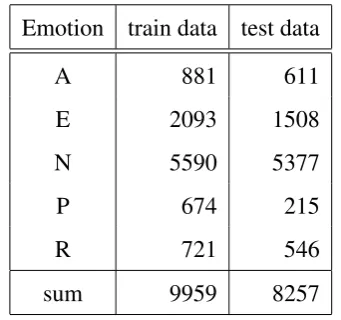
Support Super-Vector Machines in Automatic Speech Emotion
Recognition
陳嘉穎Chia-Ying Chen
國立中山大學資訊工程學系
Department of Computer Science and Information Engineering National Sun Yat-sen University
[email protected] 陳嘉平Chia-Ping Chen
國立中山大學資訊工程學系
Department of Computer Science and Information Engineering National Sun Yat-sen University
Abstract
In this paper, we use super-vectors in support vector machines for automatic speech emotion recognition. In our implementation, an utterance is converted to a super-vector formed by the mean vectors of a Gaussian mixture model adapted from a universal back-ground model. The proposed method is evaluated on FAU-Aibo database which is well-known to be used in INTERSPEECH 2009 Emotion Challenge. In the case of HMM-based dynamic modeling classifier, we achieve an unweighted average (UA) recall rate of 40.0%, over a baseline of 35.5%, by using the delta features and increasing the number of mixture components. In the case of SVM-based static modeling classifier, we achieve an unweighted average (UA) recall rate of 38.9%, over a baseline of 38.2%, by using the proposed super-vectors.
Keywords:Speech Emotion Recognition, GMM, Super-vector, SVM
The 2016 Conference on Computational Linguistics and Speech Processing ROCLING 2016, pp. 142-152
Table 3: Baseline acoustic features [2].
LLDs Functionals
RMS Energy mean
ZCR standard devation
MFCC 1-12 kurtosis, skewness
HNR extrmes:value, rel.position, range
F0 linear regression:offset, slope, MSE
4
Results
4.1
SVM Static Model with Super-Vectors
The SVMs are implemented as specified by the Challenge. The dimension of the super-vector is related to the number of components in GMM. Since there are 16 LLD, the dimension is
16×K
with LLD alone, and
16×2×K
if the delta LLD are also included in the feature vector. We use notation O (Original) to describe 16 LLDs, and use notation∆to describe their delta.
The results with varyingKare summarized in Table 4.
Table 4: Recall rates in percentage with support super-vector machines, using original data.
feature no. comp vector size UA WA
O 8 128 26.9 64.9
32 512 28.4 62.5
64 1024 28.3 60.9
O +∆ 8 256 31.0 64.8
32 1024 29.8 60.1
64 2048 30.1 55.5
to the number of data points of N, resulting in 27,950 data points for the training data. The results with varyingKis summarized in Table 5.
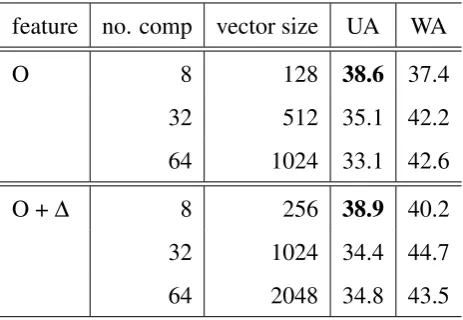
Table 5: Recall rates in percentage with support super-vector machines, combining SMOTE
for data balance.
feature no. comp vector size UA WA
O 8 128 38.6 37.4
32 512 35.1 42.2
64 1024 33.1 42.6
O +∆ 8 256 38.9 40.2
32 1024 34.4 44.7
64 2048 34.8 43.5
From the results in Table 4 and Table 5, the following observations can be made.
• The proposed super-vectors outperform the baseline feature vectors, with SMOTE for data bal-ance (38.9% over 38.4%) or without SMOTE (31.0% over 28.9%).
• WhenK=8, the performance of 38.9% UA is better than the performance of 38.2% UA achieved by the baseline feature vectors. Note that this is achieved by a lower dimension of feature space (256 vs. 384).
• We can exclude the delta features to reduce feature dimension to 128, and still get better results than baseline (38.6% vs. 38.2%).
4.2
HMM Dynamic Model for LLD
Following the Challenge [2], we use HMMs for the standard LLDs. The results with baseline settings as follows are shown in Table 6.
• left-to-right HMM
• one model per emotion
• diverse number (1, 3, 5) of states
• 2 Gaussian mixtures
Table 8: UA recall rates in percentage of GMM-UBM on standard LLDs with varying
compo-nents.
no. comp. feature UA WA
8 O 33.7 21.8
O +∆ 34.1 20.2
32 O 37.6 29.1
O +∆ 39.1 32.4
64 O 36.2 25.4
O +∆ 37.9 31.5
256 O 34.2 20.5
O +∆ 39.2 27.6
components.
5
Conclusion
References
[1] X. Zhang, Y. Sun, and S. Duan, “Progress in speech emotion recognition,” TENCON 2015 - 2015 IEEE Region 10 Conference,pp. 1 – 6, 2015.
[2] B. Schuller, S. Steidl, and A. Batliner, “The INTERSPEECH 2009 emotion challenge,” in Pro-ceedings of INTERSPEECH, 2009, pp.312–315.
[3] G. Weiss and F. Provost, “The effect of class distribution on classifier learning: An empirical study,” Department of Computer Science,Rutgers University, 2001.
[4] B. Vlasenko, “Processing affected speech within human machine interaction,” in Proc. Interspeech. Brighton, 2009, pp. 2039–2042.
[5] D. Le and E. M. Provost, “Emotion recognition from spontaneous speech using hidden markov models with deep belief networks,”Proceedings of Automatic Speech Recognition and Understand-ing(ASRU), 2013.
[6] Y. Yang, M. Yang, and Z. Wu, “A rank based metric of anchor models for speaker verification,” Proc. IEEE Intl Conf. Multimedia and Expo (ICME 06), pp. 1097–1100, 2006.
[7] S. Ntalampiras and N. Fakotakis, “Anchor models for emotion recognition from speech,” IEEE Transactions on Affective Computing,vol. 4, pp. 280–290, 2013.
[8] W. Campbell, D. Sturim, D. Reynolds, and A. Solomonoff, “Svm based speaker verification using a gmm supervector kernel and nap variability compensation,” Proc. of ICASSP 2006, pp. 97–100, 2006.
[9] M. Liu and Z. Huang, “Multi-feature fusion using multi-gmm supervector for svm speaker verifi-cation,” International Congress on Image and Signal Processing. Tianjin: IEEE, pp. 1–4, 2009. [10] H. Hu, Ming-XingXu, and W. Wu, “Gmm supervector based svm with spectral features for
speech emotion recognition,” in Proc. Int. Conf.Acoustics, Speech, and Signal Processing, vol. 4, pp.413–416, 2007.
[11] Bishop, Pattern Recognition and Machine Learning. LLC, New York: Springer Science Business Media, 2006.
[13] D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, “Speaker verification using adapted gaussian mixture models,” Digital Signal Processing, 10(1 - 3), pp. 19–41, 2000.
[14] J. L. Gauvain and C. H. Lee, “Maximum a posteriori estimation for multivariate gaussian mixture observations of markov chains,”IEEE Trans. Speech Audio Process, pp. 291–298, 1994.
[15] C. Cortes and V. Vapnik, “Support-vector networks,” Machine learning, vol. 20, no. 3, pp. 273–297, 1995.