DOI : https://doi.org/10.32628/CSEIT1952178
Deep Embedding Sentiment Analysis on Product Reviews Using Naive Bayesian
Classifier
Nukabathini Mary Saroj Sahithya, Manda Prathyusha, Nakkala Rachana, Perikala Priyanka, P. J. Jyothi
Department of CSE, Vasireddy Venkatadri Institute of Technology, Guntur, Andhra Pradesh, India
ABSTRACT
Product reviews are valuable for upcoming buyers in helping them make decisions. To this end, different opinion mining techniques have been proposed, where judging a review sentence’s orientation (e.g. positive or negative) is one of their key challenges. Recently, deep learning has emerged as an effective means for solving sentiment classification problems. Deep learning is a class of machine learning algorithms that learn in supervised and unsupervised manners. A neural network intrinsically learns a useful representation automatically without human efforts. However, the success of deep learning highly relies on the large-scale training data. We propose a novel deep learning framework for product review sentiment classification which employs prevalently available ratings supervision signals. The framework consists of two steps: (1) learning a high-level representation (an embedding space) which captures the general sentiment distribution of sentences through rating information; (2) adding a category layer on top of the embedding layer and use labelled sentences for supervised fine-tuning. We explore two kinds of low-level network structure for modelling review sentences, namely, convolutional function extractors and long temporary memory. Convolutional layer is the core building block of a CNN and it consists of kernels. Applications are image and video recognition, natural language processing, image classification
Keywords : Deep Learning, Opinion Mining, Sentiment Classification.
I. INTRODUCTION
With the booming of ecommerce, individuals are getting used to consuming online and also composing comments concerning their acquisition experiences on merchant/review Internet sites. These opinionated components are beneficial resources both to future consumers for decision-making and also to sellers for enhancing their items and/or service. However, as the quantity of evaluations grows rapidly, individuals need to encounter a severe information overload trouble. To minimize this problem, many viewpoint mining techniques have been proposed, e.g. point of view summarization [8], viewpoint polling, and also comparative evaluation [2] The crucial obstacle is exactly how to precisely forecast the sentiment
just handle implicit point of views in an ad-hoc means. The very first machine learning based view classification job applied popular device finding out formulas such as Ignorant Bayes to the problem. After that, most research study in this revolved around attribute design for much better classification performance. Feature engineering likewise costs a great deal of human efforts, as well as a feature set ideal for one domain name might not generate excellent performance for various other domains. In recent times, deep learning has actually emerged as efficient methods for fixing sentiment category troubles. A deep semantic network fundamentally finds out a high-level representation of the data [2], hence preventing tiresome work such as feature design. A second advantage is that deep
designs have significantly stronger expressive power than superficial versions. Nonetheless, the success of deep discovering heavily depends on the schedule of large training data. Identifying a lot of sentences is customer reviews and have currently been made use of for view analysis. Nonetheless, evaluation scores are not reliable labels for the basic sentences, e.g. a 5-stars evaluation can have negative sentences and also, we might additionally see favorable words periodically in 1 celebrity reviews. Regardless of the encouraging efficiency of deep knowing on sentiment classification, no previous work attempted to leverage the prevalently readily available scores for training deep models. In this job, we propose a novel deep knowing structure for review sentence belief classification. The structure treats review ratings as tags to train deep semantic networks. For instance, with 5-stars range we can consider rankings above/below 3-stars as positive/negative tags
respectively. The structure generally includes two steps. rating-inconsistent positioning (hereafter called wrong-labeled sentences), we suggest to punish the loved one ranges among sentences in the embedding area via a ranking loss. In the second step, a classification layer is added top of the embedding layer, and also, we make use of labeled sentences to adjust the deep network.
