDN.
In addition to matching against the TCP/IP header, this type of Network Intrusion Prevention System (NIPS) needs Deep Packet Inspection (DPI) in order to analyse packet payloads for the presence of malicious content. Existing hardware systems commonly use energy inefficient TCAM to perform pattern matching. The ever increasing number and complexity of attack signatures and traffic speeds will lead to such systems becoming a significant consumer of power in the enterprise network. Due to customer demand, there is a growing requirement to design more efficient systems that miminise the use of energy inefficient technologies such as TCAM. The challenge is therefore to find hardware solutions which can accelerate, in an energy efficient manner, the analysis of network traffic for particular header values and the presence of complex attack signatures.
1.3.
Intrusion Detection and Prevention
The NIPS is one member of a larger family of what are known as Intrusion Detection and Prevention Systems (IDPS).
1.3.1. Classification
IDPS can be classified in the following categories:
Host-based – this system is a software agent installed on an individual computer. In addition to monitoring all incoming and outgoing traffic for attacks such as a virus, a worm or hacking activity, it also monitors applications running on the
computer for suspicious behaviour. Although host-based agents provide additional security features compared to network-based systems, they can be more difficult to administer because of their distributed nature
Network-based – this system is a standalone system which monitors all traffic into and out of a network. It can also be used to monitor internal network traffic. It can be either a dedicated hardware system from a networking equipment vendor or a software program running on an off-the-shelf server. One of the most well-known network-based software solutions is the open-source Snort (Roesch et al. 2012). Wireless – this system monitors wireless network traffic and the associated
wireless networking protocols for suspicious activity.
1.3.2. Detection Methods
IDPS use one or a combination of the following techniques to detect attacks:
Signature-based – attacks are described in a large database of attack signatures known as the rule set
Anomaly-based – attacks are detected by comparing the current activity with pre-defined “normal” activity. Such systems have the advantage that they can detect attacks hidden within encrypted traffic, but often suffer from a high number of false positives, i.e. incorrectly generating an attack alert notification. Note that a network-based system that uses anomaly-based detection is also known as a Network Behavioural Analysis (NBA) System
Stateful protocol analysis – the state of network, transport and application protocols are tracked and the activity compared with correct protocol behaviour in order to detect attacks. Some signature-based systems provide the ability to specify stateful signature-based rules, e.g. flowbits keyword in Snort allows a number of rules to be linked together in order to track state across multiple datagrams in a single transport layer session; flow:established keywords restrict application of the rule to established sessions only.
1.3.3. Modes
Passive – An Intrusion Detection System (IDS) is passive in that it only monitors traffic for attacks and generates an alert and logs an event on detection
Reactive – An Intrusion Prevention System (IPS) is reactive in that it can be configured to perform an action on detection of a particular attack.
In the case of an NIPS, such an action could be to block the connection carrying the malicious traffic. Snort can function as an NIPS by running it in inline mode. Although an NIPS is a very powerful solution, it suffers from a couple of issues. Firstly, false positives can result in valid, and perhaps critical, connections being dropped. Secondly, processing overload or DoS attacks can result in valid traffic being dropped or attacks left through.
The action perform by a Host-based IPS (HIPS) depends on the exact detection technique used – e.g. it could prevent code being executed, block a network connection, stop inappropriate file access.
1.3.4. NIDS Sensor Location
The most common location for an NIDS system is inside an enterprise’s firewall so as to reduce its incoming traffic workload and exposure to DoS attacks. The firewall is the first line of defence which is configured to block all incoming connections on ports which have not been opened. The NIDS will monitor traffic passed by the firewall for attack patterns, e.g. a virus inside HTTP connection traffic.
On detection of potential malicious traffic by the NIDS, the event is typically logged on the management server and an alert sent to the console.
Figure 1 shows an example enterprise network with NIDS systems placed in a number of locations:
NIDS outside the firewall in order to detect attacks against the firewall
NIDS in DMZ (demilitarised zone) to detect attacks against web/mail servers, etc. Each server should also run a HIDS agent for increased security
NIDS in the internal network to detect internal attacks and external attacks that firewall left through.
