On the Limitations of Unsupervised Bilingual Dictionary Induction
Full text
Figure

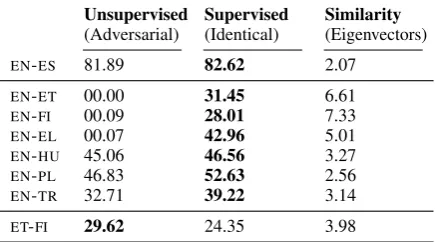
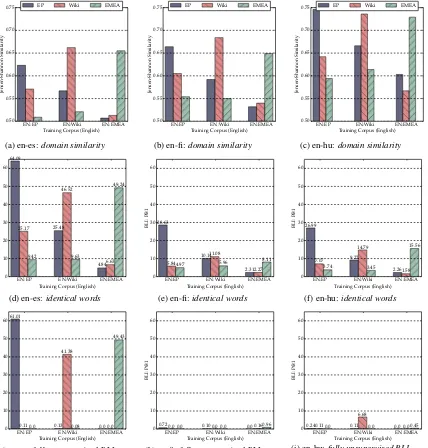
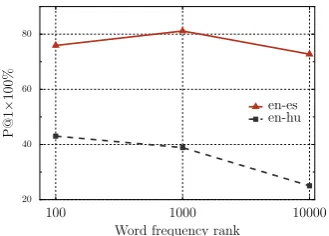
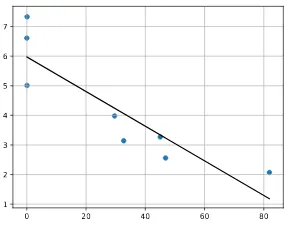
Related documents
We believe that great ideas drive investment performance, and through their rigorous investment approach, the multi asset team ensures that every idea in the fund has earned
-depth average soil mobility (I)Determine early work during and at the end of the work and the determination is made at several points (minimum 20), length of 100m with
Too often, NGOs lament that they could do much more with $1m over three years for a consistent and reliable water and sanitation programme, as compared with $25m that has to be
The anatomy, palynology, morphology and distribution of the trichomes on the aerial parts of Salvia chrysophylla Stapf, an endemic species in Turkey, were studied in order to
หมวด 5 ข้อเสนอแนะจากการด าเนินการปี 2555 สิ่งที่ขอร ับการสน ับสนุนผู้บริหารระด ับสูง • คณะท างานเป็นระด ับปฏิบ ัติการไม่สามารถ ก าหนดทิศทางการพ ัฒนาบุคลากร และ
Those Marines who did serve ashore, did so either as part of ships’ landing forces or when directly assigned to assist the Union Army.. The senior officers of the Corps
Commission’s Safeguards Rule, the Commission has engaged in a broad educational campaign to educate businesses and consumers about the importance of information security and
This is a list of current service addresses for recycling front-end containers, including the number of front-end containers at each location.. The list is for information and
