Abstracting Multi-Core Topologies with
MCTOP
Georgios Chatzopoulos
1, Rachid Guerraoui
1, Tim Harris
2and Vasileios Trigonakis
2∗†1
EPFL
{
first.last
}
@epfl.ch
2
Oracle Labs
{
timothy.l.harris, vasileios.trigonakis
}
@oracle.com
Abstract
Portability and efficiency are usually antagonists in multi-core computing. In order to develop efficient code, one needs to take into account the topology of the target multi-cores (e.g., for locality). This clearly hampers code portability. In this paper, we show that you can have the cake and eat it too. We introduce MCTOP, an abstraction of multi-core topologies augmented with important low-level hardware in-formation, such as memory bandwidths and communication latencies. We show how to automatically generateMCTOP using libmctop, our library that leverages the
determin-ism of cache-coherence protocols to infer the topology of multi-cores using only latency measurements.
MCTOP enables developers to accurately and portably define high-level performance optimization policies. We illustrate several such policies through four examples: (i-ii) thread placement in OpenMP and in a MapReduce li-brary, (iii) a topology-aware mergesort algorithm, as well as (iv) automatic backoff schemes for locks. We illustrate the portability of these optimizations on five processors from In-tel, AMD, and Oracle, with low effort.
1.
Introduction
Since 2000, computing systems are becoming more diverse in terms of the numbers of threads per core, cores per socket, as well as the on-chip and off-chip interconnects. This ten-dency makes the task of developers very challenging, for they need to fine-tune software to the underlying hardware in order to achieve performance (e.g., [12, 18, 19, 30, 37]). Furthermore, optimizing for specific multi-core topologies hinders software portability. In fact, the need for such opti-mizations raises two main questions: (i) how to harvest and ∗This project started while the author was interning at Oracle Labs and was completed while the author was at EPFL.
†The authors appear in alphabetical order.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
EuroSys ’17, April 23 - 26, 2017, Belgrade, Serbia c
2017 Copyright held by the owner/author(s). Publication rights licensed to ACM.
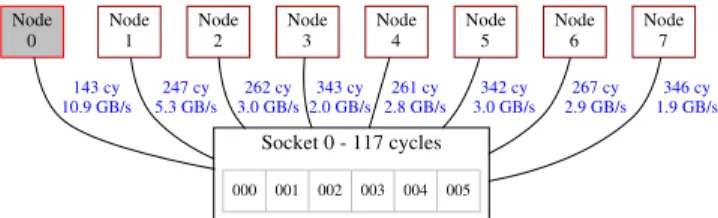
ISBN 978-1-4503-4938-3/17/04. . . $15.00 DOI: http://dx.doi.org/10.1145/3064176.3064194 Socket 0 - 117 cycles 000 001 002 003 004 005 Node 0 143 cy 10.9 GB/s Node 1 247 cy 5.3 GB/s Node 2 262 cy 3.0 GB/s Node 3 343 cy 2.0 GB/s Node 4 261 cy 2.8 GB/s Node 5 342 cy 3.0 GB/s Node 6 267 cy 2.9 GB/s Node 7 346 cy 1.9 GB/s
(a) Topology of a single socket, augmented with the intra-socket communication latencies, and memory latencies and bandwidths.
0 1 197 cy 5.3 GB/s 2 217 cy 3.0 GB/s 4 217 cy 2.8 GB/s 6 217 cy 2.9 GB/s 3 217 cy 2.8 GB/s 217 cy 5 4.2 GB/s 7 217 cy 2.7 GB/s 197 cy 5.3 GB/s 217 cy 3.0 GB/s 217 cy 2.8 GB/s 217 cy 2.9 GB/s 217 cy 2.7 GB/s 197 cy 5.3 GB/s 217 cy 2.8 GB/s 217 cy 3.0 GB/s 197 cy 5.3 GB/s level 4 (2 hops) 300 cy
(b) Cross-socket topology, augmented with socket-to-socket laten-cies and bandwidths. Level 4 represents non-direct links.
Figure 1: Visualization of the MCTOP topology of an 8-socket AMD processor. Both the topology and the graphs are automatically generated bylibmctop.
expose multi-core details in software, and (ii) how to fine-tune according to these details, while ensuring portability.
Traditionally, developers have been relying on the topol-ogy information of operating systems, through libraries, for abstracting the topology of multi-cores (e.g., using
libnuma [47] on Linux, liblgrp [6] on Solaris, or
hwloc[19]). These libraries offer a topology representation
of multi-cores, as well as a companion interface for placing threads (and data). However, the provided representations are low-level and offer only the limited topology view of the operating system. As such, developers do not have access to the performance characteristics of the underlying multi-core processor. Moreover, developers still need to optimize their software for each platform. For example, they need to manually identify the hardware contexts that belong to the
same cores (usually for avoiding them), calculate the best-connected sockets, and consult processor manuals for dis-covering the actual topology of their multi-core. The result is ad-hoc implementations, tied to the underlying platform.
We present in this paper an easier, more portable ap-proach to optimizing software for multi-cores. We intro-duce MCTOP, a multi-core topology abstraction of impor-tant low-level information, such as communication latencies and memory bandwidths.MCTOPis automatically generated and exposed to software developers by ourlibmctop
user-level library. Figure 1 depicts the visual representation of the MCTOPof an AMD Opteron. Of course, a developer could directly use this low-level information to fine-tune her soft-ware for this Opteron. For instance, she could decide to use sockets 0 and 1 as they are connected with minimum latency. However, such optimizations—that rely on the specifics of a processor—are not portable. Instead, she could write apolicy that uses any two sockets (if available) that minimize latency. MCTOPenables the design of easy, portable, and efficient optimizations using such high-level policies. In turn, these policies make use of the actual numbers included inMCTOP. Essentially,MCTOPallows developers to express high-level semantics that utilize the low-level performance details of multi-cores, thus deliveringportable optimizations. For in-stance, usingMCTOP, we can easily define policies such as “use one hardware context per core,” “use two sockets with maximum bandwidth,” or even “use the maximum number of threads, in the two most remote sockets, so that each thread has access to at least 3 MB of LLC.”
libmctop is based on MCTOP-ALG, our novel
algo-rithm for inferring the topology of multi-cores.MCTOP-ALG relies on two fundamental observations: (i)cache-coherence
protocols are deterministic in the absence of contention,
and (ii) communication latencies characterize the topol-ogy. These observations are in accordance with the net-work view of multi-cores that has been proposed for OS de-sign [12, 13, 70]. MCTOP-ALG leverages these two obser-vations by collecting accurate core-to-core communication latencies, which are used to infer the topology of the proces-sor. On top of this topology,libmctopcollects additional
low-level measurements, such as cache latencies and mem-ory latencies/bandwidths. The end result is an automatically-generatedMCTOPrepresentation of the multi-core.
We argue that MCTOP-ALG’s measurement-based ap-proach is superior to loading multi-core topologies from the underlying OS or hardware (e.g., usingCPUID) for various
reasons: (i)portability—collecting measurements is almost identical on any architecture or OS, unlike reading topol-ogy info from the OS or the hardware; (ii)
forward/back-wards compatibility—measurements do not depend on the
OS version; (iii)correctness—numbers do not lie, while the OS can be misconfigured1; (iv)extensibility—independence
1On the multi-core of Figure 1, the OS has an incorrect mapping of cores to memory nodes, whileMCTOP-ALGinfers the correct mapping.
from the information that vendors do or do not expose; and
(v)accuracy—a measurement-based approach collects
ac-curate low-level measurements that we need inMCTOP. We illustrate portable optimizations withMCTOPthrough four examples on five processors from Intel, AMD, and Oracle. First, we automate backing off in locking using the latencies ofMCTOP. Our optimized spinlocks deliver up to 39% average throughput improvements. Second, we design a topology-aware mergesort algorithm that builds a cross-socket merge tree on top ofMCTOP. Our algorithm is 17% faster on average than the parallel sort algorithm of the C++ standard library which is topology agnostic.
