Open Text Archive Server and
Microsoft Windows Azure Storage
Whitepaper
Open Text
2 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Contents
Executive Summary / Introduction ... 4
Overview ... 4
About the Open Text Archive Server ... 5
Architecture ... 5
Scalability and Distribution ... 5
Features of the Open Text Archive Server ... 6
Single Instance Archiving ... 6
Compression ... 6
Encryption of the stored data ... 6
Secure Data Transport ... 6
Data transport secured with checksums ... 6
Retention Handling ... 6
Storage Management ... 7
Logical archives ... 7
Hardware abstraction ... 7
Supported storage media ... 7
Backup, Replication, High Availability and Disaster Recovery ... 7
Backup ... 7
Disaster recovery ... 8
Remote standby ... 8
High Availability ... 8
About Microsoft Windows Azure Storage ... 9
Archive Server integration with Azure Storage ... 10
Business Case... 12
How can Open Text customers profit from the Microsoft Azure Storage? ... 12
What are the benefits for the customer ... 12
Performance Measurements ... 13
Test scenarios ... 13
Test environment ... 13
Host system ... 14
Virtual test clients ... 14
Archive Server ... 15
Network connection ... 15
Performance Results ... 1716
Load on the Archive Server ... 1716
Iteration with 10 kB documents ... 2019
Iteration with 20 kB documents ... 2221
Iteration with 50 kB documents ... 2322
3 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Iteration with 200 kB documents ... 2524
Iteration with 500 kB documents ... 2625
Iteration with 1000 kB documents ... 2726
Improvement options ... Fehler! Textmarke nicht definiert.26 Summary ... 28
Microsoft Windows Azure Update ... 31 About Open Text ... 33
4 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Executive Summary / Introduction
Overview
This white paper describes how the Open Text Archive Server integrates with Microsoft Windows Azure Storage.
Azure Storage is not only a newly supported storage platform for the Archive Server, but also brings new features for the deployment of an ECM environment. Traditional storage platforms are optical jukeboxes or hard disk systems which are installed at customer site. The customer had to purchase the hardware together with maintenance contracts. Besides these investments UPS (uninterruptible power supply), cooling and space in the IT center had to be provided.
Microsoft Azure Storage relieves the customer from buying expensive hardware which after only a few years is out-dated. With Azure Storage the customer gets a virtually unlimited storage through a web service interface.
The performance of local storage will be better than for cloud storage, but for long-term storage cost factors can overweigh high-performance requirements.
5 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
About the Open Text Archive Server
The Open Text Archive Server is a core component of the Open Text ECM Suite and constitutes the archiving foundation for enterprise-wide ECM solutions. It enables storage, ingestion and retrieval of archived content.
The archiving functionality is an integral part of the Open Text Enterprise Library. Open Text offers several connectors to expand the archiving functionality. These connectors allow you to manage business documents in different applications and to link them to the business processes, e.g. Open Text Email Archiving for Microsoft Exchange, Open Text Storage Services for Microsoft SharePoint
Architecture
The Open Text Archive Server comprises multiple services and processes, such as the Document Service, the Administration Server and the Storage Manager. The Document Services provides document management functionality, storage of technical metadata, and secure communication with archiving clients. . The Storage Manager is responsible for managing external devices. The
Administration Server offers an API to administer the archive environment, tools and jobs.
Open Text ArchiveServer Architecture
Scalability and Distribution
The Archive Server is built for enterprise-wide deployments. This means, the Archive Server has:
6 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Strong capabilities to distribute the system to all business regions.
Flexibility to run the system on existing databases and operation systems.
Flexibility to connect the system to existing or new storage hardware. The Archive Server client/server architecture provides versatile options for configuring, scaling and distributing an enterprise-wide archive system.
Features of the Open Text Archive Server
Single Instance Archiving
In groupware scenarios, identical documents can be a risk of wasting storage space when emails with attachments are sent to hundreds of recipients. The Archive Server enables single instance archiving (SIA), keeping the same document only once on the connected storage platform.
