Towards Building Contextual Representations of
Word Senses Using Statistical M o d e l s
Claudia Leacock, l Geoffrey Towdl ~ and Ellen Voorhees 2 I Peinceton University
leacockOclarity.princeton, edu 2Siemens Corporate Research, Inc.
towellOlearning.scr.siemenJ, com, ellenOlearning.scr.siemenJ, com
A b s t r a c t
Automatic corpus-based sense resolution, or sense dlsambiguation, techniques tend to focus either on very local context or on topical context. Both components axe needed for word sense resolution. A contextual representation of a word sense consists of top- ical context and local context. Our goal is to construct contextual representations by automatically extracting topical and local information from textual corpora. We re- view an experiment evaluating three statistical classifiers that automatically extract topical context. An experiment designed to examine human subject performance with similar input is described. Finally, we investigate a method for automatically extracting local context from a corpus. Preliminary results show improved perfor- m s , n c e .
1
C o n t e x t u a l Representations
T h e g o a l of a u t o m a t i c sense resolution is to acquire a conteztual representation o f word senses. A c o n t e x t u a l r e p r e s e n t a t i o n , as defined by Miller a n d Charles [7], is a c h a r a c t e r i - z a t i o n of the linguistic c o n t e x t s in which a word can be used. W e look a t two c o m p o n e n t s o f c o n t e x t u a l r e p r e s e n t a t i o n s t h a t can be a u t o m a t i c a l l y e x t r a c t e d f r o m t e x t u a l c o r p o r a using s t a t i s t i c a l m e t h o d s . These are topical contezt a n d local contezt.
Topical contezt is c o m p r i s e d o f s u b s t a n t i v e words t h a t are likely to co-occur w i t h a given sense o f a t a r g e t word. If, for e x a m p l e , the p o l y s e m o u s word line occurs in a sentence w i t h poetry a n d we/re, it is p r o b a b l y being used to express a different sense of line t h a n if it occurred w i t h s t a n d a n d wait. T o p i c a l c o n t e x t is r e l a t i v e l y insensitive to t h e o r d e r o f words or t h e i r g r a m m a t i c a l inflections; the focus is on t h e m e a n i n g s of the open-class words t h a t are used t o g e t h e r in t h e s a m e sentences.
Local contezt includes i n f o r m a t i o n on word order, d i s t a n c e a n d s y n t a c t i c s t r u c t u r e . For e x a m p l e , a line from does not suggest t h e s a m e sense as in line .for. O r d e r a n d inflection are critical clues for local i n f o r m a t i o n , which is n o t r e s t r i c t e d to open-class words.
In t h e n e x t section, we briefly review a n e x p e r i m e n t using three s t a t i s t i c a l classifiers designed for sense resolution, a n d show t h a t t h e y are effective in e x t r a c t i n g t o p i c a l con- t e x t . Section 3 describes a n e x p e r i m e n t t h a t was p e r f o r m e d t o e s t a b l i s h t h e u p p e r b o u n d o f p e r f o r m a n c e for these classifiers. Section 4 presents s o m e techniques t h a t we are devel- o p i n g t o e x t r a c t local c o n t e x t .
2
Acquiring Topical Context
it. T h e task is to identify the topic, then to select t h a t sense of the polysemous word t h a t best fits the topic. For example, if the topic is writing, then
sheet
probably refers to a piece of paper; if the topic is sleeping, then it probably refers to bed linen; if the topic is sailing, it could refer to a sail; and so on.Instead of using topics to discover senses, one can use senses to discover topics. T h a t is to say, if the senses are known in advance for a textual corpus, it is possible to search for words t h a t are likely to co-occur with each sense. This strategy requires two steps. It is necessary (1) to partition a sizeable n u m b e r of occurrences of a polysemous word according to its senses, and then (2) to use the resulting sets of instances to search for co-occurring words t h a t are diagnostic of each sense. T h a t was the strategy followed with considerable success by Gale, Church, and Yarowsky [1], who used a bilingual corpus for (1), and a Bayesian decision system for (2).