An NIDS is a passive system that sniffs packets from the network. It can be connected to the network using a hub, ethernet tap or via the SPAN port of a switch. In the case of a switch, it may be possible to mirror a number of ports to the SPAN port using a VLAN. The disadvantages of the SPAN port are that the total VLAN traffic may exceed the bandwidth of the port and, the performance of the switch may be degraded. Bandwidth is typically more of an issue when the NIDS is used to monitor internal network traffic since the traffic throughput is likely to be much higher than that found at the gateway to the external internet. Finally, some networking equipment vendors have switches and firewalls with built-in NIDS functionality.
1.3.5. NIPS Sensor Location
An NIPS system is an inline sensor which the monitored traffic must flow through. It is typically deployed on secure side of the firewall in order to reduce its workload. As time goes on, the line between firewall and IPS is becoming blurred as more and more firewall vendors provide IPS functionality as part of next generation firewall systems. The NIPS can be configured to carry out various actions on detection of a particular attack or undesirable traffic, e.g.:
drop packets containing an attack pattern
block the corresponding transport layer connection. This could be done inline or by automatically reconfiguring the firewall
reset the transport layer connection
throttle the bandwidth used by undesirable traffic (e.g. P2P file sharing, suspected DoS attack, etc.)
run a script written by the NIPS administrator – script gives a lot of flexibility to automatically reconfigure third-party networking equipment.
Figure 2 shows an example enterprise network with two NIPS systems. One is positioned just inside the firewall to detect any attacks that manage to get through it. The second is used to protect a particularly important segment of the network against internal intrusions, e.g. finance department, labelled segment 1.
Figure 2. Example of NIPS placement in enterprise network
1.4.
Research Goals
This thesis focuses on the three primary parts of an NIDPS system, namely TCP/IP reassembly, multi-match header classification and regular expression (regex) DPI, as highlighted in grey in Figure 3. Depending on the requirements of the DPI stage implementation, the multi-match header classification stage may run either in series or in parallel with the DPI stage. When placed in front of the DPI, the header classification stage acts as a pre-filter which reduces the number of rules that need to be processed at the DPI stage for a particular connection flow. However, some DPI algorithms cannot take advantage of this as they always examine every rule for every packet, and, in this case, it makes more sense to run the header classification in parallel. In the parallel architecture, a negative header match will result in a fast overall negative match decision which will cut short the processing in the DPI block for that particular connection flow.
IP traffic Reassembly of IP fragments & TCP segments Header Classification Fixed String DPI Regular Expression DPI Match Decision Making Action Data stream Matching Rules
Figure 3. Example NIDPS Architecture
The overall goal of this thesis is to propose new, or extend existing, algorithms and architectures that lead to systems that can handle higher traffic throughputs, greater numbers and complexity of attack signatures, while keeping power consumption to a minimum. The specific goals in each area are as follows:
Improve on existing hardware acceleration techniques for the acceleration of TCP/IP reassembly in the context of DPI:
Existing hardware-based designs typically drop out-of-order TCP segments in order to force the originating host to resend. Dropping packets in this way is not ideal as network performance is adversely affected. This leads to the thesis goal of outlining a hardware-based architecture that avoids unnecessary packet dropping.
Develop and evaluate algorithmic solutions to the problem of multi-match header matching:
Hardware-based NIDPS typically use TCAM-based technology to perform TCP/IP header matching. The strategy adopted in this thesis is to adapt a number of single match algorithms to perform multi-matching and to compare their performance with existing solutions. Such algorithms can use SRAM instead of TCAM and should therefore be less expensive and more energy efficient.
Survey existing research work on DPI, with a particular focus on regular expression matching:
A review of the most significant research in the area of DPI will be of use to other researchers looking to improve the state of the art.
Extend Bit-Parallel (BP) hardware architecture from existing research to include improved handling of constrained {min,max} repetition syntax:
Constrained repetition syntax is commonly used in DPI regular expressions. Existing BP architectures handle such repetitions by unrolling of the repetition with the result that the regex is often unsuitable for processing because of its excessive length. The goal is to modify the BP architecture based on the Glushkov NFA so that it can handle these repetitions without unrolling, thereby greatly increasing the number of DPI signatures that can be handled.
