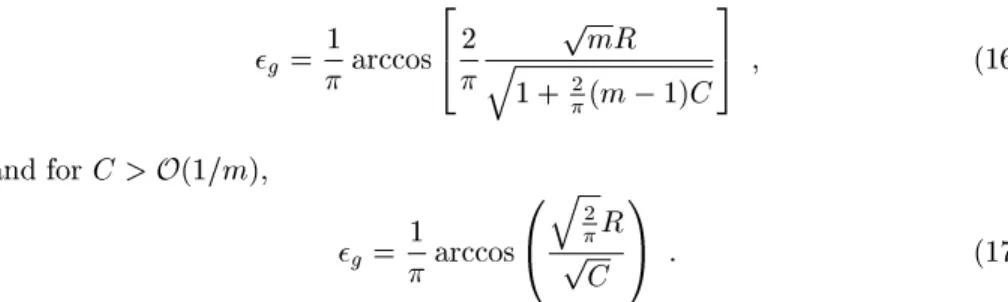A Statistical Mechanics Perspective
of Multiple Neural Network Approaches
Jong-Hoon Oh1 and Kukjin Kang2
1 Bell Labs, Lucent Technologies, 600 Mountain Ave., Murray Hill, NJ 07974, U.S.A. 2 Department of Physics, Pohang Institute of Science and Technology, Hyoja San 31,
Pohang, Kyongbuk 790-784, Korea
Abstract. In the framework of statistical physics, we studied the
'en-semble learning' and the 'mixture of experts', which are the typical re-alizations of the mutiple neural network approach. Generalization capa-bilities of the two methods are analyzed. We discuss the pro and con of the two approaches, and the possibility of unied method combining the merit of two approaches.
1 Introduction
Recently, the concept of combining multiple networks has been used widely within the neural network community to obtain optimal generalization capability [1, 2, 3, 4, 5, 6]. Most of published studies fall into two classes. One is the 'ensem-ble' approach [1] in which we generate an ensemble of networks independently trained for the whole problem and the outputs of the networks are combined with an appropriate weighting. The other class is the `expert' approach, where the problem is divided into manageable sizes for several subnetworks (experts) and each expert learns locally from a part of the problem domain. The outputs from the experts are combined using human expertise [4] or by independently-trained gating networks [5, 6]. The main dierence between the two approaches is that in the rst instance each neural network manages the global problem domain, while in the second, it is specialized for the local tasks.
The key issues in the multiple neural network approach are how the outputs of the various subnetworks should be combined to give the best generalization performance and how to make the best use of a limited data set. Perrone and Cooper [1] proposed a method for calculating optimal weighting factors for an ensemble of neural networks. Wolpert devised a method to train a supervisor network to give the weighting factors [2]. The mixture of experts [5, 6] is a well known example of the expert approach which implements the philosophy of divide-and-conquer elegantly.
Whereas these approaches are gaining more popularity in various applica-tions, it has been dicult to nd theoretical studies that have analyzed their validity and performance. In this paper we will address some fundamental issues related to the ensemble and expert approaches through the statistical mechanics formulation [7, 8, 9, 10, 11].
Here we study analytically soluble models of both methods. The former is the case of majority vote of perceptrons learning dichotomy rules. This corre-sponds to the `basic ensemble method', described by Perrone and Cooper, where the weightings of the networks are equal. We also study generalization in the mixture of experts which is a typical realization of the 'expert' approach. These models are obviously not the best choices in real situations, but they allow us to understand when each approach can be useful and where the weak points exist.
2 Ensemble Learning
We rst consider a situation of unrealizable learning by a population of percep-trons. A population of single-layer perceptrons is independently trained from examples presented by a two-layer teacher network called a committee machine. We consider cases where the training example set is the same for each perceptron. An individual perceptron (voter) maps the input vectorx=fxi;:::;xNgto
the output as:
(W;x) =g( 1 p N N X i Wx); (1)
where W is a set of the synaptic weights whose component Wi is a weight
from theith input node to the output node. We consider the transfer function g(x) = sgn(x).
