434 | P a g e
Applications and Analysis of Machine Learning
Techniques for Plagiarism detection and Semantic
Integration
Neetu Rani
ABSRRACT
Plagiarism identification is increasing expanding significance because of prerequisites for honesty in
instruction. The current research has explored the issue of plagiarism location with a differing level of
achievement. The writing uncovered that there are two primary techniques for recognizing plagiarism, to
be specific extraneous and inherent. The creator has contemplated two novel ways to deal with address
both of these strategies. Right off the bat a novel extraneous technique for identifying counterfeiting is
talked about. The strategy depends on four surely understood methods in particular Bag of Words
(BOW), Latent Semantic Analysis (LSA), Stylometry and Support Vector Machines (SVM). The LSA
application was tweaked to take in the stylometric highlights (most regular words) to portray the report
initiation. The examination uncovered that LSA based stylometry has beated the customary LSA
application. Bolster vector machine based calculations were utilized to play out the characterization
method to anticipate which writer has composed a specific book being tried. The examined strategy has
effectively tended to the confinements of semantic qualities and distinguished the record source by
allocating the book being tried to the correct writer much of the time.
Keywords: machine learning, semantic, plagiarism, detection.
I.INTRODUCTION
Plagiarism location and authorship analysis approaches have a long history of endeavors to enhance their
execution in recognizing content abuse and distinguishing the creator of mysterious content. Be that as it may,
notwithstanding impressive work in enhancing such strategies, by utilizing diverse kinds of highlights and an
extensive variety of systems, the execution of these techniques is as yet inadmissible now and again of
plagiarism location. The primary objective of this paper is to examine those cases and propose another way to
deal with address unoriginality location successfully by joining both customary and machine learning strategies.
This paper centers around content counterfeiting identification difficulties and features a portion of the
restrictions of the current plagiarism recognition instruments. The paper additionally talks about the examination
foundation, the exploration issue and the inspiration for the exploration. Moreover, this paper introduces the
435 | P a g e
The simplicity of sharing on the web data in this period of computerized correspondence has supported theabuse of content and the predominance of plagiarism. Scholastic bodies and logical distributing organizations
are assuming a dynamic part in distinguishing counterfeiting keeping in mind the end goal to keep up the
trustworthiness of scholarly productions. Redfern and Barnwell (2009) brought up that numerous instances of
scholastic work put together by understudies contain some level of appropriated material. Roig (2001) detailed
that up to 60% of understudy assignments contain some level of counterfeited material. Barely any years after
the fact, the worldwide focus of scholarly honesty (ICAI) distributed that 86% of understudies were associated
with some type of plagiarism. Huge distributing organizations, for example, Springer and Elsevier, asserted that
6% - 23% of articles were rejected because of the generous rate in the covering of data between papers showed
that 25.8% of submitted articles for distributing in China are considered to have an impressive level of written
falsification. The above insights and numerous more present unmistakably that the plagiarism issue is
developing and being exacerbated in scholarly work. A notable report by Maurer, Kappe, and Zaka (2006) and
took after by Maurer and Zaka (2007) gave an exhaustive provide details regarding a portion of the difficulties
of unoriginality location frameworks, for example, Turnitin© and Copycatch, and noted down how
summarizing frequently renders these apparatuses ineffectual [3].
The creators uncovered that current business discovery apparatuses were to a great extent unfit to adapt to
equivalent words, broad rewording and cross-lingual plagiarism, bringing about various written falsification
cases going undetected. They additionally prescribed the utilization of a proficient calculation to remove
instructive highlights previously running a half breed calculation, that can work productively on datasets of little
archives. The two most generally perceived techniques for written falsification discovery are extraneous and
inborn. However, the dominant part of existing recognition devices (industrially or uninhibitedly accessible)
utilize extraneous strategies and performed indistinguishable content coordinating. Turnitin© and Cross-check,
the main plagiarism identification programming in most scholarly organizations and distributing firms, are as
yet confronting huge difficulties in recognizing phonetic changes, for example, supplanting words by their
equivalent words. They were likewise censured attributable to their helplessness for expanding the quantities of
false positives (i.e. at the point when cases are distinguished as appropriated however in actuality are definitely
not). Accordingly they are dependably needing human intercession to finish choices. An extensive variety of
concentrates concentrated on inquiring about and creating strategies for viably battling written falsification.
