Dynamic Load Balance for Approximate Parallel
Simulations with Consistent Hashing
Roberto Solar
Yahoo! Labs
Santiago, Chile
[email protected]
Veronica Gil-Costa
Universidad Nacional de San
Luis, Argentina
[email protected]
Mauricio Marin
CEBIB, Universidad de
Santiago, Chile
[email protected]
ABSTRACTParallel simulation is a powerful tool to evaluate the perfor-mance of large-scale systems. However when it comes to simulating large scale Web search engines, the parallel sim-ulation execution can introduce imbalance among processors because event occurrence is driven by user behavior which is unpredictable, making events take place in different parts of the system in an irregular manner. In this paper, we study the impact of load balance strategies on the performance of a parallel simulation strategy. In particular, we present a consis-tent hashing load balance algorithm aimed to reduce queuing waiting times, evenly distribute the costs of executing events among processors, and more importantly migration of logi-cal processes only occurs between neighbor processors. We use a Web search engine composed by services deployed on a cluster of processors as the application case study. Our simu-lations are driven by actual query log traces. We evaluate our proposed load balance algorithm in terms of running time, communication, memory consumption and accuracy. Results show that the proposed load balance strategy is capable of reducing the execution times of simulations and maintaining quality of results.
Author Keywords
Load balance, scheduling, approximate parallel simulation.
ACM Classification Keywords
I.6.8 SIMULATION AND MODELING : Parallel
1. INTRODUCTION
Performance evaluation of new algorithms designed for large-scale Web search engines (WSE) is a difficult task. In many cases, their assessment on the actual system running in pro-duction is not practical due to its possible effects on the sta-ble operation of the search engine. On the other hand, re-producing the search engine computations on a replicated in-frastructure can have significant costs in large search engines. Typically, a large search engine is composed of a collection of services which are software components executing opera-tions such as (a) calculation of the top-k documents that best
Paste the appropriate copyright statement here. ACM now supports three different copyright statements:
•ACM copyright: ACM holds the copyright on the work. This is the historical ap-proach.
•License: The author(s) retain copyright, but ACM receives an exclusive publication license.
•Open Access: The author(s) wish to pay for the work to be open access. The addi-tional fee must be paid to ACM.
This text field is large enough to hold the appropriate release statement assuming it is single spaced.
match an user query; (b) routing queries to the appropriate services and blending of results coming from them; (c) con-struction of the result Web page for queries; (d) advertising related to query terms; (e) query suggestions, among many other operations.
Parallel discrete-event simulation provides a practical alterna-tive to evaluate new algorithms without interfering the system currently in production. It has been widely used in the past years to evaluate the performance of large scale systems[4, 14]. In fact, there are various proposals to make parallel sim-ulation more efficient [21, 22, 23]. During the last few years, discrete-event simulation have been used as a supporting tool for designing, implementing and evaluating large-scale web search engines [3, 5, 17, 18]. However, these simulation models usually assume that computations on the distributed search engine services are fairly well balanced across clus-ter processors, which is an assumption that can be unrealistic in scenarios where user query traffic dynamically changes in intensity and content.
In [16] a new parallel discrete event simulation approach for performance evaluation of WSEs called approximate parallel simulation is introduced. It is a key-based approach designed to simulate the life cycle of queries in large-scale web search engines. A key is used to identify a particular event and its as-sociated processing code. Keys are evenly distributed among the processors by means of a hash function. Despite this approach accelerates the execution of simulations, with the counterpart of a small loss of precision in the final results, it can be prone to load-imbalance because the performance of WSE simulations can be affected by unpredictable user query behavior which tends to overload a sub-set of keys.
In this work, we propose to tackle the imbalance problem by introducing a consistent hash load balance algorithm into the approximate parallel simulator described in [16]. The load balance algorithm works at the communication layer of the simulation framework.
Our strategy introduces some overheads during the execution of the simulations since it is necessary to periodically collect data in order to decide whether the load balance algorithm has to be executed; which can cause the migration of logical processes. Nevertheless, we show that in large scale systems where millions of events are simulated the proposed load bal-ance algorithm improves overall performbal-ance when keys be-come unevenly distributed among processors.
There are various works studding the load balance problem on parallel simulations [1, 9, 20]. However, we have found that our consistent hashing based approach is a suitable strat-egy to follow in the parallelapproximatesimulations of [16] as it enables a natural mapping among the key values and the consistent hash ring that defines the processors in charge of serving dynamically changing ranges of key values. To the best of our knowledge, the consistent hash scheme has not been previously employed to balance the load of parallel dis-crete event simulations. Our experimental results show that our strategy is capable of quickly improving the overall load balance of the parallel simulation.
The remaining of this paper is organized as follows. The re-lated work is presented in Section 2. Section 3 describes our application domain. Section 4 presents the proposed load bal-ance algorithm. Experimental results are presented in Section 5 and final conclusions in Section 6.
2. RELATED WORK
The authors in [1] study the problem of load balance for con-servative distributed simulations by using a set of benchmark network models. They propose a dynamic load balance al-gorithm based on the CPU-queue length which indicates the workload at each processor. The load balance process is com-posed by two components:load balancer- which is in charge of determining the re-allocation of processes, andprocess mi-gration- which is in charge of executing the decision made by the load balancer. Furthermore, there are two load balance strategies proposed:centralizedandmulti-level. Both meth-ods work in a similar way, where a load balancer periodically request the load of each processor in order to compute the imbalance and determine the exchange of work.
