N ariyoshi YAM AI*, T adashi S E K O t, Noboru K U B O ^ and Toru K A W A TA ^ t D ep artm en t of Inform ation Engineering, N ara N ational College of Technology,
Y am atokoriyam a, N ara 639-11, Ja p a n
I t C o m p u ter System s L aboratories, C o rp o rate Research and D evelopm ent G roup, SH A R P C o rp o ratio n , Tenri, N ara 632, Ja p an
A n Efficient E n u m e r a t i o n A l g o r i t h m o f P a rses
for A m b i g u o u s C o n t e x t - F r e e L a n g u a g e s
A bstract
An efficient algorithm th a t enu m erates parses of am biguous context-free languages is described, and its tim e and space com plexities are discussed.
W hen co n text-free parsers are used for n a tu ra l language parsing, p a tte rn recognition, and so forth, there may be a g rea t num ber of parses for a sentence. One com m on stra te g y for efficient en um eratio n of parses is to assign an a p p ro p ria te weight to each p ro d u ctio n , and to en u m erate parses in th e order of the to ta l weight of all applied p ro d u ctio n . However, th e existing algorithm s taking this stra te g y can be applied only to the problems of lim ited areas such as regular languages; in th e o th er areas only inefficient ex haustive searches are known.
In this p a p e r, we first in tro d u ce a hierarchical g rap h su itab le for en u m eratio n. Using this g raph , enu m eration of parses in the ord er of accep tab lity is equivalent to finding p ath s of this g raph in the order of length. T h en , we present an efficient enu m eration algorithm w ith this g raph , which can be applied to arb itra ry context-free g ram m ars. For en um eration of k parses in the order of the to ta l weight of all applied productions, the tim e and space com plexities of our algorithm are 0 ( n 3 + k n 2) and 0 ( n z + fcn), respectively.
1
I n tr o d u c tio n
Context-free p arsers are com m only used for n a tu ra l language parsing, p a tte rn recognition, and so fo rth. In these ap p lic atio n s, th ere m ay be a g rea t num ber o f parses (or deriv ation s) for a sentence, only a few of which would be needed in la te r processes. T herefore, we look up only a few prom ising parses and do not make an inefficient ex h au stiv e search of parses. In order to find a few prom ising parses efficiently, we often take a stra te g y th a t an a p p ro p ria te weight is assigned to each p ro d u ctio n and parses are looked up in the order of th e to ta l weight of all applied p ro d u ctio n s. If the assigned weight is selected carefully to have strong co rrelatio n to w h eth er a p arse is accepted or not, looking up parses in the ord er of the to ta l weight is equivalent to e n u m e ratio n of parses in the o rd er o f acceptability. For exam ple, in the p u n c tu a tio n problem of Japan ese sentences, the nu m b er o f th e phrases of the sentence is known to be an excellent c a n d id a te for the weight of parses. However, th e alg o rith m s proposed so far th a t took this s tra te g y are applied only to the problem s of the lim ited areas such as regular languages, and they are not applied to general con text-free languages.
In this p ap er, we present an efficient en u m eratio n algorithm based on this strateg y , which can be applied to general co n tex t-free g ram m ars. We in tro d u ce a d a ta s tru c tu re su ita b le for en u m eratio n of parses nam ed
a parse graph, and present how to c o n stru c t a parse graph in section 3. W ith a parse grap h , a p a th between two special vertex, some of whose arcs are replaced iteratively by the p ath denoted by their labels, represents a right parse of the parsed sentence. Because the length of path s represents the to ta l weight of all applied p ro d u ctio n s for parses, enu m eratio n of parses in the order of the to ta l weight of all applied p rod u ctio n s is equivalent to finding p ath s on the parse g raph in the order of length. In section -4. we show the outline of how to en u m e rate the parses of th e am biguous sentence in the order of their weight, using the parse graph. We also discuss the tim e and space com plexities of the algorithm in th a t section.