1.5.
Contributions
The main contributions of this thesis are summarised as follows: TCP Segment Reassembly
The importance of IP fragment and TCP segment reassembly in DPI systems is examined and the reassembly functionality of open source software NIDPS is analysed. Existing research solutions to hardware acceleration of TCP/IP reassembly do not fully handle all cases of out-of-sequence packets. This thesis outlines an FPGA-based architecture that handles the common case of reassembling in-sequence data streams in hardware and the much rarer out-of-sequence data streams in software. Multi-match Packet Classification
A number of algorithmic approaches to multi-match classification which use SRAM instead of TCAM are evaluated and compared in terms of throughput performance and energy efficiency. These algorithms are mainly for single-match classification and so have to be adapted for multi-match. The adapted algorithms were implemented in C code and evaluated on an ARM simulation platform. The EGT-PC and ART algorithms were found to be a suitable alternative to TCAM. Although these algorithms do not currently match the performance of existing bit vector based algorithms, such as FSBV and StrideBV, due to the commonality of field values in recent rule sets, this may change in the future.
Deep Packet Inspection
While extensive research has been conducted into algorithms for performing fixed string and general regex matching, the majority has ignored some of the more complicated regex syntax such as constrained repetition quantifiers and back references. This thesis describes a hardware architecture for handling regexes containing constrained repetitions. The issue of pattern overlap affecting the handling
of these repetitions is then examined and, a First-In-First-Out (FIFO) queue based solution is described for susceptible regexes. The algorithms were implemented in VHDL and evaluated using the Xilinx tool set and the open-source NetFPGA (Naous et al., 2008) research platform as the target.
The impact of this work is that the handling of many regexes that would otherwise be unfeasible due to their unrolled length can now be efficiently and correctly handled by the BP architecture based on the Glushkov NFA. This enables the hardware acceleration of over half the regexes found in recent Snort rule sets. The remainder could be handled by extracting suitable sub-expressions and using the BP system as an imprecise pre-filter followed by full verification of any positive matches in software.
The design evaluated in this thesis matches against all regexes in parallel. An alternative approach would be to use multi-match header and fixed string matching as pre-filters so as to greatly reduce the number of regexes to match against per packet. The counting block algorithm outlined in this thesis could equally be used in such a design. Such an approach would allow for regex data to be stored in external SRAM, thereby allowing for the storage of a much larger number of regexes. Such a design would give high throughput through the use of pipelining and parallel processing of packets.
Hardware acceleration of regex matching for DPI is a very challenging task. It is hoped that the contributions of this thesis will be useful to other researchers looking to further advance the state of the art.
1.6.
Thesis Organisation
The remainder of this thesis is structured as follows: Chapter 2: Background
This gives background information useful for a better understanding of the thesis. Operation of the open-source NIDPS, Snort, is looked at and the rule syntax examined. Some of the mathematical concepts related to the finite automaton representation of regexes are described.
Chapter 3: TCP/IP Reassembly
Most research articles on signature-based NIDPS do not mention TCP/IP reassembly. This chapter looks at what is an essential element of any NIDPS as
attack patterns may be split over multiple IP fragments or TCP segments. Moreover, target OS–based reassembly is necessary in order to avoid attack evasion. An FPGA-based design is outlined for the acceleration of this reassembly.
Chapter 4: Multi-match Header Classification
This chapter describes the adaption and evaluation of a number of single-match packet classification algorithms for multi-match classification. Multi-match header classification is needed in NIDPS because a number of rules may match the header of the incoming IP packet.
Chapter 5: Pattern Matching Methods
This chapter looks at the general theory of both fixed string and regex matching in DPI and related research.
Chapter 6: Constrained Repetition Handling Algorithm
A counter-based algorithm and a corresponding Bit-Parallel (BP) hardware architecture are presented for the more efficient processing of regexes which include constrained repetitions.
Chapter 7: Dealing with Pattern Overlap in the case of Constrained Repetitions
This chapter describes how certain regexes which include constrained repetitions are not suitable for the counter-based algorithm as they are susceptible to a pattern overlap issue. A FIFO-based mechanism to deal with the issue is outlined and evaluated.
