Distributed Edge Cloud for Data Escalated
Computing
Apeksha.T.Alva1, Maithra.S.T2, G.V.Kavya3, Mamatha.T.S 4
U.G. Student, Department of Computer Science &Engineering, Sri Krishna Institute of Technology,
Bangalore, India123
Assistant Professor, Department of Computer Science &Engineering, Sri Krishna Institute of Technology, Bangalore,
Bangalore, India 4
ABSTRACT: Brought together cloud frameworks have turned into the well known stages for information escalated processing today. Be that as it may, they experience the ill effects of wasteful information portability because of the centralization of cloud assets, and henceforth, are very unsuited for geo-dispersed information concentrated applications where the information might be spread at various topographical areas. In this paper, we exhibit Nebula: a scattered edge cloud foundation that investigates the utilization of willful assets for both calculation and information stockpiling. We depict the lightweight Nebula design that empowers conveyed information escalated processing through various improvement methods including area mindful information and calculation situation, replication, and recuperation. We assess Nebula execution on an imitated volunteer stage that ranges more than 50 Planet Lab hubs circulated crosswise over Europe, and show how a typical information serious registering system, Mapreduce, can be effectively conveyed and keep running on Nebula. We demonstrate Nebula Mapreduce is strong to a wide cluster of disappointments and significantly beats other wide-zone adaptations in view of copied existing frameworks.
KEYWORDS: Mapreduce, PlanetLab, Mobile computing, Cloudlets,Geo-distributed data analytics.
I. INTRODUCTION
Currrently, server farms or mists have turned into the accepted stage for information concentrated registering in the business, and progressively, logical areas. The interest is clear: mists, for example, Amazon AWS and Microsoft Azure offer a lot of adapted co-found calculation and capacity appropriate to run of the mill handling errands, for example, clusters investigation. Be that as it may, numerous Big Data applications depend on information that is geologically appropriated, and isn't assembled with the incorporated computational assets gave by mists. Cases of such applications incorporate examination of client information, for example, web journals, video nourishes taken from geologically isolated cameras, checking and log investigation of server and substance appropriation organize (CDN) logs, and logical information gathered from dispersed instruments and sensors. Such applications prompt various difficulties for productive information investigation in the present cloud stages. To start with, in numerous applications, information is both vast and generally dispersed and information transfer may constitute a non-trifling bit of the execution time. Second, information transfer combined with the high overhead in instantiating virtualized cloud assets, additionally restricts the scope of applications to those that are either cluster arranged or long-running administrations. Third, the cost to transport, store, and process information might be outside of the financial plan of the little scale application architect or end-client.
expanding measure of high transfer speed Internet network. In the event that cost is an issue, at that point we advocate the utilization of volunteer edge assets, else, one could imagine utilizing adapted edge assets crosswise over CDNs or even ISPs, gave these were prepared to offer computational administrations. In this paper, we introduce Nebula: a scattered cloud foundation that investigates the utilization of volunteer assets to democratize information concentrated figuring. Rather than existing volunteer stages, for example, BOINC [1], which is intended for register escalated applications, and record sharing frameworks, for example, Bit Torrent [4], our Nebula framework is intended to help disseminated information concentrated applications through a nearby between activity between both process and information assets. In addition, not at all like a significant number of these frameworks, our objective isn't to actualize a particular asset administration arrangement, however to give adaptability to clients and applications to determine and execute their own particular strategies.
II. PROPOSED SYSTEM
We introduce Nebula: a scattered edge cloud foundation that investigates the utilization of intentional assets for both calculation and information storage. We delineate the lightweight Nebula building that engages circled data concentrated figuring through different upgrade techniques checking territory mindfull data and count course of action, replication, and recovery We actualized a Map Reduce Word count application which numbers the aggregate recurrence of each word showing up in reports. Word count calculation on it which brings about a rundown of key-esteem match where the key is the word and the key-esteem is the recurrence of the word. All guide yields are transferred back to the Data Store toward the finish of each guide assignment.