2
C o n tex t-F re e Parsing A lg o rith m
Several general context-free parsing algorithm s have been proposed so far, nam ely C ock e-Y ou ng er-K asam i algorithm [2, 3], E arley ’s algorithm [4], V alian t’s algorithm [5j, G ra h a m -H a rriso n -R u z z o algorithm [6, 8], and so forth. T h e features of these algorithm s are the following. C o ck e-Y o u n g er-K asam i algorithm (CYK alg o rith m for sh o rt) is a kind of the bo tto m up parsing algorithm s, and has 0 ( n 3 ) tim e com plexity, w h e r e n
is the length of the sentence. In this algorithm , the g ram m ar is required to be w ritten in Chom sky normal form. E a rle y ’s algorithm is a kind of th e top down parsing algo rith m s, and has 0 ( n 3) tim e com plexity. By c o n tra s t w ith CYK algorithm , no special pro d u ctio n form is required in E a rle y ’s algo rith m . V alian t’s alg o rith m and G ra h a m -H a rriso n -R u z z o algorithm (G H R algorithm for sh o rt) are the m odified versions of CYK algo rithm and E a rle y ’s algo rith m , respectively. B oth of them use th e technique of m atrix m ultiplication in order to reduce the tim e com plexity, T he tim e com plexity of V a lia n t’s algo rith m is 0 ( n2 81) and th a t of
G H R a lg o rith m is 0 ( n 3/ l o g n). However, in b o th algorith m s, the overhead for m atrix m u ltip licatio n is so large th a t these algo rithm s d o n ’t seem su itab le for the p ractical use.
In this p ap er, we ad o p t E a rle y ’s algorithm as the base of our algorithm because of the following two reasons:
(1) No special p ro d u ctio n form is required.
(2) E a rle y ’s alg o rith m seems m ore su ita b le th a n V a lia n t’s algorithm and G H R alg orith m because the overhead of these two alg o rithm s is qu ite large.
Let G = (V^v, Vt, P , S ) be a g ram m ar, w here V y is the set of no n term in al sym bols, V j is th e set of te rm in a l sym bols, P is th e set of p ro d u ctio n s, and 5 € V y is the s ta r t sym bol. In E a rle y ’s alg o rith m , the item lists /q, A , . . . , I n+i are c re a te d , w here n is the length of th e parsed sentence. Each item list consists o f several i t ems [A — a ■ /3 (p), / ] , w here A — a ft G P, p is the index num ber of the p ro d u ctio n , is the m e ta sym bol th a t shows how much of th e right side of th e pro d u ctio n has been recognized so far, and / is an integer which den otes the p osition in th e in p u t strin g at which we began to look for th a t in sta n c e of the p ro d u ctio n . T h e set of item lists {/o, A , . . . , / n , / n+ i} is called the parse list.
As for th e tim e and space com plexities for E a rle y ’s alg o rith m , the following are know n[l].
( e - 1 ) T h e tim e and space com plexities for parsing a sentence by E a rle y ’s alg orith m are 0 ( n 3) an d 0 ( n 2), respectively, w here n is th e len g th of the parsed sentence.
( e - 2 ) T h e tim e com plexity for deriving a parse from the parse list is 0 ( n 2), w here n is the len g th of the parsed sentence.
3
Parse G raphs
3.1 T h e f e a t u r e s o f p a r s e g r a p h s
The parse g raph is a d irected graph which consists of several connected com po nen ts. Each connected com ponent is called a layer of the parse graph. Each layer is an acyclic g raph th a t has only one source, and it co rresponds to eith er a non term in al sym bol or an integer. An layer co rresponding to a n o nterm in al sym bol has only one sink. W ith this grap h , we can e x tra c t parses more efficiently th an with a parse list of E arley ’s alg orith m . As shown in the next section, a path between two special vertex, some of whose arcs are replaced iteratively by the p ath d enoted by their labels, represents a right parse of the parsed sentence.
In the rem aind er of this paper, we use the following n o tation s. L ( f ) T h e layer corresponding to an integer / . L{ A) T h e layer corresponding to a non term inal sym bol .4. L( v) T he layer containing a • tex v.
L(e) T h e layer containing an ^.rc e.
Uj(A') T he source of the layer L ( X ) , where X is eith er an integer, a n on term inal sym bol, a vertex, or an arc.
vt( A ) T h e sink of the layer L{A) , where .4 is a n o n term in al sym bol. Note th a t the layer co rresponding to a nonterm in al sym bol has only one sink.
In the parse g rap h , each arc has one of the following labels.
(1 ) An index num ber of the p ro d u ctio n p, which denotes the derivatio n by .4 — a (p). (2 ) A n o n term in al sym bol A, which denotes the derivation A ^ e.
(3 ) T h e index of a vertex v, which denotes the p a th from u ,(y ) to v.