The authors in [20] introduce a dynamic partitioning algo-rithm for optimistic distributed simulation of synthetic work-load simulation models. This work-load balance algorithm operates on the basis of computation and communication, which are possible sources of imbalance. Imbalances are detected by means of estimating three metrics: the capacity of each host, the computation load generated by each LP and the commu-nication load between LPs. These estimations can trigger two different procedures: a load balance cycle or a communica-tion refinement cycle. The communicacommunica-tion refinement cycle consists of grouping into processors the most communicated LPs. The load balance cycle consists of transferring load ex-cess from overloaded to underused proex-cessors.
In [12] the authors present a scheme to balance the com-munication and computational load during the execution of distributed high-level architecture (HLA) based simulations. The load balance scheme consists of a system based on a hier-archical architecture in order to constantly monitor resources and simulations decreasing the monitoring overhead. Once a load imbalance is detected, the system defines a load redis-tribution according to partitioning policies and re-configures the load by means of a low-latency federate migration tech-nique. A load balance cycle consists of triggering the mon-itor of resources in order to detect imbalances. If a load re-partitioning is required, load redistribution is invoked and mi-gration moves are performed.
Two dynamic load balance algorithms are presented in [19]. They are devised to balance the computational and communi-cation load in a Time Warp simulation of digital logic circuits. Furthermore, authors also present a protocol which selects a load balance algorithm by using a multi-state Q-learning ap-proach. In this paper, a deep first search is used to initially distributed the LPs among processors. The computing bal-ance mechanism is as follows: each processor sends com-putation and communication values to a master processor, the master processor builds a bipartite graph using comput-ing values as processors and communication values as edges. A bipartite graph matching algorithm is used to match the overloaded and under-used processors. Overloaded proces-sors send a set ofL LPs to their corresponding under-used processor in order to balance the workload. The communi-cation balance mechanism consists of grouping pairs of the most communicated LPs into the same processor.
In [8] is presented a load balance scheme that combines both static partitioning and dynamic load balance for distributed conservative simulation. A supply-chain model is used to evaluate the proposed partitioning strategies. The static parti-tioning scheme consists of grouping multiple simulation ob-jects into LPs prior to the simulation. To this end, the simula-tion objects are mapped to the processors of the given graph, and the edges represent the interaction between simulation objects. A graph partitioning package (METIS1or Scotch2) is
used in order to group simulation objects into LPs while min-imizing load imbalances and maxmin-imizing lookaheads. The dynamic scheme consists of dynamically scheduling LPs to threads. LPs with lower simulation time have high priority of being scheduled. There are two centralized pools:active pool
andpassive pool. Processors grab LPs from the active pool and return LPs to the passive pool. Finally, when all LPs in the active pool are consumed, the two pools are swapped. More similar to our work, but in the context of real systems implementations (no simulation is involved), the authors in [11] propose a dynamic load balance algorithm upon consis-tent hashing in order to cope with sudden increases in query traffic and processors failure in Caching Service processors. The load balance algorithm is based on the Sender Initiated Diffusion (SID) algorithm. Each overloaded partition dis-tributes excess of load to under-used neighbors partitions by using the consistent hashing approach. There is no migration processes involved on the load balance strategy.
3. SIMULATING WEB SEARCH ENGINES
We focus on Web search engines composed by three services deployed in clusters of computers interconnected by a high-speed network: Front-service (FS), Caching-Service (CS) and Index-service (IS). The Front-service receives queries form users, routes them to the corresponding CS or IS, and is in charge of blending partial results coming from the IS to present the top-kmost relevant documents to the users. The Caching-service keeps in memory the most frequent queries along its top-k document results. This service avoid re-computing the top-kresults for popular queries. Finally, the
1
http://glaros.dtc.umn.edu/gkhome/views/metis 2http://www.labri.fr/perso/pelegrin/scotch/
IS computes the top-kdocument results for user queries by accessing an index and computing score algorithms like the WAND [2].
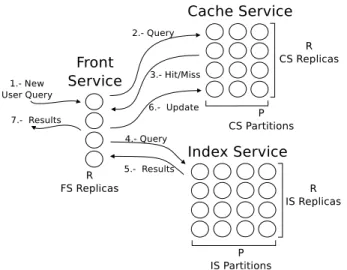
Figure 1. Life cycle of a query on a Web search engine.
Figure 1 shows the steps executed within the life cycle of a query on a Web search engine. The Front-Service (FS) is composed of several processors where each processor is hosted by a dedicated cluster. Each FS processor receives user queries and sends back the top-kresults for each query to the users. After a query arrives to a FS processor, it selects a caching service (CS) processor. These processors keep the top-kresults for frequent queries previously issued by users, so response time for these queries is very small. The query-results set for the CS is kept partitioned intoP disjoint sub-sets and each partition is replicatedRtimes to increase query throughput. A simple LRU strategy can be used to imple-ment the CS processors. A hash function on the query terms is used to select a CS partition whereas a respective replica can be selected in a round-robin manner.
