Procedia Computer Science 17 ( 2013 ) 506 – 513
1877-0509 © 2013 The Authors. Published by Elsevier B.V.
Selection and peer-review under responsibility of the organizers of the 2013 International Conference on Information Technology and Quantitative Management
doi: 10.1016/j.procs.2013.05.065
Information Technology and Quantitative Management (ITQM2013)
An EMM-based Approach for Text Classification
J.G.Liang
a*, X.F.Zhou
a, P.Liu
a, L.Guo
a, S.Bai
a,b aInstitute of Information Engineering Chinese Academy of Sciences , Beijing 100190, ChinabShanghai Stock Exchange, Shanghai 200120, China
Abstract
In this paper, a classification method named explicit Markov model is applied for text classification. Currently some machine learning technologies, such as support vector machine (SVM), have been discussed widely in text classification. However, these methods consider that any two features are independent and ignore the language structure information. Hidden Markov model is a powerful tool for sequence tagging problems. This paper presents a new method called explicit Markov model (EMM) which is based on HMM for text classification. EMM make better use of the context information between the observation symbols. Our experiments are conducted on three datasets: Reuter s 21578 R8 dataset, WebKB and Fudan University Chinese text classification corpus. Experimental results show that the performance of EMM is comparable to SVM for text classification.
© 2013 The Authors. Published by Elsevier B.V.
Selection and/or peer-review under responsibility of the organizers of the 2013 International Conference on Computational Science
Keywords: Type your keywords here, separated by semicolons ;
1.Introduction
Text classification plays an important role for managing huge amount of text documents in information retrieval, nature language, web mining and content security research fields. The task of text classification is to assign one or more predefined classes or topics to a natural text document according to the knowledge gained from text expression and feature dimension reduction at the training stage. Many efficient machine learning approaches have been used to text classification, such as Bayesian methods [1], decision trees [2], neural networks [3], k nearest neighbour (KNN) [4], and support vector machines (SVM) [5]. However, these methods base on the vector space method (VSM) without the application of the feature s context. Hidden Markov model (HMM) is a kind of sequence tagging model based on statistics. Context information can be considered in HMM.
* Corresponding author. Tel.: 86-010-82546749; fax: 86-010-82546701. E-mail address: [email protected].
© 2013 The Authors. Published by Elsevier B.V.
Selection and peer-review under responsibility of the organizers of the 2013 International Conference on Information Technology and Quantitative Management
Open access under CC BY-NC-ND license.
Hidden Markov Model was proposed by Baum and his group in the 1970s. Since then, HMM has been widely used in many various domains such as speech recognition [6], nature language process, information extraction [7], computational molecular Biology [8] and text classification [9] [10], etc. In the field of text classification, [9] combines 2 and improved TFIDF method to construct the output observation distribution. In the category process, the classifier uses forward-backward algorithm to obtain the probability of respective category and chooses the category label with the max probability as the final result. However, this method needs to train a classification for each category. The training process can be very time consuming. In this paper, a novel approach called explicit Markov model (EMM) that takes advantage of context information is proposed. In this model, an EMM is generated by learning from the training dataset. Given an input document, this model will serialize it according to observation symbols after feature selection by FS. Then, using decoding algorithm to decode this sequence, a predicted category will be output.
The remainder of this paper is organized as follows: Section 2 presents techniques to HMM. In Section 3 introduces our new text categorization approach. Section4 describes the experiments and obtains results. Finally, section 5 is the conclusion.
2.Hidden Markov Model
An HMM is a finite state automaton [11], and it is a doubly stochastic process with an underlying stochastic process that is not observable (it is hidden), but can only be observed through another set of stochastic processes that produce the sequence of observed symbols [12]. A discrete HMM consists of a finite set of states, a finite set of observations, two conditional probability distributions and the initial state distribution. States in HMM are uncertain and invisible, which can only be observed through another stochastic process that produce the sequence of observed symbols.
