Contents lists available atScienceDirect
International
Journal
of
Approximate
Reasoning
www.elsevier.com/locate/ijar
Probabilistic
abductive
logic
programming
using
Dirichlet
priors
Calin
Rares Turliuc
a,∗
,
Luke Dickens
b,
Alessandra Russo
a,
Krysia Broda
aaDepartmentofComputing,ImperialCollegeLondon,UnitedKingdom bDepartmentofInformationStudies,UniversityCollegeLondon,UnitedKingdom
a
r
t
i
c
l
e
i
n
f
o
a
b
s
t
r
a
c
t
Articlehistory:
Received22January2016
Receivedinrevisedform4June2016 Accepted1July2016
Availableonline15July2016 Keywords:
Probabilisticprogramming Abductivelogicprogramming MarkovChainMonteCarlo LatentDirichletallocation Repeatedinsertionmodel
Probabilistic programming is an area of research that aims to develop general inference algorithms for probabilistic models expressed as probabilistic programs whose execution corresponds to inferring the parameters of those models. In this paper, we introduce a probabilistic programming language (PPL) based on abductive logic programming for performing inference in probabilistic models involving categorical distributions with Dirichlet priors. We encode these models as abductive logic programs enriched with probabilistic definitions and queries, and show how to execute and compile them to boolean formulas. Using the latter, we perform generalized inference using one of two proposed Markov Chain Monte Carlo (MCMC) sampling algorithms: an adaptation of uncollapsed Gibbs sampling from related work and a novel collapsed Gibbs sampling (CGS). We show that CGS converges faster than the uncollapsed version on a latent Dirichlet allocation (LDA) task using synthetic data. On similar data, we compare our PPL with LDA-specific algorithms and other PPLs. We find that all methods, except one, perform similarly and that the more expressive the PPL, the slower it is. We illustrate applications of our PPL on real data in two variants of LDA models (Seed and Cluster LDA), and in the repeated insertion model (RIM). In the latter, our PPL yields similar conclusions to inference with EM for Mallows models.
©2016 The Author(s). Published by Elsevier Inc. This is an open access article under the CC BY license (http://creativecommons.org/licenses/by/4.0/).
1. Introduction
Probabilisticprogrammingisanareaofresearchthataimstodevelopgeneralinferencealgorithmsforprobabilistic mod-elsexpressedasprobabilisticprogramswhoseexecutioncorrespondstoinferringtheparametersoftheprobabilisticmodel. Awide rangeofprobabilisticprogramminglanguages(PPLs)havebeendevelopedtoexpressa varietyofclassesof prob-abilisticmodels.ExamplesofPPLsincludeChurch[1],Anglican[2],BUGS [3],Stan[4]andFigaro[5].1 SomePPLs,suchas Church,enrichafunctionalprogramminglanguage withexchangeablerandomprimitives,andcantypicallyexpressawide rangeofprobabilisticmodels.However,inferenceisnotalwaystractableintheseexpressivelanguages.OtherPPLsare logic-based.Theytypicallyaddprobabilistic annotationsorprimitivestoalogicalencoding ofthemodel.Thisencoding usually relates eitherto first-orderlogic, e.g. Alchemy[6], BLOG [7]or to logic programming, e.g. PRiSM [8], ProbLog [9]. Most
*
Correspondingauthor.E-mailaddress:[email protected](C.R. Turliuc).
1 Foramorecomprehensivelistcf.http://probabilistic-programming.org/. http://dx.doi.org/10.1016/j.ijar.2016.07.001
0888-613X/©2016TheAuthor(s).PublishedbyElsevierInc.ThisisanopenaccessarticleundertheCCBYlicense (http://creativecommons.org/licenses/by/4.0/).
logic-basedPPLsfocusonlyondiscretemodels,andconsequentlyareequippedwithmorespecializedinferencealgorithms, withtheadvantageofmakingtheinferencemoretractable.
However, logic-basedPPLsgenerallydonot considerBayesianinferencewithprior distributions.Forinstance,Alchemy implements Markovlogic, encoding afirst-order knowledgebase intoMarkovrandom fields.Uncertaintyis expressedby weights on the logical formulas, butit is not possible to specify prior distributions on theseweights. ProbLog is a PPL that primarily targetsthe inference ofconditional probabilities andthe mostprobable explanation (maximum likelihood solution);itdoesnotfeature thespecificationofprior distributionsoncategoricaldistributions. PRiSMisaPPL which in-troducesDirichletpriorsovercategoricaldistributionsandisdeignedforefficientinferenceinmodelswithnon-overlapping explanations.
Thispapercontributestothefieldoflogic-basedPPLbyproposinganalternativeapproachtoprobabilisticprogramming. Specifically, we introduce a PPL based on logic programming for performing inference in probabilistic models involving categorical distributions with Dirichletpriors. We encode these models as abductive logic programs [10] enriched with probabilisticdefinitionsandinferencequeries,suchthattheresultofabductionallowsoverlappingexplanations.Wepropose twoMarkovChainMonteCarlo(MCMC)samplingalgorithmsforthePPL:anadaptationoftheuncollapsedGibbssampling algorithm,describedin[11],andanewlydevelopedcollapsedGibbssampler.OurPPLissimilartoPRiSManddifferentfrom ProbLog inthat itcan specifyDirichletpriors. UnlikePRiSM,butsimilarlyto ProbLog,we allowoverlapping explanations. However,inthispaper,allthemodelswestudyhavenon-overlappingexplanations.
WeshowhowourPPLcanbeusedtoperforminferenceintwoclassesofprobabilisticmodels:LatentDirichletAllocation (LDA, [12]), a well studied approach for topic modeling, including two variations thereof (Seed LDA and Cluster LDA); and therepeatedinsertion model (RIM,[13]), a modelused forpreference modeling and whosegenerative story canbe expressed usingrecursion. Ourexperimentsdemonstrate thatour PPL can expressabroad classof modelsin a compact way and scale up to medium size real-data sets, such asLDA with approximately 5000documents and100 words per document.OnsyntheticLDAdata,we compareourPPL withtwo LDA-specificalgorithms:collapsedGibbssampling(CGS) andvariationalexpectationmaximization(VEM),andtwostate-of-the-art PPLs:StanandPRiSM.Wefindthatallmethods, with theexception ofthe chosen VEMimplementation,perform similarly, andthatthe moreexpressive the method,the sloweritis,inthefollowingorder,withtheexceptionofVEM:CGS(fastest),PRiSM,VEM,ourPPL,Stan(slowest).
Thepaperisorganized asfollows.Section2presentstheclassofprobabilisticmodelssupportedbyourPPL.InSection3 weoutlinethesyntaxandthesemanticsofthePPL,whereasourtwoGibbssamplingalgorithmsarediscussedinSection4. Section 5 shows our experimental results and Section 6 relates our PPL to other PPLs and methods. Finally, Section 7 concludesthepaper.
2. Theprobabilisticmodel
This section begins with the description of a particular approach to probabilistic programming. Then we introduce
peircebayes
2 (PB), ourprobabilistic abductivelogic programming language designedto performinference indiscrete modelswithDirichletpriors.Throughoutthepaperwewillusenormalfontforscalars(α
),arrownotationforvectors(α
), andboldfontforcollectionswithmultipleindexes(α
α
α
),e.g.setsofvectors.Probabilisticprograms,asdefinedin[14],are“ ‘usual’programswithtwoaddedconstructs:(1)theabilitytodrawvalues atrandomfromdistributions,and(2)theabilitytoconditionvaluesofvariablesinaprogramviaobservestatements”.We caninstantiatethisgeneraldefinitionbyconsideringthenotionsofhyperparameters
α
α
α
,parametersθθθ
,andobservedvariables f andassumingthegoaltobethecharacterization oftheconditionaldistribution P(θθθ
|
f;
α
α
α
)
.Most PPLs assume such a conditional with a continuous sample space, i.e. they allow, in principle, probabilistic pro-grams with an uncountably infinite numberof unique outputs, should one not take into account issues ofreal number representations.Inourapproach,theconditionalsample spaceisassumedtobefinite,i.e.one canenumerateall possible executions.Specifically,inourPPLwerestricttheclassofdistributionsfromwhichwecandrawtocategoricaldistributions withDirichletpriors.TheDirichletpriorsarechosenfortheirconjugacy,whichsupportsefficientmarginalization.
The generality ofourPPL is not givenby therangeof probability distributionsthat we can drawfrom, butratherby thewaythedrawsfromcategoricaldistributionsinteractinthe“generativestory”ofthemodel.Wechooseour“usual pro-grams”tobeabductivelogicprogramsenrichedwithprobabilisticprimitives.SimilarlytoChurch,AnglicanandotherPPLs thisisdeclarativeprogramminglanguage,butoneinwhichthegenerativestoryisexpressedasanabductivereasoningtask responsibleforidentifyingrelevantdrawsfromthecategoricaldistributionsgiventheobservations.Ourchoiceismotivated by thesignificant amountofrelatedworkinprobabilisticlogicprogramming,althoughbothfunctionalandlogic program-mingareTuringcomplete,sotheyareequallygeneral.Inwhatfollowswepresenttheclassofprobabilisticmodelsthatare supportedbyourPPL.Wedefinethemfirstasuncollapsedmodels,thenshowhowtheycanbecollapsed.Asdemonstrated inSection 4,thisdualformalization leadsnaturally tothepossibilityofusinginourPPL uncollapsedaswellascollapsed MCMCsamplingmethods.
