© 2018 IJSRST | Volume 4 | Issue 2 | Print ISSN: 2395-6011 | Online ISSN: 2395-602X Themed Section: Science and Technology
Video Co-segmentation Based on Speed up Robust (SURF)
Feature Detector
Muddala Sravanthi
1, Dr. G. Sreenivasulu
21M.Tech, Electronics and Communication Engineering Department, Sri Venkateswara University, Tirupathi, Andhra Pradesh,
India
2Professor, Electronics and Communication Engineering Department, Sri Venkateswara University, Tirupathi, Andhra Pradesh,
India
ABSTRACT
Along side division, co-division assumes a noteworthy part in the field of picture handling. The majority of the current superior co-division calculations are generally perplexing because of the method for co-marking an arrangement of pictures and additionally the normal need of adjusting couple of parameters for powerful co-division .In this paper as opposed to following the ordinary method for co-naming various pictures, the co-division perform on every individual picture. Our future work depends on the video co-division utilizing surf indicator. Our exploratory outcome turns out to be better when contrasted with the other condition of workmanship strategies. Next computing the slipped by time and precision of the framework precisely. This strategy gives accurate and substantial outcomes.
Keywords : Segmentation, Co-Segmentation Accuracy, Elapsed Time, Surf Detector
I.
INTRODUCTION
In PC vision, picture division is the route toward allocating a propelled picture into various segments (sets of pixels, generally called super-pixels). The target of division is to modify and furthermore change the depiction of a photo into something that is more vital and more straightforward to separate. Picture division is as often as possible used to find articles and cutoff focuses (lines, turns, and so on.) in pictures. All the more correctly, picture division is the course toward apportioning a stamp to each pixel in a photograph to such an extent, to the point that pixels with a similar name share certain qualities.
The inevitable result of picture division is a game-plan of bits that with everything considered cover the whole picture, or a course of action of structures removed from the photograph (see edge region). Each of the pixels in an area are comparative with respect
to some trademark or took care of property, for example, shading, power, or surface. Near to zones are all around exceptional concerning practically identical attributes. Precisely when related with a stack of pictures, regular in therapeutic imaging, the following shapes after picture division can be utilized to make 3D ages with the assistance of addition estimations like walking solid shapes.
indicator and descriptor. It can be utilized for undertakings, for example, protest, picture enrollment, arrangement or 3D reproduction.
It is somewhat motivated by the scale-invariant element change descriptor. The standard form of Speed up robust feature transform is a few times speedier than scale invariant feature and guaranteed by its creators to be more powerful against various picture changes than scale.
To distinguish intrigue focuses, speed up robust feature transform uses an entire number gauge of the determinant of Hessian blob pointer, which can be handled with 3 number operations using a precompiled vital picture. Its segment descriptor relies upon the whole of the Haar wavelet response around the reason for interest. These can in like manner be prepared with the guide of the basic picture.
Speed up robust feature transform descriptors have been used to discover and see dissents, people or faces, to repeat 3D scenes, to track addresses and to isolate motivations behind interest.
Speed up robust feature transform was first presented by Herbert Bay European Conference on Computer Vision. An utilization of the figuring is authorized in the United States. An "upright" form of speed up robust features isn't invariant to picture pivot and in this manner quicker to figure and more qualified for application where the camera stays pretty much flat.
The picture is changed into facilitates, utilizing the multi-determination pyramid strategy, to duplicate the first picture with Pyramidal Gaussian or Laplacian Pyramid shape to acquire a picture with a similar size however with diminished transfer speed. This accomplishes an exceptional obscuring impact on the first picture, called Scale-Space and guarantees that the purposes of intrigue are scale invariant.
II.
RELATED WORK
Different weight maps
Luminance weight map
For the most part a debased photograph has a tendency to wind up plainly level in definite outcome where we are controlling its luminance pick up. It characterizes the standard deviation between luminance L and each R, G, and B shading channels while saving each info locale. This guide upgrades debased info however it might lessen the shading and picture differentiate. For this decreased shading and difference we have characterized different weights as Chroma and saliency (worldwide differentiation).