Fig.2.1. Word Count Algorithm
III. EXISTING SYSTEM
undertaking mappings and when hubs check in for work they are allotted the doled out task(s)
Cloud has been outlined because of the accompanying objectives:
•Support for conveyed information concentrated processing: Unlike other volunteer registering structures, for example, BOINC that attention on figure serious applications, Nebula is intended to help information escalated applications that require effective development and accessibility of vast amounts of information to process assets. Subsequently, notwithstanding an effective computational plat-frame, Nebula should likewise bolster a versatile information stockpiling stage. Further, Nebula is intended to help applications where information may start in a geologically appropriated way, and isn't really pre-stacked to a focal area.
•Location-mindful asset administration: To empower efficient execution of disseminated information concentrated applications, Nebula must consider arrange data transmission alongside calculation abilities of assets in the volunteer stage. Subsequently, asset overseement choices must enhance on calculation time and in addition information development costs. Specifically, register assets might be chosen in view of their region and closeness to their info information, while information might be arranged nearer to proficient computational assets.
•Sandboxed execution condition: To guarantee that volunteer hubs are totally sheltered and confined from malignant code that may be executed as a major aspect of a Nebula-based application, volunteer hubs must have the capacity to execute all client infused application code inside an ensured sandbox.
•Fault resilience: Nebula must guarantee blame tolerant execution of uses within the sight of hub stir and transient system disappointments that are regular in a volunteer domain.
IV. EXPERIMENTAL DISCUSSIONS
A. Volunteer Cloud Computing: MapReduce over the Internet(2011)
Volunteer Computing tackles processing assets of machines from around the globe to perform appropriated autonomous errands, following an ace/specialist show. In spite of the current increment in prominence and power in middleware, for example, BOINC, there are as yet a few impediments in existing frameworks. Ebb and flow investigate is arranged towards advancing existing applications, while the quantity of dynamic clients and tasks has achieved a level. A programming worldview that has been fundamentally famous and is utilized by a few frameworks on the cloud is MapReduce. The fundamental preferred standpoint of this worldview is that it can be utilized to comprehend a tremendous measure of various issues, by breaking them into basic advances and exploiting appropriated assets. Volunteer Computing gives these assets, and despite the fact that it can't coordinate the conditions offered by a group, it has different points of interest that can be utilized. In this paper, we endeavor to expand the computational energy of Volunteer Computing frameworks by permitting more perplexing applications and standards, for example, MapReduce to be run, hence opening new roads and potential outcomes for the utilization of computational gadgets scattered through the Internet.
B. The Case for VM-Based Cloudlets in Mobile Computing(2013)
C. Low Latency Geo-distributed Data Analytics(2010)
Low idleness examination on geologically circulated datasets (crosswise over datacenters, edge bunches) is an up and coming and progressively imperative test. The predominant approach of totaling every one of the information to a solitary server farm significantly inmates the convenience of examination. In the meantime, running inquiries over geo-disseminated inputs utilizing the current intra-DC investigation systems additionally prompts high inquiry reaction times in light of the fact that these structures can't adapt to the moderately low and variable limit of WAN connections. We display Iridium, a framework for low idleness geo-distributed examination. Iridium accomplishes low question reaction times by improving arrangement of the two information and errands of the inquiries. The joint information and errand arrangement operation optimization, nonetheless, is recalcitrant. Along these lines, Iridium utilizes an online heuristic to redistribute datasets among the destinations preceding inquiries' entries, and spots the errands to decrease arrange bottlenecks amid the question execution. At long last, it likewise contains a handle to spending WAN use. Assessment crosswise over eight overall EC2 regions utilizing generation inquiries demonstrate that Iridium accelerates questions by 3 19 and brings down WAN use by 15% 64% contrasted with existing baselines.