II. RELATED WORK
View evaluation is a long-standing research study subject. Visitors can refer to for a current study. Belief category is among the essential tasks in sentiment analysis and also can be classified as paper level, sentence degree and element level. Conventional maker discovering techniques for belief classification can generally be put on the three levels. Our job comes under the last classification since we take into consideration element info. In the following we assess 2 subtopics carefully related to our work.
domain adjustment issue of sentiment category. Socher et al. suggested a collection of Recursive Neural Network designs for belief classification. These methods find out vector representations of variable-length sentences through compositional calculation recursively. Kim examined utilizing CNN for sentence sentiment classification as well as discovered it outshined ReCNN. An alternative CNN with vibrant k-max merging as well as numerous convolution layers were suggested. Researchers have additionally explored utilizing consecutive versions such as Recurrent Neural Network (RNN) such as Lengthy Short-Term Memory for belief category. Le as well as Mikolov established an unsupervised embedding knowing method for sentences, paragraphs as well as files. Two easy network versions were suggested which were inspired. Kiros et al proposed the unsupervised skip-thoughts design which generalized the skip-gram model to the sentence level. The vital suggestion was to make use of the embedding representation of a sentence to anticipate its surrounding sentences. A supervised sentence embedding discovering structure was proposed by Wieting et al., where sentence similarity in the embedding area was trained according to a paraphrase data source via a margin loss. Just recently, neural models have been recommended for element degree view category.
III. PROPOSED MODEL
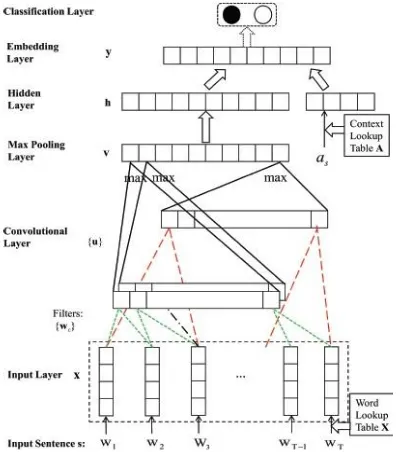
Network Architecture in General: The basic design of the neural network made from DE, at the very first layer, the network takes a review sentence as input as well as removes a fixed-length low-level function vector from the sentence. Unlike several traditional techniques for view analysis, no feature engineering is called for and also the extractor is discovered instantly. Details implementation of the extractor will certainly be discussed in the adhering to for DE-CNN. The low-level feature vector is then gone through a surprise layer, adding enough nonlinearity,
and also the result is utilized to compute the embedding representation of the sentence. The embedding representation likewise takes the sentence's aspect contextual info into consideration. An element is a topic on which customers can comment with respect to a type of entities. As an example, battery life is an element for cellular phone. We make use of a learnable context vector to stand for an aspect.
Eg. "the screen is big" vs. "the dimension allows". In the supervised training stage, the goal is to find out and also embedding room which can appropriately show data's semantic distribution. For this reason, the network made use of in this stage includes just the layers as much as the embedding layer. The last category layer is added in the adhering to monitored training phase, in order to find out the last forecast design.
Fig 1: The network architecture for DE-CNN.
The trainable word lookup table X is then a k n matrix with word vectors as its columns. The input layer merely maps s =< w1w2::: wT > to its corresponding word vector depiction < x1x2::: xT >. The lookup table is initialized utilizing the publicly offered 300-dimensional word vectors educated on 100 billion words from Google Information by word2vec. Out-of-sample words are initialized arbitrarily.
Embedding Training with Ratings: With the label meaning, we can separate testimonial sentences right into two sets: P = fsj '(s) = posg as well as N = fsj '(s) = negg. Since P and N include wrong-labeled sentences, they cannot straight be utilized to train a classifier. Consequently, we suggest to first train and embedding area that captures the general belief circulation of sentences. With ease, we must allow sentences in P/N stick, while keeping P as well as N divided. A straightforward training plan could be adjusted from [50] by stochastic gradient descent (SGD): we example sentence pairs as well as reduce ranges for same-label sets and enhance ranges for opposite-label pairs. Nonetheless, when wrong-labeled sentences are tested, there is still a relatively high opportunity that we make an incorrect move.
