DOI : https://doi.org/10.32628/CSEIT1952103
Dynamic Allocation of Cloud Resources Using Skewness and SVM Algorithm
Dr. P. Tamijiselvy, Ramprakash M, Aswath R
Department of Computer Science and Engineering, Sri Krishna College of Technology, Coimbatore, Tamil Nadu, India
ABSTRACT
Exploring huge information applications realize huge data and also difficulties to modernize group and so the genius community. Cloud computing with its huge opportunity is the way to deal these issues. Let that be as it is, this cannot play its part on the off beat that we do not expert in fine allocation for cloud foundation resources. In this paper, we introduce a multi-target advancement calculation to exchange off the execution of Big Data and accessibility of Big Data, thereby reducing the cost of application running on Cloud. In the view of splitting and showcasing the interweaved relations among these destinations, we plan and execute our approach on trial condition. At long last, three sets of analyses demonstrate that our approach can keep running our application quicker than other regular improvement techniques and can accomplish the process at an higher execution rate than other heuristic calculations, while also having reduction in the cost of the system due to lesser usage of resources.
Keywords : Cloud Infrastructure; Big Data; Resource Allocation; Optimization; Automated Resource Allocation.
I. INTRODUCTION
In the current era, Big Data is the final go to place for all sorts of analytical purposes, different branches of huge datas are created, handled, transmitted, and put away in orderly fashion. Different aspects and the quick increment of data, most endeavours, examine relationships, world is not ready to face with such crazy unique challenges. In any case, this information is useful to the point that none can overlook them [1]. Luckily, some enormous data sellers, for example, Hortonworks, Cloudera, Databricks, and AmazonEMR, give another usage of cloud management to administer huge data, which is Big Data as a Service (BDaaS). BDaaS gives users the exposure to usable collected and improved information suggesting to them redid requirements. In view of various genres of huge information creation, cloud-based enormous information applications can be separated into a few levels, including cloud foundation, data administration, data creation, and information investigation. In this paper,
we work in cloud foundation level, in the process we are discussing over different levels also to acquire worldwide improvement. In the meantime, with the development of virtualization, it is possible for huge information applications to be sent into heterogeneous stages or servers [2]. Be that as it may, cloud specialist organizations and clients have distinctive purposes towards applying cloud computing [3]. The principle reason for cloud benefit suppliers is to diminish the cost for higher benefit, while clients worry about the execution, accessibility, and security [4]. These limitations are connected and confined to each other, which make the allotment issue to a great degree muddled to settle.
calculations to acquire the worldwide ideal arrangement meeting all limitations.
There are some different investigations in which the creators utilized heuristic calculations to explain the information allotment issue rapidly. These calculations are intended for issues stressing on various viewpoints, subsequently any one of them can't be appropriate for all circumstances.
To explain the cloud foundation asset allotment for enormous information application issue and make the arrangement adaptable for different circumstances, we must discover the relations between these destinations initially. As the fundamental figuring unit, virtual machine (VM) can be utilized as the figuring and systems administration hub in framework displaying period [5]. It is ordinary that one VM can't meet both high execution and low value, in this manner the main connection is the confinement amongst cost and execution. Both the execution and accessibility appreciate the advantage of expanding the measure of virtual machines. In any case, they are constrained by each other in type of the correspondence cost. Correspondence cost is the deferral between working virtual machines, and it is inescapable in cloud computing which is a commonplace appropriated framework.
II. RELATED WORK
First Execution, or Quality of Service (QoS), as the most vital part of distributed computing, is a hotly debated issue of asset designation issue. ROAR is proposed to improve, streamline, furthermore, robotize cloud asset assignment choices to meet QoS prerequisites. Thought about different asset setups to spare cost also, however we include accessibility into thought. Another meaning of QoS-levels and exhibited another QoS-based offering instrument for shower occupations in OpenStack. A QoS-mindful administration assessment technique proposed for a
common administration's co-determination exploiting of Analytic Hierarchy Process hypothesis.
