2019 International Conference on Computation and Information Sciences (ICCIS 2019) ISBN: 978-1-60595-644-2
An Improved Spectral Feature Alignment
for Domain Adaptation in Sentiment
Classification
Chuanlin Huang and Yi Ge
ABSTRACT
The problem of sentiment classification is extremely sensitive to the variation of domain, thus the sentiment classification model trained in one domain is often not applicable to the data from another domain. This paper proposes an improved spectral feature alignment domain adaptation algorithm (ISFA). ISFA extracts domain-independent words by term frequency and mutual information. Based on word co-occurrence relation, the bipartite graph between domain-independent words and domain-specific words is initially constructed. Then revision of sentiment dictionary is introduced to obtain a more accurate bipartite graph. In this graph, feature representation is obtained by utilizing spectral clustering dimension reduction. Besides, a new feature representation is obtained by combination updating for GBDT training. In this paper, 20 groups of experiments show that the accuracy of ISFA is 3.4% higher than that of SFA on average, which proves that ISFA is capable of finding out the feature space that makes the distribution of the two domains much closer.
1. INTRODUCTION
Sentiment classification is remarkably sensitive to the variation of domain. Regardless of the text data in either Chinese or English, the sentiment descriptive word varies from domain to domain. The related technology in machine learning has quite matured in tackling classification problems. Whereas the training set and test set required by traditional machine learning must satisfy the condition of
Chuanlin Huang, Science and Technology on Electronic Information Control Laboratory, Chengdu, 610036, China
independent-identical-distribution, which is difficult to meet in practical application scenarios of sentiment classification.
Domain adaptation is a sub-problem of transfer learning [1]. Domain adaptation relaxes the requirement of independent identical distribution condition, meanwhile solves the problem of lack of tags in target domains. Bickel and Jiang [2-3] adjusted conditional probability distribution and marginal probability distribution by instance-weight method. Arnold and Zhong [4-5] lessened the discrepancy between conditional probability distribution and marginal probability distribution by feature representation. In the research of using feature representation to lessen the discrepancy of distribution among domains, Blitzer et al [6] proposed SCL algorithm. Pan et al. [7] proposed the SFA (Spectral Feature Alignment) algorithm. Whitehead and Yeager [8] utilize domain dictionary to calculate the cosine similarity between the words in the source and target domain.
Aiming at the above background, this paper proposes an improved spectral feature alignment domain adaptation algorithm (ISFA) based on the SFA algorithm. Initially, ISFA promotes the extraction of domain-independent words by introducing term frequency and mutual information. Further, the bipartite graph between domain-independent words (DI words) and domain-specific words (DS words) is constructed by introducing the modification of sentiment dictionary and simultaneously two parameters are used to control the new feature representation to obtain a new feature representation method.
2. MATERIALS AND METHODS
2.1 The method
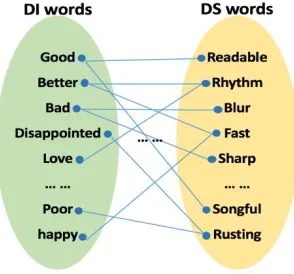
[image:2.612.232.379.517.654.2]The ISFA algorithm firstly uses term frequency to filter candidate sets of domain-independent words, then uses promoted mutual information to filter domain-independent words, and finally obtains DS words by subtracting DI words from the complete set.
Secondly, in the construction of bipartite graphs, words in a certain time window have similar sentiment polarity and the sentiment intensity, so as to obtain the link and weight of the initial bipartite graph. Through the analysis, know that it is terribly inaccurate to receive the initial weight by word co-occurrence. For example, negative words have influences on the sentiment of sentences, which is known that the negative word can lead to the opposite sentiment polarity between the front and back of it. Accordingly, on basis of hypothesis, we deduce that 1. Synonyms and antonyms in sentiment dictionary definitely have the same and opposite sentiments. 2. Annotations of positive and negative sentiment in sentiment dictionary are very valuable. Besides, ISFA algorithm can obtain more precise bipartite graph by drawing in the revision of sentiment dictionary.
Thirdly, making use of spectral clustering algorithm, eigenvalues and their corresponding eigenvectors are obtained by the calculation of Laplace matrix. Finally, the original feature and the dimension-reduction feature are combined and renovated to obtain the new representation which is shown in formula 1, where
xi ∈ ℝ1×n& xi′ ∈ ℝ1×(n+k), and the dimensions of new feature representations
become n + k. ISFA algorithm introduces two parameters, γ and α, to balance the weights of feature representation between original features and the features of after dimensionality reduction. And then GBDT model is used to train the sentiment classifier.