Compression
In order to save storage space, content can be compressed before writing to storage system. Compression can be activated different content types, and can reduce storage storage by more than 30 percent.
Encryption of the stored data
By encrypting data, e.g. critical data such as salary tables, content is on the storage is secured and cannot be read without an archive system.
Secure Data Transport
Use of SSL ensures authorized and encrypted communication.
Data transport secured with checksums
Checksums are used to recognize and reveal unwanted modifications to content on its way from creation to the long-term storage. Checksums are verified, and errors reported.
Retention Handling
The Archive Server allows applying retention periods to content. Retention periods are handled by the Archive Server and are passed to the storage platform, as far as the storage platform supports the notion of retention.
7 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Storage Management
Logical archives
A logical archive is an area on the Archive Server in which documents belonging together can be stored. Each logical archive can be configured to represent a different archiving strategy appropriate to the types of documents archived exclusively there.
Logical archives make it possible to store documents in a structured way. You can organize archived documents in different logical archives according to various criteria, e.g.
Compliance requirements
The archiving and cache strategy
Storage platforms
Customer relations (for ASPs)
Security requirements
Hardware abstraction
Key task of the Archive Server is hiding specific hardware characteristics to leading applications, providing transparent access, and optimizing storage resources.
The Archive Server can handle various types of storage hardware; and provides hardware abstraction by offering a unified storage. If a hardware vendor’s storage API changes, or if new versions come up, it’s not necessary to change all the leading applications using the hardware, but only the Archive Server’s interface to the storage device.
Supported storage media
The Archive Server supports a wide range of different storage media and devices. Supported storage media are cloud storage, normal hard disk drive storage, hard disk write-once media and optical media.
Backup, Replication, High Availability and Disaster
Recovery
Backup
Power outages, physical damage, outdated media, hardware faults or usage errors can unexpectedly shut down IT operations at any time. Archive Server provides a variety of options to optimize the availability of the business documents.
8 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
Archive Server can create copies of volumes as backups. The copies may be produced on the local archive server or on a remote backup or standby server. To avoid losing data in the event of a hard disk failure and resume using Archive Server immediately, we recommend using RAID (Redundant Array of
Independent Disks) technology as an additional data backup mechanism. In addition to document content, administrative information is synchronized between original and backup systems.
Disaster recovery
The Archive Server stores the technical meta data together with content on the storage media (e.g. DocId, aid, timestamp, …). This allows Archive Server to completely restore access to archived documents in case the Archive Server hardware has a major breakdown or has been destroyed.
Remote standby
With a remote standby server, all the documents in an archive are duplicated on a second Archive Server —the remote standby server—via a WAN connection for geographic separation. If the production Archive Server fails, the remote standby server continues to provide read-access to all the documents. Physically
separating the two servers also provides optimal protection against fire, flood and other catastrophic loss.
High Availability
To eliminate long downtimes, the Archive Server offers active-passive high availability.
High availability is a two node cluster solution, in which a fully-equipped Archive Server node monitors the current production system by heart-beat. If a node fails, the other node automatically assumes all activities, with full transparency for end users.
If the production system fails, users can continue to work normally on the secondary archive system. In contrast to the remote standby server scenario, both read (retrieval) and write (archiving) access to documents is possible in this configuration.
9 | M ic r o s o f t W in d o w s A zu r e P la t f o r m W h it e P a p e r
About Microsoft Windows Azure Storage
Describe the properties and features of Azure Storage1 0 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Archive Server integration with Azure
Storage
The Archive Server treats Microsoft Windows Azure Storage as a storage device where single documents can be stored. To configure the connection to Azure Storage a file <device>.Setup has to be configured.
The *.Setup file (e.g. azure.Setup) is the link between the Archive Server and the Azure system. It contains all necessary information to access the Azure servers. The first line contains the connection info, which is needed to load the
corresponding Azure library. This library is provided by Open Text, and establishes the connection to the Azure storage.
