Vector-based Natural Language Call
Routing
J e n n i f e r C h u - C a r r o l l *
Lucent Technologies Bell Laboratories
B o b C a r p e n t e r *
Lucent Technologies Bell Laboratories
This paper describes a domain-independent, automatically trained natural language call router for directing incoming calls in a call center. Our call router directs customer calls based on their response to an open-ended How may I direct your call? prompt. Routing behavior is trained from a corpus of transcribed and hand-routed calls and then carried out using vector- based information retrieval techniques. Terms consist of n-gram sequences of morphologically reduced content words, while documents representing routing destinations consist of weighted term frequencies derived from calls to that destination in the training corpus. Based on the statistical discriminating power of the n-gram terms extracted from the caller's request, the caller is 1) routed to the appropriate destination, 2) transferred to a human operator, or 3) asked a disambiguation question. In the last case, the system dynamically generates queries tailored to the caller's request and the destinations with which it is consistent, based on our extension of the vector model. Evaluation of the call router performance over a financial services call center using both accurate transcriptions of calls and fairly noisy speech recognizer output demonstrated robustness in the face of speech recognition errors. More specifically, using accurate transcriptions of speech input, our system correctly routed 93.8% of the calls after redirecting 10.2% of all calls to a human operator. Using speech recognizer output with a 23% error rate reduced the number of correctly routed calls by 4%.
1. Introduction
The call routing task is one of directing a customer's call to an appropriate destination within a call center or directly providing some simple information, such as current loan rates, on the basis of some kind of interaction with the customer. In current systems, such interaction is typically carried out via a touch-tone system with a rigid predetermined navigational menu. The primary disadvantages of navigating menus for users are the time it takes to listen to all the options and the difficulty of matching their goals to the given options. These problems are compounded by the necessity of descending a nested hierarchy of choices to zero in on a particular activity. Even requests with simple English phrasings such as I want the balance on my car loan may require users to navigate as many as four or five nested menus with four or five options each. We describe an alternative to touch-tone menus that allows users to interact with a call router in natural spoken English dialogues just as they would with a h u m a n operator.
In a typical dialogue between a caller and a h u m a n operator, the operator responds to a caller request by either routing the call to an appropriate destination, or querying the caller for further information to determine where the call should be routed. Thus,
in developing an automatic call router, we select between these two options as well as a third option of sending the call to a human operator in situations where the router recognizes that to automatically handle the call is beyond its capabilities. The rest of this paper provides both a description and an evaluation of an automatic call router that consists of 1) a routing module driven by a novel application of vector-based information retrieval techniques, and 2) a disambiguation query generation module that utilizes the same vector representations as the routing module and dynamically generates queries tailored to the caller's request and the destinations with which it is consistent, based on our extension of the vector model. The overall call routing system has the following desirable characteristics: First, the training of the call router is domain independent and fully automatic, 1 allowing the system to be easily ported to new domains. Second, the disambiguation module dynamically generates queries based on caller requests and candidate destinations, allowing the system to tailor queries to specific circumstances. Third, the system is highly robust to speech recognition errors. Finally, the overall performance of the system is high, in particular when using noisy speech recognizer output. With transcription (perfect recognition), we redirect 10.2% of the calls to the operator, correctly routing 93.8% of the remainder either with or without disambiguation. With spoken input processed automatically with recognition performance at a 23% word error rate, the percentage of correctly routed calls drops by only 4%.
2. Related Work
Call routing is similar to text categorization in identifying which one of n topics (or in the case of call routing, destinations) most closely matches a caller's request. Call routing is distinguished from text categorization by requiring a single destination to be selected, but allowing a request to be refined in an interactive dialogue. The closest previous work to ours is Ittner, Lewis, and Ahn (1995), in which noisy documents produced by optical character recognition are classified against multiple categories. We are further interested in carrying out the routing process using natural, conversational language.
The only work on natural language call routing to date that we are aware of is that by Gorin and his colleagues (Gorin, Riccardi, and Wright 1997; Abella and Gorin 1997; Riccardi and Gorin 1998), who designed an automated system to route calls to AT&T operators. They select salient phrase fragments from caller requests (in response to the system's prompt of How may I help you ?), such as made a long distance and the area code for, and sometimes including phrases that are not meaningful syntactic or semantic units, such as it on my credit. These salient phrase fragments, which are incorporated into their finite-state language model for their speech recognizer, are then used to compute likely destinations, which they refer to as call types. This is done by either computing a posteriori probabilities for all possible call types (Gorin 1996) or by passing the weighted fragments through a neural network classifier (Wright, Gorin, and Riccardi 1997). Abella and Gorin (1997) utilized the Boolean formula minimization algorithm for combining the resulting set of call types based on a hand-coded hierarchy of call types. This algorithm provides the basis for determining whether or not the goal of the request can be uniquely identified, in order to select from a set of dialogue strategies for response generation.
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
250
200
150
100
50
0 llIlllilllIE~ItilllllTFIH~ ...
20 40 60 80 100 120
Number of Words in Initial User Ulterance
1200
1000
6OO
2OO
0 . . . .
2 4 6 8 10 12 14 18 18 Number of Conlent W o r d s in Initial User Ultersnce
[image:3.468.39.369.68.244.2](a) Total words Figure 1
Histogram of call lengths.
(b) Content words
3. Corpus Analysis
To e x a m i n e h u m a n - h u m a n d i a l o g u e behavior, w e a n a l y z e d a set of 4,497 t r a n s c r i b e d t e l e p h o n e calls i n v o l v i n g actual c u s t o m e r s interacting w i t h h u m a n call o p e r a t o r s at a large call center. In the v a s t m a j o r i t y of these calls, the first c u s t o m e r u t t e r a n c e c o n t a i n e d b e t w e e n 1 a n d 20 w o r d s , while the longest first utterance h a d 131 w o r d s . H o w e v e r , these utterances i n c l u d e d o n l y a f e w content w o r d s , 2 w i t h a l m o s t all calls containing f e w e r t h a n 10 content w o r d s in the initial u s e r utterance. Figures l(a) a n d l(b) s h o w h i s t o g r a m s of call lengths b a s e d on total w o r d s a n d content w o r d s in the initial user utterance in each call, respectively.
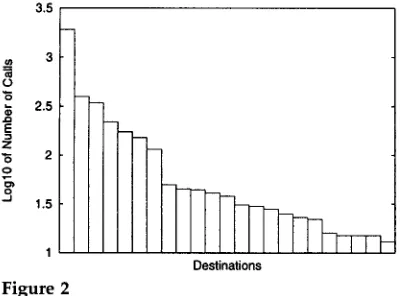
Figure 2 s h o w s the distribution of calls to the t o p 23 destinations on a log scale in o u r corpus. 3 The p e r p l e x i t y of a p r o b a b i l i t y distribution p r o v i d e s a m e a s u r e of the difficulty of classification of s a m p l e s d r a w n f r o m that distribution. U s i n g the e s t i m a t e of call distribution b a s e d on Figure 2, o u r task p e r p l e x i t y is 6.836. 4
We f u r t h e r a n a l y z e d o u r c o r p u s of calls a l o n g t w o dimensions: the s e m a n t i c s of caller requests a n d the d i a l o g u e actions for o p e r a t o r responses. The analysis of the semantics of caller requests is i n t e n d e d to e x a m i n e the w a y s in w h i c h users typically express their goal w h e n p r o m p t e d , a n d is u s e d to focus on an a p p r o p r i a t e subset of the classes of user utterances that the call r o u t e r s h o u l d h a n d l e a u t o m a t i c a l l y (as o p p o s e d to t r a n s f e r r i n g to a h u m a n operator). The analysis of the d i a l o g u e actions for o p e r a t o r responses, on the other h a n d , is i n t e n d e d to d e t e r m i n e the t y p e s of r e s p o n s e s the call r o u t e r s h o u l d be able to p r o v i d e in r e s p o n s e to user utterances in order to h e l p d e s i g n the r e s p o n s e g e n e r a t i o n c o m p o n e n t of the call router. The analysis of the c o r p u s a l o n g b o t h d i m e n s i o n s w a s p e r f o r m e d b y the first author.