W hen we describe the arc e = (m, v) w ith its label of each kind, we use the n o tatio n s e(p), e( A) , e[u], or the a lte rn a tiv e n o tatio n s (u ,t> ;(p )), ( u , v \ ( A ) ) , (« ,u ;[v j), respectively.
In stead of an item of the form [A — ot-fi (j>), / ] in E a rle y ’s algorith m , we use the trip le t [.4 — or-/? (p), / , y] as an item o f our algorithm for c o n stru c tin g a parse grap h , where v is th e index of a vertex.
For exam ple, we parse the sentence xx of the gram m ar shown in Figure 1. T h e parse list and the parse graph g e n e ra te d from this sentence are shown in Figure 2 and Figure 3, respectively.
In Figure 3, th e label “(2 )” of th e arc from v ertex # 8 to vertex # 9 ind icates th e d erivation by 5 — 5 / (2), the label “ ( 5 ) ” of th e arc from vertex # 0 to vertex # 1 in d icates the derivation 5 ^ 6 , and th e label “[7]” of the arc from vertex # 2 to vertex # 8 in d icates the p ath s from vertex # 0 to vertex # 7 .
O ur algo rith m for c o n stru c tin g a parse g rap h is based on E arley ’s algorithm . In E a rle y ’s algorithm , one of three o p eratio n s is perform ed on each item , d epending on its form, to add m ore item s to the item lists. In our alg orith m , these o p eratio ns not only add m ore item s to item lists b u t also add new vertices and arcs to the parse g rap h, shown as follows.
3 .2 A n a lg o r it h m for c o n s t r u c t in g a p a r s e g r a p h
S - € (1) S — S J (2) J - F (3) J -* / (4) F —* x (5)
I —►X (6)
Figure 1: An am biguous context-free g ram m ar
Io
h
S' — •5$ (0), 0, 0
s — (1), 0, 0
s — ■S J (0), 0, 0
' S' — S - $ (0), 0, 1
s — 5 • .7 (2), o, 2
J — ■F (3), 0, 0
J — ■I (4), 0, 0
F — ■i (5), 0, 0
I —- ■i (6), 0, 0
F — x • (5), 0, 0
I — x- (6), 0, Q
J — F- (3), 0, 4
J — I- (4), 0, 6
s — S J - (2), 0, 8
S' — S - $ (0), o, 10
s — 5 • J (2), 0, 11
J — ■F (3), 1, 12
J — ■I (4), 1, 12
F — ■x (5), 1, 12
I —* ■I (6), 1, 12
F — X" (5), 1, 12
I — I- (6), 1, 12
J — F- (3), 1, 14
J — I- (4), 1, 16
S — S J - (2), 0, 18
S ' — s ■ $ (0), 0, 20
s — 5 • J (2), 0, 21
J — ■F (3), 2, 22
J — ■I (4), 2, 22
F — ■x (5), 2, 22
I — ■X (6), 2, 22
S' — 5$ . (0), o, 20
Layer 0:
.i? * * 0 j z u 0 j.2lK 3
2 8 g
|- (- - K D
\ ( 3 )
h'-^KD >
5 ,/ * 7
[51 / < 4 >
6 [9]
K D 10
^Uoiizi*o<2
i>o
11 18 19
[19]
20
[19] * o
21
Layer 1:
r — K D
13
\ ( 3 ) ^ 15 >/▼ 17
[151 / < 4 >
12 18
Layer 2:
o
22Layer S:
y-V»<S) vi(S)
(p) : a label "production p"
[v] : a label “vertex v“
<S> : a label "nonterm inal S'
Figure 3: A parse graph for the sentence xx of the g ram m ar in Figure 1
h :
re 2: A parse list for th e sentence xx of the g ram m ar in Figure 1
[image:5.560.5.543.18.737.2]T he s canner is perform ed when an item in Ij is of the form [.4 — a ■ aJ + l 3 ( p ) , f , v ] . It puts the item [*4 — a a j+1 • 3 {p), / , v] to Ij + l .
