©IJRASET: All Rights are Reserved
451
Survey Paper on Data Mining Algorithms Applied
for Recommendation System
Mrs. S. Panimalar1, S. Gayathri Lakshmi2, S. Harshitha3
1
Assistant Professor, Department of CSE, Panimalar Institute of Technology, Chennai, India
2, 3
Student, Department of CSE, Panimalar Institute of Technology, Chennai, India
Abstract: As a standout amongst the best ways to deal with building recommender frameworks, collaborative filtering (CF) utilizes the known inclinations of a gathering of clients to make suggestions or forecasts of the obscure inclinations for different clients. In this paper, we initially present CF undertakings and their primary difficulties, for example, information sparsity, adaptability, synonymy, security insurance, and so forth, and their conceivable arrangements. We at the point present three principle algorithms of data mining strategies: content based filtering, user based filtering, agglomerative clustering (that join CF with other suggestion systems), with models for delegate calculations of every classification, and examination of their prescient execution and their capacity to address the difficulties. From fundamental strategies to the cutting edge, we endeavor to show a complete review for CF systems, which can be filled in as a guide for research and practice around there.
Keywords: Collaborative filtering; agglomerative clustering; classification.
I. INTRODUCTION
The Recommender System (RS) is a device and method that encourages individuals to achieve content on the premise of their advantage and in this way spare a great deal of time Numerous sites, as Amazon, Netflix, and other informal communities, have received recommender frameworks.
Cooperative sifting is one of the key methods utilized in customized recommender systems. The quintessence of cooperative separating is to uncover the connection among clients and things dependent on accessible client data, for example, client appraisals of things, Framework Factorization (MF), a standout amongst the most well-known community sifting methods, ventures clients and things into a common dormant space, and uses an inert which include vector to speak to either a client or a thing. Along these lines, the connection of the client with the thing is displayed as the internal result of the inactive vectors.
The last objective of a recommender framework is to give a rundown of things that estimated client inclinations. Be that as it may community separating faces two issues. The first is that recommender frameworks chiefly depend on understood criticism, which is scanty and can't really reflect client preferences. This restrains the execution of recommender frameworks. The second issue is that customary community oriented sifting utilizes straight models to learn client thing relations, which confines the proposal execution. For instance, to produce a proposal, the creators utilized MF to learn client and thing idle vectors by breaking down a client rating lattice into client and thing idle vectors that have high
significance. MF is a procedure of decreasing measurement, which definitely results in loss of client thing collaborations. Consequently, customary community oriented separating techniques experience issues in enhancing the exactness of suggestions. Information mining has achieved great triumph in pretty much every space, for example, human services, remote sensor arrange, interpersonal organization and so forth with improvement of its different calculations. Each datum mining calculation has its characteristic confinements.
The application space and the genuine information, both together, vigorously impact the specific decision and in addition execution of any information mining, machine learning or factual calculation.
©IJRASET: All Rights are Reserved
452
II. LITREATURE SURVEY
A. W. M. Campbell, Member, IEEE, D. E. Sturim, Member, IEEE, and D. A. Reynolds, Senior Member, IEEE
Gaussian blend models (GMMs) have demonstrated extremely effective for content autonomous speaker acknowledgment. The standard preparing technique for GMM models is to utilize MAP adaptation of the methods for the blend parts dependent on discourse from an objective speaker. Later strategies in remuneration for speaker and channel in constancy have proposed stacking the methods for the GMM model to frame a GMM mean super vector. They analyze using the GMM super vector in a help vector machine (SVM) classifier [1]. They propose two new SVM parts dependent on separate measurements between GMM models. And demonstrate that these SVM parts deliver superb grouping exactness in a NIST speaker acknowledgment.
They have shown two novel portions for SVMs utilizing GMM super vectors. The SVM was appeared to have superb performance on a NIST SRE 2005 errand. Execution was found to be aggressive with a standard GMM UBM framework with versatile [1]. TNorm. Future work on this strategy incorporates applying SVM channel remuneration
strategies and expanding the way to deal with HMM MAP adjustment.
