Exploring machine learning techniques in epileptic seizure detection and prediction
Full text
Figure

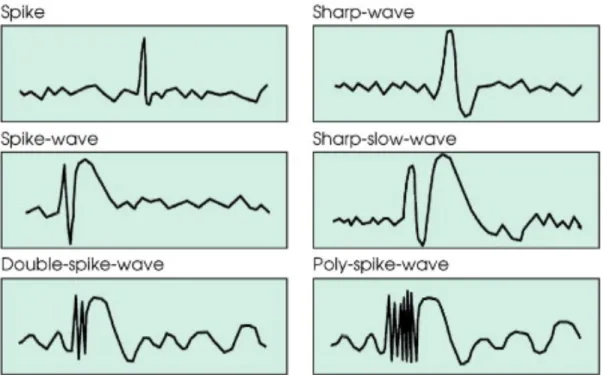
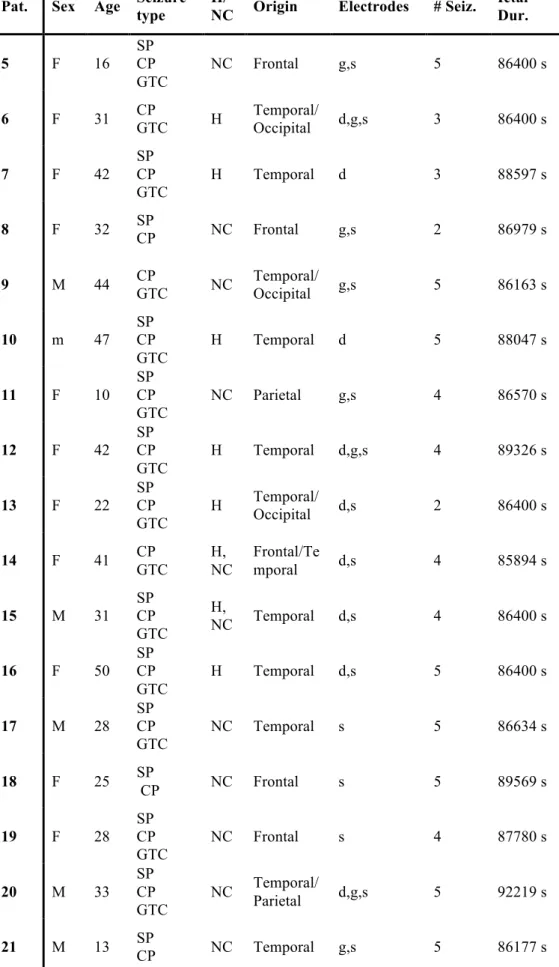

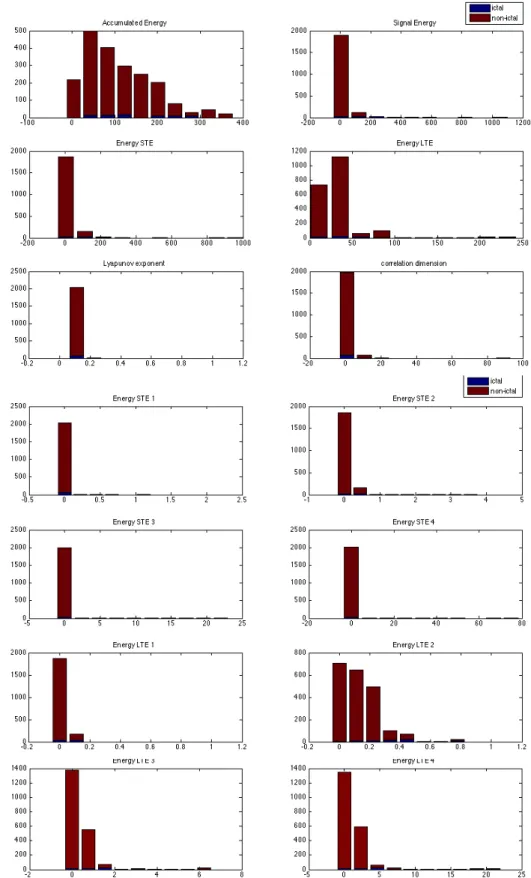
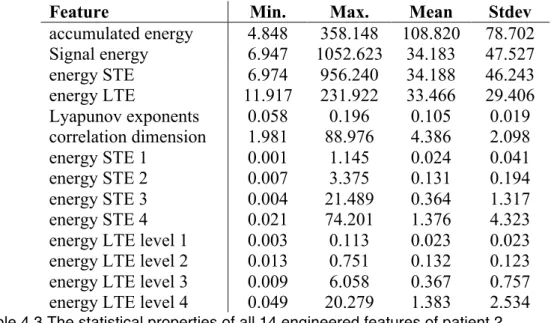
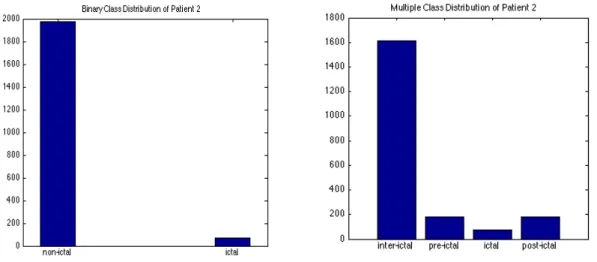
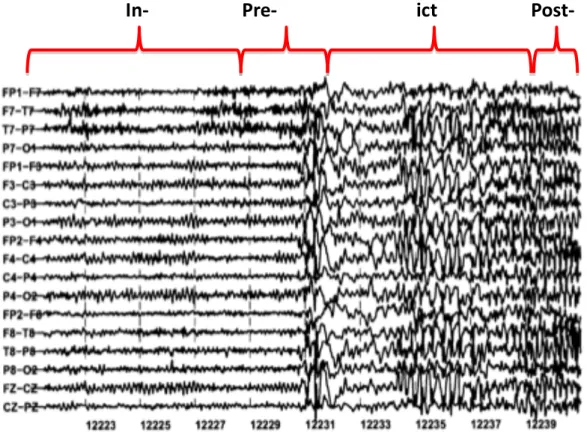
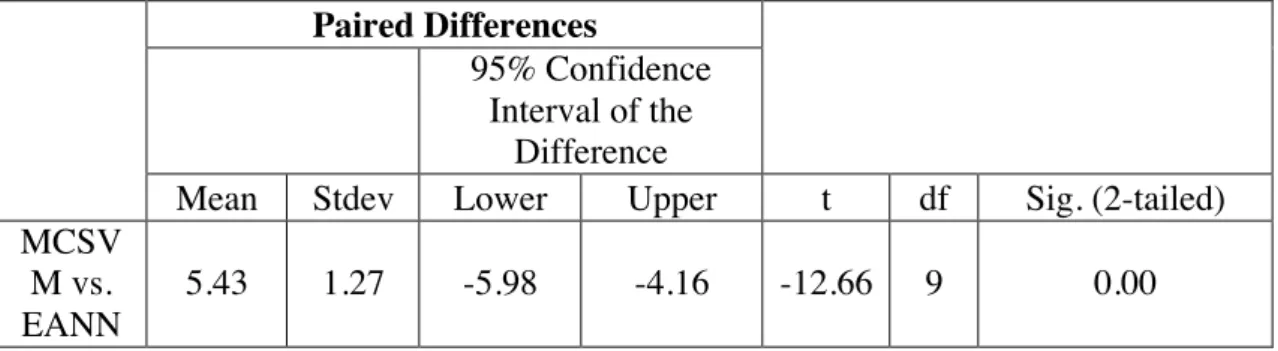
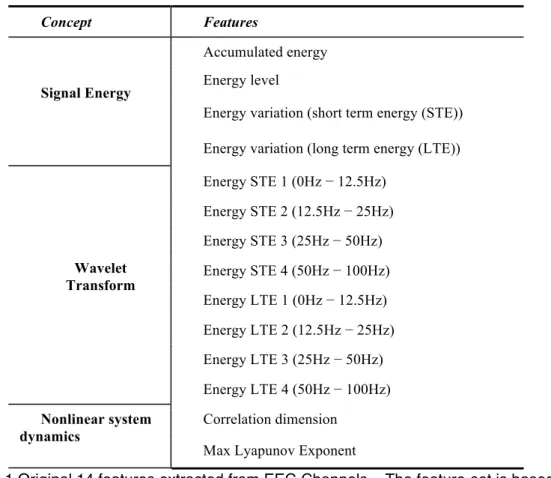
Outline
Related documents
The main contribution of this study is to decrease income inequality in risk sharing network such as informal insurance through an analytical method, this study
It then discusses the impact of the market crisis beginning in 2007 on short sale regulation, the current debate over the Securities and Exchange Commission’s (“SEC”) revisions
the Siberian stonechats, whereas the growth rate towards adult wing length is higher in the European stonechats (note, however, that in the European birds the wing
Before your scan begins, you’ll be asked to provide information about your medical history and any previous experience with X-ray contrast (“dye”).. Preparation for a CT scan
The current study has tested two previously-published RILD models M1 and M2 (2, 3) on the independent validation sets V1 and V2 of the SCOPE1 trial data (18, 19), which
Optimal control strategies, both in the case of hospitalization (with and without quarantine) and vaccination are used to predict the possible future outcome in terms of
Resumo – O objetivo deste trabalho foi avaliar a patogenicidade de Beauveria bassiana a ninfas de Diaphorina citri (Hemiptera: Psyllidae) e verificar a compatibilidade do