There are some other research concentrating on half breed cloud asset administration. A vitality product asset designation EnReal strategy, named EnReal, proposed for logical work process execution at crosswise over cloud stages. To utilize different cloud benefit for higher quality of cloud benefit by means of the Weather Research and Forecasting administration has been introduced. In these examination, the principle objective is to utilize heterogeneous assets to meet lower cost or higher execution, while the accessibility is difficult to be computed in these methodologies. In our examination, we just apportion assets in single cloud foundation, which makes it conceivable to figure the accessibility. In the interim, the evaluating issue of half breed or heterogeneous cloud is still up in the air. Without unravelling this issue, half breed cloud asset administration is difficult to be pragmatic.
Multi-target streamlining is a traditional issue, which is not unravelled at present. Numerous overviews, calculations, and applications have been proposed to endeavour to take care of this issue while meeting functional prerequisites. Some examination achieves the ideal arrangement of multi-target streamlining issue in principle, for example, MEMO, KKTPM, MOPSO calculation, and CMMS proposed an asset distribution mindful insatiable stream verification approach to use restricted vitality and registering assets. Be that as it may, these strategies are limited to situations and need down to earth noteworthiness.
process execution cost while meeting due date limitations. CloudOpt which was based on Heuristic Packing with MIP (H-MIP) calculation, to acquire the arrangement of ideal organization for cloud. In any case, in nature of running 500 errands of 50 applications in 81 has, the time cost of registering the arrangement is 54.547 seconds. More over if adding emphasizing to incorporate conflict, the ideal opportunity for streamlining will be 61.62 seconds, and time for LQNS will be 121.86 second for running 20 applications under high pressure. The execution time of their approach is too long to meet the necessity of current cloud-based enormous information applications. Albeit heuristic calculations can get surmised ideal arrangement inside low time multifaceted nature, they may not accomplish any of the necessities, which will make the SLA infringement amazingly immense. For handy essentialness, there are some advancement approaches in view of constant input strategy drawing from robotization field, for example, Intercloud, proposed online dynamic asset distribution calculation and Monitoring and Optimizing Virtual Resources (MOVR) design. Assume that every one of the inputs address the issues, the last arrangement acquired by this approach will be significant. In any case, it can't be guarantee that the input circle will be merged, which implies this approach may get none arrangement. Moreover, the procedure of finding the ideal arrangement might be vacillate which spends gigantic time.
Toward SLA, numerous scientists composed and proposed a few approaches. A cloud SLA into a few parts and utilized them to think about the SLA supporting data of surely understood open IaaS suppliers. Exhibited that none of the suppliers offered any certification about the execution, and all left the weight of giving confirmation for SLA infringement to the customers. A technique for VM position to limit the power and movement cost. The calculation proposed in this paper depended on arched
streamlining and dynamic programming. Be that as it may, disregarded the execution, or the reaction time, from the perspective of customers. Initially, the SLAs must turn out to be more itemized concerning real KPIs used to characterize accessibility. Next, with a specific end goal to send additionally vital undertaking benefits in mists, distinctive levels of accessibility ought to be advertised. At long last, the SLAs ought to be accessible on request, that implies that they ought to be movable on request. Nonetheless, these investigate just centred around maybe a couple angles in SLA, however investigate endeavour to get arrangements which can meet the prerequisites from the two suppliers and customers.
III. System Model
accessibility exchange with others in shape of the topological structure. Heterogeneous information is an imperative normal for cloud-based applications. Therefore, the VMs utilized as a part of cloud-based huge information applications are not with the same setup. They are with different working frameworks, CPU, memory, organizing transfer speed, and geographic area. As a result, we must mull over heterogeneity, which information assignment issue to a great degree muddled to illuminate.
Regularly one physical host can take tens even several VMs, with various arrangements, capacities, execution, and costs. From the perspective of cloud specialist organizations, the aggregate cost of a cloud-based enormous information application utilized by some customer is the aggregate of VMs utilized as a part of this application. Even though there is a considerable measure of various costs of heterogeneous VMs as information mediums, this limitation is the easiest one to assess. We will likely locate the most extreme aggregate execution while meeting different necessities about cost and accessibility. Our approach will be sent on the cloud servers, and controlled by the cloud specialist organizations, along these lines the cost requirement must be fulfilled crucially to maintain a strategic distance from SLA infringement. In this paper, the cost we broke down is the Profit in reasonable, which ought to be Cost by Cost, claiming point by point cost and cost are resolved at running period, and this change can help to straightforward the cost demonstrate.
