R E S E A R C H
Open Access
Improving the conditioning of the
optimization criterion in acoustic
multi-channel equalization using shorter
reshaping filters
Ina Kodrasi
*and Simon Doclo
Abstract
In acoustic multi-channel equalization techniques, such as complete multi-channel equalization based on the multiple-input/output inverse theorem (MINT), relaxed multi-channel least-squares (RMCLS), and partial multi-channel equalization based on MINT (PMINT), the length of the reshaping filters is generally chosen such that perfect
dereverberation can be achieved for perfectly estimated room impulse responses (RIRs). However, since in practice the available RIRs typically differ from the true RIRs, this reshaping filter length may not be optimal. This paper provides a mathematical analysis of the robustness increase of equalization techniques against RIR perturbations when using a shorter reshaping filter length than conventionally used. Based on the condition number of the (weighted) convolution matrix of the RIRs, a mathematical relationship between the reshaping filter length and the robustness against RIR perturbations is established. It is shown that shorter reshaping filters than conventionally used yield a smaller condition number, i.e., a higher robustness against RIR perturbations. In addition, we propose an automatic non-intrusive procedure for determining the reshaping filter length based on the L-curve. Simulation results confirm that using a shorter reshaping filter length than conventionally used yields a significant increase in robustness against RIR perturbations for MINT, RMCLS, and PMINT. Furthermore, it is shown that PMINT using an optimal intrusively determined reshaping filter length outperforms all other considered techniques. Finally, it is shown that the automatic non-intrusively determined reshaping filter length in PMINT yields a similar performance as the optimal intrusively determined reshaping filter length.
Keywords: Speech dereverberation, Condition number, Reshaping filter length, L-curve
1 Introduction
The microphone signals recorded in many hands-free speech communication applications, such as teleconfer-encing, voice-controlled systems, or hearing aids, do not only contain the desired speech signal but also attenuated and delayed copies due to reverberation. While early reverberation may be desirable [1–3], late reverberation may degrade the perceived speech quality and intelligibil-ity [4–6] as well as the performance of automatic speech recognition systems [7,8]. In order to mitigate these detri-mental effects of reverberation, several single-channel and
*Correspondence:[email protected]
Department of Medical Physics and Acoustics, University of Oldenburg, 26111 Oldenburg, Germany
multi-channel dereverberation techniques have been pro-posed [9], with multi-channel techniques being generally preferred since they are able to exploit both the spectro-temporal and the spatial characteristics of the received microphone signals. Existing multi-channel dereverber-ation techniques can be broadly classified into spectro-temporal enhancement techniques [10–14], probabilistic modeling-based techniques [15–18], and acoustic multi-channel equalization techniques [19–26]. Acoustic multi-channel equalization techniques aim to reshape the available room impulse responses (RIRs) between the speaker and the microphone array. Since in theory they can achieve perfect dereverberation [19], they represent an attractive approach to speech dereverberation.
A well-known complete multi-channel equalization technique aiming at acoustic system inversion is the multiple-input/output inverse theorem (MINT)-based technique [19], which however suffers from drawbacks in practice. Since the available RIRs typically differ from the true RIRs due to fluctuations (e.g., temperature or position variations [27]) or due to the sensitivity of blind system identification (BSI) and supervised system identifi-cation (SSI) methods to near-common zeros or interfering noise [28–30], MINT generally fails to invert the true RIRs, possibly leading to severe distortions in the output signal [22–24, 26]. In order to increase the robustness against RIR perturbations, partial multi-channel equal-ization techniques, such as relaxed multi-channel least-squares (RMCLS) [23] and partial multi-channel equalization based on MINT (PMINT) [24], have been proposed. Since early reflections tend to improve speech intelligibility [1–3] and late reflections are the major cause of speech intelligibility degradation [4–6], the objective of partial equalization techniques is to shorten the overall impulse response by suppressing only the late reflections. While RMCLS imposes no constraints on the remaining early reflections, PMINT has been shown to be more perceptually advantageous since it also aims to control the remaining early reflections. Although partial equalization techniques can be significantly more robust than MINT, their performance still remains rather susceptible to RIR perturbations [23,24,26]. As a result, several methods have been proposed to further increase the robustness against RIR perturbations. In [22, 24], it has been proposed to incorporate regularization, such that the distortion energy due to RIR perturbations is decreased. In [26], it has been proposed to use a signal-dependent penalty function to promote sparsity in the output signal and reduce artifacts generated by non-robust techniques. In [31, 32], it has been proposed to relax the constraints on the filter design by constructing approximate reshaping filters in the subband domain. In [33], it has been proposed to relax the constraints on the filter design by using a shorter reshaping filter length than conventionally used. The objective of this paper is to provide a mathematical analysis of the robustness increase when using a shorter reshaping filter length as well as to propose an automatic non-intrusive procedure for selecting an optimal shorter reshaping filter length.
The length of the reshaping filters in MINT, RMCLS, and PMINT is conventionally chosen such that per-fect dereverberation can be achieved for perper-fectly esti-mated RIRs. As already mentioned, since in practice the available RIRs typically differ from the true RIRs, this choice of the reshaping filter length yields a high sensi-tivity to RIR perturbations. In [33], it has been analyt-ically shown that decreasing the reshaping filter length increases the robustness for MINT and PMINT only if the
multi-channel convolution matrix of the RIRs is a square matrix. In this paper, it is analytically shown that decreas-ing the reshapdecreas-ing filter length increases the robustness of MINT, RMCLS, and PMINT independently of the dimen-sion of the (weighted) multi-channel convolution matrix of the RIRs. A mathematical relationship between the reshaping filter length and the condition number of the (weighted) multi-channel convolution matrix of the avail-able RIRs, hence, the sensitivity of equalization techniques to RIR perturbations, is derived. We show that shorter reshaping filters than conventionally used yield a smaller condition number, i.e., a higher robustness against RIR perturbations.
In general, the reshaping filter length yielding opti-mal performance can only be determined intrusively (i.e., using a clean reference signal), obviously limiting the prac-tical applicability. Hence, we also propose and investigate an automatic non-intrusive selection procedure for the reshaping filter length based on the L-curve [34–36].
Simulation results for several acoustic systems and RIR perturbations show by means of instrumental per-formance measures that using shorter reshaping filters in MINT, RMCLS, and PMINT significantly increases the robustness against RIR perturbations. In addition, it is demonstrated that PMINT using the optimal intru-sively determined reshaping filter length outperforms the other considered equalization techniques, yielding a larger reverberant energy suppression and perceptual speech quality improvement. Furthermore, it is shown that the non-intrusively determined reshaping filter length yields a nearly optimal performance for PMINT.
