ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
Explore the Potential Impact of Big Data
Challenges, Open Research Issues and various
Tools Associated
V.Vinay Kumar*1, T.Aruna Jyothi*2, Dr.G.Shyama Chandra Prasad*3
Assistant Prof, Dept. of CSE, Matrusri Engineering College, Saidabad, Hyderabad, India1*
Assistant Prof, Dept. of CSE, Matrusri Engineering College, Saidabad, Hyderabad, India2*
Associate Prof, Dept. of CSE, Matrusri Engineering College, Saidabad, Hyderabad, India3*
ABSTRACT: An immense store of terabytes of information is produced every day from current data frameworks and advanced advances, for example, Internet of Things and distributed computing. Investigation of these monstrous information requires a ton of endeavors at different levels to extricate learning for basic leadership. Along these lines, huge information investigation is flow range of innovative work. The fundamental goal of this paper is to investigate the potential effect of huge information challenges, open research issues, and different devices related with it. Accordingly, this article gives a stage to investigate enormous information at various stages. Moreover, it opens another skyline for specialists to build up the arrangement, in view of the difficulties and open research issues.
KEYWORDS: Structured data, Big data analytics, Hadoop, Massive data, Unstructured Data.
I. INTRODUCTION
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
information mining and factual examination. These difficulties for the most part emerge when we wish to perform learning revelation and portrayal for its viable applications. A basic issue is the manner by which to quantitatively portray the fundamental attributes of enormous information. There is a requirement for epistemological ramifications in depicting information upheaval [5]. Furthermore, the examination on multifaceted nature hypothesis of huge information will help comprehend fundamental attributes and development of complex examples in huge information, rearrange its portrayal, shows signs of improvement learning deliberation, and guide the plan of processing models and calculations on huge information [4]. Much research was done by different scientists on enormous information and its patterns [6]. Notwithstanding, it is to be noticed that all information accessible in the type of enormous information are not helpful for investigation or basic leadership prepare. Industry and the scholarly community are occupied with scattering the discoveries of huge information. This paper concentrates on challenges in huge information and its accessible strategies.
II. CHALLENGES IN BIG DATA ANALYTICS
Late years huge information has been amassed in a few spaces like human services, open organization, retail, natural chemistry, and other interdisciplinary logical examines. Online applications experience huge information every now and again, for example, social processing, web content and reports, and web seek ordering. Social figuring incorporates informal community investigation, online groups, recommender frameworks, notoriety frameworks, and forecast markets where as web seek ordering incorporates ISI, IEEE Xplorer, Scopus, Thomson Reuters and so on. Considering this points of interest of enormous information it gives another open doors in the learning handling errands for the up and coming specialists. However opportunities dependably take after a few difficulties.
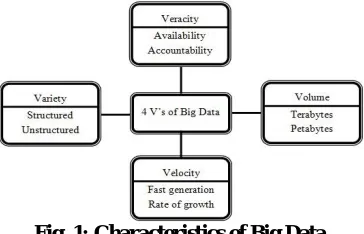
Fig. 1: Characteristics of Big Data
To deal with the difficulties we have to know different computational complexities, data security, and computational technique, to examine huge information. For instance, numerous measurable techniques that perform well for little information estimate don't scale to voluminous information. Correspondingly, numerous computational methods that perform well for little information confront critical difficulties in examining huge information. Different difficulties that the wellbeing area confront was being investigated by much analysts. Here the difficulties of huge information examination are characterized into four general classifications to be specific information stockpiling and examination; learning disclosure and computational complexities; adaptability and representation of information and data security.