Furthermore, we design a thread placement library, called MCTOP-PLACE, on top of MCTOP (libmctop) and use
it in optimizing the Metis MapReduce library [53] and OpenMP [7]. MCTOP-PLACE includes 12 high-level per-formance policies that optimize for locality, bandwidth, or energy efficiency. We plug MCTOP-PLACE in Metis and achieve 17% better average performance, while consuming 14% less energy in four of the workloads. Similarly, we ex-tend OpenMP with runtime support for configuring place-ment policies, enabling portable, high-level, and dynamic thread placement. We evaluate Green-Marl’s [42] OpenMP-based graph workloads and improve the performance of var-ious graph analytics, such as PageRank, by 22% on average.
To summarize, our main contributions are as follows: 1.MCTOP, a rich multi-core topology abstraction that
en-ables policy-based portable software optimizations; 2.MCTOP-ALG, a portable algorithm for inferring the
topology of multi-cores without relying on the topology information of the OS or the hardware;
3.libmctop and the software we build using
libmctop, both available at:
http://lpd.epfl.ch/site/mctop
Of course, libmctophas certain limitations. We have
portedlibmctop onx86and SPARCarchitectures, and
cannot yet guarantee the effectiveness of MCTOP-ALG on other architectures (e.g.,ARM,POWER). Additionally, in
or-der to collect accurate measurements,libmctoprequires a
solo execution on the target processor for the one run that in-fers the topology (this means stopping all other applications for the duration oflibmctop’s first execution).
The rest of the paper is organized as follows. In Sec-tion 2, we describe the programming interface ofMCTOP. In Section 3, we introduce a generic algorithm for harvest-ingMCTOPtopologies of multi-cores, while in Section 4, we present how to extendMCTOPtopologies. We then describe examples of high-level performance optimization policies in Section 5 and use these ideas in designing a thread place-ment library in Section 6. Finally, we present practical ex-amples, our related work, and conclude the paper in Sec-tions 7, 8, and 9, respectively.
2.
The
MCTOPTopology Abstraction
The first step for achieving portable optimizations is to pro-vide a programming abstraction of multi-core topologies. Software can build on this abstraction and avoid using the limited, non-extensible, specific view of multi-cores that is exposed by operating systems. To this end, we design MCTOP (multi-core topology), a portable topology abstrac-tion. We opt for MCTOP, and for a user-level implemen-tation oflibmctop, instead of changing the existing OS
interfaces and enriching them with extra information. This way, MCTOP andlibmctopare (i) portable across OSs,
and (ii) readily available to software developers, without the need to install new OS kernels. Additionally,MCTOPhas two important characteristics. First,MCTOPisgeneric: It can be used to describe many modern multi-cores. Second,MCTOP
is extensible: It can be extended to support any low-level
details of multi-cores, which are necessary to achieve fine-tuning of software and portability at the same time.
In the remainder of this section, we first highlight cer-tain characteristics of modern multi-cores that affect the de-sign of MCTOP, we then describe the programming inter-face ofMCTOP, and, finally, we illustrate several examples ofMCTOPtopologies.
State of Affairs of Modern Multi-Cores. Multi-core
servers are typically multi-socket processors with
non-uniform memory accesses(NUMA—i.e., the latency to
ac-cess data depends on the placement of both the thread and the data). Non-uniformity is mainly a result of the multiple sockets of the processor. Traditionally, every socket is di-rectly connected to onelocalmemory node.2
Furthermore, modern multi-cores include several CPU cores in order to offer thread-level parallelism. Many proces-sors also employ simultaneous multi-threading (SMT) for even higher thread-level parallelism. In short, with SMT, every core contains more than onehardware context (i.e., the scheduling granularity for software threads is hardware contexts, not cores). Each hardware context shares most of the core’s resources with the other hardware context(s) (e.g., the caches and the pipeline). Both Linux and Solaris expose hardware contexts as individual cores to the user.
libmctop Programming Interface. MCTOP topologies
are stored in description files, which are created by
libmctop once and are then used to load the topology.
Once a topology is loaded, the developer can either use
libmctop’s programming interface to access MCTOP, or
visualize the topology as textual output or as a graph.
libmctoprepresentsMCTOPtopologies as a set of
struc-tures that are linked together to describe the processor. The most important structures ofMCTOPare shown in Table 1.
These structures are interconnected (i) vertically, in or-der to represent the actual topology, and (ii) horizontally, 2On very large NUMA machines, it is possible to have fewer memory nodes than sockets (e.g., two sockets can share one memory node).
hw context The lowest scheduling unit of the processor. If SMT
exists,hw contextrepresents a hardware context,
otherwise it represents an actual core.
hwc group A group ofhw contexts orhwc groups, such as a
core that contains two hardware contexts, or a group of cores that share the L2 cache. There might be multiple levels ofhwc groupwithin a socket.
socket Ahwc groupwith additional information about the
NUMA memory nodes and the interconnection with other sockets.
node A memory node with information such as capacity. interconnect The interconnection between twosockets. Contains
information such as the communication latencies.
mctop The structure that represents a processor and links
everything together. Contains info about the latency levels, SMT, the number of sockets and cores, etc. Table 1: The main structures ofMCTOP.
for simplifying the traversal of all objects at each level. For instance, a hw context holds pointers to its parent
hwc group, its parentsocket, as well as its successor
(in terms of proximity)hw context. Additionally, every
structure holds pointers to additional low-level information, such as memory latencies and bandwidths.
We opt for a representation that uses terms that match any modern processor and are extensible for future designs. As such, the interface oflibmctopuses terms which are
familiar to system designers, such as:
•mctop get local node(hw ctx) to get the local
node of ahw context;
•mctop socket get cores(socket) to get the
cores of asocket; and
•mctop get latency(id0, id1)to get the latency
between any two components. 2.1 Examples ofMCTOPTopologies
libmctopcan generate a simplified visual representation
ofMCTOP(using Graphviz [1]) in order to make the topol-ogy more accessible to developers. We illustrateMCTOP
us-inglibmctopon variousx86andSPARCprocessors. We
present below the automatically generated graphs and pro-vide details of each platform. In Section 7, we use these plat-forms in our experiments.
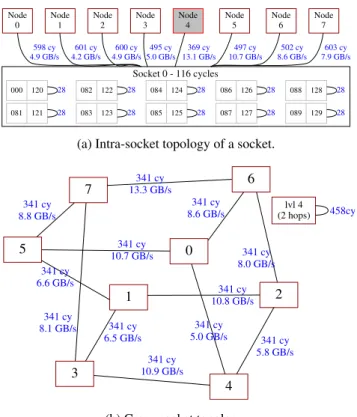
ReadingMCTOP Graphs. MCTOP’s visual representation includes two main graphs, depicting the intra- and the cross-socket topologies respectively—e.g., Figure 2. The intra-socket graph (Figure 2a) includes the communication laten-cies inside a socket—28 cycles between SMT contexts of the same core and 116 cycles between difference cores. It also includes the latency and bandwidth from this socket to all the available memory nodes. The local node (Node 4—shown as a gray box) has a latency of 369 cycles and a maximum throughput of 13.1 GB/s.
The cross-socket graph (Figure 2b) shows the commu-nication latencies between hardware contexts on different sockets of the machine (e.g., two threads on sockets 0 and
5 have a latency of 341 cycles), as well as the memory band-widths when accessing the memory of another socket (cross-socket bandwidth is limited by the interconnect). Finally, the two-hops latency between hardware contexts that belong to sockets that are not directly connected is depicted as “lvl 4.”
Intel Xeon Ivy Bridge (Ivy). The 20-core Intel Xeon (used
as an example for explainingMCTOP-ALG—Figure 6) sists of two E5-2680 v2 10-core sockets (40 hardware con-texts). Ivy runs at 1.2-2.8 GHz and includes 32 KB, 256 KB, and 25 MB (per die) L1, L2, and LLC, respectively.
Intel Xeon Westmere (Westmere). The 80-core Intel Xeon
(Figure 2) consists of eight E7-8867L 10-core sockets (160 hardware contexts). Westmere operates at 1.1-2.1 GHz and has 32 KB, 256 KB, and 30 MB (per die) L1, L2, and LLC data caches, respectively.
Intel Xeon Haswell (Haswell). The 48-core Intel Xeon
(graph not shown due to space limitations) consists of four E7-4830 v3 12-core sockets (96 hardware contexts). Haswell operates at 1.2-2.7 GHz and has 32 KB, 256 KB, and 30 MB (per die) L1, L2, and LLC data caches, respectively.
