2008
A Roadmap For Intelligent Data Analysis Using
Clustering Algorithms And Implementation On
Health Insurance Data
Shamitha S K, V Ilango
Abstract—Clustering is one of the standard unsupervised approaches in the field of data mining. Clustering techniques carry a long history, and an expansive number of clustering techniques have developed by the analysts in the areas of mining. Still, there are acute challenges even today. The paper provides a brief overview of clustering methods from a data mining perspective, with the aim of providing necessary information and references to fundamental concepts available to the community of clustering practitioners. This paper primarily focuses on the four-step procedure of clustering. We described several tightly related topics from data samples to result in interpretation and associated concepts such as classification of clustering algorithm and their characteristic, proximity measure, cluster types and cluster validation techniques. We have implemented some of the clustering algorithms such as kmeans, hierarchical clustering, PAM and fuzzy c means for classifying fraudulent and legitimate transactions in the paper. The results show that fuzzy c means and hierarchical clustering has good classifications accuracy. The article would be supportive in concocting the choice of algorithm and techniques for machine learning research.
Index Terms— Clustering, cluster types, feature selection, similarity measures, validation criteria, Fraud detection.
—————————— ——————————
1 I
NTRODUCTIONCluster analysis plays a crucial part in understanding different phenomena and exploring the characteristics of the obtained data. Many disciplines such as biomedical, health care, business, economics, finance, intrusion, and fraud detection use clustering techniques. The biologists Sneath and Sokal in 1963 coined clustering algorithm in a numerical taxonomy way. Cluster assigns data objects (records) into data groups (called clusters) with the goal that data from a similar group are more likely to be each other than items from different clusters [19]. The similarity of data in each cluster is found by calculating the distance measure of the data objects in each cluster. The term cluster analysis, which was initially used by Tryon in 1939. It includes different techniques and algorithms which help in grouping objects having similar properties into respective categories. This paper points to cover a few algorithms used for clustering, with a brief description of each. Clustering algorithms are broadly divided into following methods such as, partitioning methods, hierarchical methods, density-based methods, grid-based methods, model-based methods, and clustering high dimensional data [57]. An excellent overview of clustering algorithms and techniques can be found in papers [22] [26]. Clustering has its ability to work with really high dimensional data and also to find clusters with different characteristics having irregular shape, it also handles outliers, deals with time complexity, data order dependency,
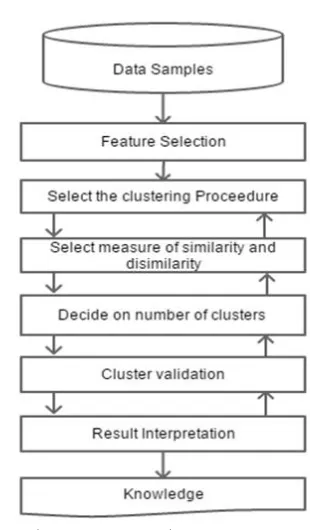
Fig 1. Clustering Procedure
labeling or assignment, reliance in a priori knowledge, user-defined parameters and interpretability of results [45] [37]. The paper provides an introduction to clustering within the field of data mining. We also try to examine some clustering strategies that have currently created mainly for the field of data mining. In Section 2 Four-step clustering procedure is discussed. Section 3 describes the data samples techniques. Section 4 explains the primary clustering algorithm and their characteristics and the various proximity measures. Section 5 gives a detail review on clustering algorithm, section 6 narrates the type of clusters, and section 7
————————————————
Shamitha S K is currently pursuing her PhD from Visveswaraya Technological University, India, PH-9742260158. E-mail: shamithashibu@gmail.com V Ilango is currently working as a professor at CMR Institute of Technology
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 8, ISSUE 10, OCTOBER 2019 ISSN 2277-8616
describes cluster validation and section 8 and 9 details on experiments and validation of results after implementation. The final section concludes this work.