2 Named,inChurchstyle,afterCharlesSandersPeirce,thefatheroflogicalabduction,andThomasBayes,thefatherofBayesianreasoning.Pronounced [’p3rs’beız].
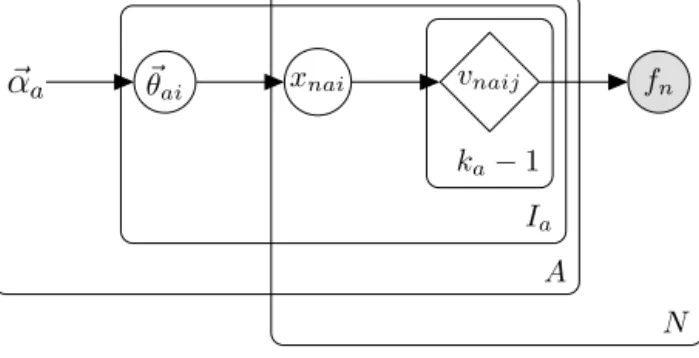
Fig. 1.The PB plate model.
2.1. TheuncollapsedPBmodel
Theclassofprobabilistic modelsthatcan beexpressedinPB,inspiredby “propositionallogic-basedprobabilistic (PLP) models”[11],isdepictedinFig. 1,usingthegeneralplatenotation[15].Inthefigure,unboundednodesareconstants,circle nodesarelatentvariables,shadednodesareobservedvariables,diamondnodesarenodesthatcanbe(butarenotalways) deterministicgiventheirparentx(wediscussthedetailsbelow),and A,Ia,N,andkaarepositiveintegers,withka
≥
2. Theaboveplatemodelencodesthefollowing(joint)probabilitydistribution:P
(
f,
vvv,
xxx, θθθ
;
α
α
α
)
=
A a=1 Ia i=1 P(
θ
ai;
α
a)
N n=1P
(
xnai|
θ
ai)
P(
vnai∗|
xnai)
Nn=1
P
(
fn|
vvvn∗)
(1) Weuse∗
todenotethesetofvariablesobtainedbyiteratingoverthemissingindexes,e.g.vnai∗ isthesetofallthevariablesvnai j, for j
=
1,
. . . ,
ka−
1, andvvvn∗ is the set of all the variables vnai j, fora=
1,
. . . ,
A, i=
1,
. . . ,
Ia, j=
1,
. . . ,
ka−
1. Un-indexedvariablesareimplicitlysuchsets,e.g.xxx=
x∗.Inthemodel,each
α
a,fora=
1,
. . . ,
A,isavectoroffinitelengthka≥
2 ofpositive realnumbers.Eachα
amayhavea differentsize,andrepresentstheparametersofaDirichletdistribution.Fromeachsuchdistribution Ia samplesaredrawn, i.e.:θ
ai|
α
a∼
Dirichlet(
α
a)
a=
1, . . . ,
A,i=
1, . . . ,
IaThesamples
θ
ai areparametersofcategoricaldistributions.Foreachi anda,thereareN samplesxnai fromtheassociated categoricaldistributionoftheform:xnai
|
θ
ai∼
Categorical(
θ
ai)
a=
1, . . . ,
A,i=
1, . . . ,
Ia,n=
1, . . . ,
NEachxnai
∈ {
1,
. . . ,
ka}
isencoded,similarlyto[16],asasetofpropositionalvariables vnai j∈ {
0,
1}
,for j=
1,
. . . ,
ka−
1,in thefollowingmanner:P
(
vnai∗|
xnai=
l)
=
2l−(ka−1)vnai1
. . .
vnail−1vnail , ifl<
kavnai1
. . .
vnail−1 , ifl=
ka (2)wherev denotesbooleannegation,and2l−(ka−1)isanormalizationconstant.
Notethatnotallvariablesinvvvaredeterministic,morespecificallyforall j suchthatl
<
j<
ka,vnai j arenotdetermined bytherealizationxnai=
l.Ourpresentationdeviatesfrom[11] inthatwepresentbothxxx andvvv inthesamemodel,rather thanconsideringtwotypesofequivalentmodels(“basemodels”and“PLPmodels”). Buttheprobabilisticsemanticsofvvvis thesameastheonederivedfromtheannotateddisjunction(AD)compilation(cf.Section3.3.1of[17]).InourPBmodel:P
(
vnai1=
0, . . . ,
vnail−1=
0,
vnail=
1|
θ
ai)
=
P(
vnail=
1|
θ
ai)
1−[l=ka] l−1 j=1 1−
P(
vnai j=
1|
θ
ai)
=
θ
ail a=
1, . . . ,
A i=
1, . . . ,
Ia n=
1, . . . ,
N l=
1, . . . ,
ka (3) where[
i=
j]
istheKroneckerdeltafunctionδ
i j.Therefore,itfollowsthat:P
(
vnail=
1|
θ
ai)
=
θ
ail l−1 j=1 1−
P(
vnai j=
1|
θ
ai)
Example2.1. For the reader unfamiliar with ADs, we offer a brief example. Let there be a four-sided die with
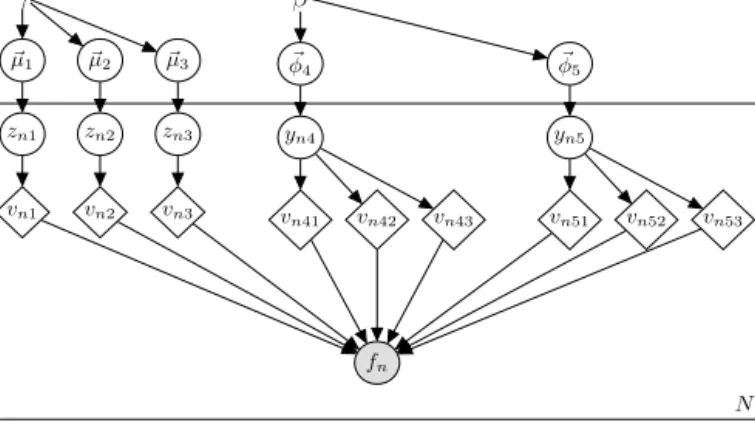
Fig. 2.The PB model for an LDA example with 3 documents, 2 topics and 4 tokens.
in Equation (3): 0
.
3, 1−0.30.2≈
0.
285, (1−0.3)(1−0.285)0.4≈
0.
8. To recoverthe original probabilities, we use Equation (2),e.g. 0.
1≈
(
1−
0.
3)(
1−
0.
285)(
1−
0.
8)
.2
Theobservedvariablesofthemodel, fn
∈ {
0,
1}
,representtheoutputofbooleanfunctionsofv,suchthat: P(
fn|
vvvn∗)
= [
fn=
Booln(
vvvn∗)
]
n=
1, . . . ,
NwhereBooln
(
vvv)
denotesanarbitrarybooleanfunctionofvariables vvv.Inourapproachitisassumedtheobservedvaluefor each fn tobe1 (ortrue).Inference in PB can be described in terms of a general schemaof probabilistic inference presented atthe beginning of this section, i.e. the characterization of P
(θθθ
|
f;
α
α
α
)
. The parameters and the hyper-parameters correspond toθθθ
andα
α
α
, respectively.Theobserveddataf isavectorofN datapoints(observations)where,byconvention, fn=
1 ensuresthatthen-thobservationisincludedinthemodel(assumethistobe alwaysthecase).Furthermore,observation fn isindependent of anyotherobservations fn,n
=
n,ifconditioned onxxx (sincexxx determines vvv);thisis implied bythe jointdistribution giveninEquation(1).Thevariouswaysinwhichann-thdatapointcanbegenerated,aswellasthedistributionsinvolved inthisprocess,areencodedthroughthebooleanfunctionBooln(
vvvn∗)
.Example2.2.LDAasaPBmodel.Weillustratetheencodingofapopularprobabilisticmodelfortopicmodeling,thelatent
Dirichletallocation(LDA)[12],asaPBmodel.ThiswillalsoserveasarunningexamplethroughoutSection3.LDAcanbe summarizedasfollows:givenacorpusofDdocuments,eachdocumentisalistoftokens,thesetofalltokensinthecorpus is the vocabulary, withsize V, andthere exist T topics. There are two sets of categorical distributions: D distributions over T categories(onetopic distributionper document), each distributionparametrized by
μ
d; and T distributions overV categories (one token distribution per topic), each distribution parametrized by
φ
t. The tokens of a document d are produced independentlybysamplingatopict fromμ
d,thensamplingatokenfromφ
t.Furthermore,eachdistributioninμ
μ
μ
issampledusingthesameDirichletpriorwithparametersγ
,and,similarly, eachdistributioninφ
φ
φ
issampledusingβ
. Notethat{
μ
μ
μ
,φ
φ
φ
}
correspondtotheparametersθθθ
inthegeneralmodel,and{
γ
,β
}
correspondtoα
α
α
.Toinstantiateaminimal LDAmodel,letusconsideracorpuswith3documents,2topicsandavocabularyof4tokens.TheplatenotationofthePB modelforthisminimalLDA,depictedinfull,isgiveninFig. 2.RelatingtothePBmodel,wehave A=
2,i.e.oneplatefor each ofγ
andβ
,I1=
3,onetopicmixtureforeachofthe3documents,I2=
2 andk1=
2 forthetwotopics,andk2=
4 forthe4tokensinthevocabulary.Letthefirstdatapointtobetheobservationoftoken2 indocument3.Thentheassociatedbooleanfunctionis:
Bool1
(
vvv1∗)
=
v13v141v142+
v13v151v152 (4) The literals v13 and v13 denotethe choice,in document3,of topic1and2,respectively, andtheconjunctions v141v142 and v151v152 denotethechoiceofthesecond tokenfromtopic1and2,respectively.Notethat,inFig. 2,eventhoughall possibleedges betweendeterministicnodesand fn aredrawn,notallthevariableswillnecessarilyand/orsimultaneously affectthe probabilityof fn.Forinstance,thevalue ofBool1(vvv1∗)
doesn’tdependon thevalue of v12,which isrelatedto document2andobservationsaboutdocument3anddocument2areindependent.Also, Bool1(vvv1∗)
cannotdependatthe sametimeonboth v141andv151,sincethetruthvalueofv13effectivelyfiltersouttheeffectofoneortheother.2
2.2. ThecollapsedPBmodel
The above model,described as uncollapsed, can be inefficient tosample from, due to thelarge number of variables. The same PB model can be reformulated as collapsed model where the parameters of the categorical distributions are marginalized out. Thisisstraightforwardsincewe assumeconjugatepriors.Wepresentthecollapsedmodelhereinorder tointroducethedistributionsusedinthederivationofthecollapsedGibbssampler(CGS)giveninSection4.