B. Patrick Kenny, Member, IEEE, Gilles Boulianne, Member, IEEE, and Pierre Dumouchel, Member, IEEE
They infer a correct answer for the issue of maximum probability estimation of the super vector covariance grid utilized in expanded MAP (or EMAP) speaker adjustment and show how it very well may be viewed as another strategy for eigen voice estimation. In contrast to different ways to deal with the issue of evaluating eigen voices in circumstances where speaker-subordinate preparing isn't possible, their strategy empowers them to assess the same number of eigen voices from a given preparing set as there are preparing speakers [2]. In the limit as the measure of preparing information for every speaker keeps an eye on interminability, it is identical to group versatile preparing.
All with more aggressively, one could supplant each Gaussian in a HMM yield dissemination by a free segments analyzer [2], tying the blending frameworks in the soul for a remarkable instructional exercise on ICA. Coordinating ICA with HMMs is direct on a basic level. This recommends that non-Gaussian demonstrating of speaker super vectors could likewise be considered yet they don't have any proof to show whether this merits seeking after[2].
C. Hyeong-Joon Kwon, Student Member, IEEE and Kwang-Seok Hong, Member, IEEE
The survey set-based technique experiences issues guaranteeing that a client will appreciate suggested programs, and the model-based cooperative sifting strategy contains framework side continuous suggestion issues on the grounds that most ongoing evaluations can't be connected in the suggestions and it has expanded computing costs because of the preparation procedure. In this paper, they propose a customized program recommender for brilliant TVs utilizing memory-based community oriented separating with a novel likeness technique that is strong and quicker than the frequently utilized, existing comparability strategy. The proposed strategy can move forward the suggestion execution of electronic program guides and recommender applications for brilliant TVs. They decided the forecast precision of the appraisals under different conditions so as to assess the proposed strategy [3].
They proposed a customized PRS for two-way TV dependent on MBCF that exhibited rapid and ended up being an exact comparability strategy [3]. The proposed strategy gives client focused PRS by foreseeing evaluations on non-saw programs utilizing unequivocal inclinations. Their future investigation will utilize a cross breed PRS procedure
dependent on express inclinations and program qualities.
D. Sven Ewan Shepstone, Member IEEE, Zheng-Hua Tan, Senior Member IEEE and Søren Holdt Jensen Senior Member IEEE
Prescribing TV substance to gatherings of watchers is best completed when applicable data, for example, the socioeconomics of the gathering is accessible. Be that as it very well may be troublesome and tedious to separate data for each client in the gathering. This paper demonstrates how a sound examination of the age also, sexual orientation of a gathering of clients viewing the TV can be utilized for suggesting a grouping of N short TV content things for the gathering[4]. Initial, a cutting edge sound based classifier decides the age and sexual orientation of every client in a M-client gathering and makes a aggregate profile.
©IJRASET: All Rights are Reserved
453
E. Rafael Sotelo, Member, IEEE, Yolanda Blanco-Fernandez, Martin Lopez-Nores, Alberto Gil-Solla, Jose J. Pazos-Arias, Member, IEEE
The appearance of Digital TV and Personal Digital Recorders guarantee to change the manner in which individuals stare at the TV. The higher productivity of advanced coding will prompt expanding the number of substance offered to the client, requesting programmed apparatuses for substance proposal[5]. In the other hand, computerized recorders will allow a non-straight utilization display, empowering the production of (programmed) customized plans that join the engaging substance for an explicit client or gathering of clients. This paper shows a way to deal with substance proposal for gatherings of individuals, in view of TV-Anytime depictions of TV substance and semantic thinking techniques.