2
C
LUSTERINGP
ROCEDUREGenerally, clustering procedure has four steps [52]: Feature selection or extraction: As mentioned in the paper [3], feature selection picks unique features from a data set, while the later one employs a few changes or some transformations to produce valuable and new features from the dataset. Table 1 explains the key factors for feature selection. Clustering algorithm design or selection: This step is a blend of proximity measure selection, which directly affects the creation of the resulting clusters and the criterion function construction, which makes partition of clusters towards optimization. First, the proximity measures will be selected, and then the algorithm aims towards building clustering criterion for the further optimization of a problem. This will be well defined mathematically. Cluster validation: Cluster validation is divided into external and internal validation. This is an essential and vital criterion to determine whether the clusters are classified accurately. Validation measures provide the users to measure an adequate degree of confidence in the results obtained from the algorithm. Result
Interpretation, it refers to interpreting the data partition by the experts of the relevant fields
3
D
ATAS
AMPLE2010
4
F
EATURE SELECTIONFeature selection techniques are categorized into following such as filter methods, wrapper methods and embedded methods [5][21][28][35][40][51]. Each dimension is further explained in Table.2 and Table 3 provides a framework of feature selection techniques, showing for every technique the most important advantage and disadvantage, evaluation Criteria and also gives related algorithm and software tools [67]. Feature selection strategies are mainly classified into three types: complete, sequential, and random search [38][66]. Complete search always tries to the best solution about the evaluation criteria. An exhaustive guarantees a complete solution, it assures that not a single subset is missed. While using sequential search, it does not use completeness and therefore there is always a danger of losing optimal subsets. There are many alternatives of greedy hill
2012
5
C
LUSTERINGA
LGORITHMS 5.1 Major clustering algorithmsA broad range of clustering algorithms have been projected in the literature in numerous scientific disciplines over a decade making it very difficult in reviewing all the approaches. Every clustering methods differ in the selection of their objective function, probabilistic generative models, and heuristics [63] [61]. We have reviewed a few of the approaches based on clustering. Based on this we can categorize the clustering methods into partitioning, hierarchical, density, grid-based, constraint-based, model-based and high dimensional clustering [3] [10] [12] [13] [15] [53]. Some
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 8, ISSUE 10, OCTOBER 2019 ISSN 2277-8616
different partitions can be viewed as studying the similarity degree in the data points. Table 4 gives a brief review of different clustering algorithm.
5.2 Characteristics of Clustering Algorithm
Attributes given by the user are the ones to be applied with Partition Cluster; User has to enter some clusters and the corresponding stopping criteria; the main disadvantage of partitioning clustering is that they cannot handle outliers [17]. They produce spherical shaped clusters only. In Hierarchical clustering, data can be in more than one clusters [32]. It has the ability to handle outliers and noisy data and produces arbitrarily shaped clusters. Clustering based on density, is applied to spatial data, where multiple features has to be chosen for clustering [6]. Grid-based methods clusters data at a different level of detail based on all the dimensional attributes [2] [43]. Using this approach clusters can be show cased in a better way. The clusters produce arbitrarily shaped clusters. data is a fundamental element in a computational system. Due to dynamic changes in science and technology, the need for intelligent computing is becoming important. A good learning system is necessary for exploring knowledge through the data analysis process. The unsupervised learning system is considered as one of the efficient techniques. In this, cluster analysis is a superior method. Though regularly new methods and algorithms are being discovered in
2014
[59]. [7] Clustering with high dimensional data requires efficient clustering algorithms; most of the automated clustering algorithms tend to fail [71][51][70]. Its difficulty in finding necessary parameters for tuning the algorithms for an application with high dimensional data. The primary solution is to try and build ensembles of clustering algorithms. Combining clustering ensembles is a herculean task because the ensemble algorithm should be good enough in terms of effectiveness and efficiency [72]. There are several ways in which cluster ensembles can be
formed such as using the same techniques with different configurations or using the results of one technique in other, some methods follow a split and merge strategy, etc. The important characteristic of clustering algorithm in terms of effectiveness and efficiency are shown in table 5.