Consideraandifixed.Sincewemakemultipledrawsfromacategoricaldistributionparametrizedby
θ
aiitisconvenient to workwithcount summaries.Thereforewe overloadthenotation x∗ai todenote aka sizedvector ofcounts, i.e.forall categoriesl=
1,
. . . ,
ka,x∗ail=
Nn=1[
xnai=
l]
.Similarly,xxxisoverloadedtodenoteasetofsuchvectorsforeacha=
1,
. . . ,
A,i
=
1,
. . . ,
Ia.Integratingoutθ
forasingleDirichlet-categoricalpairyields: P(
x∗ai;
α
a)
=
( (
α
a))
( (
α
a)
+
(
x∗ai))
ka l=1(
x∗ail+
α
al)
(
α
al)
where
(
v)
denotesthesumoftheelementsofsomevector v anddenotesthegammafunction.Also, fromthe condi-tionalindependenceofourx∗ai:
P
(
xxx;
α
α
α
)
=
A a=1 Ia i=1 P(
x∗ai;
α
)
ThejointdistributionofthecollapsedPBmodelbecomes:
P
(
f,
vvv,
xxx;
α
α
α
)
=
P(
xxx;
α
α
α
)
P(
vvv|
xxx)
P(
f|
vvv)
(5) where P(
vvv|
xxx)
=
A a=1 Ia i=1 N n=1 P(
vnai∗|
xnai)
P(
f|
vvv)
=
N n=1 P(
fn|
vvvn∗)
Thejointdistribution inEquation(5)issimplyEquation(1)with
θθθ
integratedout.Notethat vvv musttake valuesfrom themodelsoftheformulasBoolninordertohaveP(
f|
vvv)
=
1 (recallthat f isobserved).Furthermore,givenarealizationofvvv,itisuniquelydecodedtoarealizationofxxx.Inpractice,wealwaysmakesurethattheseconditionsaremet,cf.Section3. Insummary,inferenceinPBmodelsmeanstocharacterize P
(θθθ
|
f,
α
α
α
)
.SinceDirichletpriorsareconjugatetocategorical distributions,theposteriordistributionsarealsoDirichletdistributionswithparametersα
α
α
:θ
ai|
f,
α
α
α
∼
Dirichlet(
α
ai)
a=
1, . . . ,
A,i=
1, . . . ,
Ia Therefore,theinferencetaskistoestimateα
α
α
.Informally,thePBinferencetaskiscomputedintwosteps.Thefirststep,describedinSection3,consistsofrepresenting agivenprobabilisticmodelasanabductivelogicprogramenrichedwithprobabilisticprimitivesandexecutingthisprogram. Thelatteryields theformulasBooln,andthusthePBmodeliscompletelyspecified.The secondstepconsistsofsampling thePBmodelandisdescribedinSection4.
3. Syntaxandsemantics
In thissection we formally define the syntax andsemantics (upto MCMC sampling)of probabilistic programs in PB. PBprograms will bedefinedasabductivelogic programs wherethesetof abduciblescorrespondto thesamplespaceof
P
(
xxx|
θθθ )
.Eachobservationinthemodelcorresponds toan abductivequery.The executionoftheabductivequerygiventhe programmeansexplainingthat observation,andtheresultofthisexecutionwillbe aformulaintermsofabducibles.This formulaisthentranslatedintoabooleanformulaBool expressedintermsofthebooleanvariables vvv fromthePBmodel. Wearguethatallobservationsneednotbeexplainedindividually,i.e.byexecutingthepreviousstepsforeachobservation, andinsteadproposeamoreefficientapproach.Finally,we describeacompactencoding ofeachbooleanformulaBool into a(reducedordered)binarydecisiondiagram,whichwillbeusedforMCMCsampling.3.1. AbductivelogicprogrammingandPB
APBprogramisanabductivelogicprogram[10] enhancedwithprobabilisticpredicates.Adaptingthedefinitionsfrom [18],an abductivelogicprogramisa tuple
(,
AB)
,whereisanormallogic program,ABisa finitesetofgroundatoms calledabducibles.InPB,anabductivelogicprogramencodesthegenerativestoryofthemodel,aswellastheobserveddata. Aquery Q isa conjunctionof existentially quantified literals. InPB, thereexists one queryfor each observation, de-scribing how that observation should be explained. An abductivesolution for a query Q is a set of ground abducibles
⊆
A B:•
comp3(
∪
)
|=
Qwhere CET denotes the Clark Equality Theoryaxioms [19], and comp3
()
the Fitting three-valued completion of a pro-gram[20]. CET isneeded todefine the semantics ofuniversally quantified negation inprograms containing variables. Theresultofaqueryisthedisjunctionofalltheabductivesolutionscomputedbytheabductivelogicprogram,whereeach abductivesolutionisconsideredaconjunctionofitselements.ThiscomputationisdescribedinSupplementaryAppendixA. The syntax of the non-probabilistic predicates is similar to Prolog, and is documented in [21]. The domain of the abducibles is specified through a probabilistic predicate
pb_dirichlet
. This predicate defines a set of cat-egorical distributions with the same Dirichlet prior, i.e. it allows draws from P(
xnai|
θ
ai)
, for a fixed a and all n and i. A conjunction of such predicates defines the plate indexed by a. In PB, the syntax of the predicate ispb_dirichlet(Alpha_a, Name, K_a, I_a)
. The first argument,Alpha_a
, corresponds toα
a in the model,and can be eithera list of ka positive scalars specifying the parameters ofthe Dirichlet, ora positive scalar that specifies a symmetricprior.Thesecondargument,Name
isanatomthatwillbeusedasafunctorwhencallingapredicatethat repre-sentsarealizationofacategoricalrandomvariableonthea-thplate.ThethirdargumentK_a
correspondstoka,andI_a
represents Ia,i.e.thenumberofcategoricaldistributionshavingthesameprior.Example3.1.ConsidertheLDAexamplefromExample 2.2.Tospecifytheprobabilitydistributions,assumingflatsymmetric
priorsover
μ
μ
μ
andφ
φ
φ
,weneedthefollowingpredicates: pb_dirichlet(1.0, mu, 2, 3).pb_dirichlet(1.0, phi, 4, 2).
2
Declaring
pb_dirichlet
predicatessimplystatesthatthedistributionsonthea-indexedplateexist.Thedrawsfrom thesedistributions,i.e.samplesfromP(
xxx|
θθθ )
,arerealizedusingapredicateName(K_a, I_a)
.Thefirstargumentdenotes a category from 1,
. . . ,
ka, and the second argument a distribution from 1,
. . . ,
Ia.Informally, the meaning of the predi-cate is that it draws a valueK_a
fromtheI_a
-thdistribution withDirichlet prior parametrized byα
a. All predicatesName(K_a, I_a)
areassumedtobegroundatomswhencalled.Thereforethesetofabduciblescanbedefinedas:AB
= {
Name(K_a, I_a)
|∀
a,
K_a
,
I_a
}
Example3.2.ContinuingExample 3.1,weshowtherestoftheabductivelogicprogram.Notethatthisisnotthecomplete
PBprogram,sincewehavenotdefinedallprobabilisticpredicates. observe(d(1),[(w(1),4),(w(4),2)]). observe(d(2),[(w(3),1),(w(4),5)]). observe(d(3),[(w(2),2)]). generate(Doc, Token) :-Topic in 1..2, mu(Topic, Doc), phi(Token, Topic).