If the query is not cached, it is sent to the index service (IS) cluster. The IS contains a distributed index built from the document collection held by the search engine (e.g. HTML documents from a big sample of the Web). This index is used to speed up the determination of what documents contain the query terms and calculate scores for them. Thekdocuments with the highest scores are selected as the query answer. The index and its respective document collection are partitioned intoPpartitions and each partition is kept replicatedRtimes to enable high query throughput. Partitions help to reduce response time for individual queries since time is proportional to the number of documents that contains the query terms. Queries are sent to all partitions and the results are merged to obtain the global top-kresults.
Figure 1 also shows an overall description of the message traf-fic among the Web search engine services. These messages must pass through a number of communication switches to reach their destinations. Switches are usually organized in a fat-tree topology. On the other hand, each processor is expected to be a multi-core processor. Thus search engine service processors are multi-threaded components where it
is necessary to take into consideration the effects in perfor-mance of concurrency control strategies.
The implementation of the parallel approximate simulator [16] and its corresponding tool developed in [10], is based on multi-threading and a bulk-synchronous message passing strategy to automatically conduct simulation time advance. The parallelization of execution of simulations is simplified as no rollbacks are considered to correct erroneous compu-tations. The simulation is designed according to the parallel computing model named Bulk Synchronous Parallel (BSP) computing model [24]. Under the BSP model, computation is organized as a sequence of supersteps. During a superstep, processors may perform computations on local data and/or send messages to other processors. At the end of a super-step there is always a synchronization barrier. It permits that messages sent during the current superstep are available for processing at their destinations at the next superstep. The underlying communication library ensures that all messages will be available at their destinations before starting the next superstep. In each processor there is one master thread that synchronizes with all otherP−1master threads to execute the BSP supersteps and exchange messages. Then, in each processor and superstep the remainingT−1threads synchro-nize with the master thread to start the next superstep, though they may immediately exchange messages during the current superstep as they share the same processor main memory. Additionally, a key-based approach is used in [16]. Each event has a key which determines the operation to be per-formed (e.g. ranking, merge, etc.) and by means of a hash function it obtains the processor identifier and the thread re-sponsible to simulate that operation. In this context, the threads are in charge of performing the computations of what is called logical processes (LPs) in the parallel discrete event simulation (PDES) parlance [7]. The typical content of a key is a string like class=ClassName; instance=ID, e.g. class=CacheService; partition=3; replica=28. The only re-quirement is to specify the class identification field to let the simulation framework instantiate the right object.
As it is well-known, processing events in parallel during pe-riods of time where no messages from other processors (re-mote threads or LPs) are received can lead to the problem of missing the arrival of event messages at the right simulation time. The approach presented in [16] simply ignores such situations but proposes a strategy to significantly reduce the arrival of those “straggler” messages.
The approximate parallel simulations of [16] are performed in a cluster ofP processors where each processor contains
T threads so that LPs are evenly distributed on theT ×P
threads. Each thread/LP has its own instance of a sequential simulation kernel which includes a local event list and func-tions related to event processing and message handling. In each processor there is one master thread that synchronizes with all otherP−1master threads to execute the BSP steps and exchange messages. In each processor and super-step, the remainingT−1threads synchronize with the master thread to start the next superstep, though they may
immedi-ately exchange messages during the current superstep as they share the same processor main memory.
4. PROPOSAL
We present a dynamic load balance strategy based on consis-tent hashing [13], for approximate parallel simulation of web search engines. Keys are mapped into a ring managed as a set of buckets. Each bucket is composed of a set of equal-sized partitions. Each partition is associated with one LP. The buckets can be associated with a variable number of partitions but the total number of partitions is kept fixed. Buckets can only exchange partitions with neighboring buckets along the ring. There is one bucket per processor. Our load balance strategy consists of adjusting the flow of events (messages) between processors by means of changing the number of par-titions of adjacent buckets in order to balance the computation load while reducing LPs migrations among processors. To this end, we implement a centralized scheduler in charge of collecting information of the messages passing between pro-cessors. The scheduler evaluates load imbalances (by using a threshold mechanism) and re-configures the consistent hash-ing rhash-ing (by movhash-ing the limits of the buckets which requires migration of LPs between processors). The main advantage of our load balance strategy is that migrations only occur be-tween neighboring processors of the consistent hashing ring which keeps small the amount of data transferred during the redistribution of the workload.
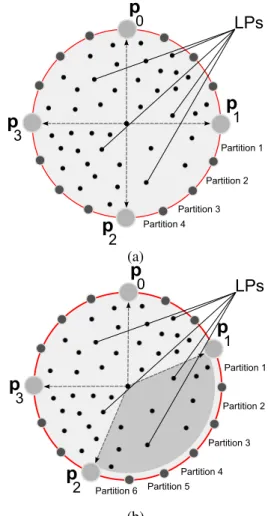
Figure 2 shows an example of how the proposed algorithm works. In Figure 2.(a) we show the initial state of the consis-tent hashing ring. The ring is composed by a set of 4 buckets and each bucket has 4 partitions (evenly distributed). In Table 1 we show the bucket configuration before executing the load balance algorithm. The 2th column shows the number of par-titions assigned to each bucket and the 3th column shows the total workload reported by each processor. In this example,
P0 has four partitions which report a workload of{4,3,3,3} respectively. P1 has four partitions which report a workload of{1,1,1,1}respectively.P2has four partitions with a work-load of{3,4,3,4}respectively, andP3has four partitions re-porting a workload of{3,2,3,2}.