3.1 Semantics of Caller Requests
In o u r corpus, all callers r e s p o n d to an initial o p e n - e n d e d p r o m p t of /ABC/ banking services call director; how may I direct your call? Their r e s p o n s e s v a r i e d greatly in their
2 Content words are keywords automatically extracted from the training corpus that are considered relevant for routing purposes. For details on how the list of content words is selected, see Section 4.1.2. 3 These are destinations that received more than 10 calls in the corpus we analyzed.
3.5
~ 3
o
1
m
o 2.5
T
' 5 2
. J
1.s
II ~
[image:4.468.52.252.66.214.2]Destinations
Figure 2
Distribution of calls.
degree of specificity. We roughly classified the calls into the following three broad classes:
Destination Name, in which the caller explicitly specifies the name of the department to which he wishes to be transferred. The requested destination can form an answer to the operator's prompt by itself, as in deposit services, or be part of a complete sentence, as in I would like to speak to someone in auto leasing please.
Activity, in which the caller provides a description of the activity he wishes to perform, and expects the operator to transfer his call to the appropriate department that handles the given activity. Such descriptions m a y be ambiguous or unambiguous, depending on the level of detail the caller provides, which in turn depends on the caller's understanding of the organization of the call center. Because all transactions related to savings accounts are handled by the deposit services department in the call center we studied, the request I want to talk to someone about savings accounts will be routed to Deposit Services. On the other hand, the similar request I want to talk to someone about car loans is ambiguous between Consumer Lending, which handles new car loans, and Loan Services, which handles existing car loans. Queries can also be
ambiguous due to the caller's providing more than one activity, as in I need to get m y checking account balance and then pay a car loan.
Indirect Request, in which the caller describes his goal in a roundabout way, often including irrelevant information. This typically occurs with callers who are unfamiliar with the call center organization, or those who have difficulty concisely describing their goals. An example of an actual indirect request is ah I'm calling "cuz ah a friend gave me this number and ah she told me ah with this number I can buy some cars or whatever but she didn't know how to explain it to me so I just called you you know to get that information.
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
Table 1
Semantic types of caller requests.
Destination Name Activity Indirect Request
# of calls 949 3271 277
% of all calls 21.1% 72.7% 6.2%
/
Table 2 ..-
Call operator dialogue actions.
Notification Query
NP Others
# of calls 3,608 657 232
% of all calls 80.2% 14.6% 5.2%
tinct destinations, 5 a n d each d e s t i n a t i o n o n l y h a n d l e s a fairly small n u m b e r (dozens to h u n d r e d s ) of activities, requests b a s e d o n d e s t i n a t i o n n a m e s a n d activities are ex- p e c t e d to b e m o r e p r e d i c t a b l e a n d thus m o r e suitable for h a n d l i n g b y a n a u t o m a t i c call router. H o w e v e r , o u r s y s t e m d o e s not directly classify calls in t e r m s of specificity; this classification w a s o n l y i n t e n d e d to p r o v i d e a sense of the distribution of calls received.
3.2 Dialogue Actions for Operator Responses
In a d d i t i o n to a n a l y z i n g h o w the callers p h r a s e d their requests in r e s p o n s e to the o p e r a t o r ' s initial p r o m p t , w e also a n a l y z e d h o w the o p e r a t o r s r e s p o n d e d to the callers' requests. 6 We f o u n d that in o u r corpus, the h u m a n o p e r a t o r either notifies the caller of a d e s t i n a t i o n to w h i c h the call will be transferred, or queries the caller for f u r t h e r i n f o r m a t i o n , m o s t f r e q u e n t l y w h e n the original r e q u e s t w a s a m b i g u o u s and, m u c h less often, w h e n the original r e q u e s t w a s not h e a r d or u n d e r s t o o d .
Table 2 s h o w s the f r e q u e n c y w i t h w h i c h e a c h d i a l o g u e action w a s e m p l o y e d b y h u m a n o p e r a t o r s in o u r corpus. It s h o w s that n e a r l y 20% of all caller requests require f u r t h e r d i s a m b i g u a t i o n . We f u r t h e r a n a l y z e d these calls that w e r e n o t i m m e d i a t e l y r o u t e d a n d n o t e d that 75% of t h e m i n v o l v e u n d e r s p e c i f i e d n o u n p h r a s e s , s u c h as re- questing car loans w i t h o u t specifying w h e t h e r it is a n existing car l o a n or a n e w car loan. The r e m a i n i n g 25% m o s t l y i n v o l v e u n d e r s p e c i f i e d v e r b p h r a s e s , s u c h as a s k i n g to transfer funds w i t h o u t specifying the accounts to a n d f r o m w h i c h the transfer will take place, or m i s s i n g v e r b p h r a s e s , s u c h as a s k i n g for direct deposit w i t h o u t specify- ing w h e t h e r the caller w a n t s to set u p a direct d e p o s i t or c h a n g e an existing direct deposit.
Based o n o u r analysis of o p e r a t o r responses, w e d e c i d e d to first focus o u r r o u t e r r e s p o n s e s o n n o t i f y i n g the caller of a selected d e s t i n a t i o n in cases w h e r e the caller r e q u e s t is u n a m b i g u o u s , a n d o n f o r m u l a t i n g a q u e r y for n o u n p h r a s e d i s a m b i g u a - tion in the case of n o u n p h r a s e u n d e r s p e c i f i c a t i o n in the caller request. For calls that
5 Although the call center had nearly 100 departments, in our corpus of 4,500 calls, only 23 departments received more than 10 calls. We chose to base our experiments on these 23 destinations.
Caller
Response
Disambiguating
Query
Caller
Request
-[ Routing Module I
-I
~
didate Destinations
Routing l~_~a~o,;#oOf o~X'-~ 0
Notification ~
I Disambiguation
ModuleI
ential
QueryYes
/ Ouerv ~ NoHuman
[image:6.468.51.301.62.309.2]~
Figure 3
Call router architecture.
d o n o t satisfy either criterion, the call r o u t e r s h o u l d s i m p l y relay t h e m to a h u m a n operator. 7
4. Vector-based Call Routing
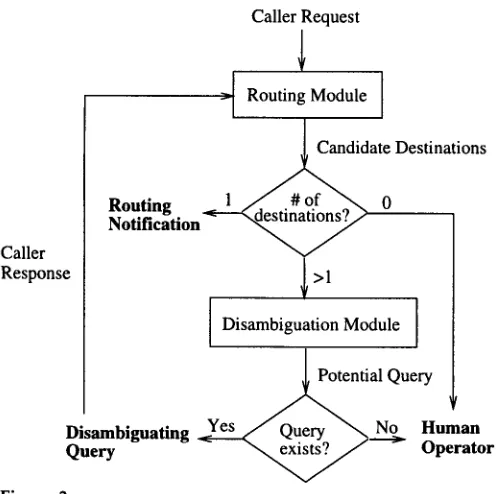
In a d d i t i o n to n o t i f y i n g the caller of a selected d e s t i n a t i o n or q u e r y i n g the caller for f u r t h e r i n f o r m a t i o n , an a u t o m a t i c call r o u t e r s h o u l d be able to identify w h e n it is u n a b l e to h a n d l e a call a n d route the call to a h u m a n o p e r a t o r for f u r t h e r processing. The p r o c e s s of d e t e r m i n i n g w h e t h e r to route a call, g e n e r a t e a d i s a m b i g u a t i o n query, or redirect the call to a n o p e r a t o r is carried o u t b y t w o m o d u l e s in o u r s y s t e m , the
routing
m o d u l e a n d thedisambiguation module,
as s h o w n in Figure 3. G i v e n a caller request, the r o u t i n g m o d u l e selects a set of c a n d i d a t e d e s t i n a t i o n s to w h i c h it believes the call can r e a s o n a b l y be routed. If there is exactly o n e s u c h destination, the call is r o u t e d to that d e s t i n a t i o n a n d the caller notified; if there is n o a p p r o p r i a t e destination, the call is sent to a n operator; a n d if there are m u l t i p l e c a n d i d a t e destinations, the dis- a m b i g u a t i o n m o d u l e is i n v o k e d . In the last case, the d i s a m b i g u a t i o n m o d u l e a t t e m p t s to f o r m u l a t e a q u e r y that it believes will solicit r e l e v a n t i n f o r m a t i o n f r o m the caller to allow the r e v i s e d r e q u e s t to be r o u t e d to a u n i q u e destination. If such a q u e r y is suc- cessfully f o r m u l a t e d , it is p o s e d to the caller, a n d the s y s t e m m a k e s a n o t h e r a t t e m p t at r o u t i n g the r e v i s e d request, w h i c h includes the original r e q u e s t a n d the caller's r e s p o n s e to the f o l l o w - u p question; otherwise, the call is sent to a h u m a n operator.7 Note that the corpus analysis described in this section was conducted with the purpose of determining guidelines for system design in order to achieve reasonable coverage of phenomena in actual
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
Credit Card Servio
O
0 •
Credit Card Fraud
o Bank
Hours
o Deposit Services
C:
I want the balance on
,,;/,o my car loan.