Nonetheless, there is absence of viable plagiarism recognition techniques [2].
II.LITERATURE REVIEW
The past paper has talked about the inspiration for this work by displaying the issue articulation. The point and
destinations are additionally talked about with a specific end goal to deliver the issue identified with plagiarism
identification. This paper will additionally talk about the issue of plagiarism location and present various
existing methodologies which intended to address this issue with changing degrees of accomplishment. This
paper will likewise talk about the qualities and confinements of the current methodologies. Written falsification
436 | P a g e
content examination methods to surmise the initiation of suspicious writings. In conventional origininvestigation, a suspicious content is ascribed to one creator, while given gathering of creators with their literary
examples (Sebastian 2002). The creation investigation approaches have originated from a semantic root called
stylometry which alludes to the field of study examining the writer's composition style in light of insights by
utilizing registering calculations (Abbasi, and Chen, 2008). Stylometry expands on an idea that each writer has
indispensable composition propensities that can't be imitated which are known as etymological highlights or
characteristics [4].
Plagiarism recognition frameworks really started as discovery instruments for multiplechoice evaluations
(Angoff, 1974) and PC source code (Ottenstein, 1976). Preceding plagiarism location in regular dialects, code
clones and programming abuse identification had existed since the 1970s. Around then, various investigations
endeavored the identification of appropriated programming codes and calculations (Ottenstein, 1976. From that
point, plagiarism identification in normal dialects through measurable or mechanized techniques started to pick
up fame around 1990, established by investigations of duplicate discovery systems in advanced records. In the
vicinity of 1990 and 2000, most counterfeiting frameworks created were gone for recognizing programming
code unoriginality, and just a couple of concentrates concentrated on plagiarism discovery for composed
writings (Lathrop and Foss, 2000). A model known as COPS was a case of these early created location
approaches for composed writings, intended to recognize incomplete or finish duplicates of computerized
records utilizing sentence-level coordinating (Brin et al., 1995). In spite of the fact that the series of sentences in
each archive were coordinated against different successions in the more extensive records, this sentence-level
coordinating methodology appeared to be ineffectual at recognizing fractional sentence covers. Because of this
intrinsic restriction, Shivakumar and Garcia-Molina (1995, 1996) talked about another model known as SCAM,
as an augmentation to COPS. Trick presented, as a pre-handling step, the evacuation of both regular words and
stop words, rather guaranteeing the correlation of writings as covering arrangements of words or passages [5].
Another unoriginality discovery device that rose at the time was the YAP3 instrument (Wise, 1996), which was
particularly intended to distinguish likenesses in programming code. As an organized metric comparability
identification framework, YAP3 used the Running-Karp-Rabin Greedy-String Tiling (RKR-GST) calculation
which is an adjustment of the Longest Common Subsequence (LCS) calculation. This calculation was intended
to manage situations where liars have endeavored the reordering of content groupings, which is conceivable in
light of the fact that the apparatus permits an insignificant match close by a maximal match length between
writings. Sadly, the YAP3 instrument and the RKR-GST calculation were principally tried on PC source code.
