Improving Data Grids Performance by using Modified
Dynamic Hierarchical Replication Strategy
N. Mansouri* and Gh. Dastghaibyfard** (C.A.)
Abstract: A Data Grid connects a collection of geographically distributed computational and storage resources that enables users to share data and other resources. Data replication, a technique much discussed by Data Grid researchers in recent years creates multiple copies of file and places them in various locations to shorten file access times. In this paper, a dynamic data replication strategy, called Modified Dynamic Hierarchical Replication (MDHR) is proposed. This strategy is an enhanced version of Dynamic Hierarchical Replication (DHR). However, replication should be used wisely because the storage capacity of each Grid site is limited. Thus, it is important to design an effective strategy for the replication replacement task. MDHR replaces replicas based on the last time the replica was requested, number of access, and size of replica. It selects the best replica location from among the many replicas based on response time that can be determined by considering the data transfer time, the storage access latency, the replica requests that waiting in the storage queue, the distance between nodes and CPU process capability. Simulation results utilizing the OptorSim show MDHR achieves better performance overall than other strategies in terms of job execution time, effective network usage and storage usage.
Keywords: Access Pattern, Data Grid, Data Replication, Simulation.
1 Introduction1
Millions of files will be generated from scientific applications and researchers around the world need access to the large data [1-6]. It is difficult and inefficient to store such huge amounts of data using a centralized storage. Grid technology is the best solution to this kind of problem. The main objective of the Grid Project is to provide sharing of computing and storage resources by users located in different part of the world. Grid can be divided as two parts, Computational Grid and Data Grid. Computational Grids are used for computationally intensive applications that require small amounts of data. But, Data Grids deals with the applications that require studying and analyzing massive data sets [7-10]. Replication technique is one of the major factors affecting the performance of Data Grids by replicating data in geographically distributed data
Iranian Journal of Electrical & Electronic Engineering, 2014. Paper first received 20 June 2012 and in revised form 6 Oct. 2013. * The Author is with the Department of Computer Science, Shahid Bahonar University of Kerman, 22 Bahman Bolvar, Kerman, Iran. ** The Author is with the Department of Computer Science and Engineering, College of Electrical & Computer Engineering, Shiraz University, Molla Sadra Avenue, Shiraz, Iran.
E-mails: [email protected], [email protected] and [email protected].
stores. There are three key issues in all the data replication algorithms as follows:
• Replica selection: process of selecting replica among other copies that are spread across the Grid.
• Replica placement: process of selecting a Grid site to place the replica.
• Replica management: the process of creating or deleting replicas in Data Grid.
Meanwhile, even though the memory and storage size of new computers are ever increasing, they are still not keeping up with the request of storing large number of data. The major challenge is a decision problem i.e. how many replicas should be created and where replicas should be stored. Hence methods needed to create replicas that increase availability without using unnecessary storage and bandwidth. In this work a novel dynamic data replication strategy, called Modified Dynamic Hierarchical Replication (MDHR) algorithm is proposed. This strategy is an enhanced version of Dynamic Hierarchical Replication strategy. According to the previous works, although DHR makes some improvements in some metrics of performance like mean job time, it shows some deficiencies. Replica selection and replica replacement strategies in DHR strategy are not very efficient. But MDHR algorithm
28 Iranian Journal of Electrical & Electronic Engineering, Vol. 10, No. 1, March 2014 deletes files in two steps when free space is not enough
for the new replica: First, it deletes those files with minimum time for transferring (i.e. only files that are exist in local LAN and local region). Second, if space is still insufficient then it uses three important factors into replacement decision: the last time the replica was requested, number of access, and file size of replica. The number of requests and the last time the replica was requested define an indication of the probability of requesting the replica again. It also improves access latency by selecting the best replica when various sites hold replicas. The proposed replica selection selects the best replica location from among the many replicas based on response time that can be determined by considering the data transfer time, the storage access latency, the replica requests that waiting in the storage queue, the distance between nodes and CPU process capability. The proposed algorithm is implemented by using a Data Grid simulator, OptorSim developed by European Data Grid project. The simulation results show that our proposed algorithm has better performance in comparison with other algorithms in terms of job execution time, effective network usage and storage resource usage.
The rest of the paper is organized as follows: Section 2 presents some examples motivating Data Grid use. In section 3 the classification of data replication strategies is briefly explained. Section 4 explains some advantages of data replication strategies. Section 5 gives an overview of pervious work on data replication in Data Grid. Section 6 presents the novel data replication strategy. We show and analyze the simulation results in section 7. Finally, section 8 concludes the paper and suggests some directions for future work.
2 Motivation
Nowadays large volume data are generated in many fields like scientific experiments and engineering applications. The distributed analysis of these amount data and their dissemination among researchers located over a wide geographical area needs important techniques such as Data Grid.
For example, the high-energy physics experiment requires a lot of analyses on huge amounts of data sets. CERN is the world’s largest particle physics center [11]. The LHC (Large Hadron Collider) at CERN will start to work in 2007. The volume of data sets produced by the LHC is about 10 PB a year. CERN has used the Grid technique to solve this challenging huge data storage and computing problem.
Climate models are important to find climate changes and they are improved after today’s models are completely analyzed [12]. Climate models require large computing capability and there are only a few sites world-wide that are appropriate for executing these models. Climate scientists are distributed all over the world and they test the model data. Now, model analysis is done by transferring the data of interest from
the computer modeling site to the climate scientist’s organization for different post-simulation analysis tasks. The effective data distribution method is necessary to the climate science when the data volume is large.
The Biomedical application field [13] wants to use the Grid to help the archiving of biological objects and medical images in distributed databases, communications between hospitals and medical organization and to present distributed access to the data. Hence, data movement is essential. The Earth observation application area investigates the nature of the planet’s surface and atmosphere. One application of Grid technique is for the analyzing and validation of ozone profiles. The processed data sets is scattered to other places worldwide. Use cases for Earth observation science applications are explained in more detail in Ref. [14].