AMD Opteron (Opteron). The 48-core AMD Opteron
(Figure 1) contains four AMD Opteron 6172 multi-chip modules (MCMs) [27]. Each MCM has two 6-core dies, for a total of eight sockets. Opteron operates at 2.1 GHz and has 64 KB, 512 KB, and 5 MB (per die) L1, L2, and LLC data caches, respectively. Socket 0 116 cycles 089 129 28 088 128 28 087 127 28 086 126 28 085 125 28 084 124 28 083 123 28 082 122 28 081 121 28 000 120 28 Node 0 598 cy 4.9 GB/s Node 1 601 cy 4.2 GB/s Node 2 600 cy 4.9 GB/s Node 3 495 cy 5.0 GB/s Node 4 369 cy 13.1 GB/s Node 5 497 cy 10.7 GB/s Node 6 502 cy 8.6 GB/s Node 7 603 cy 7.9 GB/s
(a) Intra-socket topology of a socket.
0 4 341 cy 5.0 GB/s 5 341 cy 10.7 GB/s 6 341 cy 8.6 GB/s 1 10.8 GB/s341 cy 2 3 341 cy 6.5 GB/s 341 cy 6.6 GB/s 341 cy 5.8 GB/s 341 cy 8.0 GB/s 341 cy 10.9 GB/s 7 341 cy 8.1 GB/s 341 cy 8.8 GB/s 341 cy 13.3 GB/s lvl 4 (2 hops) 458cy (b) Cross-socket topology.
Figure 2:MCTOPof an 8-socket Intel processor.
Socket 0 207 cycles 056 057 058 059 060 061 062 063 101 048 049 050 051 052 053 054 055 101 040 041 042 043 044 045 046 047 101 032 033 034 035 036 037 038 039 101 024 025 026 027 028 029 030 031 101 016 017 018 019 020 021 022 023 101 008 009 010 011 012 013 014 015 101 000 001 002 003 004 005 006 007 101 Node 0 479 cy 28.2 GB/s Node 1 679 cy 15.3 GB/s Node 2 689 cy 15.2 GB/s Node 3 688 cy 15.1 GB/s
Figure 3:MCTOPof a socket of an Oracle processor.
Oracle SPARC T4-4 (SPARC). The Oracle SPARC T4-4
(Figure 3) consists of four T4 sockets with eight cores per socket and a total of 256 hardware contexts. SPARC operates at 3 GHz and has 16 KB, 256 KB, and 4 MB (per die) L1, L2, and LLC data caches, respectively.
3.
MCTOP-
ALG: Inferring Topologies
We introduce MCTOP-ALG, our algorithm that infers the basic topology of cache-coherent shared memory proces-sors using only latency measurements.MCTOP-ALG relies on two simple, yet important observations regarding cache-coherence protocols of modern multi-core processors. OBSERVATION1
(Cache-coherence protocols are deterministic in the ab-sence of contention)
Cache-coherence protocols are responsible for keeping data consistent in the various caches of multi-cores. Most modern processors implement theMESI coherence proto-col [60], or variants of MESI.
Hardware cache-coherence protocols are deterministic by design. Still, non-deterministic schedules can appear, but only under contention (e.g., if multiple threads contend for a cache line, then the schedule of coherence messages is nat-urally not deterministic). In the absence of contention, hard-ware coherence protocols deliver deterministic schedules. In simple words, a given request type (e.g., requesting for writ-ing), on a given multi-core, for a block of data in a specific MESI state and the same placement, always takes the same steps. Consider the simplified example of Figure 4, where a cache lineclis in the modified state3in the caches of coreo
and another coreris requesting the data for writing—a
re-quest known asrequest for ownership(RFO). The RFO re-quest forcl misses in the private caches ofr. The request
finds thatoholds the only copy ofclthrough the last-level
cache (LLC) (or using a directory, depending on the specific implementation of MESI4). Once the copy is found, an
inval-idation request is sent too’s private caches to discard their
3Recall that the modified state means that this cache line is the only fresh copy of the data and this data is stale in memory.
4For example, modern Intel server processors use the LLC, while AMD servers use a directory (known as the probe filter [27]).
directory
socket 0
L3 (LLC) L1 core r L2 cl L1 core o L2 1-RFO 5-inv 2-miss 3-miss 4a-hit 4b-miss 6-granted L3 (LLC) L1 core r L2 cl 5-invalidate 4-hit 3-miss 1-RFO 2-miss 6-granted L1 core o L2so
c
ke
t
0
Figure 4: Coherence traffic for an RFO request. copy ofcl, after which the RFO request is granted tor. Ifr
is not in the same socket aso, the RFO request is propagated
to the corresponding socket.
Overall, the coherence request takes deterministic steps. Hence, we can devise thread schedules that accurately mea-sure the communication latency between any two contexts. OBSERVATION2
(Communication latencies characterize the topology) Multi-cores include several cache levels for minimizing la-tency to data. The lala-tency of a request defines at large the
distancebetween the source of the request and the placement
of data. For instance, on the 2-socket Intel Xeon Ivy Bridge (see Section 2.1), 4, 12, and 42 cycles are (approximately) the latencies to access the three levels of caches, while 112 and 308 cycles represent the latencies to access data that are in the private caches of another core within the same socket and across sockets, respectively.
Two threads can potentially detect their relative place-ment based on their communication latency. For example, on Ivy, if two threads communicate in approximately 4 cycles,
theyhave toreside on the same core as the L1 cache
deliv-ers this latency. In contrast, communication latency of 300+ cycles reveals that the two threads are on different sockets.
MCTOP-ALG Algorithm. MCTOP-ALG takes advantage of the aforementioned observations by collecting accu-rate hardware-context-to-hardware-context communication latency measurements and using them in inferring the topol-ogy of the machine. The implementation ofMCTOP-ALGin
libmctoprequires only three functionalities from the
un-derlying OS: A way to read the number of available hard-ware contexts and the number of memory nodes, and a way to pin threads to specific contexts.
MCTOP-ALGtakes the following four steps:
1. Collects context-to-context latency measurements→
la-tency table;
2. Clusters close values into groups and normalizes the la-tencies accordingly→normalized latency table;
3. For each latency valuel, categorizes hardware contexts
into groups of contexts that communicate with latency
l with each other and with the same latency with other
groups→per latency level components;
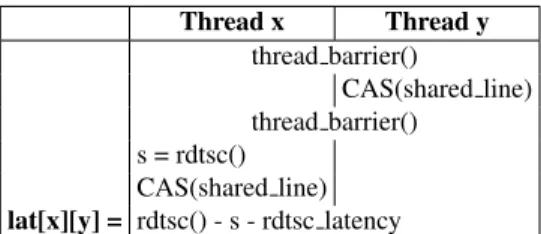
4. Creates the multi-core representation by assigning roles to components→topology; Thread x Thread y thread barrier() CAS(shared line) thread barrier() s = rdtsc() CAS(shared line) lat[x][y] = rdtsc() - s - rdtsc latency
Figure 5: Lock-step execution ofMCTOP-ALG’s threads. We detail below these four steps using Ivy as an example—Figure 6. We then discuss several practical con-siderations regardingMCTOP-ALGand how the correctness of the inferredMCTOPs can be validated.
3.1 Context-to-Context Latencies
MCTOP-ALGuses two threads that move from hardware con-text to hardware concon-text and fill up anN ×N latency
ta-ble, whereNis the number of hardware contexts of the
pro-cessor. For each data point, the two threads execute in lock step as shown in Figure 5 (similar measurements have been used in existing systems research [18, 30, 40, 73]). Thready
brings the data in a modified state in its local caches and then threadxmeasures the latency of its own access to the shared
data using the timestamp counter of the core [4]. Reading the timestamp counter has a non-negligible latency which must be deducted from the latency measurements. Accord-ingly, the execution in Figure 5 subtracts the estimated cost of readingrdtsc(see Section 3.5 for more details).
The use of an atomic operation, such as compare-and-swap (CAS), is crucial for two reasons. First, CAS includes a memory fence, hence it precludes the effects of memory consistency models [67]. Second, CAS brings the data in the modified MESI state. The modified state is necessary for avoiding potential whole-machine communication when broadcasting invalidations for a shared cache line (e.g., in AMD Magny Cours [27, 30]). As we describe in Section 3.5,
libmctop performs the measurements several times to
produce stable results.