If installed and configured correctly, you will see an entry in Administration Client under Devices showing the Azure storage device.
Storage space in Archive Server devices can be accessed through volumes. Volumes are attached to logical archives, thus providing dedicated storage space to logical archives.
Volumes in Azure devices are closely related to Azure containers. A container is basically the top-level directory in an Azure cloud data is being stored in. One or more volumes can be associated with one Azure container. Linkage between Azure containers and volumes is configured in the Setup file. Actually so-called GS-partitions are linked to the containers. GS-partitions have a one-to-one relation to Archive Server volumes.
To access an Azure container an account name and access key is necessary.
The following picture shows an Azure device names “OTCloud”. Five volumes are configured.
11 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 1 Configuration of Microsoft Windows Azure as storage device
The volumes market_vol1, market_vol2, market_vol3 are used in the logical archive HH_LA_4.
1 2 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Business Case
How can Open Text customers profit from the Microsoft
Azure Storage?
Any customer using an application based on the Open Text ECM Suite and the Archive Server is a candidate for using Azure Storage. Customers have to upgrade to Archive Server 9.7.1. Use of Azure Storage is not restricted to Microsoft Windows platforms, but also available for Unix OS, such as Sun Solaris, IBM AIX, HP HP-UX and Linux. The Archive Server runs on-premise at customer site whereas the Azure Storage is provided over the Internet.
To use Azure Storage customers need to contact Microsoft for an account. With the account the customer can configure the storage environment (see page 10) and start using the cloud.
The Archive Server comes with an in-built Volume Migration tool which allows transparently migrating existing content on local hardware to the Azure Storage.
What are the benefits for the customer
The customer only buys what he needs and can grow continuously. He has only to pay for the storage space in use and the upload and download traffic.
With Azure Storage customers have a small initial investment, no maintenance fees and pay only for what you really need.
1 3 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Performance Measurements
Performance tests were done by using the Open Text XOTE test tool.
The XOTE test tool is an internal test suite developed by the Open Text Quality Assurance department to run performance and benchmark tests with the Archive Server and storage platforms. The tool allows creating arbitrary documents of different size; supports automated test scenarios and collects result for evaluation in log files.
Within the benchmark test the following test cases were set up.
Test scenarios
1. Write documents to the disk buffer
2. Read documents from the disk buffer (verify)
3. Write the documents to the Microsoft Windows Azure
4. Purge documents from disk buffer (not evaluated in this white paper) 5. Read documents from Microsoft Windows Azure
6. Delete documents from Microsoft Windows Azure The tests were performed with different documents sizes.
# of documents Document size
20’000 10 kB
10’000 20 kB
10’000 50 kB
5’000 100 kB
5’000 200 kB
2’000 500 kB
2’000 1’000 kB
Measured times are extracted from the log files of the tool with a precision of milliseconds. The start and end times are given in GMT+1 (CET).
Test environment
The test setup consists of one Archive Server 9.7.1 connected to Microsoft Windows Azure storage.
1 4 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Microsoft Windows Azure is configured as storage device on the Archive Server, and documents are written to the storage by using a so-called “Single file” pool. Compression and single instance archiving are disabled. The pool is configured with 15 threads to OT Azure library, and 15 connections were configured for the connection between the OT Azure library and Microsoft Windows Azure. SSL was used to connect to Microsoft Azure Storage.
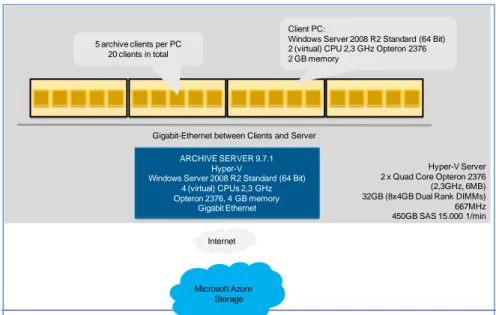
Figure 3Archive Server and Microsoft Windows Azure connection
There are four test PCs each hosting 5 virtual clients that send parallel read and write request to the Archive Server. In sum, 20 parallel clients send read and write requests.
