International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)51
Enhance HADOOP Performance by Tuning Mapreduce
Configuration
Amit Dubey
1, Shilpa Tripathi
21Asst. Professor, 2M.Tech, Department of Computer Science & Engineering, OCT, Bhopal, India
Abstract— Hadoop has become a key component of big data, and gained more and more support. MapReduce is emerging as an important programming model for large-scale data-parallel applications such as web indexing, data mining, and scientific simulation. MapReduce is a widely used parallel computing framework for large scale data processing. The two major performance metrics in MapReduce are job execution time and cluster throughput. In this paper we tune the mapreduce configuration parameters and compare it with default configuration. We can prepare a two mapreduce job existing.jar which is a default configuration and a proposed.jar in which we can tune the mapreduce configuration in which we can fetch the data to corresponding compute nodes in advance, so by using proposed technique the performance of mapreduce framework is increases as compared to default base configuration.
Keywords— Big data, Hadoop, Mapreduce, performance, tuning.
I. INTRODUCTION
MapReduce could be a comparatively young framework - each a programming model associated an associated run- time system - for large-scale processing. Hadoop [2] is that the most well liked open-source implementation of a MapReduce framework that follows the planning arranged enter the initial paper. a mixture of options contributes to Hadoop's increasing quality, together with fault tolerance ,data-local programing, ability to work in an exceedingly heterogeneous atmosphere, handling of drone tasks, furthermore as a standard and customizable design.
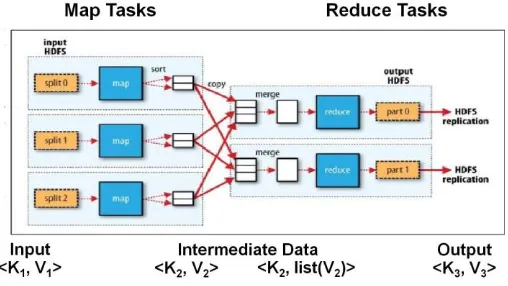
The MapReduce programming model [3] consists of a map(k1; v1) method and a reduce(k2; list(v2)) method. Users will implement their own process logic by specifying a customised map() and reduce() method written in an exceedingly general language like Java or Python. The map(k1; v1) method is invoked for each key-value combine hk1; v1i within the computer file to output zero or additional key-value pairs of the form hk2; v2i (see Figure 1). The reduce(k2; list(v2)) method is invoked for each distinctive key K2 and corresponding values list(v2) within the map output. reduce(k2; list(v2)) outputs zero or additional key-value pairs of the form hk3; v3i.
[image:1.595.316.570.315.458.2]The MapReduce programming model additionally permits alternative functions like (i) partition(k2), for dominant however the map output key-value pairs ar divided among the reducer tasks, and (ii) combine(k2; list(v2)), for performing arts partial aggregation on the map aspect. The keys k1, k2, and k3, furthermore because the values v1, v2, and v3, will be of various and impulsive sorts.
Figure 1: Execution of a MapReduce job
.
A Hadoop MapReduce cluster employs a master-slave design wherever one master node (called JobTracker) manages variety of slave nodes (called TaskTrackers). Figure 1 shows however a MapReduce job is executing on the cluster. Hadoop launches a MapReduce job by initial spliting (logically) the input information set into data splits. every information split is then regular to at least one TaskTracker node and is processed by a map task. A Task computer hardware is accountable for programing the execution of map tasks whereas taking
information section into consideration. every
TaskTracker features a predefined variety of task execution slots for running map (reduce) tasks. If the work can execute a lot of map (reduce) tasks than there ar slots, then the map (reduce) tasks can run in multiple waves. once map tasks complete, the run-time system merge all intermediate key-value pairs using associate
external sort-merge formula. The intermediate
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)52
The Map task execution is split into 5 phases:
1. Read: Reading the input split from HDFS and making the input key-value pairs (records).
2. Map: execution the user-defined map method to get the map-output information.
3. Collect: Partitioning and assembling the intermediate (map-output) information into a buffer before spilling.
4. Spill: Sorting, and merging the mix operate if any, perform compression if given, and at last writing to local disk to form file spills.
5. Merge: Merging the file spills into one map outputfile. Merging may be performed in multiple rounds.
The Reduce Task is split into four phases:
1. Shuffle: Transferring the intermediate information from the mapper nodes to a reducer's node and decompressing if required. Partial merging may additionally occur throughout this section.
