International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 4, April 2012)Detecting E-mail Spam Using Spam Word Associations
N.S. Kumar
1, D.P. Rana
2, R.G.Mehta
3Sardar Vallabhbhai National Institute of Technology, Surat, India
3
Abstract— Now-a-days, mailbox management has become a big task. A large proportion of the emails we receive are spam. These unwanted emails clog the inbox and are very ubiquitous. Here, a new technique for spam detection is presented that makes use of clustering and association rules generated by the Apriori algorithm. Vector space notation is used to represent the emails. The results obtained from experiments conducted on the ling-spam dataset demonstrate the effectiveness of the proposed technique.
Keywords—Association rules, Content based spam, detection, Email spam, Text clustering, Vector space model
I. INTRODUCTION
Spam is an unfortunate problem on the internet. Spam emails are the emails that we get without our consent. They are typically sent to millions of users at the same time. Spam can be defined as unsolicited (unwanted, junk) email for a recipient or any email that the user does not want to have in his inbox. It is also defined as ―Internet Spam is one or more unsolicited messages, sent or posted as a part of larger collection of messages, all having substantially identical content.‖ [1]
Most spam is sent to sell products and services and the reason that spam works is because a small number of people choose to respond to it. It costs the sender of the spam mail almost nothing to send millions of spam emails.
Spam is a big problem because of the large amount of shared resources it consumes. Spam increase the load on the servers and the bandwidth of the ISPs and the added cost to handle this load must be compensated by the customers. In addition, the time spent by people in reading and deleting the spam emails is a waste. Taking a look at the 2010 statistics[2], 89.1% of the total emails were spam. This amounts to about 262 spam emails per day. These are truly large numbers.
This paper is organized as follows. A brief introduction about spam was given in the paragraphs above. Related work in this field is discussed in section II. The work proposed in this paper is explained in Section III. The results & inferences are presented in section IV. Lastly, the conclusions are presented in section V
II. RELATED WORK
Several solutions to the spam problem involve detection and filtering of the spam emails on the client side. Machine learning approaches have been used in the past for this purpose. Some examples of this are: Bayesian classifiers as Naive Bayes[3], [4], [5], [6], C4.5[7], Ripper[8] and Support Vector Machine(SVM)[9] and others. In many of these approaches, Bayesian classifiers were observed to give good results and so they have been widely used in several spam filtering software. A number of techniques make use of clustering as a part of their spam detection approach as: clustering followed by KNN classification [10], [11], clustering followed by KNN or BIRCH classification [1] and clustering followed by SVM classification [12]. Up to the knowledge of the authors, clustering with association rules has not been used for spam detection in the past.
Vector space model[13] is an algebraic model for representing text documents as vectors of identifiers.
Each dimension corresponds to a separate term. If the term occurs in the document, it has some non-zero value in the vector. This is shown in Figure 1.
The simplest scheme is to set this value to the number of times a particular word occurs in that document. The drawback of this approach is that some terms occur with very high frequency and usually can’t be used to discriminate the documents.
The tf-idf weighting scheme is an improvement over the simple scheme. In this scheme, the value increases proportionally to the number of times a word appears in the document, but is offset by the frequency of the word in the corpus. According to this scheme the value is computed as:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 4, April 2012)223 Where N is the number of documents and dft is the number of documents that contain that term. The tf-idf value is high when the document frequency is high and the inverse document frequency is low. The effect is that the common terms are filtered out.
Figure1. Vector space notation
Clustering is assigning a set of objects into groups (called clusters) so that the objects in the same cluster are more similar to each other than to those in other clusters. It is one of the most important unsupervised learning problems. Document (or text) clustering is a subset of the larger field of data clustering. In our system, clustering is a data reduction step. i.e. after the clusters of email documents are formed, we select only the 'spammy' clusters and then the subsequent steps are applied only to the selected clusters. This helps in reducing the time and effort needed to perform the entire operation.
K-means[14] is one of the simplest clustering algorithms. It attempts to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean. The main idea is to define k centroids, one for each cluster. The choice of the initial centroids affects the final outcome and ideally they should far away from each other. The steps in the algorithm are as given below:
• Arbitrarily choose k email documents as the initial centroids.
• Repeat
• (re)assign each email document to the cluster to which it is the most similar, based on the decided similarity measure
• Obtain new centroids for each cluster • Until no change
In distance-based clustering, the similarity criterion is distance: two or more objects belong to the same cluster if they are ―close‖ according to a given distance. In our case, the distance measure that we use is the cosine distance between documents. It is the most popular similarity measure applied to text documents.