All servers are hosted on a Hyper-V server with Microsoft Windows 2008 Server as operating system.
Host system
2 x Quad Core Opteron 2376 (2,3GHz, 6MB) 32GB (8x4GB Dual Rank DIMMs) 667MHz 450GB SAS 15.000 1/min
Gigabit Ethernet network
Virtual test clients
Windows Server 2008 R2 Standard (64 Bit) 2 (virtual) CPU 2,3 GHz Opteron 2376 2 GB memory
ARCHIVE SERVER
MICROSOFT AZURE STORAGE
Document Service
libAzure http client
http server
15 connections
1 5 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Archive Server
Version 9.7.1, Patch AS097-057
Windows Server 2008 R2 Standard (64 Bit) 4 (virtual) CPU 2,3 GHz Opteron 2376 4 GB memory
Network connection
The Archive Server is connected via a Gigabit Ethernet to the Open Text network in Munich/Germany. The Open Text network (Ethernet backbone) connects via the Internet (155 Mbit) to the cloud storage stored in South US. Therefore, the latencies and throughput from the Archive Server to Windows Azure is dominated by a combination of (a) the connection between Munich and South US, (b) the bandwidth between the two sites..
Hyper-V Server 2 x Quad Core Opteron 2376 (2,3GHz, 6MB) 32GB (8x4GB Dual Rank DIMMs)
667MHz 450GB SAS 15.000 1/min
ARCHIVE SERVER 9.7.1 Hyper-V
Windows Server 2008 R2 Standard (64 Bit) 4 (virtual) CPUs 2,3 GHz Opteron 2376, 4 GB memory
Gigabit Ethernet
Client PC:
Windows Server 2008 R2 Standard (64 Bit) 2 (virtual) CPU 2,3 GHz Opteron 2376 2 GB memory
5 archive clients per PC 20 clients in total
Gigabit-Ethernet between Clients and Server
Microsoft Azure Storage Internet Location: Munich, Germany
1 6 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 4 Test environment and deployment
Hyper-V Server 2 x Quad Core Opteron 2376
(2,3GHz, 6MB) 32GB (8x4GB Dual Rank DIMMs) 667MHz 450GB SAS 15.000 1/min
ARCHIVE SERVER 9.7.1 Hyper-V
Windows Server 2008 R2 Standard (64 Bit) 4 (virtual) CPUs 2,3 GHz Opteron 2376, 4 GB memory
Gigabit Ethernet
Client PC:
Windows Server 2008 R2 Standard (64 Bit) 2 (virtual) CPU 2,3 GHz Opteron 2376 2 GB memory
5 archive clients per PC 20 clients in total
Gigabit-Ethernet between Clients and Server
Microsoft Azure Storage Internet
1 7 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Performance Results
Load on the Archive Server
The following figures show the load of the server during the different phases. These figures didn’t change with different document size.
Figure 5 Archive Server taskmanger during archiving documents to the disk buffer
1 8 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 7 Archive server taskmanger during writing documents to the Azure
1 9 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 9 Archive server taskmanger during verifying documents from Microsoft Windows Azure
2 0 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 10 kB documents
The minimum and maximum values for the different scenarios can vary
extremely. This can be due to temporary additional load on the server or on the network.
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 19,75 < 16 297
Read from disk buffer 87,25 16 656
Write to Azure 1.239,89 1.190 2.846
Read from Azure 825,25 578 11.327
Delete from Azure 1.153,75 828 2.969
Table 1 Overview on results for 10 kB documents
Iteration duration for 20.000 documents: 6,5 hours
Start: 2009-11-13 22:11:54 (Fri) End: 2009-11-14 04:32:12 (Sat)
The cause for the maximum value is unknown. The average was calculated over 20.000 documents. The minimal value (578 ms) for reading from Azure is an upper boundary for the latency time.