Processor # of Partitions Workload
p0 4 13
p1 4 4
p2 4 14
p3 4 10
Table 1. Bucket configuration before executing the load balance algorithm.
In this case, our algorithm calculates an imbalance of 27%, computed as100−Ef where the efficiencyEf = 73%
ac-cording to formula (1) of Section 4.1. Then, if we assume a maximum imbalance threshold of10%, the load balance al-gorithm is triggered. In Figure 2.(b) and Table 2 we show the configuration of the consistent hashing ring after executing the load balance algorithm. Therefore, the result of applying the efficiency formula (1) tell us that the system is 93% bal-anced, i.e. there is an imbalance of 7%. Therefore, the algo-rithm attempts to balance the workload by means of changing the number of partitions per bucket. The number of partitions
p
0p
1p
2p
3LPs
Partition 1 Partition 2 Partition 3 Partition 4 (a)p
0p
1p
2p
3LPs
Partition 1 Partition 2 Partition 3 Partition 4 Partition 5 Partition 6 (b)Figure 2. Overview of the consistent hashing load balance algorithm.
per bucket is adjusted meanwhile the percentages of imbal-ance are kept below the threshold value.
Processor # of Partitions Workload
p0 3 10
p1 6 10
p2 3 11
p3 4 10
Table 2. Bucket configuration after executing the load balance algorithm.
4.1 Load balance algorithm
We use a key-based approach, where each LP is associated with an unique key and any departing event must specify the destination LP by means of a key. We have designed a fine grain load balance algorithm which takes advantage of this approach on the consistent hashing scheme [13]. At the end of each superstep, thecommunication layer is in charge of routing each event stored in the output message queue. The approach in a standard consistent hash ring consists of apply-ing a hash function to the key of events which is then used to determine the physical destination (processor identifier).
In our approach we proceed differently. Each
proces-sor maintains a local hash table named Tl[index] =< proc, weight >, whereindexis the hash value of the next
Event Value Time (# of triggered events) FS NEWQ 5.0 0.000019 FS MERGE N IS+4.0 0.000037 CS HIT 5.0 0.000020 CS NOHIT 5.0 0.000020 IS T 5.0 0.000041 CS T / CS U 5.0 0.000015
Table 3. Benchmark of the simulated events.
event key in the output message queue,weightis the num-ber of events that are going to be processed by this event when simulated in its destination LP, andprocis the processor hold-ing this LP.
Figure 3. Mapping keys into the local hash table.
Keys are string values, therefore we first apply a hash function in order to transform astring key(ke.str) to aninteger key
(kint). To this end, we use theFowler-Noll-Vohash function
[6]: kint = F N V1a(ke.str), because is fast and maintains
a low collision rate. Theinteger keyis mapped into the hash tableTlby means of a second hash functionindex=h(kint)
(based on the module function, see Figure 3).
The hash table is filled up by processing the destinationstring keysof departing messages (events), duringNsupersteps. At the end of each superstep, thecommunication layeriterates over the output message queue and determines the destina-tion processor of each event by accessing to the hash tableTl.
If there is no entry for a given eventeand a given destination string keyke.str, we compute the processor destination of the
event for the first time asTl[index].proc=hash(ke.str)and we setTl[index].weight=weight(e.type). If the hash en-try is not empty, the processor destination is retrieved from the hash table and the elementTl[index].weightis increased
by the respectiveweight(e.type)units.
The value ofweight(e.type)is the number of new events that must take place inside the destination LP when the eventeis simulated in its LP where each value is amplified by an esti-mation of the running time demanded by the internal event. For the experimentation presented in this paper, those values are listed in Table 3 as an example. The first column shows the most important events IDs simulated in our model, which are related to the operations executed by our WSE test ap-plication. The events with IDF S N EW Qrepresent queries arriving from users (step 1 of Figure 1). TheF S M ERGE
events represent partial results of queries coming from the Index Service partitions. The Front Service waits for allP
partial results before executing the merge operation (step 5 of Figure 1). Events with IDCS HIT represent acache hit
for a given query and theCS N OHIT events, represent a
cache missand the query has to be sent to the Index Service (step 3 of Figure 1). Events with IDIS Trepresent messages coming from the Front Service to the Index Service (step 4 of Figure 1). Events with IDCS T represent messages coming
from the Front Service to the Caching Service to search for the query in the cache memory (step 2 of Figure 1). Events
with ID CS U represent messages coming from the Front
Service to the Caching Service to update the cache memory (step 6 of Figure 1)
The second column in Table 3 shows the number of events triggered by an event of the first column. For example,
weight(FS NEWQ) = 5 means that the event FS NEWQ
triggers 5 new events, also F S M ERGE events triggers
N IS+ 4new events, where N IS is the number of Index
Service partitions. The third column shows the average exe-cution time spend in simulating the corresponding events. We executed a benchmark for the simulation executions in order to obtain these values.