Like other cloud benefit, the execution and accessibility necessity are stipulated in the SLAs. In SLA, the reaction time is typically used to assess the execution. For instance, the coordinator of some site requires that the reaction time of each site page in their site must be not surpassing 0.2s, which can be set as the edge to decide the use of virtual machines. By and large execution is specifically dictated by the
sum what's more, every individual execution of utilized VM. We can without much of a stretch get the estimated straight connection between the execution what's more, virtual machines. Moreover, correspondence cost between virtual machines is nontrivial for the execution of cloud-based huge information applications. In an extraordinary measure of cloud applications, correspondence cost has more effect all in all execution than the figuring technique does. The more extended the separation is the more noteworthy the correspondence cost will be. Subsequently the relationship between correspondence cost and the separation between VMs is surmised straight too.
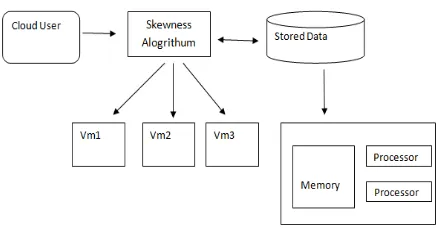
Fig 1. System Architecture
IV.Algorithm
A. Skewness Algorithm
Skewness is often applied in determining which measurement of central tendency is the best at finding
the “center.”
For example, if you looked at the 10 people who graduated with cultural geography degrees from UNC
in 1984, you’d find the mean amount that people
made in the next year is around 3.5 million dollars. Say what? Obviously someone who studies cultural
geography isn’t a millionaire at 22, so what’s
happening here? Michael Jordan was one of those 10 people who graduated, and he made 33 million dollars.
However, upon realising that this distribution is more skewed than a shrimp skewer, you realize that the mean is not a very good estimate of the amount of money someone would make graduating with a cultural geography degree from UNC. Instead, you take the median, which is around 50,000 dollars, not 33 million dollars.
This presents the idea of strain to evaluate the variety of the use of various assets on the server. Also, that it is the quantity of assets we consider, n attempt to ri and is the utilization of assets of the ith. It characterizes the assets and skewness of server P.
Consider r is the normal use of all assets of the server p. Truth be told, a wide range of assets since it is vital to execution, it must think about the bottleneck assets
in the above figuring’s. By limiting the contortion, we
can utilize a mix of various kinds effectively stacked, to enhance the general use of the server assets. The calculation can be keep running all the time to assess the asset allotment status considering the asset necessities of the anticipated eventual fate of VM.
the memory utilization is more prominent than 80%. In plummeting request the temperature, it sorts the rundown of problem areas in the framework. The objective of the proposed approach is to wipe out the problem areas when all conceivable. If not, as low as could be expected under the circumstances, to keep up its temperature. For every server P, decides it is important to move away to the initially, or of that VM. If it is the VM moved away, in view of the temperature acquired the server to sort the rundown of virtual machines.
The reason for the proposed approach will move off the virtual machine that can diminish the temperature of the most servers. Because of a tie, it is conceivable to diminish the skewness of the server expelling the most and select the VM. Regardless of whether can discover the goal server for the comparing, for each VM in the rundown, please observe. In the wake of tolerating this virtual machine, the server ought not be made to the problem area. Among all servers, for example, this, you select the one that can acknowledge by this VM that skewness, to decrease most. This decrease, it please knows that it is negative to expanded skewness than that, it is intended to choose the server. On the off chance that the goal server is discovered, record the relocation of virtual machines on the server and updates the figure heap of related servers. Something else, go to the following virtual machine in the rundown; please search for the goal server for them. With a specific end goal to have the capacity to discover the goal server for any of the virtual machine, think about the accomplishment of this execution of the calculation, we will move to the following problem area as long. If you don't mind take note of that you relocate away to a solitary VM every execution of the calculation is at most from the server over-burden. This dispenses with the problem area essentially, at any rate, are not bring down its temperature. If you leave a problem area, the calculation will rehash this procedure in the
execution of the choice of tailing it. It is conceivable to have the capacity to relocate away more than one VM for each run-time, to outline a calculation. Notwithstanding, on the off chance that they are over-burden as of now, amid the period, this enables you to include a heap increasingly the server to be connected. It was chosen to abandon some an opportunity to respond before it utilizes a more preservationist approach, to begin extra relocation of the framework.