2. Merge: Merging the sorted fragments from the various mappers to make the input to the reduce method.
3. Reduce: execution the user-defined reduce method to supply the final output information.
4. Write: writing the final output to HDFS.
II. LITERATURE REVIEW
According to [1], process and analyzing bigdata could be a very tuff task for currently a days. there's inherent problem in standardization the parameters owing to two necessary reasons - initial, the parameter search area is storage and second is processing the data. we are in the era of massive information and large volumes of data has been generated in numerous domains like social media, stock exchange, e-commerce websites, transportation etc. fast analysis of such vast quantities of unstructured information could be a key demand for achieving success in several of those domains. acting distributed sorting, extracting hidden patterns and unknown correlations and alternative helpful data is crucial for creating higher selections. To with efficiency analyze massive volumes of knowledge, there's a requirement for parallel and distributed processing/programming methodologies.
One way to equalization load, Hadoop victimisation HDFS distributed huge size information to multiple nodes supported local disk storage capability in clusters [4]. the information location is economical in homogenized setting wherever all nodes have identical each computing speed and disk storage. during this setting computes same work on all nodes representing that no information must be affected from one node to a different node. All nodes are connected additionally as can't share information between 2 nodes in cluster of homogenized setting.
In heterogeneous setting or clusters have set of nodes wherever every node computing speed capacities and local disk capability could also be considerably totally different. If all nodes have totally different size work then a quicker computing ( high performance) nodes will complete process native information quicker than slow computing (low- performance)nodes. quicker node finished process information then result residing into its native disk and handle unprocessed information of remote slow node. once move or transfer unprocessed information from low performance (remote) node to high performance node is large then overhead of knowledge transmission is going on. If needs Progress the MapReduce performance in heterogeneous setting then cut back the quantity of knowledge affected between low performances nodes to high performance nodes.
Improve The MapReduce performance in numerous Environments:
A.information Placement in Heterogeneous Hadoop Clusters
B.Heterogeneous Network Environments and Resource Utilization
C.good Speculative Execution Strategy D.Longest Approximate Time to finish.
A. Improve MapReduce Performance through information Placement in Heterogeneous Hadoop Clusters [5].
We want improve the performance then minimize information movement between slow and quick nodes achieved by information placement theme that distribute and store information across multiple heterogeneous nodes supported their computing speed.
1) information placement in Heterogeneous- 2 algorithms area unit enforced and incorporated into Hadoop HDFS. the primary algorithmic program is to at first distribute file into heterogeneous nodes in a very cluster. once all file fragments of Associate in dividing input and distributed to the computing nodes. The second algorithmic program is employed to reorganize file fragments to resolve the information skew drawback. There 2 cases during which file fragments should be organized. First, new computing nodes area unit more to Associate in distributing existing cluster to own the cluster expanded . When, new information is appended to Associate in distributing existing input data. In each cases, file fragments distributed by the initial information placement algorithmic program will be noncontinuous.
B. Enhance MapReduce Performance in Heterogeneous Network Environments and Resource Utilization [6]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)53
Resource utilization is inefficient once there don't seem to be some enough tasks to fill all task slots because the reserved resources for idle slots area unit simply wasted. Then Resource stealing, that allows running tasks to steal the residual resources and come them once new tasks area unit appointed. there's use of wasted resources to boost overall resource utilization and cut back job execution. First-come-Most(FCM) , Shortest-Time-Left-Most(STLM) , Longest –Time-Left-Most(LTLM) these area unit resource allocation policies.
2) profit Aware Speculative Execution –This mechanism predicts the advantage of launching new speculative tasks and greatly eliminates extra runs of speculative tasks. Speculative execution in Hadoop was determined to be inefficient, that is caused by the excessive runs of useless speculative tasks. profit Aware Speculative Execution manages speculative tasks in a very benefit-aware manner and expected to boost the potency.
C. Enhance MapReduce Performance victimisation good Speculative Execution Strategy [7]
Multiple speculative execution ways in to enhance the
performance in Heterogeneous additionally as
homogenized. however there are some Pitfalls degrade the performance. once existing ways cannot work well, then they develop a brand new strategy, MCP (Maximum Cost Performance), that improves the effectiveness of speculative execution considerably.