The paper is organized as follows. In Section2, the con-sidered acoustic configuration and the used notation is introduced. In Section3, state-of-the-art acoustic multi-channel equalization techniques, i.e., MINT, RMCLS, and PMINT, are briefly reviewed. In Section 4, the sensitiv-ity of these equalization techniques to RIR perturbations is evaluated by means of the condition number of the (weighted) convolution matrix and analytical insights on increasing the robustness by decreasing the reshaping filter length are provided. In Section5, the automatic non-intrusive procedure for determining the reshaping filter length is discussed. Using instrumental performance mea-sures, the dereverberation performance of all considered techniques is compared in Section6.
2 Configuration and notation
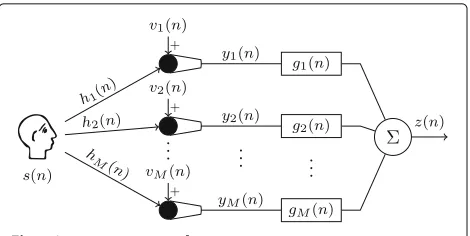
We consider an acoustic system with a single speech source and M microphones, as depicted in Fig. 1. The m-th microphone signal ym(n),m = 1, 2, . . ., M, at discrete time indexn, is given by
ym(n)=hm(n)∗s(n) xm(n)
Fig. 1Acoustic system configuration
where∗denotes convolution,s(n)is the clean speech sig-nal,hm(n)is the RIR between the speech source and the m-th microphone,xm(n)is the reverberant speech com-ponent, andvm(n)is the noise component. Since acoustic multi-channel equalization techniques generally design reshaping filters without taking the additive noise into account, in the following it is assumed thatvm(n)=0, and hence,ym(n)=xm(n).
Using the filter-and-sum structure in Fig.1, the output signalz(n)is equal to the sum of the filtered microphone signals, i.e.,
wheregm(n)is the filter applied to them-th microphone signal andc(n) denotes the equalized impulse response (EIR) between the speech source and the output of the sys-tem. In vector notation, the RIRhm and the filtergmare given by
hm=[hm(0)hm(1) . . . hm(Lh−1)]T, (4) gm=gm(0)gm(1) . . . gm(Lg−1)T, (5) whereLh andLg denote the RIR length and the reshap-ing filter length, respectively. Usreshap-ing theMLg–dimensional stacked filter vectorg=gT1gT2. . .gTMT, the EIR vectorc
of lengthLc=Lh+Lg−1, i.e.,c=[c(0)c(1) . . .c(Lc−1)]T can be expressed as
c=Hg, (6)
where H denotes the Lc × MLg–dimensional multi-channel convolution matrix of the RIRs, i.e., H = [H1H2. . .HM], with
Using the Lc-dimensional clean speech vector s(n) =[s(n)s(n−1) . . .s(n−Lc+1)]T, the output signal in (3) can be expressed as
z(n)=cTs(n)=gTHTs(n). (8) The reshaping filtergcan then be constructed based on different design objectives for the EIRc.
3 Acoustic multi-channel equalization
Acoustic multi-channel equalization techniques aim at speech dereverberation by designing the reshaping fil-terg such that the (weighted) EIRcin (6) is equal to a (weighted) target EIRcd. For the equalization techniques considered in this paper, i.e., MINT [19], RMCLS [23], and PMINT [24], the definition of the target EIRcdis pre-sented in Table 1, where τ denotes a delay, Ld denotes the length of the direct path and early reflections, and p ∈ {1, . . ., M}. The delay τ is incorporated in order to relax the causality constraints on the filter design [22]. The length of the direct path and early reflections Ld in the RMCLS and PMINT is typically considered to be between 10–50 ms [23,24]. It should be realized that in practice, only the perturbed RIRs hˆm are available, i.e., ˆ
hm = hm + em, where em represents the RIR pertur-bations due to fluctuations (e.g., temperature or position fluctuations [27]) or due to the sensitivity of BSI and
Table 1Definition of the target EIRcdand weighting matrixWfor MINT, RMCLS, and PMINT
Technique Target EIRcd Weighting matrixW
SSI methods to near-common zeros or interfering noise [28–30]. Hence, for the filter design, the perturbed convo-lution matrixHˆ =H+Eis used, whereErepresents the convolution matrix of the RIR perturbations. The consid-ered equalization techniques compute the filterg as the solution of the system of equations
WHgˆ =Wcd, (9)
with W an Lc × Lc–dimensional diagonal weighting matrix. The definition of the weighting matrix W for MINT, RMCLS, and PMINT is presented in Table 1, whereIdenotes theLc×Lc–dimensional identity matrix. Based on these definitions ofWandcd, it can be observed that on the one hand, MINT and PMINT do not use a weighting matrix and constrain all taps of the EIR (i.e., W = I), while on the other hand, RMCLS uses a weight-ing matrix and does not constrain all taps of the EIR (i.e., W = diag1 . . . 1 experimentally validated in [23,24,26] that by constrain-ing all taps of the EIR, MINT and PMINT may result in a good perceptual speech quality but a high sensitivity to RIR perturbations, whereas by not constraining all taps of the EIR, RMCLS may result in a lower sensitivity to RIR perturbations but a decreased perceptual speech quality.
For all considered equalization techniques, the reshap-ing filter solvreshap-ing (9) is computed by minimizing the (weighted) least-squares cost function
JLS= W(Hgˆ −cd)22. (10)
As shown in [19,23,24], assuming that the RIRs do not share common zeros and using a reshaping filter length
Lg≥
with·the ceiling operator, the reshaping filter minimiz-ing (10) to 0, and hence solving (9), is given by [19,23,24]
gLS=(WHˆ)+(Wcd), (12)
where{·}+denotes the matrix pseudo-inverse. When the true RIRs are available, i.e.,Hˆ = H, the reshaping filter of lengthLg according to (11) yields perfect dereverber-ation, i.e., WHgLS = Wcd. However, in the presence of RIR perturbations, i.e.,Hˆ = H, this filter typically fails to achieve perfect dereverberation, i.e.,WHgLS = Wcd, possibly even causing severe distortions in the output sig-nal [24,26]. The sensitivity of the reshaping filter to RIR perturbations can be evaluated by analyzing the condition number of the matrixWH.ˆ
4 Robust acoustic multi-channel equalization
In this section, the Wedin theorem [37] relating the con-dition number of the matrix being inverted to the
sensi-tivity of the solution to perturbations is briefly reviewed. In addition, it is analytically shown that using shorter reshaping filters than conventionally used decreases the condition number of the matrixWH, hence increasing theˆ robustness against RIR perturbations.