B. SVM Algorithm
SVM aka Support Vector Machine’s depends on
supervised learning algorithms. The aim of using SVM is to correctly classify unseen data. SVMs have a number of applications in several fields like Face detection, Text and hypertext categorization, Classification of images, Bioinformatics, Handwriting recognition, etc..,
In Face Detection, It classifies the parts of the image as face and non-face. It contains training data of n x n pixels with a two-class face (+1) and non-face (-1). Then it extracts features from each pixel as face or non-face. Creates a square boundary around faces on the basis of pixel brightness and classifies each image by using the same process.
In Bioinformatics,In the field of computational biology, the protein remote homology detection is a common problem. The most effective method to solve this problem is using SVM. In last few years, SVM algorithms have been extensively applied for protein remote homology detection. These algorithms have been widely used for identifying among biological sequences. For example classification of genes, patients on the basis of their genes, and many other biological problems.
strategy because of their summed-up properties. With its strong hypothetical establishment and furthermore demonstrated adequacy, SVM has added to specialists' accomplishment in numerous fields. In any case, SVM's suffer from a generally perceived versatility issue in both memory prerequisite and computational time. SVM's calculation and memory necessities in- wrinkle quickly with the quantity of examples in informational collection, numerous informational collections are not reasonable for classification. The SVM calculation is planned as quadratic enhancement issue. Quadratic improvement issue has O(m3) time and O(m2) space many-sided quality, where m is the preparation set size. The calculation time of SVM preparing is quadratic in the quantity of preparing occurrences. The rest way to deal with conquer substantial scale informational collection preparing is to decrease feature vector estimate. Highlight determination and highlight change techniques are essential approaches for diminishing vector measure. Highlight choice calculations pick a subset of the highlights from the first list of capabilities and highlight change calculations makes new information from the first element space to another space with diminished dimensionality. In writing, there are a few strategies; Singular Esteem Decomposition (SVD), Principal Component Analysis (PCA), Independent Component Analysis (ICA), Correlation Based Feature Selection (CFS), Sampling based informational collection determination. These strategies have a major issue for speculation of machine learning model. Second approach for vast scale informational collection preparing is lumping. A parallel SVM preparing calculation that every subset of entirety dataset is prepared with SVM and after that the classifiers are joined into a single classifier has been proposed. An appropriated bolster vector machine (DSVM) calculation that bolster vectors (SVs) on unequivocally associated networks. Each site inside an emphatically associated arrange classifies subsets of preparing information locally by means of SVM and passes the figured SVs to its relative destinations
what's more, gets SVs from its precursor destinations and recalculates the SVs and passes them to its relative destinations et cetera. One needs to make a mistake on the old Support Vectors (which speak to the old learning set) more exorbitant than a mistake on another illustration. The dispersed help vector machine (DSVM) calculation that SVs locally and forms them by and large in a focal handling focus. This calculation enhanced by permitting the information preparing focus to send bolster vectors back to the conveyed information source and iteratively accomplish the worldwide ideal. A calculation that executed conveyed processors into course top-down system topology, Cascade SVM. The base hub of the system is the focal handling focus. The appropriated SVM techniques in these works unite and increment test precision. These works have comparable issues. They require a predefined organize topology and PC measure in their system. The execution of preparing relies upon the uncommon network configuration. Principle thought of current disseminated SVM strategies is rest information lumping then parallel usage of SVM preparing. Worldwide synchronization overheads are not considered in these methodologies.