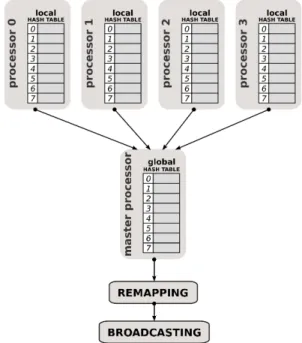
At the end ofN supersteps, each processor sends its local hash tableTlto the master processor (top of Figure 4). Each
processor only sends information regarding non empty en-tries ofTl. The master processor collects all hash entries into
a global hash tableTg(middle of Figure 4). Then, the
mas-ter processor demas-termines whether there is load imbalance by applying the following efficiency formula:
Ef = ( P−1 X
i=0
load[proci]/max (load[0, . . . , P −1]))/P (1)
whereload[proci]is the sum of the weights corresponding
to events processed by the processorproci. If the efficiency
value is below certain threshold, the load balance algorithm is triggered.
Figure 4. Load balance process.
The load balance algorithm consists of moving the limits be-tween adjacent buckets of the consistent hashing ring, in or-der to adjust the workload per processor. The goal of the
al-gorithm is to achieveload[proci]values close to the average workload reported by all processors.
Algorithm 1Load balance algorithm
1: procedureLOAD BALANCE(Tg) 2: m←avg load(Tg)
3: clear(load) 4: proc←0
5: forentry∈Tgdo
6: if (|load[proc] + entry.weight − m| ≥ |load[proc]−m|AN D proc6= (P−1)) then
7: proc←proc+ 1
8: end if
9: load[proc]←load[proc] +entry.weight
10: entry.proc←proc .Remapping.
11: end for
12: bcast(Tg)
13: clear(weight(Tg)) 14: migration() 15: end procedure
Algorithm 1 shows the main steps executed by the load bal-ance algorithm. We first compute the average workload per
processor m = P1 P
∀e∈Tg(e.weight) (line 2). Then, the
load balance algorithm consists of iterating over the global consistent hashing tableTg(line 5) and assigning hash entries
to processors by adjusting their workload close to the average
m. In line 6, the algorithm calculates which would be the workload of the current processorproc, if it is assigned the next entry of the global table (load[proc]+entry.weight). If the difference between this new estimated workload and the averagemis greater than the distance of the current workload to the average, the algorithm proceeds to the next processor identifier. In other words, no more entries are assigned to the current processor.
Next, the processor workload is increased byentry.weight
units (line 9) and the processor assigned to theentryis up-dated (line 10). Finally, the algorithm broadcasts Tg (only
entry values and processor identifiers) and clears the weight values of the global consistent tableTg. At this point the
mi-gration process is executed.
5. EXPERIMENTS
In this section we present the experimental results obtained from the execution of the distributed simulator with a set of different configurations.
5.1 Simulation Model
In this work we use a simulation model that describes a web search engine composed by the following configuration:
• A set of front-end services (FS) processors
• A set of caching services (CS) processors (partitioned and replicated)
• A set of index services (IS) processors (partitioned and replicated)
• AQuery Generatorin charge of injecting queries from the
AOL query logto the FS by using a different query arrival rate.
• A two-level caching strategy. On one hand, the first level consists of a result cache which stores the most frequent queries with their top-kresults. On the other hand, the sec-ond level cache consists of a location cache [15] in charge of storing the partition identifiers of the index service capa-ble of placing documents in the top-kresults for frequent queries.
5.2 Settings
Experiments were performed on a 32-core platform with 64GB Memory (16x4GB), 1333MHz and a disk of 500GB, 2x AMD Opteron 6128, 2.0GHz, 8C, 4M L2/12M L3, 1333 Mhz Maximum Memory, Power Cord, 250 volt, IRSM 2073to C13. The operating system is Linux Centos support-ing 64 bits. The simulator was developed by ussupport-ingC++ (gcc-4.5.3),BSPonMPI (0.2)3, andOpenMP.
We used a log of 36,389,567 queries submitted to the AOL Search service between March 1 and May 31, 2006. We pre-processed the query log following the rules applied in (Gan and Suel 2009) (removal of stopwords, term normal-ization, deletion of duplicated terms and assumption that two queries are identical if they contain the same words, no mat-ter the order). The resulting log had 16,900,873 queries, where 6,614,176 are unique queries and the vocabulary con-sists of 1,069,700 distinct query terms. We also used a sam-ple (1.5TB) of the UK-Web obtained in 2005 by the Yahoo! search engine, over which an inverted index with 26,000,000 terms and 56,153,990 documents was constructed. We exe-cuted the queries against this index in order to get the empir-ical cost distributions for our models. The document ranking method used was WAND [2] and the cache policy was LRU. Experiments were performed usingP = {1,2,4,8,16,32}
cores. Table 4 shows the three different service configura-tions (namely, the number of processors per service) used for the simulation of the model described in Section 3. The col-umnCSp corresponds to the number of partitions assigned
to the Caching Service.CSrrefers to the number of replicas
assigned to the Caching Service. The same nomenclature is used for the Index Service.
Additionally, we used three different query arrival time: Low query traffic (the mean value of the exponential distribution is1.6∗10−5), Medium (the mean value of the exponential distribution is1.6∗10−6) and High (the mean value of the exponential distribution is1.6∗10−7).
Results were obtained for the simulation of Q = 100.000
queries. Furthermore, the load balance algorithm uses a max-imum imbalance threshold of5%and the consistent hashing table has a fixed number of8.192entries.