5.3 Proximity Measures
Proximity measures determine the closeness or how the objects are similar to each other. It is quite natural to question on the kind of methods used to determine the similarity between a pair of objects or clusters. [4] [9] [11] [23]. The various similarity and dissimilarity measures are given in the Tabel.7. [64] Clustering algorithms are constructed based on the proximity of the objects, in which each data objects are defined by a set of features which are represented as a multidimensional vector. These features can be of any type say qualitative, quantitative, discreate or continuous, which leads to different measure mechanisms as shown in Table 9. Accordingly, the data set with N data objects of d features will be recorded as an N x d data matrix, in which each row represents an object and columns denotes a feature. The data matrix should be a two-mode matrix because its rows and columns have different meaning. This is in contrast to the one-mode elements representing the similarity or distance measure for any pairs of data objects in the data set, because in a proximity matrix, both dimensions share the same meaning. Properties of similar and dissimilar conditions are explained in Table 6. Proximity matrix, which is N
6
C
LUSTERT
YPESGenerally, clusters are formed based on size and different scaling factors. They are classified as well-separated, center-based, contiguous, density-based, conceptual clusters [8] [34] [39]. Well-Separated Cluster- In this type of clusters each point inside the clusters are closer to each other, but not closer to the points outside the cluster. Center-based Cluster- In a center-based clusters every data object in a cluster are closer to its centroid (A center of the cluster). In this type the center of the cluster is the most representative point. Contiguous Cluster – In a continous cluster, the cluster points will be closer to one or more points in the cluster. Density-based- Density based clusters are separated based on its thickness. It separates low density regions by high density. [24] Density based clusters are used in the case of irregular clusters, or when the data has noise or outliers present. Conceptual Clusters- Conceptual clusters always represent a particular concept, it also shares common properties. [33].
7.
C
LUSTER VALIDATION AND RESULT INTERPRETATIONCluster validation is a process were the results are evaluated [37], it can be either quantitative or objective way. The main reason behind validating cluster analysis results are to determine
whether there is a non-random structure in the data; determine the number of clusters; evaluate whether the given solution fits; evaluate whether the solution agrees with the clusters obtained accordance with other data sources [14] [49] [58] [61] [68] [69]. The results obtained will to compared to know which is better[30] [41]. According to papers[16] [44] validation measures are classified into the following types: Internal validation, external validation and relative validation. Internal Index is used to measure the degree of goodness of a clustering structure with out considering the outer clustering elemnents [20]. Fitness and stability are considered as main measures which are used to evaluate the clustering results internally. Fitness of a cluster can be refferd as the arrangment of cluster, which is based on following properties such as compactness, separation of the objects inside the cluster. This is usually evaluated by indices that are based on geometrical connectedness [36] [60] . Stability of a clustering solution is another point to be considered for evaluating the results, which usually refers to how strong a clustering solution is under perturbation or sub-sampling of the original data. External Index validation criteria are used to find the degree to which each cluster labels match externally. It can share measures used in stability validation as described above both contingency tables and entropy-related indices can be employed for external validation as well. The Relative Index criteria are used to compare two different clusters. Often an external or internal validation criterias are used in common. Result Interpretation-This must be done through experimentation. Cluster analysis discovers structures in data However, clustering alone does not provide an explanation or interpretation. Cluster analysis naturally discovers groups within the raw data without explaining why they exist. Interpretation looks at what they score highly (importance), where they score low (not critical) and the demographic similarities. Table 7 shows some of the important validation measures and related index.
8
E
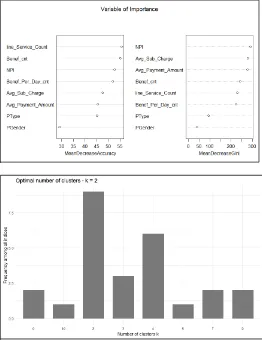
XPERIMENTThis experiment aims to find how efficiently different clustering algorithms work on the health insurance database. The database used in this paper is taken from CMS (Center Medicare and Medicaid Services), which is a Medicare provider’s data set. The data contains doctors and their beneficiaries who have enrolled in Medicare insurance. A detailed simplified data set is prepared by excluding the features. Initially, it had 29 attributes; seven attributes were selected by finding the mean decrease accuracy and mean decrease gini from Random forest. Gini importance finds the purity by splitting the particular variable, and it compares that variable with the class label, which is a kind of supervised technique. Figure 2 shows the variable importance result obtained after running the random forest. Once the variable was finalized preprocessing was performed on the data. Following steps were carried out
There were some missing values it was then replaced by its mean.