Wedin theorem[37]: Consider the system of equations Aq=b, where the matrixAhas dimensions u×v and rank r≤min{u,v}. LetAbe perturbed toA+A. The pseudo-inverse solutionq = A+bis then perturbed toq+q =
(A+A)+b, whereqis the deviation between the true and the perturbed solution. The condition number χA of the matrixAis defined as
χA= defining the variableξas
ξ = A2
A2
, (14)
the norm of the deviation between the true and the per-turbed solution is bounded by
q2≤ χAξ
q2 1−χAξ + (
AAT)+b2A2, (15) where it is assumed thatχAξ <1.
The relation in (15) shows that a large condition num-berχAcan result (and typically does) in a large deviation between the true and the perturbed solution [37,38].
For clarity of presentation, the notation summarized in Table2 is used in the following. In order to satisfy (11), reshaping filters in acoustic multi-channel equalization
Table 2Notation for different reshaping filter lengths and the
corresponding matrices
Reshaping filter length conventionally used in acoustic multi-channel equalization techniques
WtHˆt Matrix when using the reshaping filter lengthLtg
pt=Lh+Lgt−1 Number of rows inWtHˆt qt=MLtg≥pt Number of columns inWtHˆt rt≤pt Rank ofWtHˆt
Ls
g<Ltg Reshaping filter length smaller thanLtg WsHˆs Matrix when using the reshaping filter lengthLsg
techniques are conventionally designed using the filter lengthLtg=Lh−1
M−1
, i.e., based on thept×qt-dimensional
matrixWtHˆtwithpt ≤ qtand rankrt ≤pt(cf. Table2). However, reshaping filters can also be designed using a shorter filter lengthLsg < Lst, i.e., based on the ps ×qs -dimensional matrixWsHˆs(cf. Table2). Considering that Ls
g < LMh−−11, the matrixWsHˆsis a full column-rank matrix with fewer columns than rows, i.e.,qs<ps, since
(M−1)Lsg <Lh−1⇒MLsg qs
<Lh+Lsg−1
ps
. (16)
As schematically illustrated in Fig.2, the matrixWsHˆs is a sub-matrix ofWtHˆt, constructed by deletingLtg−Lsg rows and MLtg − Lgs columns from WtHˆt. Aiming at establishing a relation between the condition numbers of the matricesWtHˆtandWsHˆs, i.e.,
χWtHˆt =
σWtHˆt(1)
σWtHˆt(rt)
, (17)
χWsHˆs =
σWsHˆs(1)
σWsHˆs(rs)
, (18)
we consider the following interlacing inequalities between the singular values of a matrix and its sub-matrices [39].
Interlacing inequalities [39]: Given a matrix A of dimensions u×v and a sub-matrixBobtained by deleting l rows and/or columns fromA, the singular values ofAand Binterlace as
σA(i)≥σB(i)≥σA(i+l), (19) for i=1, . . ., min{u−l,v−l}.
Fig. 2Schematic illustration of the construction of the
ps×qs-dimensional sub-matrixWsHˆsfrom thept×qt-dimensional
matrixWtHˆt
Using (19), in Appendix A we derive the following inequalities relating the largest and the smallest non-zero singular values ofWtHˆtandWsHˆs:
σWtHˆt(1)≥σWsHˆs(1), (20)
σWsHˆs(rs)≥σWtHˆt(rt). (21)
It readily follows from (20) and (21) that the condition number ofWsHˆsis smaller than or equal to the condition number ofWtHˆt, i.e.,
χWsHˆs =
σWsHˆs(1)
σWsHˆs(rs)
≤ σWtHˆt(1)
σWtHˆt(rt)
=χWtHˆt. (22)
Hence, using a shorter reshaping filter than conventionally used in equalization techniques can result (and based on simulations, it always does) in a lower condition number of the matrix being inverted.
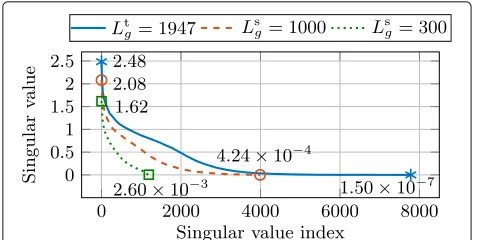
Figure3depicts the singular values of the matrixWtHˆt for PMINT, constructed using the conventional reshaping filter lengthLtg = 1947. The used acoustic system is sys-tem S1described in Section6.1, withM=4 microphones andLh = 5840. The singular values of two sub-matrices WsHˆs, constructed using Lsg = 1000 and Lsg = 300, are also depicted. The largest and the smallest non-zero singular values of each matrix are marked in order to illus-trate the inequalities presented in (20) and (21). Using these singular values, the condition numbers of the differ-ent matrices are presdiffer-ented in Table3, where it is illustrated that using a shorter reshaping filter length than con-ventionally used decreases the condition number of the matrixWH.ˆ
Fig. 3Singular values of the matrixWtHˆt(Ltg=1947) and of two sub-matricesWsHˆsLsg=1000 andLsg=300
for PMINT. The largest and the smallest non-zero singular values of each matrix are explicitly marked. The considered acoustic system is system S1described in
Table 3Condition number of the matrixWtHˆt(Ltg=1947) and of two sub-matricesWsHˆs(Lsg=1000 andLsg=300) for PMINT
Filter length Condition number
Lt
g=1947 χWtHˆt=1.65×10
7
Ls
g=1000 χWsHˆs=4.91×10
3
Lsg=300 χW
sHˆs=6.23×10
2
The considered acoustic system is system S1described in Section6.1
In summary, decreasing the reshaping filter length in acoustic multi-channel equalization techniques decreases the condition number of the matrix being inverted, increasing the robustness against RIR perturbations. However, decreasing the reshaping filter length also reduces the equalization performance with respect to the true RIRs, resulting in a trade-off between equalization performance for perfectly estimated RIRs and robustness in the presence of RIR perturbations. Using a shorter reshaping filter is not only desirable to increase the robust-ness against RIR perturbations, but also because of the lower computational complexity of the reshaping filter design.