Chapter 8: Conclusion and Future Work
A summary is presented of the results achieved in the preceding chapters and possible directions for future research are discussed.
Chapter 2 -
Background
This chapter provides a brief introduction to those aspects of automata theory that are helpful for a better understanding of the thesis. An overview is also provided of some of the main open source and commercial NIDPS, including a discussion of the recent trend for IPS functionality to be included in next generation firewall products. The choice of platform for an NIDPS product has a significant impact on achievable performance and price. All the various commodity and custom hardware platforms, suitable for an NIDPS implementation, are examined.
2.1.
Automata Theory
2.1.1. Formal Languages
Alphabet
An alphabet, denoted by the symbol Σ, is a finite, nonempty ordered set of symbols. e.g.:
Σ = {a,b,...z} is the set of all lower-case letters
Σ = {00,01,02,...FF} is the set of 256 symbols that can be represented by 8-bit values (using hexadecimal representation).
Strings
A string is a finite sequence of symbols from a particular alphabet. e.g. bxsf is a string from the alphabet Σ = {a,b,...z}. An empty string, denoted by ε, has zero occurrences of symbols from Σ.
Exponential notation is used to express the set of all strings of a particular length from an alphabet, e.g.
If Σ = {0,1}, then Σ2 = {00, 01, 10, 11}. Σ0 = { ε }, regardless of the alphabet.
Languages
If Σ is an alphabet, and Σ* , then L is a language over Σ. In other words, L is a set of strings chosen from Σ*. Formal languages are treated in the same way as mathematical sets and so set theory operations such as union and intersection can be applied. It can be defined using an automaton or formal grammar system.
Formal languages are often used to define computer programming languages.
Grammars
A formal grammar consists of
a finite set of non-terminal variable symbols that can be rewritten as a sequence of symbols
a finite set of terminal symbols, Σ, the alphabet of the language, that cannot be rewritten – hence “terminal”
a finite set of rewrite/derivation rules X → Y, (i.e. X directly derives Y), where X and Y consist of non-terminals and/or terminals
a start variable, S, which is an element of the set of non-terminals
Chomsky (1956) categorised formal grammars into four classes, as shown in Table 1, by restricting the forms of X and Y.
Table 1. Chomsky Hierarchy
Language Grammar Automaton Rewrite rule
restriction* 3 Regular Regular (Right-linear or Left-linear) † NFA or DFA A→a and
A→aB (or A→Ba) † and
A→ ε
2 Context-free Context-free Push-Down
Automaton A→α 1 Context-sensitive Context-sensitive Linear-Bounded Automaton α Aβ→ α µβ 0 Unrestricted/Free Recursively enumerable Turing Machine α → β
* A and B represent single non-terminal variables, a represents a single terminal symbol and, greek letters represent strings of terminals and non-terminals. α and β can be empty. † See section 2.1.2 for explanation of left-linear and right-linear grammars
2.1.2. Regular Languages
Regular Grammars
Strictly regular grammars generate regular languages and can be represented by finite state automata. The rewrite rules are restricted to having a left-hand side consisting of a single non-terminal and a right-hand side consisting of a single terminal possibly followed by a single non-terminal in the case of a right-linear grammar, or it can alternatively be preceded by a single non-terminal in the case of a left-linear grammar. Left and right-linear rules cannot be mixed in the same regular grammar. The rule S→
ε is allowed, provided the start variable, S, does not appear on the right-hand side of any rule. Left and right-linear grammars are discussed further at the end of this section.
An Extended Regular grammar is similar to a regular grammar except that in the rule
A→aB (or A→Ba), a can be a string of terminals. It can be shown that any extended regular grammar can be also expressed as an equivalent strictly regular grammar.
A regular grammar is said to be non-deterministic if it includes two rules A→aB and
A→a or two rules A→aB and A→aC. Otherwise it is said to be deterministic.
Finite State Automata
A finite automaton is a 5-tuple ( Q, Σ, q0, F, δ ) where Q is a finite set of states (circles in state diagram). Σ is a finite set of symbols called the alphabet.
q0∈ Q is the start state (state with incoming arrow not connected to any other state
in the state diagram).