The Human Genome Project [15] produces detailed genetic and physical maps of the human genome. The project requires advanced means of making novel scientific information widely available to researchers so that the results may be used for the public good. Data Grid project is funded by the European Union [16]. A Data Grid consists of a group of geographically distributed computational and storage resources placed in various locations, and enables users to share data and other resources [17-20].
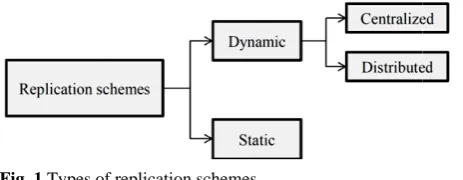
3 Classification of Data Replication Strategies Generally, replication algorithms are either static or dynamic as shown in Fig. 1. In static approaches the created replica will exist in the same place till user deletes it manually or its duration is expired. The disadvantages of the static replication strategies are that they cannot adapt to changes in user behavior and they are not appropriate for huge amount of data and large number of users. Of course static replication methods have some advantages like: they do not have the overhead of dynamic algorithms and job scheduling is done quickly [21, 22]. On the other hand, dynamic strategies create and delete replicas according to the changes in Grid environments, i.e. users’ file access pattern [23-27]. As Data Grids are dynamic environments and the requirements of users are variable during the time, dynamic replication is more appropriate for these systems [28]. But many transfers of huge amount of data that are a consequence of dynamic algorithm can lead to a strain on the network’s resources. So, inessential replication should be avoided. A dynamic replication scheme may be implemented either in a centralized or in a distributed approach. These methods also have some drawbacks such as; the overload of central decision center further grows if the nodes in a Data Grid enter and leave frequently. In case of the decentralized manner, further synchronization is involved making the task hard.
Fig. 1 Types o
4 Advanta Availabil improve ava system can other site. In Reliability the probabi completely, a Scalabilit provided by dependent on Grid than rep
Adaptabi changeable a time. The da the informat provide bette Performa Grid systems a user can ac
5 Related W Foster an replica strate Replication, Replica and also introduc • Tem are shor • Geo rece requ • Spa acce near These s patterns: firs data access w finally data a geographical indicate that replica strate the best in th different sch
Rahman e selection by Nearest Neig
of replication sc
ges of Data R lity: All the r ailability. Whe resort to rep
this manner t ty: The more t ility that us and hence a sy ty: This is a k a replication n architecture plication strate ility: The na and users can ata replication tion of the G er results. ance: One wa s is to store re ccess the data
Works nd Ranganath
egies: No Re Plain Cachin Fast Spread) ced three types mporal locality much possi rtly.
ographical lo ently by a uested by adja atial locality: essed file are r future. trategies eva st, access patt with a small d access with a l locality. T t different ac egies. Cascadi
he simulation eduling and re et al. [29] pro y using a sim
ghbor (KNN) chemes.
Replication St replication st en a fail happ plicated data the availability the number of ser’s request
ystem is more key paramete n strategy. Sc e model selec
egy.
ature of the n enter and qu n strategy mu Grid environm
ay to speed u eplicas at mult from the near
an [28], prop plica, Best C ng, Caching for multi-tier s of localities, y: The files a ible to be
ocality: The client are p acent clients, t
The related likely to be
aluated with tern with no degree of temp
small degree The results ccess pattern ing and Fast S
s. Also, the a eplication stra oposed an algo mple techniqu ). The KNN
trategies trategies want pen in any sit
that is stored y increases. f replicas mor
will be d e reliable. er which must
alability is m cted for the D
e Grid is v uit a Grid at st be adaptive ment in order
up access in d tiple locations rest site.
posed six disti Client, Cascad plus Cascad Data Grid. T , namely: accessed recen requested ag files acces probably to too.
files to recen requested in
different d locality. Seco poral locality of temporal of simulati needs differ Spread perform authors combi ategies. orithm for rep ue called the rule chooses t to e, a d at re is done t be more Data very any e to r to data s, so inct ding ding hey ntly gain ssed be ntly the data ond, and and ions rent med ned lica e k- the bes log the pre tec fro stra gua pra cac dis the rep site per tim sim alg rep and the dat a r the thr nod sys his do res ban bec int int ‘im sca a pro det dat als env the can inc on stra Pop per cha pop var beh dis
st replica for gs. They also e transfer tim ediction error chniques. Acco om a site whic
In [30] the ategy that ha arantee and c actical manne ching strategy stributed syste eir distributed plicas, each G e. This can rformance be me and bandw
mulation demo gorithm signif plication strate Tang et al. [3 d Aggregate B e average dat
ta grid. The m replica to nod e file’s acces reshold. SBU
de, but ABU stem. With storical access the same un sults show tha
ndwidth con cause its aggre
Andronikou eroperable ne o account the mportance’ of alable and the Grid environ oposed QoS-termines the ta request, co so places of vironment acc e overhead th
n handle the creasing or de the number a
Lee et al. [34 ategy for a pular File R riodically com anges of user pular files to riation. They haviors, inclu stributions, to
r a file by us suggested a p me between r as reported
ordingly, one h has minimu authors pre as a provabl can be implem
er. They als y, which can em such as Da d strategy is th Grid site keeps
n dramatical ecause transfe
width consum onstrated that ficantly outpe egy under vari 32] presented Bottom-Up (A a access resp main idea of th des close to i
ss rate is h uses the fil aggregates th ABU, a no s records to its ntil these rec at ABU impro sumption bet egation capab et al. [3 ew data repli infrastructura f the data.
strategies can nment to pro -aware dyna number of r ntent importa f the new r cording to th at the replica e dynamicity
ecreasing the and the geogra 4] presented a star-topology Replicate Fir mputes file acc rs’ access beh o suitable clu considered s uding Zipf-lik evaluate PFR
sing previous predictive wa sites and d by using Neu site can reque um transfer tim esented a dat
e theoretical mented in a di
o proposed n be easily a ata Grids. The hat when ther s track of its c lly enhance erring large-s ming [31]. Th
the distribute erforms a pop ious network Simple Botto ABU) strategie ponse time fo
he two strateg ts requesting igher than a e access hist he file access ode transmits s top tiers, and cords reach t oves job respo
tter than tho bility.