At the end of the day, their viability in composed writings was yet to be checked at the time and further analyses
were expected to assess this. The current advancements in related fields, for example, machine learning,
information mining, computational semantics, and data recovery (IR) has affected the exploration on
computerized plagiarism recognition in composed writings. The effects and advancement of the previously
437 | P a g e
From the year 2000, the field of written falsification location has seen an expansion in the quantity of newplagiarism recognition apparatuses, systems and strategies for usage. A critical number of researchers and
research establishments started to give careful consideration to the issue of composed content unoriginality
identification. This is obvious from the development in the quantity of business unoriginality discovery
frameworks accessible on the web, from as meager as five out of 2000 to around 47 out of 2010 (Kohler and
Weber-Wulff, 2010). The greater part of the current unoriginality discovery investigate basically used non-NLP
(Natural Language Processing) based methodologies and identification approaches were generally deficient in
conveying the ultimate results on written falsification cases (Eisa, Salim and Alzahrani, 2015). Human judgment
was regularly required at last (Lukashenko, Graudina, and Grundspenkis , 2007; Ramnial, Panchoo and
Pudaruth, 2016). In an examination that planned to audit existing plagiarism apparatuses and innovations,
Clough (2000) featured a few related fields that may improve the comprehension of written falsification
identification. Clough (2003) likewise inspected the idea of unoriginality in connection to the issue of
multilingual written falsification recognition and proposed the utilization of machine learning strategies and
Natural Language Processing methods as future changes in plagiarism identification undertakings. Bull et al.
(2001) assessed five of the early plagiarism recognition frameworks in view of a specialized evaluation of their
exhibitions, utilizing proposals of the Joint Information Systems Committee (JISC). The assessed frameworks
incorporate CopyCatch, Turnitin©, Findsame, WordCHECK and EVE2. The creators suggested doing further
trials on three of the frameworks, to be specific: CopyCatch, EVE2 and Turnitin© as far as enhancing their
capacity to deal with bigger datasets and to make identifications from different sources. In another pilot
concentrate to evaluate the utilization of Turnitin© in the instructive setting, Chester (2001) prescribed and
affirmed of Turnitin© as a suitable plagiarism identification apparatus for advanced education organizations
over the UK. In any case, consequent general client criticism on the device appeared to be unsuitable as
Turnitin© did not have the capacity to deal with revamping or muddling writings viably [7].
Maurer et al. (2006) and Maurer and Zaka (2007) gave an exhaustive provide details regarding a portion of the
difficulties of written falsification recognition frameworks, for example, Turnitin© and Copycatch, and noted
down how rewording frequently renders these devices less powerful. The creators uncovered that current
business discovery instruments are to a great extent unfit to adapt to equivalent words, broad rewording and
cross-lingual written falsification, bringing about various plagiarism cases going undetected. They additionally
suggested the utilization of an effective calculation to remove useful highlights previously running a crossover
calculation that can work productively on the diminished dataset. This endures the sensible use of incorporation
between profound content examination methods and others which can be portrayed externally. For this
examination the outward methodologies are looked into in view of two classifications: the content coordinating
438 | P a g e
III.TECHNIQUE FOR PLAGIARISM DETECTION
This paper shows a foundation of the strategies that were featured from writing and talks about their
experimental establishment. It additionally with the end goal of this exploration investigates the key thoughts,
reveals insight into every strategy and talks about its basic ideas. The writing survey demonstrates that a large
portion of the robotized plagiarism location strategies depend on string coordinating procedures and they
disregard the semantic connection between the copied content and the reference archive. Henceforth the
semantics of the content is as yet a test for all bolstered unoriginality location apparatuses. This paper talks
about an outward strategy for plagiarism recognition to address the hole that has been featured in the writing.
This hole in existing outward location strategies has focused on the issue of recognizing content semantics and
distinguishing its initiation. So as to gauge the closeness between two writings, existing instruments depend on
indistinguishable content coordinating strategies utilizing distinctive calculations. So as to address these holes a
strategy was talked about that incorporates the joining of the sack of words (BOW), Latent Semantic Analysis
(LSA), Stylometry and Support Vector Machines (SVM) procedures [9].