5.3 Results
Performance evaluation 3http://bsponmpi.sourceforge.net
configuration FS CSp CSr ISp ISr
small 50 20 10 60 140
medium 70 35 15 90 200
large 90 50 20 120 260
Table 4. Web service configuration used in the experiments.
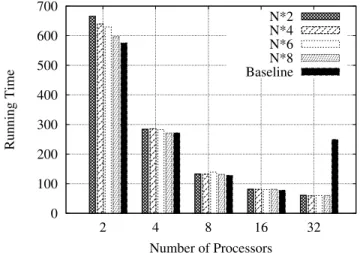
Figure 5 shows the time required to simulateQ = 100.000
queries with a large system configuration (simulating a total of 32290 services) when query traffic is low. For the proposed load balance algorithm we setN = 10and perform experi-ments varying the number of supersteps elapsed to compute the imbalance of the simulation (N ×2,N ×4,N ×6 and
N×8). Thex-axis shows the running time in seconds and they-axis the number of processors. Results show that with few processors, the baseline approach achieves lower running time. The load balance approach fails to improve the execu-tion time with few processors, mainly because of the com-putations required to compute the imbalance of the proces-sors and also because of the communication cost associated to transmit the information of the hash tablesTlandTg.
However, the load balance approach outperforms by 75% the baseline algorithm when running the simulation with 32 pro-cessors. The different numbers of supersteps elapsed to com-pute the imbalance of the simulation, have a bigger impact on the performance of the load balance algorithm when using few processors (2 or 4 processors), but with a larger number of processors this impact is negligible.
0 100 200 300 400 500 600 700 2 4 8 16 32 Running Time Number of Processors N*2 N*4 N*6 N*8 Baseline
Figure 5. Running times for a large WSE service configuration with low query traffic.
Figure 6 shows the results achieved by the baseline approach and our load balance algorithm when simulating a large WSE service configuration but under high query traffic. With this experiment we evaluate the performance of the load balance algorithm when simulations are saturated. In other words, with this experiment we saturate the communication network and the incoming message buffers in each processor among others. Results show that under such extreme conditions, our proposed load balance algorithm is capable of improving the performance of the baseline approach. WithP = 2the load
balance approach improves by 22% the baseline algorithm. This improvement tends to rise up to 71% withP = 32.
0 500 1000 1500 2000 2500 3000 2 4 8 16 32 Running Time Number of Processors N*2 N*4 N*6 N*8 Baseline
Figure 6. Running times for a large WSE service configuration with high query traffic.
In Figure 7 we compare the performance achieved by the baseline approach and the load balance algorithm with differ-ent query traffics and differdiffer-ent WSE services configurations usingP = 32. Thex-axis shows the labelCH which cor-responds to the Consistent Hashing algorithm and the label
B, which corresponds to the Baseline algorithm. They-axis shows normalized running times to better illustrate the per-formance and differences reported by the algorithms. To this end, we divide the running time reported in each experiment by the maximum reported in that set of experiments. In other words, we group the experiments according to the query traf-fic (Low, Medium and High), and each running time reported by the algorithms in a particular group, is divided by the max-imum in that group.
As expected, the large system configuration requires a larger running time to finish the processing ofQqueries. Moreover, under high query traffic, the execution time required to simu-late a large system configuration is 30% slower than the time required to simulate a medium service configuration system. This reflects the fact that under such conditions, the simula-tion execusimula-tions are saturated producing addisimula-tional overheads and delays. However, in general, results show that in all cases, the load balance approach is capable of outperform the base-line performance by 70% in average.
Communication evaluation
Figure 8 and Figure 9 show communication percentage over the total execution time. In Figure 8 the experiment was per-formed with a large service configuration system, when query traffic is low. Results shows that the baseline approach with
P = 2spends more time performing computations tasks and only 9% of the time is for communication. However, as we increase the number of processors the time spent for commu-nication is higher, reaching 94% of the total execution time. On the other hand, the load balance algorithm spends up to 29% of the total execution time to perform communication tasks including sending hash tables. But withP = 32, the
0 0.2 0.4 0.6 0.8 1 1.2 1.4 CH B CH B CH B
Normalized Running Time
Algorithms
Low Medium High
Large Medium Small
Figure 7. Normalized running time forP= 32.
load balance algorithm reports lower communication costs, only 80% of the total time is spent in communication oper-ations. That is because, as we increase the number of pro-cessors, the baseline communication can be seen as spaghetti of messages coming and going from different processors, whereas the load balance algorithm tends to organize com-putation among processors.
In Figure 9 we set query traffic to high, but we observe simi-lar results as when query traffic is low. The baseline approach withP = 2spends 26% of the total time for communication operations. WithP = 16the baseline spends 80% of the time in communication operations and withP = 32this percent-age in increased to 91% of the total execution time. The com-munication operations of the load balance algorithm require 48% of the total execution time forP= 2and forP = 32this percentage is increased to 80% of the total execution time.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 2 4 8 16 32 Communication percentage Number of Processors N*2 N*4 N*6 N*8 Baseline
Figure 8. Percentage of time required to perform communication operations for a large system configuration with low query traffic.