J
,
~
Loan Services~
Consumer Lending
[image:7.468.33.336.61.355.2]o ABA
Routing
Figure 4
Two-dimensional vector representation for the routing module.
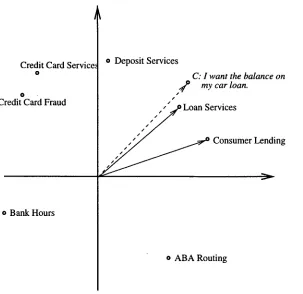
O u r a p p r o a c h to call routing is n o v e l in its application of vector-based informa- tion retrieval techniques to the routing process, a n d in its extension of the vector- based representation for d y n a m i c a l l y generating d i s a m b i g u a t i o n queries (Chu-Carroll a n d C a r p e n t e r 1998). The routing a n d d i s a m b i g u a t i o n m e c h a n i s m s are detailed in the following sections.
4.1 The Routing Module
4.1.1
Vector Representation for the Routing Module.
In vector-based i n f o r m a t i o n retrieval, the database contains a large collection of d o c u m e n t s , each of w h i c h is rep- resented as a vector in n-dimensional space. G i v e n a query, a q u e r y vector is c o m p u t e d a n d c o m p a r e d to the existing d o c u m e n t vectors, a n d those d o c u m e n t s w h o s e vectors aresimilar
to the q u e r y vector are returned. We a p p l y this technique to call routing b y treating each destination as a d o c u m e n t , and representing the destination as a vec- tor in n-dimensional space. G i v e n a caller request, an n-dimensional request vector is c o m p u t e d . The similarity b e t w e e n the request vector a n d each destination vector is then c o m p u t e d a n d those destinations that are close to the request vector are t h e n selected as the candidate destinations. This vector representation for destinations a n d q u e r y is illustrated in a simplified t w o - d i m e n s i o n a l space in Figure 4.Corpus of Transcribed & Routed Calls
Text for Filtered Text for
ABA Routing XNNN~ / ABA Routing
i Morphological "
Document Text for ~. I Filtering &
:,_ ] ~. Filtered Text for
Construction
Oep°s'* Svc / l g:Ff W:gd
Text for / ~k~x~NX Dep°sit SVCFiltered TextTouchline for Touchline
DocumentTerrn ~ Decomposition j L m x n ~ Term'D°cument
Vectors & Singular Value Term-Document Matrix
| Matrix Construction
Vectors
Figure 5
Training process for the routing module.
Term Extraction
/ SA~BAnR°T~tinrr~: f°r
~ _ _ Salient Terms for
x Salilnt Terms ~ Deposit Svc
for Touchline
unchanged. 8 Second, we must determine how a caller request will be m a p p e d to the same vector space for comparison with the destination vectors. Finally, we must de- cide h o w the similarity between the request vector and each destination vector will be measured in order to select candidate destinations.
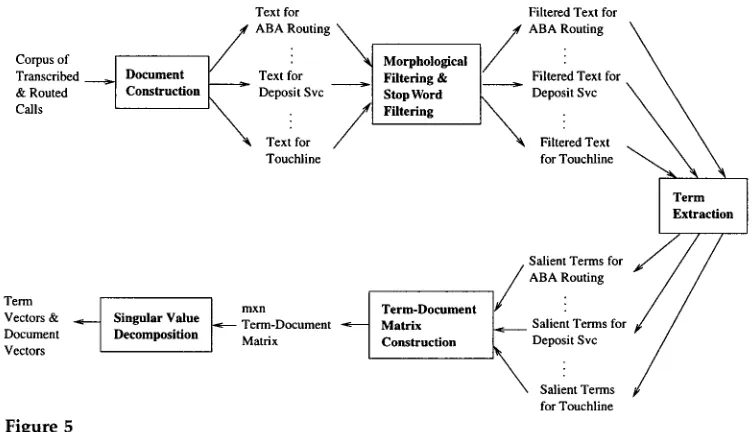
4.1.2 The Training Process. The goal of the training phase of the call router is to de- termine the values of the destination vectors (and term vectors) that will subsequently be used in the routing process. Our training process, depicted in Figure 5, requires a corpus of transcribed calls, each of which is routed to the appropriate destination. 9 These routed calls are processed by five domain-independent procedures to obtain the desired document (destination) and term vectors.
Document Construction. Since our goal is to represent each destination as an n-dimen- sional vector, we must create one (virtual) document per destination. The document for a destination contains the raw text of the callers' contributions in all calls routed to that destination, since these are the utterances that provided vital information for routing purposes. For instance, the document for deposit services m a y contain utterances such as I want to check the balance in my checking account and I would like to stop payment on a check. In our experiments, the corpus contains 3,753 calls routed to 23 destinations. 1°
8 One may consider allowing the call router to constantly update the destination vectors as new data are being collected while the system is deployed. We leave adding learning capabilities to the call router for future work.
9 The transcription process can be carried out by humans or by an automatic speech recognizer. In the experiments reported in this paper, we used human transcriptions.
[image:8.468.51.427.66.282.2]Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
Morphological Filtering and Stop Word Filtering. For r o u t i n g p u r p o s e s , w e are c o n c e r n e d w i t h the s e m a n t i c s of the w o r d s p r e s e n t in a d o c u m e n t , b u t n o t w i t h the m o r p h o l o g i c a l f o r m s of the w o r d s t h e m s e l v e s . T h u s w e filter each (virtual) d o c u m e n t , p r o d u c e d b y the d o c u m e n t construction process, t h r o u g h the m o r p h o l o g i c a l p r o c e s s o r of the Bell Labs Text-to-Speech s y n t h e s i z e r (Sproat 1998) to extract the root f o r m of e a c h w o r d in the corpus. This process will r e d u c e singulars, plurals, a n d g e r u n d s to their root forms, such as r e d u c i n g service, services, a n d servicing to the root service. Also, the v a r i o u s v e r b f o r m s are also r e d u c e d to their root forms, such as r e d u c i n g going, went, a n d gone to go. 11
Next, the root f o r m s of caller utterances are filtered t h r o u g h t w o lists, the i g n o r e list a n d the s t o p list, in o r d e r to b u i l d m o r e accurate n - g r a m t e r m m o d e l s for sub- s e q u e n t processing. The ignore list consists of noise w o r d s , w h i c h are c o m m o n in s p o n t a n e o u s s p e e c h a n d can be r e m o v e d w i t h o u t altering the m e a n i n g of a n utter- ance, s u c h as um a n d uh. These w o r d s s o m e t i m e s get in the w a y of p r o p e r n - g r a m extraction, as in I'd like to speak to someone about a car uh loan. W h e n the noise w o r d uh is filtered o u t of the utterance, w e can t h e n p r o p e r l y extract the b i g r a m car+loan. The stop list e n u m e r a t e s w o r d s that are u b i q u i t o u s a n d therefore do n o t contribute to d i s c r i m i n a t i n g b e t w e e n destinations, such as the, be, for, a n d morning. We m o d i f i e d the s t a n d a r d stop list d i s t r i b u t e d w i t h the SMART i n f o r m a t i o n retrieval s y s t e m (Salton 1971) to include domain-specific t e r m s a n d p r o p e r n a m e s that o c c u r r e d in o u r training corpus. 12 N o t e that w h e n a w o r d o n the ignore list is r e m o v e d f r o m a n utterance, it allows w o r d s p r e c e d i n g a n d s u c c e e d i n g the r e m o v e d w o r d to f o r m n - g r a m s , s u c h as car+loan in the e x a m p l e above. O n the other h a n d , w h e n a stop w o r d is r e m o v e d f r o m an utterance, a p l a c e h o l d e r is inserted into the u t t e r a n c e to p r e v e n t the w o r d s p r e c e d - ing a n d following the r e m o v e d stop w o r d f r o m f o r m i n g n - g r a m s . For instance, after stop w o r d filtering, the caller u t t e r a n c e I want to check on an account b e c o m e s (sw) (sw) (sw) check (sw) (sw) account, resulting in the t w o u n i g r a m s check a n d account. W i t h o u t the placeholders, w e w o u l d extract the b i g r a m check+account, just as if the caller h a d u s e d the t e r m checking account in the utterance.