Cloud Computing based SVM strategy is proposed with MapReduce method for dispersed preparing period of calculation. By part preparing set over a
distributed computing framework’s information hub,
V.CONCLUSION
The relations among the cost, execution, and accessibility of one cloud-based enormous information application is represented by the figure above, what's more, constructed three models. Considering these three models we proposed BRA calculation to get the ideal arrangement meeting all prerequisites. At that point we composed and actualized an entire way to deal with designate assets of huge information application running on cloud. At last, we perform three arrangements of SLAs to confirm the plausibility of our approach and contrasted it and seven other ways to deal with demonstrate the viability. In future, we will grow us investigate in two viewpoints. The first is to include more imperatives, counting the security and information preparing inclination. The second one is to test our approach on cutting edge organizing situations, for example, Software-Defined Networking (SDN).
VI.REFERENCES
[1]. S. Y. Li, W. Dai, Z. Ming, and M. Qiu, “Privacy
protection for preventing data over-collection
in smart city,” IEEE Transactions on
Computers, vol. 65, no. 5, pp. 1339-1350, 2015. [2]. M. Qiu, L. Chen, Y. Zhu, J. Hu, and X. Qin,
“Online data allocation for hybrid memories on
embedded tele-health systems,” in 2014 IEEE
11th Intl Conf on Embedded Software and Syst (ICESS), Aug 2014, pp. 574-579.
[3]. M. Qiu and E. H.-M. Sha, “Cost minimization
while satisfying hard/soft timing constraints for
heterogeneous embedded systems,” ACM
Transactions on Design Automation of Electronic Systems, vol. 14, no. 2, p. 25, 2009.
[4]. J. Niu, C. Liu, Y. Gao, and M. Qiu, “Energy
efficient task assignment with guaranteed probability satisfying timing constraints for
embedded systems,” IEEE Transactions on
Parallel and Distributed Systems, vol. 25, no. 8, pp. 2043-2052, 2014.
[5]. K. Gai and S. Li, “Towards cloud computing: a
literature review on cloud computing and its
development trends,” in 2012 Fourth Int’l Conf.
on Multimedia Information Networking and Security, Nanjing, China, 2012, pp. 142-146.press.
[6]. J. Li, Z. Ming, M. Qiu, G. Quan, X. Qin, and T.
Chen, “Resource allocation robustness in multi
-core embedded systems with inaccurate
information,” Journal f Systems Architecture,
vol. 57, no. 9, pp. 840-849, 2011.
[7]. A. Beloglazov and R. Buyya, “Optimal online
deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in
cloud data centers,” Concurrency and
Computation: Practice and Experience, vol. 24, no. 13, pp. 1397-1420, 2012.
[8]. M. T. Sandholm, J. Ward, F. Balestrieri, and B.
A. Huberman, “Qos-based pricing and
scheduling of batch jobs in openstack clouds,”
arXiv preprint arXiv:1504.07283, 2015.
[9]. O. Elzeki, M. Reshad, and M. Elsoud,
“Improved max-min algorithm in cloud
computing,” International Journal of Computer
Applications, vol. 50, no. 12, pp. 22-27, 2012. [10]. H. Chen, F. Wang, N. Helian, and G. Akanmu,
“User-priority guided min-min scheduling
algorithm for load balancing in cloud
computing,” in 2013 National Conference on
Parallel Computing Technologies, Feb 2013, pp. 1-8.
[11]. C.-L. Hung, H.-h. Wang, and Y.-C. Hu,
“Efficient load balancing algorithm for cloud
computing network,” in International
Conference on Information Science and Technology, 2012, pp. 28-30.
[12]. Wireless Y. Li, M. Chen, W. Dai, and M. Qiu,
scheduling mobile cloud computing,” IEEE
Systems Journal, vol. PP, no. 99, pp. 1-10, 2015.
Cite this article as :
Dr. P. Tamijiselvy, Ramprakash M, Aswath R, "Dynamic Allocation of Cloud Resources Using Skewness and SVM Algorithm", International Journal of Scientific Research in Computer Science, Engineering and Information Technology (IJSRCSEIT), ISSN : 2456-3307, Volume 5 Issue 2, pp. 402-410, March-April 2019. Available at doi : https://doi.org/10.32628/CSEIT1952103