5 Automatic non-intrusive reshaping filter length
The optimal reshaping filter lengthLoptg yielding the high-est dereverberation performance obviously depends on the acoustic system and the RIR perturbation level. In simulations,Loptg can beintrusivelydetermined by exploit-ing a clean reference signal. Reshapexploit-ing filters for several reshaping filter lengths can be computed and applied to the received microphone signals such that different out-put signals are generated. The optimal reshaping filter lengthLoptg can then be selected by comparing the differ-ent output signals to the clean reference signal. Since one typically does not have access to the clean reference sig-nal, an automaticnon-intrusiveprocedure is required in practice.
Motivated by the simplicity and the applicability of the L-curve to automatically determine a regularization parameter in regularized (weighted) least-squares solu-tions [24, 34, 35], in this section, we propose to use the L-curve to automatically determine the reshaping fil-ter length Lautog in acoustic multi-channel equalization techniques.
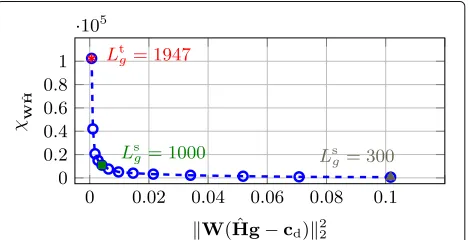
Using a shorter reshaping filter introduces a trade-off between the condition number χWHˆ and the (weighted) least-squares errorW(Hwˆ −cd)22. An appropriate fil-ter length should incorporate knowledge about χWHˆ and W(Hwˆ − cd)22, such that preferably both quan-tities are kept as small as possible. Due to the aris-ing trade-off between these quantities, the parametric plot of the condition number versus the (weighted)
least-squares error for several reshaping filter lengths has an L-shape. The corner of the L-curve, i.e., the point of maximum curvature, is located where the filter changes from being dominated by a large condition number to being dominated by a large (weighted) least-squares error. Hence, we propose to automatically select the reshap-ing filter length Lautog as the filter length corresponding to the corner of the parametric plot of the condition number χWHˆ versus the (weighted) least-squares error
W(Hwˆ −cd)22.
Figure 4 depicts a typical L-curve obtained using PMINT for acoustic system S1described in Section 6.1. As illustrated in this figure, decreasing the reshap-ing filter length decreases χWHˆ but at the same time increasesW(Hwˆ −cd)22. Although from such a curve it seems straightforward to determine the reshaping fil-ter length corresponding to the corner of the L-curve (i.e., Ls
g = 1000 in this example), numerical problems may occur, and hence, a numerically stable algorithm is required. Similarly as in [24], in this paper we use the triangle method [36] for locating the corner of the L-curve.
6 Simulation results and discussion
In this section, we investigate the influence of the reshap-ing filter length on the dereverberation performance of all considered acoustic multi-channel equalization tech-niques. In Section 6.1, the considered acoustic systems, instrumental performance measures, and algorithmic set-tings are introduced. In Section 6.2, the increase in robustness when using shorter reshaping filter lengths is investigated. In Section 6.3, the performance of all considered equalization techniques using the intrusively determined reshaping filter length Loptg is compared for several acoustic systems and RIR perturbation levels. In Section6.4, the performance of PMINT using the auto-matic non-intrusively determined reshaping filter length Lautog is investigated.
Fig. 4Typical L-curve obtained using PMINT for several reshaping filter lengths ranging fromLt
6.1 Acoustic systems, instrumental performance measures, and algorithmic settings
Acoustic systems. We consider three different reverber-ant acoustic systems with a single speech source placed at a distance of 2 m fromM = 4 omni-directional micro-phones. The RIRs between the speech source and the microphones are measured using the swept-sine tech-nique [40] and the reverberant signals are generated by convolving 10 sentences (approximately 17 s long) from the HINT database [41] with measured RIRs. For each acoustic system, Table4presents the reverberation time T60 of the room, the length of the RIRs Lh at a sam-pling frequency fs = 8 kHz, and the input direct-to-reverberant-ratio (iDRR). The iDRR is computed using the RIR of the first microphoneh1(n)and is defined as
where the first nd samples (corresponding to 3 ms) of h1(n) represent the direct path propagation and the remaining samples represent reflections [9]. In order to simulate RIR perturbations, the measured RIRs are per-turbed by proportional Gaussian distributed errors as pro-posed in [42], such that a desired normalized projection misalignment (NPM), i.e.,
is generated. Introducing proportional Gaussian dis-tributed errors is a widely used technique to systematically simulate RIR perturbations arising from system identifi-cation methods. The considered NPMs for each acoustic system are
NPM∈ {−33 dB, −30 dB, . . ., −15 dB}, (25) with−33 dB a moderate perturbation level and−15 dB a larger perturbation level. It should be noted that the
Table 4Characteristics of the considered measured acoustic
systems
Acoustic system T60[ms] Lh iDRR [dB]
S1 730 5840 −2.79
S2 610 4880 −0.87
S3 360 2880 1.43
NPMs in (25) represent realistic NPMs achieved by state-of-the-art BSI methods (for relatively short RIRs in the order of 300−500 taps) [30].
Instrumental performance measures. The performance of the equalization techniques is evaluated in terms of the reverberant energy suppression and perceptual speech quality improvement. The reverberant energy suppression is evaluated using the improvement in direct-to-reverberant ratio (DRR), i.e.,DRR = oDRR
−iDRR, with
and iDRR defined in (23). Although DRR exactly describes the reverberant energy suppression, it cannot be solely used to evaluate the dereverberation perfor-mance of equalization techniques, since it does not provide any insight on the reverberant energy decay rate. To evaluate the reverberant energy decay rate, the energy decay curve (EDC) [9] of the EIRc(n)is compared to the energy decay curve of the true first RIRh1(n). The EDC of the EIRcis computed as
EDCc(n)= The perceptual speech quality is evaluated using the frequency-weighted segmental signal-to-noise-ratio (fSNR) and the cepstral distance (CD) [43]. In [44], it has been shown that measures such as fSNR and CD can exhibit a high correlation with subjective listening tests when evaluating the overall quality and the perceived amount of reverberation for a wide range of state-of-the-art dereverberation (and noise reduction) techniques. These signal-based measures are intrusive measures, generating a similarity score between a test signal and a reference signal. The reference signal employed here is obtained by convolving the clean speech signal with the direct path and early reflections (considered to be 10 ms long) of h1(n). The improvement in fSNR, i.e., fSNR, is computed as the difference between the fSNR of the output signalz(n)and the fSNR of the first microphone signalx1(n). Similarly, the improvement in CD, i.e.,CD, is computed as the difference between the CD of the output signal z(n) and the CD of the first microphone signal x1(n). Note that a positivefSNR and a negative
Algorithmic settings. For the acoustic systems described in Table 4 and for all considered equaliza-tion techniques, the convenequaliza-tionally used filter length is Ltg = Lh−1
M−1
, i.e.,Ltg = 1947 for system S1,Ltg = 1627 for system S2, andLtg = 960 for system S3. The delay is set toτ = 90 and the length of the direct path and early reflections is set toLd=0.01×fs, corresponding to 10 ms (cf. Table1). The target EIRcdfor PMINT is constructed using the first RIR, i.e.,p=1 (cf. Table1).