3] proposed ication strateg al constraints
The presente n be easily im ovide fast ex amic replicat eplicas requir ance and requ
replicas with he network ba ation techniqu of the Grid set of data r aphy of the da an adaptive da y Data Grid rst algorithm cess popularit haviors, and th usters/sites to everal types o ke, geometric,
RF. The simu
s file transfer ay to estimate decreased the ural Network est the replica me.
ta replication performance istributed and a distributed adopted in a e key point of re are several closest replica Data Grid sized files is he results of ed replication pular existing parameters. om-Up (SBU)
es to improve or a multi-tier gies is to store clients when a pre-defined tory for each history for a s aggregated d the top tiers the root. The onse time and ose of SBU
d a set of gies that take as well as the ed system is mplemented on xecution. The tion strategy red based on uested QoS. It hin the Grid andwidth and ue presents. It d system by replicas based ata demands.
ata replication d, called the m (PFRF). It ty to track the hen replicates adapt to the of file access and uniform ulation results r e e k a n e d d a f l a d s f n g ) e r e n d h a d s e d U f e e s n e y n t d d t y d n e t e s e s m s
30 demonstrate turnaround ti Saadat et replication s Dynamic Da (PDDRA). P and pre-repli prediction is of the Grid s files, it will show that t execution tim replications, Taheri et optimization Bee Colony operations computationa storage elem independent, (i.e., makesp heterogeneou Three tailor-m are applied t compare it w JDS-BC’s scenarios. JD making beha its objectives optimizing th Mansouri Dynamic Hi store replica has been acc sites. It also best replica proposed rep replica loca considering storage and show, it has other strateg comparativel Park et a based Repli access time avoiding net into several r the regions regions. So region, its fe two deficien within the re in all the req strategy has of storage el extension of
that PFRF ime and bandw
t al. [35] pre trategy which ata Replicatio PDDRA predic icates them be done based o sites. So when get them lo this strategy me, effective
hit ratio and p al. [36] prop strategy, call (JDS-BC). JD
to efficien al elements ments in a , and in many pan and transfe us systems made test Gri o evaluate the with other str
superiority DS-BC also p avior, where i s (e.g., transf he other one ( i and Dastg erarchical Re a in suitable s
cessed most, i decreases ac when differ plica selectio ation for th the replica data transfer less job execu gies especiall
ly small storag al. [38] prese cation (BHR by maximizin twork conges regions, wher is lower tha if the require etching time w ncies, first it egion and seco quested sites n
good perform lement is sma f BHR [38] st
Iran F can reduc
width consum esented a new h is called Pr on Algorithm cts future requ efore needs ar
on the past fi n a Grid site ocally. The si improves in e network us
percentage of osed a new B led Job Data S
DS-BC has tw ntly schedu
and replicat system so y cases confli er time of all d
are concurre ids varying fro e performance rategies. Resu under diffe presented a b
it occasionall fer time) to o e.g., makespa ghaibyfard [3 eplication (DH
sites where th instead of stor ccess latency rent sites hol on strategy c he users’ ru requests that time. The si ution time in y when the ge size. ented a Band R) which dec
ng network-le stions. They d re network ban an the bandw ed file is pla will be less. B
terminates, ond replicated not the approp mance only w
all. Modified trategy which
nian Journal o ce average mption.
w dynamic d re-fetching ba m in Data Gr uires of Grid s re requested. T
ile access hist requests a se imulation res n terms of sage, number storage filled Bee Colony ba Scheduling us wo collaborat ule jobs o te data sets
that the t icting, objecti datafiles) of s ently decreas om small to la e of JDS-BC ults showed t erent operat alanced decis ly relaxes one obtain more fr an).
37] presented HR) strategy t he particular ring file in m by selecting ld replicas. T chooses the b unning jobs t waiting in
imulation res comparison w
Grid sites h
dwidth Hierar creases the d
evel locality divided the s ndwidth betw width within aced in the sa BHR strategy if replica ex d files are pla priate sites. B when the capa BHR [39] is h replicates a
of Electrical & job data ased rids sites This tory t of ults job r of d. ased sing ting onto on two ives uch sed. arge and that ting sion e of rom d a that file many the The best by the ults with have rchy data and sites ween the ame has xists aced BHR city s an file tha nea stru [40 tha am has Sim Th (Le the res site 6 and Fig lev thr com reg to (sit eac 6 DH req siz can ban req tha rep Fig
& Electronic E at has been ac
ar future. A replicatio ucture and a 0]. They cons at has three le mong the cand
s the highes milarly, it use his leads to a b east Recently eir algorithm spectively. Be e) with most o
Proposed Dy In this sectio d then the DH
The Grid top g. 2. The hie vels. First le rough internet mprises LAN gion that has m
the first leve tes) within e ch other with
6.2 Dynamic In previous w HR strategy quested file si ze, file will
ndidate replic ndwidth to the quests. It also at has the high plica.
g. 2 Grid topolo
Engineering, V ccessed most
on algorithm scheduling a sidered a hier
evels. In thei didate replicas st bandwidth es the same t better perform Used) method selects the b est region (LA of the requeste
ynamic Repli on, first netw HR and MDHR
6.1 Network pology of sim erarchical net evel are Reg t i.e. have low N’s (local ar
moderately hig el. Finally the
ach the LAN a high bandw
Hierarchical work, we prop first checks ize is greater t be accessed cas selects the
e requester no places replica hest number o
ogy in the simul
Vol. 10, No. 1 and it may al
for a 3-lev algorithm are rarchical netw r replica sele s they selected h to the re technique for mance compari d. For efficien best region, L AN, site) is a r
ed files.
ication Algor work structure R algorithms a
k Structure mulated platfor
twork structu gions that ar w bandwidth. rea network)
gher bandwid e third level a N’s, that are width.
l Replication posed DHR al replica feasi than SE (Stor remotely. It e one that ha ode and has lea
as in best site of access for t
lation.