The outcome of this step is a latency table (Figure 6 1 ). Note that in practice we only need to take measurements for either the upper or the lower triangular of the table because the topology is symmetric.
3.2 Latency Normalization
As the heatmap of Figure 6 1 shows, the relations between hardware contexts are rather clear. The white diagonal rep-resents the individual contexts, the two light gray diagonals represent the hardware contexts of the same core, and the gray and dark-gray rectangles are the intra- and cross-socket latencies, respectively. To extract these relations, MCTOP -ALG calculates the cumulative distribution function (CDF) of the latency values—Figure 6 2a . The value clusters of CDF represent these aforementioned relations.MCTOP-ALG
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 0 0 124 124 120 120 108 104 104 128 128 320 320 320 320 316 304 304 300 324 324 28 124 124 120 120 108 104 104 128 128 320 320 320 320 316 304 304 300 324 324 1124 0 128 124 120 112 108 108 128 128 324 324 324 320 320 308 304 304 324 328 128 28 128 124 120 112 108 108 128 128 324 324 324 320 320 308 304 304 324 328 2124 128 0 124 124 112 108 108 128 128 328 328 328 328 324 316 312 308 328 328 128 128 28 124 124 112 108 108 132 128 328 328 328 328 324 316 312 308 328 328 3120 124 124 0 124 108 108 104 128 128 328 328 328 328 324 312 312 312 328 328 128 128 128 28 124 108 108 104 128 128 328 328 328 328 324 312 312 312 332 332 4120 120 124 124 0 108 108 104 128 128 324 324 324 320 320 308 304 304 324 324 124 124 124 120 28 108 108 104 124 124 324 324 324 320 320 308 304 304 324 324 5108 112 112 108 108 0 96 92 116 116 312 316 312 308 308 296 292 292 316 316 116 116 116 112 108 28 96 92 116 116 312 316 312 308 308 296 292 292 316 316 6104 108 108 108 108 96 0 92 116 116 308 312 312 308 308 292 292 288 312 312 112 112 112 108 108 96 28 92 116 116 308 312 312 308 308 296 292 288 312 312 7104 108 108 104 104 92 92 0 108 108 308 308 308 304 304 292 288 288 308 308 108 108 108 104 104 92 92 28 108 108 308 308 308 304 304 292 288 288 308 308 8128 128 128 128 128 116 116 108 0 116 312 312 312 308 308 296 292 292 316 316 112 112 112 108 104 92 92 88 28 116 312 316 312 308 308 296 292 292 316 316 9128 128 128 128 128 116 116 108 116 0 312 312 312 308 304 292 292 288 312 312 112 112 112 108 108 96 92 92 116 28 312 312 312 308 304 292 292 288 312 312 10320 324 328 328 324 312 308 308 312 312 0 124 124 120 120 108 104 104 128 128 324 328 328 324 320 308 308 304 328 328 28 124 124 120 120 108 104 104 128 128 11320 324 328 328 324 316 312 308 312 312 124 0 128 124 120 112 108 108 128 128 328 328 328 324 320 308 308 308 332 332 128 28 128 124 120 112 108 108 128 128 12320 324 328 328 324 312 312 308 312 312 124 128 0 124 124 112 108 108 128 128 332 332 332 328 324 312 312 308 332 332 128 128 28 124 124 112 108 108 128 128 13320 320 328 328 320 308 308 304 308 308 120 124 124 0 124 108 108 104 128 128 328 328 328 324 324 312 308 308 332 332 128 128 128 28 124 108 108 104 128 128 14316 320 324 324 320 308 308 304 308 304 120 120 124 124 0 108 108 104 128 128 324 324 324 320 320 308 304 304 328 328 124 124 124 120 28 108 104 104 128 128 15304 308 316 312 308 296 292 292 296 292 108 112 112 108 108 0 96 92 116 116 312 312 312 308 308 296 292 292 316 316 116 116 116 112 108 28 96 92 116 116 16304 304 312 312 304 292 292 288 292 292 104 108 108 108 108 96 0 92 116 116 312 312 312 308 308 296 292 292 316 316 112 112 112 108 108 96 28 92 116 116 17300 304 308 312 304 292 288 288 292 288 104 108 108 104 104 92 92 0 108 112 308 312 308 304 304 292 288 288 312 312 108 108 108 108 104 92 88 28 108 108 18324 324 328 328 324 316 312 308 316 312 128 128 128 128 128 116 116 108 0 116 316 316 316 312 312 296 296 292 316 320 112 112 112 108 104 92 92 88 28 116 19324 328 328 328 324 316 312 308 316 312 128 128 128 128 128 116 116 112 116 0 316 316 316 308 308 296 296 292 316 316 112 112 112 108 108 96 92 92 116 28 20 28 128 128 128 124 116 112 108 112 112 324 328 332 328 324 312 312 308 316 316 0 124 124 140 140 128 108 104 128 128 320 320 320 320 316 304 304 300 324 324 21124 28 128 128 124 116 112 108 112 112 328 328 332 328 324 312 312 312 316 316 124 0 128 124 120 112 108 104 128 128 324 324 324 320 320 308 304 304 324 324 22124 128 28 128 124 116 112 108 112 112 328 328 332 328 324 312 312 308 316 316 124 128 0 124 124 112 108 108 128 128 328 328 328 328 324 316 312 308 332 328 23120 124 124 28 120 112 108 104 108 108 324 324 328 324 320 308 308 304 312 308 140 124 124 0 124 108 108 104 128 128 328 328 328 328 324 312 312 312 332 328 24120 120 124 124 28 108 108 104 104 108 320 320 324 324 320 308 308 304 312 308 140 120 124 124 0 108 108 104 124 124 324 324 324 320 320 308 304 304 324 328 25108 112 112 108 108 28 96 92 92 96 308 308 312 312 308 296 296 292 296 296 128 112 112 108 108 0 96 92 116 116 316 316 316 312 308 296 296 296 316 316 26104 108 108 108 108 96 28 92 92 92 308 308 312 308 304 292 292 288 296 296 108 108 108 108 108 96 0 92 116 116 312 316 316 312 312 296 296 292 316 316 27104 108 108 104 104 92 92 28 88 92 304 308 308 308 304 292 292 288 292 292 104 104 108 104 104 92 92 0 108 112 312 312 312 308 304 292 292 288 312 312 28128 128 132 128 124 116 116 108 28 116 328 332 332 332 328 316 316 312 316 316 128 128 128 128 124 116 116 108 0 116 316 316 316 312 312 296 296 296 316 316 29128 128 128 128 124 116 116 108 116 28 328 332 332 332 328 316 316 312 320 316 128 128 128 128 124 116 116 112 116 0 312 316 316 312 308 296 296 292 316 316 30320 324 328 328 324 312 308 308 312 312 28 128 128 128 124 116 112 108 112 112 320 324 328 328 324 316 312 312 316 312 0 124 124 120 120 108 104 104 128 128 31320 324 328 328 324 316 312 308 316 312 124 28 128 128 124 116 112 108 112 112 320 324 328 328 324 316 316 312 316 316 124 0 124 124 120 112 108 108 128 128 32320 324 328 328 324 312 312 308 312 312 124 128 28 128 124 116 112 108 112 112 320 324 328 328 324 316 316 312 316 316 124 124 0 124 124 112 108 108 128 128 33320 320 328 328 320 308 308 304 308 308 120 124 124 28 120 112 108 108 108 108 320 320 328 328 320 312 312 308 312 312 120 124 124 0 124 108 108 104 128 128 34316 320 324 324 320 308 308 304 308 304 120 120 124 124 28 108 108 104 104 108 316 320 324 324 320 308 312 304 312 308 120 120 124 124 0 108 108 104 128 128 35304 308 316 312 308 296 296 292 296 292 108 112 112 108 108 28 96 92 92 96 304 308 316 312 308 296 296 292 296 296 108 112 112 108 108 0 96 92 116 116 36304 304 312 312 304 292 292 288 292 292 104 108 108 108 104 96 28 88 92 92 304 304 312 312 304 296 296 292 296 296 104 108 108 108 108 96 0 92 116 116 37300 304 308 312 304 292 288 288 292 288 104 108 108 104 104 92 92 28 88 92 300 304 308 312 304 296 292 288 296 292 104 108 108 104 104 92 92 0 108 112 38324 324 328 332 324 316 312 308 316 312 128 128 128 128 128 116 116 108 28 116 324 324 332 332 324 316 316 312 316 316 128 128 128 128 128 116 116 108 0 116 39324 328 328 332 324 316 312 308 316 312 128 128 128 128 128 116 116 108 116 28 324 324 328 328 328 316 316 312 316 316 128 128 128 128 128 116 116 112 116 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 0 0 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 28 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 1112 0 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 28 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 2112 112 0 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 28 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 3112 112 112 0 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 28 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 4112 112 112 112 0 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 28 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 5112 112 112 112 112 0 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 28 112 112 112 112 308 308 308 308 308 308 308 308 308 308 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 6112 112 112 112 112 112 0 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 28 112 112 112 308 308 308 308 308 308 308 308 308 308 0 28 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 7112 112 112 112 112 112 112 0 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 28 112 112 308 308 308 308 308 308 308 308 308 308 1112 28 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 8112 112 112 112 112 112 112 112 0 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 28 112 308 308 308 308 308 308 308 308 308 308 2112 112 28 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 9112 112 112 112 112 112 112 112 112 0 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 28 308 308 308 308 308 308 308 308 308 308 3112 112 112 28 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 10308 308 308 308 308 308 308 308 308 308 0 