We consider several shorter reshaping filter lengths for all equalization techniques, i.e.,
For each acoustic system, each NPM, and each equaliza-tion technique, the optimal filter length Loptg is selected from (28) as the filter length yielding the lowest CD. It should be noted that using the CD for determining the optimal reshaping filter length is an intrusive procedure which cannot be applied in practice, since knowledge of the clean reference signal is required. In Section 6.4, the performance when using the automatic non-intrusive procedure for selecting the reshaping filter length is investigated.
6.2 Increasing robustness using shorter reshaping filters
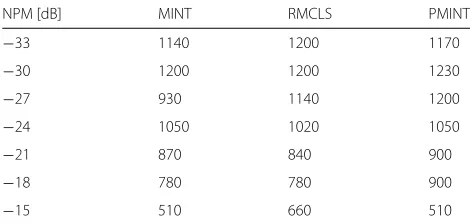
In this section, the robustness of MINT, RMCLS, and PMINT against RIR perturbations is investigated when using the conventional reshaping filter lengthLtgand the optimal (shorter) reshaping filter length Loptg . Although similar results are obtained for all considered acoustic sys-tems, in this section, only results for acoustic system S1are presented. For completeness, the intrusively determined optimal reshaping filter length Loptg for each considered technique and NPM is presented in Table5.
MINT using Ltg and Loptg . Figure 5 depicts the performance of MINT when using the filter lengths Ltg
Table 5Optimal intrusively determined reshaping filter length
Loptg for MINT, RMCLS, and PMINT for acoustic system S1and all considered NPMs
NPM [dB] MINT RMCLS PMINT
−33 1140 1200 1170
The conventionally used reshaping filter length isLt g=1947
andLoptg in terms ofDRR, EDC,fSNR, andCD. As expected, theDRR values presented in Fig.5ashow that using the conventional filter length Ltg fails to suppress the reverberant energy, even significantly worsening the DRR by about 20 dB on average in comparison to h1. Furthermore, it can be observed that using the shorter filter lengthLoptg (cf. Table 5) significantly increases the robustness of MINT for all NPMs, improving the DRR by about 4 dB on average in comparison toh1. These results are confirmed in Fig. 5b, which depicts the EDC ofh1 and the EDCs of the EIRs obtained using MINT withLtg andLoptg for an NPM of−33 dB. It can be observed that while using Ltg completely fails to achieve dereverbera-tion and results in a slower reverberant energy decay rate thanh1, usingLoptg yields a significantly faster reverberant energy decay rate. However, usingLoptg yields only a slight improvement of the reverberant energy decay rate when compared to h1, even for the moderate NPM of −33 dB. ThefSNR andCD values depicted in Fig.5c,dshow that using the conventional filter length Ltg in MINT yields a significantly worse quality than the unprocessed microphone signalx1(n)for all NPMs. While an increase in robustness is obtained for all NPMs using Loptg , for most considered NPMs, the performance in terms of
fSNR is still worse than for the unprocessed microphone signalx1(n).
In summary, as expected from the theoretical analysis in Section 4, these simulation results demonstrate that using an optimal intrusively determined shorter reshap-ing filter length than conventionally used in MINT is advantageous to increase the robustness against RIR perturbations. However, since acoustic system inversion using MINT is very sensitive to RIR perturbations, these results indicate that even a shorter reshaping filter is not sufficient to make MINT robust enough against RIR perturbations.
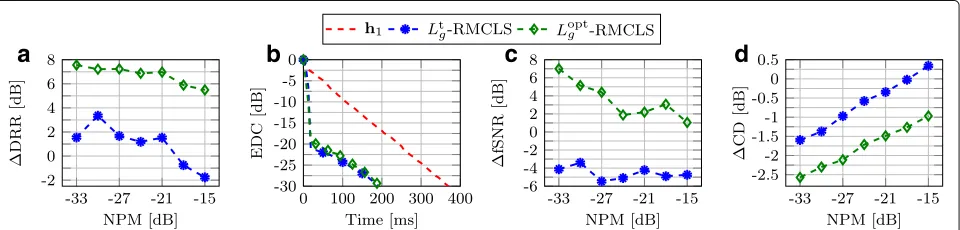
RMCLS using Ltg and Loptg . Figure 6 depicts the per-formance of RMCLS using the filter lengthsLtg andLoptg in terms ofDRR, EDC,fSNR, andCD. TheDRR values presented in Fig. 6a show that using the con-ventional filter lengthLtg improves the DRR for moder-ate NPMs, whereas for NPMs larger than −21 dB, the DRR is worsened in comparison to h1. In addition, it can be observed that using the shorter filter length Loptg (cf. Table5) significantly increases the reverberant energy suppression for all NPMs, on average yielding a 6 dB larger
a
b
c
d
Fig. 5Performance of MINT using the conventional filter lengthLt
gand the optimal intrusively determined reshaping filter lengthLoptg for acoustic system S1in terms ofaDRR,bEDC for an NPM of−33 dB,cfSNR, anddCD
when using Ltg and Loptg . Since RMCLS using the con-ventional filter lengthLtgis relatively robust for moderate NPMs and yields a fast reverberant energy decay rate, a shorter reshaping filter does not yield any improvement in the reverberant energy decay rate, but instead leads to a significant improvement in the perceptual speech quality. This is illustrated in Fig.6c,d, which shows that usingLoptg in RMCLS significantly improves the fSNR andCD values for all NPMs.
In summary, as expected from the theoretical analysis in Section 4, these simulation results demonstrate that using an optimal intrusively determined shorter reshap-ing filter length than conventionally used in RMCLS is advantageous and increases the robustness against RIR perturbations.