It is a technique to anticipate the enthusiasm of a gathering of individuals for a varying media content has been introduced that enables us to make exact suggestions for the gathering. They characterized homogeneous and heterogeneous gatherings and considered diverse proper calculations for every sort of gathering [5], what reflects genuine propensities for TV utilization. As a necessity for the improvement of interoperable customer electronic hardware, TV-Anytime metadata is broadly used to ensure (I) the accessibility of point by point enough substance portrayals, and (ii) the suitability of good systems to comment on and gather clients' profiles.
F. Najim Dehak, Patrick J. Kenny, Reda Dehak, Pierre Dumouchel, and Pierre Ouellet
This paper exhibits an augmentation of their past work which proposes another speaker portrayal for speaker check. In this demonstrating, an extraordinary failure dimensional speaker-and channel-subordinate space is characterized utilizing a basic factor examination[6]. This space is named the aggregate fluctuation space since it displays both speaker and channel inconstancies. Two speaker confirmation frameworks are proposed which utilize this new portrayal. The first framework is a help vector machine-based framework that utilizes the cosine portion to appraise the closeness between the information. The second framework straightforwardly utilizes the cosine likeness as the last choice score. They tried three channel pay strategies in the aggregate changeability space, which are inside class covariance standardization (WCCN), direct separate investigation (LDA), and aggravation trait projection (NAP)[6]. And found that the best outcomes are gotten when LDA is trailed by WCCN. They accomplished an break even with mistake rate (EER) of 1.12% and MinDCF of 0.0094 [6] utilizing the cosine remove scoring on the male English preliminaries of the center condition. It likewise acquired 4% supreme EER enhancement for both-sex preliminaries on the 10 s-10 s condition contrasted with the traditional joint factor investigation scoring[6].
The best outcomes were gotten with the blend of LDA what's more, WCCN. The benefit of utilizing LDA is the expulsion of irritation headings and the boost of the change between the speakers, which is the key point in speaker confirmation. The results acquired with cosine separate scoring beat those acquired with both SVM-FA and traditional JFA scorings on a few NIST assessment conditions[6].Notwithstanding, the cosine scoring framework is by all accounts all the more amazing and hearty, particularly on brief term conditions like 10 sec-10 sec of the NIST 2008 SRE dataset, where they accomplished a flat out enhancement of 4%-point on the EER contrasted with traditional JFA. As of late, they proposed an augmentation of the aggregate changeability framework to the meeting and receiver states of the NIST 2008 SRE. This methodology comprises of stacking 200 additional add up to factors assessed in the mouthpiece dataset to the first 400 phone add up to factors. The last space has an aggregate of 600 add up to factors. They additionally demonstrated how LDA and WCCN can be reached out to these conditions.
G. Sven Ewan Shepstone, Member, IEEE, Zheng-Hua Tan, Senior Member, IEEE, and Søren Holdt Jensen, Senior Member, IEEE
This paper presents the idea of full of feeling counterbalance, which is the contrast between a client's apparent full of feeling state what's more, the full of feeling explanation of the substance they wish to see. They indicate how this full of feeling counterbalance can be utilized inside a structure for giving proposals to TV programs. Initially a client's inclination profile is resolved utilizing 12-class sound based feeling characterizations [7]. An underlying TV content thing is then shown to the client dependent on the extricated temperament profile. The client has the alternative to either acknowledge the suggestion, or to investigate the thing once or a few times, by exploring the feeling space to ask for an elective match. The last match is then contrasted with the underlying match, regarding the distinction in the things emotional parameterization [7]. This balance is then used in future suggestion sessions. The framework was assessed by inspiring three diverse states in 22 separate clients and looking at the impact of applying full of feeling balance to the clients sessions. Results appear that, for the situation when full of feeling balance was connected, better client fulfillment was accomplished[7], the normal appraisals went from 7.80 up to 8.65, with a normal decline in the quantity of evaluating cycles which went from 29.53 down to 14.39.