V. SYSTEM DESIGN
Frameworks configuration is the way toward characterizing the engineering, modules, interfaces, and information for a framework to fulfill indicated prerequisites. Frameworks configuration could be viewed as the utilization of frameworks hypothesis to item advancement. There is some cover with the orders of frameworks examination, frameworks design and frameworks building.
UI Design is worried about how clients add data to the framework and with how the framework presents data back to them. Information Design is worried about how the information is spoken to and put away inside the framework. At long last, Process Design is worried about how information travels through the framework, and with how and where it is approved, secured as well as changed as it streams into, through and out of the framework. Toward the finish of the framework configuration stage, documentation portraying the three sub-undertakings is delivered and made accessible for use in the following stage.
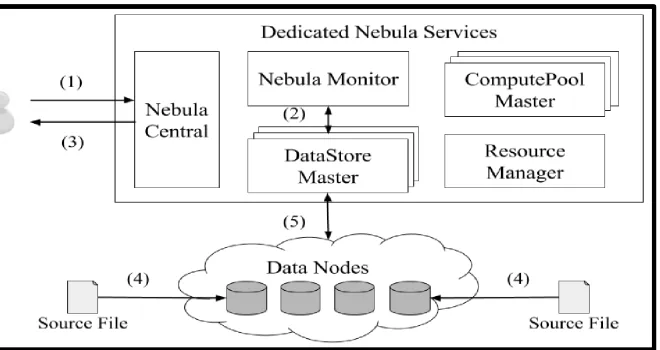
Fig 5.1: Nebula architecture
• Nebula Central: Nebula Central is the front-end for the Nebula eco-framework. It gives a basic, simple touse Web-based entry that enables volunteers to join the framework, application authors to infuse applications into the framework, and apparatuses to oversee and screen application execution. Cloud Central is the front-end for the Nebula biological system. It is the front aligned part of the framework for overseeing applications and assets in the framework. It uncovered a web front-end entryway where hubs can join to contribute process or potentially stockpiling assets to Nebula, and clients can transfer their applications and start execution. Cloud Central uses various parameters (Table 1) to make an ex-panded inward portrayal of the whole application, the part employments, and the arrangement of errands. It likewise instantiates an application-particular DataStore and ComputePool Master (to be examined straightaway) that handle the information arrangement and occupation execution for the application. It at that point gives the vital application parts to the DataStore and ComputePool Masters, for example, the application executable code.
• DataStore: The DataStore is a straightforward per-application stockpiling administration that backings proficient and locationaware information handling in Nebula. Each DataStore comprises of volunteer information hubs that store the real information, and a DataStore Master that keeps up the capacity framework metadata and makes information arrangement decisions.TheDataStore is intended to give a basic stockpiling administration to help information handling on Nebula. In an exceedingly scattered edge cloud display, hubs are commonly intercon-nected by WAN that has restricted data transmission. Advancing information exchange time is urgent to productive information handling for this situation. Every application claims a DataStore that it might arrange to help wanted execution, limit, or reli-capacity imperatives. Information hubs that are a piece of a DataStore might be multiplexed crosswise over conceivably different DataStores.
• DataNode:The information hubs give storage room and store application information as records. An information hub is actualized utilizing a light-weight web server that stores and serves records. Cloud permits devoted information hubs notwithstanding volunteer information hubs for two or three reasons. To start with, information that is put away in Nebula may have a protection concern, in this way the proprietor may just need to store the information in trusted committed hubs. Second, volunteer-based information hubs have a tendency to be less solid. Subsequently, clients may store basic information in committed hubs that give higher unwavering quality. For instance, input information might be put away in exceedingly dependable information hubs while the middle of the road information can be put away in less-solid information hubs which exchanges off the unwavering quality viewpoint for higher territory to the figure hubs. When all is said in done, the information hubs bolster two essential tasks that are presented to customers to store and recover records:
• store(filename, namespace, record): stores a document into the DataStore and refresh the DataStore Master. • retrieve(filename, namespace): recovers the record determined by the namespace-filename mix.