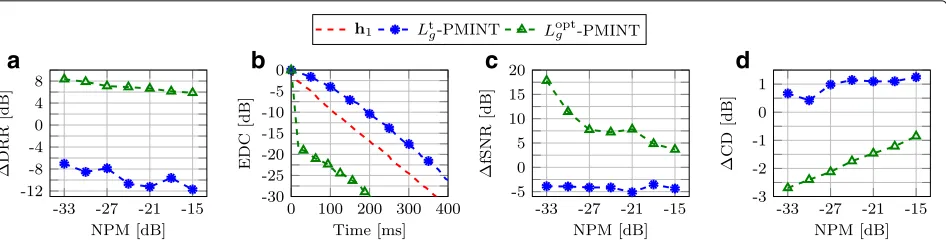
PMINT using Lt g and L
opt
g . Figure7depicts the perfor-mance of PMINT using the filter lengthsLtg andLoptg in terms ofDRR, EDC, fSNR, and CD. As expected, the DRR values presented in Fig. 7a show that using the conventional filter lengthLtg in PMINT fails to sup-press the reverberant energy, even worsening the DRR in comparison toh1. Furthermore, it can be observed that usingLoptg (cf. Table5) significantly increases the robust-ness for all NPMs, on average improving the DRR by about 7 dB in comparison toh1. These results are further con-firmed in Fig.7b, which depicts the EDC ofh1and the
EDCs of the EIRs obtained using PMINT withLtgandLoptg for an NPM of−33 dB. It can be observed that PMINT usingLtg completely fails to achieve dereverberation and results in a slower reverberant energy decay rate thanh1. Using the optimal reshaping filter lengthLoptg yields a sig-nificant increase in robustness, resulting in a much faster reverberant energy decay rate thanh1. Furthermore, the
fSNR andCD values depicted in Fig.7c,dshow that while PMINT using Ltg worsens the perceptual speech quality in comparison to the unprocessed microphone signal x1(n), using Loptg results in a significantly better performance.
In summary, as expected from the theoretical analysis in Section4, these simulation results demonstrate that using an optimal intrusively determined shorter reshaping fil-ter length than conventionally used in PMINT results in a significant increase in robustness against RIR perturba-tions, both in terms of reverberant energy suppression and perceptual speech quality improvement.
6.3 Performance of equalization techniques when using the optimal intrusive reshaping filter length
In the previous section, it was shown that using a shorter reshaping filter than conventionally used increases the robustness of all considered equalization tech-niques against RIR perturbations. In this section, the
a
b
c
d
a
b
c
d
Fig. 7Performance of PMINT using the conventional filter lengthLt
gand the optimal intrusively determined reshaping filter lengthL
opt
g for acoustic system S1in terms ofaDRR,bEDC for an NPM of−33 dB,cfSNR, anddCD
performance of MINT, RMCLS, and PMINT using the optimal intrusively determined reshaping filter lengthLoptg is extensively compared for all acoustic systems in Table4 and all NPMs in (25). The performance of the differ-ent techniques is evaluated in terms of DRR,fSNR, andCD, where the presented performance measures are averaged over all considered NPMs.
Table6presents the obtainedDRR,fSNR, andCD values for all considered techniques1. First, it can be observed that MINT usingLoptg results in the lowest per-formance in terms of all perper-formance measures, often worsening the perceptual speech quality in comparison to the unprocessed microphone signalx1(n). Since MINT is very sensitive to RIR perturbations (cf. Fig.5), the robust-ness increase that can be obtained by using a shorter reshaping filter length is also limited. Second, it can be observed that RMCLS and PMINT usingLoptg result in a high reverberant energy suppression in terms ofDRR, with PMINT outperforming RMCLS for systems S2and S3whereas a similar performance is obtained for system S1. Finally, it can be observed that for all considered acous-tic systems, PMINT using the reshaping filter lengthLoptg yields the highest perceptual speech quality improvement, outperforming RMCLS in terms of fSNR and CD. While PMINT always improves the perceptual speech quality in comparison to the unprocessed microphone signalx1(n), RMCLS sometimes fails to yield an improve-ment, as indicated by the negativefSNR for systems S2 and S3. The advantage of PMINT lies in its control of the early reflections in the EIR, hence better preserving the perceptual speech quality of the output signal.
In summary, based on instrumental measures, it can be said that PMINT using the optimal intrusively deter-mined reshaping filter length Loptg is a robust and per-ceptually advantageous equalization technique, yielding a high reverberant energy suppression and outperforming all other considered equalization techniques in terms of perceptual speech quality. Informal listening tests further support this conclusion.
6.4 Performance of PMINT when using the automatic non-intrusive reshaping filter length
In this section, we investigate the performance of PMINT when using the automatic non-intrusively determined reshaping filter length Lauto
g (cf. Section 5) instead of the optimal intrusively determined reshaping filter length Loptg . For completeness, the obtained values ofLautog are also compared to the values of Loptg . Similarly as in Section 6.3, we consider all acoustic systems in Table 4 and all NPMs in (25). In order to generate the parametric L-curve, the matrixWHˆ is constructed for all reshaping filter lengths in (28), the PMINT reshaping filter is com-puted, and the quantitiesχWHˆ andW(Hwˆ −cd)22are calculated. Using the triangle method [36], the automatic reshaping filter length Lautog corresponding to the point of maximum curvature of the L-curve is determined. The performance of PMINT using Lautog is evaluated in terms ofDRR,fSNR, andCD, where the presented performance measures are averaged over all considered NPMs.
Table 7 presents the values of Loptg and Lautog for the acoustic system S1 and all considered NPMs2. It can be
Table 6Average performance of MINT, RMCLS, and PMINT using the optimal intrusively determined reshaping filter lengthLoptg
S1 S2 S3
DRR [dB] fSNR [dB] CD [dB] DRR [dB] fSNR [dB] CD [dB] DRR [dB] fSNR [dB] CD [dB]
Loptg -MINT 4.41 −0.55 −1.31 1.66 −2.07 0.07 1.20 −3.89 −0.22
Loptg -RMCLS 6.75 3.53 −1.77 1.76 −0.81 −0.39 1.31 −0.61 −0.52
Table 7Intrusively and non-intrusively determined reshaping filter lengths for PMINT for acoustic systemS1and all considered NPMs
NPM [dB] −33 −30 −27 −24 −21 −18 −15
Loptg 1170 1230 1200 1050 900 900 510
Lauto
g 1200 1170 1170 1230 1230 1170 1170
observed that for low NPMs, the non-intrusively deter-mined reshaping filter length is very similar to the opti-mal intrusively determined one. As the NPM increases beyond−21 dB, the reshaping filter length obtained using the proposed non-intrusive procedure is larger than the optimal intrusively determined one.