, March 2014 lso be used in
vel hierarchy e proposed in work structure ection method d the one that equested file. file deletion. ing with LRU nt scheduling, LAN and site region (LAN,
rithm e is described
are presented.
rm is given in ure has three re connected Second level within each dth comparing are the nodes connected to
Algorithm lgorithm [37]. ibility. If the rage Element) t among the as the highest ast number of s i.e. best site that particular 4 n y n e d t . . U , e , d n e d l h g s o . e ) e t f e r
If the ava requested fil files should minimum tim exist in local
6.3 Modi
MDHR a 1. Replica Se of file, there the best repli location is th factors are us • Stor The stora have a key r calculated by 1 F T Storage = StorageSp FileSize repr • Wai Each stor time and the time. So, one the storage q equation:
∑
==
n i iT
T 0 2where n is nu • Dist D(x,y) rep and y. Comp route comm information c the first time
• CPU
CPU proc
CP
C= ×F U where F is th
1 2 T = +T T
( , )
F x y =w
This func a weighted c The proper empirically. equations interrelations
ailable space in le size, it rep
be deleted. me for transfe l LAN and loc
ified Dynamic Alg algorithm has election: Whe is a significan ica. Replica s he best for th sed to choose rage access la age media spe ole in the ave y the followin
( )
( /
FileSize MB eSpeed MB Speed shows t
resents size of iting time in th rage media h e storage can p
e has to wait f queue. T2 can
umber of requ tance between presents netw puted using th mand. To can be stored e.
U process cap cess capability
PU
he CPU freque
1 2
w × +T w ×D
ction can be ta ombination of weights (w1,
We exam and selecte ships between
n best SE is g plicates the fi It deletes t ferring (i.e. on
cal region).
c Hierarchica gorithm
been describe en different si
nt benefit real election decid he Grid users
a best replica atency eed and size o erage response
g equation:
/Sec)
the storage m f file.
he storage que as some requ perform only for all the pre n be defined b
uests waiting i n nodes work distance
he number of h reduce the
when a replic
pability y is defined by
ency, UCPU is
3
( , )
D x y +w ×
ailored, becau f the three for w2, w3) hav
mined differe ed the b n the above pa
greater or equa ile. If not, so those files w nly files that
al Replication
ed in three pa ites have repli lized by select des which rep . Four import a:
of requests qu e time. T1 can
media speed
eue
uests at the sa one request a evious request
by the follow
in the queue.
between node hops with a tr cost, dista ca is checked
y equation
CPU usage.
C
×
se it is defined rmer metrics. ve been obtai ent weights est values.T arameters are al to ome with are n arts: icas ting lica tant ueue n be (1) and ame at a ts in wing (2)
es x race ance for (3) (4) (5) d as ned in The not ver tec red una exi in rep file sea the rep Oth in tha not pla loc sel rep file firs BS sel the job sto for bec wh exi Oth the rep ava del Fig
ry simple. In chnique for de
The goal of duce file trans available req istence of the
the same LAN plicas and sele
e doesn’t ex arches within e same region plicas and se herwise it gen other regions at has minimum
2. Replica p t available in t ace. Accordin cality the repl lect the BSE, D plica access) o
e in the region st storage ele SE. If more t
lected random e requested sit b execution tim
Assume MD oring replica R
r replica R, th cause S7 has hich is shown
3. Replica M ists in the B herwise if the e file is access plication does ailable in the leted using the
• Genera both av LAN. N list till
g. 3 Replica pla
future work etermining we replica manag sfer time for quested files file in local L N, then it wil ects a replica w xist in the s
the local regi n, then it will elects a replic nerates a list o
, and from th m F. placement: W
the local stora ng to the te lica is placed DHR creates of all SE’s tha n. Now the re
ment (SE) of than one SE mly. Therefore
tes. Hence, sto me can decrea DHR wants R. Now list1 sh
hen MDHR s the highest in Fig. 3. Management:
BSE, the se e file is availa sed remotely. s not exist a
same LAN, o e following ru ate a LRU sor vailable in th Now start del
space is availa
cement strategy
k, we plan to ights. ger (RM) in e
each job. RM of each job LAN. If the f ll create a list with the minim same LAN,
on. If the file l create a list ca with the of replicas that his list it selec
When a reques age, replicatio emporal and
in the best si a sorted list ( at requested t eplica will be f the above so
is candidate , replica is no orage cost as ase.
to find the hows the sorte selects site S7 number of re
If enough s elected file i able in the loc Now, if enou and requested one or more fi ules:
rted list of rep e site as well leting files fro able for replic
y.