√ ⁄ [ ] [ ] [ ]
Luminance measures the perceivability at every pixel by doling out low esteems to districts with low perceivability and high esteems to areas with great perceivability. This weight delineate given by the accompanying condition
Chromaticity is a weight outline to control the immersion pick up at the yield and accordingly increment its colorfulness.it is given by the condition
(
)
Chromatic weight map
It controls saturation gain in the result image, using gauss curve
d = exp (-s- ... (3)
With standard deviation σ= 0.3 computes the distance between saturation value S and maximum of saturation range σ indicates saturation. Higher saturation images are always preferred.
Saliency weight map
districts. The saliency weight for any pixel at position (x,y) of info IK is given by
…….. (4)
Where u is arithmetic mean pixel value of input image is blurred version of the same input which has its objective to remove high frequency noise and textures.
Superpixel Segmentation
A super pixel can be characterized as a gathering of pixels which have comparative attributes. It is for the most part shading based division. Super pixels can be extremely useful for picture division. There are numerous calculations accessible to fragment super pixels yet the one that I am utilizing is cutting edge with a low computational overhead.
Straightforward Linear Iterative Clustering is the cutting edge calculation to portion super pixels which doesn't require much computational power. In a word, the calculation bunches pixels in the consolidated five-dimensional shading and picture plane space to effectively produce smaller, almost uniform super pixels. This calculation was produced at picture and visual portrayal gather at EPFL and here's the distributed paper and authority source code.
The approach is extremely straightforward really. SLIC plays out a nearby grouping of pixels in 5-D space characterized by the L, a, b estimations of the CIELAB shading space and x, y directions of the pixels. It has an alternate separation estimation which empowers conservativeness and consistency in the super pixel shapes, and can be utilized on grayscale pictures and also shading pictures.
SLIC creates superpixels by grouping pixels in view of their shading likeness and nearness in the picture plane. A 5 dimensional space is utilized for bunching. CIELAB shading space is considered as never-endingly uniform for little shading separations. It isn't fitting to just utilize Euclidean separation in the
5D space and subsequently the creators have presented another separation measure that considers superpixels estimate.
Otsu Thresholding
In PC vision and picture taking care of, Otsu's technique, named after nobuyuki Otsu is used to normally perform gathering based picture thresholding, or the reducing of a graylevel picture to a parallel picture. The computation acknowledge that the photo contains two classes of pixels following bi-secluded histogram (frontal territory pixels and establishment pixels), it by then finds out the perfect edge disconnecting the two classes with the objective that their joined spread (intra-class change) is unimportant, or proportionately (in light of the fact that the aggregate of pairwise squared divisions is enduring), so their between class variance is maximal. In this way, Otsu's technique is around a one-dimensional, discrete straightforward of Fisher's Discriminant Analysis. Otsu's strategy is likewise straightforwardly identified with the Jenks enhancement technique.
In Otsu's technique we thoroughly look for the limit that limits the intra-class change (the difference inside the class), characterized as a weighted whole of fluctuations of the two classes:
Weights and are the probabilities of the two
classes separated
byathreshold t ,and and are variances of these two classes. The class probability is computed from the bins of the histogram:
∑
∑
The flow process of the proposed method is as follows First the Input consider as video and that video is converted into frames .from that number of frames considering the single frame and processing can be done on that frame .
Input video
The info video process includes a few preparing steps. To start with the flag is digitized by a simple to-advanced converter to deliver a crude, computerized information stream. On account of composite video, the luminance and chrominance are then isolated; this isn't fundamental for S-video sources. Next, the chrominance is demodulated to deliver shading contrast video information. Now, the information might be altered in order to change shine, difference, immersion and tone.
k-means clustering
K-implies batching is a strategy for vector quantization, at first from hail setting up, that is pervasive for bunch examination in data mining. k-implies grouping expects to section n discernments into k bundles in which each observation has a place with the gathering with the nearest mean, filling in as a model of the gathering. This results in an allocating of the data space into Voronoi cells.
∑ ∑
∑ ∑
(8) The issue is computationally troublesome; regardless, there are capable heuristic counts that are consistently used and join quickly to an area perfect. These are by and large like the want increase count for mixes of Gaussian movements by methods for an iterative refinement approach used by the two computations. Likewise, they both use cluster centers to show the
data; regardless, k-infers gathering has a tendency to find gatherings of for all intents and purposes indistinguishable spatial degree, while the want extension instrument empowers gatherings to have unmistakable shapes.