The examples are randomly generated by a committee machine teacher with N input nodes andMhidden nodes. The network maps an input vectorxto an
output given by:
(V;x) =g 2(M ? 1 2 M X j g1( 1 p NVjx)); (2)
whereg1(x) andg2(x) are transfer functions of the hidden nodes and the output
node respectively. We also consider threshold unitsg1(x) =g2(x) = sgn(x). Vj
is a vector representation for the synaptic weights whose component Vji is a
weight from theith input node to thejth hidden node.
The energy of the system is dened as the dierence between the output of the teacher network and the output of eachindividual perceptron,
E=XP
l=1
(W;xl); (3)
(W;xl) =(?(V;xl)(W;xl)); (4)
where (x) is the heaviside step function, and P is the number of training examples. Each component of the inputSliis randomly drawn from the Gaussian distribution with variance unity.
The stochastic learning algorithm, used for each perceptron, leads, after a long time, to a Gibbs distribution of the weights as:
P(W) =Z
where= 1=T is the inverse temperature and the normalization factorZis the partition function, Z
d(W)e
?E(W ) : (6)
The prior distribution of weights d(W) contains appropriate constraints for
weights. In this paper we consider both binary weights and continuous weights with spherical constraints.
The free energyF is given by:
?F =hhlogZii: (7)
wherehh ii= R
Q
ld(xl) denotes the quenched average over possible example
sets. We use the replica trick:
hhlogZii= lim
n!0
hhZnii?1
n ; (8)
which has already been applied successfully to the problems of storage capacity and learning from examples [8, 9, 10, 11].
The performance of the network is measured by the generalization error. We consider a majority vote ofmperceptrons fW
1;:::;
Wmgvoting for answer,
g(fW g;x) = sgn
m
X
a (
Wa;x): (9)
The average generalization error is given by: g(T;P) =hhh
Z
d(x)(?(V;x)g(fW g;x)iT ii; (10)
wherehiT is the thermal average over the distributionP(W).
In the thermodynamic limit, N !1, the free energy can be written as a
function of several order parameters. The order parameters are dened as:
Raj = 1NWaVj ; (11)
qa = 1
NWaWa; (12)
where; are replica indices. The replica symmetric ansatz is written as:
Raj =r ; (13)
qa =+ (1?)q : (14)
We also assume that overlaps between the student and weights of the teacher connected to dierent hidden nodes are equal.
The generalization error depends upon both the generalization capability of individual perceptrons and the correlation among them. To calculate the gener-alization performance of the group decision, we need to introduce a new order parameter.Cabis dened as the overlap of theath andbth student perceptrons:
WhenCO(1=m), the generalization error is written as: g = 1 arccos 2 42 p mR q 1 + 2 (m?1)C 3 5 ; (16) and forC >O(1=m), g= 1arccos 0 @ q 2 R p C 1 A : (17)
The value of C can be determined from the saddle point equation of the free energy. We nd that the overlap between dierent perceptrons is the same as the overlap between two replicas when the perceptrons are trained from the same example set, that is:
C=q : (18)
By substituting the values of the order parameters obtained from the saddle-point equations into Eq. (17), we get the generalization error. The resulting learning curve for the network with binary weights are plotted in Fig. 1, together with the learning curve of a single perceptron.
εg 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0 20 40 60 80 100 α
Fig.1.The dotted line shows the generalization curves of majority vote by a population
of binary perceptrons trained with the same example sets atT = 5. For comparison, the dashed line depicts the learning curve of a single perceptron. The dots show the results of the Monte Carlo simulation, averaged over 10 independent runs whereN= M =m= 51.
Here we nd an interesting non-monotonic learning curve. The generalization error of the single perceptron decreases monotonically as a function of. When the number of examples is small, generalization performance of the group deci-sion by majority vote is much better than that of a single perceptron. However, generalization error reaches a minimum value at a certain value of, and then
increases again. When the number of examples approaches innity, the general-ization error converges to the same value as that of the single perceptron. This result can be interpreted as follows. Whenis small, the generalization error is mainly controlled by the order parameterRwhich increases with . This order parameter C measures similarity between dierent students. For small , the perceptrons have diverse congurations, and the group decision can show much better performance than a typical member of the population. As increases further, the order parameter C increases, and the perceptrons are located in or near the shrunken version space. If they are too similar to each other, they cannot exploit the advantage of the group decision. The group decision loses the advantage over an individual student, and the generalization performance of the algorithm deteriorates. When approaches innity, Capproaches one, and the generalization error of the majority vote approaches that of a single perceptron. When the perceptrons learn an unrealizable task, the generalization error converges to a nonzero constant: 0
1
cos?1( q
2
). When each perceptron
learns from the same example set, the asymptotic behavior is written as:g? 0
'
T=2, whereas a single perceptron has asymptoticsg? 0
'T=. This means
that we need only half the examples to achieve the same performance when we use multiple networks. Whenis small, this can be a big advantage, but it does not make much dierence when is large and the generalization error is close to the limiting value0.