DataStore customers, for example, process hubs that need to store or recover information to/from the DataStore, utilize a com-bination of these activities to get and store information. These activities can likewise be utilized to put information in a coveted manner before the calculation even starts. All the knowledge is a piece of the DataStore Master and is straightforward to the customers
• DataStoreMaster:TheDataStore Master monitors a few things: information hubs that are on the web, document metadata, record replication, and information situation arrangement. It fills in as a section point to the DataStore when writing to or perusing information from it. The data it gathers is utilized to settle on choices with respect to the situation and recovery of information. The DataStore Master bolsters an arrangement of activities to deal with the information hubs and to do viable information position choices. Some of these activities are summoned by DataStore customers before putting away or recovering information to/from the DataStore. Different tasks are summoned by the information hubs and are utilized to trade metadata and wellbeing data:
• get_nodes_to_store(option): restores a requested rundown of information hubs. The request of the hubs relies upon the choice determined by the customer, for example, the heap of information hubs, nearest hubs to the customer, accessibility of process hubs around the information hub or arbitrary.
• get_nodes_to_retrieve(filename, namespace):
• set(filename, namespace, nodeId, filesize):
sets another passage in the DataStore Master for the given record. This activity is summoned by an information hub once the transfer is finished effectively.
• ping(nodeid, is_online): reports that a hub is on-line. The information hubs intermittently ping the DataStore Master to tell their status. Information hubs that don't check in after a timeframe are set apart as disconnected. The second contention additionally gives a choice to a hub to physically report itself as disconnected upon an agile exit or shutdown.
• ComputePool: The ComputePool gives perapplication calculation assets through an arrangement of volunteer figure hubs. Code execution on a register hub is completed inside a Google Chrome Web program based Native Client (NaCl) sandbox [21]. Process hubs inside a ComputePool are booked by a ComputePool Master that arranges their execution. The register hubs utilize the DataStore to get to and recover information, and they are doled out undertakings in view of use particular calculation necessities and information area. Figure hubs are volunteer hubs that complete com-putation for the benefit of an application. All calculations in Nebula are completed inside the Native Client (NaCl) sandbox [15] gave by the Google Chrome program. The utilization of NaCl gives a few focal points. Initial, one of the greatest worries of giving computational assets in intentional figuring is the security of the volunteer hub. The volunteer hub must be shielded from malevolent code and keep such code from harming the volunteer. NaCl is a sandboxing innovation that executes local code in a web program, and all.
VI. RELATED WORK
Volunteer edge processing and information sharing frameworks are best exemplified by Grid and distributed frameworks includ-ing, Kazaa [26], BitTorrent [11], Globus [27], Condor [28], BOINC [10], and @home ventures [29]. These frameworks ace vide the capacity to take advantage of sit out of gear gave assets, for example, CPU limit or total system transfer speed, however they are not intended to abuse the qualities of particular hubs in the interest of uses or administrations. Moreover, they are not intended for information escalated figuring.
Different undertakings have thought about the utilization of the edge, however their concentration is unique. [19], [30], [31] center around minimiz-ing idleness in noting inquiries in geo-conveyed server farms and [18], [32] center around stream explanatory in geo-circulated framework. Cloud4Home [33] centers around edge stor-age where Nebula empowers both capacity and calculation basic to accomplishing territory for information concentrated figuring. Other capacity just arrangements incorporate CDNs, for example, Ama-zon'sCloudFront that emphasis more on conveying information to end-clients than on calculation.
There are various important appropriated MapReduce extends in the writing [34], [35], [36], [37]. Moon [34] fo-cuses on willful assets however not in a wide-zone setting.ProgressiveMapReduce [35] is worried about process concentrated MapReduce applications and how to apply mul-tiple disseminated bunches to them, yet utilizes groups and not edge assets. [36] concentrates more on cross-stage MapRe-duce advancement, but in a wide-region setting.
