The Multi-layer Language Knowledge Base of Chinese NLP
Hu Junfeng, Yu Shiwen
The Institute of Computational Linguistics,
Dept. of Computer Science and Technology, Peking University, Beijing, 100871, P.R. China
[email protected] , [email protected]
Abstract
This paper introduced the effort to build a multi-layer knowledge base of Chinese NLP which combined with list-based, rule-based and corpus-based language information. Different kinds of information are designed to solve different kind of problems that encountered in the Chinese NLP. The whole knowledge base is designed with theoretical consistency and can easily be put into practice in the application systems.
1. Introduction
For Chinese, there are no remarkable boundary and also lack of inflection of the words. A lot of efforts have been made to give the automatic word segmentation and POS-tagging and most of the systems claim accuracy of 98% or even above. But until now, the result of word segmentation and POS-tagging failed to meet the requirement of some farther applications such as MT. One of the reason is that there exits a gray region between Chinese compound words and phrases. For example, ‘å v’/treetop (å / tree, v/tip ) will probably be taken as a word because the character ‘v’ in this sense is seldom be used as a word separately. But when you come across ‘å ’/bark (å/tree, /skin), there will be some disputes about it because /skin can be used a little bit more separately than ‘v’. Until now, there don’t have a very strict standard to make difference of the compound words and the phrases in Chinese. In most of the systems, a dictionary is used to make the decision and the standard of the word collection of the dictionary is arbitrary. The strings which have the exactly the same grammatical and semantic behavior will probably be treated differently as word or phrase. This will surely lead to the inconsistency of the system and brings a lot of trouble in grammar and semantic analysis.
Other reason that we cannot count on the result of the POS-tagging system is due to the multiple standards of Chinese POS-tagging. In Chinese, the string ‘¥)’ , which means develop, have exactly the same form when it behaves like ‘development’ in a sentence. If you just tag all the existence of ‘¥)’ as ‘v’(verb), it will not help
too much to the farther analysis of the sentence. If you want to tag the string ‘¥)’ differently as ‘v’ or ‘n’ (noun), according to its grammatical function in each specific sentence, that will be a grammatical problem rather than a lexical one. It will not only lead to the sharp lower of the accuracy rate but also will lead to a recursive problem of POS-tagging and parsing.
In dealing these problems, we think, a multi-layer language knowledge base which combining with different kind of language information and with theoretical consistency, should be needed.
2. The Grammatical Dictionary of
Contemporary Chinese.
As the foundation of this knowledge base, ICL started to build “The grammatical dictionary of contemporary Chinese” in year of 1986. With 13 years efforts, this dictionary has now concluded more than 73 thousand Chinese words described with hundreds of grammatical attributes (120 attributes for verb only).
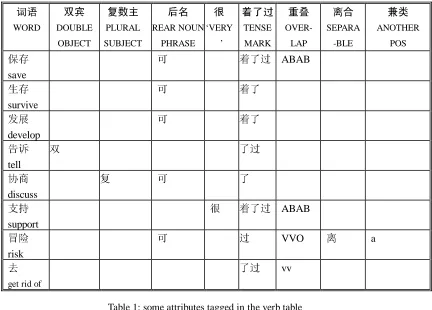
Table 1 illustrated some attributes tagged in the verb table. The column ‘DOUBLE OBJECT’ shows the verb can have double object or not. If a verb marked “ ” in the ‘PLURAL SUBJECT’ column, it means the verb can only have plural form subject. The ‘REAR NOUN PHRASE’ means the verb can combine with a rear noun to form a noun phrase. The detailed information of this dictionary can be found in the book "Grammatical Knowledge base of contemporary Chinese—a Complete Specification ",
templates (22,736 in total), large-scale processed corpus make up a multi-layer knowledge base of Chinese NLP. As we know, for most of the NLP applications, only the grammatical information is not enough. For corpus processing, segmentation and POS tagging is just the first step. There still have a lot of work needs to be done on the phrase binding, the maximal noun phrase discovery and some other fields. A semantic dictionary concerning with valence dependency and semantic classification is under construction.
7. References
[1] Fu Guohong, Wang Xiaolong. (1999). Unsupervised Word Segmentation and Unknown Word Identification. 5th National Language Processing Pacific Rim Symposium
[2] Swen Bing,Yu Shiwen. (1999). A graded Approach for the Efficient Resolution of Chinese Word Segmentation Ambiguities, 5th National Language Processing Pacific Rim Symposium
[3] ²¿J, (1998). ·ÁÁ©µC¡Lº· ,
Ù"û:Î