A. Information Storage and Analysis
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
memory (PCM) was presented. However the accessible capacity advances can't have the required execution for handling huge information. Another test with Big Data investigation is credited to assorted qualities of information. with the steadily developing of datasets, information mining assignments has fundamentally expanded. Furthermore information lessening, information choice, highlight choice is a basic undertaking particularly when managing vast datasets. This shows a phenomenal test for scientists. It is on account of, existing calculations may not generally react in a sufficient time when managing these high dimensional information. Robotization of this procedure and growing new machine learning calculations to guarantee consistency is a noteworthy test lately. Notwithstanding all these Clustering of vast datasets that assistance in investigating the enormous information is of prime concern. Late advances, for example, hadoop and outline make it conceivable to gather substantial measure of semi organized and unstructured information in a sensible measure of time. The key building challenge is the way to successfully break down these information for acquiring better learning. A standard procedure to this end is to change the semi organized or unstructured information into organized information, and after that apply information mining calculations to separate learning. A structure to examine information was talked about by Das and Kumar. Correspondingly detail clarification of information investigation for open tweets was likewise talked about by Das et al in their paper. The real test for this situation is to give careful consideration for outlining stockpiling frameworks and to raise productive information investigation instrument that give ensures on the yield when the information originates from various sources. Moreover, plan of machine learning calculations to investigate information is basic for enhancing effectiveness and adaptability.
B. Information Discovery and Computational Complexities
Learning disclosure and portrayal is a prime issue in enormous information. It incorporates various sub fields, for example, validation, documenting, administration, conservation, data recovery, and portrayal. There are a few devices for learning revelation and portrayal, for example, fluffy set, harsh set, delicate set, close set, formal idea examination, key segment investigation and so on to give some examples. Moreover many hybridized systems are too created to handle genuine issues. Every one of these methods are issue subordinate. Advance some of these procedures may not be reasonable for vast datasets in a consecutive PC. At a similar time a portion of the systems has great qualities of versatility over parallel PC. Since the extent of huge information continues expanding exponentially, the accessible instruments may not be effective to handle these information for acquiring significant data. The most prominent approach if there should arise an occurrence of vast dataset administration is information distribution centers and information stores. Information distribution center is for the most part mindful to store information that are sourced from operational frameworks though information shop depends on an information stockroom and encourages investigation. Investigation of vast dataset requires more computational complexities. The significant issue is to deal with irregularities and vulnerability introduce in the datasets. When all is said in done, orderly demonstrating of the computational many-sided quality is utilized. It might be hard to build up a complete numerical framework that is extensively relevant to Big Data. In any case, a space particular information examination should be possible effortlessly by understanding the specific complexities. A progression of such advancement could reproduce enormous information examination for various ranges. Much research and overview has been completed toward this path utilizing machine learning systems with the minimum memory necessities. The essential goal in these exploration is to limit computational cost handling and complexities. Be that as it may, current huge information investigation devices have poor execution in dealing with computational complexities, instability, and irregularities. It prompts an extraordinary test to create systems and advances that can bargain computational multifaceted nature, instability, and irregularities in a viable way.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
approach model and aversion framework. Albeit much research has been done to secure huge information however it requires parcel of change. The real test is to build up a multi-level security, protection safeguarded information show for huge information.
III. OPEN RESEARCH ISSUES IN BIG DATA ANALYTICS
Enormous information examination and information science are turning into the exploration point of convergence in enterprises and the scholarly community. Information science goes for looking into huge information and learning extraction from information. Uses of huge information and information science incorporate data science, vulnerability displaying, questionable information investigation, machine learning, measurable learning, design acknowledgment, information warehousing, and flag handling. Successful mix of advancements and investigation will bring about foreseeing the future float of occasions. Principle center of this segment is to talk about open explore issues in huge information investigation. The examination issues relating to enormous information investigation are grouped into three general classes in particular web of things (IoT), distributed computing, bio propelled figuring, and quantum registering. In any case it is not constrained to these issues. More research issues identified with social insurance enormous information can be found in Husing Kuo et al. paper.