3 Mixture of Experts
Here we study generalization in the mixture of experts [6] and its variety with a two-level hierarchy [5]. The network was trained using examples given by a teacher network with the same architecture. We found an interesting phase tran-sition driven by symmetry breaking among the experts. This phase trantran-sition was closely related to the `divide-and-conquer' mechanism which this model was originally designed to accomplish.
The mixture of experts [5] is a tree consisting of expert networks and gating networks which assign weights to the outputs of the experts. The expert networks sit at the leaves of the tree and the gating networks sit at its branching points. For the sake of simplicity, we consider a network with one gating network and two experts.
Each expert produces its outputj as a generalized linear function of theN
dimensional inputx:
j =f(Wjx); j= 1;2; (19)
whereWj is a weight vector of thejth expert with spherical constraint [9]. We
consider a transfer function f(x) = sgn(x) which produces binary outputs. The principle of divide-and-conquer is implemented by assigning each expert to a subregion of the input space with dierent local rules. A gating network makes partitions in the input space by a weighting factor assigned to each expert:
where the gating function(x) is the Heaviside step function. For two experts, this gating function denes a sharp boundary between the two subregions which is perpendicular to the vectorV
1 = ?V
2 =
V, whereas the softmax function
used in the original literature [5] yields a soft boundary. Now the weighted output from the mixture of expert is written as:
(V;W;x) = 2
X
j=1
gj(x)j(x): (21)
The whole network, as well as the individual experts, generates binary outputs. Therefore, it can learn only dichotomy rules.
The training examples are generated by a teacher with the same architecture as: (x) = 2 X j=1 (V 0 jx)sgn(W 0 jx); (22) where V 0 j andW 0
j are the weights of the gating network and the expert of the
teacher.
The learning of the mixture of experts is usually interpreted in terms of probabilities, and the learning algorithms are considered as maximum likelihood estimation. Learning algorithms originating from statistical methods such as the EM algorithm are often used. Again we consider Gibbs algorithm with noise level T (= 1=) that leads to a Gibbs distribution of the weights after a long time: P(V;Wj) = 1 Z e?E(V;W j ); (23) whereZ =R Q
jdVjdWjexp(?E(Vj;Wj)) is the partition function.
Training both the experts and the gating network is necessary for a good generalization performance. The energyE of the system is dened as a sum of errors overP examples:
E(V;Wj) = P X l=1 (V;Wj;xl); (24) (V;Wj;xl) =(?(V;Wj;xl)(V 0; W 0 j;xl)): (25)
Since the replica calculation proves to be intractable, we use the annealed approximation:
hhlogZii'loghhZii: (26)
The annealed approximation is thought to be good only at the high temperature limit, but it is known that the approximation can give a qualitatively good result, even at a moderately low temperature, in the case of learning realizable rules [9, 10].
The generalization function(V;Wj) can be written as a function of overlaps
between the weight vectors of the teacher and the student: (V;Wj) = 2 X i=1 2 X j=1 Pijij (27)
where Pij = 12 1? 1 cos?1RVij (28) ij = 1cos?1R ij; (29) and RVij = 1NViV 0 j; (30) Rij = 1NWiW 0 j: (31)
are the overlap order parameters. Here,Pijis a probability that theith expert of
the student learns from examples generated by thejth expert of the teacher. It is a volume fraction in the input space whereVixandV
0
jxare both positive.