To understand this a n d other statistical systems better, we posed a very specific prob- lem: given a set of contexts, each containing the noun
line
in a known sense, construct a classifier t h a t selects the correct sense ofline for new contexts. To see how the degree
of polysemy affects performance, we ran three- and six-sense tasks. A full description of the three-sense task is reported in Voorhees, et. al. [11], and the six-sense task in Leacock, et. al [5]. These experiments are reviewed briefly below.We tested three corpus-based statistical sense resolution m e t h o d s which a t t e m p t to infer the correct sense of a polysemous word by using knowledge a b o u t patterns of word co-occurrences. T h e first technique, developed by Gale et. al. [1] at A T & T Bell Labora- tories, is based on Bayesian decision theory, the second is based on neural network with back propagation [9], and the third is based on content vectors as used in information retrieval [10]. T h e only information used by the three classifiers is co-occurrence of char- acter strings in the contexts. T h e y use no other cues, such as syntactic tags or word order, nor do they require any a u g m e n t a t i o n of the training and testing d a t a t h a t is not fully a u t o m a t i c . T h e Bayesian classifier uses all of the information in the sentence except word order. T h a t is, it uses punctuation, upper/lower case distinctions, a n d inflectional endings. T h e other two classifiers remove punctuation and convert all characters to lower case. In addition, they remove a list of stop words, a set of a b o u t 570 very high frequency words t h a t includes m o s t function words as well as some content words. T h e remaining strings are
stemmed."
suffixes are removed to conflate across morphological distinctions. For example, the stringscomputer(s), computing, computcdion(al),
etc. are conflated to the stemcomput.
2 . 1 M e t h o d o l o g y
T h e training and testing contexts were taken from the 1987-89
Wall Street Journal corpus
and from the A P H B corpus. 1 Sentences containingline(s)
andLine(s)
were extracted and m a n u a l l y assigned a single sense from WordNet. 2 Sentences with proper names con- tainingLine,
such asJapan Air Lines,
were removed from the set of sentences. Sentences containing collocations t h a t have a single sense in WordNet, such asproduct line and
line
of products,
were also excluded since the collocations are not ambiguous.1 The 25 million word corpus, obtained from the American Printing House for the Blind, is arc.hlved at IBM's T.J. Watson Research Center; it consists of stories and articles from books and general circulation magazines.
T y p i c a l l y , e x p e r i m e n t s have used a fixed n u m b e r o f words or c h a r a c t e r s on either side o f t h e t a r g e t word as the context. In these e x p e r i m e n t s , we used linguistic u n i t s - sentences - instead. Since the t a r g e t word is often used a n a p h o r i c a l l y to refer b a c k t o t h e previous sentence, as in:
T h a t was the last t i m e Bell ever t a l k e d on t h e phone. He c o u l d n ' t get his wife off t h e line.
we chose to use two-sentence contexts: the sentence c o n t a i n i n g line a n d the preceding sentence. However, if the sentence c o n t a i n i n g line was the first sentence in the article, then the c o n t e x t consists o f one sentence. If the preceding sentence also c o n t a i n e d line in the s a m e sense, t h e n a n a d d i t i o n a l preceding sentence was a d d e d to t h e c o n t e x t , c r e a t i n g c o n t e x t s t h r e e or m o r e sentences long. T h e average size o f the t r a i n i n g a n d t e s t i n g c o n t e x t s was 44.5 words.
T h e sense r e s o l u t i o n t a s k used the following six senses of the n o u n line: 1. a product: ... a new line o f m i d s i z e d cars ...
2. a f o r m a t i o n o f p e o p l e or things: People w a i t e d p a t i e n t l y in long lines ...
3. s p o k e n or w r i t t e n tezt: One w i n n i n g line f r o m t h a t speech ... 4. a thin, flexible object; cord: W i t h a line tied to his foot, ...