Memory evaluation
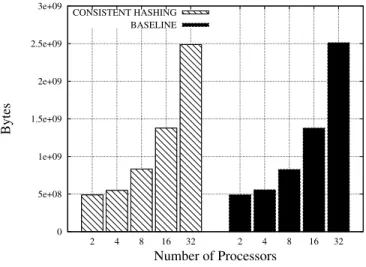
Regarding memory consumption, Figure 10 shows the max-imum amount of bytes used by both the baseline and load balance algorithms with different number of processors at any
0 0.2 0.4 0.6 0.8 1 1.2 1.4 2 4 8 16 32 Communication percentage Number of Processors N*2 N*4 N*6 N*8 Baseline
Figure 9. Percentage of time required to perform communication operations for a large system configuration with high query traffic.
instant of the execution. Results show that both algorithms re-port similar memory usage. Thus, although the load balance algorithm uses a local and a global hash table to compute the imbalance of processors, the additional amount of memory required to run this operations is not significant.
0 5e+08 1e+09 1.5e+09 2e+09 2.5e+09 3e+09 2 4 8 16 32 2 4 8 16 32 Bytes Number of Processors CONSISTENT HASHING BASELINE
Figure 10. Maximum memory usage. Number of stragglers and accuracy evaluation
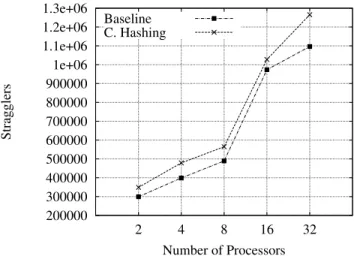
Figure 11 and Figure 12 show the number of stragglers events (events processed in incorrect order) with a large service con-figuration system and with low and high query traffic respec-tively. In both cases (but with a higher impact when query traffic is high), the baseline approach reports fewer number of stragglers events.
When events arrive to an LP, the approximate parallel simu-lation algorithm checks whether this events are stragglers. If an event is considered straggler (its execution time is lower than the clock of the simulation kernel), the clock of the sim-ulation kernel is backed up to the time of the straggler event and it is stored in the FEL (List of Future Events). However, these stragglers events may not be executed in the current su-perstep. Then, when the load balance algorithm detects an
imbalance and some LPs are migrated to other processors, some events stored in the FEL of the migrated LPs can be de-tected as stragglers, because their execution time is compared against the clock of the simulation kernel of the new proces-sor.Thus, some events may be counted as stragglers more than once.
When the query traffic is low, the load balance approach re-ports in average 2% more stragglers events than the baseline approach (Figure 11). This percentage is increased to 13% when query traffic is high as shown in Figure 12. Then, sim-ulating a saturated WSE with high flow of queries is more likely to affect the accuracy of the approximate parallel sim-ulations. However, as shown in Table 5, the accuracy is not drastically affected.
We evaluate the accuracy of the load balance approach by computing the relative error between the results achieved by the sequential simulation and its corresponding parallel ap-proach (the baseline) and our load balance apap-proach. We calculated the root mean square error of the deviation which is a measure of the differences between values obtained by the sequential simulation and the values reported by the par-allel simulations with load balance. It is defined as m =
p
(P
(xi −x)2/(n(n−1))and we calculated the relative
error (er) defined asm/x.
We used the following metrics: throughput, average query re-spond time (QRT) and hit ratio. Results presented in Table 5 show a small relative error for all metric. The most sensitive one is the average query response time which presents an rel-ative errorer= 0.0102,and it is small enough indicating that
the load balance approach is capable of maintaining a good estimation of the metrics obtained by the simulations.
200000 400000 600000 800000 1e+06 1.2e+06 1.4e+06 1.6e+06 1.8e+06 2e+06 2.2e+06 2.4e+06 2 4 8 16 32 Stragglers Number of Processors Baseline C. Hashing
Figure 11. Number of stragglers events under low query traffic and using a large system configuration.
Metric Baseline Consistent Hashing
Throughput 0.0014 0.0045 QRT 0.0024 0.0102 Hit cache 0.0151 0.0169
Table 5. Accuracy of the simulations using the baseline and the load balance approach with a large service configuration system and high query traffic.
200000 300000 400000 500000 600000 700000 800000 900000 1e+06 1.1e+06 1.2e+06 1.3e+06 2 4 8 16 32 Stragglers Number of Processors Baseline C. Hashing
Figure 12. Number of stragglers events under high query traffic and using a large system configuration.
6. CONCLUSION
We proposed to use a load balance algorithm to improve the performance of approximate parallel simulations as presented in [16]. The presented algorithm aims to minimize the num-ber of LPs migrations between processors by applying a con-sistent hashing approach which forms a ring of buckets. Each processor holds a sub-set of LPs belonging to each bucket. The migration of LPs is performed between neighboring pro-cessors of the consistent hashing ring. To compute the imbal-ance, our load balance algorithm takes into account the num-ber of events processed by each LP and the time required to simulate those events. The experimental results show that our load balance algorithm is capable of quickly restoring paral-lel simulation to a situation of efficient performance. The best results are observed for large number of processors operating under saturation caused by high traffic flows of events in real life simulation models of large Web search engines.
ACKNOWLEDGMENTS
This research was partially funded by Basal funds FB0001, Conicyt, Chile; and Mincyt-Conicyt CH1204.
REFERENCES
1. Boukerche, A., and Das, S. K. Reducing null messages overhead through load balancing in conservative distributed simulation systems.J. Parallel Distrib. Comput. 64, 3 (Mar. 2004), 330–344.