When a machine takes an oddly lasting to complete a task (the supposed lagger machine), it'll delay the duty execution time (the time from job initialized to job retired) and degrade the cluster output (the range of jobs completed per second within the cluster) considerably. This drawback handled speculative execution. a brand new speculative execution strategy named MCP for max price Performance. we tend to take into account the value to be the computing resources occupied by tasks, whereas the performance to be the shortening of job execution time and therefore the increase of the cluster output. MCP aims at choosing lagger tasks accurately and promptly and backing them informed correct employee nodes.MCP is sort of ascendible, that performs fine in each tiny clusters and enormous clusters.
III. PROBLEM DEFINITION
When an analysis is being conducted on Big Data it is of utmost importance that the data being dealt with is accurate and does not have any abnormalities.
There are numerous factors that affect the performance of Hadoop such as hardware and software when handling huge amounts of data. Both the main components of Hadoop, that is, HDFS and MapReduce play a major role in its performance Hadoop and the results that are generated.
HDFS: The number of reading and writing operations performed on the nodes also affects the performance of Hadoop. The performance of HDFS also depends on whether the work is being performed on big or small dataset.
MapReduce: Tuning the number of map tasks and reduce tasks for a particular job in the workload is another way that performance can be optimized. If the mappers are running only for a few seconds then fewer mappers can be used for longer periods. Also performance depends on the number of reducers used which should be slightly less than the number of reduce slots in the cluster to improve performance. This allows the reducers to finish in one wave and fully utilizes the cluster during the reduce phase. MapReduce job performance can also be affected by the number of nodes in the Hadoop cluster and the available resources of all the nodes to run map and reduce tasks.
Shuffle tweaks: The MapReduce shuffle also helps to alter performance as it maintains a balance between the map and reduce functions. If adequate amount of memory is allocated to map and reduce functions then the shuffle can also be allocated enough memory to operate thereby improving performance. Therefore, a trade off needs to be carried out when allocating memory to tasks in MapReduce.
IV. PROPOSED WORK
Step 1: first we collect dataset and apply these dataset into various mapreduce job.
Step 2: now we develop mapreduce job with default parameters or with tuning parameters on which we can apply the same datasets.
Step 3: Configure hadoop on which we can run the mapreduce job jar file.
Step 4: The dataset should be store in HDFS and mapreduce takes input from HDFS and perform mapreduce task and stored the mapreduce output in HDFS.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)54
ANALYSIS STEPS
V. EXPERIMENTAL &RESULT ANALYSIS
[image:4.595.50.290.131.385.2]All the experiments were performed using an i3-2410M CPU @ 2.30 GHz processor and 4 GB of RAM running, and vmware is installed on it and on this vmware we can configure ubuntu 14 on this vmware with @GB RAM is allocated to the vmware. After that we can configure hadoop in pseudo distributed mode in which all the hadoop daemons are running on a single machine. After that we can load the different size datasets into the HDFS by using hadoop put command in figure 2.
Figure 2. Dataset is loaded into HDFS
After loading datasets we can developed two mapreduce jobs first is in default configuration and second one is our proposed approaching in which we can tune the mapreduce job. we can launch the existing.jar file on hadoop environment shown in figure 3.
[image:4.595.314.570.324.505.2]Figure 3. launching existing job on medium size dataset After execution of existing mapreduce job the final output is shown in output directory and the other performance fields such as shuffle bytes taken and time taken for execution, the execution time taken are shown in figure 4.
Figure 4. time taken by existing.jar job
After existing mapreduce job execution is done than we launch a proposed mapreduce job on hadoop which are shown in figure 5.
Figure 5. launching proposed.jar job on medium size dataset
[image:4.595.48.289.522.654.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018) [image:5.595.49.292.123.332.2]55
Figure 6. time taken by proposed.jar mapreduce job [image:5.595.313.574.159.329.2]After performing all the execution we can say that our proposed technique of combining function within map tast will produce faster execution result as compared to default configuration. We can perform same execution on different size datasets and the execution time taken by both of these are shown in table 1.
Table 1. Execution time taken in ms
[image:5.595.317.572.377.540.2]Time taken by map task in existing and proposed approach are shown in figure 7.
Figure 7. Time taken by map task
Time taken by reduce task in existing and proposed approach are shown in figure 8.
Figure 8. Time taken by Reduce task
The total time taken by existing and proposed techniques are shown in figure 9.
Figure 9. Total time taken by existing & proposed Techniques The proposed techniqus shows better execution result as compared to existing default configuration because in proposed we can perform all the operation on map side so the reducer input records is less thats by the network cost and the reduce load is optimize in proposed. Table 2 shows the number of records process by mapper and reducer.