Each
observe
fact encodes a document,indexed using the first argument, and consistingof a bag-of-words in the secondargument.Thebag-of-wordsisalistofpairs:atokenwithanindexandits(positive)countperdocument.The
generate
ruledescribeshoweachobservation,characterizedbyaparticularToken
inaDocument
,isgenerated (orexplained).ThevariableTopic
isgroundedaseither1or2,ingeneral1upto T.Notethatobserve
andgenerate
are notkeywords,butdescriptiveconventionalnames.Inthisexample,theabduciblesarethepredicateswithfunctors
mu
and
phi
.2
In PB, each abducible corresponds to a draw from P
(
xnai|
θ
ai)
, representedas a tuple(
a,
i,
l)
via a bijectionρ
:
AB→
{
(
a,
i,
l)
|
a∈ {
1,
. . . ,
A}
,
i∈ {
1,
. . . ,
Ia}
,
l∈ {
1,
. . . ,
ka}}
.The tupleconsistsofan indexofthe distribution(
a,
i)
andthe drawn categoryl.ForanabducibleName(K_a, I_a)
,K_a
correspondstol,I_a
correspondstoi,andaisdeterminedbythe or-derofthepb_dirichlet
definitioninvolvingName
.Forinstance,inthecontextofExample 3.1,ρ
(
phi(3,2)
)
=
(
2,
2,
3)
.Abusingnotation,themapping
ρ
isalsousedtomapabductivesolutions,i.e.ρ
()
isalistoftuples(
a,
i,
l)
.Thesemanticsoftheabductivelogicprogramensuresthatabductivesolutionsareminimal,whichmeansnoabducibles are included inan abductivesolutionunless they arenecessary tosatisfy the query.Probabilistically, thismeans thatno draws are made except the ones needed to explain an observation. This implicit marginalization and compactness (e.g. queriesthatproducev1andv1v2
+
v1v2areequivalent)iseffectivelyenforcedbyBDDcompilation,describedinSection3.2. ThePBmodelconstrainsthedrawsfromthecategoricaldistributionssuchthat,foreachobservation,wecandrawonce per distribution,andsince each observation isexplained by an abductivequery, we must enforcethis constrainton our abductivesolutions,i.e.therecanbeno(
a,
i,
l1),(
a,
i,
l2)∈
ρ
()
suchthatl1=
l2.Example3.3.ContinuingExample 3.2,considerobservingtoken2 indocument3.Thecorrespondingqueryis
generate(3,
2)
. The executionofthe abductivelogic programwiththis queryproduces two solutions corresponding tothe explana-tions ofthe token,i.e. itcan be produced eitherfrom topic1 or topic 2.The solutions are{
mu(1,3)
,
phi(2,1)
}
and{
mu(2,3)
,
phi(2,2)
}
.Weobtaintheresultofthequerybyapplying
ρ
totheabductivesolutionsandtakingtheirdisjunction:((
1,
3,
1)
∧
(
2,
1,
2))
∨
((
1,
3,
2)
∧
(
2,
2,
2))
2
3.2. Knowledgecompilationandmultipleobservations
Thepurposeofabductionistoproduce,foreachobservationn
=
1,
. . . ,
N,aformulaBooln(
vvvn∗)
.Havingcomputedthe resultofaquery,allthatisleftistotranslateeachdraw(
a,
i,
l)
intobooleanvariables.Wedefinethistranslation,denoted conditionalADcompilation,asorderingalldrawsbytheirdistributionindex(
a,
i)
,i.e.firstbya theni,andcompilingeach distributionasanADtothecategoriespresentintheresultofthequery.Example3.4.ContinuingExample 3.3,intheresultofthequery,wehavethesorteddistributions
(
a,
i)
:1.
(
1,
3)
,withtwooutcomespresentinthesolution,i.e.(
1,
3,
1)
and(
1,
3,
2)
,andonevariablev1. 2.(
2,
1)
,withoneoutcomepresentinthesolution,i.e.(
2,
1,
2)
,andonevariable v2.3.
(
2,
2)
,withoneoutcomepresentinthesolution,i.e.(
2,
2,
2)
,andonevariable v3.ThereforetheresultofthequeryisparsedusingconditionalADcompilationintotheformula:
v1v2
+
v1v3Notethatforafixednumberoftopics,thisrepresentationisinvarianttoV,thenumberoftokensinthevocabulary,due tothefact,whenexplaininganobservation,wedrawasingletokenfromsometopic.
2
The proposed representationof conditional AD compilationis differentfrom conventionalAD compilation(cf. Section 3.3.1of[17])inthatinsteadofconsideringthesample spaceofthedistributions,itconsiderstheconditionalsamplespace ofthedistributionsgivenaparticularobservation.InmodelssuchasLDAthisdifferenceiscrucial,sinceintypicalinference tasks,thesize ofthevocabulary V is ofthe orderoftensofthousandsoftokens, andAD compilationwouldthus create conjunctionsofupto V
−
1 variables.Sofarwe havediscussedtheexplanation ofasingle observation,i.e.thecomputation ofasingle abductivequeryand thetranslationoftheresultofthequeryintoabooleanformula. Itwouldbeinefficienttotreat multipleobservationsby computing a query forevery single observation. For instance, inthe LDA example,the same token
Token
can be pro-ducedmultipletimesfromthesamedocumentDocument
.Thequeriescorrespondingtotheseobservationsareidentical:generate(Document, Token)
,thereforeitisredundanttoexecutethequerymorethanonceforallsuchobservations. We make a furtherremark, namelythat all observations generated fromthe sameset of topicsin an LDA taskproduce the same formulaafter conditional AD compilation, although the particular distributions used are different for different document-tokenpairs.WeexploitthesepropertieswhenexpressingqueriesinaPBprogram.Todoso,weintroducetheprobabilisticpredicate
pb_plate(OuterQ, Count, InnerQ)
,wherethequeriesOuterQ
andInnerQ
areconjunctionsrepresentedaslists, andCount
is a positive integer. For each successful solution ofOuterQ
, theCount
argument and the arguments ofInnerQ
are instantiated, then thepredicate executesthequeryInnerQ
.We assume that all observations definedby apb_plate
predicateyield the same formula fromthe abductive solutions ofInnerQ
. If one didn’t know whetherthe formulasareidentical,onecouldsimplywriteapb_plate
definitionforeachobservation,withanemptyouterquery,and acountargumentof1.Example3.5.Continuingthepreviousexamplesofthissection,wespecifythelastpartofthePBprogramforanLDAtask.
The
pb_plate
predicate iterates through the corpus andgenerates each token according to the model. In this model, iteratingthroughobservationsmeansselectingdifferentpairsofdocumentandtokenindexes.pb_plate(
[observe(d(Doc), TokenList),
member((w(Token), Count), TokenList)], Count,
[generate(Doc, Token)] ).
Anexample ofaPBprogram withmultiple
pb_plate
definitionsis givenfortheSeedLDA model,discussed in Sec-tion5,inTable 1.2
Theformulaforeach
pb_plate
definitioniscompiledintoareducedorderedbinarydecisiondiagram(ROBDD,inthe restofthepapertheROattributesareimplicit)[22,23],withthevariablesinascendingorderaccordingtotheirindex.The BDDofabooleanformulaBool allowsonetoexpressinacompactmannerallthemodelsofBool.Thisenablesustosample(asubsetof)thevariablesvvv suchthat P
(
f|
vvv)
equals1.Furthermore,theconditionalADcompilationallowsustocorrectly decodevvv intoxxx,suchthatallthedeterministicconstraintsofthemodelaresatisfied.Compilingtheabductivesolutions intoaBDD allowPBto performinferencein modelswithoverlappingexplanations, similarlytoProbLog.
ThefinalstepofinferenceinPBissamplingviaMarkovChainMonteCarlo(MCMC),whichwediscussinSection4.
4. MCMCsampling
Inferenceinhigh-dimensionallatentvariablemodelsistypicallydoneusingapproximateinferencealgorithms,e.g. varia-tionalinferenceorMCMCsampling.Weusethelatter,inparticulartwoalgorithms:anadaptationtoPBmodelsofIshihata andSato’suncollapsedGibbssamplingforPLPmodels[11],andournovelcollapsedGibbssampling(CGS)forPBmodels.
4.1. UncollapsedGibbssampling
Following [11],wecan performuncollapsedGibbs samplingalong twodimensions(
θθθ
andxxx) byalternativelysampling from P(
xxx|ˆ
θθθ ,
f)
andP(θθθ
|ˆ
xxx,
α
α
α
)
.Weusehattodenotethesamplesinsome iteration,andifthevariableisavector, weomit vector notation.Asamplefrom P(θθθ
|ˆ
xxx,
α
α
α
)
yieldsanestimateθθθ
ˆ
thatisaveragedoverthesamplingiterations toproduceour posteriorbeliefofθθθ
.Samplingfrom P
(θθθ
|ˆ
xxx,
α
α
α
)
meanssampling:ˆ
θ
ai∼
Dirichlet(
α
a+ ˆ
x∗ai)
a=
1, . . . ,
A,i=
1, . . . ,
Ia Assumethisisimplementedbyafunction:θθθ
←
sample_theta(
α
α
α
,
xxx)
Sampling from P
(
xxx|ˆ
θθθ ,
f)
canbe doneby samplingapathfromrootto the“true”leaf3 ineachofthe BDDsforBooln,n
=
1,
. . . ,
N,whichyieldasample fromvvv thatisthendecodedtoxxx.Tosample aBDD,we samplethetruthvalueofeach node,andthereforeweneedtouse P(
vvv;
θθθ )
,asdefinedinSection2.1.According tothe conditionalAD compilationdefinedinSection 3.2,eachcompilation isperformedforeachindividual observation, andtheobservationsare groupediftheycorrespondtothesamequery,andgroupedagainwhenthey corre-spondtothesamecompiledbooleanformulaBool. ThismeansthatforeachformulaBool, theprobabilitiesoftheboolean variables P
(
vvv;
θθθ )
mustbe computedfromθθθ
foreach distinct query.Let Nbdd bethe numberofbooleanvariablesinBDDbdd,andNQ,bdd bethenumberofdistinctquerieswhoseresultyieldsthesameformulaBool encodedinbdd.Then
θθθ
bdd is an NQ,bddby Nbddmatrix,computedfromθθθ
usingafunction:θθθ
bdd←
reparametrize(θθθ ,
bdd)
The samplingalgorithmis giveninAlgorithm 1,andthe algorithmforsamplinga single BDD(sample_x
(
)fromAlgo-rithm 1)isexplainedinSupplementaryAppendixB.