Descriptive analysis was performed on the data.
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 8, ISSUE 10, OCTOBER 2019 ISSN 2277-8616
Normalization was performed on the data. Normalization helps in producing good quality clusters.
Once the preprocessing stage is completed, different clustering algorithms were applied on the data to investigate, study and compare the performance of each. The algorithms chosen here are kmeans, Fuzzy c means, BIRCH and hierarchical clustering.
Fig 2. The list of variables of importance
Fig 3 Optimum number of clusters obtained after running the data
9
R
ESULTS AND INTERPRETATIONThe work is implemented in RStudio 3.3.2. Clustering was applied on an array of two clusters. R package NbClust was used to determine the number of clusters for the data. NbClust package gives the best clustering scheme by trying all the possible combinations using the cluster number, its distance measures and clustering methods. Figure 3 shows the result of NbClust method. After that, the same k value was applied to four different clustering algorithms such as kmeans, fuzzy cmeans, hierarchical clustering, and PAM.
After examining the results, the following observations are made:
Data was clustered based on fraud and legitimate transactions. The points outside the clustered regions are outliers which can be considered as fraud itself. There are 953 incorrect instances in kmeans, 267 in hierarchical clustering, 743 in PAM and 619 in fuzzy c means. Though
hierarchical clustering has less incorrect instances, these points were in cluster 1, which is dangerous because here fraud is mentioned as legitimate transactions. In rest of the algorithms cluster 2 was filled with incorrect instances causing least harm.
K means took 8.46 seconds to complete the task, which was comparatively less considering to other algorithms. Hierarchical clustering took 10.36 seconds; PAM took 18.46 seconds and fuzzy c means tool 436.46 seconds to complete, Table 8 compares the accuracy and performance of the algorithms.
From the results, hierarchical clustering maintained proper distances between clusters, but the average within-cluster value was high compared to other clusters. K means maintained a good average within value better.
10
C
ONCLUSION2016
capacity to handle massive and high dimensional datasets with a lower computational time; detect and remove possible outliers and noise; treat effectively categorical and turbulent data. The integration of clustering theories and algorithms with multidisciplinary research is an emerging trend. This integration will significantly benefit both fields and facilitate their advancement of long-standing challenges. By applying the clustering algorithm to claims data, we found that the clustering algorithm when implemented on claims data groups the data into legitimate, and fraud instances. From the above experiment, the majority of the activities are concentrated on one cluster. Most of the frauds could be correctly identified. There are some legitimate activities which are wrongly got detected as frauds. Fraud detection on insurance claims is indispensable, and clustering is the most sought alternative as companies refuse to share trained data with the fear of losing confidentiality. Analysts in this field try with a combination of clustering methods and algorithms with multidisciplinary research for dealing with many issues in fraud detection domain such as class imbalance. From the above experiment, we can conclude that clustering cannot alone predict fraud; it can just group different items. There are many issues and challenges for effectively detecting fraud. So, hybrid techniques will be most suitable to classify and identify fraud. Future work will be focusing on a hybrid method with a combination of semi-supervised, clustering and anomaly detection methods for handling major fraud detection problem, such as class imbalance for efficient fraud classification.
R
EFERENCES[1] Ameer Ahmed Abbasi and Mohamed Younis, ―A survey on clustering algorithms for wireless sensor networks.‖ Computer Communications 30 (2007) 2826–2841
[2] A.Hinneburg and D.A. Keim, ―A General Approach to Clustering in Large Databases with Noise‖, Knowledge and Information Systems (KAIS), Vol. 5, No. 4, pp. 387- 415, 2003. [3] A.K. Jain, M. N. Murty, and P. J. Flynn, ―Data clustering: A
review,‖ACM Computer. Survey., vol. 31, pp. 264–323, 1999. [4] A.Patrikainen and M. Meila, ―Comparing Subspace
Clustering’s,‖ IEEE Trans. Knowledge and Data Eng., vol. 18, no. 7, pp. 902-916, July 2006.
