ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 7, Issue 12, December 2018
Optimizing Performance of Web Content
Discovery Based on Web Mining Process
Pawar S.Priyanka1, Suchita Wankhade2
M.E. Student, Dept. of Computer Engineering, Trinity College of Engineering and Research, Kondhawa-Saswad Road,
Pune, Maharashtra India1
Assistant Professor, Dept. of Computer Engineering, Trinity College of Engineering and Research, Kondhawa-Saswad
Road, Pune, Maharashtra India2
ABSTRACT: In present situation, internet is imperative piece of our life. Due to large number of web resources and the dynamic nature of web, it becomes difficult to efficiently search the result in less time. It becomes challenge to achieve better result for respective query. To solve this problem we propose a two-stage framework, mainly Web Crawler. In first stage, Web Crawler performs “Reverse searching” that matches user query with URL. In the second stage “Incremental-site prioritizing” is performed to match the query content within form. Then according to match frequency, we classify relevant and irrelevant pages and rank this page.Our proposed crawler efficiently retrieves web interfaces from large sites and achieves greater result than other crawlers .We will analyze the hotspot topic discovery algorithm based on Web mining technology, and the fundamental standards, related advancements and their application regions of these calculations. We develop searching through personalized search according to profession and domain classification to improve performance, User can bookmark the links.
KEYWORDS: Topic detection,Web mining technology, Web crawler.
I. INTRODUCTION
A web crawler also known as robot or spider is a massive download system for web pages. Web crawlers are utilized for an assortment of purposes. Main components of web search engines, systems that assemble large web pages, point to them and allow users to publish queries in the index and find web pages that match queries. In the deep web there is growing interest in techniques that help you locate the deep interfaces efficiently. Be that as it may, because of the vast volume of web assets and the dynamic idea of the profound website pages, achieving an expansive inclusion and high productivity is a test. Topic detection and tracking are the basis of hotspot research and algorithm discovery. At present, the study of hot topics mainly includes two aspects: topic discovery and hot topic recognition. We propose a two-stage framework, namely Web Crawler, for efficient harvesting deep web interfaces. In the first stage, Web Crawlerperforms Link based searching for center pages with the help of search engines, avoiding visiting a large number of pages. In second stage we will coordinate frame content, at that point we ordering relevant and irrelevant sites. Here we developed personalized search for efficient results and we are maintaining log for efficient time management.
II. OBJECTIVE & SCOPE
To Search the hot spot and trending topic detection using crawler. Perform personalized search.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 7, Issue 12, December 2018
Scope of this project is finding web pages efficiently of user requirements needs to be improved. This system helps to personalize user’s requirement according to his profile. All in all, there is a tradeoff between the hunt quality and the dimension of security insurance accomplished from speculation. Web Crawler gives space detail crawler to web substance. This help to save the time by providing efficient web search.
III. LITERATURE SURVEY
In this system Lidan Shou, He Bai, Ke Chen, & Gang Chen.consider security insurance in PWS applications that demonstrate client inclinations as various leveled client profiles. We propose a PWS structure called UPS that can adaptively sum up profiles by questions while regarding user specified security necessities. Our runtime hypothesis goes for striking amicability between two judicious estimations that evaluate the utility of personalization and the security threat of revealing the summed up profile. We present two insatiable calculations, in particular Greedy DP furthermore, Greedy IL, for runtime speculation.[1]
Brindha, S., Prabha, K.proposed the advancement of the World Wide Web it is never again attainable for a client can see every one of the information coming from order into classes. The extension of data and control programmed order of information and printed information gains progressively and give elite. According to Sukumaran, S five essential content groupings are portrayed Naive Bayesian, KNearest Neighbor, Support Vector Machine, Decision Tree and Relapse. Which are sorted the content information into pre characterize class. The objective of the paper is to think about various order methods and finding the characterization precision for various datasets. A productive and powerful content records into commonly select classifications. [2]