An HMM can be defined as a quintuple, (S,V,A,B, ). Formally, we can describe an HMM as follows:
(1) S (S1,S2,...,SN 1,SN), N is the number of the states in S;
(2) V (V1,V2,...,VM 1,VM), M is the number of the observations in V;
(3) The matrix of state transition probability A {aij P(qt Sj|qt 1 Si), 1 i,j N}, 1
1 N j
ij
a ;
(4) The matrix of observation symbol emission probability B {biO(k)) P(Ot Vk|qt Si),
} 1 , 1 i N k M , 1 1 ) ( M k biOk ;
(5) The initial state distribution { i P(q1 Si),1 i N}, 1
1 N i
i .
Given the form of the HMM discussed in the previous section, there are three key problems that must be solved for the model to be useful in real world applications. These problems are the following:
(1) Evaluation problem: given a sequence of observations O O1,O2,...,OT 1 ,OT and a
model (S,V,A,B, ), how can we calculateP(O| )? This problem can be solved by forward algorithm or backward algorithm.
(2) Decoding problem: given a observation sequenceO O1,O2,...,OT 1,OT , how to determine a hidden
state sequence q q1,q2,...,qT 1,qT which is most likely to generateO? This problem can be solved by
Viterbi algorithm.
(3) Learning problem: how can we adjust the model parameters (S,V,A,B, ) to maximizeP(O| )? This problem can be solved by Baum-Welch algorithm.
3.Text Classification based on EMM
In this section, we propose a classifier which called explicit Markov model (EMM) based on HMM. The process of EMM classification include learning the parameters of the model from the training dataset after the pre-processing of features selection, generating the observation symbol sequence and calculate each probability of the categories, and choosing the category which has the maximum probability.
3.1. Explicit Markov model
In an HMM, the state is hidden, what can be observed is observation symbol. When used as a classifier, the state is explicit, it can be observed directly. As a result, we call the new model as explicit Markov model (EMM).
This EMM classifier is based on the following hypothesis: the current observation depends on the last observation and the current state. As a result, we should reconstruct HMM to be a classifier. We denote
) , , , ,
(SV AB as an EMM classifier, which can be described as follows: (1) C (C1,C2,...,CN 1,CN), N is the number of the categories in C; (2) W (W1,W2,...,WM 1,WM), M is the number of the features in W;
(3) A {a((Ok))(O) P(Ot Wj|Ot 1 Wi,qt Ck),1 i,j M,1 k N} j i ; (4) B {bi(Ok) P(qt Ci|Ot Wk),1 i N,1 k M}; (5) { i(O) P(q1 Ci|O1 Wk),1 i N,1 k M} k . 3.2. Feature selection
There are many methods used for feature selection, such as TF-IDF, information gain, mutual information, and 2 statistics. In this paper, we put forward a new method to select the most useful features. FS(, )
i
C t is defined to measure the relevance between feature t and the category Ci.
Ci t i F A F D TF B A B A C t, ) 2* * * 1( ) 1( )* , ( FS
A is the percentage of documents which contains feature t belonging to category Ci. B is the percentage of documents which contains feature t in the whole dataset. The first part of the formula is to calculate the harmonic mean of A and B. D is the percentage of documents which contains feature t in negative categories.
1
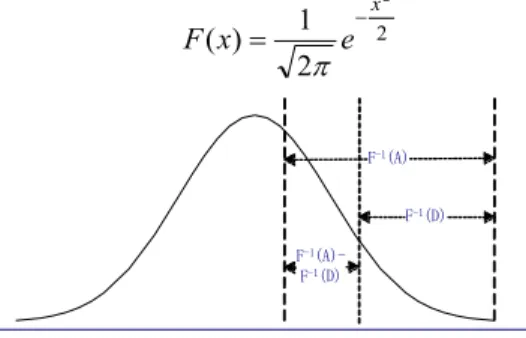
F is the standard Normal distribution s inverse cumulative probability function [13].
2 2 2 1 ) ( x e x F
Fig. 1 function graph of F )$
)'
)$ )'
From Fig. 1, we know that if the feature has a strong prevalence with a category, it should have a bigger area under the curve.
TF is term frequency based on the sub-linear scale transform method. TF is computed as follows: i i C t C t N TF, , log 1 others Nt,Ci 0, Here is a smooth coefficient.