use Taguchi
each site is to M for locating controls the file duplicated t of candidate mum F. If the then MDHR duplicated in of candidate minimum F. t are available cts the replica
ted replica is on should take geographical ite (BSE). To by number of that particular placed in the orted list, i.e. e one can be t placed in all well as mean
best site for ed list created 7 from LAN3 equests for R
storage space is replicated. cal LAN, then ugh space for d file is not iles should be
plicas that are l as the local om the above ca. i o g e d e e R n e . e a s e l o f r e . e l n r d 3 R e . n r t e e l e
32 • If
prev rand sort the • If sp
(tha dele som loca The cost fact num be c acce requ prob Obv with num valu
1
RV=w× +S
where the va users, S is fi replica, CT i time of repl would be r describes DH
7 Experim In this s configuration described res
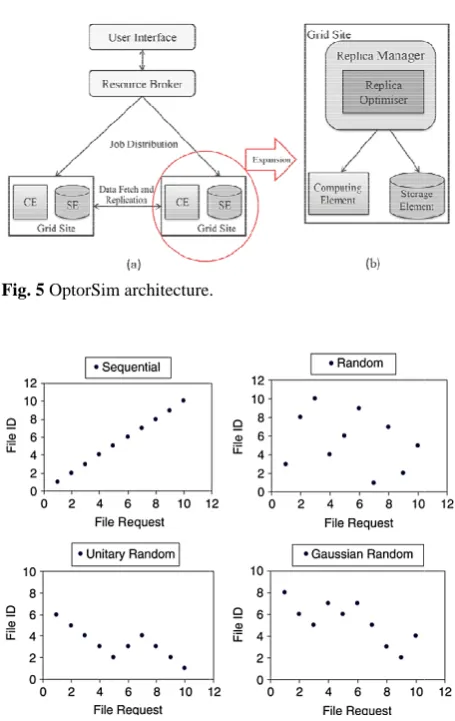
OptorSim a real Data strategies, as several parts
• Com
com • Stor in D • Res
allo sele • Rep data acce • Rep
imp
The Op configuration
space is sti vious step for domly. In ot ted list of repl
site as well as pace is still in at contains one eted. In this me valuable fil al region and erefore, such d t of transfer.
ors (the last ti mber of access considered ins ess and the uested defin bability of r viously, it is m h large size, mber of repli
ue (RV) is calc
2 3
w NA w
+ × +
alue of w1, w2
ile size, NA is s the current t lica. The rep eplaced with HRS strategy.
ments
section, simul n, experimen spectively.
7.1 Sim m was develop a Grid for ev s shown in Fig
:
mputing El mputational res rage Element Data Grid.
ource Broker cates each jo ected schedulin plica Manager
a transferring essing the Rep plica Optim plements the re
7.2 Simu ptorSim tool
n files.
Iran ill insufficien r each LAN i ther words, g licas that are s the local reg nsufficient, a g
e or more rep step using L es that may no d may be ne deletions will
In this step ime the replic s, and file siz stead of LRU last time t ne an indi requesting the more importan because it ica replaceme culated by equ
3
1
CT LA
×
− and w3 can be
s the number time and LA i plica with lea h the new re
lation tool, s nt results and
ulation Tool ped to simulat valuating var g. 5 [41, 42].T
lement (CE source in Data
(SE): represe
(RB): gets th ob to proper s
ng policy. r (RM): at ea
and provides plica Catalog. mizer (RO):
eplication algo
ulation Input works bas
nian Journal o nt, then rep in current reg generate a L both available ion.
group of repli plicas) need to LRU may de
ot be availabl eeded in futu l result in a h p three valua ca was reques
e of replica) w U. The number
the replica w ication of
e replica ag nt to replace f can reduce ent. The rep uation
e assigned by of access to is the last requ ast value of eplica. Figure
simulation inp d discussion
te the structure rious replicat The OptorSim
E): represe a Grid. ents data resou
he user’s job site based on
ach site contr a mechanism
within R orithm.
t
sed on sev
of Electrical & peat
gion LRU e in
icas o be elete e in ure. high able ted, will r of was the ain. files the lica
( 6 )
the the uest RV e 4
put, are
e of tion has
ents
urce
and the
rols m for
RM
eral
Fig
& Electronic E • Parame
simulat configu to be ru maximu strategi • Grid co
topolog availab and nu sizes. • Job co
about s job, the
• Bandw
backgro
g. 4 MDHR algo
Engineering, V eter configur
tion paramete uration file su un, delays bet um queue size ies, access pat onfiguration gy, i.e., the lin ble network b umber of CEs
onfiguration f simulated jobs e probability e idth configur ound network
orithm.
Vol. 10, No. 1 ration file: rs are set in t uch as total nu tween each job e, the choice tterns for the j file: contains nks between g
bandwidth b and SEs, as
file: describes s, the files ne each job runs,
ration file: k traffic.
, March 2014 The basic the parameter umber of jobs b submission, of replication job, etc.
the network grid sites, the etween sites, well as their
s information eeded by each
etc.
specifies the
4 c
r s , n
k e , r
n h
e
Fig. 5 OptorSi
Fig. 6 Various
As menti during execu requested is important acc are selected file), random distribution), one direction the direction Gaussian (fil These file ac
There ar each region master files consists of th topology of o 11 SEs. The GB and the s Bandwidth in job types, an (each is 2 GB
im architecture
s file access pat
ioned above, ution. The or
determined cess patterns a in the order s m (files are , random walk n away from
n will be les are request ccess patterns
7.3 Con re three regio
has an aver are distribut he original fil our simulated e storage capa storage capac n each level is nd each job typ B) for executio .
tterns.
jobs require rder in which
by the acce are as follow: stated in the j e accessed u k unitary (file the previous random) and ted in a Gauss are shown in
nfiguration ons in our co
rage two LA ted to CERN le and cannot platform incl acity of the m
ity of all othe s given in Tab pe on average on.
s to access f h those files
ss pattern. F Sequential (f ob configurat using a rand es are selected file request d random w sian distributio
Fig. 6.
onfiguration ANs. Initially N. A master
t be deleted. T ludes 10 CEs master site is 3
er sites is 40 G ble 1. There ar e requires 16 f
files are Four files tion dom d in and walk on).
and all file The and 300 GB. re 6 files
Ta
Ta
val we
stra Ra Ra alg
ble 1 Bandwidt
Parameter Inter LAN b Intra LAN b Intra Regio
ble 2 General j
Parameter Number of Number of Number of Size of sin Job delay (
Table 2 spec lues used in o e assumed that
We evaluated ategies in fou andom Access andom Walk gorithms have • In Lea always the job space f storage • In Leas replicat is exec new re elemen
• Bandw
stores bandwi likely to • The M
files wi the high • 3-Leve
conside has thr factor f
• Dynam
(DHR) best sit for tha access conside the stor
th configuration
r
bandwidth (lev bandwidth (lev on bandwidth (le
ob configuratio
r f jobs f jobs types f file access per ngle file (GB)
(ms)
cifies the simu our study. To t the data is re
7.4 Simulati d the perform ur types of ac s, Random W k Gaussian
been used for ast Frequentl replication ta b is executing for the new re e element is de st Recently U
tion takes plac cuting. If ther
plica, least ac nt is deleted.
idth Hierarchy the replicas idth and repl o be requested Modified BHR
ithin the regio hest access. l Hierarchic ers a hierarch ree levels. B for replica sele mic Hierarchi
places replic te that has the at particular r latency by se ering the repli rage and data n.
