**Deptt of Electronics & Communication Engineering, Dronacharya College of Engineering Gurgaon-123506, India
Abstract: Audio coding is the technology to represent audio in digital form with as few bits as possible while maintaining
the intelligibility and quality required for particular application. Interest in audio coding is motivated by the evolution to digital communications and the requirement to minimize bit rate, and hence conserve bandwidth. There is always a tradeoff between compression ratio and maintaining the delivered audio quality and intelligibility. Audio coding is widely used in application such as digital broadcasting, Internet audio or music database to reduce the bit rate of high quality audio signal without comprising the perceptual quality. In this dissertation work Design and implementation of a MPEG Lossless audio codec using wavelet transform has been proposed. The major issues concerning the development of audio codec are choosing optimal wavelets for audio signals, decomposition level in the digital wavelet transform and thresholding criteria for coefficient truncation which is the basis to provide compression ratio for audio with suitable peak signal to noise ratio (PSNR), wavelet packet compression technique has also been used to compare the performance of audio codec using wavelet transform. A psychoacoustic model is used to improve the quality of audio signal. The proposed audio codec has been implemented on DSK6713 Starter Kit using MATLAB-7.3 and Link to Code Composer Studio and various audio signals of different time duration have been tested. Result obtained show that the proposed codec improves quality of the reconstructed audio signal.
I. INTRODUCTION
A. Need of Compression for Audio
Audio signal compression has found application in many areas, such as multimedia signal coding, high-fidelity audio for radio broadcasting, audio transmission for HDTV, audio data transmission/sharing through Internet, etc. High-fidelity audio signal coding demands a relatively high bit rate of 705.6 kbps per channel using the compact disc format with 44.1 kHz sampling and 16-bit resolution. For large amount of exchange and transmission of audio information through internet and wireless systems, efficient (i.e., low bit rate) audio coding algorithms need to be devised. Two major classes of techniques can be used in audio coding to reduce the coded bit rate. The first class takes advantage of the statistical redundancy in audio signal and applies some form of digital encoding, it is a lossless audio coding in which original audio signal can be perfectly recovered from the encoded audio signal. The second class employs some signal processing so that essential information and perceptually irrelevant signal components can be separated and later removed, it is a lossy audio coding in which original and reconstructed audio signal are not perfectly identical. This class includes techniques such as subband coding, transform coding, critical band analysis, and masking effects [1].
Digital Signal Processing (DSP) techniques can be used to decrease the redundancy and irrelevancy contained in an audio signal. Audio coding is an important step towards delivering a high quality communications for multimedia and Internet. Digital audio compression allows the efficient storage and transmission of audio data.
Just like every other digital data compression, it is possible to classify them into two categories: lossless compression and lossy compression. [2]
II. MAIN FEATURES OF THE IMPLEMENTATION
The Matlab implementation includes the following features: (a) Signal division and processing using small frames (b) Discrete wavelet decomposition of each frame (c) Compression in the wavelet domain
(d) A psychoacoustic model
(e) Non linear quantization over the wavelet coefficient using the psychoacoustic model (f) Signal reconstruction
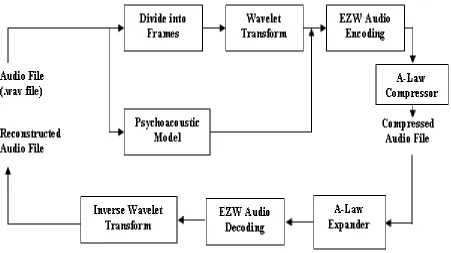
Figure 1.- Block diagram of the described encoder/decoder
A. Wavelet representation for audio signals
I have chosen to implement an adaptive DWT and DWPT signal representation because both is a highly flexible family of signal representations that may be matched to a given signal and it is well applicable to the task of audio data compression. In this case the audio signal will be divided into overlapping frames of length 2048 samples.[3] When designing the wavelet decomposition I have considered some restrictions to have compact support wavelets, to create orthogonal translates and dilates of the wavelet (the same number of coefficients than the scaling functions), and to ensure regularity (fast decay of coefficients controlled by choosing wavelets with large number of vanishing moments). In that sense the DWT will act as an orthonormal linear transform. The wavelet transform coefficients are computed recursively using an efficient pyramid algorithm. In particular, the filters given by the decomposition are arranged in a tree structure, where the leaf nodes in this tree correspond to subbands of the wavelet decomposition. This allows several choices for a basis. This filter bank interpretation of the DWT is useful to take advantage of the large number of vanishing moments.[3]
Wavelets with large number of vanishing moments are useful for this audio compression method, because if a wavelet with a large number of vanishing moments is used, a precise specification of the pass bands of each sub band in the wavelet decomposition is possible. Thus, it can be approximate the critical band division given by the auditory system with this structure and quantization noise power could be integrated over these bands.