©IJRASET: All Rights are Reserved
454
utilized for future suggestion sessions. They utilized every client's full of feeling balance to find an underlying district for suggestion, from which a suggestion was resolved. The utilization of full of feeling balance prompted better client fulfillment generally speaking, where evaluations went from 7.80 up to 8.65 [7]. Moreover, there was a checked decline in the quantity of cycles that was expected to locate a decent thing, contrasted with the situation when no emotional counterbalance was connected, which went from 29.53 down to 14.39. Future work could incorporate better demonstrating of things arranged near the VA beginning, progressively prescient demonstrating of the directional disposition vector and a structure that considers state of mind profiles that shift overtime.
H. Patrick Kenny
It gives a full record of the calculations expected to do a joint factor investigation of speaker and session changeability in a preparation set in which every speaker is recorded over numerous diverse channels and it examines the down to earth constraints that will be experienced whether these calculations are actualized on extremely extensive informational collections [8].
In this article they have tried to demonstrate session changeability by methods for a Gaussian appropriation on super vectors. A regular expansion which ought to most likely be investigated if a appropriate preparing set can be found, can utilize Gaussian blend dispersions rather where every blend segment has related with it a centroid in the super vector space and a super vector covariance lattice of low position. (This is roused to some degree by the component mapping procedure which treats channel impacts as discrete. In this kind of blend conveyance is alluded to as a blend of probabilistic essential segments analyzers [8]. To the extent they have possessed the capacity to decide there is no deterrent on a fundamental level to expanding the joint factor investigation demonstrate along these lines (expecting obviously that a reasonable preparing set can be found) yet there might be imposing computational deterrents.
I. Carlos A. Gomez-Uribe and Neil Hunt, Netflix, Inc
This article talks about the different calculations that make up the Netflix recommender framework, and depicts its business reason. They likewise depict the job of hunt and related calculations, which for them transforms into a proposals issue also. They clarify the inspirations driving and survey the methodology that they use to enhance the proposal calculations, joining A/B testing concentrated on enhancing part maintenance furthermore, medium term commitment, and additionally disconnected experimentation utilizing authentic part commitment information. They examine a portion of the issues in structuring and deciphering A/B tests [9]. At last, they depict some present territories of centered advancement, which incorporate making their recommender framework worldwide and dialect mindful.
They have portrayed the distinctive calculations that make up the Netflix recommender framework, the procedure that they use to enhance it, and a portion of the open issues. People are confronting an expanding number of decisions in each part of their lives— surely around media, for example, recordings, music, and books, other taste-based inquiries, for example, get-away rentals, eateries, etc, however more imperatively, around zones, for example, wellbeing protection designs and medicines and tests, pursuits of employment, training and getting the hang of, dating what's more, discovering life accomplices, and numerous different territories in which decision matters essentially. They are persuaded that the field of recommender frameworks will keep on playing a significant job in utilizing the abundance of information now accessible to settle on these decisions reasonable[9], viably directing individuals to the genuinely best couple of choices for them to be assessed, coming about in better choices. They additionally trust that recommender frameworks can democratize access to long-tail items, administrations, and data, since machines have a vastly improved capacity to learn from immensely greater information pools than master people[9], in this way it can make helpful expectations for regions in which human limit essentially isn't satisfactory to have enough involvement to sum up helpfully at the tail.
J. Zhiwen Yu · Xingshe Zhou · Yanbin Hao · Jianhua Gu
©IJRASET: All Rights are Reserved
455
blending result can properly mirror the inclinations of the larger part of individuals inside the gathering, and the proposed proposal technique is powerful for numerous watchers staring at the TV together.