Value vel 3) 1000 vel 2) 100
evel 1) 10
on.
Valu 2000 6 r jobs 16
2 2500
ulation parame simplify the ead-only.
on Results mance of MDH
ccess patterns Walk Unitary
Access. Six r evaluation, n ly Used (LF akes place in t
g. If there is eplica, the old
eleted. sed (LRU) str ce in the site w re is not enou
ccessed file i
y based Repli in a site tha licates those d soon within R algorithm r on in a site w
cal Algorith hical network andwidth is ection and del ical Replicat cas in appropr e highest num replica. It als electing the be ica requests th transfer time.
e (Mbps)
ue
eters and their requirements,
HR and the six s: Sequential, y Access and x replication namely: FU) strategy the site where s not enough dest file in the
rategy always where the job ugh space for in the storage
ication (BHR) at has a high files that are the region. replicates the where file has
hm (3LHA) structure that an important letion. tion strategy riate sites i.e. mber of access so minimizes est replica by hat waiting in r ,
x , d n
y e h e
s b r e
) h e
e s
) t t
y . s s y n
34 Iranian Journal of Electrical & Electronic Engineering, Vol. 10, No. 1, March 2014 Fig. 7 Mean job execution time for various replication
algorithms.
The comparison result is shown in Fig. 7. The experiment results show that MDHR has the lowest value of mean job execution time in all the experiments and all of file access patterns. Obviously, the No Replication strategy has the worst performance as all the files requested by jobs have to be transferred from CERN. In this simulation LRU and LFU have almost the same execution time. BHR algorithm improves data access time by avoiding network congestions. The 3LHA performs better than BHR because it considers the differences between intra-LAN and inter-LAN communication. DHR mean job execution time is faster than Modified BHR. MDHR strategy has the best performance since it will not delete those file that have a high transferring time. One of the important parameters that reduce the Grid site’s job execution time is having their needed files locally stored on their storage element. It replicates files wisely and does not delete valuable files which results in preserving the valuable replicas. As in Random access patterns comprising Random, Unitary random walk and Gaussian random walk, a certain set of files is more likely to be requested by Grid sites, so a large percentage of requested files have been replicated before. Therefore, MDHR strategy and also all the other strategies have more improvement for random file access patterns.
Figure 8 displays the mean job time based on changing number of jobs for seven algorithms. It is clear that as the job number increases, MDHR is able to process the jobs in the lowest mean time in comparison with other methods. It is similar to a real Grid environment where a lot of jobs should be executed.
Data replication takes time and consumes network bandwidth. However, performing no replication has been demonstrated to be ineffective compared to even the simplest replication strategy. So, a good balance must be discovered, where any replication is in the interest of reducing future network traffic. Effective Network Usage (ENU) is used to estimate the efficiency the network resource usage. ENU (Eenu) is given from
[43]:
rfa fa
enu
lfa
N N E
N
+
= (8)
where Nrfa is the number of access times that CE reads a
file from a remote site, Nfa is the total number of file
replication operation, and Nlfa is the number of times
that CE reads a file locally.
The effective network usage ranges from 0 to 1. A lower value represents that the network bandwidth is used more efficiently. Figure 9 shows the comparison of the Effective Network Usage of the seven replication strategies for the sequential access pattern. The ENU of MDHR is lower about 58% compared to the LRU strategy. The main reason is that Grid sites will have their needed files present at the time of need, hence the total number of replications will decrease and total number of local accesses increase. The MDHR is optimized to minimize the bandwidth consumption and thus decrease the network traffic.
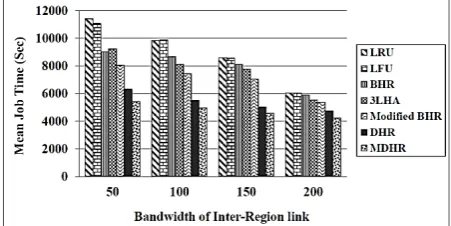
Figure 10 shows the mean job time of replication algorithms for varying inter region bandwidth. When we set narrow bandwidth on the inter-region link, our strategy outperforms other strategy considerably.
Fig. 8 Mean job time based on varying number of jobs.
Fig. 9 Effective network usage with sequential access pattern generator.
Fig. 10 Mean job time with varying bandwidth.
8 Conclusion
Data replication is a key method used to improve the performance of data access in distributed systems. In this paper, we propose a novel data replication algorithm for a three level hierarchical structure with limited storage space to improve system performance. MDHR replaces replicas based on the last time the replica was requested, number of access, and file size of replica. Therefore, sites will have their required files locally at the time of need and this will decrease response time, access latency, bandwidth consumption and increase system performance considerably. It also improves access latency by selecting the best replica when various sites hold replicas. The proposed replica selection selects the best replica location from among the many replicas based on response time that can be determined by considering the data transfer time, the storage access latency, the replica requests that waiting in the storage queue, the distance between nodes and CPU process capability. To evaluate the efficiency of our policy, we used the Grid simulator OptorSim that is configured to represent a real world Data Grid test bed. We compared MDHR to seven of existing algorithms, No replication, LRU, LFU, BHR, Modified BHR, 3LHA and MDHR for different file access patterns. The evaluation shows that MDHR outperforms the other algorithms and improves Mean Job Time and Effective Network Usage under all of the access patterns, especially under the different random file access patterns. Also, we concluded that MDHR can be effectively utilized when hierarchy of bandwidth appears apparently.