In o u r e x p e r i m e n t s , the ignore list contains 25 w o r d s , w h i c h are v a r i a t i o n s of c o m m o n transcriptions of s p e e c h disfluencies, such as ah, aah, a n d ahh. The stop list contains o v e r 1,200 w o r d s , including function w o r d s , p r o p e r n a m e s , greetings, etc. Term Extraction. The o u t p u t of the filtering processes is a set of d o c u m e n t s , o n e for each destination, containing the root f o r m s of the content w o r d s extracted f r o m the r a w texts originally in each d o c u m e n t . In o r d e r to c a p t u r e w o r d co-occurrence, n - g r a m t e r m s are extracted f r o m the filtered texts. First, a list of n - g r a m t e r m s a n d their counts are g e n e r a t e d f r o m all filtered texts. T h r e s h o l d s are t h e n a p p l i e d to the n - g r a m c o u n t s to select as salient t e r m s those n - g r a m t e r m s that o c c u r r e d sufficiently frequently. Next, these salient t e r m s are u s e d to r e d u c e the filtered text for each d o c u m e n t to a b a g of salient terms, i.e., a collection of n - g r a m t e r m s a l o n g w i t h their respective counts. N o t e that w h e n a n n - g r a m t e r m is extracted, all of the l o w e r order k-grams, w h e r e 1 < k < n , are also extracted. For instance, the w o r d sequence checking account balance will result in the t r i g r a m check+account+balance, as well as the b i g r a m s check+account a n d account+balance a n d the u n i g r a m s check, account, a n d balance.
11 Not surprisingly, confusion among morphological variants was a source of substantial error from the recognizer. Details can be found in Reichl et al. (1998).
In o u r experiments, w e selected as salient terms u n i g r a m s that o c c u r r e d at least twice a n d bigrams a n d trigrams that o c c u r r e d at least three times. This resulted in 62 trigrams, 275 bigrams, a n d 420 unigrams. In o u r training corpus, no f o u r - g r a m occurred three times. M a n u a l e x a m i n a t i o n of these n-gram terms indicates that almost all of the selected salient terms are relevant for routing purposes. 13
Term-Document Matrix Construction.
Once the b a g of salient t e r m s for each destinationis constructed, it is v e r y s t r a i g h t f o r w a r d to construct an m x n t e r m - d o c u m e n t f r e q u e n c y matrix A, w h e r e m is the n u m b e r of salient terms, n is the n u m b e r of destinations, a n d an e l e m e n t
at,d
represents the n u m b e r of times the t e r m t o c c u r r e d in calls to destination d. This n u m b e r indicates the degree of association b e t w e e n t e r m t a n d destination d, a n d o u r u n d e r l y i n g a s s u m p t i o n is that if a t e r m o c c u r r e d f r e q u e n t l y in calls to a destination in o u r training corpus, t h e n occurrence of that t e r m in a caller's request indicates that the call s h o u l d be r o u t e d to that destination.In the t e r m - d o c u m e n t f r e q u e n c y matrix A, a r o w
At
is an n-dimensional vector representing the t e r m t, while a c o l u m n Ad is an m-dimensional vector r e p r e s e n t i n g the destination d. H o w e v e r , b y using the r a w f r e q u e n c y counts as the elements of the ma- trix, m o r e w e i g h t is given to terms that o c c u r r e d m o r e often in the training c o r p u s t h a n to those that occurred less frequently. For instance, a u n i g r a m t e r m such asaccount,
w h i c h occurs f r e q u e n t l y in calls to multiple destinations will h a v e greater f r e q u e n c y counts t h a n say, the t r i g r a m t e r m
social+security+number.
As a result, w h e n the t w o vectors representingaccount
a n dsocial+security+number
are combined, as will be d o n e in the r o u t i n g process, the t e r m vector foraccount
contributes m o r e to the c o m b i n e d vector t h a n that forsocial+security+number.
In o r d e r to balance the c o n t r i b u t i o n of each term, the t e r m - d o c u m e n t f r e q u e n c y matrix is n o r m a l i z e d so that each t e r m vector is of unit length (later w e i g h t i n g s do not p r e s e r v e this normalization, though). Let B be the result of n o r m a l i z i n g the t e r m - d o c u m e n t f r e q u e n c y matrix, w h o s e elements are given as follows:a t , d
Bt'd = iX-" A 2 "~1/2
\z--.,l<eKn t,eJ
O u r second w e i g h t i n g is b a s e d o n the n o t i o n that a t e r m that only occurs in a few d o c u m e n t s is m o r e i m p o r t a n t in routing t h a n a t e r m that occurs in m a n y d o c u m e n t s . For instance, the t e r m
stop+payment,
w h i c h o c c u r r e d only in calls to deposit services, s h o u l d be m o r e i m p o r t a n t in discriminating a m o n g destinations t h a ncheck,
w h i c h occurred in m a n y destinations. Thus, w e a d o p t e d the I n v e r s e - d o c u m e n t f r e q u e n c y (IDF) w e i g h t i n g s c h e m e (Sparck Jones 1972) w h e r e b y a t e r m is w e i g h t e d inversely to the n u m b e r of d o c u m e n t s in w h i c h it occurs. This score is given by:n
IDF(t)
= l o g 2d(t)
w h e r e t is a term, n is the n u m b e r of d o c u m e n t s in the corpus, a n d
d(t)
is the n u m b e r of d o c u m e n t s containing the t e r m t. If t only o c c u r r e d in one d o c u m e n t ,IDF(t)
= log 2 n; if t occurred in e v e r y d o c u m e n t ,IDF(t)
= log 2 1 -- 0. Thus, using this w e i g h t i n g scheme, terms that occur in e v e r y d o c u m e n t will be eliminated. 14 We w e i g h t the matrix B b y13 It w o u l d have b e e n possible to hand-edit the set of n - g r a m t e r m s at this p o i n t to r e m o v e u n w a n t e d terms. The results w e report in this p a p e r use the automatically selected t e r m s w i t h o u t any hand-editing.
14 To preserve all terms, w e could h a v e u s e d a c o m m o n variant of the IDF w e i g h t i n g w h e r e IDF(t) =
nq-e
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
m u l t i p l y i n g each r o w t b y
IDF(t)
to arrive at the m a t r i x C:Ct, d =
IDF(t)
• Bt,dSingular Value Decomposition and Vector Representation. In
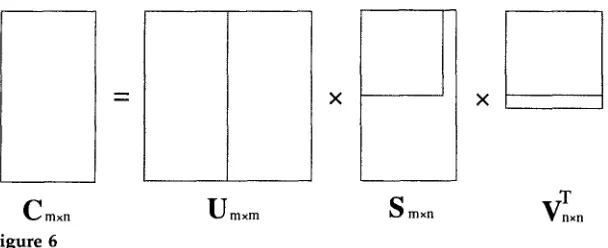
the w e i g h t e d t e r m - d o c u m e n tf r e q u e n c y m a t r i x C, t e r m s are r e p r e s e n t e d as n - d i m e n s i o n a l v e c t o r s (in o u r s y s t e m , n = 23), a n d destinations are r e p r e s e n t e d as m - d i m e n s i o n a l vectors (in o u r s y s t e m , m = 757). In o r d e r to p r o v i d e a u n i f o r m r e p r e s e n t a t i o n of t e r m a n d d o c u m e n t vectors a n d to r e d u c e the d i m e n s i o n a l i t y of the d o c u m e n t vectors, w e a p p l i e d the singular v a l u e d e c o m p o s i t i o n to the m x n m a t r i x C ( D e e r w e s t e r et al. 1990) to obtain: 15
C = U . S . V T,
w h e r e
.