Algorithm1UncollapsedGibbssamplingforPB.
functionuncollapsed_Gibbs(ααα,bdds,maxit) samples← [] forit=1,. . . ,maxitdo θθθ←sample_theta(ααα,xxx) updatesθθθ forbdd∈bddsdo θθθbdd←reparametrize(θθθ ) end for fora=1,. . . ,Ado resetsxxx fori=1,. . . ,Iado x∗ai←zeros(ka) end for end for forbdd∈bddsdo updatesxxx
for(obs,count)∈bdddo θθθobs←θθθbdd[obs,:] sample_x(bdd,count,θθθobs) end for
end for
samples←append(samples,θθθ ) end for
returnavg(samples) end function
InAlgorithm 1,the input tothe sampler are thepriors
α
α
α
,a setof BDDsbdds,anda numberof iterations maxit.We define some additional notation:we use[
]
to denotean empty list, append(
list,
el)
to append element el to a list list, zeros(
)tocreateemptyvectorsormatricesofshapesspecifiedbytheargumentsandavg(
)totaketheaverageofavectororlist.Toupdatexxx,wemustsampleall BDDs(oneforeach
pb_plate
definition),andall observationswithineachBDD. Weassumethatanobservationobstakesvaluesin1,
. . . ,
NQ,bdd,andcountrepresentsthenumberoftimestheobservation isrepeated,asspecifiedbytheCount
argumentofapb_plate
predicate.Foreachobservationobswewilluseonlytheobs-throwfrom
θθθ
bdd,denotedasθθθ
bdd[
obs,
:]
.4.2. CollapsedGibbssampling
Asexplained in[11],it isnotfeasible toperformCGS inPLP models,asageneralization ofCGSforLDAin[24].Itis, however,possible to define a generalCGS procedure forPB. Thisuses the independenceproperty ofour observations
fgivenxxx.TheadvantageofcollapsedversusuncollapsedGibbssamplingisthefasterconvergenceofthecollapsedsampler. WeshowthatthisisthecaseforanexperimentusingsyntheticdatainanLDAtaskinSection5.1.
CGSforPBmodelsentailssampling P
(
xxxn∗|
α
α
α
,
xxxˆ
−n∗)
,forn=
1,
. . . ,
N,wherethesubscript−
nmeanstherangeofvalues 1,
. . . ,
n−
1,
n+
1,
. . . ,
N.Notethat incontrast touncollapsedGibbs sampling,we sample oneobservationatatime, andθθθ
isintegrated out. Sincesamplinga BDD requires probabilitieson booleanvariables, P(
vvv|
θθθ )
, we “uncollapse”θθθ
forthis purposeastheaverageofitscurrentDirichletposteriorparametrizedbyα
α
α
:θ
ai=
α
ai(
α
ai)
a=
1, . . . ,
A,i=
1, . . . ,
IA Weassumethisisimplementedbyavg(
α
α
α
)
.TheCGSisshowninAlgorithm 2:
Algorithm2CollapsedGibbssamplingforPB.
functioncollapsed_Gibbs(ααα,O,maxit) samples← []
xxx←initialize(ααα) forit=1,. . . ,maxitdo
for(obs,bdd)∈shuffle(O)do for(a,i,l)∈draws(obs)do
x∗ai[l]← x∗ai[l]−1 αai[l]← αai[l]−1 end for θθθ←avg(ααα) θθθbdd←reparametrize(θθθ ) θθθobs←θθθbdd[obs,:] sample_x(bdd,1,θθθobs) fora=1,. . . ,Ado fori=1,. . . ,Iado αai← αa+ x∗ai end for end for end for
samples←append(samples,ααα) end for
returnavg(samples) end function
Beforesampling,weinitializexxxbysetting
θθθ
totheaverageoftheDirichletprior,thenxissampledlikeinaniterationof theuncollapsedGibbssampler.Weassumethissetupisimplementedinafunctioninitialize(
α
α
α
)
.WeswitchrepresentationfromasetofBDDstoasetofO ofobservations,eachobservationhavingitsownBDD.Eachiterationloopsoverthe obser-vationsandremovesthedrawsofthecurrentobservationfromxxx,thenupdates
θθθ
,thenre-samplesthecurrentobservation to update xxx. Toremove the draws ofthe currentobservation, we usea function draws(
obs)
,that, forsome observationobs,returnsthelistofdrawsrequiredtoexplainthatobservation,i.e.alistof
(
a,
i,
l)
tuples.Thedrawsrepresentthepath sampledfromtheBDD inthepreviousiteration.UnliketheuncollapsedGibbssamplingalgorithm,whereallobservations weresampledgiventhesameθθθ
,inCGS,we updateθθθ
aftereachobservation. Furthermore,thesampleswerecord arenotθθθ
,buttheposteriorDirichletparametersα
α
α
.Fig. 3.Comparison between PB samplers and LDA-specific CGS on 10 sampled synthetic corpora (10 runs per corpus).
5. Evaluation
InthissectionwepresentexperimentswithPB.4Thefirsttwoexperimentsarequantitative,whiletherestarequalitative. Inthelatter,weshow thatinferenceinPByieldsreasonable resultsgivenourintuitionaboutthemodels,andinthecase oftherepeatedinsertionmodel,wereachsimilarconclusionscomparedtoadifferentmodel(theMallowsmodel).
5.1. PBandcollapsedGibbssampling(CGS)forLDAonsyntheticdata
We run avariation ofthe experimentperformedin[24,11].A syntheticcorpusis generatedfroman LDAmodelwith parameters: 25words inthe vocabulary,10topics,100 documents,100 wordsper document,anda symmetric prior on themixtureoftopics
μ
,γ
=
1.Thetopicsusedasgroundtruthspecifyuniformprobabilitiesover5words,cf.[24,11].We evaluatetheconvergenceofthePBsamplersandanLDA-specificCGSimplementationinthetopicmodels
Rpackage.The parameters are:β
=
γ
=
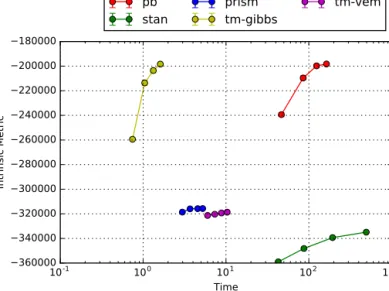
1 as(symmetric)hyper-parameters,andwe run100iterations ofthesamplers.The experiments are run10timesovereachcorpusfromasetof10identicallysampledcorpora,yielding 100valuesoftheloglikelihoods per iteration.Theaverageand95%confidenceinterval(underanormaldistribution)per iterationareshowninFig. 3.The experimentyieldstwoconclusions:1)similarlyto[11],wefindthatuncollapsedGibbssamplingconvergesslowerthanCGS and2)thePB-CGSperformssimilarlytotheLDA-specificCGS,whichsupportsourclaimthatCGSinPBgeneralizesCGSin LDA.5.2. PB,CGS-LDA,VEM-LDA,PRiSMandStanforLDAonsyntheticdata
WecomparePBwithtwoLDA-specificmethodsfromthe
topicmodels
Rpackage:collapsedGibbssampling(tm-gibbs) andvariationalexpectationmaximization(tm-vem),andtwostate-of-the-art PPLs:PRiSM[8]andStan[4].Themetricswe areinterestedinare:1)theintrinsicmetricofeachmethod,usedtosubjectivelydecidewhenasamplerhasconverged,2) loglikelihood,usedtoassesthequalityoffittotheobserveddataand3)fold-averageperplexityin5-foldcross-validation, used toasses thegeneralization powerofeach method.Inaprevious paper,we showedthatChurch [1]doesn’tseem to convergeinareasonableamountoftimeonsimpleLDAtasks,cf.AppendixCof[18].We usea similarsetup tothe previous experiment(T
=
10,
γ
=
1), exceptthat we generateonlyone corpusof1000 documentsandaverageover10runswithdifferentRNGseeds.The firstprobleminevaluatingthemethodsisdecidingwhenhasthemodelconverged.Weusethedefaultsettingsof allimplementationsunlessspecifiedandtheirintrinsicmeasures:thelikelihoodattributesofLDAobjectsfortm-gibbsand tm-vem(
@logLiks
),theLDA-likelihoodforPB,cf.AppendixBof[18],theget_logposterior
functionforStanandthe variational freeenergy(VFE)forPRiSM.Timeis measuredinsecondsandaveraged acrossruns, themetrics areaveraged acrossrunsandtheerrorbarsshowonestandarderror,thoughveryoftenthemethodsshowlittlevariation.We plotthe resultsinFigs. 4 and 5. Notethat themethods shouldnot be comparedwitheach other basedon these figures. Thelastvalueofthenumberofiterations istheonewherewedeemthereisconvergence.Forsamplingmethods, we ranupto200iterations fortm-gibbs,400iterationsforPBand25iterations forStantomakethisdecision.ForPBwe
4 Seesupplementarymaterialsfordetailsonimplementationandsoftwareavailability(AppendixC).Inallbutthefirstexperimentweuseonly uncol-lapsedGibbssamplingforPB,since,althoughitconvergesslowerthanCGS,itisbetteroptimizedinthecurrentimplementation.
