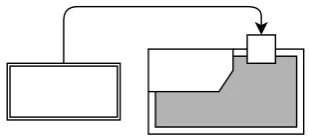
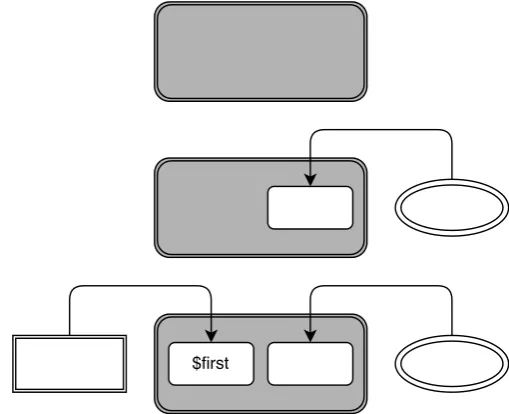
Behavioural analysis of program intent using data origins, influence and context
Full text
Figure
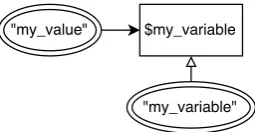
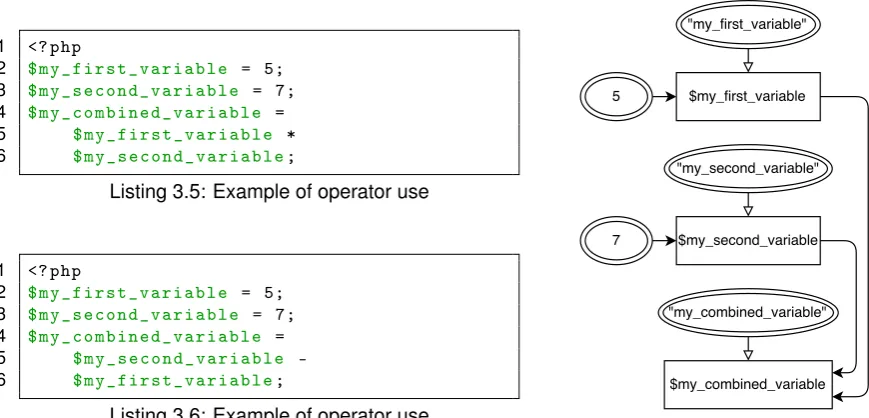
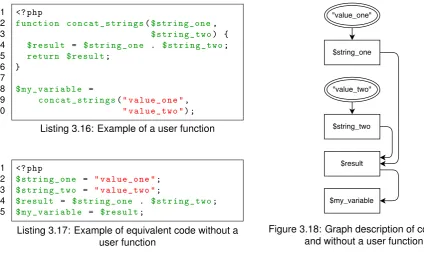
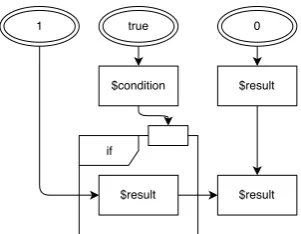
Related documents
I understand and agree that the granting of this license requires my compliance with all applicable City of Birmingham Tax Code provisions, and state laws, as well as with
Thank you for your interest in Hillsborough Community College Health Sciences Programs. Acceptance to the Health Sciences Programs is selective, a complete
These include work requirements, number and duration of exposures, heat exchange components, rest area conditions, and worker clothing (Clayton, 1978). Actions to control heat
there was no reason to think that Hadrian's Wall had been abandoned before the general collapse of Roman rule in Britain in the early.. years of the
I understand and acknowledge that the institutions that comprise the South Dakota system of higher education are also permitted to share such academic, enrollment and financial
Hence, if an independence model is true and a misrounded treatment is carried out for the MAFF data, the second misleading effect in relation to the changing age-at-onset
Applicants are responsible for verifying that final official high school (regular or dual enrolled students) transcripts or GED scores have been received by the Hillsborough
Thank you for your interest in Hillsborough Community College Health Sciences Programs. Acceptance to the Nursing Program is selective, a complete application packet must be