The cosine distance of two documents is defined by the angle between their feature vectors.
Where "." denotes the dot-product of the two frequency vectors A and B, and ||A|| denotes the length (or norm) of a vector.
Document similarity is based on the amount of overlapping content between documents. The resulting similarity ranges from -1 meaning exactly opposite, to 1 meaning exactly the same, with 0 usually indicating independence, and in-between values indicating intermediate similarity or dissimilarity.
Advantages of the K-means algorithm are that apart from being simple, it is efficient for operating on large data sets. Disadvantages are that initial choice of the centroids can give varied outcomes; it is sensitive to noise and outliers and tends to terminate at local optimums. The time complexity of the k-means algorithm is O (nkl), where n is the number of objects, k is the number of clusters, and l is the number of iterations [15].
Association rules are if/then statements that help uncover relationships between seemingly unrelated data in a relational database or other information repository. For example, the rule {milk, bread} {butter}found in the sales data of a supermarket would indicate that if a customer buys milk and bread together, he or she is also likely to buy butter.
Two important terms that go along with association rules are Support and Confidence. Support is an indication of how frequently the items appear in the database. Confidence indicates the number of times the if/then statements have been found to be true. Support and confidence values can be changed to control the number of rules that are generated
Apriori[16] is a classic algorithm for learning association rules. It attempts to find subsets which are common to at least a minimum number C of the item sets. Apriori uses a "bottom up" approach, where frequent subsets are extended one item at a time and groups of candidates are tested against the data. The algorithm terminates when no further successful extensions are found. The purpose of the Apriori Algorithm is to find associations between different sets of data. In our technique, the associations that we are interested are between the spam words that occur in emails.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 4, April 2012)TABLE I
FOUR POSSIBLE OUTCOMES OF EMAIL ASSOCIATION
Support and Confidence are used to control the number of rules generated, they are not the evaluation criteria. Instead, four measures – precision, recall, specificity and accuracy were used in the evaluation process. They are defined in Table II[1].
TABLE II
EVALUATION MEASURES USED IN THE SYSTEM
Measure Defined as What it means
Precision
FP TP
TP
Percentage of positive predictions that are correct Recall/Sensitivity
FN TP
TP
Percentage of positive labeled instances that were predicted as positive Specificity
FP TN
TN
Percentage of negative labeled instances that were predicted as negative Accuracy
FN FP TN TP
TN TP
Percentage of
predictions that are correct
Accuracy alone is not sufficient to gauge the effectiveness of the system because we want both the spam and the non-spam emails to be correctly labeled. Accuracy value might be high but it might be labeling only one of spam or non-spam emails correctly. If the precision is high, it means that the false positives are less. If he Recall is more, it means that the system recognizes most of the spam messages. A high value of specificity means that very few non-spam messages are associated as spam. A perfect predictor would be described as 100% sensitivity and 100%
III. PROPOSED WORK
The purpose of this paper is to present a technique to identify email messages as spam or non-spam. Once that is done, the accuracy of the method is tested to see how many mails were correctly categorized. Emails messages are represented as vectors. Clustering is then applied to group together spam and non-spam emails. Then, Apriori algorithm is applied to generate the association rules. These can be then applied to the new mails to see whether they are spam or not.
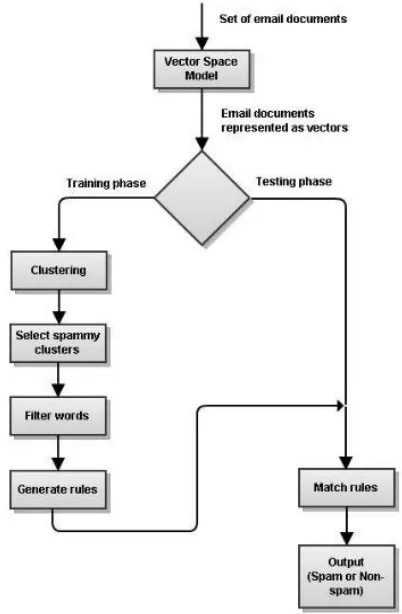
[image:3.612.344.545.414.721.2]The steps in the proposed system are as indicated in Figure 2.