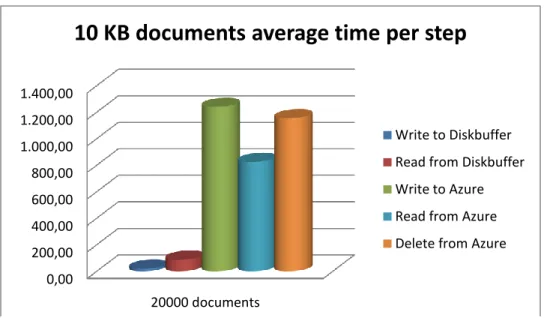
In the Figure 11 the average time per step during the test is shown in a graphical view.
2 1 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 11 Graphical overview on results for 10 kB documents 0,00
200,00 400,00 600,00 800,00 1.000,00 1.200,00 1.400,00
20000 documents
10 KB documents average time per step
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 2 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 20 kB documents
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 20,00 < 16 344
Read from disk buffer 121,25 16 39.059
Write to Azure 1.213,52 1.170 2.441
Read from Azure 822,50 578 22.048
Delete from Azure 1.125,75 827 2.375
Table 2 Overview on results for 20 kB documents
The Figure 12 shows the values of Table 2 in a graphical view.
Figure 12 Graphical overview on results for 20 kB documents
Iteration duration for 10.000 documents: 6,5 hours.
Start: 2009-11-13 22:11:54 (Fri) End: 2009-11-14 04:32:12 (Sat)
0,00 200,00 400,00 600,00 800,00 1.000,00 1.200,00 1.400,00
10000 documents
20 KB documents average time per step
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 3 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 50 kB documents
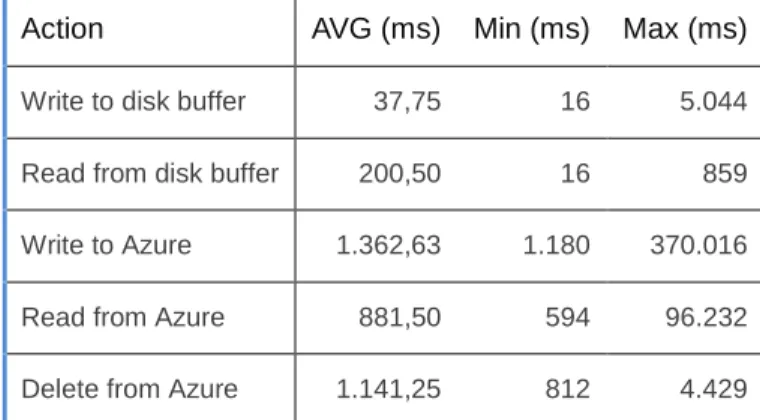
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 37,75 16 5.044
Read from disk buffer 200,50 16 859
Write to Azure 1.362,63 1.180 370.016
Read from Azure 881,50 594 96.232
Delete from Azure 1.141,25 812 4.429
Table 3 Overview on results for 50 kB documents
The graphical overview is shown in Figure 5 below.
Figure 13 Graphical overview on results for 50 kB documents
Iteration duration for 10.000 documents: approx. 7 hours.
Start: 2009-11-07 11:31:44 (Sat) End: 2009-11-07 18:12:24 (Sat)
0,00 200,00 400,00 600,00 800,00 1.000,00 1.200,00 1.400,00
10000 documents
50 kB documents
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 4 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 100 kB documents
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 54,25 16 328
Read from disk buffer 350,50 31 906
Write to Azure 1.402,12 1.354 4.332
Read from Azure 1.310,25 828 6.874
Delete from Azure 1.114,00 797 2.531
Table 4 Overview for 100 kB documents
Figure 14 Graphical overview for 100 kB documents
The graphic shows that the read request is longer than the delete request and almost as long as the write request.
The following iterations show that the time of the read process will increase with file size.