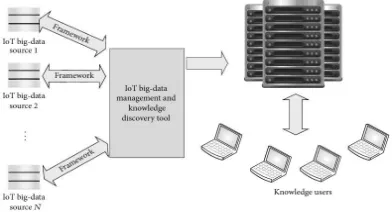
A. IoT for Big Data Analytics: Web has rebuilt worldwide interrelations, the craft of organizations, social insurgencies and a mind blowing number of individual attributes. Right now, machines are getting in on the demonstration to control multitudinous self-sufficient contraptions by means of web and make Internet of Things (IoT). Subsequently, apparatuses are turning into the client of the web, much the same as people with the web programs. Web of Things is pulling in the consideration of late specialists for its most encouraging open doors and difficulties. It has a basic financial and societal effect for the future development of data, system and correspondence innovation. The new direction of future will be in the long run, everything will be associated and astutely controlled. The idea of IoT is winding up plainly more germane to the reasonable world because of the advancement of cell phones, installed and universal correspondence advances, distributed computing, and information investigation. Also, IoT presents challenges in blends of volume, speed and assortment. In a more extensive sense, much the same as the web, Internet of Things empowers the gadgets to exist in a bunch of spots and encourages applications extending from trifling to the critical. On the other hand, it is as yet perplexing to comprehend IoT well, including definitions, substance and contrasts from other comparable ideas. A few expanded advancements, for example, computational insight, and huge information can be joined together to enhance the information administration and learning disclosure of huge scale robotization applications. Much research toward this path has been completed by Mishra, Lin and Chang. Information securing from IoT information is the greatest test that enormous information proficient are confronting. Consequently, it is basic to create foundation to investigate the IoT information. An IoT gadget creates persistent surges of information and the scientists can create instruments to separate important data from these information utilizing machine learning procedures. Understanding these surges of information produced from IoT gadgets and breaking down them to get important data is a testing issue and it prompts enormous information investigation. Machine learning calculations and computational knowledge systems is the main answer for handle huge information from IoT forthcoming. Key advancements that are related with IoT are likewise talked about in many research papers. Figure 2 delineates an outline of IoT enormous information and learning disclosure prepare
.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
Knowledge exploration system have originated from theories of human information processing such as frames, rules, tagging, and semantic networks. In general, it consists of four segments such as knowledge acquisition, knowledge base, knowledge dissemination, and knowledge application. In knowledge acquisition phase, knowledge is discovered by using various traditional and computational intelligence techniques. The discovered knowledge is stored in knowledge bases and expert systems are generally designed based on the discovered knowledge. Knowledge dissemination is important for obtaining meaningful information from the knowledge base. Knowledge extraction is a process that searches documents, knowledge within documents as well as knowledge bases. The final phase is to apply discovered knowledge in various applications. It is the ultimate goal of knowledge discovery. The knowledge exploration system is necessarily iterative with the judgment of knowledge application. There are many issues, discussions, and researches in this area of knowledge exploration. It is beyond scope of this survey paper. For better visualization, knowledge exploration system is depicted in Figure 3.
Fig. 3: IoT Knowledge Exploration System
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
condition. Else, it winds up noticeably hard to control the appropriation of calculation and the basic equipment. Yet, the real issues are protection concerns identifying with the facilitating of information on open servers, and the capacity of information from human investigations. Every one of these issues will take enormous information and distributed computing to an abnormal state of improvement.
VI. CONCLUSION
As of late information are created at an emotional pace. Examining these information is trying for a general man. To this end in this paper, we review the different research issues, difficulties, and instruments used to investigate these huge information. From this study, it is comprehended that each enormous information stage has its individual core interest. Some of them are intended for bunch preparing though some are great at constant systematic. Each enormous information stage likewise has particular usefulness. Distinctive procedures utilized for the investigation incorporate measurable examination, machine learning, information mining, keen examination, distributed computing, quantum registering, and information stream preparing. We believe that in future analysts will give careful consideration to these procedures to take care of issues of huge information successfully and effectively.
V. FUTURE WORK
The measure of information gathered from different applications everywhere throughout the world over a wide assortment of fields today is required to twofold at regular intervals. It has no utility unless these are dissected to get valuable data. This requires the advancement of methods which can be utilized to encourage huge information examination. The improvement of intense PCs is an aid to execute these strategies prompting robotized frameworks. The change of information into learning is by no methods a simple errand for elite vast scale information handling, including abusing parallelism of present and up and coming PC structures for information mining. In addition, these information may include instability in a wide range of structures. A wide range of models like fluffy sets, harsh sets, delicate sets, neural systems, their speculations and half and half models got by joining at least two of these models have been observed to be productive in speaking to information. These models are additionally especially productive for investigation. As a general rule, huge information are decreased to incorporate just the critical qualities important from a specific report perspective or relying on the application territory. In this way, diminishment methods have been created. Frequently the information gathered have missing esteems. These qualities should be created or the tuples having these missing esteems are dispensed with from the informational index before examination. All the more critically, these new difficulties may contain, some of the time even break down, the execution, proficiency and adaptability of the committed information serious processing frameworks.