The center segment of this strategy is LSA which can be distinguished as a shrewd system that investigations
words co-event and catches the inactive relationship between them so as to uncover content semantics
(Deerwester et al., 1990). This strategy shows another application for LSA to address the content semantics
utilizing its inward procedures. It was likewise tweaked to take-in the stylometric includes with a specific end
goal to upgrade the characterization system in distinguishing the content initiation (class). Stylometry has
constrained capacity in this technique as its cooperation has been spoken to by the utilization of the most
well-known words. BOW was utilized as an underlying tokenisation method for all content. BOW tokenises content
into all content words without wiping out any class of words. With this method the books for all writers were
prepared by their right marks, the preparation for each book for every one of the 292 books being performed. At
that point each book is tried to be arranged to the right writer (class).
This strategy was based on the presumption that each test book is contrasted with a gathering that incorporate
books from a similar writer and books from different writers. The execution of the talked about strategy is
estimated on the quantity of books that were ordered to the right writer. SVM was utilized keeping in mind the
end goal to construct the classifier demonstrate. Using LSA for outward written falsification location was talked
about by Ceska (2009), the investigation that empowered this approach. However Ceska in his paper was
restricted to applying the conventional LSA and estimating its execution for identifying content semantics. The
commitment of this talked about strategy was to consolidate stylometry which managed the shallow qualities of
a writer's composition style with LSA. LSA is characterized as a profound content analyser that can manage
inert semantic content attribution. The incorporation between both of strategies is to deal with setting up a useful
arrangement of literary highlights for grouping purposes. The work proposes a novel exploratory procedure for
testing the execution of the talked about approach. This strategy depends upon the CEN (corpus of English
439 | P a g e
The talked about approach plans to answer the essential research question as expressed in paper 1, theexploration question is How powerful is the utilization of inert semantic investigation when joined with
stylometry and machine learning methods for the undertaking of recognizing semantic examples and
distinguishing which creator composed the record, when a reference accumulation is accessible for correlation?
Whatever remains of the paper is sorted out as takes after: Section 4.2 depicts the examined approach, its
different parts and their execution subtle elements. Segment 4.3 presents a rundown of the work in this paper
[10].
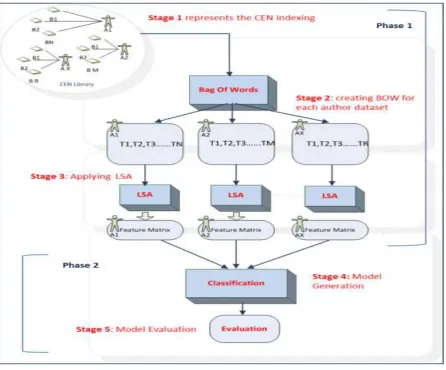
SVM is a managed learning method utilized for grouping undertaking. A few parts have been talked about as
appeared in Figure (1), every segment has a particular computational capacity to achieve the model fitting.
Figure 1: extrinsic method for plagiarism detection together with the main components; BOW, LSA and
440 | P a g e
LATENT SEMANTIC ANALYSIS (LSA)An introductory step for dataset representation using BOW technique was used to tokenise the text into words
accompanying with their frequencies. With a specific end goal to decrease the meager condition of the
term-archive includes that was come about because of BOW, inert semantic investigation (LSA) was connected. LSA
is utilized as a dimensionality lessening to diminish the measure of the highlights space from a BOW with a
specific end goal to make "inactive" relevant hints about the significance of words. These logical pieces of
information depend on the co-event of words in a specific setting. The smaller component space is intended to
be trimmed of overabundance commotion (irregular relationship from chance cases of co-event). The objective
is to accomplish this smallness without losing a huge part of data. The more reasonable highlights framework is
additionally less demanding to gone through classifiers, since it requires less registering time and can be
prepared effectively. Outward counterfeiting location is most like content grouping procedures since it thinks
about the suspicious information report (e.g., inquiry) to a gathering of known records. In the examined
approach, two content delegates' arrangements of highlights: most basic words (MCW) and substance words
(CW) were talked about. MCW are characterized as dialect components without (much) natural significance.