O p e r a t i o n 2 ( p r e d i c t o r )
T he predictor is perform ed when an item in Ij is of the form [.4 — a • B 3 [ p ) , f , v]. It adds item s [B — •7 k (Pk) * j i i>iO)] for B -productions B — ~{k (pk) to Ij,except in the case where these item s have already been added to Ij. If the vertex v , ( j ) have not been created yet, the predictor creates v , { j ) to the layer L ( j ) . Especially, in the case where B => C LC2 • • • C m e and C LC V - - C m G V y , the p red ictor adds the vertices vs{B) , v u u2, . . . , ym_ ! , vm , vt{B) , and the arcs ( t>,( B) , v{\(C L)), ( , i'2;( C 2)), ( e?2, vy, (C 3)), ( t'm —21 ym — I i ( C m— L ) ) t ( ^m —1 ? L'm ; (C m)), ( um, (p)) to 1 ( 5 ) if they are not in L{ B) , and perform s one of the following:
( a ) If an item of the form [.4 — q B • 3 (p ) , f , w ] is already in Ij, then add the arc (v , w \ ( B )) to the parse g rap h .
( b ) O therw ise, add the vertex w and the arc ( v , w ' , ( B ) ) to the parse grap h , and add the item [.4 — q B • 0 [ p ) , f , w ] to Ij.
O p e r a t i o n 3 ( c o m p l e t e r )
T h e com pleter is perform ed when an item in Ij is of the form [.4 — a • ( p ) , f , v ] . It perform s one of the following:
( a ) If / = j , th en the item would be processed by the p red ictor. T herefore, the co m pleter does nothing. ( b ) If / ^ and th ere exists an item of the form [A — ,3• (9-),/, u] ( p ^ q, u ^ v ) in /j, and th e arc
(u, w; (<7)) in the parse g rap h , then add the arc (v, w\ (/>)) to the parse grap h.
(c ) O therw ise, add a new vertex 1 and a new arc { v , x ; ( p ) ) to the parse g rap h . F u rth erm o re, for all items
of the form [Bk — Ik ■Abk ipk), f k , ^ k ] in / / , perform one of the following:
( c -1) If th ere exists an item o f the form [Bk — 7*.4 • 6k (p k ) , f k , V k] in Ij w here u k ^ v*, th en add a
new arc [ uk , i>*;[1]) to the parse graph.
( c -2) O therw ise, add a new vertex vk and a new arc (u*, t;*; [z]) to the parse g rap h , and add a new item [Bk — 7k A ■6k (Pk), A , Vfc] to Ij.
We describe our algorith m for c o n stru c tin g a parse graph as follows:
A lg o r ith m 1. A n a lg o r ith m for c o n s tr u c tin g a p a rse grap h
A co n tex t-free g ram m ar G = { Vy , V j, P, S ) and a sentence a La2 • • • a n are given.
[step 1] A dd th e m e ta sym bol “ $n to th e tail of the sentence. Add th e p ro d u ctio n S ' — 5$ (0) to P. C re a te the parse grap h co n sisting of r , (0). C re a te the item list Iq consisting of [5 ' — -5$ (0), v,(0)].
[step 2] C re a te th e item lists Iq , /
1
,. . . , /„+ i in order, by perform ing the following o p e ra tio n s from k = 1to k = n.
O p e r a t i o n 1 ( s c a n n e r )
(1 ) Perform the predictor or the com pleter to add item s to the item list Ik, until no more item s can be added to I
( 2 ) T h en, perform the scanner to add item s to
Ik+i-[ s te p 3] If / n+i has an item of the form Ik+i-[5 / —* 5$ • (0), u], then it m eans th a t the parser accepts the sentence, and the algorithm term in ates. O therw ise, it m eans th a t the p arser rejects the sentence, and th e algorithm term in ates.
Note th a t this algorithm is the sam e as E arley's algorithm except the portion for co n stru ctin g a parse graph.
As for the tim e and space com plexities of this algorithm , the following theorem holds.
T h e o r e m 1. The tim e and space com plexities of our algorithm are b oth 0 ( n 3), where n is the length of the sentence.
(p ro o f) C onsider the num ber of item s in the item lists. Acc«. .ding to th ree o p eration s, nam ely the scanner, th e p redictor and the com pleter, each item list does not have item s such th a t their first and second com ponents are the sam e. T herefore, each item list has 0 ( n ) item s, because th e num ber of th e kinds of the first com po nen t is c o n sta n t, and th a t of the second com ponent is not more th an n + 2. Hence, th e num ber of item s of the parse list is 0 ( n 2), because the parse list consists of n + 2 item lists. Consider the tim e and space com plexities of th e o p eratio n s per item .
(1) As for the scan ner, the tim e and space com plexities are both 0 ( 1 ) .