In the future, we plan to test our simulation results on real Data Grid. We also try to investigate dynamic replica maintenance issues such as replica consistency. In the longer-term, we would like to consider the set of QoS factors taken into account for dynamic replication, including both service provider and client-related requirements.
References
[1] A. Folling, C. Grimme, J. Lepping and A. Papaspyrou, “Robust load delegation in service Grid environments”, IEEE Transactions on Parallel and Distributed Systems, Vol. 21, pp. 1304-1316, 2010.
[2] O. Sonmez, H. Mohamed and D. Epema, “On the benefit of processor co-allocation in multi cluster Grid systems”, IEEE Transactions on Parallel and Distributed Systems, Vol. 21, pp. 778-789, 2010.
[3] H. Li, “Realistic workload modeling and its performance impacts in large-scale E-science Grids”, IEEE Transactions on Parallel and Distributed Systems, Vol. 21, pp. 480-493, 2010. [4] M. Sedghi and M. Aliakbar-Golkar, “Distribution
Network Expansion Using Hybrid SA/TS Algorithm”, Iranian Journal of Electrical &
Electronic Engineering, Vol. 5, No. 2, pp. 122-130, 2009.
[5] M. Sharma and K. P. Vittal, “A Heuristic Approach to distributed Generation Source Allocation for Electrical Power Distribution Systems”, Iranian Journal of Electrical & Electronic Engineering, Vol. 6, No. 4, pp. 224-231, 2010.
[6] M. R. Aghamohammadi, “Static Security Constrained Generation scheduling Using Sensitivity Characteristics of Neural Network”, Iranian Journal of Electrical & Electronic Engineering, Vol. 4, No. 3, pp. 104-114, 2008. [7] GriPhyN: The Grid physics network project, 12
July 2010. http://www.griphyn.org, [Accessed: January 2014].
[8] R. S. Chang and M. S. Hu, “A resource discovery tree using bitmap for Grids”, Future Generation Computer Systems, Vol. 26, pp. 29-37, 2010. [9] J. Wu, X. Xu, P. Zhang and C. Liu, “A novel
multi-agent reinforcement learning approach for job scheduling in Grid Computing”, Future Generation Computer Systems, Vol. 27, pp. 430-439, 2011.
[10] S. Ebadi and L. M. Khanli, “A new distributed and hierarchical mechanism for service discovery in a Grid environment”, Future Generation Computer Systems, Vol. 27, pp. 836-842, 2011. [11] CERN. http://public.web.cern.ch/public/,
[Accessed: January 2014].
[12] N. T. Thuy, T. T. Anh, D. D. Thanh, D. T. Tung, N. T. Kien and T. T. Giang, “Construction of a Data Grid for meteorology in Vietnam”, Proceedings of the 2007 Int. Conf. on Grid Computing & Applications, pp. 186-191, 2007. [13] J. Montagnat and H. Duque, “Medical data
storage and retrieval on the Data Grid”, Technical Report DataGrid-10-TED-345148-0-1, the European Data Grid Project, 2002.
[14] Work Package 9, WP9.4 Use Case, Technical Report DataGrid-09-TED-0101-1-1, the European Data Grid Project, 2002.
[15] Human Genome Project: http://
www.nhgri.nih.gov/
,
[Accessed July 2011]. [16] The Data Grid project.http://eu-datagrid.web.cern.ch/eu-datagrid/, [Accessed January 2014].
[17] S. Figueira and T. Trieu, “Data replication and the storage capacity of Data Grids”, Berlin, Heidelberg: Springer-Verlag, pp. 567-75, 2008. [18] D. G. Cameron, A. P. Millar, C. Nicholson, R.
Carvajal-Schiaffino, K. Stockinger and F. Zini, “Analysis of scheduling and replica optimization strategies for Data Grids using Optorsim”, Journal of Grid Computing, Vol. 2, No. 1, pp. 57-69, 2004.
[19] H. Zhong, Z. Zhang and X. Zhang, “A Dynamic replica management strategy based on Data
36 Iranian Journal of Electrical & Electronic Engineering, Vol. 10, No. 1, March 2014 Grid”, in 2010 Ninth Int. Conf. on Grid and
Cloud Computing, pp.18-22, 2010.
[20] H. Lamehamedi, B. Szymanski, Z. Shentu and E. Deelman, “Data replication strategies in Grid environments”, in Proceedings of the fifth int. conf. on Algorithms and Architectures for Parallel Processing, pp. 378-383, 2002.
[21] O. Tatebe, Y. Morita, S. Matsuoka, N. Soda and S. Sekiguchi, “Grid datafarm architecture for petascale data intensive computing”, Proc. of the 2nd IEEE/ACM Int. Symp. on Cluster Computing and the Grid (CCGrid), pp. 102-110, 2002. [22] A. Chervenak, E. Deelman, I. Foster, L. Guy, W.
Hoschek, A. Iamnitchi, C. Kesselman, P. Kunszt, M. Ripeanu, B. Schwartzkopf, H. Stockinger, K. Stockinger and B. Tierney, “A framework for constructing scalable replica location services”, in Proc. of Super Computing, ACM/IEEE Conf., pp. 1-17, 2002.
[23] I. Foster and K. Ranganathan, “Design and evaluation of dynamic replication strategies a high performance Data Grid”, in Proceedings of Int. Conf. on Computing in High Energy and Nuclear Physics, China, 2001.
[24] U. Cibej, B. Slivnik and B. Robic, “The complexity of static data replication in Data Grids”, Parallel Computing, Vol. 31, No. 8, pp. 900-912, 2005.