Their basic role is to elucidate the connection between words' classes in various printed parts and considered as
separating highlights for creator's style (Stamatatos, 2009). CW are antiques of specific written work demeanors
or have a place with particular themes, for example, things, verbs, descriptive words, and modifiers which
portray a few items, activities, or statuses. They stand out from the MCW in capacities, moreover they help to
portray content setting however not creator's style.
IV.CONCLUSION
The communication between users and detection tools do not go much further than highlighting the similarity
between submitted texts and the repositories of plagiarism tools. Truth be told the devices have strayed a long
way from their main goal to secure the logical condition and stress moral ideas. Actually they are constraining
the clients to discover diverse routes keeping in mind the end goal to beguile the checking calculations now and
again. Moreover they have neglected to impact the consciousness of clients viewing unoriginality as they are
focusing on the impersonation of the dialect as opposed to the importance of the content. In the examination
condition, analysts are relied upon to create novel information in a specific train; along these lines the use of
words is a method for communicating the contemplations, developments, proposals, methodologies and results
related with that learning. The current plagiarism location devices focused on the examples of dialect without
considering the center of the novel information or how this learning was produced. The restrictions in existing
discovery apparatuses were clear even in the location of the words themselves. They are constrained when
managing setting that can be implanted in a word. Equivalent words (i.e. different words for a similar
441 | P a g e
REFRENCES
[1] Al Batineh, M.S. (2015) Latent Semantic Analysis, Corpus stylistics and Machine Learning Stylometry
for Translational and Authorial Style Analysis: The Case of Denys Johnson-Davies’ Translations into
English (Doctoral dissertation, Kent State University).
[2] Alsallal, M., Iqbal, R., Amin, S. and James, A., (2013) ‘Intrinsic Plagiarism Detection Using Latent
Semantic Indexing And Stylometry’. IEEE. In Developments in eSystems Engineering (DeSE), 2013
Sixth International Conference on 145-150
[3] Boukhaled, M.A. and Ganascia, J.G., (2015) ‘Using Function Words for Authorship Attribution:
Bag-Of-Words vs. Sequential Rules’. Natural Language Processing and Cognitive Science: Proceedings 2014,
115.
[4] Britt, M.A., Wiemer-Hastings, P., Larson, A.A. and Perfetti, C.A., (2004) ‘Using Intelligent Feedback To
Improve Sourcing And Integration In Students' Essays’. International Journal of Artificial Intelligence in
Education 14 (3, 4), 359-374.
[5] Clough, P., (2000) ‘Plagiarism In Natural And Programming Languages: An Overview Of Current Tools
And Technologies’. Plagiarism – overview and current tools, 1-13.
[6] De Jager, K. and Brown, C., (2010) ‘The Tangled Web: Investigating Academics’ views of plagiarism at
the University of Cape Town’. Studies in Higher Education, 35 (5), 513-528.
[7] Diederich, J., Kindermann, J., Leopold, E. and Paass, G. (2003) Authorship Attribution with Support
Vector Machines. Applied intelligence 19 (1-2), 109-123.
[8] Frontini, F., Boukhaled, M.A. and Ganascia, J.G. (2015) Linguistic Pattern Extraction and Analysis for
Classic French Plays. In Presentation at the CONSCILA Workshop, Paris.
[9] Gipp, B. and Meuschke, N., (2011) ‘Citation Pattern Matching Algorithms For Citation-Based Plagiarism
Detection: Greedy Citation Tiling, Citation Chunking And Longest Common Citation Sequence. In
Proceedings of the 11th ACM symposium on Document engineering ( 249-258).
[10] Matthews, R.A. and Merriam, T.V., (1994) ‘Neural Computation In Stylometry I: An Application To The