xi′= [x
i, γ ∗ (∅DI(xi) + α ∗ ∅DS(xi))] (1)
2.2 Data Set Description
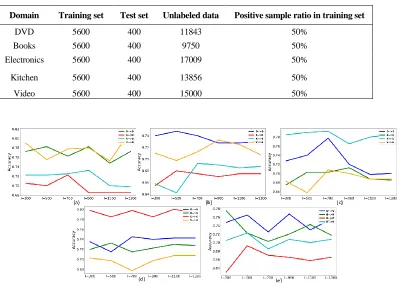
The data set selected for the experiment comes from Amazon's real comment data [9], which has been extensively used in the domain of adaptation issues of sentiment classification. This experiment chiefly consists of comments in five areas: “DVD”, “Books”, “Electronics”, “Kitchen”, “Video”. In order to verify the availability of the domain adaptation algorithm, this experiment combines five domains pairwise to get 20 domains adaptation experiments. The specific statistical results are shown in Table I.
3. ANALYSIS OF EXPERIMENTAL RESULTS
3.1 Comparison Experiment of ISFA Algorithm Parameters
sub-graph shows the trend of the accuracy of four domains adapting to a certain domain. Global observation demonstrates that each subgraph can find the optimal value of parameter l in 20 groups of experiment is instable, which varies with the source and target domains.
TABLE I. DATA SET STATISTICAL RESULTS.
Domain Training set Test set Unlabeled data Positive sample ratio in training set
DVD 5600 400 11843 50%
Books 5600 400 9750 50%
Electronics 5600 400 17009 50%
Kitchen 5600 400 13856 50%
Video 5600 400 15000 50%
Figure 2. Comparison experiments of different parameters 𝑙.
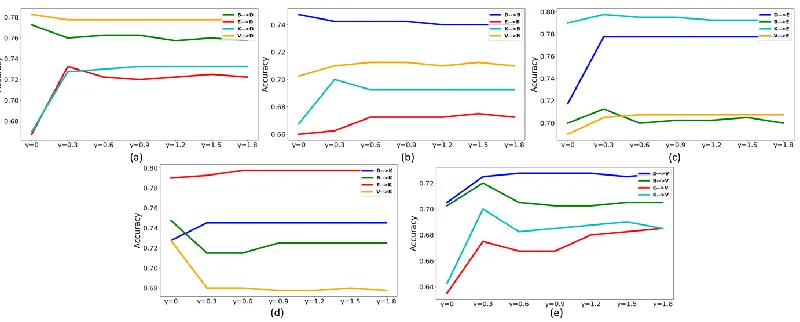
Given the parameter k that controls the dimension of feature representation of DI words and DS words after dimensionality reduction, when l = 700, γ = 0.6,
α = 1.5, the comparison experiments as shown in Figure 3. were carried out. From the global observation of 20 groups of experiments, know that compared with the trend of parameter l, parameter k appears more unstable, and the trend of accuracy fluctuating with k is irregular. Thus, the paper deduces that the selection of parameter k should be determined by different situations, aiming at the adaptation problems in different domains.
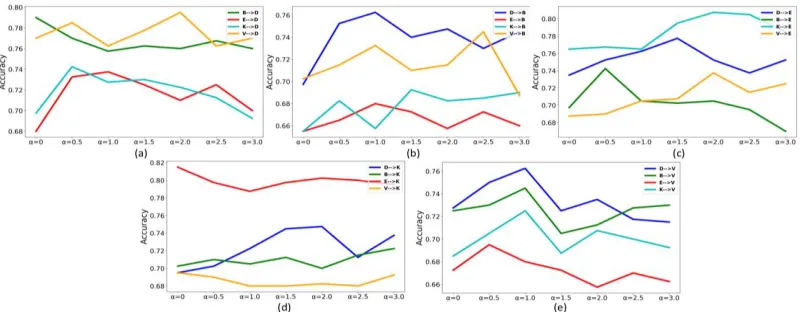
representation. Experiments are shown in Figure 4. where l = 700, k = 300, α =
[image:5.612.121.517.167.327.2]1.5. When γ = 0.3, most of the experiments can obtain relatively desirable and stable results, such as subgraphs (a), (c) and (e). It generally proves that the new feature representation proposed by ISFA algorithm is of great significance.
Figure 3. Comparison experiments of different parameters 𝑘.
[image:5.612.121.521.384.545.2]Figure 5. Comparison experiments with different parameter 𝛼.
α is used in the new feature representation to measure the feature representation weight of DI words and DS words. The comparison experiments are shown in Figure 5. where l = 700, k = 300, γ = 0.6. The observations show that with the changes of α, the accuracy rate is also excessively instable. While only the accuracy growth in subgraph (e) is basically consistent. Experiments indirectly prove the necessity of introducing of DS words.
Through the above experiments, this paper finds that the optimal four parameters need to be found by several sets of experiments aiming at the adaptation problems between different domains. The experiments of parameters γ and α show that the new feature representation proposed by ISFA algorithm is meaningful.