Fig. 4.Intrinsic metrics by log average execution time. The methods should not be compared based on these values.
Fig. 5.Intrinsic measures by number of topics in the evaluated model.
use50,100,150and200iterations,forStan5,10,15,20iterations,forPrism50,100,150and200iterations(basedonthe intrinsicconvergenceofVEM), fortm-gibbs25,50,75,100iterations, fortm-vem20,30,40,50iterations(based onthe intrinsicconvergenceofVEM).Whenvaryingthenumberoftopics,weusedthemaximumvalueofiterationsforsampling methods,andtherestranuntilconvergence.
Whenwevarythenumberoftopicsintheprobabilisticprogram,e.g.inFig. 5,wetypicallyexpectthemetrictoincrease up to 10topics, andthen decreaseor remainthe same.This behavior is illustrated by theintrinsic measures ofPB and tm-gibbs, whilethat of Stanbehaves oddlywithrespect tothisexpectation. In whatfollows weshall seethat when we tracklikelihoodandperplexity,thesebehaviors change.
Tobeabletocomparethemethods,weusedthefollowingdefinitionof“likelihood”:
L
(
C
)
=
(w,d)∈C T t=1μ
d(
t)φ
t(
w)
where
C
isacorpusoftokens(
w,
d)
, w isthetoken index,disthedocumentindex,andT,μ
andφ
arethesameasin Example 2.2.We plot the results in Figs. 6 and 7. We use the same settings foriteration numbers. As in the intrinsic metric ex-periment,the more expressive themethod, theslowerit is,with theexception of PRiSMbeing fasterthan tm-vem.The difference ofmorethanan orderofmagnitudebetweenPRiSMandPBcan beexplained bythefact that theassumption
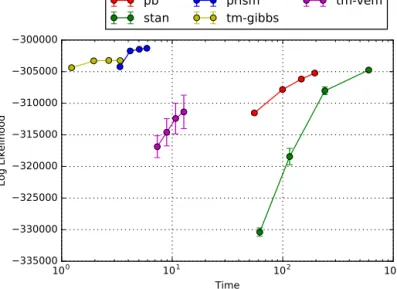
Fig. 6.Likelihood against log average execution time. Higher is better. The results are consistent withFig. 4.
Fig. 7.Likelihood against number of topics in the evaluated model. Notice the difference w.r.t.Fig. 5.
ofnon-overlapping explanationsallowsforsignificantoptimizationsinPRiSM,aswell asthefactthat theimplementation of thelatterismuch moremature.Concretely,PRiSM iswritten inC, Stancompiles itsprograms to C++code,while our currentPBprototypesamplingimplementationiswritteninPythonandCython.Withrespecttothenumberoftopics,all methodsperformsimilarly,withtheexceptionoftm-vem.
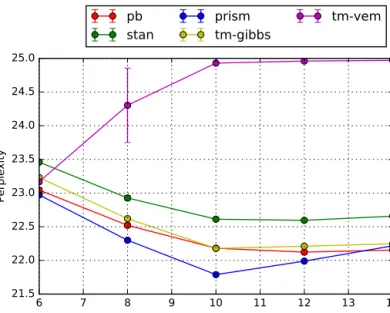
Finally, weshow theaverage perfold perplexity ina 5-foldcross-validationsplit onevery documentofthe corpusin Figs. 8 and 9.
Wedefineperplexitysimilarlyto[25]:
P
(
C
)
=
exp−
L
(
C
)
(w,d)∈C1Werunthemethodsonlyfourtimes,andduetofasteroverallconvergence,wetunethenumberofiterationsasfollows: 10,20,30,40,200forPB,2,4,6,8,20forStan,10,20,30,40,200forPRiSM,10,20,30,40,200fortm-gibbs,and5,10,15, 20,50fortm-vem.Allmethodsperformwell, withtheexceptionoftm-vem.Stanyieldsverysimilarvaluesforperplexity for2,4,6and8iterations.
Fig. 8.Average fold perplexity in 5CV against average execution time. Lower is better. The first four markers for Stan almost overlap.
Fig. 9.Average fold perplexity in 5CV against number of topics in the evaluated model. Note the consistency w.r.t.Fig. 7.
5.3. PBforseedLDAon20newsgroupsdataset
Inspiredbyanexperimentfrom[26],weusethecomputingrelated(comp.*)newsgroups inthe20newsgroupsdataset [27].Wetokenize,lemmatizeandremovestopwordsfromalldocumentstoobtainacorpuswithV
=
27206 uniquetokens inD=
4777 documentswithaveragelengthofapprox.72 tokens.WesetT=
20 topicsandpriorsγ
=
50/
T,β
=
0.
01.We seed two topicswithhardware (hardware, machine,memory, cpu), andsoftware(software, program,version, shareware) relatedterms.Seedingatokeninatopicmeansthatwheneverweobservethattokenwewillassignitonlythattopic.WeshowthePBprogram,withtheobservefactsomitted,inTable 1.Theomittedobservefactsencodethecorpusinthe samemannerasinExample 3.2.Theseedpredicatespecifiesatokenasitsfirstargumentandalistofallowedtopicsasthe secondargument.Theobservationsaresplitintoseedtokensandnon-seedtokens,andareplacedonseparate
pb_plate
predicates.Todistinguishbetweenthetwotypesoftokensweusethepredicate
seed_naf
becausenegationisuniversally quantified.WerunPBfor400iterationsandsummarizetheseededtopics,aswordclouds,inFig. 10.Weobservethat bothtopics givehighweightstotheseedwords,andotherhardware (mhz,rom,disk,bios,board)orsoftware(source,library,utility, server,user)relatedterms.
Table 1
PBprogramforseedLDA.
% ’observe’ facts are ommited pb_dirichlet(2.5, theta, 20, 4777). pb_dirichlet(0.01, phi, 27206, 20). seed(9398, [1]). seed(21247, [2]). seed(13167, [1]). seed(17982, [2]). seed(13813, [1]). seed(24490, [2]). seed(4483, [1]). seed(20682, [2]). seed_naf(Token) :- seed(Token, _). pb_plate( [observe(d(Doc), TokenList),
member((w(Token), Count), TokenList), \+ seed_naf(Token)],
Count,
[Topic in 1..20, theta(Topic,Doc), phi(Token,Topic)]). pb_plate(
[observe(d(Doc), TokenList),
member((w(Token), Count), TokenList), seed_naf(Token)],
Count,
[seed(Token, TopicList), member(Topic, TopicList), theta(Topic,Doc), phi(Token,Topic)]).
Fig. 10.Seeded topics in the seed LDA task.
5.4. PBforclusterLDAonarXivabstracts
WeconsideradifferentvariantoftheLDAmodel,oneinwhichwedefineapartitionCoverthetopics.Intheexperiment, weconsider25topicsclusteredinto5clustersof5topics.Eachtokenisthengeneratedbychoosingatopicclusteraccording to adocument-specificmixtureofclusters, thenatopicfromthecluster, againaccordingtoa document-specificmixture, andfinallythetokenischosenfromthetopic.Notethatthismodelisdifferentfromtheparametricversionofhierarchical Dirichlet processes[28],equation 29, namelythat model considersa globalset oftopics, andeach document(or group) selectsasubsetfromtheglobalset.InclusterLDA,alldocumentscanuseanyofthetopics,howeverthetopicclustersare disjoint,asopposedtothepossiblyoverlappingsubsetsintheparametrichierarchicalDirichletprocess.
We collect all abstractson arXivsubmitted in2007, fromfive categories:quantitative finance (q-fin), statistics(stats), quantitative biology(q-bio),computer science(cs),andphysics (physics).Wetokenizeandremove stopwordstoobtaina corpuswithV
=
26834 uniquetokensin D=
5769 documentswithaveragelengthofapprox.80 tokens.Weusepriorsofγ
=
50/
T=
10 foreachclustermixtureandtopicmixturepercluster,andβ
=
0.
1 forthetopics.The PBprogram fortheclusterLDAtaskisshowninTable 2.Weuse
psi
todenotethedrawofatopiccluster,anda predicatecreate_term
tocreatetermsthat,whencalledwithpb_call
,choosebetweenthetopicswithinacluster,as wellasthetokensfromthetopics.InFig. 11weplot,asheatmaps,theclustermixturesforeachdocumentineachcategory.Weobservethatquantitative biologyiswellrepresentedbycluster2andphysicsiswellrepresentedbycluster3.Computerscienceischaracterizedby cluster 5,butalso1and4,whilequantitative financeandstatisticsarevery similar,consistingmainlyofclusters1,2and 4.Thelattereffectmaybeduetothesmallnumberofdocumentsinbothquantitativefinanceandstatistics,aswellasthe factthatmostquantitativefinancepapersfocusonstatisticalmethods.
Table 2
PBprogramforclusterLDA.