Balakrishnan, R., Kambhampati, proposedissues in profound web look are in any event as mind boggling as those in surface web seek. Despite the fact that the proposed source and result positioning strategies fathom a portion of the critical ones, there are numerous conceivable territories of future research. For areas without numerous excess sources (e.g., understudy database of a college) the understanding based techniques may not work. It tends to be contended that the requirement for dissecting reliability and significance is likewise less in these sorts of databases and according to Jha, M. While the watchword coordinate based techniques like CORI or Coverage might be adequate for these kinds of databases, the execution and enhancement of these strategies might be further investigated.[3]
A.B. Gil , S. Rodríguez contemplate presents a model for the advancement of computerized content recovery dependent on the worldview of virtual associations of operators utilizing a Service Oriented Architecture. The model permits the improvement of an open and adaptable engineering that bolsters the administrations important to progressively scan for dispersed advanced substance. A noteworthy test in looking and recovering advanced substance is likewise to productively locate the most appropriate substance for the clients. F. de la Prieta and De Paz J.F. proposed this model proposes another way to deal with sifting the instructive substance recovered dependent on Case-Based Reasoning (CBR). It depends on the model AIREH (Design for Intelligent Recovery of Educational substance in Heterogeneous Environments), a multi-operator engineering that can look and coordinate heterogeneous instructive substance through a recuperation show that utilizes a unified inquiry. The demonstrate and the advances introduced in this exploration represent the potential for creating customized recuperation frameworks for computerized content dependent on the worldview of virtual associations of operators. The upsides of the proposed design, as delineated in this article, are its adaptability, customization, integrative arrangement and effectiveness. [4]
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 7, Issue 12, December 2018
Li, W., Yang, C proposed addresses the challenges by developing an effective crawler to discover and update the services in (1) Proposing an accumulated term frequency (ATF)–based conditional probability model for prioritized crawling, (2) utilizing concurrent multi-threading technique, and (3)Adopting an automatic mechanism to update the metadata of identified services. Experiments show that the proposed crawler achieves good performance in both crawling efficiency and results’ coverage/liveliness. In addition, an interesting finding regarding the distribution pattern of WMSs is discussed. Yang, C expect this research to contribute to automatic GWS discovery over the large-scale and dynamic World Wide Web and the promotion of operational interoperable distributed geospatial services. [6]
IV. EXISTING SYSTEM APPROACH
To get user expected deep web data sources, Web Crawler is developed in Reverse Searching and Incremental-site prioritizing .The first site locating stage finds the most relevant site for a given subject, and afterward the second in-site investigating stage reveals accessible structures from the site. Specifically, the site discovering stage starts with a seed set of goals in a site database. Seeds locales are competitor destinations given for Web Crawler to begin slithering, which starts by following URLs from picked seed goals to examine diverse pages and distinctive spaces. Seed fetcher get seeds and after that perform switch looking it coordinate client question content in url, at that point we going to arrange the significant and irrelevant link. Then in Incremental-site prioritizing we are matching content of query on form, depends on matching we are going to classify relevant and irrelevant We will analyze the hotspot topic discovery algorithm based on Web mining technology, and the fundamental standards, related advancements and their application regions of these calculations. Page ranking is performed and display high ranked results on result page. Domain classification is performed to show the user from which domain how many links are got.
V.PROPOSED SYSTEM APPROACH
To get user expected deep web data sources, Web Crawler is developed in Reverse Searching and Incremental-site prioritizing. .The first site locating stage finds the most relevant site for a given subject.
Fig.1 Block Diagram of Proposed System
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 7, Issue 12, December 2018
which starts by following URLs from picked seed goals to explore diverse pages and distinctive spaces. Seed fetcher get seeds and after that perform switch looking it coordinate client question content in url, at that point we going to arrange the significant and irrelevant link. Then in Incremental-site prioritizing we are matching content of query on form, depends on matching we are going to classify relevant and irrelevant We will analyze the hotspot topic discovery algorithm based on Web mining technology, and the fundamental standards, related advancements and their application regions of these calculations. Page ranking is performed and display high ranked results on result page. Domain classification is performed to show the user from which domain how many links are got. We personalize the searching according to user profile so it is easy to get accurate result to user. User can save the book mark.