[5] Alper Unler et.al., ―mr2PSO: A maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification‖, Elsevier, Information Sciences 181 ,2011 p.4625–4641
[6] Andreopoulos B, An A, Wang X. Hierarchical densitybased clustering of categorical data and a simplification. In: Proceedings of the 11th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2007), Springer LNCS 4426/2007, pp. 11–22, Nanjing, China, May 22–25, 2007.
[7] A tutorial on clustering Algorithms http://www.elet.polimi.it/upload/ matteucc/Clustering/ tutorial_html/
[8] Tutorial on Clustering Algorithms-
[9] Baca Raton, FL: Chapman and Hall/CRC, Mirkin, Clustering for Data Mining: A Data Recovery Approach, 2005
[10]Balasubramaniyan R, Huellermeier E, Weskamp N, et al.Clustering of gene expression data using a local shape-based similarity measure. Bioinformatics 2005;21:1069–77.
[11]Basu, Sugato, Davidson, Ian, Wagstaff, Kiri (Eds.), 2008. Constrained Clustering: Advances in Algorithms, Theory and
Applications. Data Mining and Knowledge Discovery, vol. 3, Chapman & Hall/CRC.
[12]Ben-David, S., Ackerman, M., 2008. Measures of clustering quality: A working set of axioms for clustering. Advances in Neural Information Processing Systems.
[13]Bill Andreopoulos et.al, ―A roadmap of clustering algorithms: finding a match for a biomedical application‖ BRIEFINGS IN BIOINFORMATICS. Advance Access publication February 24, 2009 VOL 10. NO 3. P.297-314
[14]Chen Peng and Xu Guiqiong, ―A brief study on clustering methods: Based on the k-means algorithm‖, Proceedings of International Conference on E -Business and E -Government (ICEE), 2011, p.1-5
[15]D.-W. Kim, K.-H. Lee, and D. Lee, ―Fuzzy cluster validation index based on inter-cluster proximity,‖ Pattern Recognit. Lett., vol. 24, no. 15, pp. 2561–2574, Nov. 2003.
[16]Data Clustering – Wikipedia-http://en.wikipedia.org/wiki/Data_clustering
[17]F. Boutin, M. Hascoet, Cluster validity indices for graph partitioning, in: Proceedings of the Eighth International Conference on Information Visualisation, IEEE Computer Society, 2004.
[18]F. Camastra and A. Verri. A novel kernel method for clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(5):801–804, 2005.
[19]F. Camastra, ―Data dimensionality estimation methods: A survey,‖ Pattern Recognition, vol. 360, no. 12, pp. 2945–2954, 2003
[20]Grambeier J, Rudolph A. Techniques of cluster algorithms in data mining. DataMining KnowlDiscov 2002;6:303–60.
[21]Greene, D. & Cunningham, P. (2006). Efficient prediction-based validation for document clustering. In Proc. 17th European Conference on Machine Learning (ECML’06).
[22]Guyon and A. Elisseeff, ―An introduction to variable and feature selection,‖ J. Mach. Learn. Res., vol. 3, pp. 1157–1182, 2003.
[23]H.C. Romesburg. 2004. Cluster Analysis for Researchers. Morrisville, NC: Lulu.com. ISBN 1411606175 / 9781411606173 / 1-4116-0617-5
[24]H.Yang, W.Wang, J. Yang, and P. Yu, ―Clustering by pattern similarity in large data sets,‖ in Proc. 2002 ACM SIGMOD Int. Conf. Manage.Data, 2002, pp. 394–405.
[25]HaiDong Meng et.al, ―Research and Implementation of Clustering Algorithm for Arbitrary Clusters‖, Proceedings of IEEE International Conference on Computer Science and Software Engineering, 2008,p.255-258.
[26]Hair. et.al, ―Multivariate data analysis‖, Pearson Education Pte Ltd, Fifth edition, ISBN:81-297-0021-2
[27]Han and Kamber, ― Data mining: concepts and techniques‖, Morgan Kaufmann publishers, Second edtion,2006, ISBN: 978-1-55860-901-3
[28]Hore, Prodip, Hall, Lawrence O., Goldgof, Dmitry B., 2009a. A scalable framework for cluster ensembles. Pattern Recognition 42 (5), 676–688.