F Q is the finite set of accept or final states (double circles in state diagram). δ is the transition relation, indicating where to go for a given state and input
symbol. In the same way as for regular grammars, a finite state automaton is said to be non-deterministic if there exist states for which the same input symbol results in more than one transition. The transition function can therefore be defined:
o for a Non-deterministic Finite Automaton (NFA)
δ : Q × (Σ ∪ {ε}) → P(Q)
where P(Q) is the power set (set of all subsets) of Q.
× denotes Cartesian product, the set of all ordered pairs from two sets.
This is a multi-valued transition function, i.e. for a given state and input symbol, there can be more than one transition.
o for a Deterministic Finite Automaton (DFA)
δ : Q × Σ→ Q
This is a single valued transition function.
It can be shown that the languages accepted by finite automata are regular languages. Therefore any language represented by a regular grammar can also be represented by an equivalent finite automaton.
Consider the following regular grammar in which {a,b} is the alphabet of the language and q0,q1are non-terminal variables
Now if q2 is added as a non-terminal variable corresponding to accept or final state of the equivalent NFA, the regular grammar can be rewritten as
q0→aq0 q0→bq1 q1→aq2 q1→aq1 q2→ ε
The state transition table and the state diagram of the equivalent NFA are shown in Table 2 and Figure 4, respectively. q0 is the start state and q2 is the accept state. Note that state q1 has two outgoing edges with the same symbol, i.e. this is an NFA.
Table 2. State Transition Table for example regular grammar Input Symbol State a b q0 {q0} {q1} q1 { q1,q2} ∅ (null) q0 b q1 q2 a a a
Figure 4. NFA equivalent to example regular grammar
NFA vs. DFA
In the case of DFA, for each state, q, and input symbol, α, there is exactly one transition leaving state q. This includes transitions to the null state, which are typically omitted from state diagrams. Therefore a DFA has at most one edge leaving state q
labelled with the symbol α.
In the case of an NFA, there may be multiple transitions for each combination of state and input symbol. It can also include transitions for the empty string, ε, i.e. it can transition from one state to another without consuming any input symbol.
It can be shown that any regular language L is accepted by a DFA if and only if it is also accepted by an NFA. In other words, DFA and NFA are equivalent in what they express and it is always possible to convert between them. It should also be noted that a DFA is in fact a special case of an NFA.
Regular Expressions
A regex, r, is an algebraic formula which represents the language L(r) of the regex, i.e. a set of strings in Σ*. The fundamental operators used in regexes are:
Union/Alternation: If r1 and r2 are regexes then r1|r2 is also a regex.
Concatenation: If r1 and r2 are regexes, then r1r2is also a regex.
Kleene Closure: If r is a regex, then r* is also a regex.
Two regexes over the same alphabet are equivalent if, and only if, their respective languages are equal sets. It can be shown that every language defined by a finite state automaton can also be expressed as an equivalent regex, e.g. FA in Figure 4 can alternatively be expressed as the equivalent regex a*ba*a .
Some example regexes:
a|b* denotes { ε, a, b, bb, bbb, ....}.
(b|c)* denotes all strings made up of only the symbols b and c, plus the empty string.
(ab|c)d denotes { ε, abd, cd }.
Regex operator precedence, as outlined in Table 3, is relatively simple. The most important point is that concatenation has higher priority than alternation.
Table 3. Regex operator precedence
Precedence Operator Description
Highest () Parentheses and other grouping operators
*, +, ?, {min,max}, etc. Repetition
^xyz Concatenation
Lowest | Alternation
Right versus Left Linear (Regular) Grammars
A right-linear grammar generates the strings of the language (i.e. the words) from left to right, whereas a linear grammar generates the words from right to left. Any left-linear grammar can be converted to an equivalent right-left-linear grammar and vice versa.
Figure 5 and Figure 6 show the right-linear and left-grammars, respectively, corresponding to the regex x*yz*, along with their equivalent automata.