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 28 112 112 112 112 112 112 112 112 112 4112 112 112 112 28 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 11308 308 308 308 308 308 308 308 308 308 112 0 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 28 112 112 112 112 112 112 112 112 5112 112 112 112 112 28 112 112 112 112 308 308 308 308 308 308 308 308 308 308 12308 308 308 308 308 308 308 308 308 308 112 112 0 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 28 112 112 112 112 112 112 112 6112 112 112 112 112 112 28 112 112 112 308 308 308 308 308 308 308 308 308 308 13308 308 308 308 308 308 308 308 308 308 112 112 112 0 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 28 112 112 112 112 112 112 7112 112 112 112 112 112 112 28 112 112 308 308 308 308 308 308 308 308 308 308 14308 308 308 308 308 308 308 308 308 308 112 112 112 112 0 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 28 112 112 112 112 112 8112 112 112 112 112 112 112 112 28 112 308 308 308 308 308 308 308 308 308 308 15308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 0 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 28 112 112 112 112 9112 112 112 112 112 112 112 112 112 28 308 308 308 308 308 308 308 308 308 308 16308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 0 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 28 112 112 112 10308 308 308 308 308 308 308 308 308 308 28 112 112 112 112 112 112 112 112 112 17308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 0 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 28 112 112 11308 308 308 308 308 308 308 308 308 308 112 28 112 112 112 112 112 112 112 112 18308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 0 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 28 112 12308 308 308 308 308 308 308 308 308 308 112 112 28 112 112 112 112 112 112 112 19308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 0 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 28 13308 308 308 308 308 308 308 308 308 308 112 112 112 28 112 112 112 112 112 112 20 28 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 0 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 14308 308 308 308 308 308 308 308 308 308 112 112 112 112 28 112 112 112 112 112 21112 28 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 0 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 15308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 28 112 112 112 112 22112 112 28 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 0 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 16308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 28 112 112 112 23112 112 112 28 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 0 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 17308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 28 112 112 24112 112 112 112 28 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 0 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 18308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 28 112 25112 112 112 112 112 28 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 0 112 112 112 112 308 308 308 308 308 308 308 308 308 308 19308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 28 26112 112 112 112 112 112 28 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 0 112 112 112 308 308 308 308 308 308 308 308 308 308 27112 112 112 112 112 112 112 28 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 0 112 112 308 308 308 308 308 308 308 308 308 308 28112 112 112 112 112 112 112 112 28 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 0 112 308 308 308 308 308 308 308 308 308 308 29112 112 112 112 112 112 112 112 112 28 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 0 308 308 308 308 308 308 308 308 308 308 30308 308 308 308 308 308 308 308 308 308 28 112 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 0 112 112 112 112 112 112 112 112 112 31308 308 308 308 308 308 308 308 308 308 112 28 112 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 0 112 112 112 112 112 112 112 112 32308 308 308 308 308 308 308 308 308 308 112 112 28 112 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 0 112 112 112 112 112 112 112 33308 308 308 308 308 308 308 308 308 308 112 112 112 28 112 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 0 112 112 112 112 112 112 34308 308 308 308 308 308 308 308 308 308 112 112 112 112 28 112 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 0 112 112 112 112 112 35308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 28 112 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 0 112 112 112 112 36308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 28 112 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 0 112 112 112 37308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 28 112 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 0 112 112 38308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 28 112 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 0 112 39308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 28 308 308 308 308 308 308 308 308 308 308 112 112 112 112 112 112 112 112 112 0 112 0 1 0 112 308 1 308
Reduce contexts
Reduce
cores
0 0.2 0.4 0.6 0.81 0 100 200 300 400CDF
Latency
1
aCalculate CDF
4 clusters
4
2
b3
2
Figure 6: The four steps ofMCTOP-ALG: From latency measurements to the automatic creation ofMCTOPmulti-core topology. detects these latency clusters and for each cluster generates a
triplet with the minimum, median, and maximum latencies. MCTOP-ALG uses the latency clusters for normalizing the latency table (Figure 6 2b ). Each value of the table is replaced with the median value of the corresponding cluster. 3.3 Component Creation
MCTOP-ALGuses the normalized latency table to extract the relations among hardware contexts for each latency level within the socket and assigns them to components. We
re-cursively define acomponentCl of levell > 0as a set of
components of levell−1such that any two components in
Clcommunicate with the latency of levelland have the
ex-act same normalized communication latencies with all the other components of levell−1. At level 0, with latency 0, every hardware context belongs to its ownC0component.
Using this definition of components, MCTOP-ALG re-cursively groups hardware contexts together by performing classification and reduction of the latency table. For exam-ple, in Figure 6 3 , the first step is to group the contexts
(componentsC0) of each core with each other and reduce the table by only keeping the componentsC1(i.e., the cores).5 Then, the cores of each socket are reduced toC2components and we end up with only the cross-socket latencies table.
The outcome is a set of components for each latency level. This assignment of hardware contexts to components describes the relations between contexts.
3.4 Topology Creation
In this last step,MCTOP-ALGassigns “roles” to the compo-nents of different levels according to the MCTOP represen-tation. The result is an abstraction of the actual topology of the processor as shown in Figure 6 4 (the memory measure-ments are described in Section 4).MCTOP-ALGfirst detects whether the target core includes SMT. If the multi-core has SMT, the components of the first non-zero latency group represent the physical cores of the processor. Simi-larly,MCTOP-ALGclassifies as socket level the level with as many hardware contexts as total#contexts
#nodes . Every relation
higher than sockets represents cross-socket connectivity. 3.5 Practical Considerations
Using the Timestamp Counter. Using the timestamp
counter for the fine-grained measurements required by MCTOP-ALG produces various complications [59]. As we mention earlier in this section, reading the times-tamp counter has a non-negligible latency that has to be accounted for in the measurements. To achieve this,
libmctop explicitly estimates the cost of reading the
counter (rtdsc latencyin Figure 5) and subtracts this
cost from every measurement. Of course, even the estima-tion ofrtdsc latencyis susceptible to various sources
of variability, such as DVFS and interrupts. One potential ap-proach to reducing these effects is to execute in kernel space (so that threads exclusively use the target core), to disable interrupts, and to modify the BIOS settings of the machine to remove “problematic” technologies such as DVFS [59].
However, we wantlibmctopto be readily available to
developers in user space; thus, we do not employ these ap-proaches. Instead,libmctopensures the stability of
mea-surements in user space, by taking into account technologies such as DVFS and by discarding spurious measurements— as described below. That being said, an implementation of MCTOP-ALGin kernel space would yield even higher accu-racy of measurements than the one inlibmctop.
