Foreseeing Client Conduct through Sessions
Utilizing the Web Log Mining
M Sreedevi1, Rita Roy2, D Rajendra Dev3 1, 2, 3
Department of Computer Science and Engineering, SANKETIKA Institute of Technology and Management, Visakhapatnam, Andhra Pradesh, India”
Abstract: It is the strategy to separate the client sessions from the given log documents. At first, every client is recognized by his/her IP address determined in the log record and comparing client sessions are removed. Two kinds of logs ie., server-side logs and customer side logs are regularly utilized for web utilization and ease of use examination. Server-side logs can be consequently created by web servers, with every section relating to a client ask. Client side logs can catch precise, complete use information for ease of use investigation. Ease of use is characterized as the fulfillment, productivity and viability with which particular clients can finish particular assignments in a specific domain. This procedure incorporates 3 phases, to be specific Data cleaning, User distinguishing proof, Session recognizable proof. In this paper, we are actualizing these three stages. Contingent on the recurrence of clients going by each page mining is performed. By finding the session of the client we can investigate the client conduct when spend on a specific page.
Catchphrases: Web log mining, User ID, Session distinguishing proof.
I. INTRODUCTION
The WWW as a biggest data builds has had much advance since its coming. As the WWW has progressed toward becoming standard today, feature content created by clients, interoperability and ease of use. A web may enable clients to connect and team up with each other in an online networking discourse as makers of client created setting in a virtual group. In this way, World Wide Web turns out to be more prevalent and easy to understand for exchanging information[7] [13]. Thusly, individuals are more keen on investigating log records which can offer more valuable understanding into site utilization. Information mining is the extraction of learning from the immense measure of information sets, to discover a relationship and examples in information that have been not beforehand been found to abridge the information in unique approaches to influence it to comprehend and valuable to the clients. Web mining is one of the method of information mining to separate helpful data in view of clients' needs, under web mining, web use mining is one of the utilization of information mining innovation to extricate data from weblog to investigate the client access to sites by [2] [14]. Web mining is the utilization of information mining method to consequently find and concentrate data from web records and administrations.
There are 3general classes of data that can be found by web mining [4] : Web movement: From server logs and web program movement following.
Web diagram: from joins between pages, individuals and other information.
Web content: for the information found a website page and within archives. Real utilizations of web use mining:
Web personalization: Web server logs are utilized to bunch web clients having comparative interests. It is likewise characterized as adjusting administrations and data which was accessible on a site to the necessities and the desires of an objective client, the dynamic client; the personalization errand by [13] may profit from the information picked up from an investigation of the client's navigational conduct joined with different highlights which are curious to a Web setting, to be specific its structure and substance. Framework Improvement: stack adjusting, Web reserving, organize transmission or information appropriation is the normal application zones of web digging for enhancing the framework execution [8].
Site rearrangement: The connection structure and substance structure of any site are two huge components for any site. The current improvement in web mining innovations goes towards shorter route successions, for that reason
the simplicity to get to target page in any web space should be expanded. The rearrangement errand can be performed with regard to the incessant examples separated. Web utilization information moreover give data about the plan of any site with deference to clients' practices [5] [8]. The site proprietor can upgrade these pages and watch the conduct of clients on these pages.
"strategically pitching" or offering things connected to their requests. Subsequently, information about the clients' inclinations and necessities make the CRM more viable. The fundamental objectives of organizations [2] are holding their old client and draw in new clients to beat their competitor's.
Use Categorization: In this procedure the data put away in Web server logs is handled by applying different information mining strategies in order to (an) extricating measurable data and finding intriguing use designs,
(b) as per the navigational conduct [1] the clients are being grouped and (c) decide conceivable connections between Web pages also, client gatherings. Others information mining methods are likewise utilized for finding helpful examples.
II. WEB LOG FILES
Web log records are the documents which contain finish data about the clients peruse exercises on the web server by [2] 11] [4]. These web log documents are made naturally by each client snap to the relating web servers. These log documents is in content arrangement, the greater part of the circumstances and the size fluctuates from 1KB to 100 MB.
A. Types of log documents
There are three sorts of log records which are as per the following:
1) Web Server Logs: History of website page demands is kept up as a log record. Web servers are the expensive and the most well-known information source. They gather substantial volume of data in their log documents. These logs contain name, IP, date, and time of the demand, the ask for line precisely originated from the customer, and so on. These information can be bound together as a solitary content document, or isolated into various logs, similar to get to log, referrer log, or mistake log. In any case, client particular data isn't put away in the server logs [15].
2) Intermediary Server Logs: It goes about as an interceding level of getting lies between customer program and web servers. Intermediary storing is utilized to diminish the stacking time of a website page and in addition the decrease arrange movement at the server and customer side. The real HTTP ask from different customers to various web servers are followed by the intermediary server [9]. The intermediary server log is utilized as an information hotspot for perusing conduct portrayal of a gathering of unapproved clients sharing a typical intermediary server.