S y A z x z ε Right-linear grammar: S→xS | yA A→zA | ε Regex: x*yz* Finite automaton:
Figure 5. Example of right-linear grammar and corresponding automaton
S A x z ε Left-linear grammar: S→Sz | Ay A→Ax | ε Regex: x*yz* Finite automaton: y
Figure 6. Equivalent left-linear grammar and corresponding automaton
2.1.3. Perl Compatible Regular Expressions
PCRE is a regex library written in C which implements pattern matching based on the syntax and semantics used in Perl 5.The library is used by a number of open source programs, including Apache HTTP server, PHP and Snort.
Snort PCRE syntax
The pcre keyword in Snort allows PCRE regexes to be written in the following format:
pcre:[!]"(/<regex>/|m<delim><regex><delim>)[ismxAEGRUBPHMCOIDKYS]" ;
A regex is usually delimited using “/”. However, it is possible to use almost any other special character, provided it is preceded by the letter “m” (meaning match). Prefixing the regex with an exclamation mark negates its meaning. e.g. the regex
/foo/ matches any string that contains “foo”, whereas the regex !/foo/ matches any string that does not.
The regex may be followed by a list of modifiers, ismxAEGRUBPHMCOIDKYS, some of which are Snort specific extensions. Three of the most common modifiers are:
o i – case insensitive matching
o s – single line mode, i.e. the dot wildcard metacharacter ,“.”, is to match everything including new line (otherwise new line is excluded)
o m – multi-line mode. This affects the operation of the start and end anchors, “^” and “$”, respectively. By default the input string is treated as a single line and the anchors apply to the start and end of the string. However, in multi-line mode, the “^” and “$” anchors additionally apply immediately after and before, respectively, any newline in the input stream.
The PCRE syntax and semantics most commonly used in Snort is described in Table 4.
Regex anchors
An anchor is a type of zero-width assertion that specifies a position in the input string where a match must occur. Assertions do not actually consume any characters. The most important anchors used in Snort rules are described in Table 5.
For example, the multi-line start-anchored regex /^hello/m would find a match in the strings “helloworld” and “world\nhelloworld”, but not in “worldhelloworld”. Similarly, the multi-line end-anchored regex /world$/m would find a match in “goodbyeworld” and “world\ngoodbye”, but not in “goodworldgoodbye”.
Table 4. Important PCRE Syntax and Semantics
Operator Type Example Meaning
Literals
a 4 % Letters, digits, other characters
\^ \? Special characters must be preceded by \ to cancel their special meaning
\n \t \r New line, tab, carriage return
\xa3 Hex code
Anchors and assertions
^ Regex must match at start of string, or after a new line in multi-line mode $ Regex must match at end of string, or before a new line in multi-line mode \b Word boundary – matches before and after an alphanumeric
sequence (matched by \w character class)
Character Classes
[acEoi] Any character in the list will match
[^acEoi] Any character apart from those in list will match [a-fA-F0-9] Any hex character (dash indicates a range of characters) .
Dot means any character except new line.
If single line mode modifier is specified, then new line is also allowed.
\s Any space character [ \t\r\n]
\w Any word character [A-Za-z0-9_]
\d Any digit [0-9]
\h Any horizontal whitespace character [ \t]
\S \W \D \H Inverse of above four
Repetition (applied to preceeding regex element) + 1 or more * 0 or more ? 0 or 1 {10} Exactly 10 {10,} 10 or more {,10} Up to 10 {5,10} Between 5 and 10
Counting is “greedy” by default. i.e. System tries to find the longest match before backtracking if necessary. It can be made “lazy” by appending “?” after the count – i.e. system first tries to complete a match using the shortest number of repetitions, before then trying longer ones.
Alternation | either,or, e.g. a|b means a or b
Grouping () Parentheses allow an operator to be applied to a part of a regex,
rather than a single element.
This also creates a back-reference. Each group is numbered from left to right from 1.
Back-references \n where n is a number
\2 is a back-reference to the 2nd matched group. Note that it
signifies the matched fixed string that was matched and not the regex group.