Table 2.
[image:5.595.47.284.444.554.2] [image:5.595.51.291.590.751.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 4, April 2018)56
VI. CONCLUSION
In this paper, we can fetch the data to corresponding compute nodes in advance. It is proved that the proposal of this paper reduces data transmission overhead effectively with proposed technique. We proposed a prefetch mechanism approach by tuning the mapreduce configuration and compare it with default mapreduce configuration and by using proposed technique the performance of mapreduce framework is increases as compared to default base configuration. There are many mapreduce parameters is present in future we can find the other parameters to further increase the mapreduce performance.
REFERENCES
[1] Ankita Jain, Monika Choudhary, ― Analyzing & Optimizing Hadoop Performance‖ in Big Data Analytics and Computational Intelligence (ICBDAC), in IEEE 2017.
[2] Swathi Prabhu, Anisha P Rodrigues, Guru Prasad M S & Nagesh H R, ―Performance Enhancement of Hadoop MapReduce Framework for Analyzing BigData‖, IEEE 2015, 978-1-4799-608S-9/1S
[3] MapReduce Performance Using Data Prefetching mechanism in heterogeneous or Shared Environments Tao gu,Chuang Zuo,Qun Liao , Yulu Yang and Tao Li, International Journal of grid and distributed computing (2013).
[4] ―Improve the MapReduce Performance through complexity and performance based on data placement in Heterogeneous Hadoop Cluster ‖ Rajashekhar M. Arasanal, Daanish U. Rumani Department of Computer Science University of Illinois at Urbana-Champaign.
[5] J. Xie, S. Yin, X. Ruan, Z. Ding, Y. Tian, J. Majors, A. Manzanares and X. Qin, ―Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters‖, IEEE International Symposium on Parallel & Distributed Processing, Workshops and PhD Forum (IPDPSW), (2010) April 19-23: Arlanta, USA.
[6] Improving MapReduce Performance in Heterogeneous Network Environments and Resource Utilization, Zhenhua Guo, Geoffrey Fox IEEE (2012)
[7] Improving MapReduce Performance Using Smart Speculative Execution Strategy Qi Chen, Cheng Liu, and Zhen Xiao, Senior Member, IEEE 0018-9340/13/$26.00 © 2013 IEEE
[8] Khalil, S. A. Salem, S. Nassar and E. M. Saad, ―Mapreduce Performance in Heterogeneous Environments: A Review‖, International Journal of Scientific & Engineering Research, vol. 4, no. 4, (2013).
[9] S. Seo, I. Jang, K. Woo, I. Kim, J. S. Kim and S. Maeng, ―HPMR: Prefetching and Pre-shuffling in Shared MapReduce Computation Environment‖, IEEE International Conference on Cluster Computing and Workshops, (2009) August 31-September 4: New Orleans, USA.
[10] S. Khalil, S. A. Salem, S. Nassar and E. M. Saad, ―Mapreduce Performance in Heterogeneous Environments: A Review‖, International Journal of Scientific & Engineering Research, vol. 4, no. 4, (2013).
[11] J. Xie, S. Yin, X. Ruan, Z. Ding, Y. Tian, J. Majors, A. Manzanares and X. Qin, ―Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters‖, IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW), (2010) April 19-23: Arlanta, USA.
[12] Z. Tang, J. Q. Zhou, K. L. Li and R. X. Li, ―MTSD: A task scheduling algorithm for MapReduce base on deadline constraints‖, IEEE International Symposium on Parallel and Distributed Processing Workshops and PhD Forum (IPDPSW),
(2012) May 21-25: Shanghai, China.
[13] M. Zaharia, D. Borthakur, J. Sen Sarma, K. Elmeleegy, S. Shenker and I. Stoica, ―Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling‖, Proceedings of the 5th European conference on Computer systems, (2010) April 13-16: Paris, France.
[14] X. Zhang, Z. Zhong, S. Feng and B. Tu, ―Improving Data Locality of MapReduce by Scheduling in Homogeneous Computing Environments‖, IEEE 9th International Symposium on Parallel and Distributed Processing with Applications (ISPA), (2011) May 26-28: Busan, Korea.
[15] C. Abad, Y. Lu and R. Campbell, ―DARE: Adaptive Data Replication for Efficient Cluster Scheduling‖, IEEE International Conference on Cluster Computing (CLUSTER), (2011)