Table8presents theDRR,fSNR, andCD obtained using PMINT withLautog for all considered acoustic sys-tems. It can be observed that using the automatic non-intrusively determined reshaping filter length in PMINT yields a high dereverberation performance, both in terms of reverberant energy suppression and perceptual speech quality improvement. In addition, when comparing the performance measures presented in Table8 to the ones presented in Table6, it can be observed that in general, the performance of PMINT when usingLautog is similar to the performance when usingLoptg . More precisely, the aver-age performance degradation over all considered acoustic systems when using the automatic non-intrusively deter-mined reshaping filter lengthLauto
g instead of the optimal intrusively determined reshaping filter lengthLoptg is only 0.58 dB in terms ofDRR, 1.15 dB in terms offSNR, and 0.24 dB in terms ofCD.
In summary, the presented results show that the auto-matic non-intrusively determined reshaping filter length in PMINT yields a high performance in the presence of RIR perturbations, making PMINT when using this shorter reshaping filter length a robust and perceptu-ally advantageous acoustic multi-channel equalization technique.
7 Conclusions
In this paper, we have analyzed the use of a shorter reshap-ing filter length than conventionally used in order to increase the robustness of acoustic multi-channel equal-ization techniques. We have analytically shown that using a shorter reshaping filter decreases the condition num-ber of the (weighted) convolution matrix, increasing as a result the robustness against RIR perturbations. In addi-tion, we have proposed to automatically determine the reshaping filter length as the point of maximum curvature
of the parametric plot of the condition number versus the (weighted) least-squares error, such that both quan-tities are simultaneously kept small. Using instrumental performance measures, it has been shown that using shorter reshaping filters indeed increases the robustness of MINT, RMCLS, and PMINT against RIR perturbations. In addition, it has been shown that PMINT using the optimal intrusively determined reshaping filter length out-performs MINT and RMCLS. Finally, it has been shown that the automatic non-intrusive procedure for selecting the reshaping filter length in PMINT yields a nearly opti-mal performance, confirming the practical applicability of using shorter reshaping filters in acoustic multi-channel equalization.
Endnotes
1It should be noted that the performance measures
pre-sented for system S1are an average of the results already presented in Section6.2.
2It should be noted that presentedLopt
g values are the same as the ones presented in Table5.
Appendix A
In order to construct the matrixWsHˆs from the matrix WtHˆt (cf. Fig. 2), we first create an intermediate
pt−
Lt g−Lsg
×qt−(Ltg−Lsg)
-dimensional sub-matrixT by deletingLtg−Lsgrows andLgt−Lsgcolumns fromWtHˆt. The interlacing inequalities in (19) for the matricesWtHˆt andTcan then be written as
σWtHˆt(i)≥σT(i)≥σWtHˆt
i+Ltg−Lsg, (29)
fori=1, . . ., rt−
Ltg−Lsg, . . ., pt−
Ltg−Lsg. Using i=1 andi=rt−Ltg−Lsg
in (29), the following inequali-ties between the singular values of the matricesWtHˆtand Tcan be established:
σWtHˆt(1)≥σT(1), (30)
σT
rt−
Ltg−Lsg≥σW
tHˆt(rt). (31)
Table 8Average performance of PMINT using the automatically non-intrusively determined reshaping filter lengthLautog
S1 S2 S3
DRR [dB] fSNR [dB] CD [dB] DRR [dB] fSNR [dB] CD [dB] DRR [dB] fSNR [dB] CD [dB]
In order to construct the matrixWsHˆs,(M−1)
Lt g−Lsg
columns are now deleted from the matrixT. The interlac-ing inequalities in (19) for the matricesTandWsHˆscan following inequalities between the singular values of the matricesTandWsHˆscan be written: equal to its rank, i.e.,
qt=MLtg≥pt≥rt, (35)
the index of the singular value in the right hand side of (34) can be written as
Based on (36) and the fact that the singular values of the matrices are sorted in descending order, it can be said that
σT
such that the inequality in (34) can also be written as
σWsHˆs(rs)≥σT inequalities relating the largest and the smallest non-zero singular values ofWtHˆtandWsHˆscan be established:
σWtHˆt(1)≥σWsHˆs(1), (39)
σWsHˆs(rs)≥σWtHˆt(rt). (40)
Funding
This work was supported in part by the Cluster of Excellence 1077
“Hearing4All,” funded by the German Research Foundation (DFG) and the joint Lower Saxony-Israeli Project ATHENA, funded by the State of Lower Saxony.
Authors’ contributions
The contribution of the first author consists in developing the main algorithmic idea, deriving the mathematical analysis, performing simulations, analyzing the simulation results, and drafting the article. The contribution of the second author consists in critically discussing the mathematical analysis and the simulation results and in proofreading and revising the article. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Received: 11 July 2017 Accepted: 30 January 2018
References
1. JS Bradley, H Sato, M Picard, On the importance of early reflections for speech in rooms. J. Acoust. Soc. Am.113(6), 3233–3244 (2003) 2. I Arweiler, JM Buchholz, The influence of spectral characteristics of early
reflections on speech intelligibility. J. Acoust. Soc. Am.130(2), 996–1005 (2011)
3. A Warzybok, J Rennies, T Brand, S Doclo, B Kollmeier, Effects of spatial and temporal integration of a single early reflection on speech intelligibility. J. Acoust. Soc. Am.133(1), 269–282 (2013)
4. R Beutelmann, T Brand, Prediction of speech intelligibility in spatial noise and reverberation for normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am.120(1), 331–342 (2006)
5. S Goetze, E Albertin, J Rennies, EAP Habets, K-D Kammeyer, inProc. AES International Conference on Sound Quality Evaluation. Speech quality assessment for listening-room compensation, (Pitea, 2010), pp. 11–20 6. A Warzybok, I Kodrasi, JO Jungmann, EAP Habets, T Gerkmann, A Mertins,
S Doclo, B Kollmeier, S Goetze, inProc. International Workshop on Acoustic Echo and Noise Control. Subjective speech quality and speech
intelligibility evaluation of single-channel dereverberation algorithms, (Antibes, 2014), pp. 333–337
7. T Yoshioka, A Sehr, M Delcroix, K Kinoshita, R Maas, T Nakatani, W Kellermann, Making machines understand us in reverberant rooms: robustness against reverberation for automatic speech recognition. IEEE Signal Proc. Mag.29(6), 114–126 (2012)
8. F Xiong, BT Meyer, N Moritz, R Rehr, J Anemüller, T Gerkmann, S Doclo, S Goetze, Front-end technologies for robust ASR in reverberant environments–spectral enhancement-based dereverberation and auditory modulation filterbank features. EURASIP J. Adv. Signal Process.