The calculation has a free relationship to the k-closest neighbor classifier an eminent machine learning strategy for depiction that is every now and again stirred up for k-implies in light of the k in the name. One can apply the 1-closest neighbor classifier on the package focuses got by k-plans to accumulate new information into the present packs. This is known as closest centroid classifier or Rocchio estimation. 1. Instate number of group k and focus.
2. For every pixel of a picture, compute the Euclidean separation d, between the middle and every pixel of a picture utilizing the connection given underneath 3. Appoint every one of the pixels to the closest focus in view of separation d.
4. After the sum total of what pixels have been relegated, recalculate new position of the inside utilizing the connection given underneath.
5. Rehash the procedure until the point when it fulfills the resilience or blunder esteem.
Video Object Co division
Question based co-division as a co-determination diagram in which areas with closer view like qualities are favored while additionally representing intra-video and between intra-video forefront intelligibility. To deal with various forefront objects, we grow the co-choice diagram display into a proposed multi-state determination chart show that upgrades the divisions of various questions mutually.
The goal of picture co-division is to together portion a particular question from at least two pictures, and it is accepted that all pictures contain that protest. There are additionally a few co division strategies that lead the co-division of boisterous picture accumulations.
Object discovery
Video question disclosure has as of late been broadly considered, in both unsupervised or feebly regulated settings. Anproposed an inert subject model for unsupervised question revelation in recordings by joining PLSA with Probabilistic Data Association channel. A point show by consolidating a word co-event earlier into LDA for productive revelation of topical video objects from an arrangement of key casings. The drew in human tuned in to give a couple of marks at the casing level to generally show the fundamental protest of intrigue. Its completely programmed technique to take in a class-particular question indicator from pitifully explained certifiable recordings. Tuytelaars studied the unsupervised question revelation techniques, however with the attention on still pictures. Conversely, our video protest disclosure is accomplished by proliferating superpixel level marks to outline level through a Spatial-MILBoosting calculation
Surf flow field
SURF Points protest, focuses, containing data about SURF highlights recognized in the 2-D grayscale input
picture I. The recognize SURF Features work executes the Speeded-Up Robust Features calculation to discover blob highlights. In PC vision, blob identification techniques are gone for identifying locales in a computerized picture that vary in properties, for example, splendor or shading, contrasted with encompassing areas. Calmly, a blob is a locale of a photo in which a couple of properties are reliable or generally unfaltering; each one of the concentrations in a blob can be considered in some sense to resemble each other. The most generally perceived procedure for blob disclosure is convolution. Given some property of interest imparted as a component of position on the photo, there are two rule classes of blob identifiers: (I) differential techniques, which depend on subordinates of the capacity regarding position, and (ii) strategies in light of neighborhood extraordinary, which depend on finding the nearby maxima and minima of the capacity. With the later wording utilized as a part of the field, these finders can likewise be alluded to as intrigue point administrators, or then again intrigue area administrators (see additionally intrigue point recognition and corner discovery.
SURF utilizes square-formed channels as a guess of Gaussian smoothing. (The SIFT approach utilizes fell channels to distinguish scale-invariant trademark focuses, where the distinction of Gaussians is computed on rescaled pictures logically.) Filtering the picture with a square is considerably speedier if the necessary picture is utilized:
∑ ∑
by Schmid, SURF furthermore uses the determinant of the Hessian for picking the scale, as is in like manner done by Lindeberg. Given a point p=(x, y) in a photo I, the Hessian grid H(p, σ) at point p and scale σ, is:
(
) (10)
Protest dividing is the way toward apportioning a computerized imageinto various fragments (sets of pixels, otherwise called super-pixels). The objective of division is to improve and additionally change the portrayal of a picture into something that is more important and simpler to break down.
Figure 1 : Block Diagram of Proposed Method Object partitioning
Jaccard similarity
The Jaccard file, otherwise called Intersection over Union and the Jaccard closeness coefficient (initially begat coefficient de comminute by Paul Jaccard), is a measurement utilized for contrasting the similitude and assorted variety of test sets. The Jaccard coefficient measures comparability between limited example sets.
IV.