After all the above steps are completed, we choose the features which have the top highest FS difference as the observation symbols for the text categorization task. This step can be expressed as:
)}} , ( min{ )} , ( {max{ max arg ) ( FS 1 max i N i i C t FS C t FS t 3.3. Parameters learning
In the training process, because of the limited number of corpuses for our experiments, it may lead to engender a sparse matrix. To avoid this, smoothing is necessary. We use supervised learning method to calculate the parameters as follow:
1 0 0 ) , , ( * ) , , ( * ) , , ( 1 1 1 ) ( ) )( ( elsep p C W W Transition if p C W W Transition p C W W Transition a M i j k m k m i k j i k O Oi j
where Transition(Wi,Wj,Ck) is the number of the transition from Wi to Wjin category Ck.
1 0 0 ) , ( * ) , ( * ) , ( b 1 2 2 ) ( else p p C W Emition if p C W Emition p C W Emition i k N n n i k i O i k
where Emition(Wi,Ck) is the number of Wi occurring in category Ck.
1 0 0 ) , ( * ) , ( * ) , ( 1 3 3 ) ( else p p C W tion Initializa if p C W tion Initializa p C W tion Initializa i k N n n i k i O i k
where Initialization(Wi,Ck) is the number of Wi being the first observation in category Ck. 3.4. Algorithm
We consider a text document as a sequence of observation symbols during the classification process. Given
T
T O
O O O
O 1, 2,..., 1, and (S,V,A,B, ), we use decoding algorithm to calculate the probabilities of
O being categoryCk(1 k N), and then choose the category, which has the maximum probability, as the document s category. We define t(k) as:
T N k O O O O C k) P( k| , ,..., t , t ),1 1 t ( 1 2 1 t
The algorithm may be summarized formally as: Algorithm
Input: O O1,O2,...,OT 1,OT , observation symbol sequence of the document;
Procedure: Step1: Initialization for k : 1 to N ) ( ) ( k 1(k) O1 *bkO1 end for Step2: Induction for t : 2 to T for k : 1 to N ) ( ) ( ) )( ( 1(k)* * ) k ( 1 t t t kO k O O t t a b end for end for Step3: Termination P
max
(k) 1 * T N k qarg
max
(k) 1 * T N k Return q*; 4.ExperimentsThree data sets, Fudan University Chinese text classification corpus, WebKB, and Reuters-21578 R8 are used in this paper. The Chinese corpus contains 20 categories. To reduce the computational requirements, we choose 5 categories of documents, which are total 4,000 documents. The documents in each category are further randomly split into two data sets, the first one consists of 600 documents for training, and the other contains 200 for testing. WebKB consisted of 4 categories. We randomly select 300 training documents and 100 test documents from each category to form a target data set. R8 is part of Reuters-21578. The data in training set and test set of R8 dataset are shown in Table 1. From Table 1, it can be seen that R8 is partitioned unevenly across 8 different categories and category grain and ship are small samples.
Table 1 summary of R8 dataset
class #train docs #test docs total # docs
acq 1596 696 2292 crude 253 121 374 earn 2840 1083 3923 grain 41 10 51 interest 190 81 271 money-fx 206 87 293 ship 108 36 144 trade 251 75 326 Total 5485 2189 7674
We use FS to optimally select top k features on average after removing stop words and applying stemming. The performance of EMM classification algorithm has been measured using Precision and Recall.