Lookahead Assertion
(?=regex) Zero-width positive lookahead. (Note: Lookahead assertions do not consume characters – i.e. matching position is not moved) e.g. /foo(?=bar)/ will match foo if it is followed by bar. (?!regex) Zero-width negative lookahead.
e.g. /foo(?!bar)/ will match if foo is found and is not followed by
bar. Lookbehind
Assertion
(?<=regex) Zero-width positive lookbehind.
e.g. /(?<=foo)bar/ will match bar if it is preceded by foo. (?<!regex) Zero-width negative lookbehind.
Table 5. Snort regex anchors
Anchor Multi-line
mode Description
^ Disabled The match must occur at the beginning of the string.
^ Enabled
The match must occur at the beginning of the string or line, i.e. at beginning or immediately following any newline character.
$ Disabled The match must occur at the end of the string.
$ Enabled The match must occur at the end of the string or line, i.e. at end or immediately before any newline character.
\b -
The match must occur on a word boundary, i.e. between a word and a non-word character. Word characters consist of all alphanumeric characters and underscores.
2.1.4. Construction of NFA from regex
Several algorithms have been proposed for the construction of a finite automaton from a regex. The algorithms differ in their level of complexity, in whether or not the result is deterministic, and in whether or not there are ε-transitions. The two best known classic methods are the Thompson (1968) construction algorithm and the Glushkov (1961) construction algorithm (equivalent to McNaughton-Yamada (1960) method). The Thompson method is simpler and produces an NFA with at most 2m states and at most 4m transitions, where m is the number of characters (from alphabet) in the regex – i.e. linear relationship. It does, however, have ε-transitions. The Glushkov method produces an NFA with exactly m+1 states but up to O(m2) transitions. It has the advantage of not generating ε-transitions, but the construction takes longer compared to the Thompson method. It also has the important property that all transitions into a particular state are for the same character.
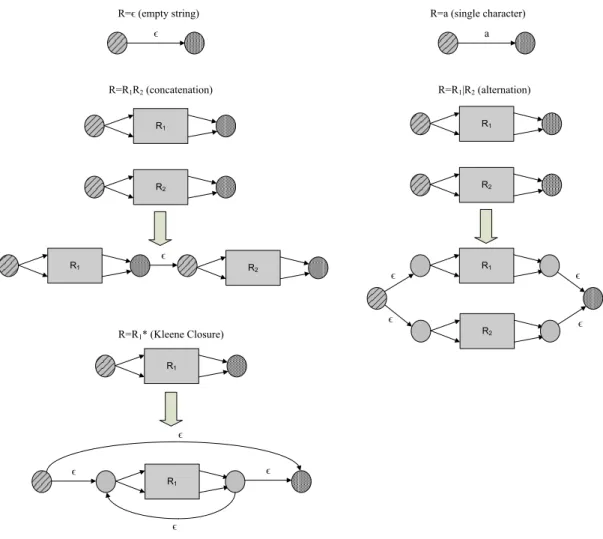
Thompson NFA ϵ a R1 R2 R1 R2 R1 R2 R1 R2 ϵ ϵ ϵ ϵ R1 R1 ϵ ϵ ϵ ϵ
R=ϵ (empty string) R=a (single character)
R=R1R2 (concatenation) R=R1|R2 (alternation)
R=R1* (Kleene Closure) ϵ
Figure 7. Thompson Construction – glueing together automata
The Thompson method first constructs a tree representation of the regex before computing, at each node of the tree, an automaton that recognises the language represented by the subtree at that node. ε-transitions are used to “glue” these automata together to eventually produce the overall NFA. Figure 7 illustrates how the sub-automata are glued together and Figure 8 shows the NFA constructed from regex
(a|b)*ca. 0 ϵ 1 2 3 4 5 6 7 a b ϵ ϵ ϵ ϵ ϵ ϵ ϵ 8 ϵ 9 c 10 ϵ 11 a
Glushkov NFA
The Glushkov construction method was first explicitly described by Berry and Sethi (1986) and is explained in detail by Navarro and Raffinot (2002). Consider the example regex RE=(a|b)*ca. The positions of the characters in the regex are marked with a number to give the marked expression RE=(
a
1|b
2)*c
3a
4. Note that the bar overRE signifies that it is the marked form of the regex. Using the following notation:
L(RE) represents the language of RE, i.e. all the strings accepted by RE. In the case of the example, L(RE) = {
c
3a
4,a
1c
3a
4,b
2c
3a
4,a
1a
1c
3c
4,b
2b
2c
3a
4,a
1b
2c
3a
4,b
2a
1c
3a
4,... } represents the marked character alphabet
* is the regex operator meaning that the preceding symbol or sub-pattern is repeated zero or more times
* represents all possible combinations of characters in the alphabet (can be null) Pos(RE){1...m} represents the set of positions in RE
αy is the indexed character at position y
the following definitions are made:
First(RE ) = {x|x Pos(RE), u *, αxu L(RE)}
i.e. the set of initial positions of L(RE). In the case of the example, First(RE ){1,2}
Last(RE ) = {x|x Pos(RE), u *, uαx L(RE)}
i.e. the set of positions in RE with index x whose corresponding character αx
forms a string from the language of RE when prefixed by some combination of characters from the alphabet. In other words this is the set of final, or accept, states of the automaton which, when reached, indicate a match has been found.