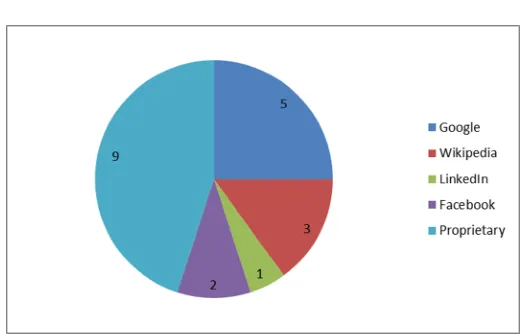
VI. COMPARATIVE RESULTS
The shows proposed Web crawler gives more searchable form than Existing Crawler Explanation: Fig. shows Comparison of links after performing Web-crawler and existing crawler. In the following table shows number of links are available for searching any word. When we search any word we get 5 links from google,3 link from wikipedia,1 links of linkedin,2 links of Facebook and 10 links of propriety from web crawler.
Query Number of links
Google 5
Wikipedia 3 LinkedIn 1 Facebook 2 Proprietary 9
Table 11.1 Table of search link
In the following graph shows number of links are available for searching any word. When we search any word we get 5 links from google,3 link from wikipedia,1 links of linkedin,2 links of facebook and 9 links of propriety from web crawler.
ISSN(Online): 2319-8753 ISSN (Print): 2347-6710
I
nternational
J
ournal of
I
nnovative
R
esearch in
S
cience,
E
ngineering and
T
echnology
(A High Impact Factor, Monthly, Peer Reviewed Journal) Visit: www.ijirset.com
Vol. 7, Issue 12, December 2018
VIII. CONCLUTION
In this system, we propose crawler to search web pages. Due to the large volume of web resources and the dynamic nature of web, achieving wide coverage and high efficiency is a challenging issue. This web crawler gives efficient and relevant result for searched query. Web crawler works in two phases: Reverse searching and Incremental-site prioritizing. This crawler efficiently searches for personalized query based on user’s profession. The ranking helps to get relevant results. Domain classification helps to know the contribution of top sources for a particular searched query as well as they help the user to surf through all the results efficiently. Log file is maintained to reduce time of query result for previously searched query.
IX. FEATURE WORK
In future user can search information using image or other various techniques.
X.ACKNOWLEDGMENT
This work is supported Hotspot Topic Discovery system of any state in India. Authors are thankful to Faculty of Engineering and Technology (FET), Savitribai Phule Pune University,Pune for providing the facility to carry out the research work.
REFERENCES
[1] Lidan Shou, He Bai, Ke Chen, & Gang Chen. (2014). “Supporting Privacy Protection in Personalized Web Search.” IEEE Transactions on Knowledge and Data Engineering, 26(2), 453–467. doi:10.1109/tkde.2012.201
[2] Brindha, S., Prabha, K., & Sukumaran, S. (2016). “A survey on classification techniques for text mining.”2016 3rd International Conference on Advanced Computing and Communication Systems (ICACCS). doi:10.1109/icaccs.2016.7586371
[3] Balakrishnan, R., Kambhampati, S., & Jha, M. (2013). “Assessing relevance and trust of the deep web sources and results based on inter-source agreement.” ACM Transactions on the Web, 7(2), 1–32. doi:10.1145/2460383.2460390
[4] A.B. Gil , S. Rodríguez , F. de la Prieta and De Paz J.F.(2013) “Personalization on E-Content Retrieval Based on Semantic Web Services” International Journal of Computer Information Systems and Industrial Management Applications. ISSN 2150-7988 Volume 5 (2012) pp. 243-251 [5] Hatzi, V., Cambazoglu, B. B., & Koutsopoulos, I. (2016). “Optimal Web Page Download Scheduling Policies for Green Web Crawling.” IEEE Journal on Selected Areas in Communications, 34(5), 1378–1388. doi:10.1109/jsac.2016.2520246
[6] Li, W., Yang, C., & Yang, C. (2010). “An active crawler for discovering geospatial Web services and their distribution pattern – A case study of OGC Web Map Service”. International Journal of Geographical Information Science, 24(8), 1127–1147. doi:10.1080/13658810903514172
BIOGRAPHY
Miss.Pawar S.Priyanka, ME-Comp, SKN Trinity College of Engineering and Research Kondhawa-Saswad Road, Pune, India.