In a document, words in the beginning part are much more important than the middle part for they carry more information. In other words, observation symbols in the top can make greater contribution than symbols in the middle. This can be confirmed by the relevant data from Figure 2. Even taking 10 observations, EMM can perform well. The lengths of observation symbols in R8 after feature selection are evener and shorter than Fudan corpus. And the length distribution of WebKB is not even, some samples are very long meanwhile some
very short. This affects the precision in some degree. From Fig. 2, we can easily draw the conclusion that different lengths lead to different results. In the experiments, we choose the length which observes the maximum precision. 10 20 30 40 50 0.75 0.80 0.85 0.90 0.95 Precision
Length of observation symbols sequence
Fudan R8 Webkb
Fig. 2 precision comparisons of different length
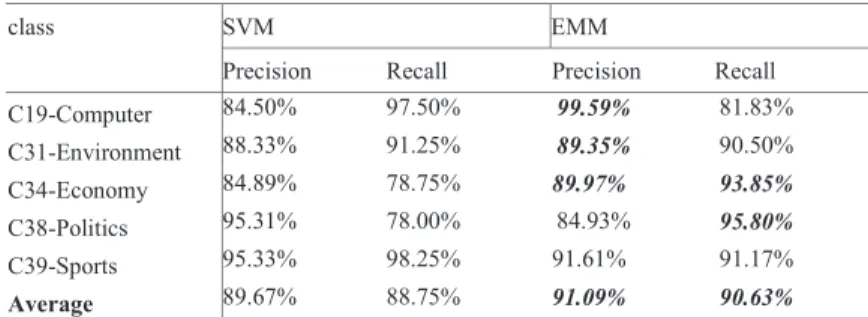
The experiments evaluated the performance of EMM compared to SVM. Table 2, 3, and 4 depict the average precisions and recalls on three datasets. The EMM method could achieve a high precision and a high recall at the same time. Table 2 presents the results of Fudan University corpus. The results show that the EMM method outperforms SVM on Chinese corpus. The precision is roughly 90% and the variance of precision is very small. Table 2 comparisons of different methods on Chinese corpus dataset
class SVM EMM
Precision Recall Precision Recall
C19-Computer 84.50% 97.50% 99.59% 81.83% C31-Environment 88.33% 91.25% 89.35% 90.50% C34-Economy 84.89% 78.75% 89.97% 93.85% C38-Politics 95.31% 78.00% 84.93% 95.80% C39-Sports 95.33% 98.25% 91.61% 91.17% Average 89.67% 88.75% 91.09% 90.63%
Table 3 comparisons of different methods on WebKB dataset
class SVM EMM
Precision Recall Precision Recall
project 85.62% 79.24% 87.36% 87.63%
course 96.44% 84.00% 92.67% 92.00%
faculty 91.70% 81.35% 80.20% 91.68%
student 73.49% 86.16% 92.89% 79.56%
Average 86.81% 82.69% 88.28% 87.72%
Table 3 shows the classification performances of SVM and EMM on WebKB dataset. Notice that on this dataset, some experimental results of EMM are contrary to that of SVM. For each category, SVM get a higher
precision and a lower recall, meanwhile EMM could achieve a higher recall and a lower precision. On the two datasets, EMM has a higher precision, and it is 2% higher than SVM.
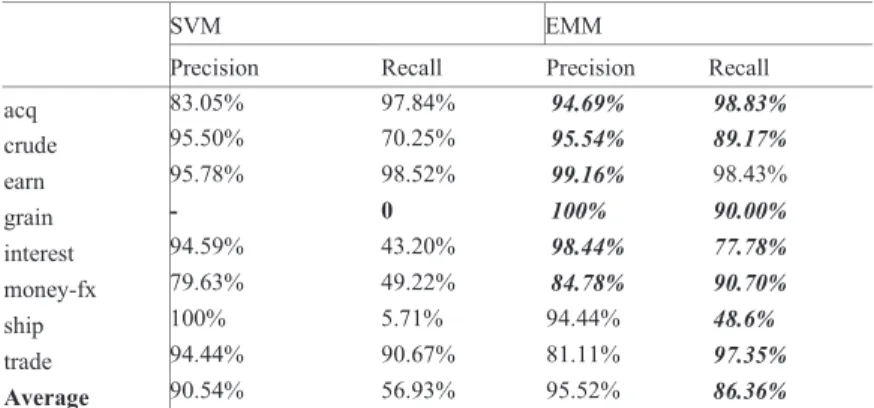
In Table 4, the symbol - means there is no test document predicted as grain . The reason may be that SVM fails to find or find fewer support vectors for grain and its negative categories. But EMM can do it well. It just because that EMM can keep every probability learned from training dataset, even a very small probability. Both methods have higher precisions when predict category ship and lower recall. It means that very few documents are predicted as ship and basically they are rightly predicted. These results show that EMM performs far better than SVM when processing uneven dataset.