B. Psychoacoustic model a. Subband masking model
The psychoacoustic model used in this implementation closely resembles Model II of the ISOMPEG specification, which means that it uses data from the previous two windows to predict, via linear extrapolation, the component values for the current window using a concept that they defined as tonality measure (it ranges from 0 to 1). Using this concept and a spreading function that describes the noise-masking property, they compute the masking threshold in each subband given a decomposition structure. The idea is to use subbands that resemble the critical bands of the auditory system to optimize this masking threshold. This is the main reason why the I chose the wavelet packet structure.
b. Masking constrain in the wavelet structure
the “best basis” approach, they do not subdivide every subband until the last level. The decision of whether to subdivide is made based on a reasonable criterion according to the application (further decomposition implies less temporal resolution). The cost function, which determines the basis selection algorithm, will be a constrained minimization problem. The idea is to minimize the cost due to the bit rate given the filter bank structure, using as a variable the estimated computational complexity at a particular step of the algorithm, limited by the maximum computations permitted. At every stage, a decision is made whether to decompose the subband further based on this cost function. Another factor that influences this decomposition is the tradeoff in resolution. If it is decomposed further down, it will sacrifice temporal resolution for frequency resolution.
The last level of decomposition has minimum temporal resolution and has the best frequency resolution. The decision on whether to decompose is carried out top-down instead of bottom-up. Following that way, it is possible to evaluate the signal at a better temporal resolution before the decision to decompose. It is proved in this paper that the proposed algorithm yields the “best basis” (minimum cost) for the given computational complexity and range of temporal resolution.[3]
D. Efficient Bit allocation
The bit allocation proceeds with a fixed number of iterations of a zero-tree algorithm before a perceptual evaluation is done. This algorithm organizes the coefficients in a tree structure that is temporally aligned from coarse to fine. This zero-tree algorithm tries to exploit the remnants of temporal correlations that exist in the wavelet packet coefficients. It has been used in other wavelets applications, where its aims has been mainly to exploit the structure of wavelet coefficients to transfer images progressively from coarse to fine resolutions. In this case, a one-dimensional adaptation has been included with suitable modifications to use the psychoacoustic model. This algorithm is discussed neither in this paper nor in this report.[3]
III. CONSIDERATIONS
Even though it is more convenient to implement the ideas described in [4], some of the suggested steps require a complicated implementation. Therefore, a few modifications and considerations have been included to the design of this MATLAB simulation:
(a) No search for optimal basis is performed Even though this is one of the key point of the paper, its implementation is requires a large programming design, and that is out of the scope of this demonstration. To compensate that, another compression technique has been used. This is based in the known discrete wavelet decomposition compression that uses an optimal global threshold. This technique has been successfully used in audio compression [5].
(b) Non overlapping frames are included
This implementation does not have overlapping frames to avoid computational complexity. The frame size is given by the recommendations in corresponding to 2048 samples per frame.
(c) The psychoacoustic model is simplified
Figure.2- Tone masker detection in a frame. Matlab implementation
(d) No new audio format was design
Even though this simplified matlab implementation performs compression over the audio signal, this is not reflected in the size of the new audio files. This is due to the fact that a new format design was not considered, so the wavwrite command was used to create the audio files (.wav). The compression ratio for each case is calculated using other variables of the simulation.
(e) A lossless compression at the end was tested and suppressed Arithmetic compression (similar to Huffman coding) was tested in this simulation but was suppressed at the end because it made the simulation too slow. However its performance is considered in the results.
IV. RESULTS
The MPEG encoder was compared with different windows of wavelet transform. The test material was taken from the standard audio sequences for MPEG Coding. It comprises almost stereo waveform data with sampling rates of 44 kHz, and resolutions of 8, 16 and 32 bits.
A. Compression Ratio
In the following, the compression ratio is defined as C=[(Compressed Size)/(Original Size)]*100
where smaller values mean better compression. The results for the examined audio formats are shown in Table 1. This experiment is done on a 44.1 Khz audio sample rate, 16 bit audio sample size and 1411 Kbps bit rate. This algorithm compressed a stereo channel into mono channel.