2. 3.
U is a n m x m o r t h o n o r m a l matrix; V is an n x n o r t h o n o r m a l matrix; a n d
S is an m x n p o s i t i v e m a t r i x w h o s e n o n z e r o v a l u e s are Sl,1,..., Sr,r, w h e r e r is the r a n k of C, a n d t h e y are a r r a n g e d in d e s c e n d i n g o r d e r
S1,1 ~ S2,2 ~ ' ' ' ~ Sr, r ~ O.
Figure 6 illustrates the results of singular v a l u e d e c o m p o s i t i o n according to the a b o v e equation. The s h a d e d p o r t i o n s of the m a t r i c e s are w h a t w e u s e as the basis for o u r t e r m a n d d o c u m e n t v e c t o r representations, as follows:
.
.
.
Ur
is an m x r matrix, in w h i c h each r o w f o r m s the basis of o u r t e r m v e c t o r representation;Vr is a n n x r matrix, in w h i c h e a c h r o w f o r m s the basis of o u r d o c u m e n t vector representation; a n d
Sr
is an r x r p o s i t i v e d i a g o n a l m a t r i x w h o s e v a l u e s are u s e d for a p p r o p r i a t e scaling in the t e r m a n d d o c u m e n t v e c t o r representations.The actual r e p r e s e n t a t i o n s of the t e r m a n d d o c u m e n t v e c t o r s are
Ur
a n d VF scaled (or not) b y e l e m e n t s inSt,
d e p e n d i n g o n w h e t h e r the r e p r e s e n t a t i o n is i n t e n d e d for c o m p a r i s o n s b e t w e e n terms, b e t w e e n d o c u m e n t s , or b e t w e e n a t e r m a n d a d o c u - ment. For instance, since the similarity b e t w e e n t w o d o c u m e n t s can b e m e a s u r e d b y the d o t p r o d u c t b e t w e e n v e c t o r s r e p r e s e n t i n g the t w o d o c u m e n t s (Salton 1971), a n d C T • C contains the d o t p r o d u c t s of all p a i r w i s e c o l u m n v e c t o r s in the w e i g h t e d t e r m - d o c u m e n t f r e q u e n c y m a t r i x C, the similarity b e t w e e n the ith a n d j t h d o c u m e n t s canX X
[image:12.468.56.360.65.189.2]Cm×n Um×m Sm×n
Vnxn
TFigure 6
Singular value decomposition.
simply be recovered b y element ( C T • C)/j. Since U is orthonormal, S is a diagonal matrix, we have:
C T • C = ( U - S " vT) T" ( U ' S " V T) = V . S T . U T - U . S . V T
= V . S . S . V T
: ( V ' S ) " ( V ' S ) w
Because only the first r diagonal elements of S are nonzero, we have: (W. S). ( V . S) T = ( W r . Sr) . ( V r • Sr) T
The above equations suggest that scaling the vectors Vr with elements in Sr, i.e., repre- senting documents as row vectors in Vr'Sr, facilitates comparisons between documents. The same reasoning holds for representing terms as row vectors in Ur" Sr for compar- isons between terms, although in this particular application, we are not interested in term-term comparisons.
To measure the degree of association between a term and a document, we look up an element in the weighted term-document frequency matrix. Because S is a diagonal matrix with only the first r elements nonzero, we have:
C ~- U . S . V T = U - ( V - S ) w
= U r " ( V r ' S r ) w
Therefore, representing terms simply by row vectors in U r and documents by row
vectors in Vr'Sr allows us to make comparisons between documents, as well as between terms and documents.
4.1.3 Call Routing. As discussed earlier, two subprocesses need to be carried out during the call routing process. First, a p s e u d o d o c u m e n t vector must be constructed to represent the caller's request in order to facilitate the comparisons between the request and each document vector. Second, a method for comparison must be established to measure the similarity between the p s e u d o d o c u m e n t vector and the document vectors
i n V r • Sr, and a threshold must be determined to allow for the selection of candidate
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
Pseudodocument Generation. Given a caller utterance (either in text form from a key- board interface or as the output from an automatic speech recognizer), we first perform the morphological and stop word filtering and the term extraction procedures as in the training process to extract the relevant n-gram terms from the utterance. Since higher-level n-gram terms are, in general, better indicators of potential destinations, we further allow trigrams to contribute more to constructing the p s e u d o d o c u m e n t than bigrams, which in turn contribute more than unigrams. Thus we assign a weight w3 to trigrams, w2 to bigrams, and wl to unigrams, 16 and each extracted n-gram term is then weighted appropriately to create a bag of terms in which each extracted n-gram term occurs Wn times. As a result, w h e n we construct a p s e u d o d o c u m e n t from the bag of terms, we get the effect of weighting each n-gram term by Wn.
Given the extracted n-gram terms, we can present the request as an m x 1 vector Q where each element Qi i n the vector represents the number of times the ith term occurred in the bag of terms. The vector Q is then a d d e d as an additional column vector in our original weighted term-document frequency vector C, as shown in Figure 7, and we want to find the new corresponding column vector in V, Vq, that represents the pseudodocument in the reduced r-dimensional space. Since U is orthonormal and S is a diagonal matrix, we can solve for Vq by setting
Q - _ U . S . Vq T
Because we want a representation of the query in the document space, we transpose Q, to yield:
QT = Vq . S . U T
Finally, multiplying both sides on the right b y U, we have: QT . u = Vq . S . UT . U
= v q . s
Finally, note that for our query representation in the document space, we have QT. U ---- QT . Ur and Vq . S = Vq • Sr. Vq • Sr is a p s e u d o d o c u m e n t representation for the caller utterance in r-dimensional space, and is scaled appropriately for comparison between documents. This vector representation is simply obtained by multiplying QT and Ur, or equivalently, summing the vector representing each term in the bag of n-gram terms.
Candidate Destination Selection. Once the p s e u d o d o c u m e n t vector representing the caller request is computed, we measure the similarity between each document vector in VF' Sr and the p s e u d o d o c u m e n t vector. There are a n u m b e r of ways one may measure the similarity between two vectors, such as using the cosine score between the vectors, the Euclidean distance between the vectors, the Manhattan distance between the vectors, etc. We follow the standard technique adopted in the information retrieval community and select the cosine score as the basis for our similarity measure. The cosine score between two n-dimensional vectors x and y is given as follows:
cos(x, y) = x . yT
V / E l ( i K n x2 " ~--~X(i(n y2
× X
C m×(n+l) U m×r
Figure 7
Pseudodocument generation.
.T
S r:~r V(n+l)×r
Using cosine reduces the contribution of each vector to its angle by normalizing for length. Thus the key in maximizing cosine between two vectors is to have them point in the same direction. However, although the raw vector cosine scores give some indi- cation of the closeness of a request to a destination, we noted that the absolute value of such closeness does not translate directly into the likelihood for correct routing. Instead, some destinations m a y require a higher cosine value, i.e., a closer degree of similarity, than others in order for a request to be correctly associated with those des- tinations. We applied the technique of logistic regression (see Lewis and Gale [1994]) in order to transform the cosine score for each destination using a sigmoid function specifically fitted for that destination. This allows us to obtain a score that represents the router's confidence that the call should be routed to that destination.