5. a n a b s t r a c t division: ... t h e A m i s h d r a w no line between work a n d religion a n d life. 6. a t e l e p h o n e connection: One key to W o r d P e r f e c t ' s g r o w t h was its toll-free help line
T h e classifiers were run three t i m e s each on r a n d o m l y selected t r a i n i n g sets. T h e set of c o n t e x t s for each sense was r a n d o m l y p e r m u t e d , w i t h each p e r m u t a t i o n c o r r e s p o n d i n g to one trial. For each t r i a l , the first 200 contexts o f each sense were selected as t r a i n i n g contexts. T h e n e x t 149 c o n t e x t s were selected as test contexts. T h e r e m a i n i n g c o n t e x t s were not used in t h a t t r i a l . T h e 200 t r a i n i n g c o n t e x t s for each sense were c o m b i n e d t o f o r m a final t r a i n i n g set of size 1200. T h e final test set c o n t a i n e d the 149 t e s t c o n t e x t s f r o m each sense, for a t o t a l of 894 contexts. To test the effect t h a t the n u m b e r o f t r a i n i n g e x a m p l e s has on classifier p e r f o r m a n c e , s m a l l e r t r a i n i n g sets of 50 a n d 100 c o n t e x t s were e x t r a c t e d f r o m the 200 c o n t e x t t r a i n i n g set.
2 . 2 R e s u l t s
All o f t h e classifiers p e r f o r m e d b e s t w i t h the largest n u m b e r (200) of t r a i n i n g contexts, a n d the p e r c e n t correct results r e p o r t e d here are averaged over the three t r i a l s w i t h 200 t r a i n i n g contexts. O n t h e six-sense task, the Bayesian classifier a v e r a g e d 71% correct answers, t h e c o n t e n t vector classifier 72%, a n d the n e u r a l networks 76%. None of these differences are s t a t i s t i c a l l y significant due to the l i m i t e d s a m p l e size o f t h r e e trials.
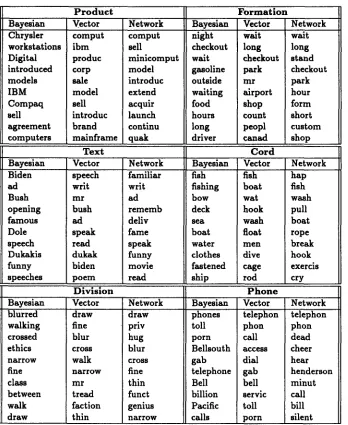
Bayesian "Chrysler workstations Digital introduced models I B M
Compacl sell agreement ,,,computers
P r o d u c t F o r m a t i o n
Vector Network Bayesian Vector Network comput ibm produc corp flale model sell introduc brand mainframe comput sell minicomput model introduc extend acquir launch continu quak night checkout wait gasoline outside waiting food hours long driver walt long checkout park m r airport shop count peopl canad walt long stand checkout park hour form short custom shop
T e x t C o r d
Bayesian Vector Network Bayesian Vector Network
speech writ m r bush ad speak read dukak biden p o e m
fish fishing bow deck s e a boat water clothes fastened ship Biden ad Bush opening famous Dole speech Dukakis funny speeches fish boat wat hook wash float
m e n
dive cage rod familiar writ ad rememb deliv fame speak funny movie read hap fish wash pull boat rope break hook exercis cry
Division P h o n e
Bayesian Vector Network Bayesian Vector Network
phones telephon toll phon porn call Bellsouth access gab dial telephone gab Bell bell billion servic Pacific toll calls porn
blurred walking crossed ethics narrow fine class between walk d r a w
draw draw
fine priv
blur hug cross blur walk cross narrow fine m r thin tread funct faction genius thin narrow
telephon phon dead cheer hear henderson minut call bill silent
[image:4.612.122.470.140.565.2]T h e results of the X 2 test for a three-sense resolution t a s k
(product, formation
a n d tezt), 3 i n d i c a t e t h a t t h e response p a t t e r n of the content vector classifier is significantly different from the p a t t e r n s o f b o t h the Bayesian a n d n e u r a l network classifiers, b u t the Bayesian response p a t t e r n is significantly different f r o m t h e n e u r a l network p a t t e r n for theproduct
sense only. In the six-sense d i s a m b i g u a t i o n task, t h e X 2 results i n d i c a t e t h a t the Bayesian a n d n e u r a l network classifiers' response p a t t e r n s are n o t significantly different for a n y sense. T h e n e u r a l network a n d Bayesian classifiers' response p a t t e r n s are significantly different f r o m t h e content vector classifier o n l y in theformation
a n d tezt senses. Therefore, w i t h the a d d i t i o n of three senses, the classifiers' response p a t t e r n s a p p e a r t o b e converging.A p i l o t two-sense d i s t i n c t i o n t a s k (between
product and formation)
y i e l d e d over 90% correct answers. 4 In t h e three-sense d i s t i n c t i o n task, the three classifiers h a d a m e a n of 76% correct, y i e l d i n g a s h a r p d e g r a d a t i o n w i t h the a d d i t i o n o f a t h i r d sense. Therefore, we h y p o t h e s i z e d degree of p o l y s e m y t o be a m a j o r factor for p e r f o r m a n c e . W e were s u r p r i s e d to find t h a t in the six-sense task, all three classifiers d e g r a d e d only slightly f r o m the three- sense task, w i t h a m e a n o f 73% correct. A l t h o u g h the a d d i t i o n of three new senses to the t a s k caused consistent d e g r a d a t i o n , the d e g r a d a t i o n is r e l a t i v e l y slight. Hence, we conclude t h a t s o m e senses are h a r d e r to resolve t h a n others, a n d it a p p e a r s t h a t overall a c c u r a c y is a function o f t h e difficulty o f the sense r a t h e r t h a n being s t r i c t l y a f u n c t i o n o f t h e degree o f p o l y s e m y . T h e h a r d e s t sense for all three classifiers to learn was tezt, followed byformation,
followed bydivision.