[25] Y. Yuan, Y. Wu, G. Yang and F. Yu, “Dynamic data replication based on local optimization principle in Data Grid”, in Proceedings of GCC, pp. 815-822, 2007.
[26] H. Lamehamedi, Z. Shentu, B. Szymanski and E. Deelman, “Simulation of dynamic data replication strategies in Data Grids”, in Parallel and Distributed Processing Symposium, 2003. [27] B. D. Lee and J. B. Weissman, “Dynamic replica
management in the service Grid”, 10th IEEE Int. Symposium on High Performance Distributed Computing Proc., pp. 433-434, 2001.
[28] K. Ranganathan and I. Foster, “Identifying dynamic replication strategies for a high performance Data Grid”, in Proceedings of the Second International Workshop on Grid Computing, pp. 75-86, 2001.
[29] R. M. Rahman, K. Barker and R. Alhajj, “Replica selection strategies in Data Grid”, Journal of Parallel and Distributed Computing, Vol. 68, pp. 1561-1574, 2008.
[30] D. T. Nukarapu, B. Tang, L. Wang and S. Lu, “Data replication in data intensive scientific applications with performance guarantee”, IEEE Transactions on Parallel and Distributed Systems, Vol. 22, No. 8, pp. 1299-1306, 2011. [31] A. Chervenak, R. Schuler, M. Ripeanu, M. A.
Amer, S. Bharathi, I. Foster and C. Kesselman, “The Globus replica location service: design and experience”, IEEE Trans. on Parallel and
Distributed Systems, Vol. 20, pp. 1260-1272, 2009.
[32] M. Tang, B. S. Lee, C. K. Yao and X. Y. Tang, “Dynamic replication algorithm for the multi-tier Data Grid”, Future Generation Computer Systems, Vol. 21, No. 5, pp. 775-790, 2005.
[33] V. Andronikou, K. Mamouras, K. Tserpes, D. Kyriazis and T. Varvarigou, “Dynamic QoS-aware data replication in Grid environments based on data “importance”, Future Generation Computer Systems, Vol. 28, No. 3, pp. 544-553, 2012.
[34] M. C. Lee, F. Y. Leu, and Y. Chen, “PFRF: An adaptive data replication algorithm based on startopology Data Grids”, Future Generation Computer Systems, Vol. 28, No. 7, pp. 1045-1057, 2012.
[35] N. Saadat and A. M. Rahmani, “PDDRA: A new pre-fetching based dynamic data replication algorithm in Data Grids”, Future Generation Computer Systems, Vol. 28, No. 4, pp. 666-681, 2012.
[36] J. Taheri, Y. C. Lee, A. Y. Zomaya and H. J. Siegel, “A Bee Colony based optimization approach for simultaneous job scheduling and data replication in Grid environments”, Computers & Operations Research, Vol. 40, No. 6, pp. 1564-1578, 2013.
[37] N. Mansouri and G. H. Dastghaibyfard, “A dynamic replica management strategy in Data Grid”, Journal of Network and Computer Applications, Vol. 35, No. 4, pp. 1297-1303, 2012.
[38] S. -M. Park, J. -H. Kim, Y. -B. Go and W. -S. Yoon, “Dynamic Grid replication strategy based on internet hierarchy”, Int. Workshop on Grid and Cooperative Computing, in: Lecture Note in Computer Science, Vol. 1001, pp. 1324-1331, 2003.
[39] K. Sashi and A. Thanamani, “Dynamic replication in a Data Grid using a modified BHR region based algorithm”, Future Generation Computer Systems, Vol. 27, No. 2, pp. 202-210, 2011.
[40] A. Horri, R.Sepahv and and Gh. Dastghaibyfard, “A hierarchical scheduling and replication strategy”, International Journal of Computer Science and Network Security, Vol. 8, No. 8, pp. 30-35, 2008.
[41] D. G. Cameron, A. P. Millar, C. Nicholson, R. Carvajal-Schiaffino, F. Zini and K. Stockinger, “Optorsim: A simulation tool for scheduling and replica optimization in Data Grids”, in Int. Conf. for Computing in High Energy and Nuclear Physics (CHEP 2004), 2004.
[42] OptorSim-A Replica Optimizer Simulation: http://edg-wp2.web.cern.ch/edgwp2/optimization/ optorsim.html, [Accessed January 2014].
[43] W. H. K. St Dynam OptorS on Gri
Science from 2009. Her re Distributed Sy
Bell, D. G. C tockinger an mic Grid
Sim”, in Proc id Computing,
Najme of Com Univer M.Sc. Depart Engine Compu Univer B.Sc. Shahid Bahon esearch interes ystems, and Gri
Cameron, L. C nd F. Zini,
Replication c. of the ACM/
, 2002.
e Mansouri is mputer Science
rsity of Kerman in software tment of Com eering, College uter Engin rsity (Iran). S
(Honor Stude ar University o sts include Pa d Computing.
apozza, P. Mi “Simulation Strategies M/IEEE Worksh
currently a fac at Shahid Baho n. She received e engineering mputer Science
e of Electeric neering, Sh She received ent) in Comp of Kerman, Iran arallel Process
illar of in hop
culty onar d her at e & cal& hiraz her puter n in sing,
Eng Shi Par Tec
gineering, Coll iraz University rallel Algorith chnology.
Gholamho received Computer Engineerin Departmen University Oklahoma respectivel professor Departmen lege of Electric y. His curren hms, Grid C
ossein D his M.Sc. a Science fro ng and Com nt, College of y of Oklaho a USA in 19 ly. He is curren
of Compute nt of Compute cal & Compute nt research int Computing and
Dastghaibyfard and Ph.D. in om Electrical mputer Science f Engineering, oma, Norman 79 and 1990, ntly an assistant er Science at er Science and er Engineering, terests include d Information d n
l e , n , t t d , e n