Table 4 comparisons of different methods on R8 dataset
SVM EMM
Precision Recall Precision Recall
acq 83.05% 97.84% 94.69% 98.83% crude 95.50% 70.25% 95.54% 89.17% earn 95.78% 98.52% 99.16% 98.43% grain - 0 100% 90.00% interest 94.59% 43.20% 98.44% 77.78% money-fx 79.63% 49.22% 84.78% 90.70% ship 100% 5.71% 94.44% 48.6% trade 94.44% 90.67% 81.11% 97.35% Average 90.54% 56.93% 95.52% 86.36%
Comparing the results reported in Table 2, Table 3, and Table 4, we find EMM has a good performance to be a classifier in both Chinese and English corpora, even better than SVM in some categories. SVM is unstable with small training samples, but EMM can work smoothly and effectively.
The training time and classification time of EMM and SVM on the three dataset are detailed in Table 5. Comparing training time and classification time, we can conclude that EMM is much shorter than SVM. The time that SVM needs is about one order of magnitude higher than EMM. Because the time complexity of EMM is linear, however, SVM is nonlinear.
Table 5 comparisons of different methods on R8 dataset
dataset mthod training time(ns) classification time(ns)
WebKB SVM 4,804,498,287 2,013,471,437 HMM 117,474,292 29,721,742 Chinese corpus SVM 134,362,456,801 7,689,443,354 HMM 1,131,429,601 218,314,925 R8 SVM 49,148,567,658 184,778,655 HMM 19,342,844,146 65,343,822 5.Conclusion
This paper introduces a classification method, explicit Markov model, for text classification. A new method is proposed to select effective features. Explicit Markov model make use of the context between observation symbols. EMM calculates the probability of the observation sequence given a category with the decoding algorithm and considers that the maximum one is the category. On three public testing datasets, EMM shows good performance for text categorization.
Acknowledgements
This work was supported by National Nature Science Foundation of China (No. 61202226), Strategic Priority Research Program of Chinese Academy of Sciences (XDA06030602), National 863 Program (No. 2011AA010703).
References
[1] Mouratis, T., Kotsiantis, S. Increasing the Accuracy of Discriminative of Multinomial Bayesian Classifier in Text Classification. 4th International Conference on Computer Sciences and Convergence Information Technology. 2009, p1246-1251.
[2] Yu Wang, Zheng-Ou Wang. Text categorization rule extraction based on fuzzy decision tree. Proceedings of 2005 International Conference on Machine Learning and Cybernetics. 2005, p2122 2127.
[3] Zhihang Chen, Chengwen Ni, Murphey, Y.L. Neural Network Approaches for Text Document Categorization. International Joint Conference on Neural Networks, 2006, p1054-1060.
[4] Soucy, P., Mineau, G.W. A simple KNN algorithm for text categorization. Proceedings IEEE International Conference on Data Mining. 2001, p647-648.
[5] Ziqiang Wang; Xu Qian. Text Categorization Based on LDA and SVM. 2008 International Conference on Computer Science and Software Engineering. 2008, p674-677.
[6] Takiguchi, T., Nakamura, S., Shikano, K. HMM-separation-based speech recognition for a distant moving speaker. Speech and Audio Processing. 2001, 9(2):127-140.
[7] Cailan Zhou, Shasha Li. Research of Information Extraction Algorithm based on Hidden Markov Model. 2nd International Conference on Information Science and Engineering. 2010, p1-4.
[8] Goutsias, J. A hidden Markov model for transcriptional regulation in single cells. Computational Biology and Bioinformatics.2006, 3(1):57-71.
[9] Text classification algorithm based on hidden Markov model. Jian Yang, Haihang Wang. Journal of Computer Applications, 2010, 30(9):2348-2350.
[10] Research on Hidden Markov Model-based Text Categorization Process. Kairong Li, Guixiang Chen, Jilin Cheng. International Journal of Digital Content Technology and its Applications, 2011, 5(6):244-251.
[11] Andrew McCallum, Dayne Freitag, Fernando C. N. Pereira. Maximum Entropy Markov Models for Information Extraction and Segmentation, Proceedings of the 17th International Conference on Machine Learning, p.591-598, June 29-July 02, 2000.
[12] L. R. Rabine An introduction to hidden Markov models. IEEE Acoustic Speech and Signal Processing Magazine, 1986, 3(1):4-16. [13] Forman G. An extensive empirical study of feature selection metrics for text classification. Journal of Machine Learning Research,