Reducing the Effects of DVFS. Dynamic Voltage and
Fre-quency Scaling (DVFS) is a common hardware technique for reducing power consumption, where underutilized cores can execute at various voltage/frequency settings. libmctop
explicitly waits for the frequency of both cores to reach its maximum before proceeding to the lock-step execution. To 5Note that the 28 cycles latency that we get for hardware contexts is higher that the L1 latency, because both threads execute on the same core while taking the measurements, thus increasing the latency.
detect DVFS, a thread executes a spin loop on a core and measures the time of this execution. If a subsequent exe-cution of the same loop is faster, the core must be transi-tioning between DVFS states. Once a core reaches the maxi-mum voltage/frequency setting, the core remains in this state
aslibmctopkeeps the core fully occupied (e.g., even the
thread barriers oflibmctopare spin-based).
Stability of Measurements. MCTOP-ALG is designed to work solo on the target processor, as it relies on the accuracy of latency measurements. In order to improve this accuracy, each latency measurement is repeatedntimes (n = 2000 by default) and the median and standard deviation (stdev) are calculated. If stdev is higher than a threshold (7% of the median by default), the execution is repeated for that con-figuration and the stdev threshold is increased (up to 14% by default). The aforementioned default values are empiri-cally selected and do not significantly affect the behavior of
libmctop. Of course, the user oflibmctophas to
con-figure the tool in a reasonable manner. For example, if stdev is allowed to be 100% of the median value, libmctop
might not get accurate measurements.
Still,libmctopmight collect a few spurious
measure-ments, mainly due to the effects of DVFS and of background OS processes executing on the same core of SMT-enabled processors. In these cases, ifMCTOP-ALGis not able to infer the topology, an error message is printed and the user must retry the execution, possibly with different settings (see Sec-tion 3.6 for more details).
Detecting SMT. libmctop detects if the processor has
symmetric multi-threading (SMT) using the same idea with “removing the effects of DVFS.” A thread first executes a spin loop solo on a core and measures the time of this execution. Then, two threads execute the same loop on two contexts with minimum latency. If these are the hardware contexts of the same core, then due to SMT sharing, the duration of the spin loop will increase.
Performance. MCTOP-ALGinlibmctoptakes∼3 sec-onds to infer the topology of our smallest platform (Ivy), and it takes 96 seconds to infer the topology of Westmere (160 contexts with DVFS).MCTOP-ALGis more stable and faster when DVFS is disabled.MCTOP-ALGis single-threaded, be-cause (i) using more threads increases variability, and (ii) when threads of parallel pairs execute on contexts of the same core, measurements are severely impacted.
Dynamic Changes of Multi-Cores. libmctopdoes not
currently support the detection of dynamic changes of the topology of a multi-core. If, after the execution ofMCTOP -ALG, SMT is disabled through BIOS, or a hardware context is disabled via the OS,MCTOP-ALGmust be re-executed in order to detect the new configuration.
3.6 MCTOP-ALGOutput Validation
Validating thatMCTOP-ALGinferred the correct topology for a multi-core is important. Currently, libmctop includes
two methods for pointing out potential misbehaviors. Addi-tionally, developers can consult processor manuals, or use manufacturer tools to validate MCTOP. In our experience,
libmctopis able to infer the correct topology of
multi-cores, except from the uncommon cases wherelibmctop
is unable to perform clustering of values, as described be-low. Additionally, the measurements oflibmctopmatch
the expected (i.e., processor datasheet) values.
Unsuccessful Clustering of Latency Values. As we
men-tion earlier, spurious measurements cannot be completely avoided in MCTOP-ALG. Our current implementation of MCTOP-ALGinlibmctoprelies on the symmetry and the
hierarchical structure of modern multi-cores to detect such values. Specifically, libmctop expects that at every
la-tency level, each componentCli of levell >0, contains the same number of Cl−1 components as any otherClj com-ponent. Additionally, every Cl−1, withl > 0, component exists in precisely oneClcomponent. Accordingly, if a
spu-rious latency measurement is clustered in an incorrect group,
libmctopcan detect the problem and report an error.
ComparingMCTOPto the OS Topology. One basic sanity
check is to compare the inferred MCTOP to the topology of the OS. If the two topologies match, we can be certain that the MCTOP topology is correct. Otherwise, if the two topologies differ, libmctopsuggests which experiments
to rerun, in order to understand whetherMCTOPor the OS has the correct view of the hardware.
ComparingMCTOPto Other Tools and Manuals. Finally,
if a developer is still in doubt regarding aMCTOPtopology, she can refer to the official processor manuals for her multi-core. Some manufacturers also offer tools for measuring memory characteristics of their processors (e.g., [3, 72]).
4.
Enriching
MCTOPTopologies
The basic topology representation created withMCTOP-ALG includes the communication latencies of the processor by design. These latencies are sufficient for defining locality-oriented performance policies, such as “find the socket that is the closest to socketx.” Although locality optimizations
are very important on NUMA multi-cores, we argue that with access to further low-level information in theMCTOP abstraction, we can implement a broader set of performance policies (see Section 5 for examples). Therefore,MCTOP in-cludes a set of additional multi-core measurements. We have implemented four essential plugins that measure memory latencies and bandwidths, cache information, and power-related measurements (only available on modern Intel pro-cessors). Essentially,libmctopgives the best-case
band-width and latency of a multi-core—i.e., these characteristics
in the absence of contention. Of course, developers can write their own plugins to further enrichMCTOP.
Memory Latency and Bandwidth. The two memory
plu-gins use standard microbenchmark techniques (inspired by the ones used in Corey [18, 73]) to estimate memory laten-cies and bandwidths. In brief, the memory latency plugin creates a randomly connected linked list of cache lines out of a large allocated memory area. Due to the size and the randomness of the list, traversing it results in cache misses (memory accesses) for almost every iteration. The memory bandwidth plugin also allocates a large chunk of memory. performing sequential accesses instead. This way, it maxi-mizes the memory accessed by each thread.
Cache Latency and Size. The cache plugin estimates both
the size and the latency of the various levels in the cache hi-erarchy. To estimate latency, the plugin uses the same tech-nique as the memory latency measurements. The cache size estimation is based on those latency measurements (i.e., it estimates the size of each level by detecting the data size that causes latency to increase). Additionally, the plugin loads and includes the cache sizes from the operating system.
Power Consumption. The latest Intel processors include
Intel’s running average power limit (RAPL) [4] interface for accurately measuring the power consumption of the cores, the package, and the DRAM. We design alibmctop
plu-gin that uses RAPL to gather power measurements which indicate the breakdown of power to hardware contexts. In or-der to estimate the maximum power consumption, we use a memory intensive workload (the same that we use for band-width measurements). We measure and include in MCTOP measurements such as: Idle processor power, full power (all hardware contexts are active), power of the first hardware context, and power of the second context of one core.
5.
Portable Optimizations with
MCTOP Optimizing a concurrent system for the underlying hardware hinders the portability to other processors. In certain cases, this lack of portability is inevitable. For example, using Intel’s restricted transactional memory [4] results in software that can only execute on specific processor models.However, for more traditional topology-oriented opti-mizations, such as for locality or bandwidth, we can achieve
portable optimizations on top of MCTOP. We can do so
because these traditional notions are accurately defined on MCTOP. For instance, “usencores that are the closest to core x,” is a policy that can be easily, accurately, and portably
de-fined inMCTOP. Consequently, we can define high-level per-formance policies that leverage, but at the same time abstract the low-level details of multi-core topologies.
Essentially,MCTOPprovides a topology query engine for multi-cores (similar to the system knowledge base of Bar-relfish [65]). Of course, software should not rely on any as-sumptions regarding the underlying multi-core, but rather
build on top oflibmctop’s programming interface to
ac-cess information in a portable manner. For instance, an al-gorithm that explicitly allocates memory on nodes 0 and 1 will not work on a single-node processor. Instead, the devel-oper can usemctop get num nodesto provision for the
available resources of any multi-core.
In what follows, we highlight several examples of portable optimizations with policies on top ofMCTOP. Sec-tion 6 contains a detailed descripSec-tion of thread placement policies. In Section 7, we evaluate several of these examples.