TABLE-1 Results for Audio-1 Total Time Duration:- 26 Secs and
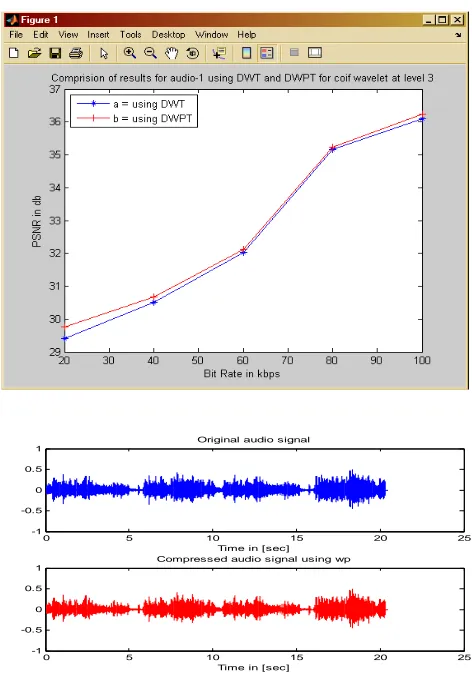
Fig 3: Graph between PSNR and bit rate using DWT and DWPT for level 3 using coif5 wavelet for ‘audio1.wav’
Figure-4 comparison between Original and Compressed Audio File
From Table-1we can easily seen that coif5 wavelet at level-5 gives the better compression ratio than level-3.
To check subjective quality of the developed system, Mean Opinion Score (MOS) is considered. The opinion of fifteen people was considered for the same audio signal. Listening tests were conducted to determine subjective quality of the codec. These results are a taken at compression ratio 10.54:1. Table-2 shows no. of listener and grades given by them after listening Original and Reconstructed signal.
TABLE-2 Comparative Analysis of Implemented Block-Set
Grades No of
Listener (Using MatLab)
No of Listener
(Using Simulink)
No of Listener
(Using DSK6713)
A 6 9 8
B 8 6 6
C 1 0 1
The grading is based on the following criteria: For A = Transparent / No Distortion
B = Near Transparent/ Slightly Distorted C = Original Preferred.
0 5 10 15 20 25
-1 -0.5 0 0.5 1
Original audio signal
Time in [sec]
0 5 10 15 20 25
-1 -0.5 0 0.5 1
Compressed audio signal using wp
V.
C
ONCLUSION ANDF
UTUREW
ORKWavelet based audio codec using wavelet transform, wavelet packet transform and psychoacoustic model has been developed, and implemented using MATLAB, SIMULINK and DSP kit. To test the codec several audio signals of different time durations have been used. The results are obtained with DWT and DWPT at level 3 and level 5. For same compression ratio and bit rate, coif5 DWPT gives better PSNR than DWT. The comparative analysis of the results as described in previous chapter shows that for good quality reconstructed signal PSNR lies between 35 to 37 dB.
It has been observed that the optimum number of wavelet decomposition level is 5.
Psychoacoustics model improves the quality of the reconstructed audio signal with wavelet packet transform as well as with wavelet transform. The performance of wavelet codec in terms of compression ratio and signal quality is comparable with other techniques such as MPEG-3, SPHIT and WLPC etc. The compression ratio can be easily changed just by deciding the masking level for psychoacoustic model.
In terms of Implementation, SIMULINK gives the better quality of audio signal then the MATLAB. In future Using DSK starter kit can be easily used for communication purpose like audio conferencing and other DSP applications like Image Processing, Video Processing etc.
REFERENCES:
[1] Yuan-Hao Huang and Tzi-Dar Chiueh, “A New Audio Coding Scheme Using a Forward Masking Model and Perceptually Weighted Vector Quantization”, IEEE transactions on speech and audio processing, vol.10, no. 5, July 2002
[2] Audio Compression using Wavelet Techniques, ECE 648 – Spring 2005 Wavelet, Time-Frequency, and Multirate Signal Processing Professor Ilya Pollak
[3] Audio Compression using Wavelet compression Techniques, ECE 648 – Spring 2005 Wavelet, Time-Frequency, and Multirate Signal Processing Professor Ilya Pollak
[4] D. Sinha and A. Tewfik. “Low Bit Rate Transparent Audio Compression using Adapted Wavelets”, IEEE Trans. ASSP, Vol. 41, No. 12, December 1993.