3) Program Logs: On customer side utilizing JavaScript or Java applets the perusing history is gathered. To execute customer side information accumulation, client participation is required. Here pre-preparing talked about utilizing Web Server Logs [11]. Web server logs are utilized as a part of the site page proposal to enhance the E-Commerce ease of use
#Version: 1.0 #Date: 12-Jan-1996 00:00:00 #Fields: time cs-method cs-uri
00:34:23 GET /foo/bar.html 12:21:16 GET /foo/bar.html 12:45:52 GET /foo/bar.html 12:57:34 GET /foo/bar.html
The NCSA Common log record design is a settled ASCII content based configuration, so you can't redo it. The NCSA Normal log document arrange is accessible for Web locales and for
SMTP and NNTP administrations, yet it isn't accessible for FTP destinations. Since HTTP.sys handles the NCSA Common log record design, this configuration records HTTP.sys part mode store hits. A case is demonstrated as follows.
216.67.1.91 - - [01/Jul/2002:12:11:52 +0000] “GET / index.html HTTP/ 1.1” 200 431
B. IIS log file Format
The IIS log file format is a fixed ASCII text-based m format, so you cannot customize it. Because HTTP.sys handles the IIS log file format, this format records HTTP. syskernel-mode cache hits.
172.16.255.255, anonymous, 03/20/01, 23:58:11, MSFTPSVC, SALES1, 172.16.255.255, 60, 275, 0, 0, 0, PASS,/Intro.html
There are some critical specialized issues that must be taken into thought since it is fundamental for Web log information to be readied and preprocessed to utilize them in the subsequent periods
of the procedure by [9] [11].
III. PHILOSOPHY
In the information preprocessing, it takes web log information as info and after that procedure the web log information and gives the dependable information. The objective of preprocessing is to pick essential highlights, at that point expel undesirable data lastly change crude information into sessions. To accomplish its objective Data preprocessing is separated into Data Cleaning, client recognizable proof, and Session ID [12] [2].
A. Information Cleaning
The utilization of information cleaning method is to evacuate all the undesirable information utilized as a part of information examination and mining. To increment the mining productivity information cleaning is vital. The cleaned information incorporate expulsion of neighborhood and worldwide clamor, disposal of recordings, realistic records and the configuration productivity, end of HTTP status code records, robots cleaning.
1) The Records of-illustrations, video and the configuration : each record of URI field, JPEG, GIF, CSS filename augmentation is discovered, these expansions will be dispensed with from the web log document. The documents with these
2) Fizzled HTTP-status code: This cleaning procedure will lessen the assessment time for finding the client's intrigued sessions. In this procedure the status field of each record in the web get to log is checked furthermore, the status code more than 299 or beneath 200 are expelled.
3) Robots-Cleaning: It is likewise called as bug or not, it is a product apparatus that sweeps a site occasionally to extricate the substance. All the hyperlinks from a website page are consequently trailed by WR. The uninterested session from the log record is evacuated consequently when WR is evacuated. Client recognizable proof Each unique client getting to the site is distinguished in the client distinguishing proof process. The point of this procedure is to recover each client's entrance qualities, at that point make client grouping and give proposal administration to the clients. Distinctive clients are distinguished by various ip addresses.
B. Session Identification
A succession of pages saw by a client amid one visit is known as the Session. The session is recorded in the log record. In pre-preparing it is important to discover session of every client. It characterizes the circumstances the client has gotten to a site page. It takes all the page reference of a given client in a log and partitions them into client sessions. These sessions can be utilized as an info information vector in arrangement, grouping, forecast and different errands. In light of a uniform settled timeout a customary session distinguishing proof calculation is utilized. Another session is distinguished when the interim between two consecutive demands surpasses the 60 minutes.
Calculation 3: Session recognizable proof Info: client recognized table
Yield: distinguished sessions Start
Read records in log_table for each record in dataset do
on the off chance that time_required > one hour dole out new session ID for that log passage increase session ID
else
appoint the old session ID. End else
C. Test Results
We have directed a few examinations on log records gathered from web server. Amid Data purging advance all immaterial sections are expelled. Test crude web log document is as
[image:5.612.216.405.121.246.2]:
Fig 1: Raw log document .
Along these lines, after consummation of Data Cleansing Web Server Log record is cleaned and is set up for information to be stacked into a social database. Here the information are stacked and put away in MYSQL Server. The outcome got subsequent to performing information cleaning stage is demonstrated as follows.
Fig 2: cleaned log record
[image:5.612.200.415.303.418.2]At that point singular client is distinguished in view of the ip address. Subsequent to distinguishing client the required outcome is appeared in the underneath figure 3.