(2) As for the p red icto r, at m ost 0 ( \ P \ ) item s are added to the item list, and 0 ( | P | ) vertices and arcs are a dd ed to the parse g rap h , where |P | denotes the nu m ber-of the p ro d uctio ns. T herefore, the tim e and space com plexities are both 0 ( | P | ) = 0 ( 1 ).
(3) As for th e co m p leter, if the second com ponent of the perform ed item is / , th e com pleter scans all item s in I f , adds at m ost 0 ( n ) item s to the item list, and adds at m ost 0 ( n ) vertices and arcs to the parse g rap h . T herefore, the tim e and space com plexities are b o th 0 ( n ) .
C onsequently, the tim e and space com plexities of the o p eration s per item is 0 ( n ) . T herefore, the tim e and space com plexities of the parse g rap h c o n stru ctio n algorithm are both 0 ( n 3). □
C o m p ared w ith (e -1 ) in section 2, th e tim e com plexity for c o n stru c tin g a parse g rap h is th e sam e as E a rle y ’s alg o rith m , but the space com plexity is worse because the num ber of arcs in a parse g rap h is 0 ( n 3).
4 E n u m e r a tio n o f P arses
4.1
E xtracting parses
In ord er to e x tra c t parses from a parse grap h , we in tro d u ce a traversal paths of a parse g rap h . T h e n o ta tio n 7r( u, v ) rep resen ts trav ersal p a th s from u to v.
A traversal path from a vertex it to a vertex v is defined as follows provided th a t L( u) = L(v). (1 ) A null sequence is defined as a trav ersal p a th if u = v .
( 2 ) T h e sequence of the arcs where e x = ( i t , - , i \ ) , is defined as a traversal pa,th if a = u i , v i =
U o, U2 = « 3 . • • • . y n - l = « n , = y
-( 3 ) Let e i e2 • • • c n be a trav ersal p a th from u to v. in which an arc e; is labeled w ith a no nterm in al sym bol
.4. T he-sequence of the arc e'i • • • e,_ i tt( i’3( .4). i’t(.4))e,-+i • • • en in which e,(.4) is replaced by a trav ersal p a th JrfwjM ), is defined as a traversal path.
(4 ) Let eieo • • • en be a traversal p a th from u to u, in which an arc e, is labeled with the index of a vertex v. T h e sequence of the arc e L • • • e ,_ Lx (vs[v), v)e, + l • • • en in which e,[u] is replaced by a traversal path i c[v, ( v) , v) is defined as a trav ersal p ath .
Especially, th e traversal p a th th a t has only the arcs labeled with the index of the p ro d u ctio n is called a proper traversal path. T he n o tatio n r* (u , v) represents proper trav ersal p a th s from u to v. T his n o tatio n is also used to represent the sequence of the labels of the proper trav ersal p ath s.
As for th e relatio nship betw een proper trav ersal p a th s and parses, the following theorem holds.
T h e o r e m 2. If there exist two item s [A — or • 7 (p), / , u] E / j , [-4 — a/3 • 7 (p), / , v] € Ik, where a ,/? , 7 G V m, the sequence of the labels r * ( u ,v ) is the reverse order of the sequence of the p ro du ction num b ers used for the rightm ost derivation aJ + 1 • • • .
r m
(p ro o f) It is easy to prove this theorem by induction on the length of the derivation sequence. □
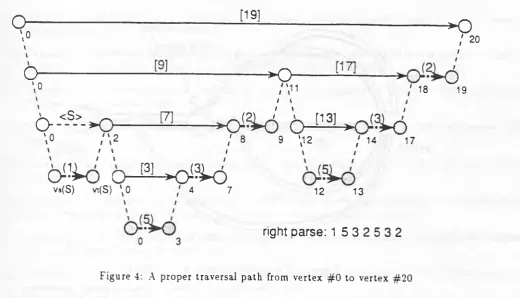
Let u((0) be th e th ird com p o n en t v of the item [5' —• 5 S ■ (0), 0, v] € / n+1- A ccording to th eorem 2, th e sequences of the labels 7rm( u,(0), vt(0)) represent the right parses of the parsed sentence. An exam ple of
a p ro p er tra v e rsa l p a th of the parse graph in Figure 3 is shown in Figure 4, w here Uj(0) is vertex # 0 and yt(0) is v ertex # 2 0 .
A right parse can be e x tra c te d from the parse grap h by searching a p ro p er trav ersal p a th from i/f(0) tow ard tfj(O). T his e x tra ctio n can be done w ith o u t backtracking, because each layer has only one source. T h erefo re, th e following theorem holds.