Apache Mahout[17] contains free implementations of scalable machine learning algorithms. It contains several algorithms for clustering, classification, pattern mining, frequent item mining amongst others. We use it for converting the set of email documents to the vector space notation and then to cluster the emails.
Christian Borglet’s[18] implementation of the Apriori algorithm is used for generating frequent item sets. By varying the values used for support and confidence, the number of rules generated can be controlled.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 4, April 2012)225 Set of email documents is converted into the vector space notation. Entries in the vectors are the tf-idf values.
It may happen that some emails in the set have more length than others. In such emails, same terms are likely to appear more times i.e. they may have more term frequencies. Plus, such emails may also have more terms that can be considered as spam. To compensate for this difference in length, some sort of normalization is needed. L2 normalization[19] is used for this purpose.
Clusters of similar emails are then formed. K-means algorithm is used for clustering. The clusters may not be distinct spam and non-spam clusters – each may consist of a mixture of spam and non-spam emails. Out of these clusters, ones having >= 50% spam emails will be selected to generate the association rules. This is to ensure that the set of emails obtained after this step has substantial number of spam emails which will improve the accuracy of the system.
As the size of the data to be clustered increases the number of clusters to be formed(k) should also be increased accordingly to obtain better clusters.
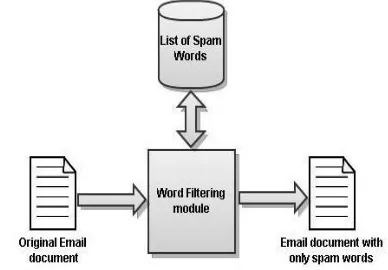
[image:4.612.74.268.492.627.2]A list of commonly occurring spam words was created. The emails obtained once we have selected the spammy clusters are compared against this list. This forms a filtering step. Only the words that occur in the list are retained and the rest of the text is deleted. At the end of this operation, we get the various combinations in which the spam words occur in the set of emails. This list can be updated periodically to include new words that can be considered as spam words.
Figure 3. Obtaining spam words combination from an email document
At this point we can go ahead and generate the association rules using the Apriori algorithm. Once we have the rules, they can be matched against new emails to decide whether it is spam or not.
To understand how the new emails will be processed, let’s take an example. Assume that the words lottery and gambling occur in the list of spam words. So there may be a rule of the form lottery —> gambling. Any new email that has both these words in its content will be treated as spam. Likewise, several other rules may match for some test email. Emails which are not spam will not contain any words from the list of spam words or won’t contain all the words that form a rule. Such emails will be identified as non-spam by the system.
IV. EXPERIMENTAL RESULT
The corpus used for training and testing is the ling-spam corpus[20]. In ling-spam, there are four subdirectories, corresponding to 4 versions of the corpus, viz.,
bare: Lemmatiser disabled, stop-list disabled, lemm: Lemmatiser enabled, stop-list disabled, lemm_stop: Lemmatiser enabled, stop-list enabled, stop: Lemmatiser disabled, stop-list enabled,
Where lemmatizing is similar to stemming and stop-list tells if stopping is done on the content of the parts or not. We use the lemm_stop subdirectory in our approach Each one of these 4 directories contains 10 subdirectories (part 1,…, part 10). These correspond to the 10 partitions of the corpus that were used in the 10-fold experiments. In every part, 9 partitions were used for training and the 10th partition was used for testing. Each one of the 10 subdirectories contains both spam and legitimate messages, one message in each file. Files whose names have the form spmsg*.txt are spam messages. All other files are legitimate messages. The total number of spam messages is 481 and that of legitimate messages are 2412. The percentage of spam in this corpus is 16.6%.
Final results are obtained by taking the average of the scores obtained in each of the 10 experiments,
One advantage of the ling-spam corpus is the focus on the textual component of the email as needed in our system. In a real email-filtering system, some part of the message header may be used to improve the classification performance. e.g. senders email address could be looked up in the address book. Such strategies do not require machine learning and are not the focus of our work here.
Results of conducting the experiments on the ling-spam data set are shown in the table below. Values are the average of 10 experiments, each using 1 of the 10 parts for testing and the other 9 for training.
TABLE III
RESULTS OF APPLYING THE PROPOSED APPROACH ON THE LING-SPAM
DATASET
Measure Average Value
Precision 60.10%
Recall 71.60%
Specificity 92.28%
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 4, April 2012)As seen in the table above, about 89.31% of the total emails were correctly identified. Precision value is on the lower side so more false positives are being generated. Recall is also low and this indicates that not all spam messages are recognized. Since the specificity is high, most non-spam emails are recognized as non-spam.