[29]Http://en.wikipedia.org/wiki/Feature_selection
[30]Http://www.cs.ucl.ac.uk/staff/M.Sewell/publications.html [31]Hui Xiong, Junjie Wu, and Jian Chen,―K-Means Clustering
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 8, ISSUE 10, OCTOBER 2019 ISSN 2277-8616
[32]Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognition Letter. (2009), doi:10.1016/j.patrec.2009.09.011,p.1-16.
[33]Jie Lian, ―A Framework for Evaluating the Performance of Cluster Algorithms for Hierarchical Networks‖, IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 15, NO. 6, DECEMBER 2007,p.1478-1489
[34]Kannan R, Vampala S, Vetta A. On clusterings: Good, bad and spectral. In: Proceedings of the Foundations of Computer Science’00, pp. 367–378, 2000.
[35]Kim D, Lee K, Lee D. Detecting clusters of different geometrical shapes in microarray gene expression data. Bioinformatics 2005;21:1927–34.
[36]L. Yu and H. Liu, ―Efficient feature selection via analysis of relevance and redundancy,‖ Journal of Machine Learning Research, vol. 5, pp. 1205–1224, 2004.
[37]Lange, T., Roth, V., Braun, M.L. & Buhmann, J.M. (2004).Stability-based validation of clustering solutions. Neural Computation, 16.
[38]Levine, E. & Domany, E. (2001). Resampling method for unsupervised estimation of cluster validity. Neural Computation, 13.
[39]Liu and Yu, ―Toward Integrating Feature Selection Algorithms for Classification and Clustering‖, IEEE Transactions on Knowledge and Data Engineering, Vol. 17, No. 4, April 2005, P.491-502
[40]Liu, Z., Yu, J.X., Chen, L., Wu, D., 2008. Detection of shape anomalies: A probabilistic approach using hidden markov models. In: IEEE Internat. Conf. on Data Engineering, pp. 1325– 1327.
[41]Luis Carlos Molina et.al., ―Feature Selection Algorithms: A Survey and Experimental Evaluation‖, proceedings of IEEE International Conference on Data Mining 2002, p.306-313 [42]M. Bouguessa, S. Wang, and H. Sun, ―An Objective Approach
to Cluster Validation,‖ Pattern Recognition Letters, vol. 27, no. 13,pp. 1419-1430, 2006.
[43]M. C. Naldi, A. C. P. L. F. de Carvalho, R. J. G. B. Campello, and E. R. Hruschka, ―Genetic clustering for data mining,‖ in Soft Computing for Knowledge Discovery and Data Mining, O. Maimon and L. Rokach,Eds. New York: Springer-Verlag, 2007, pp. 113–132.
[44]M. Ester, H.-P. Kriegel, J. Xu, andW. Sander, ―A density-based algorithm for discovering clusters in large spatial databases with noise,‖ in Proc.2nd Int. Conf.Knowl. DiscoveryDataMining (KDD-2006), pp. 226–231.
[45]M.-C. Su, A New Index of Cluster Validity, 2004. [Online].Available:http://www.cs.missouri.edu/~skubic/8820 /ClusterValid.pdf
[46]Madjid Khalilian and Norwati Mustapha, ―Data Stream Clustering: Challenges and Issues‖, Proceeding of International Multi Conference of Engineers and Computer Scientists, March 2010, Vol.1
[47]Osama Abu Abbas, ―Comparisons Between Data Clustering Algorithms‖, The International Arab journal of Information technology, Vol.5, No.3, July 2008, p.320-325
[48]Pang-ning tan et.al , ―Introduction to Data mining‖, Pearson Education, Inc.,2006, ISBN: 978-81-317-1472-0
[49]Pavel Berkhin, ―Survey of Clustering Data Mining Techniques‖, Accrue Software, 1045 Forest Knoll Dr., San Jose, CA, 95129, 2002
[50]Petros Drineas, Alan Frieze, Ravi Kannan, Santosh Vempala,V. Vinay, Clustering in large graphs and matrices, Machine Learning 56 (2004) 9–33.
[51]Piyatida Rujasiri and Boonorm Chomtee, ―Comparison of Clustering Techniques for Cluster Analysis‖, Kasetsart J. (Nat. Sci.) 43, pp. 378 - 388 2009.