T h e difficulty in t r a i n i n g for theproduct, phone,
a n dcord
senses v a r i e d a m o n g the classifiers, b u t t h e y were the three ' e a s i e s t ' senses across the classifiers. To test our conclusion t h a t the difficulty involved in l e a r n i n g i n d i v i d u a l senses is a g r e a t e r f a c t o r for p e r f o r m a n c e t h a n degree of polysemy, we r a n a t h r e e - w a y e x p e r i m e n t on the three ' e a s y ' senses. O n this task, t h e content vector classifier achieved 90% a c c u r a c y a n d n e u r a l network classifier 92% accuracy.T h e convergence of the response p a t t e r n s for t h e three m e t h o d s suggests t h a t each o f the classifiers is e x t r a c t i n g as m u c h d a t a as is a v a i l a b l e in word co-occurrences in the t r a i n i n g contexts. If this is the case, a n y technique t h a t uses o n l y w o r d counts will n o t b e significantly m o r e a c c u r a t e t h a n the techniques t e s t e d here. A l t h o u g h t h e degree of p o l y s e m y does affect the difficulty of the sense resolution task, a g r e a t e r f a c t o r ~ for p e r f o r m a n c e is t h e difficulty of resolving i n d i v i d u a l senses. F r o m i n s p e c t i o n of the c o n t e x t s for the various senses, it a p p e a r s t h a t the senses of
line
t h a t were easy to l e a r n t e n d t o be s u r r o u n d e d b y a lot o f t o p i c a l context. W i t h the senses t h a t were h a r d t o learn, t h e crucial d i s s m b i g u a t i n g i n f o r m a t i o n t e n d s to be very local, so t h a t a g r e a t e r p r o p o r t i o n o f t h e c o n t e x t is noise. A l t h o u g h it is recognized t h a t local i n f o r m a t i o n is m o r e reliable t h a n d i s t a n t i n f o r m a t i o n , the classifiers m a k e no use of locality. F i g u r e 1 shows s o m e r e p r e s e n t a t i v e c o n t e x t s for each sense o fline
used in the study. T h eproduct, phone
a n d
cord
senses c o n t a i n a lot of t o p i c a l context, while the o t h e r senses have l i t t l e or no i n f o r m a t i o n t h a t is n o t very local.T h e three classifiers are d o i n g a g o o d j o b finding t o p i c a l context. However, s i m p l y knowing which words are likely to co-occur in t h e s a m e sentences when a p a r t i c u l a r topic is u n d e r discussion is n o t sufficient for sense resolution.
1. t e x t : In a warmly received speech that seemingly sought to distance him from Reagan administration civil-rights policies, Mr. Bush outlined what he called a "positive civil-rights agenda," and promised to have "minority men and women of excellence as full-scale partners" during his presidency. One winning l i n e from that speech: "Whenever racism rears its ugly head-Howard Beach, Forsyth County, wherever-we must be there to cut it off."
2. f o r m a t i o n : On the way to work one morning, he stops at the building to tell Mr. Arkhipov: "Don't forget the drains today." Back in his office, the l l n e of people waiting to see him has dwindled, so Mr. Goncharov stops in to see the mayor, Yuri Khivrich.