From each call in the training data, we generate, for each destination, a cosine value/routing value pair, where the cosine value is that between the destination vec- tor and the request vector, and the routing value is 1 if the call was routed to that destination in the training data and 0 otherwise. Thus, for each destination, we have a set of cosine value/routing value pairs equal to the number of calls in the training data. The subset of these value pairs whose routing value is I will be equal to the number of calls routed to that destination in the training set. Then, we used least squared error to fit a sigmoid function, 1/(1 + e-(ax+b)), to the set of cosine value/routing value pairs. 17
A s s u m i n g
da
anddb
are the coefficients of the fitted sigmoid function for destinationd, we have the following confidence function for a destination d and cosine value x:
Conf(da, db, x) = 1/(1 + e -(dax+db))
Thus the score given a request and a destination, where d is the vector corresponding to destination d, and r is the vector corresponding to the request is
Conf(da, db,
cos(r, d)). To obtain a preliminary evaluation of the effectiveness of cosine vs. confidence scores, we tested routing performance on transcriptions of 307 unseen unambiguous requests. In each case, we selected the destination with the highest cosine/confidence score to be the target destination. Using raw cosine scores, 92.2% of the calls are routed to the correct destination. On the other hand, using sigmoid confidence fitting, 93.5% of the calls are correctly routed. This yields an error reduction rate of 16.7%, illustrating the advantage of transforming the raw cosine scores to more uniform confidence scores that allow for more accurate comparisons between destinations. [image:14.468.55.332.62.199.2]Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
.3
6
I
0 . 8
0 . 6
0 . 4
0 . 2
U p p e r b o u n d : 0 ' ' ' ' ' ' L ° w c ' r b ° u n d b ' ~
[image:15.468.36.236.66.204.2]0 0.1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 T h r e s h o l d
Figure 8
Router performance vs. confidence threshold.
We can c o m p u t e the k a p p a statistic for the p u r e routing c o m p o n e n t of o u r sys- t e m using the accuracies given above. 18 Recall that k a p p a is defined b y (a - e ) / ( 1 - e ) w h e r e a is the system's accuracy a n d e is the e x p e c t e d a g r e e m e n t b y chance. Select- ing destinations from the prior distribution a n d guessing destinations using the same distribution leads to a chance p e r f o r m a n c e of e = Y~a P(d) 2 = 0.2858 w h e r e the s u m m a - tion is o v e r all destinations d a n d P(d) is the percentage of calls r o u t e d to destination d. The resulting k a p p a score is (0.935 - 0.2858)/(1 - 0.2858) = 0.909.
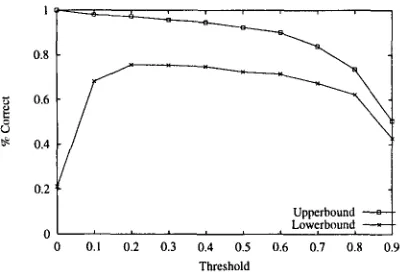
Once w e h a v e obtained a confidence v a l u e for each destination, the final step in the r o u t i n g process is to c o m p a r e the confidence values to a p r e d e t e r m i n e d threshold a n d r e t u r n those destinations w h o s e confidence values are greater t h a n the threshold as candidate destinations. To d e t e r m i n e the optimal v a l u e for this threshold, w e ran a series of e x p e r i m e n t s to c o m p u t e the u p p e r b o u n d a n d l o w e r b o u n d of the r o u t e r ' s p e r f o r m a n c e b y v a r y i n g the threshold from 0 to 0.9 at 0.1 intervals. The l o w e r b o u n d represents the percentage of calls that are r o u t e d correctly, while the u p p e r b o u n d indicates that percentage of calls that have the potential to be r o u t e d correctly after d i s a m b i g u a t i o n (see Section 5 for details o n u p p e r b o u n d a n d l o w e r b o u n d measures). Figure 8 illustrates the results of this set of e x p e r i m e n t s a n d shows that a threshold of 0.2 yields optimal performance. Thus w e a d o p t 0.2 as o u r confidence threshold for selecting candidate destinations in the rest of o u r discussion.
4.1.4 Call R o u t i n g Example. To illustrate the call routing process w i t h an example, s u p p o s e the caller r e s p o n d s to the o p e r a t o r ' s p r o m p t w i t h I am calling to apply for a new car loan. First the caller's utterance is p a s s e d t h r o u g h m o r p h o l o g i c a l filtering to obtain the root f o r m s of the w o r d s in the utterance, resulting in I am call to apply for a new car loan. Next, w o r d s on the stop list are r e m o v e d a n d replaced w i t h a placeholder, resulting in (sw I (sw I call (sw I apply (sw I (sw I new car loan. F r o m the filtered "utter- ance, the router extracts the salient n-gram terms to f o r m a bag of t e r m s as follows: new+car+loan, new+car, car+loan, call, apply, new, car, a n d loan. A request vector is t h e n c o m p u t e d b y taking the w e i g h t e d s u m of the t e r m vectors representing the salient n-gram terms, a n d the cosine v a l u e b e t w e e n this request vector a n d each destination vector is c o m p u t e d . The cosine value for each destination is s u b s e q u e n t l y t r a n s f o r m e d
1. C o n s u m e r Lending 0.979
2. Loan Services 0.260
3. Home Loans 0.077
4. Collateral Control 0.069
5. O p e r a t o r 0.038
[image:16.468.46.368.72.326.2] [image:16.468.50.299.168.329.2](a) Cosine Scores Figure 9
Ranking of candidate destinations.
1. C o n s u m e r Lending 0.913
2. Deposit Services 0.070
3. P C B a n k i n g 0.049
4. Loan Services 0.035
5. A u t o Leasing 0.032
(b) Confidence Scores
L ° a n ~ c : Car loans please.
~
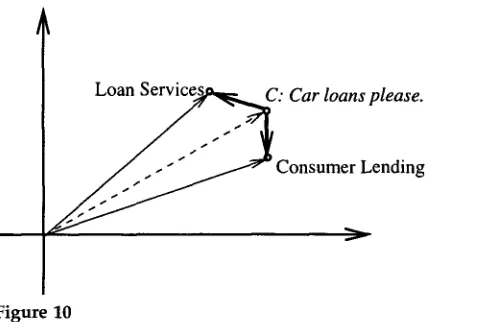
Consumer LendingFigure 10
Two-dimensional vector representation for the disambiguation module.
using the destination-specific sigmoid function to obtain a confidence score for each destination. Figures 9(a) and 9(b) show the cosine scores and the confidence scores for the top five destinations, respectively. Given a confidence threshold of 0.2, the only candidate destination selected is Consumer Lending. Thus, the caller's request is routed unambiguously to that destination.
4.2 The Disambiguation Module
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
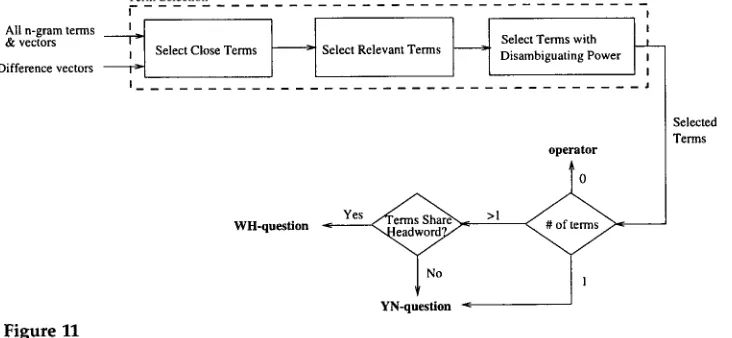
All n - g r a m terms & vectors Difference vectors
T e r m Selection
Ii Select T e r m s w i t h Select C l o s e T e r m s :' Select Relevant T e r m s D i s a m b i g u a t i n g P o w e r
I . . . .i
WH-question
Figure 11
The disambiguation process.