REFERENCES
[1] R. Kitchin, Big Data, new epistemologies and paradigm shifts, Big Data Society, 1(1) (2014), pp.1-12.
[2] C. L. Philip, Q. Chen and C. Y. Zhang, Data-intensive applications, challenges, techniques and technologies: A survey on big data, Information Sciences, 275 (2014), pp.314-347.
[3] K. Kambatla, G. Kollias, V. Kumar and A. Gram, Trends in big data analytics, Journal of Parallel and Distributed Computing, 74(7) (2014), pp.2561-2573.
[4] S. Del. Rio, V. Lopez, J. M. Bentez and F. Herrera, On the use of mapreduce for imbalanced big data using random forest, Information Sciences, 285 (2014), pp.112-137.
[5] MH. Kuo, T. Sahama, A. W. Kushniruk, E. M. Borycki and D. K. Grunwell, Health big data analytics: current perspectives, challenges and potential solutions, International Journal of Big Data Intelligence, 1 (2014), pp.114-126.
[6] R. Nambiar, A. Sethi, R. Bhardwaj and R. Vargheese, A look at challenges and opportunities of big data analytics in healthcare, IEEE International Conference on Big Data, 2013, pp.17-22.
[7] Z. Huang, A fast clustering algorithm to cluster very large categorical data sets in data mining, SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery, 1997.
[8] M. K.Kakhani, S. Kakhani and S. R.Biradar, Research issues in big data analytics, International Journal of Application or Innovation in Engineering & Management, 2(8) (2015), pp.228-232.
[9] A. Gandomi and M. Haider, Beyond the hype: Big data concepts, methods, and analytics, International Journal of Information Management, 35(2) (2015), pp.137-144.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(An ISO 3297: 2007 Certified Organization)
Website: www.ijirset.com
Vol. 6, Issue 6, June 2017
[11] X. Jin, B. W.Wah, X. Cheng and Y. Wang, Significance and challenges of big data research, Big Data Research, 2(2) (2015), pp.59-64. [12] L. A. Zadeh, Fuzzy sets, Information and Control, 8 (1965), pp.338-353.
[13] Z. Pawlak, Rough sets, International Journal of Computer Information Science, 11 (1982), pp.341-356.
[14] D. Molodtsov, Soft set theory first results, Computers and Mathematics with Applications, 37(4/5) (1999), pp.19-31. [15] J. F.Peters, Near sets. General theory about nearness of objects, Applied Mathematical Sciences, 1(53) (2007), pp.2609-2629.
[16] R. Wille, Formal concept analysis as mathematical theory of concept and concept hierarchies, Lecture Notes in Artificial Intelligence, 3626 (2005), pp.1-33.
[17] I. T.Jolliffe, Principal Component Analysis, Springer, New York, 2002.
[18] O. Y. Al-Jarrah, P. D. Yoo, S. Muhaidat, G. K. Karagiannidis and K. Taha, Efficient machine learning for big data: A review, Big Data Research, 2(3) (2015), pp.87-93.
[19] H. Zhu, Z. Xu and Y. Huang, Research on the security technology of big data information, International Conference on Information Technology and Management Innovation, 2015, pp.1041-1044.
[20] Z. Hongjun, H. Wenning, H. Dengchao and M. Yuxing, Survey of research on information security in big data, Congresso da sociedada Brasileira de Computacao, 2014, pp.1-6.
[21] I. Merelli, H. Perez-sanchez, S. Gesing and D. D.Agostino, Managing, analysing, and integrating big data in medical bioinformatics: open problems and future perspectives, Bio Med Research International, 2014, (2014), pp.1-13.
BIOGRAPHY
Mr.V.Vinay Kumar is currently working as an Asst.Professor in the Department of CSE, Matrusri Engineering College, Saidabad Hyderabad, Telangana. He received his M.Tech in Computer Science Department from JNTU School of Information Technology, Hyderabad.
Mrs.T.Aruna Jyothi is currently working as an Assistant Professor in computer Science Department, Matrusri Engineering College, Saidabad Hyderabad.