In this paper, they present a program suggestion procedure for numerous TV watchers utilizing profile blending. The client profile combining depends on aggregate separation minimization, which ensures that the blended outcome is near most clients' inclinations. Two hypotheses are proposed and demonstrated for highlight choice, which streamlines the procedure of finding the objective vector, and makes the framework doable and productive[10]. The assessment results demonstrated that the suggestion technique is powerful for various watchers sitting in front of the TV together. Moreover, the proposal procedure is basic what's more, doable. It very well may be actualized in PDRs, and additionally minimal effort STBs. For future work, they intend to convey the gathering proposal strategy in various application regions, for example, web and music suggestion.
K. Yun Lei1 Luciana Ferrer, Mitchell McLaren1 Nicolas Scheffer
They proposed the utilization of profound neural systems (DNN) instead of Gaussian Mixture models (GMM) in the I-vector extraction process for speaker acknowledgment. They have demonstrated huge exactness enhancements for the 2012 NIST speaker acknowledgment assessment (SRE) phone conditions. This paper investigates how this system can be successfully utilized on the amplifier discourse states of the 2012 NIST SRE. In this new system, the check execution incredibly relies upon the information utilized for preparing the DNN. They demonstrate that preparing the DNN utilizing both phone and amplifier discourse information can yield huge upgrades. An inside and out investigation of the impact of phone discourse information on the amplifier conditions is likewise appeared both the DNN and GMM frameworks[11]. They finish up by demonstrating that the GMM framework is dependably outflanked by the DNN framework on the phone just and amplifier just conditions, and that the new DNN/I-vector system can be effectively utilized giving a decent match in the preparation information.
In past work, they exhibited the DNN/I-vector system for speaker acknowledgment and demonstrated its execution on the SRE'12 phone conditions utilizing just phone information for preparing all framework parts. In this work, they expanded its application to receiver discourse information. They found that preparation the ASR DNN with both phone and receiver information gave better confirmation execution on mouthpiece test information than preparing on just receiver information[11]. This outcome may demonstrate that the mouthpiece information utilized for this reason for existing isn't well coordinated to the test information and that the extra phone information enhances display power by expanding decent variety. With respect to the impact of information on the framework's segment (UBM, means and covariances,
I-vector subspace and backend), it was discovered that the
I-vector subspace was touchy to the expansion of phone preparing information to the amplifier preparing set[11]. On account of the customary UBM structure, this fundamentally enhanced receiver preliminary execution while interestingly, the DNN/I-vector structure demonstrated a critical corruption.
L. Feliix Burkhardt, Martin Ecckert, Wiebke Johannsen, Joachim Stegman
This article depicts an age-commented on database of German phone discourse. With everything taken into account 47 hours of provoked and free content was recorded, articulated by 954 paid members in a style average for computerized voice administrations[12]. The members were chosen dependent on an equivalent circulation of guys and females inside four age bunch gatherings; kids, youth, grown-ups and seniors. Inside the kids, sexual orientation isn't recognized, in light of the fact that it doesn't have a sufficient impact on the voice. The printed substance was intended to be normal for robotized voice administrations and comprises for the most part of short directions, single words and numbers. An extra database comprises of 659 speakers (368 female and 291 male) that called a computerized voice gateway server and replied openly on inquiries . The information may be utilized for out-of area testing[12]. The information will be utilized to tune an age-recognizing mechanized voice benefit and may be discharged to examine initiates under controlled conditions as a component of an open age and sexual orientation identification challenge.