• : Yes
YN-question c
operator
0
1
Selected
T e r m s
4.2.2 Q u e r y Formulation. O u r d i s a m b i g u a t i o n m o d u l e selects a subset of the salient n - g r a m t e r m s f r o m w h i c h the q u e r y will b e generated. The subset of n - g r a m t e r m s are those related to the original q u e r y that can likely b e u s e d to d i s a m b i g u a t e a m o n g the c a n d i d a t e destinations. T h e y are c h o s e n b y filtering all n - g r a m t e r m s b a s e d o n the following three criteria, as s h o w n in Figure 11:
C l o s e n e s s Since the goal of the d i s a m b i g u a t i o n process is to solicit t e r m s w h o s e c o r r e s p o n d i n g v e c t o r s are close to the difference vectors, the first step in the t e r m selection process is to c o m p a r e each n - g r a m t e r m v e c t o r w i t h the difference v e c t o r s a n d select those n - g r a m t e r m v e c t o r s that are close to the difference v e c t o r s b y the cosine m e a s u r e . Since b o t h the d e s t i n a t i o n v e c t o r s a n d the r e q u e s t vector are scaled for
d o c u m e n t - d o c u m e n t c o m p a r i s o n in Vr • Sr space, the difference v e c t o r s are also r e p r e s e n t e d in Vr • SF space. As discussed in Section 4.1.2, d o c u m e n t s r e p r e s e n t e d in Vr • Sr space are suitable for c o m p a r i s o n w i t h t e r m s r e p r e s e n t e d in Ur space. In o u r system, for each difference vector, w e c o m p u t e the cosine score b e t w e e n the difference v e c t o r a n d each t e r m vector, a n d select the 30 t e r m s w i t h the h i g h e s t cosine scores as the set of close terms. The r e a s o n s for selecting a t h r e s h o l d on the n u m b e r of t e r m s instead of o n the cosine score are twofold. First, in situations w h e r e m a n y t e r m vectors are close to the difference vector, w e a v o i d g e n e r a t i n g an o v e r l y large set of close t e r m s b u t instead focus on a smaller set of m o s t p r o m i s i n g terms. Second, in situations w h e r e f e w t e r m v e c t o r s are close to the difference vector, w e still select a set of close t e r m s in the h o p e that t h e y m a y contribute to f o r m u l a t i n g a r e a s o n a b l e query, instead of giving u p o n the d i s a m b i g u a t i o n p r o c e s s outright.
[image:17.468.33.399.67.236.2]r e l e v a n t t e r m new+car+loan. This m e c h a n i s m for selecting r e l e v a n t t e r m s allows us to focus o n selecting n - g r a m t e r m s for n o u n p h r a s e
d i s a m b i g u a t i o n b y e l i m i n a t i n g close t e r m s that are s e m a n t i c a l l y related to u n d e r s p e c i f i e d n - g r a m n o u n p h r a s e s in the original r e q u e s t b u t d o n o t contribute to f u r t h e r d i s a m b i g u a t i n g the n o u n phrases.
D i s a m b i g u a t i n g p o w e r The final criterion that w e u s e for t e r m selection is to restrict attention to r e l e v a n t t e r m s that c a n b e a d d e d to the original r e q u e s t to result in a n u n a m b i g u o u s r o u t i n g decision u s i n g the r o u t i n g m e c h a n i s m described in Section 4.1.3. In other w o r d s , w e a u g m e n t the b a g of n - g r a m t e r m s extracted f r o m the original r e q u e s t w i t h e a c h r e l e v a n t term, a n d the r o u t i n g m o d u l e is i n v o k e d to d e t e r m i n e if this a u g m e n t e d set of n - g r a m t e r m s can be u n a m b i g u o u s l y r o u t e d to a u n i q u e destination. The set of r e l e v a n t t e r m s w i t h d i s a m b i g u a t i n g p o w e r t h e n f o r m s the set of selected t e r m s f r o m w h i c h the s y s t e m ' s q u e r y will b e f o r m u l a t e d . If n o n e of the r e l e v a n t t e r m s satisfy this criterion, t h e n w e include all r e l e v a n t terms. Thus, instead of giving u p the d i s a m b i g u a t i o n p r o c e s s w h e n no o n e t e r m is p r e d i c t e d to resolve the ambiguity, the s y s t e m p o s e s a q u e s t i o n to solicit i n f o r m a t i o n f r o m the caller to m o v e the original r e q u e s t one step t o w a r d b e i n g a n u n a m b i g u o u s request. After the first d i s a m b i g u a t i o n q u e r y is a n s w e r e d , the s y s t e m
s u b s e q u e n t l y selects a n e w set of t e r m s f r o m the refined, t h o u g h still a m b i g u o u s , r e q u e s t a n d f o r m u l a t e s a f o l l o w - u p d i s a m b i g u a t i o n q u e r y . 19
The result of this selection p r o c e s s is a finite set of t e r m s that are r e l e v a n t to the original a m b i g u o u s r e q u e s t and, w h e n a d d e d to it, are likely to resolve the ambiguity. The actual q u e r y is f o r m u l a t e d b a s e d o n the n u m b e r of t e r m s in this set as well as features of the selected terms. As s h o w n in Figure 11, if the three selection criteria r u l e d o u t all n - g r a m terms, t h e n the call is sent to a h u m a n o p e r a t o r for f u r t h e r processing. If there is o n l y one selected term, t h e n a yes-no q u e s t i o n is f o r m u l a t e d b a s e d o n this term. If there is m o r e t h a n o n e selected t e r m in the set, a n d a significant n u m b e r of these t e r m s share a c o m m o n h e a d w o r d , 2° X, the s y s t e m generalizes the q u e r y to a s k the wh-question For what type of X? O t h e r w i s e , a yes-no q u e s t i o n is f o r m e d b a s e d on the t e r m in the selected set that o c c u r r e d m o s t f r e q u e n t l y in the training data, b a s e d on the heuristic that a m o r e c o m m o n t e r m is m o r e likely to be r e l e v a n t t h a n a n o b s c u r e term. 21 A third alternative w o u l d be to a s k a disjunctive question, b u t w e h a v e n o t y e t e x p l o r e d this possibility. Figure 3 s h o w s that after the s y s t e m p o s e s its query, it a t t e m p t s to r o u t e the refined request, w h i c h is the caller's original r e q u e s t p l u s the r e s p o n s e to the d i s a m b i g u a t i o n q u e r y p o s e d b y the s y s t e m . In the case of wh- questions, n - g r a m t e r m s are extracted f r o m the response. For instance, if the s y s t e m asks For what type of loan? a n d the user r e s p o n d s It's a car loan, t h e n the b i g r a m car+loan
19 Although it captures a similar property of each term, this criterion is computationally much more expensive than the closeness criterion. Thus, we adopt the closeness criterion to select a fixed number of candidate terms and then apply the more expensive, but more accurate, criterion to the much smaller set of candidate terms.
20 In our implemented system, this path is selected if 1) there are five or less selected terms and they all share a common headword, or 2) there are more than five terms and at least five of them share a common headword.
Chu-Carroll and Carpenter Vector-based Natural Language Call Routing
is extracted f r o m the response. In the case of yes-no questions, the s y s t e m d e t e r m i n e s w h e t h e r a yes or no a n s w e r is given. 22 In the case of a yes response, the t e r m selected to f o r m u l a t e the d i s a m b i g u a t i o n q u e r y is c o n s i d e r e d the caller's response, w h i l e in the case of a no response, the r e s p o n s e is t r e a t e d as in r e s p o n s e s to wh-questions. For instance, if the u s e r says yes in r e s p o n s e to the s y s t e m ' s q u e r y Is this an existing car loan?, t h e n the t r i g r a m t e r m exist+car+loan in the s y s t e m ' s q u e r y is c o n s i d e r e d the u s e r ' s response.
N o t e that o u r d i s a m b i g u a t i o n m e c h a n i s m , like o u r training process for basic rout- ing, is d o m a i n - i n d e p e n d e n t (except for the m a n u a l construction of a m a p p i n g b e t w e e n n - g r a m n o u n p h r a s e s a n d their e x p a n d e d forms). It utilizes the set of n - g r a m terms, as well as t e r m a n d d o c u m e n t vectors that w e r e o b t a i n e d b y the training of the call router. Thus, the call r o u t e r can be p o r t e d to a n e w task w i t h o n l y v e r y m i n o r d o m a i n - s p e c i f i c w o r k on the d i s a m b i g u a t i o n m o d u l e .
4.2.3
Disambiguation Example.