Iteration duration for 5.000 documents: approx. 7 hours
Start: 2009-11-07 21:16:57 (Sat) End: 2009-11-08 04:17:31 (Sun)
0,00 200,00 400,00 600,00 800,00 1.000,00 1.200,00 1.400,00 1.600,00
5000 documents
100 kB documents
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 5 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 200 kB documents
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 91,00 47 4.218
Read from disk buffer 707,50 78 20.499
Write to Azure 1.650,55 1.549 3.839
Read from Azure 2.269,25 1.203 36.934
Delete from Azure 935,75 811 2.577
Table 5 Overview for 200 kB documents
As already described in the iteration of 100 kB documents the time consumption of the read process is growing significantly with the size of the documents.
Figure 15 Graphical overview on results for 200 kB documents
Iteration duration for 5.000 documents: approx. 10,5 hours. Start: 2009-11-08 11:47:28 (Sun)
End: 2009-11-08 22:13:38 (Sun)
0,00 500,00 1.000,00 1.500,00 2.000,00 2.500,00
5000 documents
200 kB documents
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 6 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 500 kB documents
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 199,00 156 1.172
Read from disk buffer 1.551,75 202 2.906
Write to Azure 2.530,55 2.221 6.773
Read from Azure 4.016,50 2.125 10.826
Delete from Azure 1.089,75 811 2.250
Table 6 Overview of time per step for 500 kB documents
The graphical overview is shown in Figure 16.
Figure 16 Graphical overview on results for 500 kB documents
Iteration duration for 2.000 documents: approx. 10 hours.
Start: 2009-11-09 19:58:19 (Mon) End: 2009-11-10 06:10:26 (Tue)
0,00 500,00 1.000,00 1.500,00 2.000,00 2.500,00 3.000,00 3.500,00 4.000,00 4.500,00
2000 documents
500 kB documents
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 7 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Iteration with 1000 kB documents
Action AVG (ms) Min (ms) Max (ms)
Write to disk buffer 383,75 328 1.484
Read from disk buffer 3.281,50 484 4.453
Write to Azure 3.866,18 2.544 5.511
Read from Azure 7.249,75 3.952 13.405
Delete from Azure 1.074,00 828 3.154
Table 7 Overview on results for 1000 kB documents
The graphical overview is shown in Figure 16.
Figure 17 Graphical overview on results for 1000 kB documents
Iteration duration for 2.000 documents: 11 hours:
Start: 2009-11-13 10:21:04 (Fri) End: 2009-11-13 21:09:09 (Fri)
0,00 1.000,00 2.000,00 3.000,00 4.000,00 5.000,00 6.000,00 7.000,00 8.000,00
2000 documents
1.000 kB documents
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
2 8 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Summary
Any interpretation of the results has to be done with care. There are a lot of known and unknown parameters influencing the results.
The following parameters can influence the results:
Throughput capacity and variations acrossof the internet is unknown
Variation of throughput capacity during time of day is unknown
Performance dependency on number of http client connections is unknown. Because of the high network latency times (response time) the throughput strongly depends on the number of parallel requests, i.e. the number of parallel http connections.
Outlook
The results show that the Internet latency seems to be limiting factor for write and read requests. To proof the assumption and to overcome this factor several steps are possible.
Client and Archive Server installation in the U.S. or use a European data center with the clients in Munich.
As read performance from Azure Storage decreases with document size, a cache implementation on the Archive Server can improve the performance for larger documents.
2 9 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
time in msec size 10 KB 20 KB 50 KB 100 KB 200 KB 500 KB 1000 KB
Write to Diskbuffer 20 20 38 54 91 199 384
Read from Diskbuffer 87 121 201 351 708 1.552 3.282 Write to Azure 1.240 1.214 1.363 1.402 1.651 2.531 3.866 Read from Azure 825 823 882 1.310 2.269 4.017 7.250 Delete from Azure 1.154 1.126 1.141 1.114 936 1.090 1.074 Table 8 Overall measurement results
The following graphic shows an overall view on the different test runs.