3. d i v i s i o n : Thus, some families are probably buying take-out food from grocery stores-such as barbecued chicken-but aren't classifying it as such. The l i n e between groceries and take-out food m a y have become blurred.
4. c o r d : Larry ignored the cries and came swooping in. The fisherman's nylon llne, taut and glistening with drops of seawater, suddenly went slack as Larry's board rode over it.
5. p h o n e : "Hello, Weaver," he said and then to put her on the defensive, "what's all the gabbing on the house phones? I couldn't get an open l l n e to you."
6. p r o d u c t : International Business Machines Corp., seeking to raise the return on its massive research and development investments, said it will start charging more money to license its 32,000 patents around the world. In announcing the change, IBM also said that it's willing to license patents for its PS/2 l i n e of personal com- puters.
3
A n U p p e r B o u n d For C l a s s i f i e r P e r f o r m a n c e
In an effort to establish an upper b o u n d for performance on corpus-based statistical sense resolution methods, we decided to see how h u m a n s would perform on a sense resolution task using the same input t h a t drives the statistical classifiers [4]. An experiment was designed to answer the following questions:
1. How do h u m a n s perform in a sense resolution task when given the same testing input as the statistical classifiers?
2. Are the contexts t h a t are h a r d / e a s y for the statistical classifiers also h a r d / e a s y for people?
T h e three-sense task was replicated using h u m a n subjects. For each of the three senses of
line (product, tezt,
andformation),
we selected 10 easy contexts (contexts t h a t were correctly classified by the three statistical methods) and 10 haed contexts (contexts t h a t were misclassified by the three methods), for a total of 60 contexts. These contexts were prepared in three formats: (1) a sentential form (as they originally appeared in the corpus), (2) along list f o r m a t (as was used by the Bayesian classifier), and (3) a
shor~
list f o r m a t (as was used by the content vector and neural network classifiers). In order to mimic the fact t h a t the classifiers do not use word order, collocations, or syntactic structure, the latter two contexts were presented to the subjects as word lists in reverse alphabetical order. 36 subjects each saw 60 contexts, 20 in each of the three formats, and were asked to choose the appropriate sense ofline.
T h e order in which the formats were presented was counter-balanced across subjects. No subject saw the same context twice. T h e subjects were Princeton undergraduates who were paid for their participation.H u m a n subjects performed almost perfectly on the sentential formats and had a b o u t a 32% error rate on the list formats. There was no significant difference between the two list f o r m a t s - indicating t h a t function words are of no use for sense resolution when word order is lost. T h e y m a d e significantly more errors on the contexts t h a t were hard for the statistical classifiers, and fewer errors on the contexts t h a t were easy for the classifiers. Not all the senses were equally difficult for h u m a n subjects: there were significantly fewer errors for the
product sense of line t h a n for the tczt and
fformgtion senses. Error rates for
the subjects on the list f o r m a t s were almost 50% for the hard contexts (contexts where the classifiers performed with 100% error), so subjects performed much better t h a n the classifiers on these contexts. However, on the easy contexts, where the classifiers m a d e no errors, the students showed an error rate of approximately 15%.4
Acquiring Local C o n t e x t
Kelly and Stone [3] pioneered research in finding local context by creating algorithms for automatic sense resolution. Over a period of seven years in the early 1970s, they (and some 30 students) hand coded sets of ordered rules for disambiguating 671 words. The rules include syntactic markers (part of speech, position within the sentence, punctuation, inflection), semantic markers and selectional restrictions, and words occurring within a specified distance before a n d / o r after the target. An obvious shortcoming of this approach is the amount of work involved.
Recently there has been much interest in automatic and semi-automatic acquisition of local context (Hearst [2], Resnik [8], Yarowsky [13]). These systems are all plagued with the s a m e problem, excellent precision but low recall. T h a t is, if the local information that the methods learn is also present in a novel context, then that information is very reliable. However, quite frequently no local context match is found in a novel context. Given the sparseness of the local data, we hope to look for both local and topical context, and we have begun experimenting with various ways of acquiring the local context.