To illustrate the d i s a m b i g u a t i o n m o d u l e of o u r call router, consider the r e q u e s t Loans please. This r e q u e s t is a m b i g u o u s b e c a u s e the call center w e s t u d i e d h a n d l e s m o r t g a g e loans s e p a r a t e l y f r o m all other t y p e s of loans, a n d for all other loans, existing loans a n d n e w loans are also h a n d l e d b y different d e p a r t m e n t s .G i v e n this request, the call r o u t e r first p e r f o r m s m o r p h o l o g i c a l , ignore w o r d , a n d stop w o r d filterings on the input, resulting in the filtered utterance of loan Iswl. N- g r a m t e r m s are t h e n extracted f r o m the filtered utterance, resulting in the u n i g r a m t e r m loan. Next, the router c o m p u t e s a p s e u d o d o c u m e n t vector that r e p r e s e n t s the caller's request, w h i c h is c o m p a r e d in t u r n w i t h the d e s t i n a t i o n vectors. The cosine v a l u e s b e t w e e n the request v e c t o r a n d each d e s t i n a t i o n vector are t h e n m a p p e d into confidence values. U s i n g a confidence threshold of 0.2, w e h a v e t w o c a n d i d a t e des- tinations, L o a n Services a n d C o n s u m e r Lending; thus the d i s a m b i g u a t i o n m o d u l e is i n v o k e d .
O u r d i s a m b i g u a t i o n m o d u l e first selects f r o m all n - g r a m t e r m s those w h o s e t e r m vectors are close to the difference vectors, i.e., the differences b e t w e e n each c a n d i d a t e d e s t i n a t i o n vector a n d the r e q u e s t vector. This results in a list of 60 close terms, the v a s t m a j o r i t y of w h i c h are s e m a n t i c a l l y close to loan, s u c h as auto+loan, payoff, a n d owe. Next, the r e l e v a n t t e r m s are c o n s t r u c t e d f r o m the set of close t e r m s b y selecting those close t e r m s that f o r m a valid n - g r a m t e r m w i t h loan. This results in a list of 27 r e l e v a n t terms, including auto+loan a n d loan+payoff, b u t e x c l u d i n g owe, since neither loan+owe n o r owe+loan constitutes a valid b i g r a m . The third step is to select those r e l e v a n t t e r m s w i t h d i s a m b i g u a t i n g p o w e r , resulting in 18 d i s a m b i g u a t i n g terms. Since 11 of these t e r m s share a h e a d n o u n loan, a wh-question is g e n e r a t e d b a s e d o n this h e a d w o r d , resulting in the q u e r y For what type of loan?
S u p p o s e in r e s p o n s e to the s y s t e m ' s query, the u s e r a n s w e r s Car loan. The r o u t e r t h e n a d d s the n e w b i g r a m car+loan a n d the t w o u n i g r a m s car a n d loan to the orig- inal r e q u e s t a n d a t t e m p t s to route the refined request. This refined r e q u e s t is a g a i n a m b i g u o u s b e t w e e n L o a n Services a n d C o n s u m e r L e n d i n g b e c a u s e the caller d i d n o t specify w h e t h e r it w a s a n existing or n e w car loan. Again, the d i s a m b i g u a t i o n m o d u l e selects the close, relevant, a n d d i s a m b i g u a t i n g terms, resulting in a u n i q u e t r i g r a m exist+car+loan. Thus, the s y s t e m g e n e r a t e s the yes-no q u e s t i o n Is this about an existing
car loan? 23 If the user r e s p o n d s yes, t h e n the t r i g r a m exist+car+loan is a d d e d to the refined r e q u e s t a n d the call u n a m b i g u o u s l y r o u t e d to L o a n Services; if the user says
N o , it's a n e w car loan, t h e n the t r i g r a m new+car+loan is extracted f r o m the r e s p o n s e a n d
the call r o u t e d to C o n s u m e r Lending. 24
5. Evaluation of the Call Router
5.1 Routing Module Performance
We p e r f o r m e d a n e v a l u a t i o n of the r o u t i n g m o d u l e of o u r call r o u t e r o n a set of 389 calls disjoint f r o m the training corpus. O f the 389 requests, 307 w e r e u n a m b i g u o u s a n d r o u t e d to their correct destinations, a n d 82 w e r e a m b i g u o u s a n d a n n o t a t e d w i t h a list of p o t e n t i a l destinations. Unfortunately, in this test set, o n l y the caller's u t t e r a n c e in r e s p o n s e to the s y s t e m ' s initial p r o m p t of H o w m a y I direct y o u r call? w a s r e c o r d e d a n d transcribed; t h u s w e h a v e n o i n f o r m a t i o n a b o u t w h e r e the a m b i g u o u s calls s h o u l d be r o u t e d after d i s a m b i g u a t i o n . We e v a l u a t e d the r o u t i n g m o d u l e p e r f o r m a n c e on b o t h t r a n s c r i p t i o n s of caller u t t e r a n c e s as well as o u t p u t of the Bell Labs A u t o m a t i c Speech Recognizer (Reichl et al. 1998) b a s e d o n s p e e c h i n p u t of caller u t t e r a n c e s ( C a r p e n t e r a n d C h u - C a r r o l l 1998).
5.1.1 T e r m Extraction Performance. Since the v e c t o r r e p r e s e n t a t i o n for caller requests is c o m p u t e d b a s e d on the t e r m v e c t o r s r e p r e s e n t i n g the n - g r a m t e r m s extracted f r o m the requests, the p e r f o r m a n c e of o u r call r o u t e r is directly tied to the the a c c u r a c y of t e r m s extracted f r o m e a c h caller utterance. G i v e n the set of n - g r a m t e r m s o b t a i n e d f r o m the training process, the a c c u r a c y of extraction of s u c h t e r m s b a s e d on t r a n s c r i p t i o n s of caller utterances is 100%. H o w e v e r , w h e n u s i n g the o u t p u t of a n a u t o m a t i c s p e e c h recognizer as i n p u t to o u r call router, deletions of t e r m s p r e s e n t in the c a l l e r ' s r e q u e s t as well as insertions of t e r m s that d i d n o t occur in the r e q u e s t affect the t e r m extraction a c c u r a c y a n d thus the r o u t i n g p e r f o r m a n c e .
We e v a l u a t e d the o u t p u t of the a u t o m a t i c s p e e c h recognizer b a s e d on b o t h w o r d a c c u r a c y a n d t e r m accuracy, as s h o w n in Table 3. 25 W o r d a c c u r a c y is m e a s u r e d b y taking into a c c o u n t all w o r d s in the transcript a n d in the r e c o g n i z e d string. T w o sets of results are g i v e n for w o r d accuracy, one b a s e d o n r a w f o r m s of w o r d s a n d the other b a s e d on c o m p a r i s o n s of the root f o r m s of w o r d s , i.e., after b o t h the t r a n s c r i p t a n d the r e c o g n i z e d string are sent t h r o u g h the m o r p h o l o g i c a l filter. T e r m a c c u r a c y is m e a s u r e d b y taking into a c c o u n t o n l y the set of a c t u a l / r e c o g n i z e d w o r d s t h a t c o n t r i b u t e to r o u t i n g p e r f o r m a n c e , i.e., after b o t h the t r a n s c r i p t a n d the r e c o g n i z e d string are sent t h r o u g h the t e r m extraction process.
For e a c h e v a l u a t i o n d i m e n s i o n , w e m e a s u r e d the recognizer p e r f o r m a n c e b y calcu- lating the precision a n d recall. Precision is the p e r c e n t a g e of w o r d s / t e r m s in the recog- nizer o u t p u t that are actually in the transcription, i.e., p e r c e n t a g e of f o u n d w o r d s / t e r m s
23 Recall that our current system uses simple template filling for response generation by utilizing manually constructed mappings from n-gram terms to their inflected forms, such as from exist+car+loan
to an existing car loan.
24 The current implementation of the system requires that the user specify the correct answer when providing a no answer to a yes-no question, in order for the call to be properly disambiguated. However, it is possible that a system may attempt to disambiguate given a simple no answer by considering the n-gram term being queried (exist+car+loan in the above example) as a negative feature, subtracting its vector representation from the query, and attempting to route the resulting vector representation. 25 In computing the precision and recall figures, we did not take into account multiple occurrences of the