RESULTSFigure 1 : Input Video
Figure 2 : Lack Joint Information Between The Video, Video segmentation And Video Object
Co-segmentation
Input Video
Video converted to frames
Converting frames to gray
Dividing into clusters
Object co-segmentation
Figure 3: Video Object Cosegmentation
Figure 4: Object Discovery
Figure 5: Object like Area Obtained After Object Recovery
Figure 6: Visualization Of Surf Flow Field
Figure 7: Over Segmentation On Surf Flow Field
Figure 8: Object Partitioning
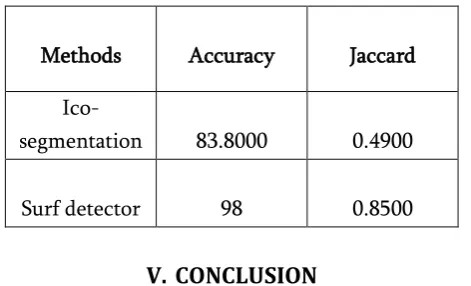
TABLE 1: Difference between Ico-segmentation and Surf detector
Methods Accuracy Jaccard
Ico-segmentation 83.8000 0.4900
Surf detector 98 0.8500
V.
CONCLUSION
Our paper manages the idea of video division .the question can be portioned utilizing surf indicator. The question sectioned utilizing surf indicator is better when contrasted with the other existing strategies .our technique gives preferable execution over the other condition of craftsmanship techniques. The execution additionally assessed as far as exactness and jaccard closeness.
VI.
REFERENCES
[1]. C. Rother, T. Minka, A. Blake, and V. Kolmogorov, Co-segmentation of image pairs by histogram matching-incorporating a global constraint into MRF, in Proc. IEEE Comput. Vis. Pattern Recog., Jun. 2006, vol. 1, pp. 993-1000. [2]. D. S. Hochbaum and V. Singh, An efficient
algorithm for co-segmentation, in Proc. IEEE Int. Conf. Comput. Vis., Sep.-Oct. 2009, pp. 269-276.
[3]. L.Mukherjee,V. Singh, andC.R.Dyer, Half-integrality based algorithms for cosegmentation of images, in Proc. IEEE Comput. Vis. Pattern Recog., Jun. 2009, pp. 2028-2035.
[4]. A. Joulin, F. Bach, and J. Ponce, Discriminative clustering for image co-segmentation, in Proc. IEEE Comput. Vis. Pattern Recog., Jun. 2010, pp. 1943-1950.
[5]. G. Kim, E. P. Xing, L. Fei-Fei, and T. Kanade, Distributed cosegmentation via submodular optimization on anisotropic diffusion, in Proc.
IEEE Int. Conf. Comput. Vis., Nov. 2011, pp. 169-176.
[6]. H. Li, F. Meng, andK.N.Ngan, ICo-salient object detection frommultiple images, IEEE Trans. Multimedia, vol. 15, no. 8, pp. 1896-1909, Dec. 2013.
[7]. F. Meng, H. Li, G. Liu, and K. N. Ngan, Object co-segmentation based on shortest path algorithm and saliency model, IEEE Trans. Multimedia, vol. 14, no. 5, pp. 1429-1441, Oct. 2012.
[8]. D. Batra, A. Kowdle, D. Parikh, J. Luo, and T. Chen, ICoseg: Interactive co-segmentation with intelligent scribble guidance, in Proc. IEEEComput. Vis. Pattern Recog., Jun. 2010, pp. 3169-3176.
[9]. M. D. Collins, J. Xu, L. Grady, and V. Singh, Random walks based multi-image segmentation: Quasiconvexity results and GPU-based solutions, in Proc., IEEE Compute. Vis. Pattern Recog., Jun. 2012, pp. 1656-1663.
[10]. D. Batra, D. Parikh, A.Kowdle, T. Chen, and J. Luo, Seed image selection in interactive cosegmentation, in Proc. IEEE Int. Conf. Image Process., Nov. 2009, pp. 2393-2396.
[11]. F. Meng, B. Luo, and C. Huang, Object co-segmentation based on directed graph clustering, in Proc. IEEE Visual Commun. Image Process. Nov. 2013, pp. 1-5.
[12]. Z. Liu, J. Zhu, J. Bu, and C. Chen, Object co-segmentation by nonrigid mapping, Neurocomputing, vol. 135, pp. 107-116, 2014. [13]. T. Ma and L. J. Latecki, Graph transduction
learning with connectivity constraints with application to multiple foreground co-segmentations, in Proc. IEEE Comput. Vis. Pattern Recog., Jun. 2013, pp. 1955-1962.