Fig 3: user identification
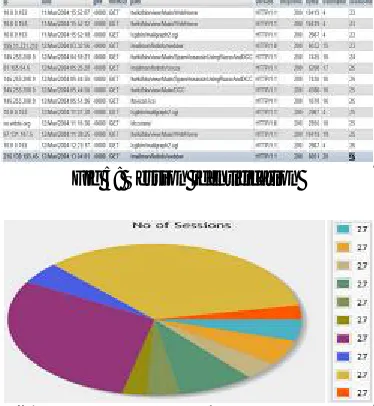
[image:5.612.165.450.460.719.2]At that point every session is distinguished in view of the time spent on each website page. Subsequent to distinguishing session the required outcome is appeared in the beneath figure 5.
Fig 5: Session identification
Fig 6: Representation of no. session identification
The figure indicates No. of sessions done by various clients, which was spoken to with various hues, each shading shows singular client. At long last, after table shows obvious thought regarding the work, here we have taken 1546 columns of test weblog dataset and subsequent to applying information cleaning calculation 1 the number of logs will diminish to 439 columns which comprises of cleaned information appeared at figure 2. Subsequent to getting the cleaned information the individual clients are distinguished by applying calculation 2 furthermore, the outcome is appeared in figure 3 and 4. Subsequent to getting the client recognizable proof the No.of sessions are distinguished for the singular client by applying calculation 3 and the outcome was appeared in figure 5 and 6. The general outcome was appeared in the following table 1.Final Result:
Rows in the Web Log file
Rows after Preprocessing
Total No. of users
Total No. Of sessions
1546 439 20 27
Table 1: Final result
IV. CONCLUSION
Web use mining is in fact one of the developing territories of investigate and essential sub-area of information mining and its procedures. So as to take full preferred standpoint of web utilization mining and its all procedures, it is critical to complete preprocessing stage productively and viably. This paper tries to convey zones of preprocessing, including information purging, session distinguishing proof, client recognizable proof. Once the preprocessing stage is all around performed, we can apply information mining methods like grouping, affiliation, arrangement and so on for uses of web utilization mining, for example, business insight, online business, e-learning, personalization, and so forth.
Web log mining is one of the current regions of research in Data mining. Web Usage Mining turns into a critical angle inthe present time on the grounds that the amount of information is persistently expanding. We manage the web server logs which keep up the historical backdrop of page demands Web log record examination started with the reason to offer to Web website managers an approach to guarantee satisfactory data transmission and server ability to their association.
By breaking down these logs, it is conceivable to find different sorts of information, which can be connected conduct investigation of clients.
REFERENCES
[1] Ruili Geng, and Jeff Tian “Improving Web Navigation Usability by Comparing Actual and Anticipated Usage” IEEE TRANSACTIONS ON HUMAN-MACHINE SYSTEMS, VOL. 45, NO. 1, FEBRUARY 2015.
[2] G. Neelima and Sireesha Rodda, “An Overview on Web Usage Mining”, Springer International Publishing Switzerland December 2015.
[3] Gan Teck Wei, Shirly Kho, Wahidah Husain, Zurinahni Zainol “ A Study of Customer Behaviour Through Web Mining” Volume 2, Issue 1 available at www.scitecresearch.com/journals/index.php/jisct/index, February, 2015.
[4] Thi Thanh Sang Nguyen, Hai Yan Lu, and Jie Lu, “Web-Page Recommendation Based on Web Usage and Domain Knowledge”, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENINEERING, VOL. 26, NO. 10, OCTOBER 2014.
[5] Zhen Liao, Yang Song, Yalou Huang, Li-wei He, and Qi He “Task Trail: An Effective Segmentation of User Search Behavior”, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 12, DECEMBER 2014.
[6] George Gkotsis ·Karen Stepanyan · Alexandra I. Christie · Mike Joy,” Entropy-based automated wrapper generation for weblog data extraction”, Received: 31 October 2012 / Revised: 24 October 2013 Accepted: 4 November 2013 / Published online: 21 November 2013 © Springer Science+Business Media New York 2013.
[7] V. S. Dixit • Shveta Kundra Bhatia ,” Refinement andevaluation of web session cluster quality”, Springer transaction Received: 20 February 2014 / Revised: 2 May 2014.
[8] Renuka Mahajan & J. S. Sodhi & Vishal Mahajan ,” Usage patterns discovery from a web log in an Indian e-learning site: A case study”, Springer Science+Business Media New York 2014.
[9] Muhammad Muzammal · Rajeev Raman,” Mining sequential patterns from probabilistic databases”, Received: 11 April 2013 / Revised: 11 May 2014 / Accepted: 3 July 2014 © Springer-Verlag London 2014.
[10] Tomas Arce , Pablo E. Roman , Juan Velasquez , Victor Parada ,” Identifying web sessions with simulated annealing”, Expert Systems with Applications 41 (2014) 1593–1600.