To alleviate this problem, we recommend penalizing relative distances for sentence triplets. The training purpose is specified as a ranking loss [5].
Fig 2 : Comparison between (a) pair-based training and (b) triplet-based training.
This serves in that we will certainly not make points regrettable. For instance, in instance 2 of Figure 2(b) s2 is actually a negative sentence as well as should not be also near s1. Notification s3 is far away from s1. Hence, the range difference might already go beyond _ and there will be no action for this triplet. As a contrast, situations 1 and also 2 in Number 2(a) will continuously move s1 as well as s2 towards each other until their distance ends up being 0, which is the worst outcome.
Supervised Fine-tuning: After getting a good enough sentence representation by the embedding layer, we include a category layer on the top (Figure 1) to further train the network utilizing labeled sentences. The category layer merely executes basic affine change of the embedding layer output y and afterwards applies a SoftMax activation feature [3] to the outcome for tag prediction. In this job, we focus on binary sentiment forecast (i.e. positive or negative) given that we just consider sentences which comment on specific facets of an entity. This type of sentences hardly consists of neutral sentences. However, DE could additionally be adapted to multi-class prediction troubles. For binary prediction, the category layer is equivalent to a logistic regression design. We educate the network utilizing basic SGD, because AdaGrad can quickly "neglect" the prior version found out in the first phase. The mini-batch size is set to 64. A comparable early stopping strategy is embraced as in the embedding training stage.
IV.IMPLEMENTATION
1. Login
2. User searching for their particular product
3. Showing ratings for the products
4. Showing 5-star ratings to the products
V.CONCLUSION
In this work we proposed a unique deep discovering structure named Deep Embedding for review sentence sentiment category. DE trains deep semantic networks by manipulating score details of reviews which is prevalently available on lots of merchant/review Sites. The training is a 2-step treatment: first we find out and also embedding space which tries to record the sentiment circulation of sentences by punishing family member ranges amongst sentences according to weak tags inferred from scores; then a SoftMax classifier is added top of the embedding layer and also, we fine-tune the network by classified data. Experiments on reviews gathered from Amazon.com reveal that WDE works as well as outmatches standard approaches. Two specific instantiations of the structure, DE-CNN, is proposed. Contrasted to DE-LSTM, DE-CNN has fewer model criteria. However, DE-CNN cannot well take care of long-term dependencies in sentences. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In WWW, pages 519-528, 2003.
[2]. S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman. Indexing by latent semantic analysis. Journal of the American society for information science, 41(6):391, 1990. [3]. X. Ding, B. Liu, and P. S. Yu. A holistic lexicon-classification. In ACL, pages 49-54, 2014.
[5]. J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. JMLR, 12:2121-2159, 2011.
[6]. R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C. J. Lin. Liblinear: A library for large linear classification. JMLR, 9:1871-1874, 2008.
[7]. R. Feldman. Techniques and applications for sentiment analysis. Communications of the ACM, 56(4):82-89, 2013.
[8]. J. L. Fleiss. Measuring nominal scale agreement among many raters. Psychological bulletin, 76(5):378, 1971.
[9]. X. Glorot, A. Bordes, and Y. Bengio. Domain adaptation for large-scale sentiment classification: A deep learning approach. In ICML, pages 513520, 2011.
[10].Y. Bengio. Learning deep architectures for ai. Foundations and trendsR in Machine Learning, 2(1):1-127, 2009
[12].C. M. Bishop. Pattern recognition and machine learning. springer, 2006.
[13].L. Chen, J. Martineau, D. Cheng, and A. Sheth. Clustering for simultaneous extraction of aspects and features from reviews. In NAACL-HLT, pages 789-799, 2016.
[14].R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa. Natural language processing (almost) from scratch. JMLR, 12:2493-2537, 2011.
Cite this article as :