Local context can be derived from a variety of sources, including WordNet. The nouns in WordNet are organized in a hierarchical tree structure based on hypernomy/hyponomy. The hypernym of a noun is its superordinate, and t h e / s a kind o/relation exists between a noun and its hypernym. For example, line is a hypernym of conga line, which is to say that a conga line is a kind of line. Conversely, cong~ line is a h y p o n y m of line. Polysemous words tend to have hyponyms that are monosemous collocations incorporating the polysemous word: product line is a monosemous hyponym of the merchandise sense of line; any occurrence of product line can be recognized immediately as an instance of that sense. Similarly, phone line is a hyponym of the telephone connection sense of line, actor's line is a hyponym of the text sense of line, etc. These collocational hyponyms provide a convenient starting point for the construction of local contexts for polysemous words.
We are also experimenting with template matching, suggested by Weiss as one ap- proach to using local context to resolve word senses [12]. In template matching, specific word patterns recognized as being indicative of a particular sense (the templates) are used to select a sense when a template is contained in the novel context; otherwise word co-occurrence within the context (topical context) is used to select a sense. Weiss initially used templates t h a t were created by hand, and later derived templates automatically from his dataset. Unfortunately, the datasets available to Weiss at the time were very small, and his results are inconclusive. We are investigating a similar approach using the line data: training contexts are used to both automatically extract indicative templates and create topical sense vectors.
To create the templates, the system extracts contiguous subsets of tokens including the target word and up to two tokens on either side of the target as candidate templates, s The system keeps a count of the number of times each candidate template occurs in all of the training contexts. A candidate is selected as a template if it occurs in at least n of the training contexts and one sense accounts for at least m % of its total occurrences. For example, Figure 2 shows the templates formed when this process is used on a training set of 200 contexts for each of six senses when n = 10 and m = 75. The candidate template blurs the line is not selected as a template with these parameter settings because it does not occur frequently enough in the training corpus; the candidate template line o/is not
c o r d
his line
d i v i s i o n
a fine line between, line line between, a line line, line line line between the, the line between, line between
draw the line, over the line
f o r m a t i o n
a long line of, long line of, a long line, long line, long lines in line for, wait in line, in line
p h o n e
telephone lines access lines lille wa4l
p r o d u c t
a new line of, a new line, new line of, new line
F i g u r e 2: T e m p l a t e s f o r m e d for a t r a i n i n g set of 200 contexts for each o f six senses when a t e m p l a t e m u s t occur a t least 10 t i m e s a n d a t least 75% o f the occurrences m u s t be for one sense. No t e m p l a t e s were learned for the tezt sense.
selected because it a p p e a r s t o o frequently in b o t h the product line a n d f o r m a t i o n contexts. W i t h the e x c e p t i o n o f his line (cord) a n d line was (phone), these t e m p l a t e s r e a d i l y suggest t h e i r c o r r e s p o n d i n g sense. T h e n = 10 a n d m = 75 p a r a m e t e r s e t t i n g s are r e l a t i v e l y s t r i n g e n t c r i t e r i a for t e m p l a t e f o r m a t i o n , so n o t m a n y t e m p l a t e s are formed, b u t those t e m p l a t e s t h a t are f o r m e d t e n d to be h i g h l y i n d i c a t i v e o f the sense.
P r e l i m i n a r y results show t e m p l a t e m a t c h i n g i m p r o v e s t h e p e r f o r m a n c e o f t h e c o n t e n t vector classifier. T h e six-sense e x p e r i m e n t was r e p e a t e d using a s i m p l e decision tree to i n c o r p o r a t e the t e m p l a t e s : T h e sense c o r r e s p o n d i n g to the longest t e m p l a t e c o n t a i n e d in a test c o n t e x t was selected for t h a t context; if the c o n t e x t c o n t a i n e d no t e m p l a t e , t h e sense chosen b y t h e vector classifer was selected. T h e t e m p l a t e s were a u t o m a t i c a l l y c r e a t e d f r o m t h e s a m e t r a i n i n g set as was used to create the content vectors. To be selected as a t e m p l a t e , a c a n d i d a t e h a d to a p p e a r a t least 3 t i m e s for the t r a i n i n g sets t h a t i n c l u d e d 50 o f each sense, 5 t i m e s for t h e 100 each t r a i n i n g sets, a n d 10 t i m e s for t h e 200 each t r a i n i n g sets. In all cases, a single sense h a d to account for a t least 75% of a c a n d i d a t e ' s occurrences. T h i s h y b r i d a p p r o a c h was m o r e a c c u r a t e t h a n t h e c o n t e n t vector classifier alone on each o f t h e 9 trials. T h e average a c c u r a c y when t r a i n e d using 200 c o n t e x t s o f each sense was 75% for the h y b r i d a p p r o a c h c o m p a r e d to 72% for t h e c o n t e n t vectors alone.