% ’observe’ facts are ommited pb_dirichlet(10.0, psi, 5, 5769). pb_dirichlet(10.0, theta1, 5, 5769). pb_dirichlet(10.0, theta2, 5, 5769). pb_dirichlet(10.0, theta3, 5, 5769). pb_dirichlet(10.0, theta4, 5, 5769). pb_dirichlet(10.0, theta5, 5, 5769). pb_dirichlet(0.1, phi1, 26834, 5). pb_dirichlet(0.1, phi2, 26834, 5). pb_dirichlet(0.1, phi3, 26834, 5). pb_dirichlet(0.1, phi4, 26834, 5). pb_dirichlet(0.1, phi5, 26834, 5). pb_plate( [observe(d(Doc), TokenList),
member((w(Token), Count), TokenList)], Count,
[generate(Doc, Token)]).
create_term(Functor, Idx, Cat, Distrib, Term) :-number_chars(Idx, LIdx),
atom_chars(Functor, LFunctor), append(LFunctor, LIdx, LF), atom_chars(F, LF),
Term =.. [F, Cat, Distrib]. generate(Doc, Token)
:-Cluster in 1..5, Topic in 1..5, psi(Cluster, Doc),
create_term(theta, Cluster, Topic, Doc, Term1), pb_call(Term1),
create_term(phi, Cluster, Token, Topic, Term2), pb_call(Term2).
Fig. 11.Cluster mixture for each category (x– topic clusters,y– documents, darker color – higher probability).
Furthermore, if we inspect, for example, cluster 2, corresponding to quantitative biology, shown in Table 3, we find thatmosttopicsgive highprobability totermsusedinbiology,e.g.“proteins” intopic2,“genetic” and“brain”intopic3, “response”and“diffusion”intopic4.Theresultsagreewithourintuitionaboutthemodel:topicswithinthesamecluster aresimilar.
5.5. PBforRIMonSushidataset
Arepeatedinsertionmodel(RIM,[13])provides arecursiveandcompactrepresentationof K probabilitydistributions, calledpreferenceprofiles,overthesetofallpermutationsofM items.Thisintuitivelycaptures K differenttypesofpeople
Table 3
TopicCluster2(top10tokensandprobabilities).
important 0.0092 physical 0.0099 scaling 0.0115 expression 0.0092 proteins 0.0092 free 0.0105 model 0.0092 interaction 0.0092 similar 0.0089 fluctuations 0.0085 individual 0.008 genetic 0.0079 large 0.0082 scales 0.0072 transfer 0.0067 mechanism 0.0077 transition 0.0072 agent 0.0062 specific 0.0077 mathematical 0.0069 brain 0.006 factors 0.0075 investigate 0.0066 chemical 0.0058 recent 0.0074 process 0.0066 exhibit 0.0056 highly 0.0073 dynamical 0.0062 normal 0.0056
simulations 0.0098 structural 0.0096 response 0.0093 short 0.0095 activity 0.0087 stability 0.0094 mean 0.0084 global 0.009 diffusion 0.0084 equilibrium 0.0087 rate 0.0081 studies 0.0081 present 0.008 role 0.008 temporal 0.0075 experimental 0.0078 mechanics 0.0075 statistics 0.0074 correlations 0.0073 influence 0.0071 Table 4
MixtureparametersandmodesofpreferenceprofilesontheSushidataset.
π1=0.155 π2=0.194 π3=0.134 π4=0.194 π5=0.197 π6=0.126 fatty tuna fatty tuna fatty tuna fatty tuna fatty tuna fatty tuna shrimp tuna sea eel sea urchin tuna shrimp
salmon roe shrimp tuna salmon roe shrimp tuna sea eel squid shrimp shrimp squid sea eel squid egg squid sea eel sea eel squid tuna tuna roll tuna roll tuna tuna roll salmon roe
tuna roll sea eel salmon roe tuna roll salmon roe tuna roll
sea urchin cucumb. roll sea urchin squid sea urchin sea urchin
egg salmon roe egg egg cucumb. roll egg
cucumb. roll sea urchin cucumb. roll cucumb. roll egg cucumb. roll
with similar preferences. We evaluate a variant of the repeated insertion model in an experiment inspired by [29], on a dataset published in [30]. The data consists of 5000 permutations over M
=
10 Sushi ingredients, each permutation expressingthepreferencesofasurveyedperson.Following[29],weuse K=
6 preferenceprofiles,howeverweusetheRIM ratherthanaMallows model,andwetrainonthewholedataset.The parametersofthemodelare50/
K symmetricprior forthemixtureofprofiles,and0.
1 symmetricpriorforallcategoricaldistributionsinallprofiles.Weshow thePBprogramusedinTable 5,assumingthatthe
create_term
predicateisdefinedasinTable 2.Weare notawareofanyotherimplementationofRIMinaPPL,thereforewebrieflydescribetheprogram.Themixtureofprofiles is characterized byπ
,a setof K distributions,andforeach profilethere are M−
1 categorical distributionsthat specify the probabilitiesover thesetofpermutationsof M elements. Anobserved permutationis producedby selectinga latent profile, then generating that permutation by consecutivelyinserting elements froma permutation calledinsertion order, e.g.[
0,
1,
. . . ,
9]
,attherightposition,accordingto thedistributionsinthat profile.Therightpositionischosen usingtheinsert_rim
predicate,asnaïvelygeneratingallthepossiblepermutationsisintractable(andunnecessary).We run PB 10times for100iterations andaveragethe parameters. Foreach preference profile,we show its mixture parameter andits modeinTable 4.Theinference yieldssimilar conclusionsto [29]: thereisastrongpreferenceforfatty tuna,astrongdislikeofcucumberrollandastrongpositivecorrelationbetweensalmonroeandseaurchin.
6. Relatedwork
In thissection, we will briefly describe therelation betweenthe approachproposed in thispaperand other relevant methods. We beginwitheach of thetwo fundamental steps ofPB: 1) enumeration ofthe conditionalsample spaceand 2) samplingthereof,andconcludewithahigh-levelcomparisonwithotherprobabilisticprogramminglanguages.
The first stepofPB,the enumerationof theconditional sample spacethroughabductivelogic programming, couldbe compared to “logical inference” in ProbLog [9]. While both languagesaim togenerate a propositional formulaand com-pileit intoadecisiondiagram,“logicalinference” inPBisbasedonabductivelogicprogramming, whileProbLog grounds the relevant partsof theprobabilistic program.Moreover, in PBcompilation ofthe booleanformulas is performedusing (RO)BDDs,whileProbLogcanuseawiderrangeofdecisiondiagrams,e.g.sententialdecisiondiagrams(SDD),deterministic, decomposablenegationnormalform(d-DNNF).ThesedifferencesreflectthedifferentaimsofthetwoPPLs:ProbLogfocuses
Table 5
PBprogramforaRIMwithK=6 preferenceprofiles.
observe([5,0,3,4,6,9,8,1,7,2]). observe([0,9,6,3,7,2,8,1,5,4]). % ... 4998 ’observe’ facts ommited pb_dirichlet(8.33333333333, pi, 6, 1). pb_dirichlet(0.1, p2, 2, 6). pb_dirichlet(0.1, p7, 7, 6). pb_dirichlet(0.1, p3, 3, 6). pb_dirichlet(0.1, p8, 8, 6). pb_dirichlet(0.1, p4, 3, 6). pb_dirichlet(0.1, p9, 9, 6). pb_dirichlet(0.1, p5, 5, 6). pb_dirichlet(0.1, p10, 10, 6). pb_dirichlet(0.1, p6, 6, 6). pb_plate( [observe(Sample)], 1, [generate([0,1,2,3,4,5,6,7,8,9], Sample)] ). generate([H|T], Sample):-K in 1..6, pi(K, 1), generate(T, Sample, [H], 2, K). generate([], Sample, Sample, _Idx, _K). generate([ToIns|T], Sample, Ins, Idx, K)
:-% insert next element at Pos yielding a new list Ins1 append(_, [ToIns|Rest], Sample),
insert_rim(Rest, ToIns, Ins, Pos, Ins1), % make probabilistic choice
create_term(p, Idx, Pos, K, Pred), pb_call(Pred),
% increment position and recurse Idx1 is Idx+1,
generate(T, Sample, Ins1, Idx1, K). insert_rim([], ToIns, Ins, Pos, Ins1)
:-append(Ins, [ToIns], Ins1), length(Ins1, Pos).
insert_rim([H|_T], ToIns, Ins, Pos, Ins1) :-nth1(Pos, Ins, H),
nth1(Pos, Ins1, ToIns, Ins).
insert_rim([H|T] , ToIns, Ins, Pos, Ins1) :-\+member(H, Ins),
insert_rim(T, ToIns, Ins, Pos, Ins1).
onmodelswhere“logicalinference” needstobeefficient,andtheresultingrepresentation,thedecisiondiagrams,needto becompact,whilePBfocusesonmodelswhere“logicalinference”istypicallyeasy,howeveritmustbeappliedrepeatedly, accordingto the natureandthe numberof theobservations. However, infuture work,PB could benefitfromthe useof morecompactdecisiondiagrams.
ThesecondstepofPBisinspiredbytheuncollapsedGibbssamplingalgorithmfrom[11],whichwehaveadaptedto PB. However, samplingin thePB model,unlike PLP models, canbe performedusing collapsedGibbs sampling, an algorithm withfasterconvergencethattheuncollapsedversion,asshowninSection5.1.
InrelationtoChurch[1]andmanyotherrelatedPPLs,PBissimilarinthatitusesaTuring-completedeclarativelanguage, butthesetofprobabilisticprimitivesavailableinPBisveryrestrictedcomparedtoChurch.Ontheotherhand,inferencein discretemodels suchasLDAisdifficultinhighlyexpressive PPLs,whereasinPBinference istractableon variousdiscrete models.