V. CONCLUSION
In this paper, a new technique to effectively detect spam emails using clustering and association rules was suggested. Clustering is used as a data reduction step - to find the ―spammy‖ clusters out of all the emails. After the doubtful clusters are identified, association rules can be generated for such clusters. Using these rules, we can then associate an incoming email as spam or non-spam. As part of future work, the system can be made truly dynamic by automating the entire process on the server side.
REFERENCES
[1] Prabhakar, R. and Basavaraju, M. 2010. ―A Novel Method of Spam Mail Detection Using Text Based Clustering Approach.‖ Phil. Trans. Roy. Soc. London, vol. A247, pp. 529–551.
[2] ―Internet 2010 in Numbers.‖ Internet: http://royal.pingdom.com/2011/01/12/internet-2010-in-numbers/ [Mar. 23, 2012].
[3] Androutsopoulos, I., Chandrinos, K., Koutsias, J., Paliouras, G. and Spyropoulos, C. 2000. ―An Evaluation of Naive Bayesian Anti-spam Filtering,‖ in Proceedings of the Workshop on Machine Learning in the New Information Age: 11th European Conference on Machine Learning (ECML 2000), pp. 9–17.
[4] ―Bogofilter.‖ Internet: http://bogofilter.sourceforge.net/ [Mar. 23, 2012].
[5] Graham, P. ―Better Bayesian Filtering.‖ Internet: http://www.paulgraham.com/better.html [Mar. 23, 2012].
[6] Dumais, S., Heckerman, D., Horvitz, E. and Sahami, M. 1998. ―A Bayesian Approach to Filtering Junk E-mail,‖ in Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, pp. 1048– 1054.
[7] Quinlan, J.R. C4.5: Programs for Machine Learning, 1st ed., San
Mateo, CA: Morgan Kaufmann, 1993.
[8] Cohen, W.W. 1996. ―Learning Rules that Classify E-mail,‖ in Proceedings of the 1996 AAAI Spring Symposium on Machine Learning in Information Access, pp. 203–214.
[9] Druker, H. 1999. ―Support Vector Machines for Spam Categorization,‖ in IEEE Transaction on Neural Networks, pp 1048– 1054.
[10] Firte, L., Lemnaru, C. and Potolea, R. 2010. ―Spam Detection Filter Using KNN Algorithm and Resampling,‖ in Intelligent Computer Communication and Processing (ICCP), 2010 IEEE International Conferenc, pp. 27 – 33.
[11] Alguliev, R.M., Aliguliyev, R.M. and SNazirova, S.A. Classification of Textual E-mail Spam Using Data Mining Techniques. Applied Computational Intelligence and Soft Computing, vol. 2011, Article ID 416308, 8 pages. doi:10.1155/2011/416308.
[12] Kyriakopoulou, A. and Kalamboukis, T. 2006. ―Text Classification Using Clustering,‖ in ECML-PKDD Discovery Challenge Workshop Proceedings.
[13] ―Vector Space Model.‖ Internet: http://en.wikipedia.org/wiki/ Vector_space_model [Mar. 23, 2012].
[14] MacQueen, J. 1967. ―Some Methods for Classification and Analysis of Multivariate Observations.‖ Proc. Fifth Berkeley Sympos. Math. Statist. and Probability (Berkeley, Calif., 1965/66) Vol. I: Statistics, pp. 281–297.
[15] Manning, C.D., Raghavan, P., and Schutze, H. Introduction to Information Retrieval. 1st ed., Cambridge, England: Cambridge
University Press, pp. 109-133, 2008.
[16] Agrawal, Rakesh and Srikant, Ramakrishnan. 1994. ―Fast Algorithms for Mining Association Rules in Large Databases,‖ in
Proceedings of the 20th International Conference on Very Large Data Bases,VLDB, Santiago, Chile, pp. 487-499.
[17] ―Apache Mahout: Scalable Machine Learning and Data Mining.‖ Internet: http://mahout.apache.org/ [Mar. 23, 2012].
[18] ―Apriori - Association Rule Induction / Frequent Item Set Mining.‖ Internet: http://www.borgelt.net/apriori.html [Mar. 23, 2012]. [19] ―Lp space.‖ Internet: http://en.wikipedia.org/wiki/Lp_space [Mar.
23, 2012].