investigated four different methods for combining three sources of information [8]. The "backing off" strategy, in which the three sources of information were tried in order from most reliable to least reliable until some match was found (no resolution was done if no method matched), maintained high precision (81%) and produced substantially higher recall (95%) than any single method.
Our plans for incorporating templates into the content vector classifier include inves- tigating the significance of the tradeoff between the reliability of the templates and the number of templates that are formed. When stringent criteria are used for template for- mation, and the templates are thought to be highly reliable sense indicators, the sense corresponding to a matched template will always be selected, and the sense vectors will be used only when no template match occurs. When the templates are thought to be less reliable, the choice of sense will be a function of the uniqueness of a matched template (if any) and the sense vector similarities. By varying the relative importance of a tem- plate match and sense vector similarity we will be able to incorporate different amounts of topical and local information into the template classifier.
5
C o n c l u s i o n
The capacity to determine the intended sense of an ambiguous word is an important component of any general system for language understanding. We believe that, in order to accomplish this task, we need contextual representations of word senses containing both topical and local context. Initial experiments focused on methods that are able to extract topical context. These methods are effective, but topical context alone is not sufficient for sense resolution tasks. The human subject experiment shows that even people are not very good at resolving senses when given only topical context. Currently we are testing methods for learning local context for word senses. Preliminary results show that the addition of template matching on local context improves performance.
A c k n o w l e d g m e n t s
This work was supported in part by Grant No. N00014-91-1634 from the Defense Ad- vanced Research Projects Agency, Information and Technology Office, by the Office of Naval Research, and by the James S. McDonnell Foundation. We are indebted to George A. Miller and Martin S. Chodorow for valuable comments on an earlier version of this paper.
R e f e r e n c e s
[1] William Gale, Kenneth W. Church, and David Yarowsky. A method for disam- biguating word senses in a large corpus. Statistical Research Report 104, A T & T Bell Laboratories, 1992.
[3] Edward Kelly and Philip Stone.
Computer Recognition of English Word Senses.
North-Holland, Amsterdam, 1975.[4] Claudia Leacock, Shari Landes, and Martin Chodorow. Comparison of sense reso- lution by statistical classifiers and human subjects. Cognitive Science Laboratory Report, Princeton University, in preparation.
[5] Claudia Leacock, Geoffrey Towell, and Ellen M. Voorhees. Corpus-based statisti- cal sense resolution. In
Proceedings off the ARPA Workshop on Human Language
Technology,
1993.[6] George Miller. Special Issue, WordNet: An on-line lexical database.
International
Journal off Lezicography,
3(4), 1990.[7] George A. Miller and Walter G. Charles. Contextual correlates of semantic similarity.
Language and Cognitive Processes,
6(1), 1991.[8] Philip Resnik. Semantic classes and syntactic ambiguity. In
Proceedings of the ARPA
Workshop on Human Language Technology,
1993.[9] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. In D. E. Rumelhart and J. L. McClelland, editors,
Parallel
Distributed Processing: Ezplorations in the Microstrncture of Cognition, Volume 1:
Foundatior~s,
pages 318-363. MIT Press, Cambridge, 1986.[10] G. Salton, A. Wong, and C.S. Yang. A vector space model for automatic indexing.
Communications of the ACM,
18(11):613-620, 1975.[11] Ellen M. Voorhees, Claudia Leacock, and Geoffrey Towell. Learning context to dis- smbiguate word senses. In
Proceedings off the 3rd Computational Leaerdng Theory
and Natural Learning Systems Conference-lags,
Cambridge, to appear. MIT Press.[12] Stephen Weiss. Learning to disambiguate.
Infformation Storage and Retrieval,
9:33- 41, 1973.