Both PB and the logic-based PPL Alchemy [6] focus on discrete models, however they differ at a fundamental level dueto thefact thatthe probabilistic modelofPBis directed,whereas that ofAlchemyisundirected (Markovnetworks). Consequently,thespecificationofprobabilistic programsisalsodifferent:inAlchemy,programs areexpressedasweighted formulas, whereas in PB specifies models usingabductive logic programs where the abducibles representdraws from a categoricaldistribution with Dirichletpriors. Furthermore, by usingabductive logic programminginstead ofa first-order knowledgebase,PBcaneasilyencoderecursivegenerativemodels,suchasRIM.Itismuchlessobvioushowtodosousing Alchemy.
7. Conclusionsandfuturework
Inthis paper,we introduced PB,a probabilistic logic programminglanguage fordiscrete modelswith Dirichletpriors. This paperbridges thegap betweenlogical andprobabilistic inference in theconsidered class ofmodels, andaddresses issues onrepresentationof abductivesolutions andinference on“syntactically” identicalBDDs. The main contributionto representationistheconditionalADcompilation,whilethemaincontributiontoinferenceisthecollapsedGibbssampling algorithm thatgeneralizestheoneproposedforLDAin[24].
Wehaveshown,throughtheexperimentsinSection5,thatPByieldsreasonableinferenceresultsbothonsyntheticand realdatasets.
Infuturework,we hopetoexplore moreprobabilisticmodelsthat fitthePBparadigm,andtodesign,implement,and compareefficientalgorithmsforgeneralizedprobabilisticinferenceinPBmodels.
On theother hand,we wish torelax theimportantrestrictionto discretemodels usingDirichletprocesses,thatallow discretizationofanycontinuousdistributionspecifiedasthebasedistributionoftheprocess.
Appendix. Supplementarymaterial
Supplementary AppendicesA,BandCrelatedtothisarticlecanbefoundonlineathttp://dx.doi.org/10.1016/j.ijar.2016. 07.001.
References
[1] N.D.Goodman,V.K.Mansinghka,D.M.Roy,K.Bonawitz,J.B.Tenenbaum,Church:alanguageforgenerativemodels,in:UncertaintyinArtificial Intelli-gence,2008,pp. 220–229,http://danroy.org/papers/church_GooManRoyBonTen-UAI-2008.pdf.
[2]B.Paige,F.Wood,Acompilationtargetforprobabilisticprogramminglanguages,in:ICML,2014.
[3] D.Lunn, D.Spiegelhalter,A.Thomas,N.Best,TheBUGS project:evolution,critiqueand futuredirections,Stat.Med.28 (25) (2009)3049–3067, http://dx.doi.org/10.1002/sim.3680.
[4] StanDevelopmentTeam,StanModelingLanguageUsersGuideandReferenceManual,Version2.5.0,2014,http://mc-stan.org/. [5]A.Pfeffer,Figaro:anobject-orientedprobabilisticprogramminglanguage,in:CharlesRiverAnalyticsTechnicalReport,2009.
[6] P.Domingos,S.Kok,H.Poon,M.Richardson,P.Singla,UnifyinglogicalandstatisticalAI,in:Proceedingsofthe21stNationalConferenceonArtificial Intelligence,vol.1,AAAI’06,AAAIPress,2006,pp. 2–7,http://dl.acm.org/citation.cfm?id=1597538.1597540.
[7]B.Milch,B.Marthi,S.Russell,BLOG:relationalmodelingwithunknownobjects,in:ICML2004WorkshoponStatisticalRelationalLearningandIts Connections,2004,pp. 67–73.
[8]T.Sato,Y.Kameya,Newadvancesinlogic-basedprobabilisticmodelingbyprism,in:L.DeRaedt,P.Frasconi,K.Kersting,S.Muggleton(Eds.), Proba-bilisticInductiveLogicProgramming,in:LectureNotesinComputerScience,vol. 4911,Springer,BerlinHeidelberg,2008,pp. 118–155.
[9] D.Fierens,G.V.denBroeck,J.Renkens,D.S.Shterionov, B.Gutmann,I.Thon,G.Janssens, L.D.Raedt, Inferenceandlearninginprobabilisticlogic programsusingweightedbooleanformulas,CoRR,arXiv:1304.6810,http://arxiv.org/abs/1304.6810.
[10] A.C.Kakas,R.A.Kovalski,F.Toni,Abductivelogicprogramming,J.Log.Comput.2(1992)719–770,http://dx.doi.org/10.1093/logcom/2.6.719. [11] M. Ishihata, T. Sato, Bayesian inference for statistical abduction using Markov chain Monte Carlo, in: Proceedings of the 3rd Asian
Confer-ence on MachineLearning, ACML 2011, Taoyuan,Taiwan, November13–15,2011, 2011, pp. 81–96, http://www.jmlr.org/proceedings/papers/v20/ ishihata11/ishihata11.pdf.
[12]D.M.Blei,A.Y.Ng,M.I.Jordan,J.Lafferty,LatentDirichletallocation,J.Mach.Learn.Res.3(2003)2003.
[13] J.-P.Doignon,A.Pekeˇc,M.Regenwetter,Therepeatedinsertionmodelforrankings:missinglinkbetweentwosubsetchoicemodels,Psychometrika 69 (1)(2004)33–54,http://dx.doi.org/10.1007/BF02295838.
[14] A.D.Gordon,T.A.Henzinger,A.V.Nori,S.K.Rajamani,Probabilisticprogramming,in:InternationalConferenceonSoftwareEngineering(ICSEFutureof SoftwareEngineering),IEEE,2014,http://research.microsoft.com/apps/pubs/default.aspx?id=208585.
[15] W.L.Buntine,Operationsforlearningwithgraphicalmodels,J.Artif.Intell.Res.(JAIR)2(1994)159–225,http://dx.doi.org/10.1613/jair.62.
[16] L.D. Raedt, A. Kimmig, H. Toivonen, ProbLog: a probabilisticProlog and its application in link discovery, in: M.M. Veloso (Ed.), IJCAI, 2007, pp. 2462–2467,http://dblp.uni-trier.de/db/conf/ijcai/ijcai2007.html#RaedtKT07.
[17] A. Kimmig,AProbabilisticProlog anditsApplications(Eenprobabilistische prologenzijntoepassingen), Ph.D.thesis,LucdeRaedt (supervisor), InformaticsSection,DepartmentofComputerScience,FacultyofEngineeringScience,Nov.2010,https://lirias.kuleuven.be/handle/123456789/280932. [18] C.Turliuc,N.Maimari,A.Russo,K.Broda,Onminimalityandintegrityconstraintsinprobabilisticabduction,in:LogicforProgramming,Artificial
In-telligence,andReasoning—19thInternationalConference,Proceedings,LPAR-19,Stellenbosch,SouthAfrica,December14–19,2013,2013,pp. 759–775, http://dx.doi.org/10.1007/978-3-642-45221-5_51.
[19]K.L.Clark,Negationasfailure,in:LogicandDataBases,1977,pp. 293–322.
[20]M.Fitting,AKripke–Kleene semanticsforlogicprograms,J.Log.Program.2 (4)(1985)295–312.
[21] J.Ma,AbductivereasoningmoduleforSICStusprolog,http://www-dse.doc.ic.ac.uk/cgi-bin/moin.cgi/abduction,2012. [22] S.B.Akers,Binarydecisiondiagrams,IEEETrans.Comput.27 (6)(1978)509–516,http://dx.doi.org/10.1109/TC.1978.1675141.
[23] R. Bryant, Graph-based algorithms for boolean function manipulation, IEEE Trans. Comput. C-35 (8) (1986) 677–691, http://dx.doi.org/10.1109/ TC.1986.1676819.
[24] T.L. Griffiths, M. Steyvers, Finding scientific topics, Proc. Natl. Acad. Sci. USA 101 (suppl 1) (2004) 5228–5235, http://dx.doi.org/10.1073/pnas. 0307752101,http://www.pnas.org/content/101/suppl_1/5228.full.pdf,http://www.pnas.org/content/101/suppl_1/5228.abstract.
[25]E.Hörster,R.Lienhart,M.Slaney,Imageretrievalonlarge-scaleimagedatabases,in:Proceedingsofthe6thACMInternationalConferenceonImage andVideoRetrieval,CIVR’07,ACM,NewYork,NY,USA,2007,pp. 17–24.
[26] D.Andrzejewski,X.Zhu,M.Craven,B.Recht,Aframeworkforincorporatinggeneraldomainknowledgeintolatentdirichletallocationusingfirst-order logic,in:Proceedingsofthe22ndInternationalJointConferenceonArtificialIntelligence,IJCAI2011,Barcelona,Catalonia,Spain,July16–22,2011, 2011,pp. 1171–1177,http://ijcai.org/papers11/Papers/IJCAI11-200.pdf.
[27]K.Lang,Newsweeder:learningtofilternetnews,in:Proceedingsofthe12thInternationalMachineLearningConference,ML95,1995. [28]Y.W.Teh,M.I.Jordan,M.J.Beal,D.M.Blei,HierarchicalDirichletprocesses,J.Am.Stat.Assoc.101 (476)(2006)1566–1581.
[29] T. Lu,C.Boutilier,Effectivesamplingand learningformallowsmodelswith pairwise-preferencedata, J.Mach.Learn.Res.15(2014)3783–3829, http://jmlr.org/papers/v15/lu14a.html.