2. Broder, A. Z., Carmel, D., Herscovici, M., Soffer, A., and Zien, J. Y. Efficient query evaluation using a two-level retrieval process. InCIKM(2003), 426–434. 3. Cacheda, F., Carneiro, V., Plachouras, V., and Ounis, I.
Performance analysis of distributed information retrieval architectures using an improved network simulation model.Inf. Process. Manage. 43, 1 (2007), 204–224. 4. Calheiros, R. N., Ranjan, R., Beloglazov, A., De Rose,
C. A. F., and Buyya, R. Cloudsim: A toolkit for modeling and simulation of cloud computing
environments and evaluation of resource provisioning algorithms.Softw. Pract. Exper. 41, 1 (2011), 23–50.
5. Chowdhury, A., and Pass, G. Operational requirements for scalable search systems. InProceedings of the Twelfth International Conference on Information and Knowledge Management(2003), 435–442.
6. Fowler, G., Noll, L., Vo, K., and Eastlake, D. The fnv non-cryptographic hash algorithm. Tech. rep., IETF Internet-draft (March 2012), 2011.
7. Fujimoto, R. Parallel discrete event simulation.Comm. ACM 33, 10 (Oct. 1990), 30–53.
8. Gan, B. P., Low, Y.-H., Jain, S., Turner, S., Cai, W., Hsu, W. J., and Huang, S. Y. Load balancing for conservative simulation on shared memory multiprocessor systems. InParallel and Distributed Simulation, 2000. PADS 2000. Proceedings. Fourteenth Workshop on(2000), 139–146.
9. Gao, Z., Liu, D., Yang, Y., Zheng, J., and Hao, Y. A load balance algorithm based on nodes performance in hadoop cluster. InNetwork Operations and Management Symposium (APNOMS), 2014 16th Asia-Pacific(Sept 2014), 1–4.
10. Gil-Costa, V., Lobos, J., Solar, R., and Mar´ın, M. Ameds-tool: an automatic tool to model and simulate large scale systems. InProceedings of the 2014 Summer Simulation Multiconference, SummerSim 2014,
Monterey, CA, USA, July 6-10, 2014(2014), 20. 11. G´omez-Pantoja, C., Rexachs, D., Mar´ın, M., and Luque,
E. A fault-tolerant cache service for web search engines: Radic evaluation. InProceedings of the 18th
International Conference on Parallel Processing, Euro-Par’12, Springer-Verlag (Berlin, Heidelberg, 2012), 298–310.
12. Grande, R. E. D., and Boukerche, A. Dynamic balancing of communication and computation load for hla-based simulations on large-scale distributed systems.Journal of Parallel and Distributed Computing 71, 1 (2011), 40 – 52.
13. Karger, D., Lehman, E., Leighton, T., Panigrahy, R., Levine, M., and Lewin, D. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. In
Proceedings of the Twenty-ninth Annual ACM
Symposium on Theory of Computing, STOC ’97, ACM (New York, NY, USA, 1997), 654–663.
14. Kunkel, J. Using Simulation to Validate Performance of MPI(-IO) Implementations. InSupercomputing(2013), 181–195.
15. Mar´ın, M., Ferrarotti, F., Mendoza, M., G´omez-Pantoja, C., and Gil-Costa, V. Location cache for web queries. In
Proceedings of the 18th ACM Conference on
Information and Knowledge Management, CIKM 2009, Hong Kong, China, November 2-6, 2009(2009), 1995–1998.
16. Marin, M., Gil-Costa, V., Bonacic, C., and Solar, R. Approximate parallel simulation of web search engines.
InProceedings of the 2013 ACM SIGSIM Conference on Principles of Advanced Discrete Simulation(2013), 189–200.
17. Marin, M., Gil-Costa, V., and Gomez-Pantoja, C. New caching techniques for web search engines. In
Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing(2010), 215–226.
18. Markatos, E. On caching search engine query results.
Comput. Commun. 24, 2 (2001), 137–143.
19. Meraji, S., Zhang, W., and Tropper, C. A multi-state q-learning approach for the dynamic load balancing of time warp. InPrinciples of Advanced and Distributed Simulation (PADS), 2010 IEEE Workshop on(May 2010), 1–8.
20. Peschlow, P., Honecker, T., and Martini, P. A flexible dynamic partitioning algorithm for optimistic distributed simulation. InPrinciples of Advanced and Distributed Simulation, 2007. PADS ’07. 21st International Workshop on(June 2007), 219–228.
21. Quaglia, F., and Baldoni, R. Exploiting intra-object dependencies in parallel simulation.Inf. Process. Lett. 70, 3 (1999), 119–125.
22. Quaglia, F., and Beraldi, R. Space uncertain simulation events: Some concepts and an application to optimistic synchronization. InProceedings of the Eighteenth Workshop on Parallel and Distributed Simulation
(2004), 181–188.
23. Rao, D. M., Thondugulam, N. V., Radhakrishnan, R., and Wilsey, P. A. Unsynchronized parallel discrete event simulation. InProceedings of the 30th Conference on Winter Simulation(1998), 1563–1570.
24. Valiant, L. G. A bridging model for parallel computation.Commun. ACM 33, 8 (Aug. 1990), 103–111.