2015(1), 1–18 (2015)
9. PA Naylor, ND Gaubitch (eds.),Speech Dereverberation(Springer, London, 2010)
10. K Lebart, JM Boucher, A new method based on spectral subtraction for speech dereverberation. Acta. Acoustica.87(3), 359–366 (2001) 11. EAP Habets, S Gannot, I Cohen, Late reverberant spectral variance
estimation based on a statistical model. IEEE Sig. Process Lett.16(9), 770–774 (2009)
12. A Kuklasi ´nski, S Doclo, SH Jensen, J Jensen, Maximum likelihood PSD estimation for speech enhancement in reverberation and noise. IEEE/ACM Trans. Audio Speech Lang. Process.24(9), 1595–1608 (2016) 13. I Kodrasi, S Doclo, inProc. IEEE International Conference on Acoustics, Speech,
and Signal Processing. Late reverberant power spectral density estimation based on an eigenvalue decomposition, (New Orleans, 2017), pp. 611–615 14. I Kodrasi, S Doclo, inProc. IEEE Workshop on Applications of Signal
Processing to Audio and Acoustics. Multi-channel late reverberation power spectral density estimation based on nuclear norm minimization, (New York, 2017). (accepted for publication)
15. T Nakatani, T Yoshioka, K Kinoshita, M Miyoshi, B-H Juang, Speech dereverberation based on variance-normalized delayed linear prediction. IEEE Trans. Audio Speech Lang. Process.18(7), 1717–1731 (2010) 16. D Schmid, G Enzner, S Malik, D Kolossa, R Martin, Variational Bayesian
inference for multichannel dereverberation and noise reduction. IEEE/ACM Trans. Audio Speech Lang. Process.22(8), 1320–1335 (2014) 17. B Schwartz, S Gannot, EAP Habets, Online speech dereverberation using
Kalman filter and EM algorithm. IEEE/ACM Trans. Audio Speech Lang. Process.23(2), 394–406 (2015)
18. A Juki´c, T Van Waterschoot, T Gerkmann, S Doclo, Multi-channel linear prediction-based speech dereverberation with sparse priors. IEEE/ACM Trans. Audio Speech Lang. Process.23(9), 1509–1520 (2015) 19. M Miyoshi, Y Kaneda, Inverse filtering of room acoustics. IEEE Trans.
Acoust. Speech Signal Process.36(2), 145–152 (1988)
20. M Kallinger, A Mertins, inProc. IEEE International Conference on Acoustics, Speech, and Signal Processing. Multi-channel room impulse response shaping - a study, (Toulouse, 2006), pp. 101–104
21. JO Jungmann, R Mazur, M Kallinger, M Tiemin, A Mertins, Combined acoustic MIMO channel crosstalk cancellation and room impulse response reshaping. IEEE Trans. Audio Speech Lang. Process.20(6), 1829–1842 (2012)
22. T Hikichi, M Delcroix, M Miyoshi, Inverse filtering for speech dereverberation less sensitive to noise and room transfer function fluctuations. EURASIP J. Adv. Signal Process.2007(2007) 23. F Lim, W Zhang, EAP Habets, PA Naylor, Robust multichannel
24. I Kodrasi, S Goetze, S Doclo, Regularization for partial multichannel equalization for speech dereverberation. IEEE Trans. Audio Speech Lang. Process.21(9), 1879–1890 (2013)
25. RS Rashobh, AWH Khong, D Liu, Multichannel equalization in the KLT and frequency domains with application to speech dereverberation. IEEE/ACM Trans. Audio Speech Lang. Process.22(3), 634–646 (2014) 26. I Kodrasi, S Doclo, Signal-dependent penalty functions for robust acoustic
multi-channel equalization. IEEE Trans. Audio Speech Lang. Process.25(7), 1512–1525 (2017)
27. BD Radlovic, RC Williamson, RA Kennedy, Equalization in an acoustic reverberant environment: robustness results. IEEE Trans. Speech Audio Process.8(3), 311–319 (2000)
28. AWH Khong, L Xiang, PA Naylor, inProc. IEEE International Conference on Acoustics, Speech, and Signal Processing. Algorithms for identifying clusters of near-common zeros in multichannel blind system identification and equalization, (Las Vegas, 2008), pp. 229–232
29. MA Haque, T Hasan, Noise robust multichannel frequency-domain LMS algorithms for blind channel identification. IEEE Signal Process. Lett.15, 305–308 (2008)
30. M Hu, ND Gaubitch, PA Naylor, DB Ward, inProc. European Signal Processing Conference. Noise robust blind system identification algorithms based on a Rayleigh quotient cost function, (Nice, 2015)
31. ND Gaubitch, PA Naylor, Equalization of multichannel acoustic systems in oversampled subbands. IEEE Trans. Audio Speech Lang. Process.17(6), 1061–1070 (2009)
32. F Lim, PA Naylor, inProc. European Signal Processing Conference. Robust speech dereverberation using subband multichannel least squares with variable relaxation, (Marrakech, 2013)
33. I Kodrasi, S Doclo, inProc. European Signal Processing Conference. The effect of inverse filter length on the robustness of acoustic multichannel equalization, (Bucharest, 2012)
34. PC Hansen, Analysis of discrete ill-posed problems by means of the L-curve. SIAM Rev.34(4), 561–580 (1992)
35. PC Hansen, DP O’Leary, The use of the L-curve in the regularization of discrete ill-posed problems. SIAM J. Sci. Comput.14(6), 1487–1503 (1993) 36. JL Castellanos, S Gómez, V Guerra, The triangle method for finding the
corner of the L-curve. Appl. Numer. Math.43(4), 359–373 (2002) 37. P Wedin, Perturbation theory for pseudo-inverses. BIT Numer. Math.13(2),
217–232 (1973)
38. G Golub, C Van Loan,Matrix Computations. (The John Hopkins University Press, Baltimore, 1996)
39. RA Horn, CR Johnson,Topics in matrix analysis. (Cambridge University Press, Cambridge, 1999)
40. A Farina, inProc. AES Convention. Simultaneous measurement of impulse response and distortion with a swept-sine technique, (Pitea, 2000), pp. 18–22
41. M Nilsson, SD Soli, A Sullivan, Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. J. Acoust. Soc. Am.95(2), 1085–1099 (1994)
42. W Zhang, PA Naylor, An algorithm to generate representations of system identification errors. Res. Lett. Signal Process.2008(2008)
43. Y Hu, PC Loizou, Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process.16(1), 229–238 (2008)