Topology-Aware Work Stealing. Work stealing [16] is a
commonly used technique in parallel runtimes that aims to minimize the imbalance of work across worker threads. In brief, worker threads have access to work queues from which they dequeue and execute chunks of work. In order to avoid imbalance, workers with no work must steal work from other worker threads. Ideally, work stealing must be performed in a way that (i) reduces the overhead of accessing the non-local queue, and (ii) optimizes the non-locality/bandwidth of the stealer to the work chunk.
7→MCTOPPolicies.On top ofMCTOP, we can easily imple-ment the following work-stealing policy: If the local work queue is empty, steal from the queue of worker threads that are the closest in terms of latency. If unsuccessful, continue with the contexts that are the next closest. Continue this pro-cess until work is found, or there is no work to steal. This policy defines work stealing with optimized locality.
Topology-Aware Reduction Trees. Many parallel
algo-rithms and frameworks rely on the fork-join model. The most notable example is the MapReduce paradigm [31]. In the fork-join model, computation is split in chunks that are processed in parallel by multiple processes. The local results of each process are then reduced (joined) to get the final sult. Intuitively, on a NUMA processor, when these local re-sults represent a sizable amount of data, the thread and data placement of the reduction process can have a large effect on the performance of the computation.
7→ MCTOP Policies.We describe policies for cross-socket reduction trees that we believe are broadly applicable. The following steps assume that multiple threads can concur-rently reduce the same data. Within sockets, all threads of a socket cooperate on reducing the same chunks. Across sock-ets, we build a binary reduction tree such that (i) the final destination socket/node is the one that requires the final data, and (ii) at each level of the tree, we choose the sockets to co-operate so that we maximize the bandwidth to data. We use these policies in a sorting algorithm in Section 7.
Power Consumption Estimation. Power consumption and
energy efficiency have gained increased attention in the past few years [17, 21].MCTOP’s power-related measurements on modern Intel processors can be used to estimate the power consumption of a specific execution (i.e., a fixed thread placement) before the actual execution.
7→MCTOPPolicies.Being able to estimate the power con-sumption of an execution gives us the opportunity to trade performance for lower power. For example, a low-power pol-icy (e.g., Section 6) prioritizes the use of hardware contexts that minimize power consumption.
Educated Backoffs. Waiting for a short period of time
be-fore retrying an operation, namely backing off, is an es-sential technique for alleviating congestion in software. For example, backoffs are used in lock implementations [10]. Estimating the correct amount of time to back off is dif-ficult. Small backoffs miss a window for further optimiza-tion, while large backoffs could hurt performance by induc-ing idle periods of no work.
7→MCTOP Policies.We define the granularity of backing off on top ofMCTOPbased on the intuition that “messages” on multi-cores travel as fast as coherence protocols. Accord-ingly, we set the backoff quantum to be the maximum la-tency between any two threads that are involved in the exe-cution. We use this policy in lock algorithms in Section 7.
6.
Thread Placement with
MCTOPA prominent way of using MCTOP is developing higher-level libraries that rely on performance policies. A natural construction on top ofMCTOPis a library that abstracts the placement of threads to hardware contexts given some place-ment policy. For instance, we might need to place threads close to a specific node where some data resides.
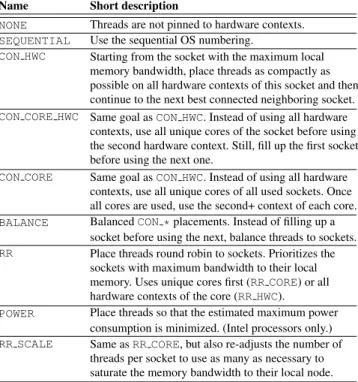
We developMCTOP-PLACE, a portable thread placement library. MCTOP-PLACE comprises two main components: Name Short description
NONE Threads are not pinned to hardware contexts. SEQUENTIAL Use the sequential OS numbering.
CON HWC Starting from the socket with the maximum local
memory bandwidth, place threads as compactly as possible on all hardware contexts of this socket and then continue to the next best connected neighboring socket.
CON CORE HWC Same goal asCON HWC. Instead of using all hardware
contexts, use all unique cores of the socket before using the second hardware context. Still, fill up the first socket before using the next one.
CON CORE Same goal asCON HWC. Instead of using all hardware
contexts, use all unique cores of all used sockets. Once all cores are used, use the second+ context of each core.
BALANCE BalancedCON *placements. Instead of filling up a
socket before using the next, balance threads to sockets.
RR Place threads round robin to sockets. Prioritizes the
sockets with maximum bandwidth to their local memory. Uses unique cores first (RR CORE) or all
hardware contexts of the core (RR HWC).
POWER Place threads so that the estimated maximum power
consumption is minimized. (Intel processors only.)
RR SCALE Same asRR CORE, but also re-adjusts the number of
threads per socket to use as many as necessary to saturate the memory bandwidth to their local node. Table 2: The set of policies offered byMCTOP-PLACE.
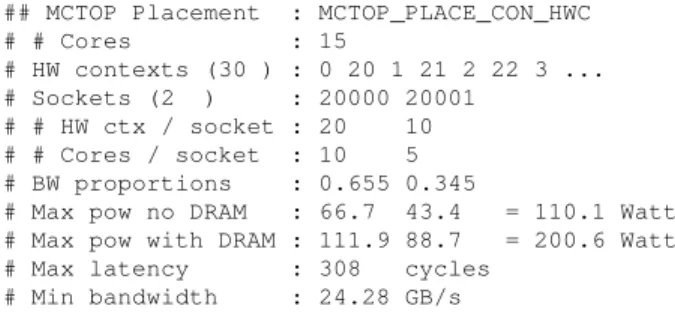
## MCTOP Placement : MCTOP_PLACE_CON_HWC # # Cores : 15 # HW contexts (30 ) : 0 20 1 21 2 22 3 ... # Sockets (2 ) : 20000 20001 # # HW ctx / socket : 20 10 # # Cores / socket : 10 5 # BW proportions : 0.655 0.345
# Max pow no DRAM : 66.7 43.4 = 110.1 Watt # Max pow with DRAM : 111.9 88.7 = 200.6 Watt # Max latency : 308 cycles
# Min bandwidth : 24.28 GB/s
Figure 7: Example output ofMCTOP-PLACE. (i) individual thread placements, and (ii) a pool of place-ments that supports runtime modification of configurations.
MCTOP-PLACE. libmctopthread placement (MCTOP -PLACE) creates a mapping of threads to hardware contexts given a placement policy. Optionally, the user can provide the number of threads and the number of sockets to be used. The basic interface ofMCTOP-PLACEincludes functions for: (i) initializing a new MCTOP-PLACE object with a given policy, (ii) pinning a thread to the next available context of aMCTOP-PLACEobject (if any), and (iii) unpinning a thread from the context and returning it toMCTOP-PLACE.
We implement 12 placement policies (Table 2). In non-SMT multi-cores, CON HWC, CON CORE HWC, and
CON COREpolicies are equivalent. We believe that the
poli-cies ofMCTOP-PLACEcover the most prominent placement choices a developer can make, such as compacting or spread-ing threads as much as possible. Still, if none of these poli-cies covers a required thread placement, implementing a new policy is straightforward since the basic data structures for doing so are already in place.
Apart from the mapping of threads to hardware contexts, MCTOP-PLACEprovides a plethora of additional information and function calls to leverage MCTOP. Figure 7 shows an example output ofmctop place printon Ivy (see
Sec-tion 2.1). For a given allocaSec-tion policy,MCTOP-PLACE cal-culates and exports details such as the number of cores used, the bandwidth proportions of each socket, and an estima-tion of the maximum power consumpestima-tion with and without DRAM (assuming that the application will execute solo on the processor). Additionally, once a thread has been pinned, it has access to information such as its local node and its hardware context and core IDs within the socket. In Sec-tion 7 we useMCTOP-PLACEin various examples.
MCTOP-PLACE Pool. MCTOP-PLACE places threads ac-cording to a single policy. However, software systems might require different placement policies in different execution phases. To support this functionality, we build a MCTOP -PLACEpool object that offers runtime selection of placement policies. In Section 7 we show how we useMCTOP-PLACE’s pool to extend the thread placement capabilities of OpenMP.