[52]R. Elankavi, ―A FAST CLUSTERING ALGORITHM FOR HIGH-DIMENSIONAL DATA‖, 2017,IJCIET , Vol. 5, Issue 5, pp. 1220-1227
[53]R. Xu, S. Damelin, B. Nadler, and D.Wunsch, II, ―Clustering of highdimensional gene expression data with feature filtering methods and diffusion maps,‖ Artificial Intell. Medicine, vol. 48, pp. 91–98, 2010.
[54]Rui Xu and Donald C. Wunsch, ―Clustering Algorithms in Biomedical Research:A Review‖, IEEE REVIEWS IN BIOMEDICAL ENGINEERING, VOL. 3, 2010,p.120-154 [55]S. B. Kotsiantis and P. E. Pintelas, ―Recent Advances in
Clustering: A Brief Survey‖, WSEAS Transactions on Information Science and Applications, 2004, vol.1, p.73—81 [56]T. F. Covo˜es, E. R. Hruschka, L. N. de Castro, and A´ tila
Menezes dos Santos, ―A cluster-based feature selection approach,‖ in Hybrid Artificial Intelligence Systems, 4th International Conference (HAIS-2009), ser. Lecture Notes in Artificial Intelligence, vol. 5572. Springer-Verlag, 2009, pp. 168– 176.
[57]T. Li, ―A Unified View on Clustering Binary Data,‖ Machine Learning, vol. 62, no. 3, pp. 199-215, 2006.
[58]T. Liao, ―Clustering of time series data—A survey,‖ Pattern Recognition, vol. 38, pp. 1857–1874, 2005.
[59]Tan, Pang Nin, Michael Steinbach,Vipin Kumar, 2006, Introduction to Data Mining,Pearson International Edition, Boston
[60]Tibshirani, R., Walther, G., Botstein, D. & Brown, P. (2001).Cluster validation by prediction strength. Tech. rep., Dept. Statistics, Stanford University.
[61]V.Ilango et al. ―Cluster Analysis Research Design model, problems, issues, challenges, trends and tools‖, International Journal on Computer Science and Engineering (IJCSE), Vol. 3 No. 8 August 2011,p. 3064-3070
[62]V.V. Raghavan, C.T. Yu, A comparison of the stability characteristics of some graph theoretic clustering methods, IEEE Transactions on Pattern Analysis and Machine Intelligence 3 (4) (1981) 393–403.
[63]WANG AND CHIANG: ―A Cluster Validity Measure With Outlier Detection for Support Vector Clustering‖ , IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 38, NO. 1, FEBRUARY 2008
[64]Witten and Frank, ― Data Mining-Practical Machine learning Tools and Techniques‖, Morgan Kaufmann Publishers, Second Edition, 2005, ISBN: 0-12-088407-0
[65]X. Wu, V. Kumar and J. Ross ect., Top 10 algorithms in data mining, Knowledge and Information Systems, vol.14, 2008, pp.1-37.
[66]Xu And Wunsch II: Survey Of Clustering Algorithms, IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 16, NO. 3, MAY 2005,P.645-678
2018
41, no. 9, pp. 2742 – 2756, 2008.
[68]Y. Li, M. Dong, and J. Hua, ―Localized feature selection for clustering,‖ Pattern Recognition Letters, vol. 29, no. 1, pp. 10– 18, 2008.
[69]Y.Saeys et al., ―A review of feature selection techniques in bioinformatics‖, Bioinformatics, Vol. 23 no. 19 2007, pages 2507– 2517
[70]Yeung K, Haynor D, Ruzzo W. Validating clustering for gene expression data. Bioinformatics 2001;17:309–318.
[71]Yu, G., Kamarthi, S.V., A cluster-based wavelet feature extraction method and its application. Engineering Applications of Artificial Intelligence (2010), doi:10.1016/j.engappai.2009.11.004
[72]Yu Dejian et al, ―Hybrid self-optimized clustering model based on citation links and textual features to detect research topics‖, Plos One, 2017, doi.org/10.1371/
[73]Zhang et al, ―An Incremental CFS Algorithm for Clustering Large Data in Industrial Internet of Things‖ Vol 13, 2018, pp. 1193-1201.