©IJRASET: All Rights are Reserved
456
M. Tomi Kinnunen , Haizhou Li
This paper gives a diagram of programmed speaker acknowledgment innovation, with an accentuation on content autonomous acknowledgment. Speaker acknowledgment has been examined effectively for a very long while. They give a review of both the established and the best in class strategies. They begin with the essentials of programmed speaker acknowledgment, concerning highlight extraction and speaker displaying. They expound progressed computational methods to address power and session changeability. The ongoing advancement from vectors towards supervectors opens up another zone of investigation and speaks to an innovation slant. They likewise give an outline of this ongoing advancement and talk about the assessment procedure of speaker acknowledgment frameworks. They have displayed a diagram of the established and new techniques for programmed content free speaker acknowledgment. The acknowledgment precision of current speaker acknowledgment frameworks under controlled conditions is high[13]. Be that as it may, in handy circumstances many negative elements are experienced including confused handsets for preparing and testing, restricted preparing information, unequal content, foundation commotion and non-agreeable clients. The systems of vigorous highlight extraction, include standardization, display area remuneration and score standardization techniques are important. The innovation headway as spoken to by NIST assessments in the ongoing years has tended to a few specialized difficulties, for example, content or dialect reliance, channel impacts, discourse terms, and cross-talk discourse. Notwithstanding, many research issues stay to be tended to, for example, human-related mistake sources, constant usage, and measurable understanding of speaker acknowledgment scores[13].
N. Koen Verstrepen Bart Goethals
Standard collective separating recommender frameworks accept that each record in the preparation information speaks to a single client. Be that as it may, various clients regularly share a solitary record. A run of the mill model is a solitary shopping represent the entire family. Conventional recommender frameworks flop in this circumstance. In the event that logical data is accessible, setting mindful recommender frameworks are the cutting edge arrangement. However, frequently no logical data is accessible. In this way, they acquaint the test of suggesting with shared records without logical data. They propose an answer for this test for all cases in which the reference recommender framework is a thing based best N communitarian separating recommender framework[14], producing proposals dependent on twofold, positive-just criticism. They tentatively demonstrate the benefits of our proposed answer for handling the issues that emerge from the presence of shared records on different datasets. They demonstrated that the broadly utilized thing based recommender frameworks falls flat when it makes suggestions for shared records. Along these lines, they presented the test of Top-N suggestion for shared records without logical data. Besides, they proposed the cover calculation, answer for this test. Focal to their methodology, They demonstrated a hypothesis that enabled us to process a proposal score in O (n log n) rather than exponential time. At long last, they tentatively approved that their proposed arrangement has imperative focal points. As future work, they intend to sum up their proposed answer for a more extensive scope of reference recommender frameworks.
O. Douglas Veras, Thiago Protaa, Alysson Bispoa, Ricardo Prudencio , Carlos Ferraza
©IJRASET: All Rights are Reserved
457
III. PROPOSED WORK
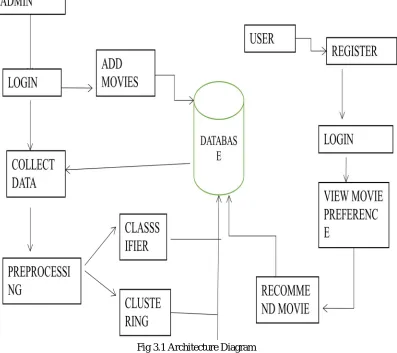
[image:7.612.110.507.287.640.2]We proposed an Agglomerative Hierarchal Clustering or Hierarchal Agglomerative Clustering. Bunching are such procedures that can lessen the information estimate by a huge factor by gathering comparable administrations together. A group contains some comparative administrations simply like a club contains some like- disapproved of clients. This is another reason other than contraction that we call this approach Club CF. This methodology is sanctioned around two phases. In the principal organize, the accessible administrations are partitioned into little scale bunches, in rationale, for further preparing. At the second stage, a synergistic sifting calculation is forced on one of the groups. This similitude metric figures the Euclidean separation d between two such client focuses this esteem alone doesn't comprise a substantial comparability metric, since bigger qualities would mean increasingly far off, and in this manner less comparable, clients. The esteem ought to be littler when clients are progressively comparable. Cluster-based recommendation system is best recommender system. Rather than recommending things to users, things square measure counseled to clusters of comparable users. This entails pre-processing part, within which all users square measure divided into clusters. Recommendations square measure then made for every cluster, specified the counseled things square measure most fascinating to the biggest range of users. The top of this approach is that recommendation is quick at runtime as a result of virtually everything is pre computed. Moreover, because the ratings of services within the same cluster square measure a lot of relevant with others than with those in other clusters.