For these particular examples, theith expert of the student gives a wrong answer with probability ij with respect to the j th expert of the teacher. We assume
that if the weight vectors of the teacher, V 0; W 0 1 and W 0 2, are orthogonal to
each other, then the overlap order parameters, other than the ones shown above, vanish. We use the symmetry properties of the network such as RV =RV11 =
RV
22= ?RV
12,R=R
11=R22, andr=R12=R21.
Now, we consider a thermodynamic limit where the dimension of the in-put space N and the number of examples P goes to innity, keeping the ratio = P=N nite. The free energy can be written as a function of three order parameters RV, R, andr. By minimizing the free energy with respect to the
order parameters, we nd the most probable values of the order parameters as well as the generalization error.
Fig. 2(a) shows the overlap order parametersRV,R andrversusat
tem-perature T = 5. Examining the plot, we nd an interesting phase transition driven by symmetry breaking among the experts. Below the phase transition pointc= 51:5, the overlap between the gating networks of the teacher and the
student is zero (RV = 0) and the overlaps between the experts are symmetric
(R=r). In the symmetric phase, the gating network does not have enough ex-amples to learn proper partitioning, so its performance is not much better than a random partitioning. Consequently each expert of the student cannot specialize for the subspaces with a particular local rule given by an expert of the teacher. Each expert has to learn multiple linear rules with linear structure, which leads to poor generalization performance. Unless more than a critical number of exam-ples is provided, the divide-and-conquer strategy does not work. Upon crossing the critical pointc, the system undergoes a continuous phase transition to the
symmetry-breaking phase. The order parameterRV, related to the goodness of
partition, begins to increase abruptly and approaches 1 with increasing. The gating network now provides a better partition which is close to that of the teacher. The plot of order parameters R and r, which is the overlap between experts of teacher and student, branches at c and approaches 1 and 0
respec-tively. This means that each expert specializes its role by making an appropriate pair with a particular expert of the teacher. Fig. 2(b) plots the generalization
0 0.2 0.4 0.6 0.8 1 0 20 40 60 80 100 120 140 160 180 α (a) εg 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0 20 40 60 80 100 120 140 160 180 α (b)
Fig.2.(a) The overlap order parametersR
V,R,r versusatT = 5:For < c=
51:5, we ndRV = 0 (solid line that followsxaxis), andR=r(dashed line). At the
transition point,RV begins to increase abruptly,R (dotted line) andr (dashed line)
branches, both of which approach 1 and 0 respectively. (b) The generalization curve (g versus ) for the mixture of experts in the same scale. A cusp at the transition
curve (gversus) on the same scale. Although the generalization curve is
con-tinuous, the slope of the curve changes discontinuously at the transition point so that the generalization curve has a cusp. The asymptotic behavior of g at
largeis given by:
' 3 1?e ? 1 ; (32)
where the 1=decay is often observed in the learning of other feedforward net-works.
We also study generalization in a two-level hierarchical mixture of experts [5]. The two-level hierarchical mixture of experts consisting of three gating networks and four experts. At the top level the tree is divided into two branches, which are in turn divided into two branches at the lower level. The experts sit at the four leaves of the tree, and the three gating networks sit at the top- and lower-level branching points. The network also learns from the training examples drawn from a teacher network with the same architecture.
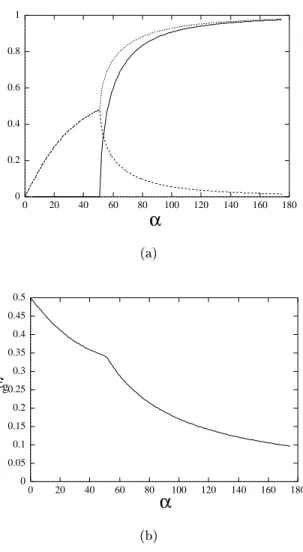
Fig. 3(a) shows a plot of overlaps Rij between the experts of the student
network and those of the teacher network versus. There exist two phase tran-sitions at c1 = 111:9 and c2 = 135:4, driven by symmetry breaking at the
dierent levels of hierarchy. For < c1, the system is in the fully symmetric
phase. The gating networks do not provide correct partition for the experts at both levels of hierarchy and the experts cannot specialize at all. All the overlaps with the weights of the teacher experts have the same value. The rst phase transition at the smaller c1 is related to the symmetry breaking by the
top-level gating network. Forc1< < c2, the top-level gating network partitions
the input space into two parts, but the lower-level gating networks do not func-tion properly. The experts partially specialize into two groups. At the second transition point c2, the symmetry related to the lower-level hierarchy breaks.