T h e o r e m 3. If the given g ra m m a r is cycle-free, the tim e com plexity for e x tra c tin g a parse is O (n), w here n is the len gth of th e sentence.
(p ro o f) If the g ram m ar is cycle-free, th e length of the parse is O( n) . T h erefo re, the tim e com plexity is
O( n) . □
C o m p ared w ith (e -2 ) in section 2, th e tim e com plexity for e x tra c tin g a parse is b e tte r th a n E arley ’s alg o rith m .
4.2
An algorithm for parse enum eration
Using a parse g rap h , en u m e ratio n of the parses in the order of the to ta l weight is equivalent to enum eration of th e p ro p er tra v e rsa l p a th s from ^j(O) to vt(0) in the ord er of th e len gth . W hile m any researchers have developed th e alg o rith m s for finding th e k sh o rte st paths[9, 10, 11, 12, 13], we ap ply one of them developed by K a to h , Ib ara k i and Mine[10] to th e parse grap h recursively. Because of the lack of the space, we explain
o --- ^ --- O
\0
!
20I
O --- s --- K D --- ^ --- >
_\ ° / v 1 ,' 18 W 19
I \ I \
fy
-<-s->- >o--- 0-- ( > [131 >0 ^ -6
\0
! \ 2; 8
9 ',12/
14 17i \ i \
o!!k) a J5 U o !^ d
vs(S) vt(S) \ 0 / 4 7 12 13
right parse: 1 5 3 2 5 3 2
Figure 4: A proper trav ersal p a th from vertex # 0 to vertex # 2 0
only the o u tlin e of the algo rith m . T h e details of the algorithm are described in [14]. In the following discussion, the k -th sh o rte st trav ersal p a th from i/,(0) to vt(0) is referred to as x*.
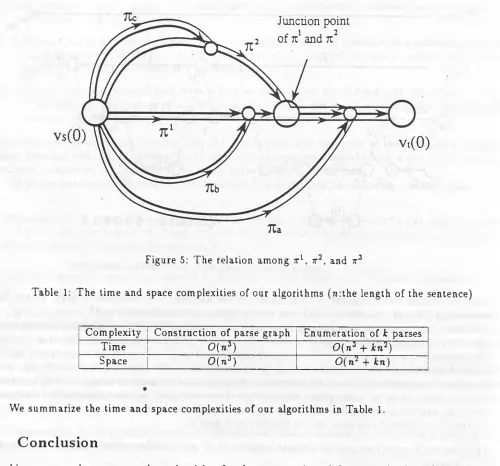
First of all, derive the shortest path tree for v ,(0 ), den oted as T ( v s(0)), which consists of the arcs of the sh o rte st p a th s from i!,(0 ) to all o th er vertices. T h e sh o rtest p a th tree can easily be derived in the alg orithm for c o n stru c tin g a parse g rap h , x 1 can be e x tra cte d from T (u J(0)). tt2 consists of th e p a th o f T ( v ,( 0 ) ) from M O ) to a vertex u, the arc (u, v) where v is one of the vertices on 7T1, and the su b p a th of from v to v*(0). T herefore, th e num ber of th e c a n d id ates of tt2 is the sam e as the sum o f the in-degree of all vertices on th e
sh o rte st p a th . As for the parse g rap h , the length of the sh o rte st p ath and the in-degree of a vertex are b o th 0 ( n ) [ l4 ] , and hence we can derive tt2 in 0 ( n 2). In order to derive t 3, all p a th s from vf (0) to ut(0) except
tt1and x 2 are divided into th re e sets as follows (see Figure 5):
(1 ) T h e set of p a th s th a t jo in the s u b p a th com m on to tt1 and tt2. T he sh o rte st p ath in this set is referred
to as i a .
(2 ) T h e set of p a th s th a t jo in x 1, and con tain the s u b p a th com m on to x l and x 2 as their final s u b p a th . T h e sh o rte s t p a th in th is set is referred to as x*,.
(4 ) T h e set of p a th s th a t jo in x 2, and contain the su b p a th com m on to x 1 and x 2 as their final s u b p a th . T h e sh o rte st p a th in this set is referred to as xc.
xa , Xi, and x c can be derived in th e sam e m an ner as deriving x 2 in 0 ( n 2), respectively, x 3 is the sh o rte st one of xa , Xfc, and xc, and the rest of these p ath s are stored in a n o th e r set as th e c a n d id a te s o f x 4. x 4, x 5, . . . are derived by rep e a tin g the sim ilar calcu latio n . T herefore, the tim e and space com plexities of the e n u m e ratio n of the k sh o rte st p a th s are 0 ( n 3 + k n2) and 0 ( n 2 + k n), respectively.