3.2 Comparison Experiments and The Results of Different Methods
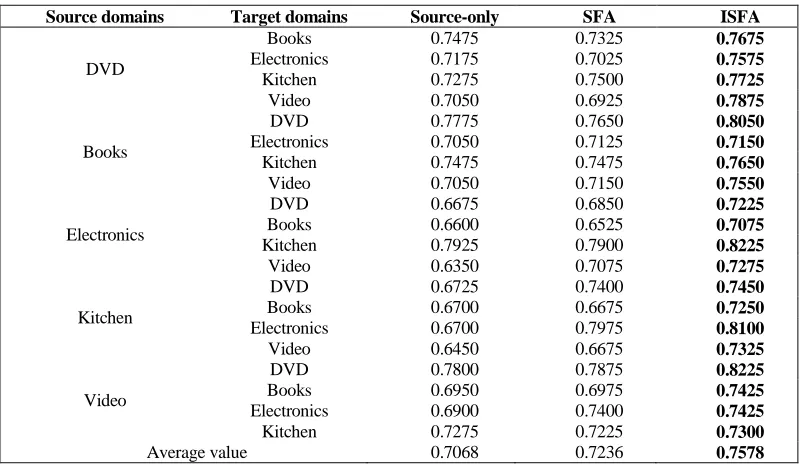
TABLE II. ACCURACY OF DIFFERENT METHODS ON THE DATASET.
Source domains Target domains Source-only SFA ISFA
DVD
Books 0.7475 0.7325 0.7675
Electronics 0.7175 0.7025 0.7575
Kitchen 0.7275 0.7500 0.7725
Video 0.7050 0.6925 0.7875
Books
DVD 0.7775 0.7650 0.8050
Electronics 0.7050 0.7125 0.7150
Kitchen 0.7475 0.7475 0.7650
Video 0.7050 0.7150 0.7550
Electronics
DVD 0.6675 0.6850 0.7225
Books 0.6600 0.6525 0.7075
Kitchen 0.7925 0.7900 0.8225
Video 0.6350 0.7075 0.7275
Kitchen
DVD 0.6725 0.7400 0.7450
Books 0.6700 0.6675 0.7250
Electronics 0.6700 0.7975 0.8100
Video 0.6450 0.6675 0.7325
Video
DVD 0.7800 0.7875 0.8225
Books 0.6950 0.6975 0.7425
Electronics 0.6900 0.7400 0.7425
Kitchen 0.7275 0.7225 0.7300
Average value 0.7068 0.7236 0.7578
Using accuracy as an evaluation index, the average accuracy of each algorithm in the table is higher than that of Source-only, among which the ISFA algorithm proposed in this paper is 5.1% higher on average, which indirectly demonstrates the necessity of domains adaptation of the sentiment classification. Besides, it can be seen that the results of the ISFA algorithm based on multiple experimental adjusting parameters were 3.4% higher than the SFA on average, in which the maximum increase from D to V reaches to 9.5%. By experiments, it is proved that the the enhancements of ISFA algorithm in extracting domain-independent words, constructing bipartite graph and improving feature representation, can make the accuracy rate be augmented to some extent.
4. CONCLUSIONS
it is necessary to determine the optimal parameters through multiple sets of experiments.
REFERENCES
1. Mingsheng Long.2007.Research on Transfer Learning Problems and Methods. Tsinghua
University.
2. Bickel S, Brückner M, Scheffer T. 2007 “Discriminative learning for differing training and test distributions,” Proceedings of the 24th international conference on Machine learning. ACM, 2007: 81-88.
3. Jiang J, Zhai C X. 2007. “Instance weighting for domain adaptation in NLP,” Proceedings of the 4th annual meeting of the association of computational linguistics. 2007: 264-271.
4. Arnold A, Nallapati R, Cohen W W. “A comparative study of methods for transductive transfer learning,” icdmw. IEEE, 2007: 77-82.
5. Zhong E, Fan W, Peng J, et al. 2009. “Cross domain distribution adaptation via kernel mapping,” Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009: 1027-1036.
6. Blitzer J, McDonald R, Pereira F. 2006. “Domain adaptation with structural correspondence learning,” Proceedings of the 2006 conference on empirical methods in natural language processing. Association for Computational Linguistics, 2006: 120-128.
7. Pan S J, Ni X, Sun J T, et al. 2009. “Cross-domain sentiment classification via spectral feature alignment,” Proceedings of the 19th international conference on World wide web. ACM, 2010: 751-760.
8. Whitehead M, Yaeger L. 2009. “Building a general purpose cross-domain sentiment mining model,” 2009 WRI World Congress on Computer Science and Information Engineering. IEEE, 2009, 4: 472-476.