Individuals have likewise taken a gander at building a solid stockpiling framework utilizing questionable hubs. They took a gander at this issue with regards to datacenter figuring, for example, the Google File System [38] and Amazons Dynamo [39]. These frameworks have the property that disappointments inside a bunch are amiable and that machines will stay accessible for longer timeframes and with bring down change than in volunteer-based frameworks.
While these frameworks are equipped for accomplishing highperformance, the rearranging suppositions made keep similar procedures from being connected to Nebula.There are likewise extends that take a gander at the issue of demonstrating solid information stockpiling in non-datacenter situations includ-ing P2P frameworks, volunteer-based frameworks, and utility-like information stockpiling frameworks [40], [41], [42].
VII. CONCLUSION
We presented the design of Nebula, an edge-based cloud platform that enables distributed in-situ data-intensive computing. The Nebula architectural components were described along with abstractions for data storage, DataStore, and computation, ComputePool. A working Nebula prototype running across edge volunteers on the PlanetLabtestbed was described. An evaluation of MapReduce on Nebula was performed and compared against other edge-based volunteer systems. The locality-aware scheduling of computation and placement of data enabled Nebula MapReduce to significantly outperform these systems. In addition, we showed that Nebula is highly robust to both transient and crash failures. Future work includes expanding the range of data-intensive applications and frameworks ported to Nebula and validation of our initial findings on a much larger scale. We also plan on first- class support for resource partitioning across frameworks and applications running across shared Nebula resources. Lastly, we plan on expanding the range of DataStore features to include the injection of external data and techniques both aggregation and decomposition across distributed resources.
REFERENCES
[1] D. P. Anderson. BOINC: A System for Public-Resource Compting and Storage. In Proceedings of the 5th ACM/IEEE International Workshop on Grid Computing, 2004.
[2] A. Chandra and J. Weissman. Nebulas: Using Distributed Voluntary Resources to Build Clouds. In HotCloud’09: Workshop on Hot topics in cloud computing, June 2009.
[3] B. Chun, D. Culler, T. Roscoe, A. Bavier, L. Peterson, M. Wawrzoniak, and M. Bowman. PlanetLab: an overlay testbed for broad-coverage services. ACM SIGCOMM Computer Communication Review, 33(3):3–12, July 2003.
[4] B. Cohen. Incentives build robustness in BitTorrent. In Proceedings of the First Workshop on the Economics of Peer-to-Peer Systems, June2003.
[5] F. Costa, L. Silva, and M. Dahlin. Volunteer Cloud Computing: MapReduce over the Internet. In Fifth Workshop on Desktop Grids and Volunteer Computing Systems (PCGRID 2011), May 2011.
[6] J. Dean and S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In Sixth Symposium on Operating Systems Design and Implementation (OSDI), 2004.
[7] A. Downey. Using pathchar to estimate Internet link characteristics. InIn Proceedings of ACM SIGCOMM, pages 241–250, 1999.
[8] I. Foster, C. Kesselman, J. Nick, and S. Tuecke. The Physiology of the Grid: An Open Grid Services Architecture for Distributed Systems Integration. In Proceedings of the Global Grid Forum, June 2002.
[9] B. Heintz, C. Wang, A. Chandra, and J. B. Weissman. Cross-Phase Optimization in MapReduce. In Proceedings of the IEEE International Conference on Cloud Engineering, IC2E’12, 2013.
[10] S. Kannan, A. Gavrilovska, and K. Schwan. Cloud4Home – Enhancing Data Services with @Home Clouds. International Conference on Distributed Computing Systems, pages 539–548, 2011.
[11] K. Lai and M. Baker. Measuring link bandwidths using a deterministic model of packet delay. In in Proceedings of ACM SIGCO pagesusing Packet Quartets. In ACM SIGCOMM Internet Measurement Workshop, pages 293–305,2002.