For > c2, all the gating networks work properly and the input space is
di-vided into four. Each expert makes an appropriate pair with an expert of the teacher. The overlap order parameters can now have three distinct values. The two phase transition results in two cusps of the learning curve, which are shown in Fig. 3(b). However, the asymptotic behavior ofg in the limit!1, is also
proportional to 1=.
4 Summary and Discussion
We have studied learning by a population of neural networks and calculated the generalization performance of group decision by majority vote. We have pointed out that a collective decision of the ensemble approach is more useful when the size of example sets is small. With large example sets the networks are too similar to each other, and the advantage of group decision cannot be exploited. Too-standardized an education sometimes ruins the creativity of students.
In the expert approach, the similarity among experts is not important be-cause each expert is trained from local examples. When the training example size is fewer, however, each expert learns from even smaller examples and the gener-alization capability of each network cannot be fully utilized. In learning of the
0 0.2 0.4 0.6 0.8 1 0 50 100 150 200 250 300 α (a) εg 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0 50 100 150 200 250 300 α (b)
Fig.3.(a) Symmetry breaking in the mixture of experts with two-level hierarchy. The
order parameters Rij, that are the overlaps between a student expert and dierent
experts of the teacher, are plotted as a function ofatT = 5:(b) The generalization curve (g versus) for the two-level mixture of experts in the same scale.
`mixture of experts' [5], the gating networks need a certain minimum example size for eective partition of the input space. The expert approach may be more useful, therefore, when a sucient number of training examples are available, whereas the ensemble approach is strong with a limited training example size.
We note that the results of this work suggest a useful direction in using a multiple neural network approach. It would be useful to derive an algorithm to unify the two approaches.
Whereas the phase transition of the mixture of experts can be interpreted as a symmetry-breaking phenomenon, which is similar to the one already observed in the committee machine [10] and the multi-layer perceptron [11], the transition is novel in that it is continuous. This means that symmetry breaking is easier for the mixture of experts than in the multi-layer perceptron. This can be an advantage in learning of highly nonlinear rules as we do not have to worry about the existence of local minima. We nd that the hierarchical mixture of experts can have multiple phase transitions that are related to symmetry breaking at dierent levels. Note that symmetry breaking comes rst from the higher-level branch, which is a desirable property of the model.
We thank M. I. Jordan, L. K. Saul, H. Sompolinsky, H. S. Seung, H. Yoon and C. Kwon for useful discussions and comments.
References
1. M.P. Perrone and L. N. Cooper, Neural Networks for Speech and Image Processing, R. J. Mammone. Ed., Chapman-Hill, London, 1993.
2. D. Wolpert, Neural Networks,5, 241 (1992).
3. H. Drucker, C. Cortes. L. D. Jackel, Y. LeCun, V. Vapnik, Neural Computation6,
1289 (1994).
4. J. B. Hampshire II and A. Waibel, Advances in Neural Information Processing Systems,2, 203, (1990).
5. R. A. Jacobs, N. I. Jordan, S. J. Nolwan, and G. E. Hinton, Neural Computation
3, 79 (1991).
6. M. I. Jordan, and R. A. Jacobs, Neural Computation6, 181 (1994).
7. For reviews, see for example, M. Opper and W. Kinzel, to be published inPhysicsof NeuralNetworks, ed. by J. L. Van Hemmen, E. Domany, and K. Schulten,
(Springer-Verlag, Verlin).
8. E. Gardner, Europhys. Lett.4, 481 (1987); J. Phys. A21, 257 (1988).
9. H. S. Seung, H. Sompolinsky, and N. Tishby, Phys. Rev. A45, 6056 (1992).
10. K. Kang, J.-H. Oh, C. Kwon and Y. Park, Phys. Rev. E48, 4805 (1993).
11. J.-H. Oh, K. Kang, C. Kwon, and Y. Park, in Proceedings of the CTP-PBSRI WorkshoponTheoreticalPhysics:NeuralNetworks,TheStatisticalMechanics