Fig 3.1 Architecture Diagram
IV. CONCLUSION
©IJRASET: All Rights are Reserved
458
REFERENCES
[1] W. M. Campbell, Member, IEEE, D. E. Sturim, Member, IEEE, and D. A. Reynolds, Senior Member, IEEE,” Support Vector Machines Using GMM Supervectors for Speaker Verification”, IEEE signal processing letters, vol. 13, no. 5, may 2006.
[2] Patrick Kenny, Member, IEEE, Gilles Boulianne, Member, IEEE, and Pierre Dumouchel, Member, IEEE,” Eigenvoice Modeling With Sparse Training Data”, IEEE transactions on speech and audio processing, vol. 13, no. 3, may 2005.
[3] Hyeong-Joon Kwon, Student Member, IEEE and Kwang-Seok Hong, Member, IEEE,” Personalized Smart TV Program Recommender Based on Collaborative Filtering and a Novel Similarity Method”, IEEE Transactions on Consumer Electronics, Vol. 57, No. 3, August 2011.
[4] Sven Ewan Shepstone, Member IEEE, Zheng-Hua Tan, Senior Member IEEE and Søren Holdt Jensen, Senior Member IEEE,” Audio-based Age and Gender Identification to Enhance the Recommendation of TV Content”, IEEE Transactions on Consumer Electronics, Vol. 59, No. 3, August 2013.
[5] Rafael Sotelo, Member, IEEE, Yolanda Blanco-Fernández, Martín López-Nores, Alberto Gil- Solla,José J. Pazos-Arias, Member, IEEE,” TV Program Recommendation for Groups based on Muldimensional TV-Anytime Classifications”, IEEE Transactions on Consumer Electronics, Vol. 55, No. 1, february 2009.
[6] Najim Dehak, Patrick J. Kenny, Réda Dehak, Pierre Dumouchel, and Pierre Ouellet,” Front-End Factor Analysis for Speaker Verification”, IEEE transactions on audio, speech, and language processing, vol. 19, no. 4, may 2011.
[7] Sven Ewan Shepstone, Member, IEEE, Zheng-Hua Tan, Senior Member, IEEE, and Søren Holdt Jensen, Senior Member, IEEE,” Using Audio-Derived Affective Offset to Enhance TV Recommendation”, IEEE transactions on multimedia, vol. 16, no. 7, november 2014.
[8] Patrick Kenny,” Joint Factor Analysis of Speaker and Session Variability: Theory and Algorithms”, draft version january 13, 2006.
[9] Carlos A. Gomez-Uribe and Neil Hunt, Netflix, Inc.,” The Netflix Recommender System: Algorithms, Business Value and Innovation”, ACM Trans. Manage. Inf. Syst. 6, 4, Article 13 (December 2015).
[10] Zhiwen Yu, Xingshe Zhou ,Yanbin Hao,Jianhua Gu,” TV Program Recommendation for Multiple Viewers based on User Profile Merging”, User Model User-Adap Inter (2006).
[11] Yun Lei, Luciana Ferrer,Mitchell McLaren ,Nicolas Scheffer,” A Deep Neural Network Speaker Verification System Targeting Microphone Speech”, Speech Technology and Research Laboratory, SRI International, California, USA.
[12] Felix Burkhardt, Martin Eckert, Wiebke Johannsen, Joachim Stegmann,” A Database of Age and Gender Annotated Telephone Speech”, Ernst-Reuter-Platz 7, 10587 Berlin, Germany.
[13] Tomi kinnuen, Haizhou li ,”An Overview of Text-Independent Speaker Recognition from Features to Supervectors”, Speech Communication 52 (2010) 12–40. [14] Koen Verstrepen, Bart Goethals,” Top-N Recommendation for Shared Accounts”, University of Antwerp, Belgium.