In th e above discussion, the k sh o rte st p a th s are derived. However, we can also derive the k longest p ath s in the sam e m an ner.
[image:9.560.35.556.53.351.2]Figure 5: T h e relation am ong tl , x2, and t3
T able 1: T h e tim e and space com plexities of our algorithm s (n :th e length of the sentence)
C om plexity C o n stru ctio n of parse graph E num eration of k parses
T im e 0 ( n 3) 0 ( n 3 + k n2)
Space 0 ( " 3) 0 ( n2 4- k n)
We su m m arize th e tim e and space com plexities of our algorithm s in Table 1.
5
C o n clu sio n
In this p a p e r, we have p resented an alg o rith m for th e en u m eratio n of the parses in th e ord er of th e accept ability. T h is alg orithm can be applied to th e general context-free languages. In order to e n u m e rate parses efficiently, we have in tro d u c ed a d a ta s tru c tu re su itab le for the en u m eratio n called th e parse grap h . Using a parse g rap h , we can e n u m e rate k parses in th e order of accep tab ility efficiently in 0 ( n z + k n 2).
A c k n o w le d g e m e n t
We a p p re c ia te Prof. Isao Shirakaw a and Prof. Hideo M iyahara of O saka U niversity for th eir helpful s u p p o r t .
T h e first a u th o r th a n k s Prof. T oshiro A raki, Dr. Hiroshi Deguchi, Dr. Shinji S him ojo of O saka University, a n d Mr. T oshiyuki M asui of S H A R P C o rp o ratio n for their helpful suggestions an d co m m en ts on this paper.
[image:10.552.35.535.62.528.2]1] Aho, A. V. and Ullman, J. D., The Theory of Parsing, Translation, and Compiling, Vol. 1:Parsing,
Prentice-Hall, 1972.
Kasami. T., “An efficient recognition and syntax analysis algorithm: for context-free languages” , Science Report, AF CRL-65-758, Air Force Cam bridge Research Laboratory, 1965.
Younger, D. H., “ Recognition and parsing of context-free languages in time n 3” , I nformation and Control, 10, p p . 189-208, 1967.
Earley, J., “ An efficient context-free parsing a lgorithm ” , Communi cati on of A. C. M. , 13-2, p p .94-102, 1970.
Valiant, L. G., “General context-fiee recognition in less th an cubic tim e ” , J.C.S.S., 10, p p .308-315, 1975.
G ra h a m , S. L., Harrison, M. A., and Ruzzo, W. L., “On line context-free recognition in less than cubic tim e ” , Proc. 8th Annu. A. C . M . Symp. on Theory of Computing, p p . 112-120, 1976.
G ra h a m , S. L., and Harrison, M. A., “ Parsing of general context-free languages” , Advances in C o m p u t ers, 14, Academic Press, pp.415-462, 1976.
G r a h a m , S. L., and Harrison, M. A., “An improved context-free recognizer” , A. C . M . Trans, on Pro gra mmin g Languages and Systems, 2-3, p p .415-462, 1980.
Yen, J. Y., “ Finding the K shortest loopless paths in a netw ork” , M anag eme nt Science, 17, p p .712-716, 1971.
K atoh, N., Ibaraki, T ., and Mine, H., “An efficient algorithm for K sh ortest simple p a th s ” , Networks, 12, p p .411-427, 1982.
Fox, B. L., ‘‘D a ta s tru c tu re s and c o m p ute r science techniques in operations research” , Operations Research, 26, pp.686-717, 1978.
[12] Denardo, E. V., and Fox, B. L., “Sho rtest-ro ute methods: 1. reaching, pruning and buckets” , Operations Research, 27, p p . 161-186, 1979.
[13] Lawer, E. L., “ A p rocedure for c o m puting the K best solutions to discrete op tim izatio n problem s and its application to the s h o rte st pa th p roblem ” , Management Science, 18, p p .401-405, 1972.
[14] Yamai, N., “A s tu d y for parsing of ambiguous languages using hierarchical grap h rep resen tation of all deriv atio ns” , Mast er Thesis of Osaka University, 1986 (in Japanese).