In the case of the example, Last(RE ){4}
Follow(RE,x ) = {y|y Pos(RE), u,v *, uαxαyv L(RE)}
i.e. for a given position x in RE, the set of positions in REwith index y for which the combination of the two characters αx followed by αy form a substring of some
string from the language of RE. In other words, for each position x, Follow(RE,x ) is the set of positions reachable from x.
In the case of the example o Follow(RE,1)={1,2,3} o Follow(RE,2)={1,2,3} o Follow(RE,3)={4}
EmptyREhas value {ε} if ε belongs to L(RE) and ∅ otherwise.
There is a transition from state x to y in the automaton if y ∈ Follow(RE,x). The resulting marked Glushkov automaton is shown in Figure 9. The Glushkov automaton is then simply obtained by removing the position indices from the marked automaton.
0
a
1 1 2 3 4b
2b
2c
3a
1a
1b
2c
3a
4Figure 9. Marked Glushkov NFA for RE=(a1|b2)*c3a4
The Glushkov construction algorithm, in the same way as the Thompson algorithm, makes use of a tree representation of the regex, where each node ν of the tree represents a sub-expression REν of the overall regex RE. First(ν), ast(ν) and Emptyν are calculated for each node ν, starting at the leaves and working back towards the root of the tree. A global variable Follow(x) is maintained for each position in RE and this is updated at each node. Full details of the recursive algorithm can be found in the textbook by Navarro and Raffinot (2002).
2.1.5. NFA to DFA conversion
Every language that can be described by an NFA can also be described by an equivalent DFA. In practice, a DFA usually has around the same number of states as an NFA but with more transitions. However, in the worst case, the smallest equivalent DFA can have 2n states compared to the n states of the smallest NFA.
The classic method to convert an NFA to a DFA is known as the subset construction
DFA corresponds to a set of states in the NFA. The algorithm, as illustrated in Figure 10 for the Thompson NFA of Figure 8, is as follows:
The DFA start state is the set of NFA states reachable by an ε-transition.
Starting with the DFA start state, repeat the following for every new DFA state created until no more new states can be found:
o For each character from the alphabet of the language, compute the set of states reachable from the DFA state – this set of states constitutes a new state.
The final or accept states in the DFA are those whose set of NFA states contains at least one final state from the NFA.
2.1.6. Trie
A trie (from retrieval) is a multi-way ordered data tree structure which can be used for storing strings. All strings that branch from the same node share the same prefix. Figure 11 shows the trie for the set of strings P={bale, ball, bark}.
{0,1,2,4,7,8} {3,6,7,8} {5,6,7,8} {9,10} a b c c c b a a b {11} a Transition Table DFA State, q δ(q,a) δ(q,b) δ(q,c) {0,1,2,4,7,8} {3,6,7,8} {5,6,7,8} {9,10} {3,6,7,8} {3,6,7,8} {5,6,7,8} {9,10} {5,6,7,8} {3,6,7,8} {5,6,7,8} {9,10} {9,10} {11} ∅ ∅ {11} ∅ ∅ ∅