MCTOP-PLACE vs. Thread Scheduling. With MCTOP -PLACE, we enable developers to assign static thread
place-ment policies to their workloads, optimizing them across platforms with no additional effort. Obviously, the developer still needs to select the right policy for optimizing a work-load. Additionally, factors like contention and workload skews can affect the behavior of an application and change the optimal policy for a specific workload/platform combi-nation. Furthermore, these static placements withMCTOP -PLACEmight result in two similar applications utilizing the same hardware contexts of a processor, resulting in poor per-formance for both applications. These placement problems are present in existing multi-core libraries (e.g.libnuma,
hwloc) and can be solved by OS-level thread scheduling—
an orthogonal, very elaborate problem. We leave centralized scheduling withMCTOPin the OS for future work.
7.
Examples of Portable Optimizations
We experimentally show how the performance policies on top of MCTOP achieve portable optimizations in software. Our goals for this section are to illustrate (i) the usefulness of the low-level measurements ofMCTOP, (ii) the ability to optimize existing software usinglibmctop, and (iii) the
portable efficiency of the resulting software.
Experimental Setup. We execute our experiments on all
five platforms described in Section 2.1. We perform 11 runs of each experiment and present the median performance. We do not to show error bars for readability as our experiments have small variance. Whenever there is variability across runs, we discuss it in text. The duration of each of our lock experiments is 5 seconds.
7.1 Using Latencies to Optimize Locking
Traditional spinlock algorithms, such as ticket locks, resort to busy waiting when the lock is not free [11, 54]. While busy waiting, it can be beneficial to back off before re-accessing the shared memory location of the lock [10, 33]. As discussed in Section 5, withMCTOPit is straightforward to make educated backoff decisions for such algorithms. We useMCTOP to optimize three lock algorithms: test-and-set (TAS), test-and-test-and-set (TTAS) and ticket (TICKET) locks. We use as backoff quantum the maximum commu-nication latency between any two threads involved in the ex-ecution. Different lock algorithms employ the backoff quan-tum in different ways. With ticket locks we set the back-off to be proportional to the position of the thread in the “queue” [30, 46, 54]. With TAS and TTAS, threads simply back off for one quantum before accessing the lock again.
Evaluation. Figure 8 includes the relative throughput of
the three lock algorithms with and without ourMCTOP-based backoff schemes. The experiment involves multiple threads competing for the same lock, performing 1000 cycles of work in the critical section, and then releasing the lock. Threads pause after each iteration to avoid long runs [56]. On both thex86and theSPARCprocessors, we use thepause
# Threads 0.5 1 1.5 2 0 10 20 30 40 Re la tiv e Th ro ug hp ut
Ivy
0.5 1 1.5 2 0 10 20 30 40 50Opteron
0.5 1 1.5 2 0 20 40 60 80 100Haswell
TAS TTAS TICKET
0.5 1 1.5 2 0 40 80 120 160
Westmere
0.5 1 1.5 2 0 60 120 180 240 300SPARC
Figure 8: Throughput of different lock algorithms using educated backoffs fromMCTOP. instruction for pausing [4, 8] as the baseline. Onx86, we
invokepausein a loop to implement our backoff quantum.
Backing off with the “correct” backoff granularity signif-icantly improves performance: On average, we improve the performance of TAS, TTAS, and TICKET by 12%, 11%, and 39%, respectively. These performance gains are consistent across platforms, without requiring reconfiguration or re-compilation of the applications. With TTAS, as contention increases, backing off does not make a difference, since most threads are still bashing the cache line with spinning.
Conclusion. MCTOP’s low-level information can be used to optimize the performance of locking algorithms. The op-timization is portable across platforms, aslibmctop’s
in-terface provides the necessary latencies on each platform. 7.2 Usinglibmctopin Parallel Mergesort
We use libmctop to devise a very fast, portable
mergesort algorithm. Our novelty lies in the way we perform NUMA-aware merging. The starting point for our algorithm is the parallel sort algorithm of the C++ standard library (gnu parallel::sort) [66].
gnu parallel::sort involves two main steps: (i) it
breaks the target array into n chunks and lets n threads
sort these chunks with the standard sequential quicksort al-gorithm (n is the number of available threads), and (ii) it
iteratively performs parallel merging on the sorted chunks until the result is a single sorted array. Our mergesort al-gorithm, namelymctop sort, takes the same first step as
gnu parallel::sort. However,mctop sortmerges
the sorted arrays using the topology-aware reduction tree policies presented in Section 5.
Using SMT Cleverly. Merging two sorted arrays using
tra-ditional comparison instructions is sub-optimal: The aggres-sive out-of-order cores are not able to predict the direc-tion of the merge branch (i.e., which of the two arrays will give the next element). Recent projects [26, 43] show how to use SIMD instructions for efficient merging. Using 128-bit instructions, we can create a 128-bitonic merge network that merges 8 elements at a time. We implement a variant of
mctop sort, namelymctop sort sse, that uses SIMD
instructions. Once the sequential sorting is over, we let the first hardware context of each core use SIMD, while the remaining perform traditional merging. To compensate for the faster merging with SIMD, SIMD threads are allocated three-time more data than the non-SIMD threads.
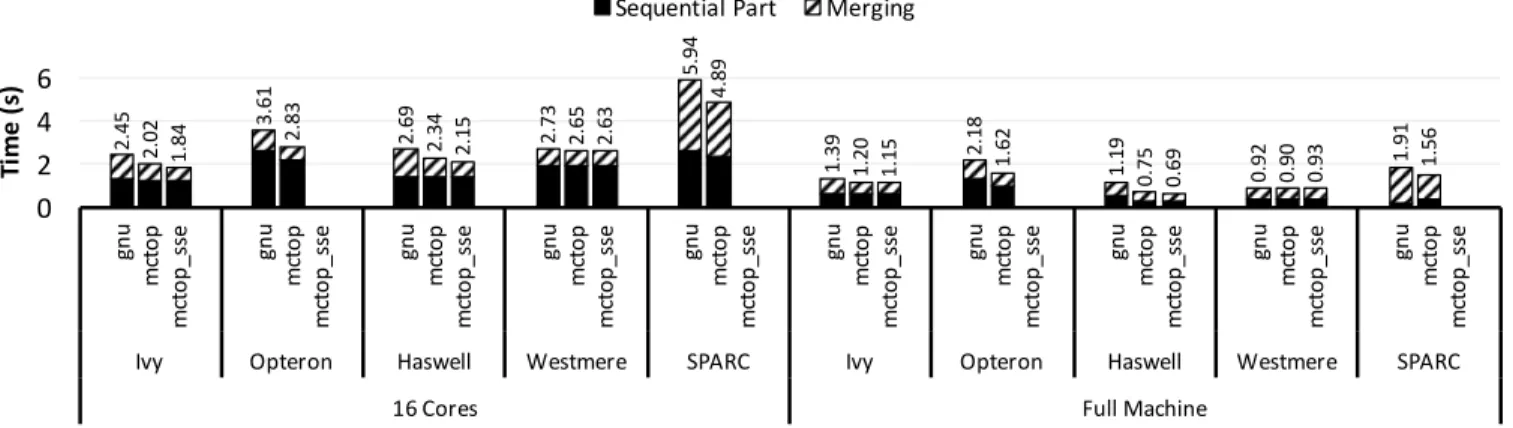
Evaluation. Figure 9 presents a performance
com-parison between mctop sort, mctop sort sse
(only on platforms that support SIMD instructions) and
gnu parallel::sort(gnu). Both algorithms assume
an unsorted array on socket 0 and produce the sorted array on the same socket. We present execution times for runs with 16 threads on every machine, as well as with the total number of hardware contexts available. With
mctop sort, threads are spread across sockets, in order to
benefit from the large LLCs of each socket (usingRRpolicy
from MCTOP-PLACE), while the merging tree is designed
2. 45 2. 02 1. 84 3. 61 2. 83 2. 69 2. 34 2. 15 2.73 2.65 2.63 5. 94 4. 89 1. 39 1. 20 1. 15 2.18 1.62 1. 19 0. 75 0. 69 0.92 0. 90 0. 93 1.91 1.56 0 2 4 6 gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e gn u mc to p mc to p_ ss e
Ivy Opteron Haswell Westmere SPARC Ivy Opteron Haswell Westmere SPARC
16 Cores Full Machine
Ti
m
e
(s
)
Sequential Part Merging