Figure 18 Overall view of benchmark tests with Microsoft Windows Azure
The following findings can be deduced from Figure 18:
Read and write requests to local disk are significantly faster than requests sent to the cloud.
The average time to write documents increases slightly with larger files. This applies to writing to the disk buffer as well as to writing to Microsoft Windows Azure.
The increase of dependency on document size is higher for write requests from the cloud compared to local disk. This is probably due to the latencies for the http requests and network bandwidth.
0 1.000 2.000 3.000 4.000 5.000 6.000 7.000 8.000
0 500 1000
Ti m e in m s
Document size in kB
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
3 0 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
The deletion of the documents is mainly independent of the document size. The time is constant over the different iterations.
The document retrieval (read) time increases for documents larger than 64 kB. This applies to reading from the disk buffer as well as to reading from the cloud. This affect is due to the fact that the Archive Server reads
documents in 64 kB chunks. This effect did not matter up to now, as it only gets significant if latency times are high. The problem could be resolved by implementing a read cache on the Archive Server.
Figure 19 Write rates for Microsoft Windows Azure
The write rate to Azure is calculated from the number of connections to Azure, document size and write time per document.
Write Rate = # of connections/write time * document size
The number of connections for writing was 15.
The rate did not yet reach the saturation, i.e. more connections or larger documents could lead to higher write rates.
0,00 0,50 1,00 1,50 2,00 2,50 3,00 3,50 4,00 4,50
0 200 400 600 800 1000
Wr ite r ate in M B /sec
Document size in kB
3 1 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Read Rate = # of clients/read time * docsize
# of clients for reading was: 20
The decrease of the rate for 20 kb documents is unclear. Due to 64 kB block reads the read rate is lower than the write rate.
Microsoft Windows Azure Update
On November 11th 2009 Microsoft released a new version of Windows Azure. Open Text was not aware of the upgrade, and some tests were already
performed with the new release. The results did not show a significant change.
The following diagram shows a representation of the results in a logarithmical manner. This allows a better overview on the results for small documents.
0,00 0,50 1,00 1,50 2,00 2,50 3,00
0 200 400 600 800 1000
R
e
ad
r
ate
in
M
B
/sec
Document size in KB
3 2 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
Figure 20 Overall view of benchmark test with Microsoft Windows Azure Cloud Storage (logarithmical) 1
10 100 1.000 10.000
0 200 400 600 800 1000
Ti
m
e
in
m
s
Document size in kB
Write to Diskbuffer Read from Diskbuffer Write to Azure Read from Azure Delete from Azure
3 3 | M ic r o s o f t W in d o w s A zu r e P l a t f o r m W h it e Pa p e r
w w w.
o p e n t e x t
. c o m
For more information about Open Text products and services, visit www.opentext.com. Open Text is a publicly traded company on both NASDAQ (OTEX) and the TSX (OTC). Copyright © 2009 by Open Text Corporation. Open Text and The Content Experts are trademarks or registered trademarks of Open Text Corporation. This list is not exhaustive. All other
trademarks or registered trademarks are the property of their respective owners. All rights reserved. SKU#_EN
About Open Text
Open Text is a leader in Enterprise Content Management (ECM). With two decades of experience helping organizations overcome the challenges
associated with managing and gaining the true value of their business content, Open Text stands unmatched in the market.
Together with our customers and partners, we are truly The Content Experts,™ supporting 46,000 organizations and millions of users in 114 countries around the globe. We know how organizations work. We have a keen understanding of how content flows throughout an enterprise, and of the business challenges that organizations face today.
It is this knowledge that gives us our unique ability to develop the richest array of tailored content management applications and solutions in the industry. Our unique and collaborative approach helps us provide guidance so that our customers can effectively address business challenges and leverage content to drive growth, mitigate risk, increase brand equity, automate processes, manage compliance, and generate competitive advantage. Organizations can trust the management of their vital business content to Open Text, The Content Experts.